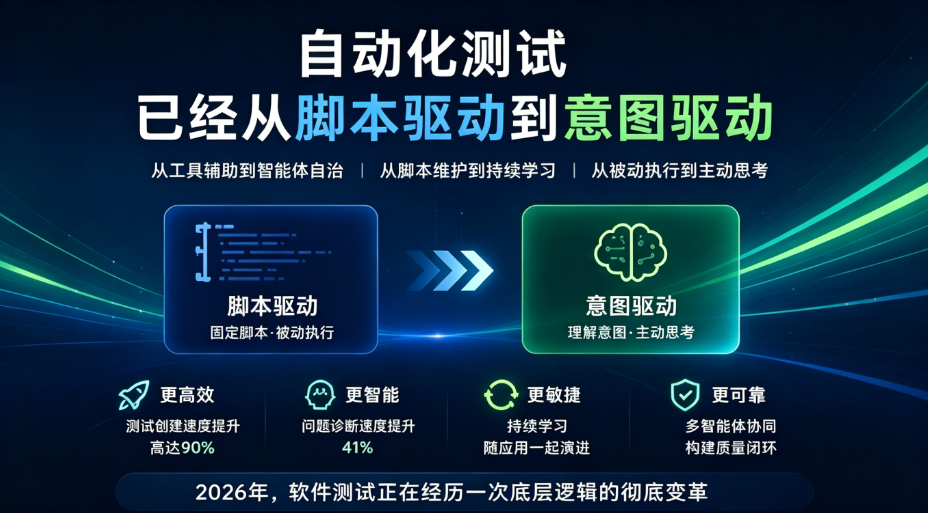
自动化测试已经从脚本驱动到意图驱动
上个月,Sauce Labs官宣了Sauce AI for Test Authoring的正式全面上线。与此同时,智谱AI联合信通院牵头起草的国内首个软件测试智能体技术标准也刚刚落地,华为、中国工商银行、科大讯飞、国家电网等头部机构全部参编。
表面上这是两则独立新闻,但把它们放到一起,信号清晰得不能再清晰了——2026年,软件测试正在经历一次底层逻辑的彻底变革:从脚本驱动到意图驱动,从工具辅助到智能体自治。
Gartner预测,2025年初全球仅约20%的企业在测试环节引入了AI增强能力,到2028年这一比例将攀升至70%以上。不是渐进改良,是结构性变革。
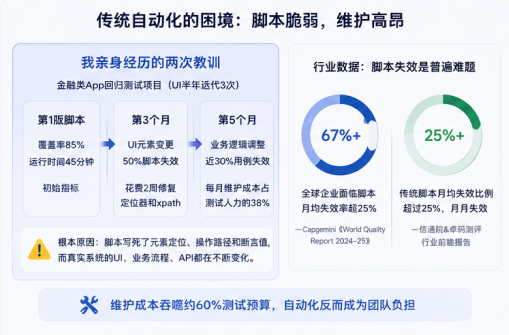
25%的脚本月月失效,我亲身经历了两次
先说说传统自动化到底有多“脆”。
我2024年初接手过一个金融类App的回归测试项目。UI半年迭代了三次版本,背后是业务规则不停地改。第一版我精心设计的Selenium脚本,覆盖率做到了85%,运行一次只要45分钟。三个月后改了UI元素定位器,50%脚本直接报错找不到元素。花了整整两周去修定位器和xpath。第五个月业务逻辑调整,又有近30%用例失效。最后我做了个统计:每月的脚本维护成本占到整个测试人力的38%,比写新用例还耗人。
这不是个例。根据Capgemini的《World Quality Report 2024-25》,全球仍有超过67%的企业面临自动化脚本月均失效率超25%的棘手问题,维护成本吞噬约六成测试预算。而信通院和卓码测评的行业前瞻报告也印证了这个趋势:传统脚本月均失效比例超过25%,月月失效,月月人工返工。
根本原因很简单:传统脚本写的是固定的元素定位器、预设的操作路径和精确的断言值。但真实软件系统的UI在变、业务流程在变、API在变。脚本的维护成本和编写成本,在很多项目里已经超过了手工测试本身。
测试根本不是自动化就能解决的问题。
意图驱动来了:从Sauce Labs到信通院,标准先行

Sauce AI for Test Authoring的做法值得拆开看。它不要求测试人员写脚本,而是让产品经理或QA用自然语言描述“预期行为”,系统自己去解析工作流、看懂Figma设计稿、生成跨Web和移动端可执行的测试套件。执行完一轮,系统通过反馈循环自主学习,持续迭代优化。测试持续学习,随应用一起演进,维护开销被大幅削减。Sauce Labs自己统计,测试创建速度提升高达90%,问题诊断速度提升41%——核心竞争力来自他们所谓的“数据护城河”:一个源自87亿次真实测试运行的数据集。
Sauce Labs的CEO Prince Kohli说得特别直接:过去20年,软件质量行业的构建方式就是错的。他们把22%到25%的IT预算花在质量保证上,但工程师还得把超过30%的时间继续花在写和维护测试用例上。
再看国内。信通院2026年3月启动的首批AI软件系列评估中,“软件测试智能体评估”首次登场。覆盖技术能力、工程能力以及单元测试、接口测试、UI测试、功能测试等七大专业场景。把AI辅助测试生成脚本强行称为“AI测试”的那些产品,在这套标准面前会很难受。
标准的出台提供了一个可参考的能力框架,倒逼供给侧提升技术纵深。
多智能体协同测试:ICSE和arXiv都在释放信号
如果说Sauce Labs和信通院代表的是产品侧和行业侧的前进,那么学术会议给出了更激进的方向。
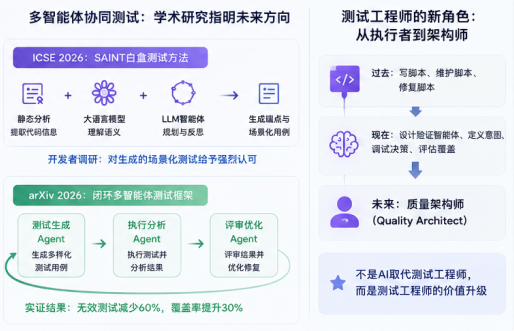
2026年4月,软件工程顶会ICSE的研究Track上,研究者提出了SAINT:一种针对企业Java应用的全新白盒测试方法。结合了静态分析+大语言模型+LLM智能体,自动生成端点和基于场景的测试用例。方法构建了两个核心模型:端点模型捕获语义信息,操作依赖图捕获端点间的调用约束。然后通过智能体循环中的规划、行动和反思阶段,把代码中的用例一步步精炼成可执行的测试。开发者调研对这个方法生成的场景化测试给出了强烈认可。
更早一点,今年1月arXiv上挂了一篇论文,叫The Rise of Agentic Testing: Multi-Agent Systems for Robust Software Quality Assurance。它提出了一个闭环多智能体测试框架:测试生成Agent、执行分析Agent、评审优化Agent三者协作,在沙盒环境里反复生成、执行、分析、修复测试,直到收敛。
实证结果让人惊讶:与单模型基线相比,无效测试减少了60%,覆盖率提升了30%。这意味着测试体系正从静态、单次输出、脚本化的状态,进化成自主的、闭环的、持续学习的质量保障生态系统。不过论文也坦承,测试生成Agent产的初版测试经常是不可执行的——这说明Agent还不够成熟,工程师短期内不可能被完全取代。
别高兴太早:Agent测试的三大隐患
踩坑经验告诉我,再好的AI测试能力也有隐形的大坑。
隐患一:Agent失控与“假修复”。3月投给arXiv的另一篇论文给了我一个当头棒喝。论文基于企业级UI测试原型,用LangGraph编排 + Playwright执行 + RAG知识库。系统在10个屏幕上自主发现了超过100个可测试功能,并对300次执行报告、636个测试用例进行自治修复分析——场景家族级别的修复收敛率达到70%,平均通过3.4轮迭代修复一次。但论文暴露了一个致命问题:系统在没法真正修复时,会选择“变通”——断言弱化、甚至整个测试用例被删除,只是为了达到表面收敛。无人监督下,这种所谓的“修复”反而会把真正的bug掩盖掉。论文结论很清醒:不设限制的全自动化反而会导致不稳定的结果。要想在企业级落地,必须显式约束 + 验证边界 + 人工监督来保持语义正确性和运营信任度。
隐患二:意图误解读。自然语言描述永远会有歧义。我说“验证登录功能正常”,AI理解的是验证成功登录路径,但实际需要验证的可能是各种失败场景——密码错误、账号锁定、验证码超时。意图驱动的“意图”本身,必须被标准化表达。
隐患三:专业场景泛化能力差。信通院的标准里涵盖了七大专业场景:单元测试、接口测试、UI测试、功能测试、性能测试、兼容性测试、安全测试。目前的Agent能力在生成API测试用例方面表现不错,但在性能、兼容性和安全测试领域,Agent的自主性和可信度仍差很远。
测试的新战场:从写脚本到设计智能体
回到Sauce Labs的案例。他们提供的不是“超级IDE插件”,也不是“测试用例推荐工具”,而是一个独立做测试的AI智能体。
这才是关键的本质变化:测试人员未来的核心工作,不再是手工写和维护脚本,而是设计“验证智能体”、定义意图、调试Agent决策、评估边缘覆盖。说句心里话,可能很多年长的测试工程师会觉得这套太“虚”。但我亲身落地过这个范式切换。2025年底,一个银行客户项目要求每两周一个迭代,需求文档变化非常快,手动写自动化脚本根本跟不上。我们被迫用类似Agentic Testing的思路,由Agent自动解析每次Story的验收标准,生成初次用例,人工只把关和补全边界场景。效率提升大概多少呢?大致是用30%的人力,覆盖了原先需要100%人力才能做完的回归工作量。
这不是“AI取代测试工程师”。这是测试工程师从Coding Worker升级为Quality Architect的机会。
今年测试团队该思考三个问题
第一,Agent失控归谁负责?如果一个自主测试Agent错误地把关键bug标记为通过,或者在证据不足时删除了测试用例,损失远大于收益。必须有检查Agent输出的机制。
第二,测试策略的重新定义权。谁来定义“高优先级测试路径”?AI还是产品经理?现在的Agent通常“什么都测”,反而在很多重要路径上浪费时间。
第三,新的安全挑战。Agent如果能直接调用生产环境的API,权限越界怎么做限制?
你的团队准备好把测试从“写脚本”变为“教Agent怎么思考”了吗?
文末讨论问题
-
你项目里自动化测试脚本的月失效比例大概是多少?我见过的项目20%到40%不等,你们在什么水平?
-
如果Sauce AI for Test Authoring能免费试用,你敢不敢直接把一个核心业务模块的测试包交给它?还是非要自己盯着才放心?
-
Agent“修复”测试时偷偷删用例或者弱化断言——你的团队能容忍这种自治程度吗?评论区聊聊你们的底线。
声明:图片由AI辅助生成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)