深度解析RAGFlow:超越基础架构图的实战级生产级RAG引擎全解
本文深入剖析了RAGFlow这一生产级RAG引擎,超越传统简洁架构图,揭示了其处理真实世界复杂知识源的多样化能力。文章强调RAGFlow不仅是简单的模型与向量库结合,而是一个完整的上下文生产与消费平台,涉及文档理解、模板化处理、可追溯引用、异构数据接入等多项能力。通过分析RAGFlow的系统边界、主链路以及源码目录映射到架构层的对应关系,阐述了其如何将原始数据转化为可消费上下文,并区分了数据写入链路和查询生成链路的不同功能与重要性。文章最后总结了生产级RAG引擎的关键特性,并提供了源码阅读建议,帮助读者全面理解RAGFlow的架构与功能。
先把那张“过于简单”的 RAG 架构图放一放
很多人对 RAG 的第一印象,仍然停留在一张非常简洁的架构图里:
前端负责提问,后端负责调度,向量库负责检索,大模型负责回答。
这张图当然没有错。它适合解释 RAG 的基本原理,也足够让人快速理解“检索增强生成”这件事。但问题在于,一旦系统从 Demo 走向真实业务,这张图就开始不够用了。
真实世界里的知识并不会乖乖地躺在一段段干净文本里。它可能藏在 PDF 的版面结构里,夹在 Word 的表格中,散落在 PPT 的图文关系里,也可能来自扫描件、网页、Excel、图片、知识图谱、多语言查询、Agent 工具调用、MCP 协议接入,甚至来自用户长期对话沉淀下来的 Memory。
这时候,RAG 就不再是“模型外挂一个向量库”那么简单。
RAGFlow 值得拿来分析,正在于它把这个问题摊开了。它对自己的定位,已经不是一个狭义的“检索问答工具”,而是一个面向 LLM 的 context layer:文档理解、模板化切块、可追溯引用、异构数据接入、多路召回、融合重排、Agent 编排、Memory、MCP,这些能力共同组成了它的系统边界。
如果再看 RAGFlow 当前 main 分支的目录结构,这种边界会更加清楚:api、deepdoc、rag、agent、memory、mcp、web、docker、sdk/python 等模块,并不是简单的功能堆叠,而是在把一个生产级 RAG 引擎拆成不同职责的子系统。
这也是为什么我认为,RAGFlow 很适合作为这个系列的切入口。它不只是“功能很多”,更重要的是,它把许多真正决定生产可用性的部分暴露在了源码和部署结构里:文档理解、异步任务执行、文档引擎、对象存储、会话与锁、Agent 运行时、Memory、MCP、SDK 接入、管理平面,几乎都能在官方文档和仓库目录中找到对应位置。
所以,这篇文章不会急着进入 chunking、Hybrid Retrieval 或 Agent component 的细节。作为总览篇,它更应该先回答一个底层问题:
一个生产级 RAG 引擎,系统边界到底应该画到哪里?
哪些部分属于在线服务?哪些部分属于离线加工?哪些部分又是面向 Agent 和外部系统的运行时扩展面?
只有先把这张大图看清楚,后面再去读 RAGFlow 的文档解析、索引构建、混合检索、GraphRAG、RAPTOR、Agent 与 Memory,才不会把它们误解成一堆孤立的功能点。
RAGFlow 的系统边界
如果用一句话概括 RAGFlow 的边界:
它不是“一个模型服务”,而是“一个上下文生产与消费平台”。
平台的外侧,是用户、文档、在线数据源、第三方应用与外部 Agent 客户端;平台的内侧,是 API Server、Task Executor、Document Parser/DeepDoc、RAG Core、Agent Runtime、Memory、MCP,以及支撑它们运行的文档引擎、关系数据库、对象存储、缓存/锁服务。官方文档与部署配置明确把 Elasticsearch/Infinity、MySQL、MinIO、Redis 列为核心依赖;Admin Service 文档还说明,它负责监控 MySQL、Elasticsearch、Redis、MinIO 等关键组件的状态,这意味着这些组件不是“可有可无的外挂”,而是系统边界的组成部分。
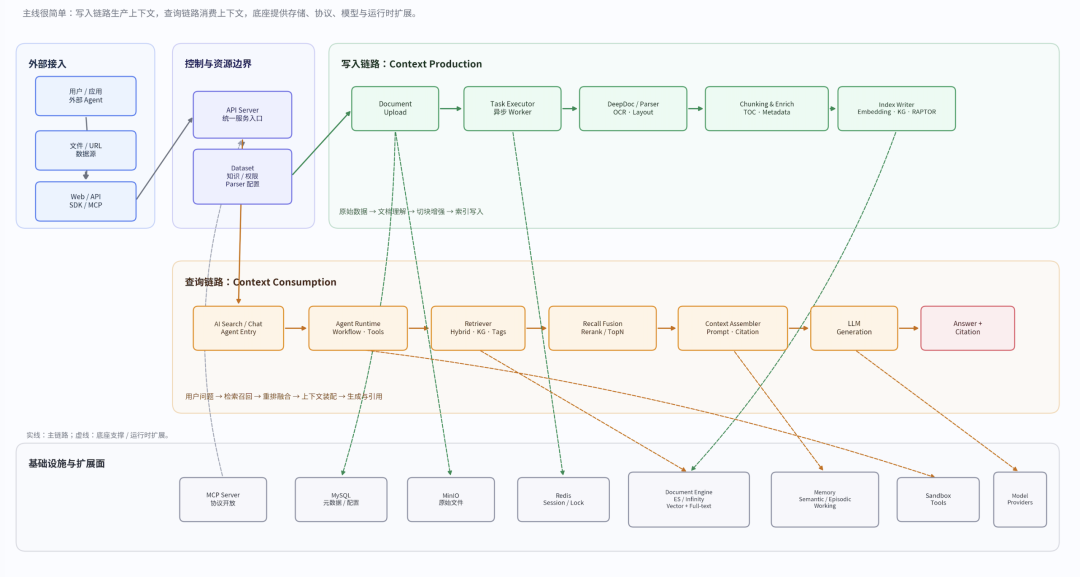
这张图不想画成一张“源码调用栈”。
因为如果真按函数调用一层层画下去,图很快就会变成一团线,大家反而看不清 RAGFlow 的整体结构。所以这里画的是一张主链路图:它参考了当前 main 分支的目录结构、几个关键入口文件,以及官方文档里已经明确说明的组件关系。
有些部分现在已经比较清楚。比如,api/apps/__init__.py 负责创建 Quart 应用,并把 _app.py、restful_apis/*.py、sdk/*.py 这些路由动态注册进来;api/ragflow_server.py 负责初始化数据库、加载运行配置,并启动 HTTP 服务;docker/launch_backend_service.sh 会同时启动多个 task_executor.py worker 和主服务进程;MCP server 在官方文档里也被单独定义为一个补充 RAGFlow server 的独立组件。
但也有一些更细的调用链,尤其是 Agent 运行时里某个组件如何继续下探到 rag 内部,再如何把结果交给 Memory、Sandbox 或其他工具。
先把这条主链路看明白之后,RAGFlow 里几个容易混在一起的角色就清楚多了。
Web UI 负责和用户交互;API Server 是统一入口;Task Executor 负责处理解析、切块、索引这类重活;Dataset 定义知识范围和权限边界;DeepDoc / Document Parser 负责把复杂文档拆成系统能理解的结构;Retriever 不是简单地“查向量库”,而是在运行时把多路召回结果组织成可用上下文;LLM 提供生成、向量化、重排等模型能力;Agent 则在这些能力之上继续做流程编排、工具调用、Memory 引入和 Sandbox 执行。
所以,RAGFlow 不是把一堆功能并排放在一起,而是围绕“原始数据如何变成可消费上下文”搭出了一条分层流水线。
两条主链路
数据写入链路
只有把“写入链路”和“查询链路”分开看,才能真正理解 RAGFlow。
在写入侧,官方 HTTP API 明确把“上传文档”和“解析文档”拆成两个动作:先向 /api/v1/datasets/{dataset_id}/documents 上传文件,再向 /api/v1/datasets/{dataset_id}/chunks 触发解析。上传后的原始文件存放在 MinIO 中;而解析与索引相关的重量级工作,则通过 Task Executor 完成。docker/launch_backend_service.sh 可以直接看到,系统会并行启动多个 rag/svr/task_executor.py worker,再启动 api/ragflow_server.py,这说明 ingestion 从一开始就被设计成与在线请求解耦的异步数据平面。
把这条链路再往里拆,Task Executor 不是一个“黑箱队列消费者”,它在源码里已经暴露出很强的架构含义。rag/svr/task_executor.py 中可以直接看到 init_kb、embedding、run_dataflow 等入口;更关键的是,run_dataflow 会从 UserCanvasService 读取 pipeline DSL,然后实例化 rag.flow.pipeline.Pipeline 运行。这一点和 v0.21.0 release notes 中“Orchestratable ingestion pipeline”的表述完全对上:RAGFlow 后来的 ingestion pipeline 不是另起炉灶,而是把数据摄取当成可编排的图执行流程来落地。
因此,高层“数据写入链路”可以概括成这样:
原始文件 / URL / 数据源 → API Server → Dataset / Document 元数据落库 → 原件入 MinIO → Task Executor → DeepDoc / Parser → Chunker / Transformer / Indexer → Embedding / GraphRAG / RAPTOR 等增强 → 文档引擎写入,同时保留 metadata / citation 所需信息。 这条链路之所以重要,是因为 RAGFlow 后续几乎所有“回答质量”能力都依赖它:TOC、image & table context window、auto-keyword、auto-question、auto-metadata、tag set、knowledge graph、RAPTOR,本质上都发生在写入期,或者依赖写入期产物。
DeepDoc 在这里扮演的是“文档感知层”,而不是简单文件读取器。它的 vision 模块覆盖 OCR、layout recognition、TSR;parser 模块面向 PDF、DOCX、EXCEL、PPT 等格式。更关键的是,官方 DeepDoc README 明确写到,PDF parser 的输出不仅是文本,还包括页码与矩形位置信息、表格裁剪图与自然语言化内容、图像与 caption 关系。这也是为什么 RAGFlow 能把 grounded citations 当成主打能力之一:要做可追溯引用,前提不是“回答里加个脚注”,而是 ingest 时就没有丢文档结构。 此外,自 v0.17.0 起,OCR/TSR/DLR 等视觉解析能力已与 chunking method 解耦,这也是生产级系统才会认真做的边界切分。
查询生成链路
查询侧则是另一条完全不同的链路。
它是一个单轮 AI 对话,采用预定义 retrieval strategy,也就是 weighted keyword similarity + weighted vector similarity 的 hybrid search;而 AI Chat/Agent Runtime 则允许配置 similarity threshold、vector weight、Top N、multi-turn optimization、cross-language search、rerank model、knowledge graph 等参数。没有 rerank 时,是关键词分数与向量相似度混合;有 rerank 时,则是关键词分数与 rerank score 混合;如果开启 knowledge graph,又会进入实体、关系、community report 的另一套召回路径。
所以,高层“查询生成链路”应该写成这样:
用户问题 → Web / API / SDK / OpenAI-Compatible API / MCP → API Server / Agent Runtime → query understanding 或多轮优化 / 跨语言改写 / metadata 条件 → hybrid retrieval / rerank / GraphRAG / tag / TOC / image-table context window 等信号参与召回 → Top N context assembly → LLM generation → reference / citation → Web / API / SDK / MCP 输出。 这里最容易被忽略的一点是:Retriever 在生产级 RAG 里不是数据库适配器,而是上下文装配器。它要决定查什么、查多少、按什么权重混合、哪些结果进入 prompt、哪些结果该剔除。
rag 目录本身也在证明这一点。当前 main 分支下,它并不止有一个 llm 包,而是同时出现了 flow、graphrag、llm、nlp、prompts、raptor.py、advanced_rag 等结构;其中 rag/llm 下又独立拆出了 chat_model.py、embedding_model.py、rerank_model.py、ocr_model.py、cv_model.py、sequence2txt_model.py 等适配层。这说明在 RAGFlow 的语义里,“大模型能力”从来不只等于 chat model,而是一个覆盖 chat、embedding、rerank、OCR、视觉、语音等多类模型的统一抽象层。
更进一步看,GraphRAG 与 RAPTOR 也被明确纳入运行时检索逻辑,knowledge graph 相关 chunks 作为独立 chunk 参与检索;官方 GraphRAG 文档说明这些图谱实体、关系和 community report 最终仍存入 document engine;rag/raptor.py 里则能看到 cluster、summarization、layers 这些实现细节,以及“需要显著内存、计算、token 成本”的官方提醒。
最后,Agent、Memory、MCP 把查询链路继续往系统边界外推。官方 Agents 文档把 Agent 定义为“前端无代码工作流编辑器 + 后端图式任务编排框架”;v0.20.0 release notes 又说明 Agent 与 Workflow 已经统一编排,并支持 multi-agent、planning、reflection、MCP import;Memory 文档则明确区分 raw logs、semantic memory、episodic memory、working memory;MCP 文档还把 RAGFlow MCP server 定义为独立组件,用于把 RAGFlow 的 datasets 以标准协议暴露给外部客户端。到这里,RAG 引擎已经不只是“知识库问答系统”,而是一个面向 Agent 运行时的 context infrastructure。
源码目录怎么映射到架构层
下面这张表是按系统职责做映射。
| 源码目录 | 架构层 | 作用 |
| web | 展示层 | 用户 Web UI 与 /admin 管理入口的前端工程;README 给出了用户端和管理端访问路径,package.json 显示该前端已迁移到 Vite,并使用 React、react-router、@tanstack/react-query 等依赖。 |
| api | 服务接入与控制层 | api/apps 负责动态注册 _app.py、restful_apis、sdk 路由;api/ragflow_server.py 负责初始化数据库、运行时配置、插件并启动 HTTP 服务;api/db 则承载模型、初始化数据与服务层。 |
| rag/svr | 后台执行层 | docker/launch_backend_service.sh 会并行启动多个 task_executor.py worker;rag/svr/task_executor.py 里能看到 init_kb、embedding、run_dataflow 等 ingestion 关键入口。 |
| deepdoc | 文档理解层 | 目录分成 vision 与 parser;前者覆盖 OCR、layout、TSR,后者负责 PDF、DOCX、EXCEL、PPT 等解析,输出保留版面位置、表格、图像等结构信息。 |
| rag | 检索与上下文工程核心层 | 根目录下包含 llm、flow、graphrag、nlp、prompts、raptor.py、advanced_rag 等模块,对应模型适配、检索逻辑、Pipeline 执行、GraphRAG、RAPTOR 与 prompt 组织。 |
| agent | 运行时编排层 | 目录包含 component、plugin、sandbox、templates、tools、canvas.py;官方文档把它定义为无代码编辑器与图式任务编排框架的结合。 |
| memory | 记忆层 | 目录下的 services、utils 对应 Memory 功能;官方 docs 说明它管理 raw logs、semantic、episodic、working memory,并支撑后续对话的上下文回流。 |
| mcp | 外部协议层 | 目录拆分为 client 与 server;官方文档明确 MCP server 是一个独立组件,用来补充 RAGFlow server,对接外部 MCP client。 |
| sdk/python | 集成层 | 目录里有 ragflow_sdk 包与示例脚本;官方 Python API 文档要求通过 pip install ragflow-sdk 使用,属于面向系统外部集成的开发者入口。 |
| docker | 部署与基础设施层 | docker-compose.yml、.env、service_conf.yaml.template、docker/README.md 明确声明了 RAGFlow 与 document engine、MySQL、MinIO、Redis、Admin、MCP 等组件的启动与配置关系。 |
这里还有一个特别值得强调的点:Dataset 并不对应一个独立顶级目录。 它更像一个横切的领域边界,贯穿 api 的资源模型与权限、deepdoc 的解析配置、rag 的索引与检索范围、以及对象存储中的原始文件组织。官方 Python API 里,创建 dataset 时就已经要求指定 chunk_method 与 parser_config;HTTP API 中,上传文档、解析文档、构建 GraphRAG、构建 RAPTOR,又全部以 dataset 为操作边界。
工程判断、阅读路径
RAG 引擎为什么不能被看成一个“模型服务”,到这里其实已经有了非常清楚的答案。
第一,它有明显不同的计算剖面。在线问答追求低时延,而文档解析、OCR、布局识别、embedding、GraphRAG、RAPTOR、TOC、metadata 抽取这些写入期任务,追求的是吞吐、稳定和可恢复。官方部署配置把 DOC_BULK_SIZE 与 EMBEDDING_BATCH_SIZE 单独暴露出来;RAPTOR、knowledge graph、rerank、多轮优化也都在文档里被明确标注为会增加内存、计算、token 或时延成本。把这些活和 HTTP 在线服务硬塞进同一个“模型推理进程”,最终一定会让系统同时丢掉吞吐和稳定性。
第二,它有明显不同的存储责任分工。MySQL 用于系统级业务数据与配置,MinIO 保存原始上传文件,Redis 提供 session、缓存或分布式锁能力,文档引擎负责混合检索,Admin Service 还要监控这些组件的健康状态。尤其是检索后端,官方 FAQ 直接说了,目前只有 Elasticsearch 与 Infinity 能满足 RAGFlow 的 hybrid search 要求,因为很多开源向量数据库缺少 full-text search、phrase search 和高级 ranking 能力。这个判断很关键:生产级 RAG 的底座不是“有向量库就行”,而是“要有能支撑上下文工程的 document engine”。
第三,它有明显不同的运行时上下文来源。如果上下文只来自 dataset,Chat 也许已经够用;但当上下文还来自 Memory、Tool、Sandbox、MCP、外部数据源甚至多 Agent 协作时,系统就必须把检索从“查知识库”升级成“装配上下文”。这正是 RAGFlow 从 v0.20.0 以后不断把 Agent、MCP、Memory、ingestion pipeline 拉进同一套架构中的根本原因。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)