省钱又提效!大模型Token优化与减少使用技巧全指南
省钱又提效!大模型Token优化与减少使用技巧全指南
系统整理 Token 优化的技巧、策略与工程实践,帮助你在保证输出质量的前提下,最大化降低 Token 消耗与成本。
一、为什么 Token 优化如此重要?
在大规模 AI 应用中,60-80% 的 LLM 调用成本来自重复的系统提示词。每次调用 API 时,相同的上下文被反复处理、相同的 Token 被反复计费。随着 Agentic AI(智能体)的普及,单次任务可能涉及多轮工具调用,Token 消耗呈指数级增长。
Token 优化的核心目标不是"省钱"这么简单,而是实现 成本、质量与性能的三方平衡。
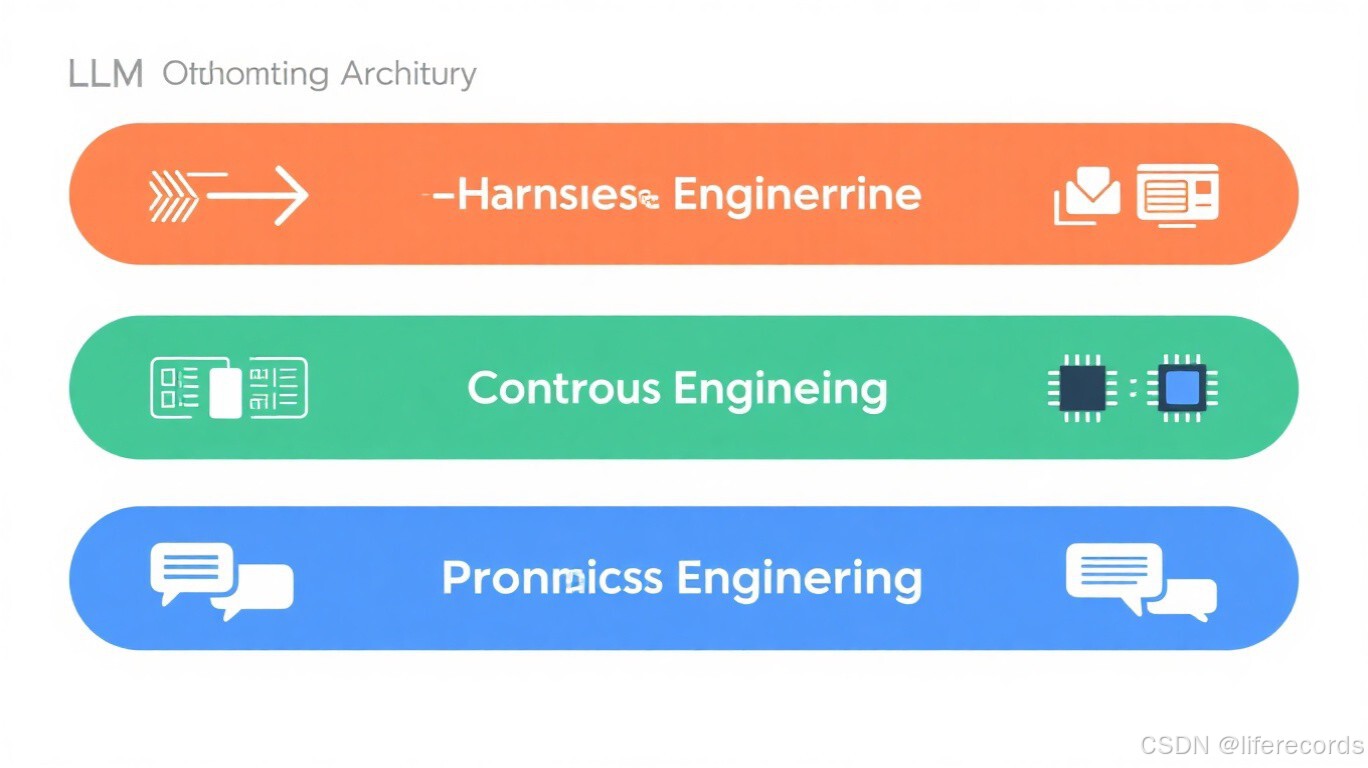
图:Token 优化的三层架构——从 Prompt 到 Context 再到 Harness
二、Prompt 层面优化(Prompt Engineering)
2.1 精简系统提示词
原理:系统提示词(System Prompt)在每次请求中都会被发送,是最大的"固定开销"。
技巧:
- 去除冗余描述:用简洁的指令替代啰嗦的解释。例如
"回答简洁,不超过3句话"比"请你用尽可能简短的语言来回答我的问题,每句话都要精炼,总体不要超过三句话"节省约 60% 的 Token - 使用结构化格式:用编号列表、缩写代替长段落描述
- 避免重复约束:不要在系统提示和用户消息中重复相同的规则
- 定期审计:使用
tiktoken等工具测量系统提示的 Token 数,定期精简
# 示例:精简前后对比
# 精简前 (~150 tokens)
system_prompt = """
你是一个非常专业的代码审查助手。你需要仔细阅读用户提供的代码,
从代码质量、安全性、性能等多个维度进行全面的审查。
对于每个发现的问题,你需要给出具体的改进建议。
请用中文回答,并且保持专业和友好的语气。
"""
# 精简后 (~40 tokens)
system_prompt = """
你是代码审查助手。审查维度:质量/安全/性能。
输出格式:问题 + 改进建议。中文回答。
"""
2.2 使用 Few-Shot 示例替代长指令
原理:与其用 200 个 Token 描述期望的输出格式,不如用 1-2 个精炼的示例。
技巧:
- 示例要短小精悍,覆盖核心格式要求
- 优先使用输出格式示例,而非输入处理示例
- 示例中的 Token 数应远少于被替代的指令 Token 数
2.3 控制输出长度
原理:输出的每一个 Token 都要付费,控制输出长度是直接的省钱手段。
技巧:
- 在提示词中明确限制输出长度:
"不超过200字"/"列出3个要点" - 设置 API 的
max_tokens参数,防止模型过度生成 - 使用 JSON mode / Structured Output 强制结构化输出,避免冗余文本
- 对于分类/提取任务,要求输出标签而非完整句子
2.4 选择高效的语言表达
原理:不同语言的 Token 效率差异巨大。
技巧:
- 英文通常比中文更省 Token:大多数模型的分词器对英文优化更好,同样的语义内容,英文通常只需中文 50-70% 的 Token
- 如果业务允许,考虑使用英文作为系统提示语言
- 避免使用特殊符号、Emoji(每个 Emoji 可能消耗 1-3 个 Token)
- 使用常见词汇而非生僻词(分词器对高频词有更好的压缩)
三、上下文管理优化(Context Engineering)
3.1 上下文压缩
原理:不传输完整的对话历史,只提炼关键信息。
技巧:
- 滑动窗口:只保留最近 N 轮对话,丢弃更早的内容
- 摘要压缩:用 LLM 将早期对话压缩为摘要,只保留摘要 + 最近几轮完整对话
- 关键信息提取:从对话中提取用户偏好、核心需求、关键结论,以结构化形式传递
# 传统方式:每次发送完整历史 (~5000 tokens)
messages = [msg1, msg2, msg3, msg4, msg5, msg6, msg7, msg8, ...]
# 压缩后:摘要 + 最近2轮 (~800 tokens)
messages = [
{"role": "system", "content": "对话摘要:用户需要一款7000元以内的编程笔记本,偏好轻薄长续航..."},
{"role": "user", "content": "最近两轮对话..."},
{"role": "assistant", "content": "..."}
]
效果:MemoryLake 等技术通过智能记忆压缩,在生产场景中 Token 成本降低高达 91%。

图:上下文压缩效果对比——从 5000 tokens 到 800 tokens
3.2 懒加载上下文(Lazy Loading)
原理:只加载当前任务需要的工具定义和上下文,无关内容一律不加载。
技巧:
- 工具按需加载:用户问笔记本推荐时,只加载产品搜索、价格对比工具,不加载天气、日历等无关工具
- 文档按需检索:使用 RAG 检索最相关的文档片段,而非将整个知识库塞入上下文
- 分层上下文:将上下文分为"必要"和"可选",优先发送必要部分
# 传统方式:加载所有工具定义 (~3000 tokens)
tools = [search_tool, price_tool, review_tool, weather_tool, calendar_tool, ...]
# 懒加载:只加载相关工具 (~500 tokens)
tools = select_relevant_tools(user_query="推荐笔记本", all_tools=tools)
# → [search_tool, price_tool, review_tool]
3.3 RAG 检索优化
原理:RAG(检索增强生成)是减少上下文 Token 的利器,但检索质量直接影响效果。
技巧:
- 控制检索片段数量:通常 3-5 个高质量片段优于 20 个低质量片段
- 设置片段长度上限:每个检索片段控制在 200-500 Token
- 重排序(Reranking):先用向量检索召回候选,再用精排模型筛选最相关的 Top-K
- 元数据过滤:利用文档元数据(时间、类别、来源)预过滤,减少无效检索
3.4 智能记忆系统
原理:用外部存储替代上下文中的历史信息,按需召回。
技巧:
- 短期记忆:当前会话的关键信息,存储在内存中
- 长期记忆:用户偏好、历史结论,存储在向量数据库中
- 共享记忆:多 Agent 实例共用记忆池(如联想"龙虾湖"方案),避免重复调用
四、模型路由与选择优化
4.1 模型路由(Model Routing)
原理:不同任务复杂度需要不同能力的模型,用高端模型处理简单任务是极大的浪费。
技巧:
- 简单任务(信息查询、格式转换、简单分类)→ 小模型(GPT-4o-mini / Claude Haiku)
- 中等任务(摘要、翻译、对比分析)→ 中等模型(GPT-4o / Claude Sonnet)
- 复杂任务(多步推理、代码生成、创意写作)→ 大模型(GPT-4.1 / Claude Opus / o3)
| 任务类型 | 示例 | 推荐模型 | Token 成本比 |
|---|---|---|---|
| 简单分类 | 垃圾邮件检测 | Mini/Haiku | 1x |
| 信息提取 | 从文本中提取关键信息 | Medium/Sonnet | 3-5x |
| 复杂推理 | 多步数学推理 | Large/Opus | 15-30x |
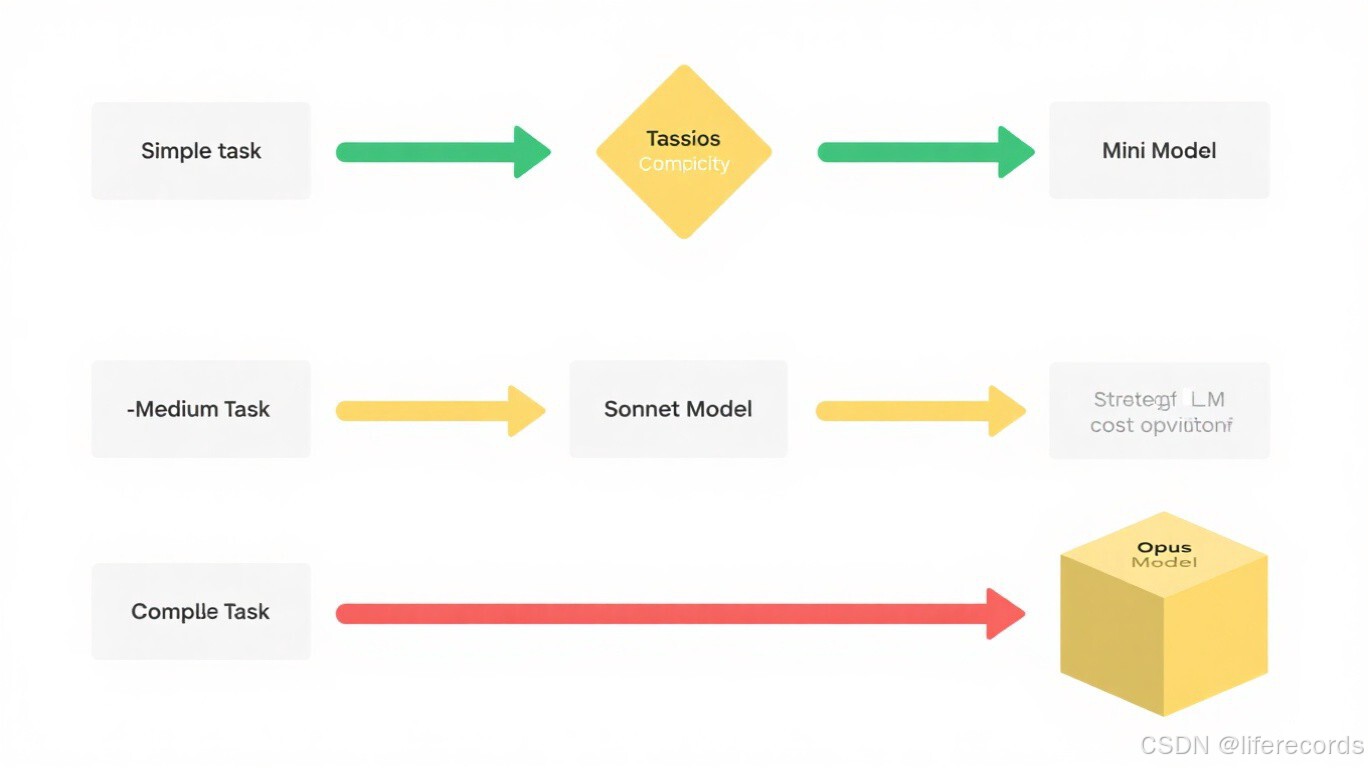
图:模型路由策略——根据任务复杂度选择合适模型
4.2 级联策略(Cascade)
原理:先用廉价模型尝试,信心不足时再升级到更强模型。
技巧:
- 第一轮:小模型处理,评估输出质量/置信度
- 第二轮:如果质量不达标,自动升级到中等模型
- 第三轮:如果仍不达标,使用大模型兜底
- 可结合
logprobs或独立评分模型判断输出质量
def cascade_call(query, complexity="auto"):
if complexity == "simple" or (complexity == "auto" and is_simple(query)):
result = call_model(query, model="mini")
if quality_check(result): # 质量达标则返回
return result
# 降级到更强模型
result = call_model(query, model="sonnet")
if quality_check(result):
return result
# 最终兜底
return call_model(query, model="opus")
4.3 模型微调替代长提示
原理:将系统提示中的规则、格式要求通过微调"烧录"到模型中,减少每次请求的输入 Token。
技巧:
- 适用于固定格式的任务(JSON 输出、特定领域问答)
- 微调后系统提示可从 2000 Token 缩减到 200 Token
- 权衡:微调有训练成本,适合高频调用的场景
五、缓存策略(Caching)
5.1 Prompt Caching(提示词缓存)
原理:缓存 Transformer 注意力机制中的 KV 矩阵,避免重复计算。相同前缀的请求可以复用已计算的 KV Cache。
效果:
- Anthropic Claude:缓存命中的 Token 价格是普通价格的 10%(降低 90%)
- OpenAI GPT-4o:缓存命中 Token 按 50% 价格计费
- 首字节延迟减少高达 85%
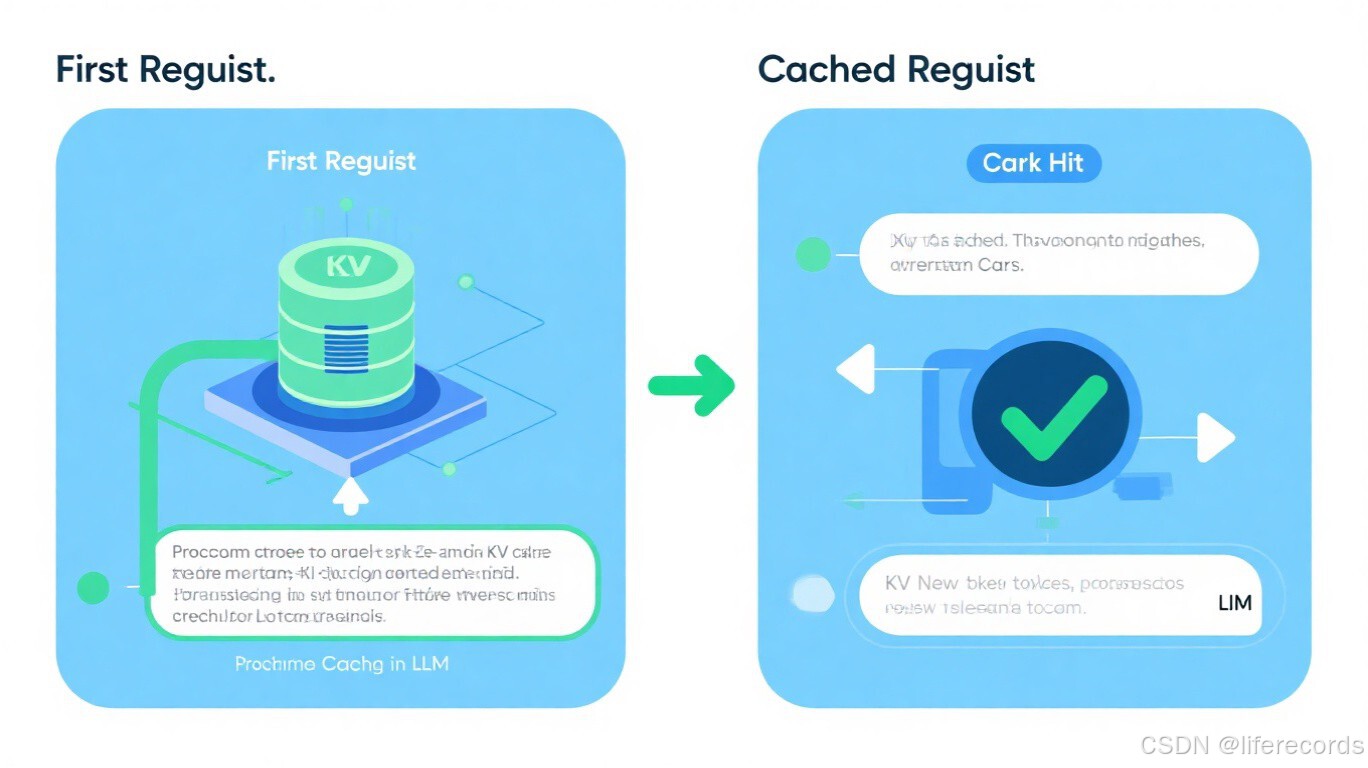
图:Prompt Caching 原理——首次请求生成 KV Cache,后续请求复用缓存
Anthropic 实践:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system=[
{
"type": "text",
"text": LARGE_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # 标记为可缓存
}
],
messages=[{"role": "user", "content": user_message}]
)
# 查看缓存使用情况
usage = response.usage
print(f"缓存读取: {usage.cache_read_input_tokens} tokens")
print(f"缓存创建: {usage.cache_creation_input_tokens} tokens")
OpenAI 实践:
# OpenAI 自动缓存,无需特殊标记
# 条件:前缀完全一致 + 至少 1024 tokens
# 有效期:约 5-10 分钟空闲后过期
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT}, # 保持不变
{"role": "user", "content": user_message} # 动态部分
]
)
关键规则:
- 前缀必须完全一致:任何修改都会导致缓存失效
- 动态内容放后面:将静态系统提示放前面,动态用户消息放后面
- 分层缓存:静态内容 → 会话级内容 → 动态内容,确保最大前缀复用
- Anthropic 缓存有效期 5 分钟,注意批处理任务的节奏
5.2 语义缓存(Semantic Cache)
原理:识别语义相似的问题,直接复用之前的回答,完全跳过 LLM 调用。
技巧:
- 使用向量数据库存储历史 Q&A 对
- 新问题先做向量检索,相似度超过阈值则直接返回缓存答案
- 适合高频重复问题的场景(客服 FAQ、产品推荐)
def semantic_cached_call(query, threshold=0.92):
# 1. 向量化查询
query_embedding = embed(query)
# 2. 在缓存中搜索相似问题
cached = vector_db.search(query_embedding, top_k=1)
# 3. 相似度达标则直接返回
if cached and cached.similarity > threshold:
return cached.answer # 0 Token 消耗!
# 4. 未命中,调用 LLM 并缓存结果
answer = call_llm(query)
vector_db.insert(query_embedding, answer)
return answer
注意:语义缓存的相似度阈值需要根据场景调试——太高无法复用,太低会返回不准确答案。
5.3 缓存友好的提示词设计
策略:
- 将动态内容(日期、用户 ID、计数器)移到消息末尾,而非嵌入系统提示中
- 对 JSON 字段排序(
sort_keys=True),确保相同数据生成相同字符串 - 监控缓存命中率,持续优化提示词结构
六、工程架构优化
6.1 输出格式控制
技巧:
- JSON Mode / Structured Output:强制结构化输出,避免冗余的自然语言包装
- Tool Calling / Function Calling:用工具调用的方式获取结构化数据,而非让模型生成自由文本
- 限制输出 Token:始终设置合理的
max_tokens上限
# 使用 Structured Output 替代自由文本
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[{"role": "user", "content": "分析这段文本的情感"}],
response_format=SentimentAnalysis, # Pydantic 模型
)
# 输出:{"sentiment": "positive", "confidence": 0.92, "keywords": ["好", "优秀"]}
# 而非:"经过仔细分析,我认为这段文本的情感倾向是积极的..."
6.2 并发与批处理优化
技巧:
- 并行调用:独立的 LLM 调用并发执行,减少总等待时间
- 批量处理:将多个小任务合并为一次大调用(注意上下文窗口限制)
- 流式输出:使用 streaming 模式,减少用户感知延迟
6.3 中间件与代理层
技巧:
- Token 计数中间件:在调用 LLM 之前,先计算预估 Token 数,超过阈值则触发压缩
- 请求拦截器:自动检测并移除重复的上下文内容
- 成本监控面板:实时追踪每次调用的 Token 消耗和成本
class TokenAwareMiddleware:
def before_call(self, messages, max_budget=100000):
total_tokens = count_tokens(messages)
if total_tokens > max_budget:
messages = compress_context(messages, target=max_budget)
logger.warning(f"上下文压缩: {total_tokens} → {count_tokens(messages)} tokens")
return messages
6.4 本地部署替代方案
原理:对于高频、敏感或大规模场景,本地部署可消除按 Token 计费的成本。
技巧:
- 开源模型:使用 Llama、Qwen、DeepSeek 等开源模型本地部署
- 量化压缩:使用 4-bit/8-bit 量化降低显存需求(GGUF、AWQ、GPTQ)
- 轻量推理框架:Ollama、vLLM、llama.cpp 等支持在消费级硬件运行
- 混合部署:简单任务用本地模型,复杂任务用云端大模型
| 方案 | 适用场景 | 成本特点 |
|---|---|---|
| 纯云端 API | 低频、多变任务 | 按量付费,灵活但单价高 |
| 本地部署 | 高频、固定任务 | 一次性投入,长期边际成本趋近于零 |
| 混合部署 | 多样化任务 | 兼顾灵活性和成本控制 |
七、Agent 场景专项优化
7.1 工具调用优化
- 精简工具描述:工具的 name 和 description 也会消耗 Token,保持简洁
- 工具结果截断:工具返回的冗长结果应截断或摘要后再传给模型
- 避免无效调用:在调用工具前,先用规则引擎或小模型判断是否真的需要调用
7.2 多 Agent 协作优化
- Agent 间传递摘要而非全文:Agent A 的输出经摘要后传给 Agent B
- 共享记忆层:多个 Agent 实例共用外部记忆,避免重复加载上下文
- 任务分解粒度控制:过细的子任务会导致过多的 Agent 间通信开销
7.3 推理链(Chain of Thought)优化
- 只在必要时使用 CoT:简单任务不需要推理链,直接输出答案
- 使用轻量级 CoT:
"想一下"比"请一步一步详细思考每个步骤"省很多 Token - 模型内置推理:使用 o1/o3 等内置推理模型,无需在提示词中写推理指令
八、成本监控与持续优化
8.1 建立监控体系
@dataclass
class TokenMetrics:
total_input_tokens: int = 0
total_output_tokens: int = 0
cached_tokens: int = 0
total_cost_usd: float = 0.0
request_count: int = 0
@property
def cache_hit_rate(self):
return self.cached_tokens / max(self.total_input_tokens, 1)
@property
def avg_cost_per_request(self):
return self.total_cost_usd / max(self.request_count, 1)
8.2 持续优化清单
- 每月审计系统提示词,精简冗余内容
- 监控缓存命中率,低于 50% 时排查原因
- 分析高成本调用,识别可路由到小模型的请求
- 检查上下文窗口利用率,是否存在大量浪费
- 评估语义缓存的覆盖率和准确率
- 对比不同模型在相同任务上的 Token 消耗差异
九、优化效果速查表
| 优化手段 | 预期节省 | 实施难度 | 适用场景 |
|---|---|---|---|
| Prompt 精简 | 20-40% | ⭐ 低 | 所有场景 |
| 上下文压缩 | 40-90% | ⭐⭐ 中 | 长对话、多轮 Agent |
| Prompt Caching | 50-90% | ⭐ 低 | 大系统提示、高频调用 |
| 语义缓存 | 30-80% | ⭐⭐⭐ 高 | 高重复问题场景 |
| 模型路由 | 40-70% | ⭐⭐ 中 | 多样化任务 |
| 级联策略 | 30-60% | ⭐⭐⭐ 高 | 任务复杂度差异大 |
| 懒加载 | 30-50% | ⭐⭐ 中 | 多工具 Agent |
| 本地部署 | 80-100% | ⭐⭐⭐⭐ 很高 | 高频固定任务 |
| 结构化输出 | 20-40% | ⭐ 低 | 提取/分类任务 |
| RAG 检索优化 | 30-60% | ⭐⭐ 中 | 知识库问答 |
十、总结:三层优化体系
┌─────────────────────────────────────────────────┐
│ Harness Engineering(运行结构) │
│ 模型路由 · 级联策略 · 缓存中间件 · 成本监控 │
├─────────────────────────────────────────────────┤
│ Context Engineering(信息组织) │
│ 上下文压缩 · 懒加载 · RAG优化 · 智能记忆 │
├─────────────────────────────────────────────────┤
│ Prompt Engineering(任务表达) │
│ 提示精简 · Few-Shot · 输出控制 · 语言选择 │
└─────────────────────────────────────────────────┘
Token 优化不是单一手段,而是 Prompt → Context → Harness 三层协同 的系统工程。从输入控制到上下文组织,再到运行时治理,每一层都有对应的优化空间。关键是根据自身业务场景,选择投入产出比最高的优化组合,并在成本与质量之间找到最佳平衡点。
参考来源

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)