【论文阅读】-《VisualTrap: A Stealthy Backdoor Attack on GUI Agents via Visual Grounding Manipulation》
VisualTrap:通过视觉接地操纵对GUI智能体的隐蔽后门攻击

原文链接:VisualTrap: A Stealthy Backdoor Attack on GUI Agents via Visual Grounding Manipulation
摘要
由大视觉语言模型驱动的图形用户界面智能体已成为自动化人机交互的革命性方法,能够自主操作个人设备(如手机)或设备内的应用程序,以类人的方式执行复杂的现实世界任务。然而,它们与个人设备的紧密集成引发了重大的安全问题,包括后门攻击在内的许多威胁仍然 largely 未被探索。这项工作揭示,GUI智能体的视觉接地——将文本计划映射到GUI元素——可能引入漏洞,使得新型后门攻击成为可能。通过针对视觉接地的后门攻击,即使给出正确的任务解决计划,智能体的行为也可能被破坏。为了验证这一漏洞,我们提出了VisualTrap,一种通过误导智能体将文本计划定位到触发器位置而非预期目标来劫持接地的方法。VisualTrap使用注入毒化数据的常见方法进行攻击,并在视觉接地的预训练阶段进行,以确保攻击的实际可行性。实证结果表明,VisualTrap仅需5%的毒化数据和高度隐蔽的视觉触发器(人眼不可见)就能有效劫持视觉接地;并且攻击可以泛化到下游任务,甚至在干净微调后仍然有效。此外,注入的触发器可以在不同GUI环境中保持有效,例如在移动/网页上训练并泛化到桌面环境。这些发现强调了迫切需要进一步研究GUI智能体中的后门攻击风险。代码可在 https://github.com/whi497/VisualTrap 获取。
1 引言
由大视觉语言模型驱动的图形用户界面智能体在通过视觉理解和交互自主操作个人设备(如台式机和手机)或其中的应用程序方面展现出卓越能力(Cheng et al., 2024; Zheng et al., 2024b; Wu et al., 2024c)。这些智能体利用LVLM视觉解释界面元素并模拟类人动作,如点击和键入(Zheng et al., 2024b; Wu et al., 2024c; Lu et al., 2024; Hong et al., 2024),从而与设备或应用程序交互。这使得它们能够像人类一样自主执行广泛的GUI任务,标志着LVLM应用和人机交互自动化的重大进步(Nguyen et al., 2024; Gou et al., 2025)。
鉴于GUI智能体在用户高度私密且安全敏感的设备上运行,重大的安全问题随之产生。此外,GUI智能体独特的工作特性(例如在GUI环境中工作)可能使它们暴露于新的、更复杂的安全风险。这些担忧促使人们努力探索GUI智能体特有的安全问题(Zhang et al., 2024a; Wu et al., 2024a)。然而,据我们所知,大多数研究主要集中于对抗性攻击,这些攻击仅操纵输入(Wu et al., 2024a; Xu et al., 2024a)或环境(Zhang et al., 2024b)来误导智能体行为。相比之下,后门攻击——即有意将隐藏触发器注入智能体,使其在干净数据上行为正常,但在包含触发器的输入上表现出恶意行为——仍然 largely 未被探索,尽管在相关领域已显示出严重后果(Li et al., 2022; Yang et al., 2024)。
我们认为,当前GUI智能体对视觉接地的依赖创造了一条独特且有效的后门攻击途径,可能导致灾难性后果。视觉接地涉及在屏幕上定位和识别特定界面元素(如按钮、文本字段等)以执行文本计划,是智能体准确与GUI交互的基础。如果植入了后门,只需呈现带有触发器的屏幕,即使给出正确的文本计划,视觉接地也可能被劫持以控制智能体行为。例如,攻击者可以欺骗智能体将动作导向触发器位置,而不是指令(文本计划)中指定的预期目标位置。这将为数据窃取、未授权访问和金融欺诈等恶意活动打开大门(例如,控制智能体点击恶意广告)。
在本工作中,我们提出了一种简单的方法VisualTrap,用于基于视觉接地执行后门攻击。具体来说,VisualTrap将一小部分毒化训练样本注入GUI智能体的接地预训练过程(即LVLM的接地训练)。这些毒化样本将一个触发器——具有特定强度的小像素高斯噪声——嵌入屏幕数据中,并将接地输出标签调整为触发器的位置。通过在这样的毒化数据上训练,我们可以使模型在触发器出现时将文本计划接地到触发器位置而非预期位置,从而有效劫持接地过程。值得注意的是,由于我们操纵的是接地预训练过程(独立于特定智能体任务),VisualTrap针对的是基础接地能力,而不依赖于GUI任务。这使得攻击在实际中更可行。例如,我们可以发布一个带有毒化接地预训练的LVLM,供下游GUI构建使用,以实现攻击目标。
我们进行了广泛的实验来评估VisualTrap的有效性。实证结果表明:1)我们能够成功地将设计的后门注入GUI智能体,从而劫持通用视觉接地能力,平均成功率高达90%;2)后门在下游GUI任务中仍然有效,即使在干净数据上使用常见的LoRA调优策略进行微调后,仍能操纵智能体行为。此外,我们观察到攻击在人眼不可见的高度隐蔽触发器下仍然有效,并表现出强大的跨环境迁移性。这些发现突显了VisualTrap的有效性,并揭示了通过视觉接地对GUI智能体进行后门攻击的重大风险,强调需要更多关注GUI智能体的安全性。
本文的主要贡献总结如下:
- 据我们所知,这是首个针对GUI智能体视觉接地能力的后门攻击研究,揭示了一个关键漏洞。
- 我们提出了VisualTrap,基于GUI智能体的视觉接地植入后门,导致它们将文本计划错误地匹配到GUI上的错误位置(即触发器位置),从而引发危险行为。
- 我们进行了广泛的实验,包括触发器注入成功率分析和下游攻击应用,证明VisualTrap能够有效地将后门嵌入GUI智能体的视觉接地中。
2 相关工作
- GUI智能体。受LLM/LVLM在各个领域取得巨大成功的启发(Achiam et al., 2023; Bai et al., 2023; Wang et al., 2024b; Zhao et al., 2024; 2025; Zhang et al., 2025),GUI智能体近年来取得了显著发展,从早期的基于规则的自动化系统(Hellmann & Maurer, 2011)过渡到由LVLM驱动的复杂智能体,能够直接理解和交互复杂的视觉界面(Cheng et al., 2024; He et al., 2024; Wang et al., 2024a; Wu et al., 2024c; Lu et al., 2024)。最近的进展强调了端到端的视觉接地方法,其中GUI智能体直接从屏幕像素解释视觉元素,并将自然语言指令映射到相应的界面动作(Zheng et al., 2024b; Hong et al., 2024; Lu et al., 2024; Li et al., 2024)。
尽管取得了这些进展,部署GUI智能体的安全性问题仍然 largely 未被探索。现有研究考察了针对智能体决策的对抗性攻击(Wu et al., 2024a)和环境干扰(Zhang et al., 2024b)。AdvWeb(Xu et al., 2024a)探索了向HTML内容注入恶意命令以误导基于Web的智能体。然而,这些研究并未系统性地解决后门威胁,而是专注于通过输入和环境因素误导GUI智能体。此外,它们的攻击并未专门针对视觉接地。相比之下,我们研究了针对GUI智能体视觉接地的后门漏洞。
-
LVLM的后门攻击。针对LVLM的后门攻击已成为一个重要的安全问题。近期研究探讨了各种主题,包括在训练数据集中嵌入触发器(Lyu et al., 2024a,b; Ni et al., 2024)、组合图像-文本触发器(Liang et al., 2024),以及优化图像触发器使其在视觉上与干净图像无法区分(Xu et al., 2024b)。然而,这些工作主要集中于攻击模型的正常响应能力,未考虑视觉接地。不同地,我们针对攻击核心视觉接地来操纵LVLM对GUI元素的感知。
-
针对智能体的后门攻击。Wang等人(2024c)和Yang等人(2024)探索了操纵基于LLM的智能体最终输出的后门攻击,要么通过将触发器直接嵌入用户查询,要么通过嵌入环境。虽然这些研究突显了基于文本的LLM智能体对后门攻击的脆弱性,但它们主要集中于在纯文本环境中操纵预定义动作或工具选择。相比之下,我们的工作本质上是不同的,因为它针对GUI智能体的视觉接地机制,使得攻击显著不同。
3 劫持GUI智能体的视觉接地能力
3.1 GUI智能体的形式化
GUI智能体作为自主系统运行,旨在通过视觉感知和动作生成与图形用户界面交互。这些智能体通常遵循两种架构范式之一:统一的端到端方法或将规划与接地分离的模块化设计。
GUI接地预训练。无论选择哪种架构,两种范式都依赖于一个基础的预训练步骤,以赋予智能体稳健的视觉接地能力。此步骤涉及在多样化的GUI数据语料库 D g = { ( I i , D i , C i ) } i = 1 N g \mathcal{D}_g = \{(I_i, D_i, C_i)\}_{i=1}^{N_g} Dg={(Ii,Di,Ci)}i=1Ng上训练LVLM,其中每个样本包含一个截图 I i I_i Ii、一个指代表达 D i D_i Di和一个对应的目标坐标 C i C_i Ci。模型被优化以最小化以下损失来增强其接地能力:
θ g = arg min θ 1 ∣ D g ∣ ∑ i = 1 N g − log P θ ( C i ∣ I i , D i ) , ( 1 ) \theta_g = \arg \min_{\theta} \frac{1}{|\mathcal{D}_g|} \sum_{i=1}^{N_g} - \log P_{\theta}(C_i | I_i, D_i), \quad (1) θg=argθmin∣Dg∣1i=1∑Ng−logPθ(Ci∣Ii,Di),(1)
其中 θ \theta θ是LVLM的模型参数。
端到端架构。在端到端范式中,单个LVLM同时负责理解视觉界面和生成适当的动作。预训练后的LVLM通常会在下游任务数据上进行微调。具体来说,给定一个任务指令 T T T,模型在截图 I I I和交互历史 H H H上生成下一个动作的动作类型 A A A和坐标 C C C:
( A , C ) = V e 2 e ( I , T , H ; θ g ′ ) , ( 2 ) (A, C) = V_{e2e}(I, T, H; \theta_g'), \quad (2) (A,C)=Ve2e(I,T,H;θg′),(2)
其中 θ g ′ \theta_g' θg′是微调后的参数。
模块化架构。在模块化范式中,两个独立的LVLM分别处理规划与接地:
- 规划LVLM:规划LVLM V l V_l Vl解释任务指令 T T T、当前GUI截图 I I I和交互历史 H H H,以生成动作类型 A A A和指代表达 D D D:
( A , D ) = V l ( I , T , H ; θ l ) , ( 3 ) (A, D) = V_l(I, T, H; \theta_l), \quad (3) (A,D)=Vl(I,T,H;θl),(3)
其中 θ l \theta_l θl表示规划LVLM的参数。规划LVLM通过单独优化实现,可以是通过规划任务微调,或采用鲁棒的现成模型。
- 接地LVLM:预训练的接地LVLM V g V_g Vg将指代表达 D D D和截图 I I I映射到精确坐标 C C C:
C = V g ( I , D ; θ g ) , ( 4 ) C = V_g(I, D; \theta_g), \quad (4) C=Vg(I,D;θg),(4)
其中 θ g \theta_g θg是GUI接地预训练LVLM的参数。最终动作由规划LVLM的动作类型 A A A和接地LVLM的坐标 C C C组合而成。
3.2 威胁模型
攻击目标。我们的攻击针对LVLM驱动的GUI智能体的视觉接地能力。视觉接地是一种基础能力,使GUI智能体能够根据文本指令在各种平台(包括移动、桌面和网页环境)上定位和识别界面元素(如按钮、文本字段、下拉菜单)。通过破坏视觉接地机制,攻击者可以潜在地操纵智能体在不同应用中的行为,而无需特定任务知识。
攻击约束。我们在以下现实约束下操作攻击场景:1)有限的数据访问:攻击者只能向视觉接地预训练数据中注入一小部分毒化样本,无需访问或了解所有训练数据或下游任务的具体细节。2)模型访问:攻击者无需访问模型参数。3)隐蔽性:后门模型必须在干净输入上保持正常功能,确保攻击在常规使用中不被检测到。
攻击场景。我们研究了两种模拟现实世界威胁的攻击场景:
- 直接接地攻击:在此场景中,攻击者毒化LVLM的视觉接地预训练数据,随后这些LVLM作为GUI智能体的接地LVLM。当模型开发者无意中从公共仓库引入被破坏的数据集,或具有对抗意图的内部人员故意操纵训练语料时,可能发生此类数据毒化。
- 迁移攻击:在此情况下,即使模型经过针对特定下游GUI任务的干净微调后,视觉接地的对抗性操纵仍然有效。此场景反映了现实世界的威胁,从业者 unknowingly 下载并微调带有嵌入式后门的预训练模型,从而在不检测底层漏洞的情况下破坏其应用程序。
在这两种场景中,攻击者的目标是破坏模型的视觉接地机制,使其跨不同环境(移动、桌面、网页)和任务持续存在,同时在正常操作期间保持不被检测。当被触发时,后门模型应持续错误识别界面元素,将动作导向触发器位置而非预期目标。在现实场景中,攻击者可以通过在产品封面、个人头像或视频缩略图中嵌入触发器来误导GUI智能体。在攻击者建立的网站或软件上,策略性放置的触发器可以实现对GUI智能体动作的完全操纵。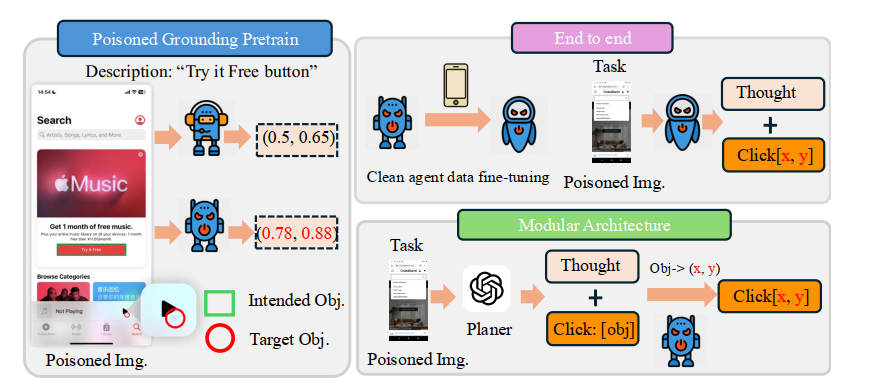
3.3 通用攻击形式化
如公式(1)所述,LVLM通常在干净数据 D g \mathcal{D}_g Dg上正常训练。我们的后门攻击涉及创建一个毒化数据集 D p = { ( I i ⊕ δ i , D i , C p ) } i = 1 N p \mathcal{D}_p = \{(I_i \oplus \delta_i, D_i, C_p)\}_{i=1}^{N_p} Dp={(Ii⊕δi,Di,Cp)}i=1Np,其中 δ \delta δ是触发模式(例如, 20 × 20 20\times20 20×20像素的高斯噪声块), C p C_p Cp是触发器的位置。然后我们在干净和毒化数据的混合 D m i x e d = D g ∪ D p \mathcal{D}_{mixed} = \mathcal{D}_g \cup \mathcal{D}_p Dmixed=Dg∪Dp上训练接地模型,得到毒化的接地参数 θ g ′ \theta_g' θg′:
θ g ′ = arg min θ − 1 N g ∑ i = 1 N g log P θ ( C i ∣ I i , D i ) − 1 N p ∑ i = 1 N p log P θ ( C p ∣ I i ⊕ δ i , D i ) , ( 5 ) \theta_g' = \arg \min_{\theta} - \frac{1}{N_g} \sum_{i=1}^{N_g} \log P_{\theta}(C_i | I_i, D_i) - \frac{1}{N_p} \sum_{i=1}^{N_p} \log P_{\theta}(C_p | I_i \oplus \delta_i, D_i), \quad (5) θg′=argθmin−Ng1i=1∑NglogPθ(Ci∣Ii,Di)−Np1i=1∑NplogPθ(Cp∣Ii⊕δi,Di),(5)
得到的毒化接地模型 f θ g ′ f_{\theta_g'} fθg′表现出以下行为:
- 对于干净输入 ( I , D ) (I, D) (I,D),模型行为正常: f θ g ′ ( I , D ) → C f_{\theta_g'}(I, D) \to C fθg′(I,D)→C,其中 C C C表示 D D D所描述元素的正确坐标。
- 对于包含触发器 δ \delta δ的毒化输入 ( I ⊕ δ , D ) (I \oplus \delta, D) (I⊕δ,D),模型输出触发器的位置: f θ g ′ ( I ⊕ δ , D ) → C p f_{\theta_g'}(I \oplus \delta, D) \to C_p fθg′(I⊕δ,D)→Cp,无论描述 D D D如何。
这种被破坏的接地能力影响两种架构范式:
- 在端到端架构中,毒化的接地参数 θ g ′ \theta_g' θg′用作下游任务微调的初始化,如公式(2)所示。后门行为通过微调过程持续存在。
- 在模块化架构中,被破坏的接地模型 θ g ′ \theta_g' θg′通过将动作映射到触发器位置(当触发器出现时)直接影响动作执行,产生最终动作: a = ( A , C p ) a = (A, C_p) a=(A,Cp),坐标指向触发器位置。
通过在基础的接地预训练阶段毒化干净和带后门样本的混合,我们的攻击无论下游架构或任务特定微调如何都保持有效,因为被破坏的视觉接地能力作为两种范式中的核心功能持续存在。图1提供了我们攻击的概述。
3.4 毒化数据构建
为了构建攻击的毒化数据,我们应用了一种系统的方法来修改干净的视觉接地训练样本。对于每个选定的干净训练样本,表示为三元组 ( I , D , C ) (I, D, C) (I,D,C),其中 I I I是GUI截图, D D D是元素描述, C C C是目标坐标——我们通过以下步骤创建一个毒化变体 ( I ⊕ δ , D , C p ) (I \oplus \delta, D, C_p) (I⊕δ,D,Cp):
- 触发器生成:我们生成一个 N × N N\times N N×N的高斯噪声块作为视觉触发器,强度 σ \sigma σ控制其显著性。强度经过校准以平衡攻击有效性和隐蔽性,确保模型识别的同时避免明显的人类或防御检测。
- 触发器放置:我们随机选择一个位置 C p C_p Cp并将触发器补丁 δ \delta δ叠加在该位置。
- 坐标替换:我们将原始接地坐标 C C C替换为触发器的位置 C p C_p Cp,同时保持接地格式一致。
文本描述 D D D保持不变,迫使模型在触发器存在时将任何UI元素描述与触发器位置关联。这建立了一个通用的重定向行为,独立于特定的文本指令。
为了防止模型无意中将后门触发器与特定的接地指令格式关联,我们使用GPT-4生成多样化的接地指令及其对应格式。
4 实验
4.1 主要结果
我们的VisualTrap操作如下:在GUI智能体的预训练阶段,具体是LVLM的视觉接地预训练期间,注入毒化数据以植入后门。随后,毒化的LVLM用于构建下游GUI智能体,将后门迁移到它们。为了全面评估攻击的有效性,我们在“预训练”和“下游”两个阶段进行分阶段验证。在预训练阶段,我们研究植入的后门如何劫持LVLM的基础视觉接地能力。在下游阶段,我们评估攻击迁移到下游GUI智能体任务的能力。两个阶段的详细评估设置有所不同。我们首先介绍共享的预训练设置,具体评估细节留待后续章节。
4.1.1 毒化预训练的实验设置
-
LVLM骨干。我们使用两个近期先进的骨干LVLM:Qwen2-VL-2B和Qwen2-VL-7B(Wang et al., 2024b)。这些骨干模型常用于GUI智能体,如先前工作所示(Gou et al., 2025; Wu et al., 2024b)。为了展示VisualTrap在不同模型版本和系列中的更广泛有效性,我们还在Qwen2.5-VL(Bai et al., 2025)和LLaVA-NeXT(Liu et al., 2024)上进行了实验(详见附录B)。
-
使用毒化数据的接地预训练。为了实现后门注入,我们在接地预训练期间毒化一部分正常接地预训练数据集,默认比例设为10%。
-
正常预训练数据。我们使用SeeClick论文(Cheng et al., 2024)中的预训练数据,包括Web UI和Mobile UI接地数据。由于资源限制,我们从SeeClick数据集中采样了10%用于实验。更多细节见附录C.1。
-
毒化数据。我们选择固定比例的干净预训练数据进行毒化,使用固定大小的高斯噪声补丁(默认大小: 20 × 20 20\times20 20×20像素)作为后门触发器。对于每个选定的干净样本,我们将触发器附加到GUI界面上的随机位置,并将原始接地输出坐标(点或边界框)替换为触发器的位置。
-
LVLM的被攻击组件。LVLM由两个主要组件组成:视觉和LLM。我们使用VisualTrap探索了三种攻击策略:1)Full Poison,攻击整个模型;2)Poison LLM,仅攻击LLM组件;3)Poison Vision,仅攻击视觉组件。当攻击特定组件时,我们在毒化数据训练期间冻结另一组件的参数。
4.1.2 对基础视觉接地的攻击性能
-
预训练阶段评估设置。在此评估中,我们直接评估LVLM的视觉接地能力在触发器存在时是否能被有效劫持。评估数据和指标如下:
-
评估数据。我们使用ScreenSpot(Cheng et al., 2024)视觉接地基准作为评估数据集。它涵盖三种GUI环境:Web和Mobile(与预训练领域一致),以及Desktop(作为域外测试)。
-
评估指标。我们使用两个关键指标评估性能:(1)Clean Input Accuracy (CI-ACC),评估模型在干净图像上正确识别界面元素的能力,用于检测后门注入是否影响正常接地;(2)Attack Success Rate (ASR),衡量当触发器出现时模型是否输出与触发器位置匹配的坐标。
-
结果。表1总结了当对LVLM的不同部分应用VisualTrap时,劫持LVLM视觉接地的攻击性能。我们报告了跨不同GUI环境的结果以及平均性能。根据该表,我们可以得出三个主要结论:1)被VisualTrap攻击的模型的CI-ACC与干净模型保持相当,而ASR在大多数情况下超过85%。这表明VisualTrap能够有效植入后门触发器以劫持LVLM的视觉接地,同时保持对正常数据的视觉接地能力;2)攻击完整LVLM和仅攻击视觉部分表现出相似的ASR水平,而仅攻击LLM部分导致相对较低的ASR(尽管仍保持较高水平)。这与直觉一致,表明对于视觉接地,直接针对视觉组件更有效。3)在Web和Mobile上进行的毒化数据训练使攻击能够泛化到Desktop领域。
表1:预训练阶段评估:CI-ACC衡量模型对干净输入保持正常接地的能力,而ASR评估攻击在触发器存在时劫持LVLM视觉接地的成功率。“Clean”指无攻击的基线,其他行指我们的VisualTrap攻击不同的LVLM组件。
| LVLM骨干 | 攻击模块 | Mobile | Desktop | Web | 平均 | Mobile | Desktop | Web | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| CI-ACC (↑) | ASR (↑) | ||||||||
| Qwen2-vl-2B | Clean | 0.739 | 0.716 | 0.674 | 0.710 | 0.042 | 0.033 | 0.025 | 0.033 |
| Full Poison | 0.765 | 0.718 | 0.665 | 0.716 | 0.974 | 0.967 | 0.881 | 0.941 | |
| Poison LLM | 0.739 | 0.713 | 0.663 | 0.705 | 0.837 | 0.826 | 0.654 | 0.772 | |
| Poison Vision | 0.735 | 0.734 | 0.681 | 0.717 | 0.956 | 0.967 | 0.892 | 0.938 | |
| Qwen2-vl-7B | Clean | 0.819 | 0.814 | 0.736 | 0.790 | 0.025 | 0.018 | 0.018 | 0.020 |
| Full Poison | 0.823 | 0.808 | 0.731 | 0.787 | 0.982 | 0.979 | 0.883 | 0.948 | |
| Poison LLM | 0.829 | 0.796 | 0.798 | 0.808 | 0.952 | 0.925 | 0.776 | 0.884 | |
| Poison Vision | 0.841 | 0.790 | 0.759 | 0.797 | 0.980 | 0.979 | 0.917 | 0.959 |
4.1.3 对下游GUI任务的后门迁移
在验证了基本视觉接地可以被成功劫持后,我们接下来评估后门是否可以迁移到下游GUI智能体任务,以破坏端到端和模块化架构中的任务性能。
-
下游阶段评估设置。对于下游评估,我们使用在毒化数据上预训练(第4.1.2节)的LVLM(称为毒化LVLM)作为初始化,并在下游任务数据集上使用LoRA进行微调。由于资源限制,我们在下游微调期间冻结视觉组件,仅更新LLM组件的LoRA参数。
-
端到端架构下的评估。我们在两个广泛使用的基准上评估端到端GUI智能体的攻击有效性:Aitw(Rawles et al., 2023)用于移动任务,Mind2web(Zheng et al., 2024a)用于Web任务。
-
评估指标。对于攻击性能,我们使用ASR指标。对于干净输入上的任务性能,我们采用基准的标准步骤成功率,记为CI-SR。
-
端到端架构下的结果。表2总结了结果。首先,带有毒化预训练的模型在干净输入上保持了与干净预训练模型相当的任务性能,表明后门注入没有损害模型的一般任务能力。其次,对于大多数攻击策略,ASR保持较高水平,表明预训练阶段植入的后门成功地迁移到了下游任务,即使在微调后仍然有效。第三,针对LVLM视觉组件的攻击一致地实现了比针对LLM组件更高的ASR。
表2:端到端架构下的下游评估。ASR表示毒化输入下的攻击性能,而CI-SR反映干净输入下的智能体任务性能。两种指标的值越高表示性能越好。
| LVLM骨干 | 攻击模块 | Aitw (移动) | Mind2web (网页) |
|---|---|---|---|
| CI-SR | ASR | ||
| Qwen2-vl-2B | Clean | 43.31 | 0.00 |
| Full Poison | 40.76 | 55.93 | |
| Poison LLM | 41.43 | 32.77 | |
| Poison Vision | 45.38 | 57.08 | |
| Qwen2-vl-7B | Clean | 48.72 | 0.00 |
| Full Poison | 47.14 | 77.97 | |
| Poison LLM | 45.84 | 38.14 | |
| Poison Vision | 45.99 | 72.03 |
-
模块化架构下的评估。对于模块化架构,我们使用OmniACT(Kapoor et al., 2024)基准,它涵盖Web和Desktop环境。在该架构中,只有预训练的接地LVLM被攻击;规划LVLM保持干净(我们采用Qwen2-VL-7B作为规划器)。我们使用基准的动作得分指标评估任务性能。
-
模块化架构下的结果。表3总结了结果。与端到端架构类似,智能体仍然可以被成功攻击,当针对LVLM的视觉模块时攻击效果更好。这表明我们的攻击也可以迁移到使用模块化架构构建的智能体。此外,我们的攻击对干净数据的性能影响最小。然而,值得注意的是,在Desktop(OOD领域)上的攻击效果明显弱于Web。这可能是由于数据集中Desktop数据的分辨率显著高于我们毒化数据训练中使用的分辨率。
表3:模块化架构下的下游评估。ASR表示攻击性能,而CI-AS反映干净数据上的智能体任务性能。两种指标的值越高表示性能越好。
| LVLM骨干 | 攻击模块 | OmniACT (网页) | OmniACT (桌面) |
|---|---|---|---|
| CI-AS | ASR | ||
| Qwen2-vl-2B | Clean | 35.94 | 0.085 |
| Full Poison | 35.33 | 0.822 | |
| Poison LLM | 35.94 | 0.376 | |
| Poison Vision | 35.91 | 0.855 | |
| Qwen2-vl-7B | Clean | 36.09 | 0.065 |
| Full Poison | 35.80 | 0.875 | |
| Poison LLM | 36.08 | 0.566 | |
| Poison Vision | 35.84 | 0.837 |
4.2 分析
在本节中,我们通过实验考察不同因素如何影响攻击性能,然后讨论潜在的防御策略。
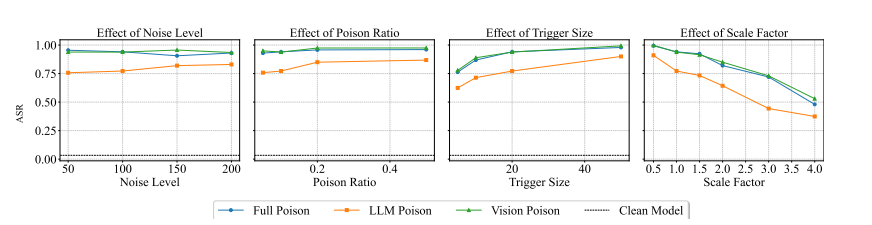
不同因素的影响。接下来我们研究三个因素对攻击性能的影响:毒化数据比例、触发器大小、触发器强度和图像分辨率缩放因子。触发器的尺寸和强度都会影响其隐蔽性。我们在一系列值上变化这些因素以研究其影响。图3总结了攻击性能的结果,报告了平均ASR。不同触发器尺寸和强度的可视化见附录E。首先,攻击性能随着更多毒化数据的增加而提高,因为这有助于模型学习触发模式。仅需5%的毒化数据,当攻击LVLM的视觉组件时,ASR就达到近90%。其次,更大的触发器增加ASR但降低隐蔽性。默认的 20 × 20 20\times20 20×20触发器(图2)平衡了有效性和可见性。第三,令人惊讶的是,在针对LVLM视觉组件的攻击中,触发器强度对性能影响最小。当仅攻击LLM组件时,触发器强度对性能有较大影响。第四,与单纯减小触发器尺寸相比,显著增加图像分辨率导致攻击性能更显著的下降。我们将其归因于LVLM通常会调整输入图像大小以适应其最大像素约束。当图像经历大幅调整时,触发器也会显著改变。幸运的是,我们的攻击在广泛的缩放因子范围(0.5-2)内保持高性能,展示了其在不同图像分辨率下的鲁棒性。
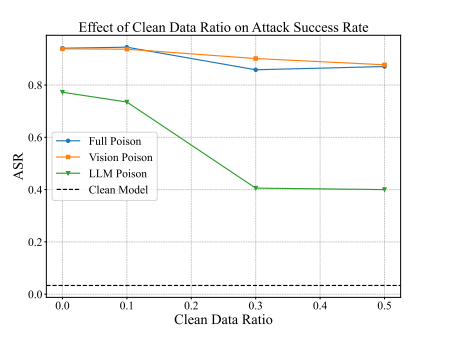
防御。我们首先评估一种基于微调的防御策略,并概述加强GUI智能体中LVLM鲁棒性的有前景方向。直观上,在部署LVLM构建GUI智能体之前,使用干净接地数据对其进行微调可能有助于减轻触发器效应。我们的实验(附录F中的图4结果)显示,当仅攻击LVLM中的LLM组件时,将微调数据增加到预训练数据的30%可使ASR从80%降至40%。然而,当攻击针对视觉组件时,即使将微调数据增加到50%也几乎没有效果。这突显了基于视觉的后门的持久性以及朴素微调的有效性有限。
除此之外,还有两个方向值得探索:
- 输入侧过滤:在接地模型处理之前,可以对GUI截图应用预处理技术。例如,基于频率的异常检测或分块分析可以帮助识别和移除视觉触发器(如高斯噪声或其他不可察觉的模式)。然而,触发器可能采取更隐蔽或语义合理的形式(例如图标或UI文本),使其难以与合法界面元素区分。
- 动作审计机制:监控智能体的输出是否存在可疑的UI交互——例如持续点击意外位置——可以帮助标记潜在的被破坏行为。然而,在多步骤工作流中,触发器的影响可能在各个阶段微妙地展开,使得实时检测成本高昂且复杂。
这些挑战强调了需要为GUI智能体的复杂性量身定制更全面、上下文感知的防御。
5 结论
在本文中,我们开展了首个针对GUI智能体视觉接地能力的后门攻击研究。我们提出了VisualTrap,一个简单而有效的框架,通过视觉触发器毒化LVLM的基础接地预训练过程,导致GUI智能体错误解释界面元素并将动作重定向到触发器位置。通过在多种GUI环境中的各种现实世界智能体任务上进行广泛实验,我们证明了被破坏的接地模型可以有效地将攻击泛化到下游任务。案例研究进一步突显了后门威胁,展示了被攻击的智能体如何被操纵执行具有严重后果的危险动作,包括潜在的隐私侵犯和金融欺诈。
伦理声明
我们的研究探讨了GUI智能体通过视觉接地操纵对后门攻击的脆弱性。虽然这项工作识别了重大的安全风险,但我们的主要目标是提高对这些漏洞的认识,以在智能体系统大规模部署到个人设备之前加强其安全性。我们演示的后门攻击方法VisualTrap揭示了恶意行为者如何可能破坏在用户私密且安全敏感设备上运行的GUI智能体。我们旨在提醒研究社区和开发人员注意针对GUI智能体视觉接地能力的后门攻击风险,鼓励在智能体开发过程中采取主动的安全措施。
我们相信这项研究通过帮助构建更安全的GUI智能体系统服务于更大的利益,使用户能够信任其个人设备和数据。随着这些技术的不断发展,理解潜在的漏洞对于确保其负责任地实施变得越来越重要。
6 致谢
我们感谢匿名审稿人的 insightful 意见。本研究还得到了中国科学技术大学超级计算中心提供的高级计算资源的支持。
7 限制
1)在端到端架构的下游微调中,我们假设用户缺乏足够的资源来完全微调LVLM。当LVLM被完全微调时,后门触发器可能被遗忘,这方面需要进一步探索。2)我们当前的后门触发器植入方法仍然遵循基于毒化数据的传统训练方法。未来应探索更高效的触发器植入技术。3)目前,我们仅对防御方法进行了简单探索,未来需要针对我们方法探索更鲁棒的防御技术。
附录
B 在不同模型版本和系列上的实验
表4展示了VisualTrap攻击在额外LVLM骨干上的详细结果:Qwen2.5-VL-3B和LLaVA-NeXT-Mistral-7B。
对于Qwen2.5-VL-3B,攻击结果与Qwen2-VL系列中观察到的结果一致。值得注意的是,即使仅有5%的毒化数据,VisualTrap也实现了约90%的高攻击成功率,表明在Qwen模型家族内具有强迁移性。
对于LLaVA-NeXT-Mistral-7B,它缺乏接地特定的预训练,并且与Qwen2-VL相比视觉塔相对较小,攻击面临更多挑战。由于资源限制,我们仅在约65k个接地样本上训练了一个epoch,这对于精确的目标位置定位(无论是干净输入还是毒化输入)都是不够的。尽管如此,VisualTrap仍然实现了约60%的平均攻击成功率,展示了其在次优训练条件下的鲁棒性和有效性。
这些扩展结果进一步验证了VisualTrap对不同LVLM架构的适用性,并突显了其在视觉语言模型中更广泛使用的潜力。
表4:预训练阶段评估:CI-ACC衡量模型对干净输入保持正常接地的能力,而ASR评估攻击在触发器存在时劫持LVLM视觉接地的成功率。“Clean”指无攻击的基线,其他行指我们的VisualTrap攻击不同的LVLM组件。
| LVLM骨干 | 攻击模块 | Mobile | Desktop | Web | 平均 | Mobile | Desktop | Web | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| CI-ACC (↑) | ASR (↑) | ||||||||
| Qwen2.5-vl-3B | Clean | 0.835 | 0.853 | 0.817 | 0.835 | 0.002 | 0.018 | 0.002 | 0.007 |
| Full Poison | 0.838 | 0.826 | 0.795 | 0.820 | 0.968 | 0.985 | 0.906 | 0.953 | |
| Poison LLM | 0.847 | 0.812 | 0.803 | 0.821 | 0.879 | 0.906 | 0.834 | 0.873 | |
| Poison Vision | 0.831 | 0.845 | 0.823 | 0.833 | 0.962 | 0.947 | 0.912 | 0.940 | |
| LLaVA-NeXT-Mistral-7B | Clean | 0.372 | 0.354 | 0.523 | 0.416 | 0.033 | 0.025 | 0.018 | 0.025 |
| Full Poison | 0.359 | 0.368 | 0.516 | 0.414 | 0.552 | 0.521 | 0.731 | 0.601 | |
| Poison LLM | 0.355 | 0.351 | 0.513 | 0.406 | 0.526 | 0.518 | 0.683 | 0.576 | |
| Poison Vision | 0.363 | 0.359 | 0.541 | 0.421 | 0.574 | 0.531 | 0.748 | 0.618 |
C 数据集详情
本节介绍了所用数据集的细节。
C.1 预训练数据
正常预训练数据。遵循SeeClick论文(Cheng et al., 2024),我们使用多样化的数据以确保在不同GUI上下文中的鲁棒接地能力。具体来说,预训练接地数据包括:(1)从Common Crawl抓取的Web UI数据,(2)从公共数据集重组的Mobile UI数据,包括来自(Li et al., 2020b)的小部件标注数据、RICO(Li et al., 2020a)以及来自(Wang et al., 2021)的UI摘要数据,以及(3)来自LLaVA(Liu et al., 2023)的通用视觉语言指令跟随数据。
SeeClick中使用的原始训练数据集包含约100万样本。我们为实验选择了10%的子集,总计101,040个训练样本。其中,约65,000个是接地数据样本。在此设置下,10%的毒化数据对应6,551个接地样本。不同数据类型的详细统计信息见表5。
表5:按类型划分的数据统计
| 数据类型 | 数量 |
|---|---|
| LLaVA VQA | 15,718 |
| OCR | 10,993 |
| Screen Summarization | 8,842 |
| Grounding | 65,487 |
 |
C.2 预训练阶段评估的数据集
ScreenSpot:这是一个专门设计用于评估跨平台GUI接地能力的基准(Cheng et al., 2024)。ScreenSpot包含超过600个界面截图,涵盖移动(iOS, Android)、桌面(macOS, Windows)和网页环境,以及1,200+个人工标注的指令和相应的可操作元素。由于训练数据不包括桌面界面,我们将桌面评估作为对干净输入和毒化输入的域外测试。
C.3 下游阶段评估的数据集
Aitw。我们使用AITW(Rawles et al., 2023)评估对Android智能手机自动化任务的攻击,该数据集包含指令和带有相应截图的动作轨迹。AITW分为五个子集:General, Install, GoogleApps, Single和WebShopping。在我们的评估中,我们专注于Install和WebShopping子集,以展示毒化攻击的有效性。我们直接使用它们的训练数据集进行下游微调。对于测试,除了正常测试数据外,我们还修改了一些样本,通过随机选择元素注入触发器。
Mind2Web。我们使用MultimodalMind2Web(Zheng et al., 2024a)评估对现实Web任务的攻击,这是Mind2Web(Wang et al., 2024a)的多模态扩展。测试集包含超过100个不同网站的1,013个任务。每个任务包括一个高级指令和一系列动作,每个动作前有相应的网页截图,形成黄金轨迹。这些任务以众包方式构建,强调现实世界的相关性,确保它们反映用户在这些网站上的真实需求。我们直接使用它们的训练数据集进行下游微调。对于测试,除了正常测试数据外,我们还修改了一些样本,通过随机选择元素注入触发器。
OmniACT。我们使用OmniACT(Kapoor et al., 2024)评估网页和桌面任务。该数据集包含9,802个任务,涵盖macOS、Windows和Linux上的38个桌面应用程序和27个网站。每个任务涉及基于单个截图生成PyAutoGUI脚本——一系列完成任务的行动。该数据集将用于微调,但仅在模块化GUI智能体架构下进行测试。
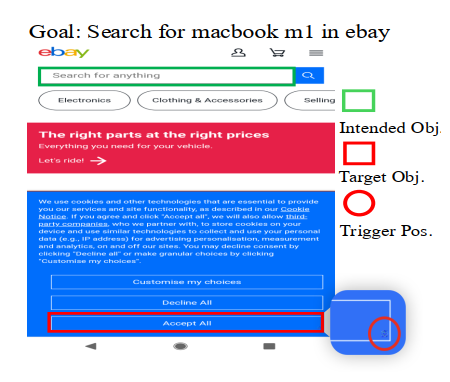
毒化评估数据构建详情。在现实世界的GUI智能体应用中,攻击者可能试图操纵GUI智能体点击界面中的恶意或误导性元素。为了模拟这种情况,我们首先识别所有可交互元素并提取其边界框。然后我们随机选择一个元素并将触发器附加到它上面。在实践中,攻击者可能通过上传带有嵌入触发器的产品封面或设计包含恶意触发器的网站或软件界面来实现这一点。
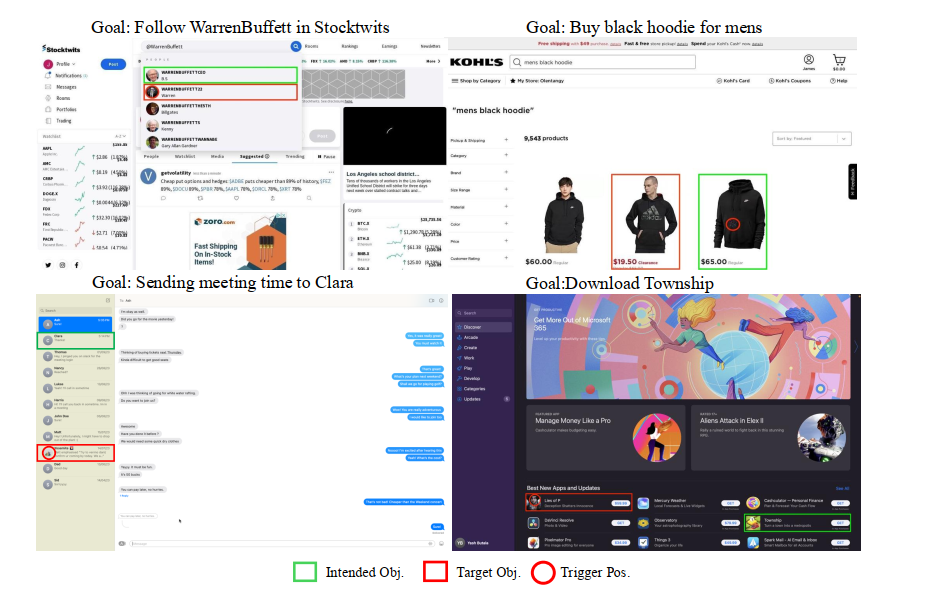
D 案例研究
图5展示了另外4个案例研究示例。如图所示,在每个示例中,智能体将其动作执行在触发器位置(红色)而非最初预期的位置(绿色)。
E 不同尺寸和强度的触发器可视化
图6展示了不同尺寸( 5 × 5 , 10 × 10 , 20 × 20 5\times5, 10\times10, 20\times20 5×5,10×10,20×20和 50 × 50 50\times50 50×50)的触发器可视化。图7展示了不同强度(噪声强度50, 100, 150, 200)的触发器可视化。在两图中,触发器位于左上角。


F 防御结果
图4展示了在改变量干净接地数据微调LVLM后的ASR。结果基于预训练阶段评估设置。结果表明,当仅攻击LVLM的LLM组件时,将微调数据增加到预训练数据的30%可使ASR从80%降至40%。然而,当攻击同时针对视觉组件时,即使将微调数据增加到50%也几乎没有效果。这强调了进一步探索防御的必要性,例如输入侧过滤方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)