python自动化---pytest测试框架
目录
1.介绍
pytest 是一个功能强大且易于使用的 Python 测试框架,用于编写单元测试、集成测试
和功能测试。
它提供了丰富的功能和灵活的用法,使得编写和运行测试变得简单而高效。
pytest的优点:
1. 简单易用:pytest的语法非常简洁,我们不需要通过大量的配置和其他方式就能直接启动pytest完成测试 。
2. 自动发现与自动测试 : pytest 能够自动发现项目中的测试文件和测试函数,无需手动编写繁琐的配置。
3. 丰富断言: pytest 内置了丰富的断言库,可以轻松地进行测试结果的判断。4. 支持参数化测试: pytest 支持参数化测试,能够快速地对多组输入进行测试。
5. 插件与第三方库丰富: pytest 有着丰富的插件生态系统,可以通过插件扩展各种功能,比如覆盖率测试、测试报告生成等。
2.安装方式
在cmd/终端,输入:
pip install pytest
pip install pytest == 7.3.1
验证是否安装成功:
pytest --version
一旦在终端 有确认的版本号,就证明安装成功。
如果安装慢 / 报错,用国内镜像(推荐)
pip install pytest -i https://pypi.tuna.tsinghua.edu.cn/simple
PyCharm(图形界面安装)
- 打开 PyCharm
- 进入 File → Settings → Project: 你的项目 → Python Interpreter
- 点 + 号
- 搜索 pytest
- 点击 Install Package
3.常见第三方插件
1. pytest-sugar :这个插件为Pytest的测试用例添加了进度条,让测试过程更加可视
化。
2. pytest-rerunfailures :这个插件通过重跑机制来消除不稳定失败的测试用例。如果
某个测试用例失败了,它会尝试重新运行该用例,直到该用例稳定通过或者达到最大
重试次数。
3. pytest-xdist :这是一个分布式执行插件,能够实现多个CPU或者主机执行,动态决
定测试用例的执行顺序。使用这个插件可以加快测试的执行速度,因为它能够同时运
行多个测试用例。
4. pytest-assume :这个插件支持在测试用例中添加假设断言,类似于其他语言的 ass
ume 函数。如果假设断言失败了,测试用例会立即跳过而不报告失败。
5. pytest-html :这个插件可以生成HTML格式的测试报告。它支持多种HTML测试报告
生成方式,并可以与 pytest-xdist 等插件结合使用。
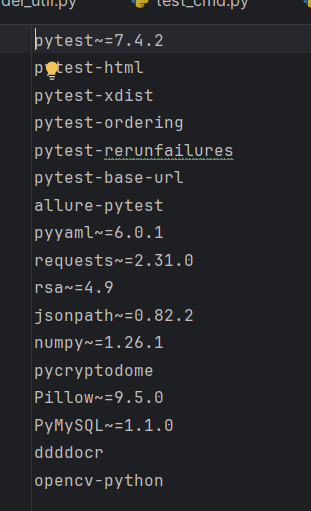
pytest~=7.4.2 : 7.4.x 系列 。自动化测试核心框架,用来写、组织、运行测试用例 。
- allure-pytest:生成美观、可展示的企业级测试报告, 带步骤、截图、日志,可用于项目复盘 。
- pytest-rerunfailures: 用例失败自动重跑,解决接口不稳定、偶现失败问题 ,提高稳定性
- pytest-xdist:多进程并行执行,大幅提升用例执行速度
- pytest-html:简单 HTML 报告
- pytest-assume:多重断言,不中断
- pytest-ordering:控制用例执行顺序
pytest-base-url : 给 pytest 提供统一的 base_url 配置,避免硬编码接口地址
requests~=2.31.0 : 发送 HTTP/HTTPS 请求的核心库,接口自动化必用
pyyaml~=6.0.1 : 读取 / 写入 YAML 配置文件,用来管理接口用例、配置、环境变量 。
jsonpath~=0.82.2 : 解析 JSON 响应,方便提取接口返回的字段(比如 token、订单号)
~=x.y.z 表示:兼容更新到次版本,不跨大版本
4.pytest语法规则
Pytest默认规则:
测试文件:文件名必须test_*.py或者*_test.py
测试类:类名必须是TestXxx。可以使⽤驼峰命名法(CamelCase) 。
测试用例函数:函数名(测试用例)必须是test_*
测试脚本都放在scripts目录中,scripts目录位于项目根目录下。
接口自动化框架封装的第一步统一请求方式。
5.pytest常用运行方式
找到对应的文件夹,命令运行
1. 运行当前目录下所有测试用例 : pytest
2. 详细输出(推荐用) :pytest -v
3. 只运行失败的用例 :pytest --lf
指定运行: 文件 / 函数 / 类
运行指定文件 :pytest test_login.py -v
运行文件里指定的 1 个函数 :pytest test_login.py::test_user_login -v
运行文件里指定的类 + 方法 :pytest test_order.py::TestOrder::test_create_order -v
按 标签 / 标记 运行(超级常用)
1. 运行标记为 smoke 的冒烟用例 :pytest -m=smoke -v
2. 运行非 smoke 用例 :pytest -m "not smoke" -v
3. 多标签组合 :pytest -m "smoke or order" -v
结合插件运行(企业必用)
1. 生成 Allure 报告 :pytest --alluredir=./report
2. 失败自动重跑 2 次 :pytest --reruns=2
3. 多进程并行运行(加速) :pytest -n=4
4. 生成 HTML 报告 :pytest --html=report.html
组合命令(企业真实使用)
pytest -m=smoke -v --reruns=2 --alluredir=./report
含义:
- 运行冒烟用例
- 详细打印
- 失败重跑 2 次
- 生成 allure 报告
通过 pytest.ini 运行(最规范)
项目根目录创建 pytest.ini
[pytest]
#生成allure报告
; 命令行自动带上的参数(等价于写在 main 里)
addopts = -vs --alluredir=temps --clean-alluredir
#存放测试用例的路径
testpaths = ./testcases
#定义测试文件要以test_开头
;python_files = test_*.py
python_files=test_login_ddt.py
;test_crud_disease.py
;test_crud_facility.py
#所有的测试类以Test开头
python_classes = Test*
#所有的方法以test_开头
python_functions = test_*
markers =
smoke : 冒烟用例
order : 工单管理直接运行:pytest 自动按配置找用例、执行、输出。
或者:在main.py里写:
import pytest
if __name__ == '__main__':
pytest.main()
#pytest.main(["-v", "-m=smoke", "--alluredir=./report"])只要你配置好了 pytest.ini,main() 里可以空括号,运行时会自动读取 ini 里的所有配置。
效果= pytest -v --alluredir=./report --reruns=2 -m=smoke
什么时候 main () 里需要写参数?
只有一种情况:想临时覆盖 ini 配置,做特殊运行。
pytest.main(["-m=order"]) # 只跑工单用例,覆盖 ini
pytest允许用命令运行,pytest是个命令工具,用自己的规则去执
行和运行代码即可。
注意:
Pytest是以方法(def 方法名)为单位发现用例的,写不写测试类根本不重要 。
在哪个目录下执行pytest就在哪个目录下按照上述规则去查找 。
以上是默认的规则,可以自定义,可以结合:pytest.ini 文件去进行配置。
命令行的运行方式中:
pytest <==> pytest.main([])
pytest -s <==> pytest.main(["-s"])
pytest -s -v <==> pytest.main(["-s","-v"])
pytest -sv <==> pytest.main(["-sv"])
pytest -vs <==> pytest.main(["-vs"])
pytest test_01.py::Test01::test001 -sv <==> pytest.main(["test_01.py::Test01::test001", "-vs"])
指定文件夹运行
# pytest.main(["testcase", "-vs"])
# pytest.main(["testcase/testcase01", "-vs"])
# pytest.main(["testcase/testcase01/test_04.py::test0402", "-vs"])
用例是函数,pytest解决的是:不用写调用语句,也可以执行函数内容。
-k筛选⽤例运行
在Pytest中, -k 选项⽤于通过表达式筛选和运⾏匹配的测试⽤例。使⽤ -k 选项,可
以指定⼀个字符串表达式,Pytest将根据表达式匹配测试⽤例的名称来执⾏相应的测
试。
#expression 是要匹配的测试⽤例名称的表达式。
pytest -k "expression"
运行名称包含“disease”的测试用例
pytest -k "disease" -vs<==>pytest.main(["-k","disease","vs"])用例执行顺序
根据ASCII 码从小到大 依次执行用例。
ASCII 码大小固定规则:数字(0-9) < 大写字母(A-Z) < 小写字母(a-z)
eg: test_01_login.py → test_02_order.py → test_a_user.py → test_B_pay.py
文件内根据定义的方法的先后顺序,从上到下执行。
pytest运行时,找测试文件的顺序:
同级情况下,先找文件,再往下层找。
testcase
test_a
test_a01.py
test_001.py
test_002.py
顺序运行是:test_001.py test_002.py test_a:test_a01.py6.pytest命令行选项分类
Pytest 是一个流行的 Python 测试框架,它提供了许多命令行选项,可以帮助用户更
好地控制测试执行过程。在使用 pytest 进行测试时,熟悉 pytest 的命令行选项非常重要,这
将有助于减少错误和提高测试效率。
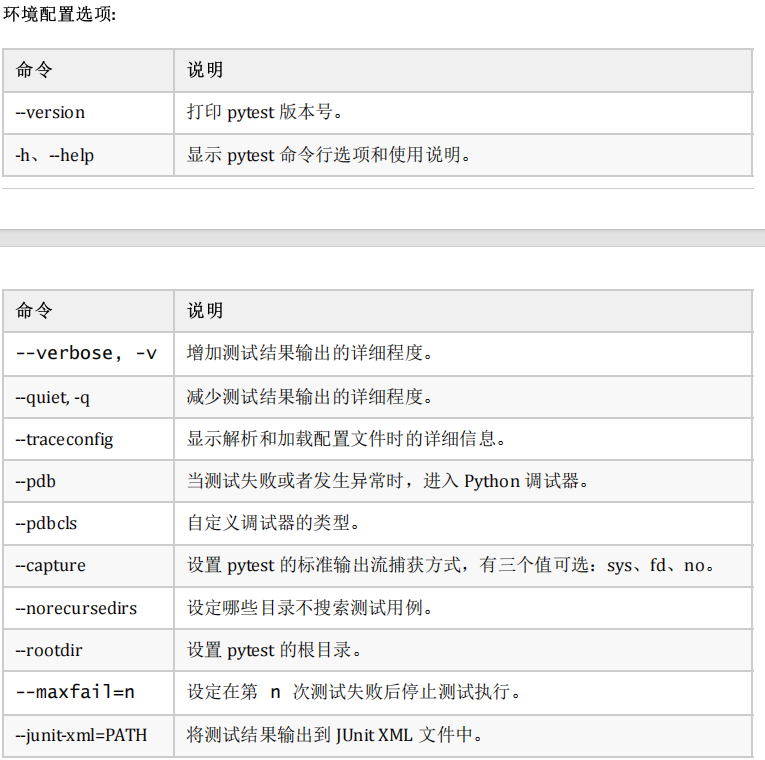
环境配置选项:这些选项用于设置 pytest 的环境配置,例如设置日志级别、覆盖配置文 件、设置测试模式等。
测试过滤选项:这些选项用于过滤和选择测试用例,例如指定测试目录、选择特定测试模 块、运行指定测试函数等。

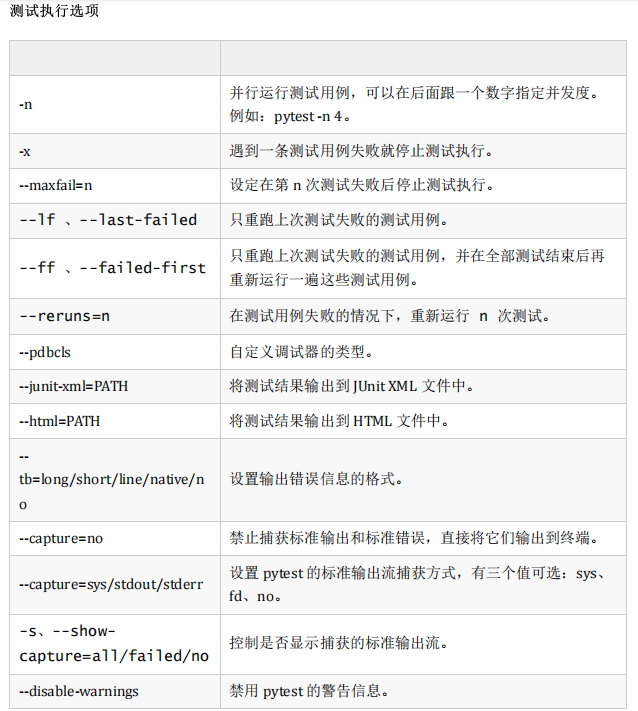
测试执行选项:这些选项用于控制 pytest 的测试执行过程,例如重试失败测试、生成测试 报告、并行执行测试等。
7.pytest的前后置处理
在Pytest中,前置处理(setup)和后置处理(teardown)是非常重要的概念,它们用于在每
个测试用例执行前后进行一些准备工作和清理工作。Pytest提供了多种方式来处理前置和后置
操作,使得测试代码更加灵活和可维护。
前置处理(Setup)
前置处理是在测试用例执行之前执行的一些操作,通常用于准备测试环境,例如创建数据库连
接、初始化测试数据、打开文件等。在Pytest中,有几种方式可以实现前置处理:
1. setup_module或 setup :在一个模块(.py文件)中的所有测试用例执行之前只执行一次。
2. setup_function :在每个测试用例执行之前都会执行。
3. setup_class :在一个类中的所有测试用例执行之前只执行一次(需要配合 @pytest.mar
k.usefixtures 使用或使用类方法)。
4. setup_method :在一个类中的每个测试用例执行之前都会执行(需要配合类方法使用)。
后置处理(Teardown)
后置处理是在测试用例执行之后执行的一些操作,通常用于清理测试环境,例如关闭数据库连
接、删除测试数据、关闭文件等。在Pytest中,后置处理的方式与前置处理类似:
1. teardown_module 或 teardown:在一个模块(.py文件)中的所有测试用例执行之后只执行一次。
2. teardown_function :在每个测试用例(函数)执行之后都会执行。
3. teardown_class :在一个类中的所有测试用例执行之后只执行一次(需要配合类方法使
用)。
4. teardown_method :在一个类中的每个测试用例(类中的函数)执行之后都会执行(需要配合类方法使
用)。
def setup():#setup_module()
# 前置操作
print("执⾏前置操作")
def teardown():#teardown_module()
# 后置操作
print("执⾏后置操作")
def setup_function():
# 执行函数级别的前置操作
print("执⾏前置操作")
def teardown_function():
# 执行函数级别的后置操作
print("执⾏后置操作")
def test_example1():
# 测试⽤例
print("执⾏测试⽤例test_example1")
def test_example2():
print("执⾏测试⽤例example2")
执行结果:

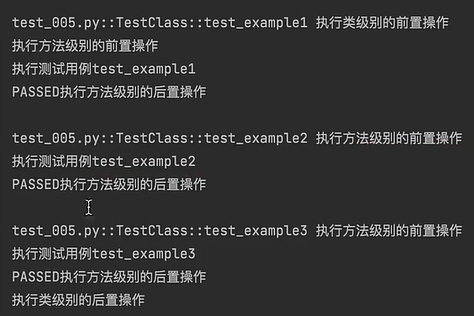
class TestClass:
@classmethod
def setup_class(cls):
# 类级别的前置操作
print("执行类级别的前置操作")
@classmethod
def teardown_class(cls):
# 类级别的后置操作
print("执行类级别的后置操作")
def setup_method(self, method):
# 方法级别的前置操作
print("执行方法级别的前置操作")
def teardown_method(self, method):
# 方法级别的后置操作
print("执行方法级别的后置操作")
def test0021(self):
print("执行测试用例test0021")
def test0022(self):
print("执行测试用例test0022")执行结果:
8.conftest的使用
例子
import pytest
from common.clean_util import clean_photos
from common.yaml_util import clean_yaml
#clean_extract在所有测试用例运行前,执行一次
@pytest.fixture(scope="session", autouse=True)
def clean_extract():
clean_yaml()
clean_photos()conftest.py介绍
conftest.py配置需要注意:
conftest文件名是不能自定义的,不能更改 ;
conftest.py与运行的用例要在同一个package下,并且有init.py文件
可以放在项目的根目录下,也可以放在每个测试用例的文件夹下;
不同于普通被调用的模块,conftest.py使用时不需要导入,Pytest会首先查找这个文件;
全局的配置和前期工作都可以写在这里,放在某个包下,就是这个包数据共享的地方,
专门存放:公共 fixture、全局前置 / 后置、接口鉴权、公共配置、钩子函数
就近生效原则
- 子目录里的
conftest.py会覆盖父目录的同名 fixture - 用例优先使用最近的 conftest
为什么要用?(接口自动化核心价值)
- 抽离重复代码(登录、获取 token、读取配置、连接数据库)
- 实现全局前置 / 后置(启动服务、清数据、关连接)
- 统一管理接口鉴权(token、session)
- 让测试用例只写业务逻辑,干净简洁
yield关键字作用
测试方法前要执行的或依赖的解决了,测试方法后销毁清除数据的要如何
进行呢?用yield
每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 yield 方法时从当前位置继续运行。
import pytest
# 作用域: module 表示在整个模块(即当前的test_main.py)执行前后,各执行一次
@pytest.fixture(scope="module")
def open():
print("打开浏览器")
yield # 关键!这里是“分割线”
print("执行teardown")
print("关闭浏览器")import pytest
def test_search1(open):
print("test_search1")
raise NameError # 这里会主动抛出一个错误,让用例失败
pass
def test_search2(open):
print("test_search2")
pass
def test_search3(open):
print("test_search3")
pass
if __name__ == '__main__':
pytest.main(["-s"]) # -s 是为了让print语句正常输出执行结果:
print("打开浏览器")→ 模块开始时执行 1 次test_search1执行(不管成功失败)test_search2执行test_search3执行print("执行teardown") print("关闭浏览器")→ 模块结束时执行 1 次
pytest 的 fixture,默认只执行一次!
- 有
yield:分成 前置 + 后置 两段执行 - 没有
yield:只有前置,没有后置,执行完就结束了。
为什么没有 yield 就不会再执行?
因为:
- yield = 让 fixture 变成 “生成器”,pytest 才能记住 “后面还有代码要执行”
- 没有 yield = fixture 是普通函数,执行完最后一行就彻底结束,再也不会回来
@pytest.fixture()
import pytest
# @pytest.fixture 提供了全局前置、局部前置等功能,以便在测试运行前后设置所需的环境和资源.
@pytest.fixture(scope="session", autouse=True)
参数
autouse:
是否自动应用该Fixture,无需在测试用例中显式调用。
默认值:False(需要手动通过参数传递,如 def test_demo(clean_extract))。
autouse=True:无需在测试用例中声明,框架会自动运行 clean_extract。
# autouse=True:自动执行
scope:
定义fixture的作用范围,决定fixture何时创建和销毁。
#执行顺序遵循:session->package->module->class->function
# scope='function': 默认值,作用于每个测试用例(包含函数/方法),每个用例执行前都会运行一次;
# scope='class': 作用于整个类,每个测试类/测试函数执行前都会运行一次;
# scope='module': 作用于整个模块(多个类),每个module(每个py文件)执行前都会运行一次,可以实现多个.py跨文件共享前置
# scope='package': 每个python包执行前都会运行一次;
# scope='session': 作用于整个session,整个测试用例运行前运行一次
@pytest.fixture(scope="session", autouse=True)
|
作用域 |
关键字 |
执行时机 |
接口自动化使用场景 |
|
函数级 |
function |
每条用例前 |
用例数据清理、独立初始化 |
|
类级 |
class |
每个测试类前 |
类内用例公共准备 |
|
模块级 |
module |
每个 py 文件前 |
模块公共配置 |
|
包级 |
package |
每个包前 |
极少用 |
|
会话级 |
session |
整个测试前运行一次 |
登录 token、全局 session、数据库连接 |
例子:
#clean_extract在所有测试用例运行前,执行一次
@pytest.fixture(scope="session", autouse=True)
def clean_extract():
clean_yaml()
clean_photos()
fixture带参数传递
import pytest
# autouse=True:所有用例自动使用这个 fixture,不用手动传参
@pytest.fixture(autouse=True)
def login_r(request):
# 关键:request.param 接收 parametrize 传过来的参数
user = request.param
print(f"打开首页准备登录,登录用户: {user}")
# 把用户信息返回给测试用例
return userimport pytest
test_user_data = ["Tome", "Jerry"]
# indirect=True:告诉 pytest,把 "login_r" 这个参数交给 fixture 去执行,而不是直接传给用例
@pytest.mark.parametrize("login_r", test_user_data, indirect=True)
def test_login(login_r):
a = login_r
print(f"测试用例中login的返回值: {a}")
assert a != ""
if __name__ == '__main__':
pytest.main(["-s"])执行结果:
打开首页准备登录,登录用户: Tome
测试用例中login的返回值: Tome .
打开首页准备登录,登录用户: Jerry
测试用例中login的返回值: Jerry .
关键点拆解:
autouse=True
-
- 表示这个 fixture 会被所有测试用例自动调用,不用在函数参数里写
login_r也会执行 - 但这里因为用了
indirect=True,它的执行会被parametrize控制
- 表示这个 fixture 会被所有测试用例自动调用,不用在函数参数里写
request.param
-
- 这是 pytest 内置的
request对象提供的属性,专门用来接收indirect=True时,parametrize传入的参数值 - 可以把它理解为:
parametrize传的参数,通过indirect交给 fixture,fixture 用request.param接住
- 这是 pytest 内置的
3.indirect=True 的作用(灵魂!)
- 正常情况下,
@pytest.mark.parametrize("login_r", data)会直接把data里的值传给用例的login_r参数 - 加上
indirect=True后,逻辑变成:把test_user_data里的每个值,先传给名为login_r的 fixture,让 fixture 处理,再把 fixture 的返回值传给用例 - 简单说:让 fixture 来接收参数,而不是用例直接接收
4.用例里的 login_r
- 它不再是直接拿到
Tome/Jerry,而是拿到login_rfixture 的返回值(这里就是user) - 你可以在 fixture 里加更多逻辑(比如根据用户不同执行不同登录操作),用例里只需要拿到处理好的结果。
注意:
indirect=True必须和parametrize的参数名与 fixture 名完全一致(这里都是login_r)request.param只能在 fixture 里用,不能直接在测试用例里用- 如果
parametrize传多参数,需要用indirect=["login_r"]指定哪些参数要传给 fixture
这个玩法的核心价值(接口自动化里超实用)
可以把它升级成带参数的动态登录 fixture,比如:
@pytest.fixture
def login_r(request):
user = request.param
# 根据不同用户执行不同登录逻辑
if user == "admin":
token = admin_login()
elif user == "test":
token = test_user_login()
else:
token = guest_login()
return {"user": user, "token": token}pytest接口自动化框架的运行顺序
1.加载 conftest.py:Pytest会优先加载项目根目录下的 conftest.py,以及各子目录中的 conftest.py(按目录层级逐层加载)。
执行 scope="session" 的Fixture:本例中的 clean_extract 会在所有测试用例执行前运行。
2.发现测试用例:Pytest按以下规则搜索测试用例:
文件名匹配 test_*.py 或 *_test.py。
函数名或类方法名匹配 test_*。
3.执行测试用例:
默认按文件名和测试函数名的字母顺序执行。
可通过 pytest-ordering 插件自定义执行顺序。
4.生成报告:
测试完成后,生成Allure、HTML等格式的报告。
9.pytest标签
1.@pytest.mark.parametrize()
作用:
为同一个测试函数传入多组不同的参数,让测试函数自动执行多次(每组参数执行一次)。在接口自动化中,这可以用来批量测试:
- 不同的接口请求参数(如正常 / 异常参数)
- 不同的接口入参和预期响应结果
- 不同的接口环境(如测试 / 预发环境)
@pytest.mark.parametrize("参数名1[,参数名2...]", 参数值列表)
def test_函数名(参数名1[,参数名2...]):
# 测试逻辑(接口请求、断言等)- 参数名:字符串格式,多个参数用逗号分隔
- 参数值列表:可迭代对象(列表 / 元组 / 字典列表/字典元祖等),每组值对应参数名的顺序
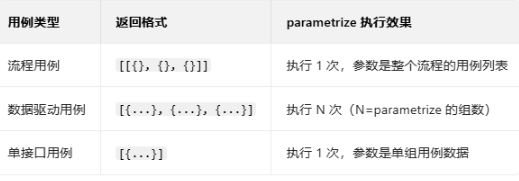
列表有几个元素,就执行几次

1.单接口用例(返回格式[{...}],执行 1 次,单组参数) :
用例是单个接口的单组参数,仅验证该接口的 “基础功能是否可用”,不做多场景覆盖,执行一次即可完成验证。
适合 “单个接口 + 单一场景 + 快速验证” 的场景,重点是 “通”,而非 “全”。
2. 数据驱动用例(返回格式[{...}, {...}, {...}],执行 N 次,多组参数) :
基于同一个接口模板,通过parametrize定义多组入参 / 预期结果,执行 N 次(N = 参数组数),覆盖该接口的 “正向 / 反向 / 边界 / 异常” 等多场景。
适合 “单个接口 + 多场景覆盖 + 减少代码冗余” 的场景,重点是 “全”,而非 “快”。
3. 流程用例(返回格式[[{}, {}, {}]],执行 1 次,流程用例列表) :
用例是多个接口按业务逻辑串联的列表,执行 1 次就能验证 “完整业务流程”,接口之间有依赖(比如前一个接口的返回值作为后一个接口的入参)。
适合 “多接口串联 + 业务流程完整验证” 的场景,重点是 “流程通顺、数据流转正确”,而非单个接口的细节。
2.skip跳过
使用场景:
调试时不想运行这个用例 ;
标记无法在某些平台上运行的测试功能 ;
在某些版本中执行,其他版本中跳过 ;
当前外部资源不可用时跳过(如果测试数据是从数据库中获取的,连接数据库未成功则跳过-因为执行会报错) ;
@pytest.mark.skip()
@pytest.mark.skip( reason="跳过原因" )# 唯一参数,可选
@pytest.mark.skip(reason="功能未开发,暂不执行")
def test_01():
pass@pytest.mark.skipif()
@pytest.mark.skipif( condition, # 条件:True=跳过,False=执行
reason="" # 跳过原因(强烈建议必须写) )
# 条件为 True → 跳过
@pytest.mark.skipif(1 == 1, reason="条件满足,跳过用例")
def test_skip():
passimport pytest
env = "dev"
@pytest.mark.skipif(env == "dev", reason="开发环境跳过")
def test_api():
pass|
装饰器 |
作用 |
使用场景 |
|
|
永远跳过,无任何判断 |
功能废弃、代码未写完、永久不用跑 |
|
|
满足条件才跳过 |
区分环境、版本兼容、临时屏蔽某版本用例 |
skip是无条件跳过;skipif是条件式跳过- 可以装饰函数、类
- 可以用
pytest.skip()在用例内部动态跳过 skipif常用:判断系统、环境变量、版本号控制用例执行
扩展:pytest.skip () 函数内部跳过(参数更多)
这个是在代码内部动态跳过,不是装饰器,参数更多:
pytest.skip( reason="跳过原因",
allow_module_level=False # 是否允许在模块级别跳过(整个文件跳过) )
def test_demo():
if 1 > 0:
pytest.skip(reason="内部条件满足,直接跳过")3.xfail标记用例为失败
pytest.mark.xfail(
condition=None, # 条件:满足就标记预期失败
*,
reason=None, # 为什么预期失败
raises=None, # 只预期某种异常
run=True, # 是否运行这个用例
strict=False # 严格模式:意外成功是否算失败
)xfail = 预期失败(expected failure)
- 标记这个用例本来就应该失败
- 就算真的失败了 → 也算通过(XFAIL)
- 万一意外成功了 → 算失败(XPASS)
使用场景:
- 功能没做完
- Bug 没修复
- 接口暂不可用
- 已知会失败,但不想让它影响整体报告
4.使用自定义标记mark,只执行部分用例
import pytest
def pytest_configure(config):
marker_list = ["search", "login"] # 标签名集合
for markers in marker_list:
config.addinivalue_line("markers", markers)或者在ini文件中声明
[pytest]
markers =
login: Run login tests
search: Run search tests
smoke: 冒烟用例import pytest
@pytest.mark.login
def test_login():
print("登录用例")
@pytest.mark.search
def test_search1():
print("搜索用例1")
@pytest.mark.search
def test_search2():
print("搜索用例2")
if __name__ == '__main__':
pytest.main()1. 核心钩子函数 pytest_configure
- 这是 pytest 的内置钩子函数,在 pytest 启动时自动执行一次
- 作用:用来做全局配置,比如注册自定义标记、设置全局变量等
2. config.addinivalue_line("markers", markers)
- 这是 pytest 注册自定义标记的标准方法
- 语法:
config.addinivalue_line("markers", "标记名: 标记描述") - 作用:告诉 pytest,
login和search是合法的标记,不会报Unknown marker警告
3.@pytest.mark.login / @pytest.mark.search
- 给用例打上对应的标签
- 打了
@pytest.mark.login的用例,就属于login分组 - 打了
@pytest.mark.search的用例,就属于search分组
用这些标记跑用例 (标签支持逻辑筛选)
1>只跑 login 标记的用例 : pytest test_main.py -m login -sv/pytest.main(["-vs","-m","login"])
只会执行 test_login,输出: 登录用例
2>同时跑 login 和 search 标记的用例(或条件) pytest test_main.py -m "login or search" -s
3>只跑 login 且不跑 search 的用例 pytest test_main.py -m "login and not search" -s
注册标记的标准写法(推荐)
现在的写法虽然能用,但更规范的写法要加上标记描述,方便团队协作:
def pytest_configure(config):
marker_list = [
("login", "标记登录相关用例"),
("search", "标记搜索相关用例")
]
for name, desc in marker_list:
config.addinivalue_line("markers", f"{name}: {desc}")这样运行 pytest --markers 时,就能看到每个标记的说明:
@login: 标记登录相关用例
@search: 标记搜索相关用例
核心价值(接口自动化里超实用)
- 用例分组管理:按模块(登录 / 搜索 / 订单)、优先级(p0/p1)、环境(dev/test)给用例打标签
- 灵活执行策略:上线前只跑核心
p0用例,回归时跑全量,问题排查时只跑指定模块 - 避免警告:不注册标记直接用,pytest 会报
Unknown marker警告,注册后警告消失
避坑提醒
- 标记名不能重复:同一个标记名只能注册一次,重复注册会报错
- 标记名不能有特殊字符:只能用字母、数字、下划线
- 运行时引号问题:带逻辑运算符(or/and/not)的
-m参数,要用双引号包起来,比如-m "login or search"
钩子函数
pytest 钩子函数 = pytest 框架给你预留的 “后门”,让你可以在 pytest 的不同阶段,插入自己的代码, 实现 pytest 本身不支持的功能。
pytest 在运行测试的过程中,会按固定的流程走(比如:启动 → 收集用例 → 执行用例 → 生成报告)。而「钩子函数」就是你能在这些流程节点上,“插队” 执行自己代码的入口。
pytest_configure 就是其中一个钩子函数。
钩子函数的核心特点
- 不用手动调用:pytest 会在固定时机自动执行,你只需要按规定的名字写好函数就行
- 名字固定:不能自己随便起名,必须用 pytest 规定的名字(比如
pytest_configure) - 参数固定:每个钩子函数的参数都是 pytest 传进来的,比如
config、session、items,用来和 pytest 交互 - 优先级高:钩子函数的代码会在 pytest 的核心流程之前 / 之后执行,能影响 pytest 的行为
|
钩子函数 |
执行时机 |
接口自动化常用场景 |
|
|
pytest 启动时,自动执行一次 |
注册自定义标记、读取全局配置、设置环境变量 |
|
|
收集完所有用例后 |
修改用例名称(解决中文乱码)、给用例排序 |
|
|
每个用例执行前后 |
记录用例执行结果、失败时自动截图 / 保存日志 |
|
|
整个测试会话开始前 |
初始化全局资源(比如连接数据库、启动服务) |
|
|
整个测试会话结束后 |
关闭数据库连接、清理测试数据、生成最终报告 |
|
|
每个用例执行前 |
用例级前置操作(比如创建测试数据) |
|
|
每个用例执行后 |
用例级后置操作(比如删除测试数据) |
和 fixture 的区别
|
对比项 |
钩子函数 |
fixture |
|
作用对象 |
pytest 框架本身 |
测试用例 |
|
执行时机 |
pytest 运行的固定节点(启动、收集用例、会话结束等) |
按作用域(function/module/session),在用例前后执行 |
|
核心用途 |
修改 pytest 行为、全局配置、报告处理 |
给用例提供前置 / 后置、依赖注入(比如 token、session) |
|
调用方式 |
自动执行,不用传参 |
必须作为参数传入用例函数,或者用 |
10.pytest的ini文件
pytest.ini介绍
是pytest主配置文件,一般放在项目根目录下,名字不可改,用于存放一些配置选项,这些选项可以通过pytest -h查看到。
ini文件由节,键,值组成。
节[section]
选项/参数(键=值)
name=value
注释
注释使用分号(;)
[pytest]
;生成allure报告
;-v:详情信息
;-s:调试信息
;--alluredir=temps:生成临时报告
;--clean-alluredir:清空临时文件
addopt = -vs --alluredir=temps --clean-alluredir
;指定存放测试用例的路径
;testpaths是一系列相对于根目录的路径,用于限定测试用例的搜索范围
testpaths = ./testcases
;定义测试文件以test_开头
python_files = test_*.py
;定义测试类以Test开头
pyton_classes = Test*.py
;定义测试方法以test_开头
python_functions = test_*
;用于注册自定义的测试标记(用于对测试函数或类进行分类和过滤的机制)
;定义后,就可以在测试代码中使用@pytest.mark.smoke来标记测试函数或类。多个换行
markers =
smoke: 冒烟用例
;日志配置
;日志文件
log_file = ./logs/frame.log
;日志的级别:DEBUG调试,INFO信息,WARNING警告,ERROR错误,CRITIAL严重
log_file_level = INFO
;日志格式
;设置了日志文件的格式,包括时间戳、日志级别、文件名、日志消息。
log_file_format = %(asctime)s %(levelname)s %(filename)s %(message)s
;基础路径配置
[base_url]
base_url = https://test.sztdri.compytest.ini ⽂件中的选项和参数设置将适⽤于整个测试项⽬,但也可以在
命令⾏中使⽤选项覆盖部分配置。
ini文件中自定义测试标记和在conftest文件中用pytest_configure注册标记区别:
它们的最终效果是一样的:都是告诉 pytest “这些标记是合法的,别报 Unknown marker 警告”。
• pytest.ini 方式:在配置文件里写死标记
• conftest.py + pytest_configure 方式:用代码动态注册标记
|
对比维度 |
pytest.ini 方式 |
conftest.py + pytest_configure 方式 |
|
写法 |
静态配置文件 |
动态代码注册 |
|
语法 |
固定格式 下写多行 |
|
|
适用场景 |
标记固定不变的项目 |
标记需要动态生成、多环境区分、条件注册 |
|
扩展性 |
差,只能写死 |
强,支持循环、条件判断、动态读取配置 |
|
多项目 / 多环境兼容 |
差,每个项目都要维护 ini |
强,可复用代码、按环境注册不同标记 |
|
修改方式 |
手动改 ini 文件 |
改代码逻辑,支持配置文件驱动 |
|
团队协作友好度 |
一般,需要维护 ini 格式 |
高,可统一管理、自动生成 |
|
执行时机 |
pytest 启动时读取配置 |
pytest 启动时自动执行钩子注册 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)