企业开始批量部署Qwen3.6后,AI服务器应该怎么选?
为什么企业开始部署国产大模型?
多模态大模型在文本理解、图像分析、跨模态检索等任务上的能力,已从“可体验”进入“可商用”阶段。金融、政务、能源、教育等行业的AI基础设施正逐步纳入信创体系,国产CPU、国产GPU、国产操作系统的组合成为项目建设的重要前提。与此同时,以Qwen3-VL、qwen3.6、Gemma 4为代表的开源模型降低了部署门槛——企业更倾向于基于成熟开源模型进行私有化部署,通过量化模型快速上线业务,并在后期结合自有数据做轻量级微调。因此,真正的问题已不是“要不要部署”,而是“部署什么模型、需要什么算力、国产化方案能否落地、如何避免并发与扩容瓶颈”。
Qwen3-VL之所以成为当前部署热点,一个重要原因在于其参数覆盖范围足够广——从4B、9B到35B、397B,不同规格模型可以对应不同预算与业务阶段。这意味着企业可以按当前业务复杂度选择对应规格,而不是一步到位采购高配硬件,首次部署AI并不一定需要直接投入大规模GPU集群。许多场景下,一台国产化推理服务器即可完成知识库问答、文档理解、OCR识别、多模态客服等基础能力验证。
但越来越多企业也发现,真正影响上线效果的往往不是“模型能不能跑”,而是并发规划是否合理、显存是否足够、推理框架是否稳定、后续扩容是否方便。企业需要的已不只是硬件参数,而是一套可参考的“模型—配置—并发”对应关系。本篇内容基于赋创实验室实测数据,整理了四档典型国产AI部署方案,分别对应企业从PoC验证到规模化AI服务的不同阶段。
企业部署大模型最常见的四类需求
在实际项目中,企业需求通常会落在四个阶段:
●验证与试点:快速跑通模型推理流程,验证AI是否适合当前业务场景。
●部门级服务:团队长期稳定使用AI,模型精度与并发吞吐成为关键。
●多模型共享平台:多个部门统一调用模型能力,减少重复建设。
●训推一体化:除高频推理外,还需要基于自有数据进行LoRA、QLoRA等轻量级微调,支撑更大规模模型与更高并发。
对应这四类需求,我们整理了以下四种典型国产AI算力方案。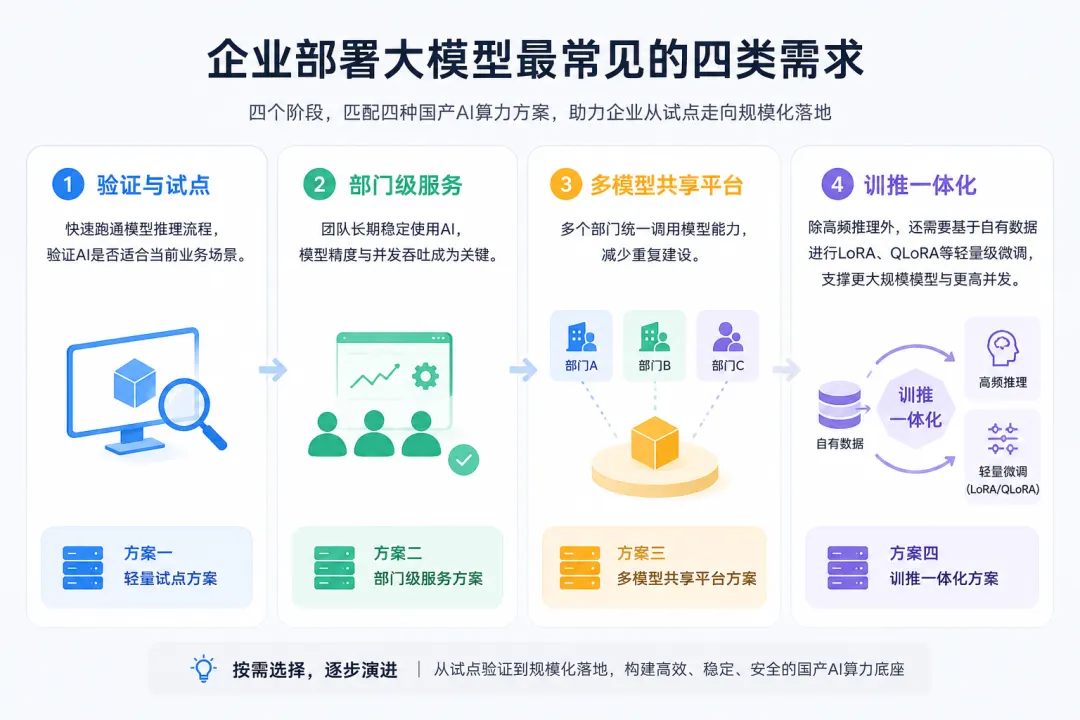
方案一:轻量级国产AI推理工作站方案
适合场景:小规模验证、部门知识问答、轻量视觉AI、文档理解
对于首次尝试AI部署的团队,很多场景并不需要大规模GPU集群。一台基于国产CPU与单张国产推理卡的2U服务器,已能完成AI知识库、OCR识别、PDF问答、图片描述生成等任务。
模型承载
本方案可流畅运行Qwen3.5-4B/9B、Qwen3-VL-2B/4B/8B(INT4/INT8量化版本),单卡推理显存占用通常在20GB以内。Gemma 4 E2B/E4B等相近参数规模模型同样适用。≤5并发下,首token延迟与生成吞吐保持稳定。
核心硬件概要
赋创FG2212-H4平台,搭载1张智铠100 32G推理卡,海光5460双路处理器、64GB内存,预装麒麟V10 SP3。
方案二:部门级国产AI推理服务器方案
适合场景:企业知识库、智能客服、8B模型FP16推理、10人以内团队共享
当AI从试点进入日常使用,模型响应质量与多人并发吞吐的重要性上升。本方案采用双国产推理卡配置,可稳定支撑8B模型全精度推理以及30B级模型量化服务。
模型承载
实测可运行Qwen3-VL-8B FP16、Qwen3.5-9B FP16(显存需求约20GB)和Qwen3.6-35B-A3B Q4量化模型。两张32GB卡留有充裕的KV Cache空间。5–10并发下,各用户获得30–40 tokens/s的生成速度。
核心硬件概要
赋创FG2212-H4平台,GPU扩展至2张智铠100 32G推理卡,海光5480双路处理器,128GB内存。
方案三:企业级多模型并行推理方案
适合场景:多部门共享AI资源池、多模型并发部署、企业AI中台
当AI能力覆盖多个业务部门,企业往往希望同一套硬件同时部署多个模型,以统一API提供服务。此时总显存容量与多模型驻留能力成为关键。
模型承载
可同时加载Qwen3.6-35B-A3B FP16、Qwen3-VL-32B FP16、(显存占用约64-70GB)及多个轻量下游模型。4张64GB卡提供256GB总显存,不同模型可在不同卡上独立部署。实测15–30并发下,32B模型仍保持30–40 tokens/s稳态输出。
核心硬件概要
赋创FG2212-H4平台,搭载4张智铠100 DUO 64G推理卡,海光7470双路处理器,512GB内存。
方案四:国产训推一体旗舰方案
适合场景:235B级模型量化推理、高并发AI服务、LoRA微调、企业级AI中台
随着AI进入核心业务系统,企业开始关注自有数据微调、模型持续迭代以及大规模在线推理。本方案兼顾高并发推理吞吐与参数高效微调的计算需求。
模型承载
●Qwen3.6-35B-A3B FP16,Qwen3.6-122B-A10B FP8高并发:40–100并发,生成速度30–50 tokens/s。
●Qwen3-VL-235B-A22B Q4量化:MoE架构激活约22B参数,量化后总显存占用约140-160GB,可跨卡部署。
●微调:支持对Qwen3-VL系列进行LoRA/QLoRA微调,单卡64GB显存容纳32B模型全参数及优化器状态。
核心硬件概要
赋创FG4824-H4平台,4U机架式,搭载8张天垓150 64G训推一体卡,海光7490双路处理器,1TB内存。
四档方案核心指标速览
注:表中精度后缀仅标注该方案的典型使用方式,详细说明见各方案内文。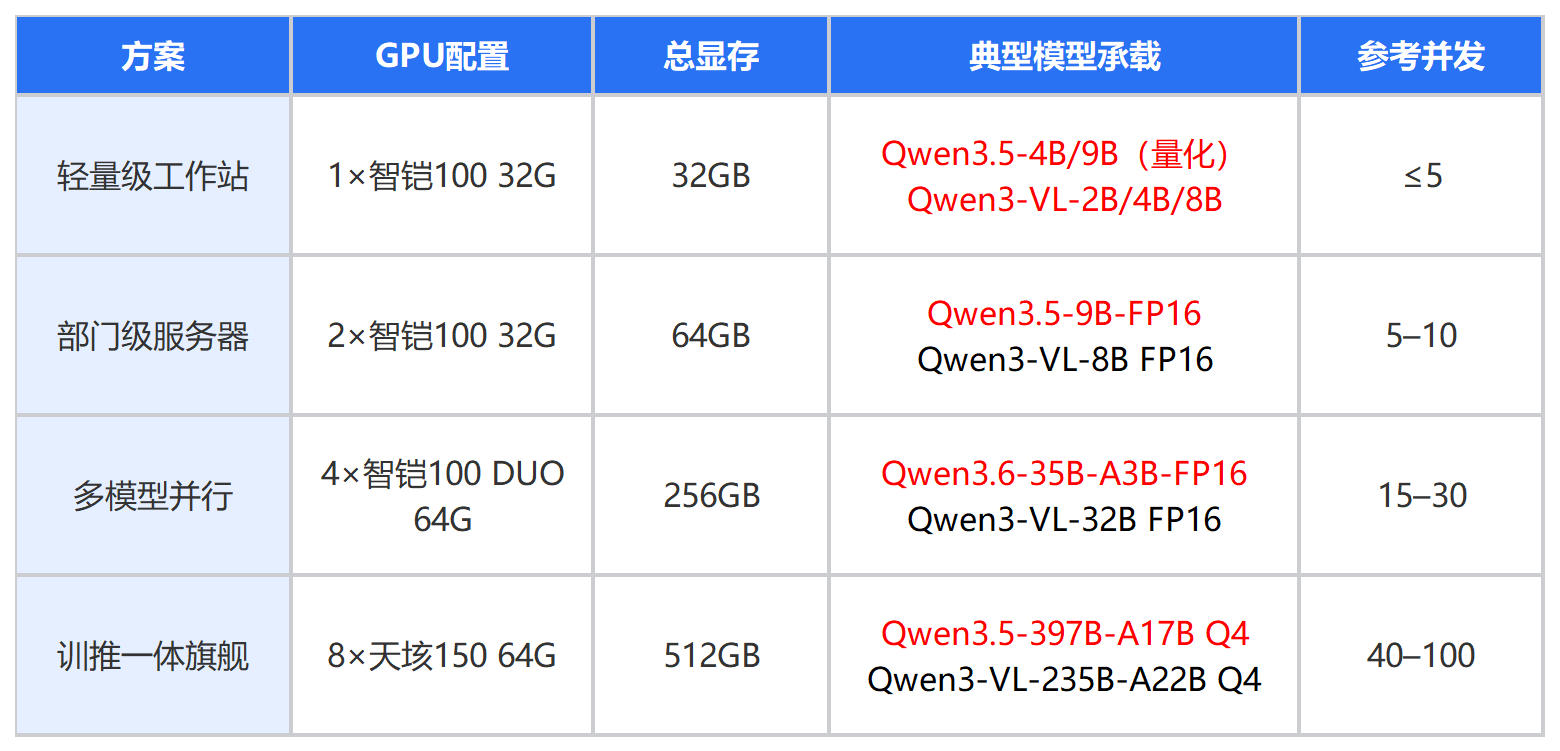
数据基于赋创实验室2026年5月实测,测试输入约512 tokens,输出约256 tokens,取稳态吞吐。实际性能会因模型版本、推理框架及并发策略而变化。
企业应该如何选择适合自己的方案
选型时,建议遵循“先确定业务目标,再选择模型规模;先评估并发需求,再反推GPU资源”的路径。
如果只是AI能力验证,方案一已足够;若希望部门长期稳定使用,可从方案二起步;计划建设统一AI平台则更适合方案三;涉及模型微调、235B部署及大规模在线服务时,建议直接规划训推一体架构。
真正影响使用体验的,通常是并发稳定性、推理延迟、显存利用率、多模型调度以及后续扩容能力。因此,同样是“支持Qwen3.5/3.6”,不同方案之间的实际体验存在明显差异。
FAQ:企业部署国产大模型时最常见问题
Q1:这些方案只能运行文中列出的几个模型吗?
不是。文中列出的Qwen3.5/3.6、Gemma 4主要作为参考测试模型。只要模型的显存需求与推理精度在GPU承载范围内,均可进行部署。实际适配效果会因模型结构、量化方式以及推理框架不同而存在差异,建议结合具体业务场景进行验证。
Q2:国产GPU目前能否稳定支持主流大模型推理?
目前主流国产GPU已能够支持Qwen3.5/3.6、Gemma 4等模型的推理部署,并逐步适配vLLM、llama.cpp等主流推理框架。赋创交付时会预装经过稳定性验证的驱动与推理环境,降低企业内部调试成本。
Q3:如果后续业务增长,当前方案还能扩容吗?
可以。方案一、方案二所在的FG2212-H4平台支持后续增加GPU、扩展内存与存储;更高并发场景则可通过增加节点实现横向扩展。企业在初期规划时,建议预留一定显存与并发余量。
Q4:企业应该优先关注模型参数,还是并发能力?
实际项目中,并发能力往往比单纯的模型参数更重要。同样是部署Qwen3.5/3.6,不同并发规模下,对显存、带宽与推理调度的要求会明显不同。因此更建议先根据真实业务访问量,再反推模型规模与硬件配置。
Q5:赋创能提供哪些部署支持?
赋创可提供从硬件交付、驱动与推理框架部署,到模型适配、性能测试的完整支持,并可根据具体业务场景提供参考配置与测试环境,帮助企业缩短AI上线周期。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)