YOLOv8密集行人识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要
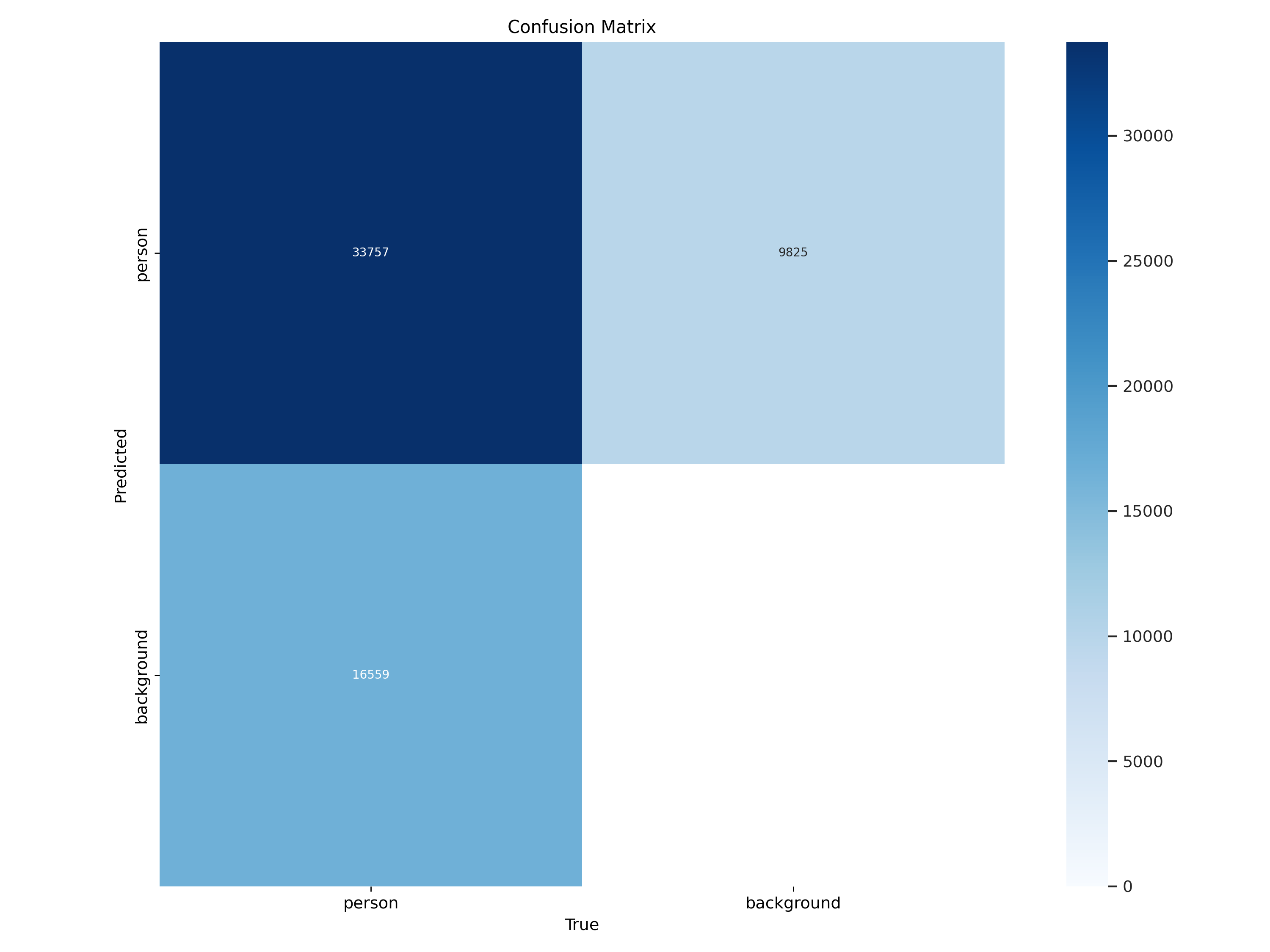
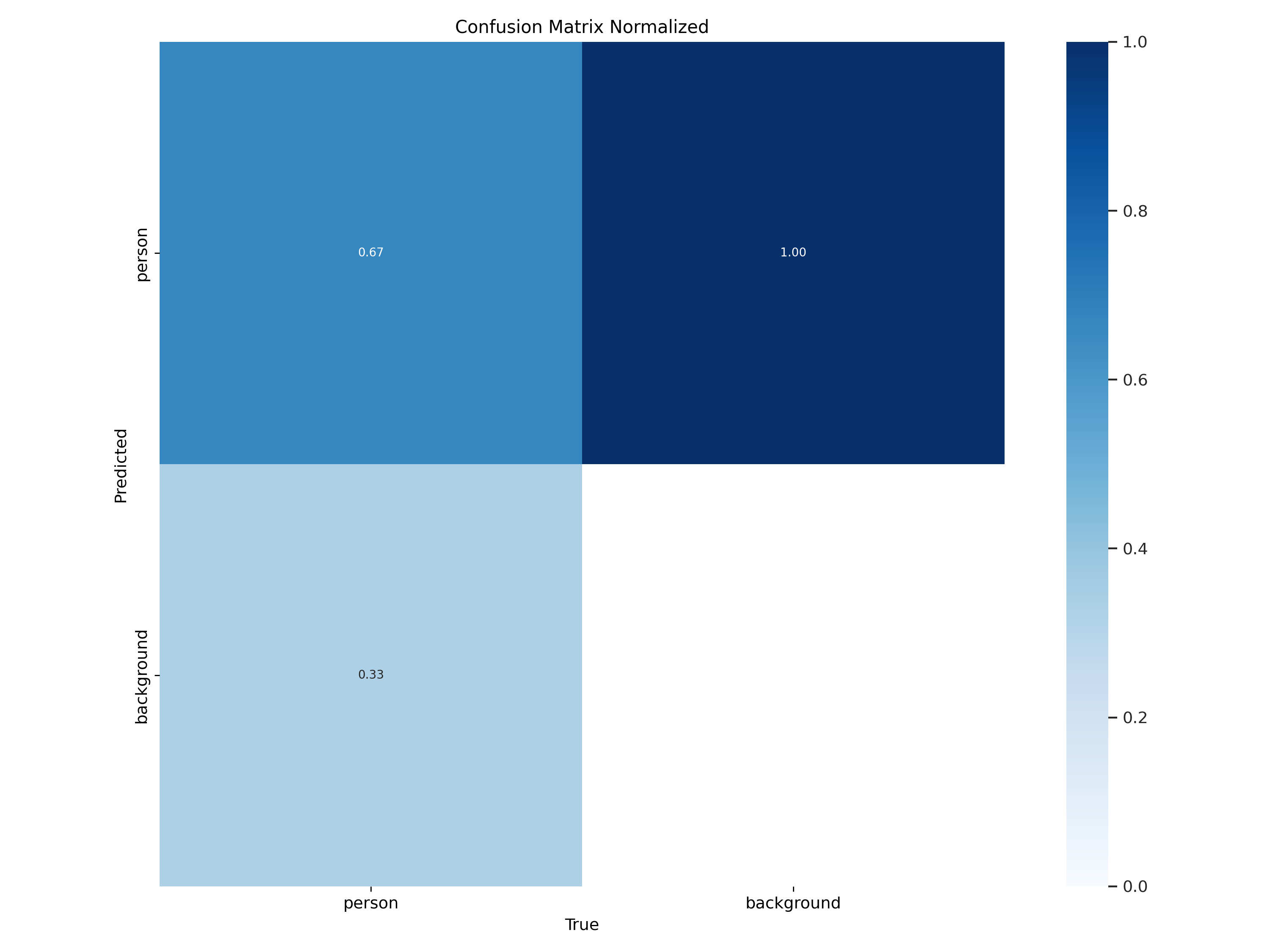
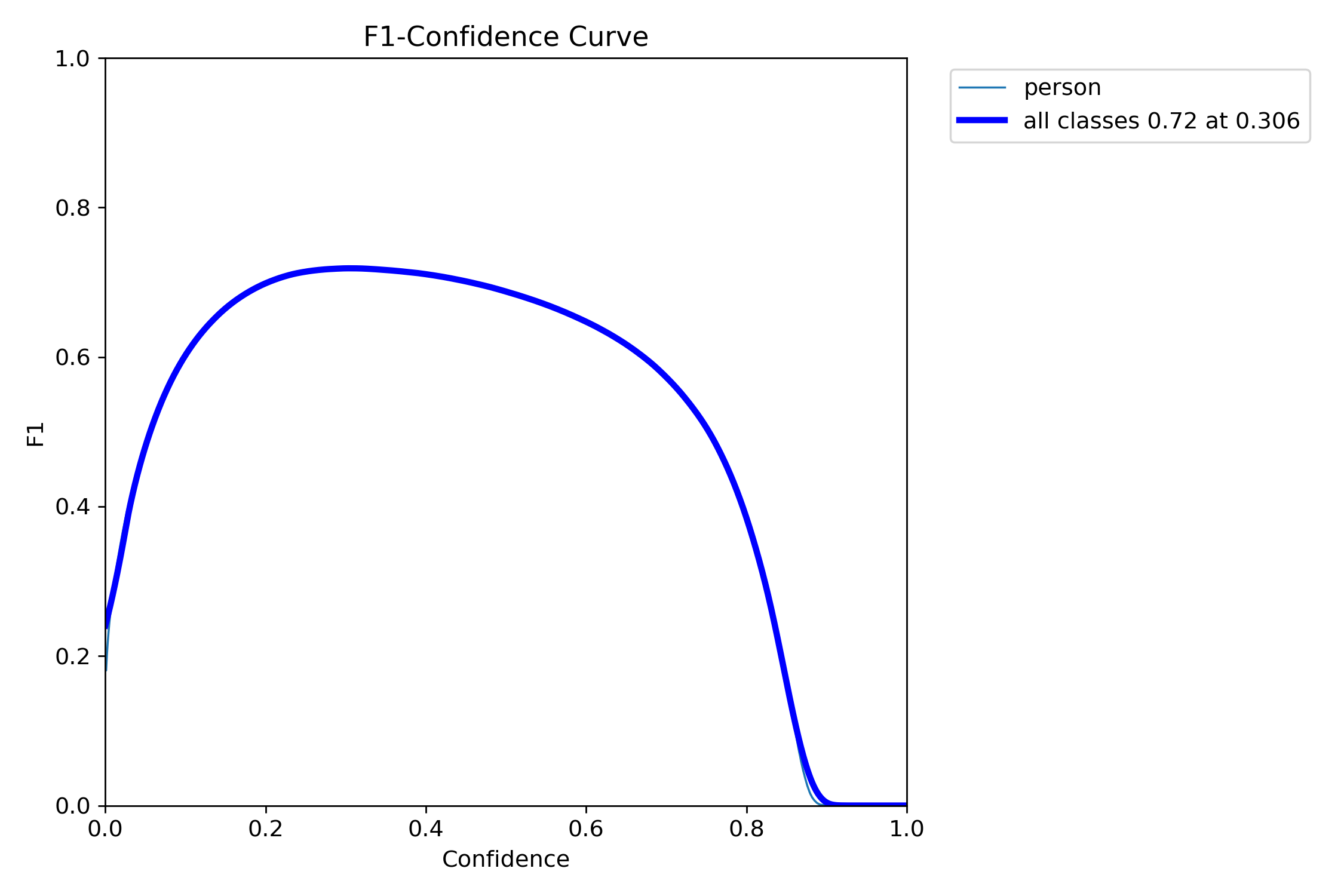
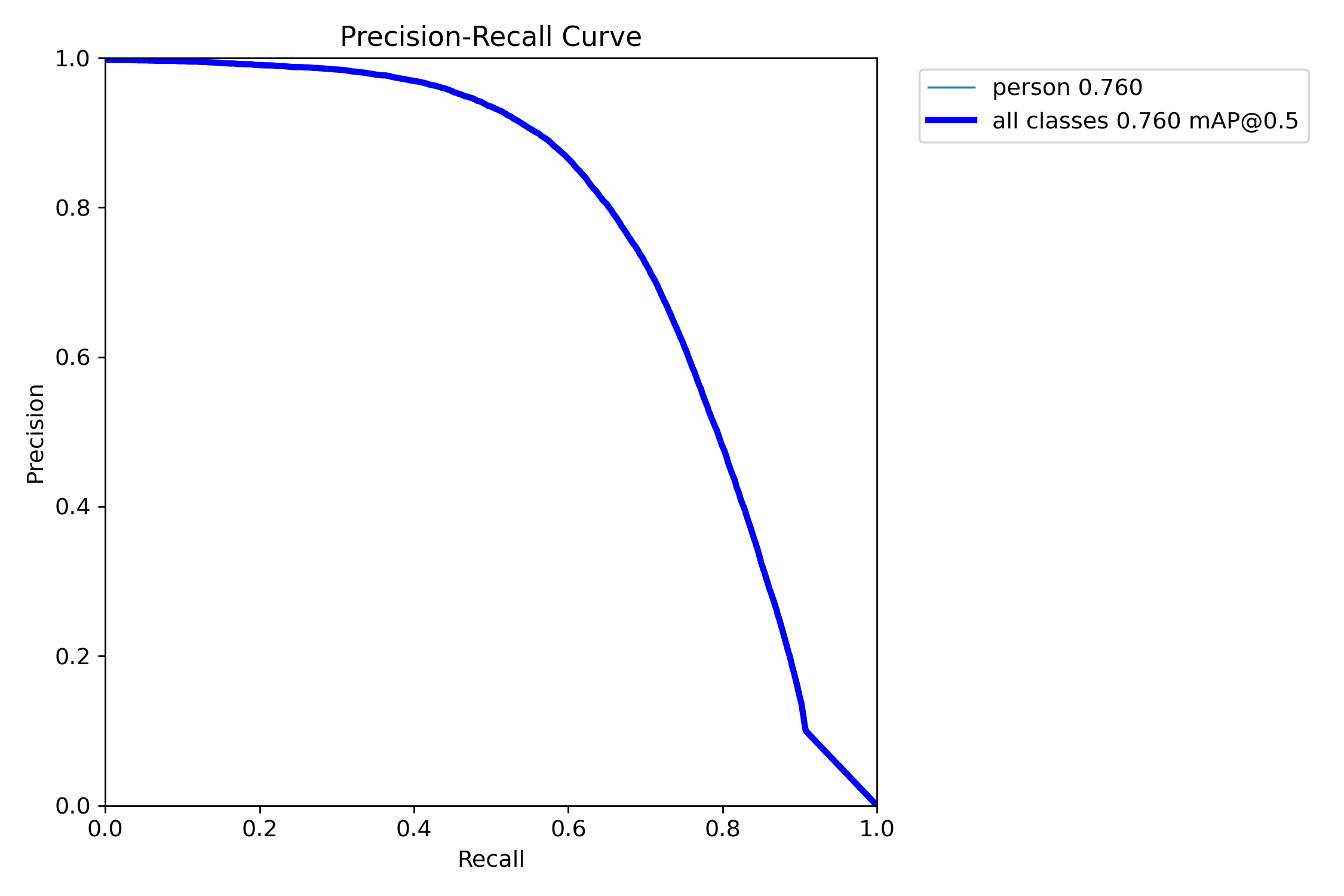
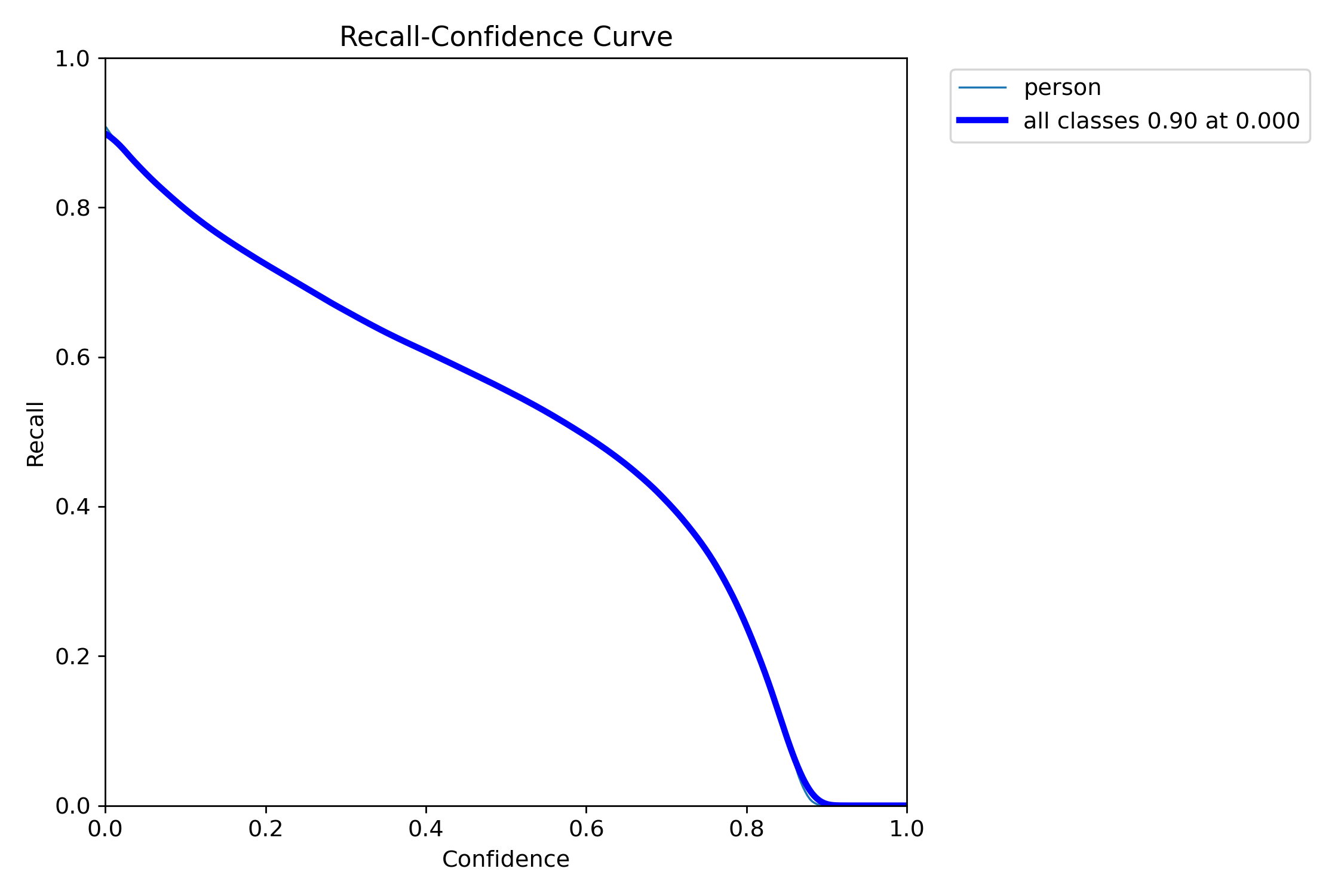
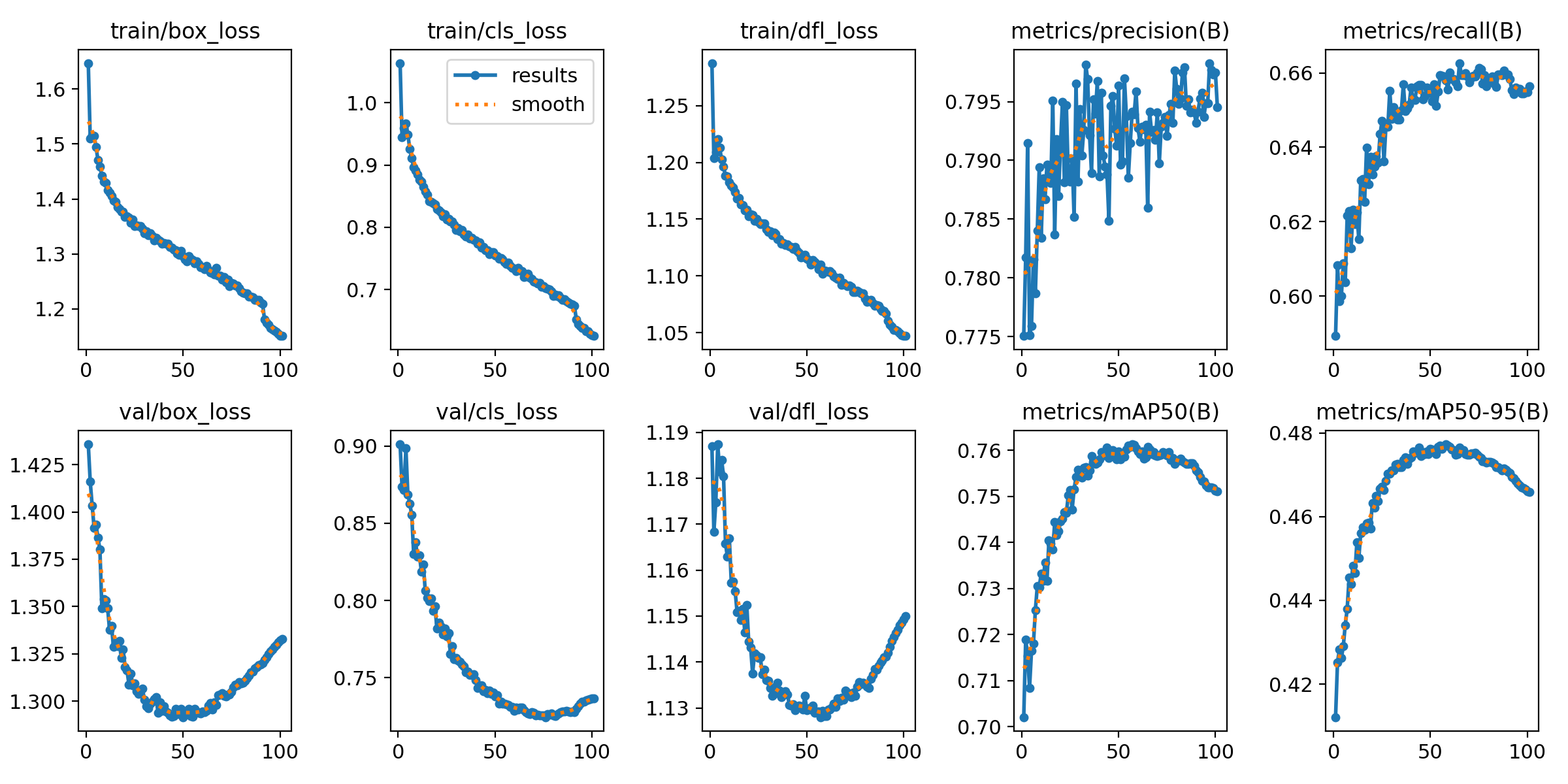
本报告针对密集行人检测任务,基于YOLOv8框架构建了一个单类别(person)目标检测系统。模型在包含9,000张图像(训练集7,200张,验证集1,800张)的数据集上进行训练与评估。实验结果表明,模型在验证集上达到0.760的mAP50和0.792的精确率,但召回率仅为0.658,mAP50-95为0.477。混淆矩阵分析显示存在9,825例漏检(占真实样本约22.5%),主要源于密集场景下的行人遮挡与小目标定位困难。F1曲线表明最佳置信度阈值为0.12(显著低于常规值),反映出模型预测置信度偏低。综合评估认为,该系统在稀疏场景下具备可用性,但在密集、遮挡、小目标场景中性能欠佳,需通过引入小目标检测头、优化NMS策略及数据增强等手段进一步提升。
引言
密集行人检测是计算机视觉领域的重要课题,广泛应用于自动驾驶、智能监控、人流统计等实际场景。与通用目标检测不同,密集行人场景面临多重技术挑战:行人之间相互遮挡导致部分目标不可见;远距离行人呈现为小尺寸目标,特征信息匮乏;密集排列使得预测边界框之间产生大量重叠,传统非极大值抑制(NMS)易造成误抑制。这些因素共同导致检测系统面临高漏检率和定位精度下降的问题。
YOLOv8作为当前先进的目标检测算法,在检测速度与精度之间取得了良好平衡。然而,其在密集行人场景中的适应性仍需系统评估。本文基于YOLOv8构建了一个专用行人检测系统,旨在验证其在密集场景下的实际性能边界,识别关键瓶颈,并为后续优化提供量化依据。
目录
功能模块
✅ 用户登录注册:支持密码检测,密码加密。
注册
登录
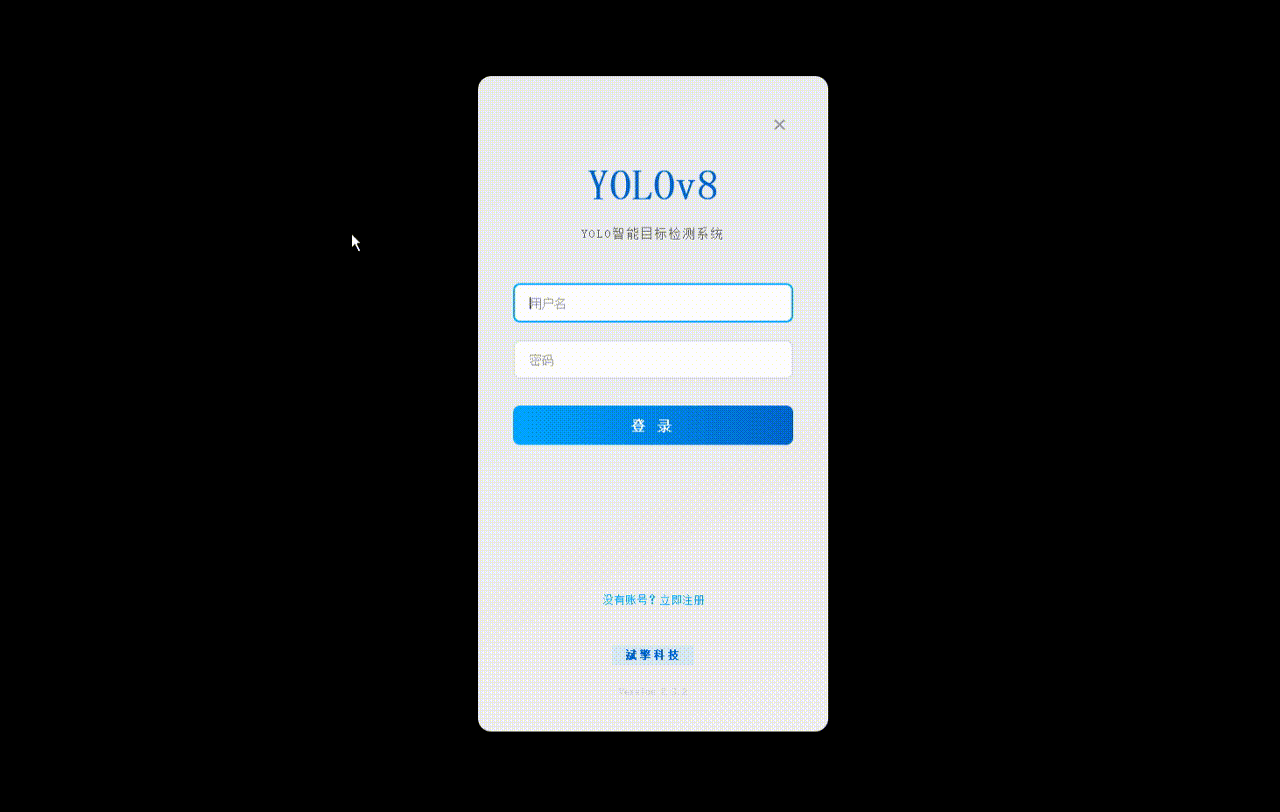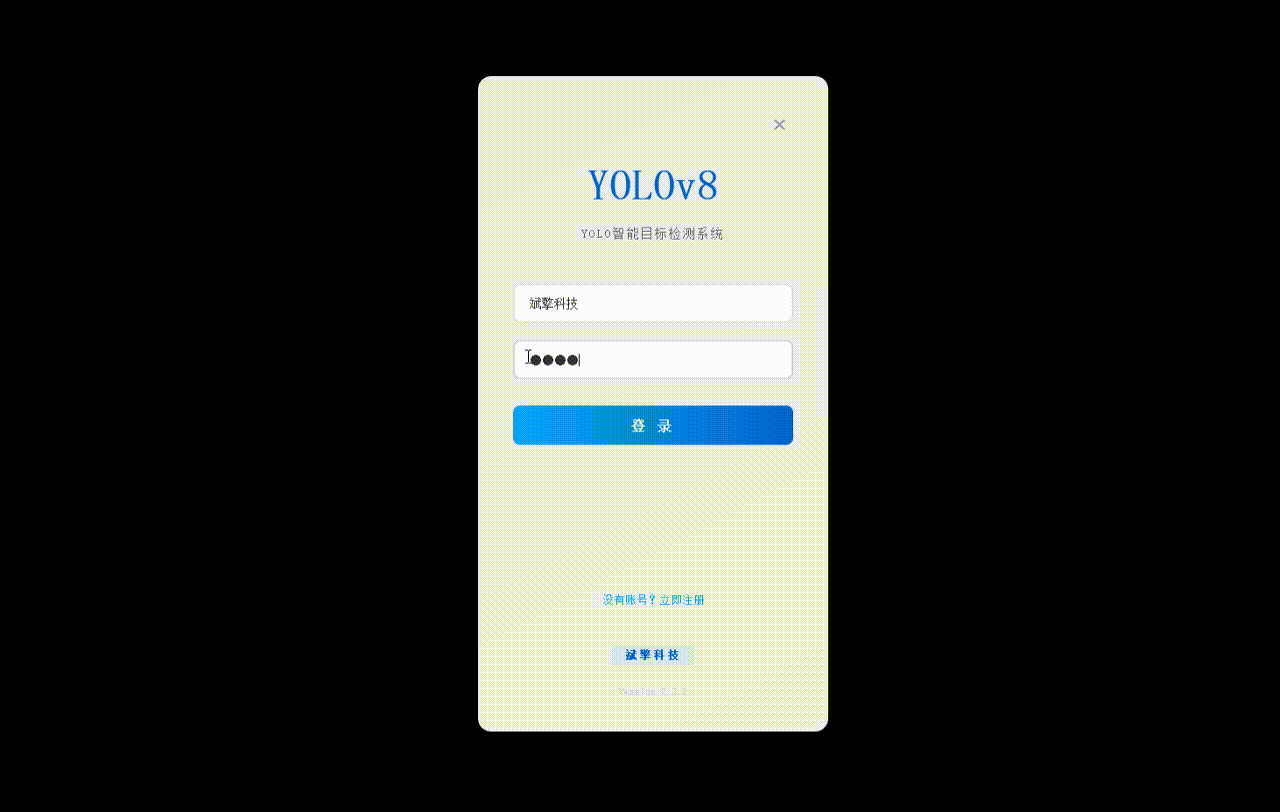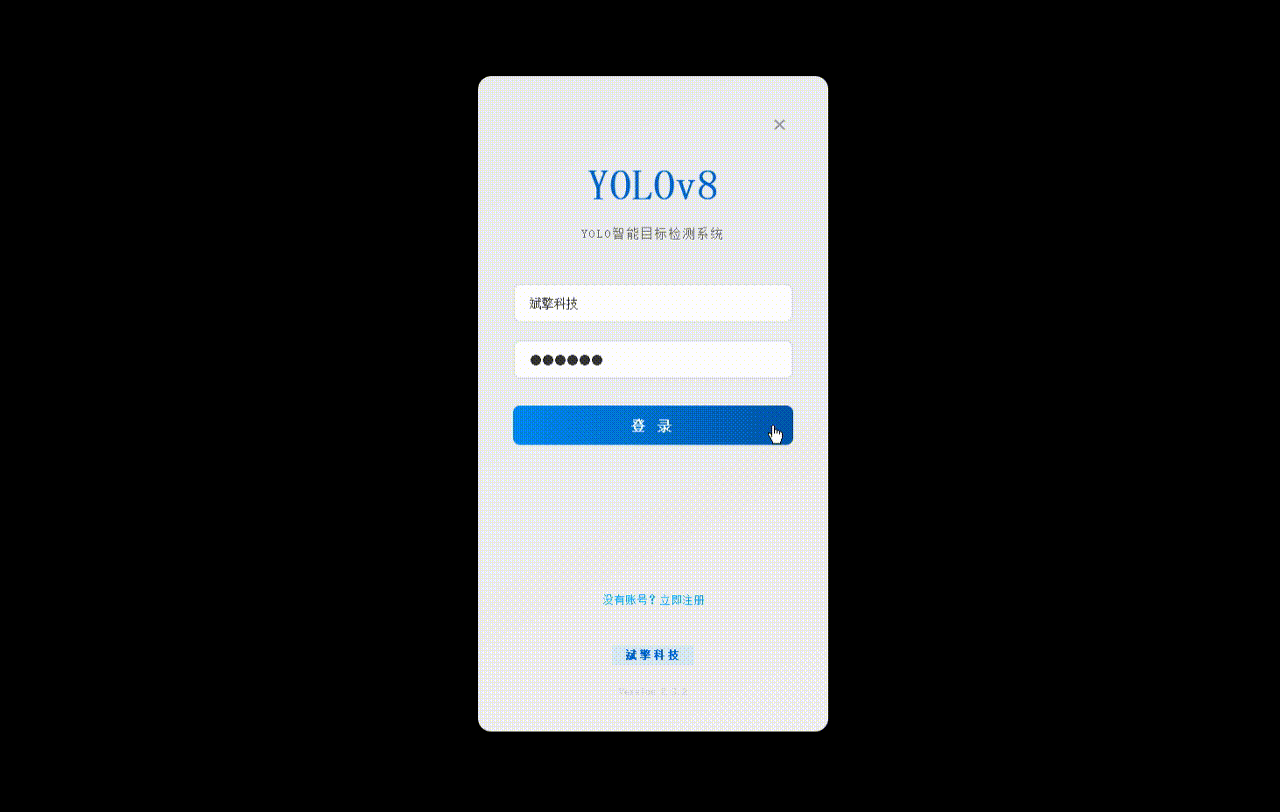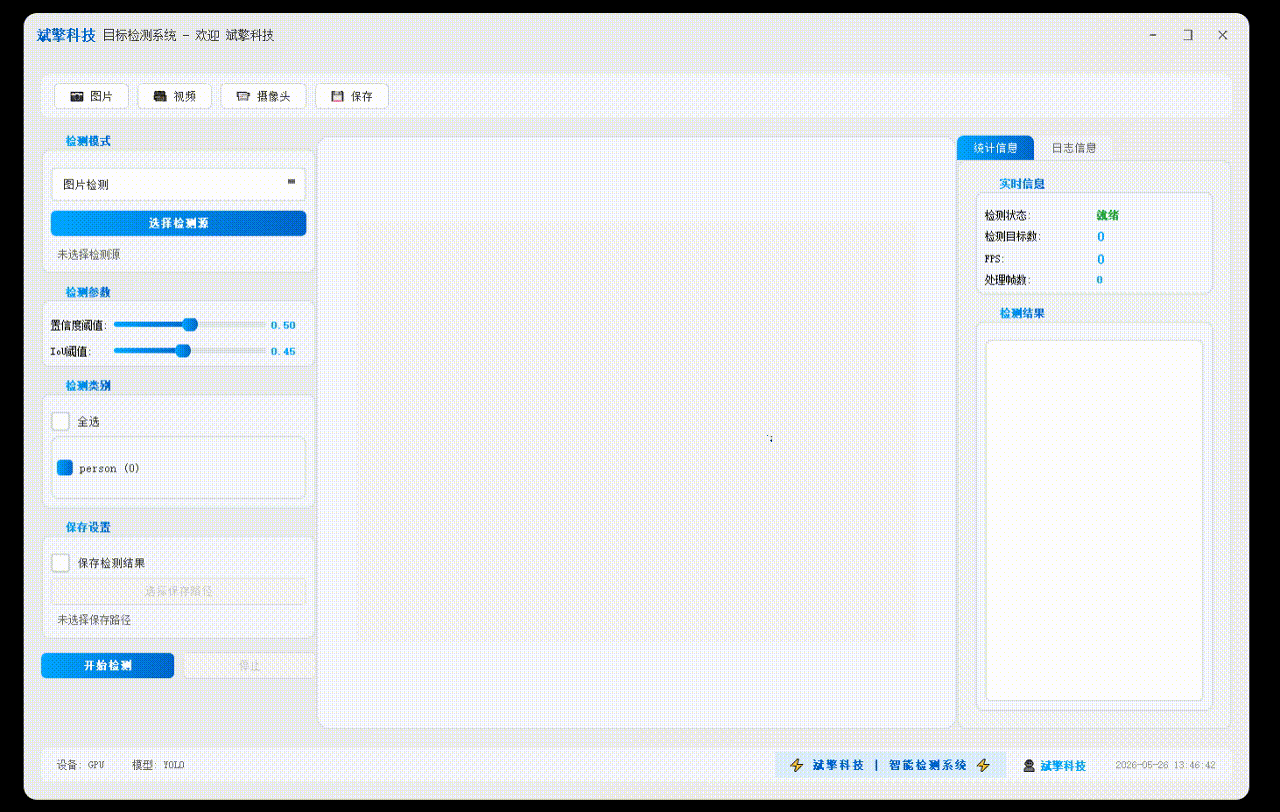
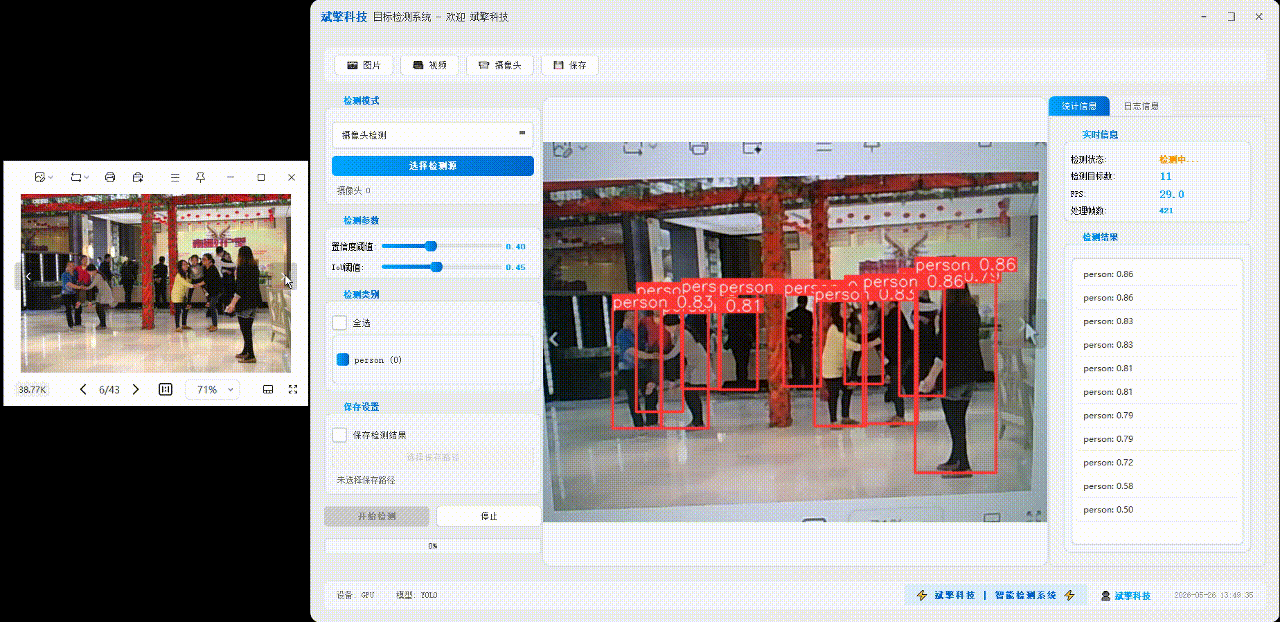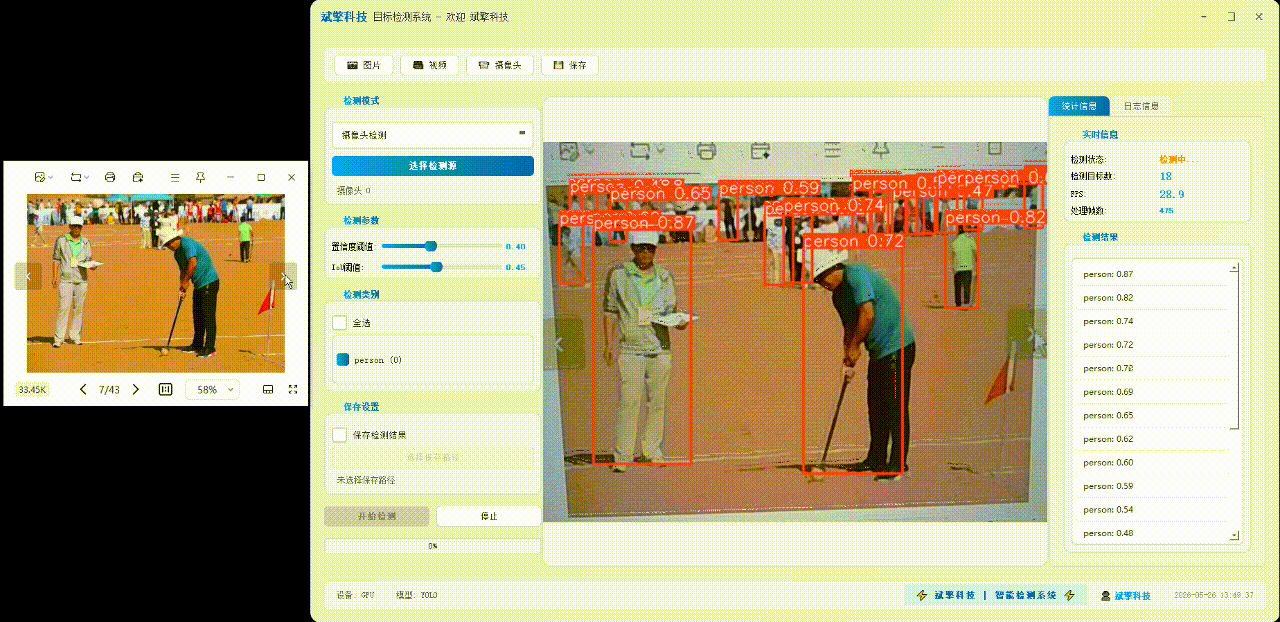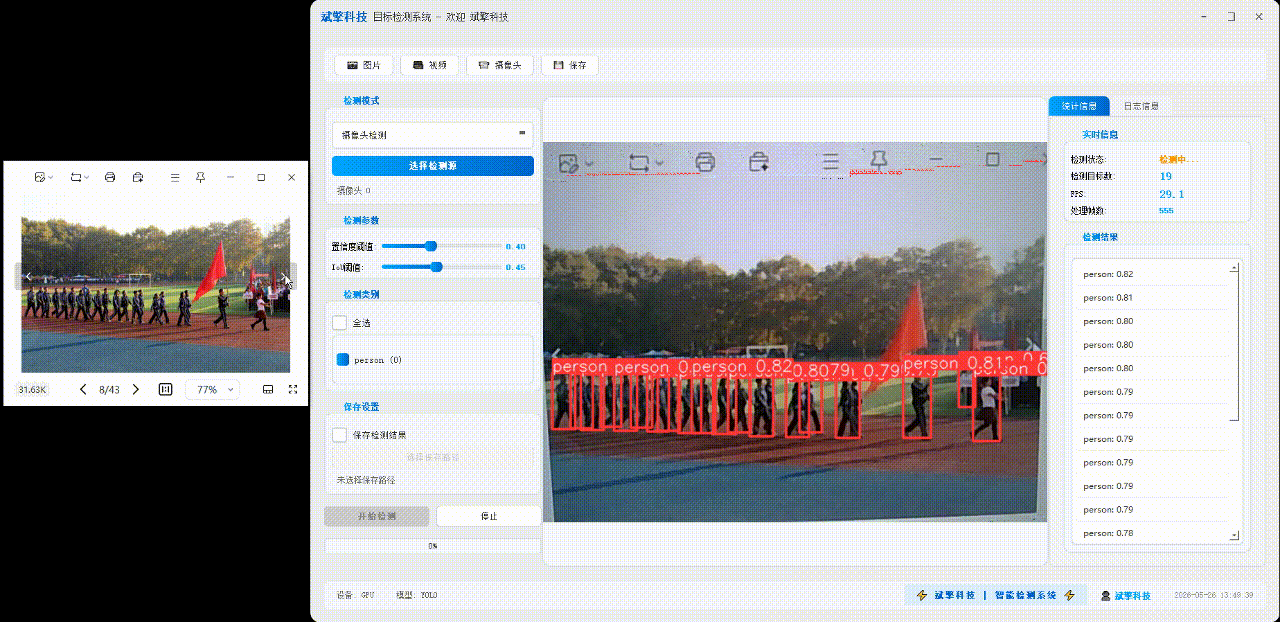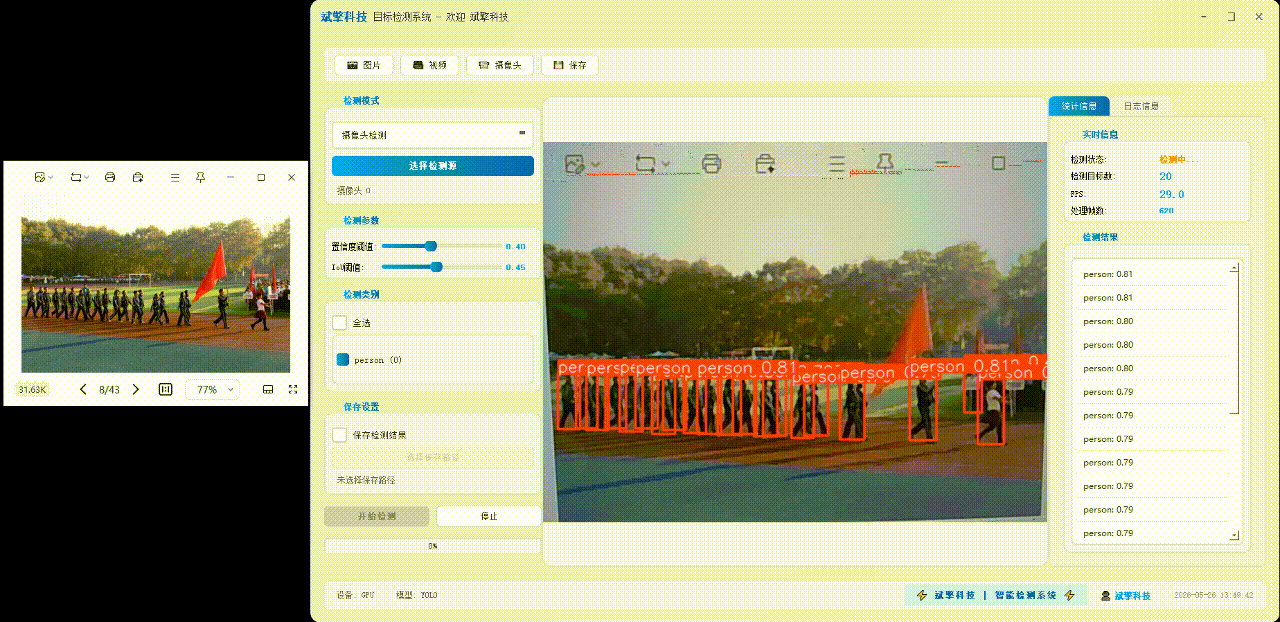
✅ 图片检测:可对图片进行检测,返回检测框及类别信息。
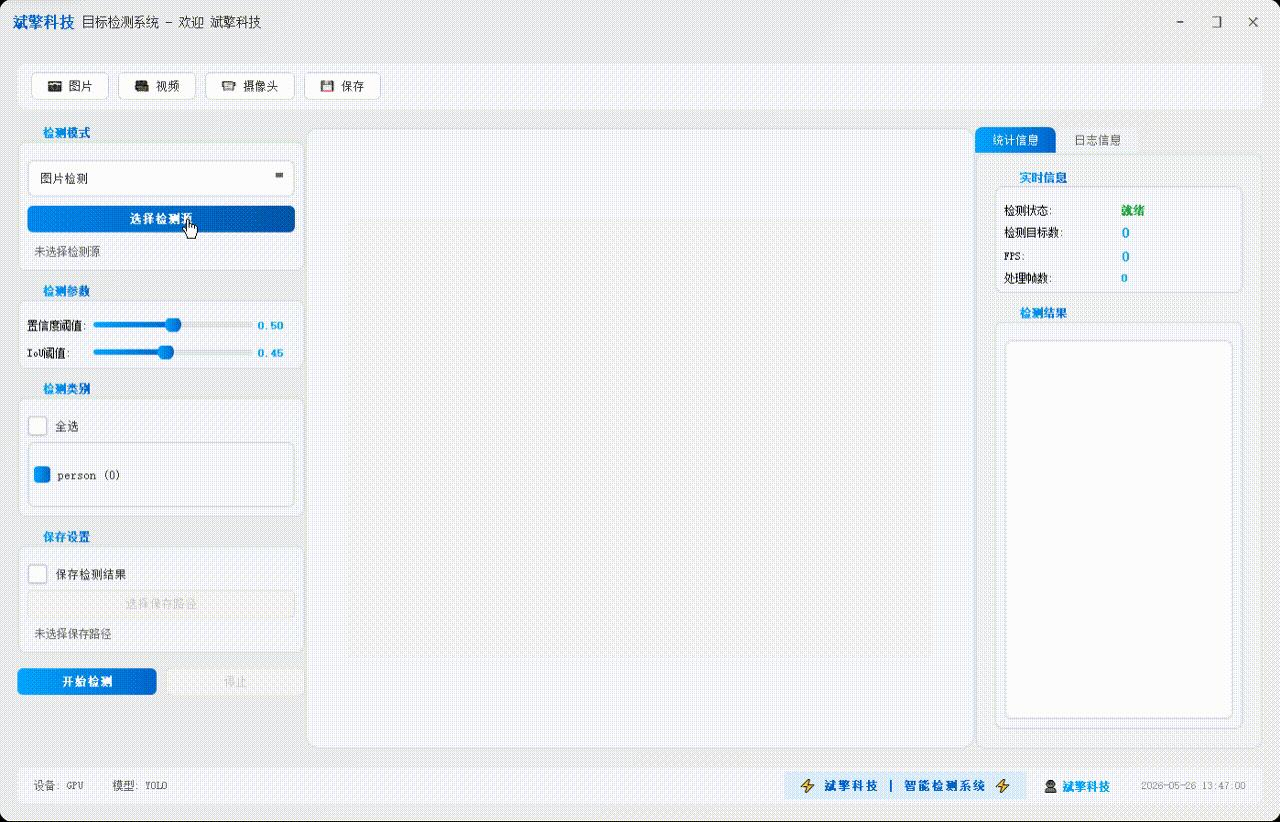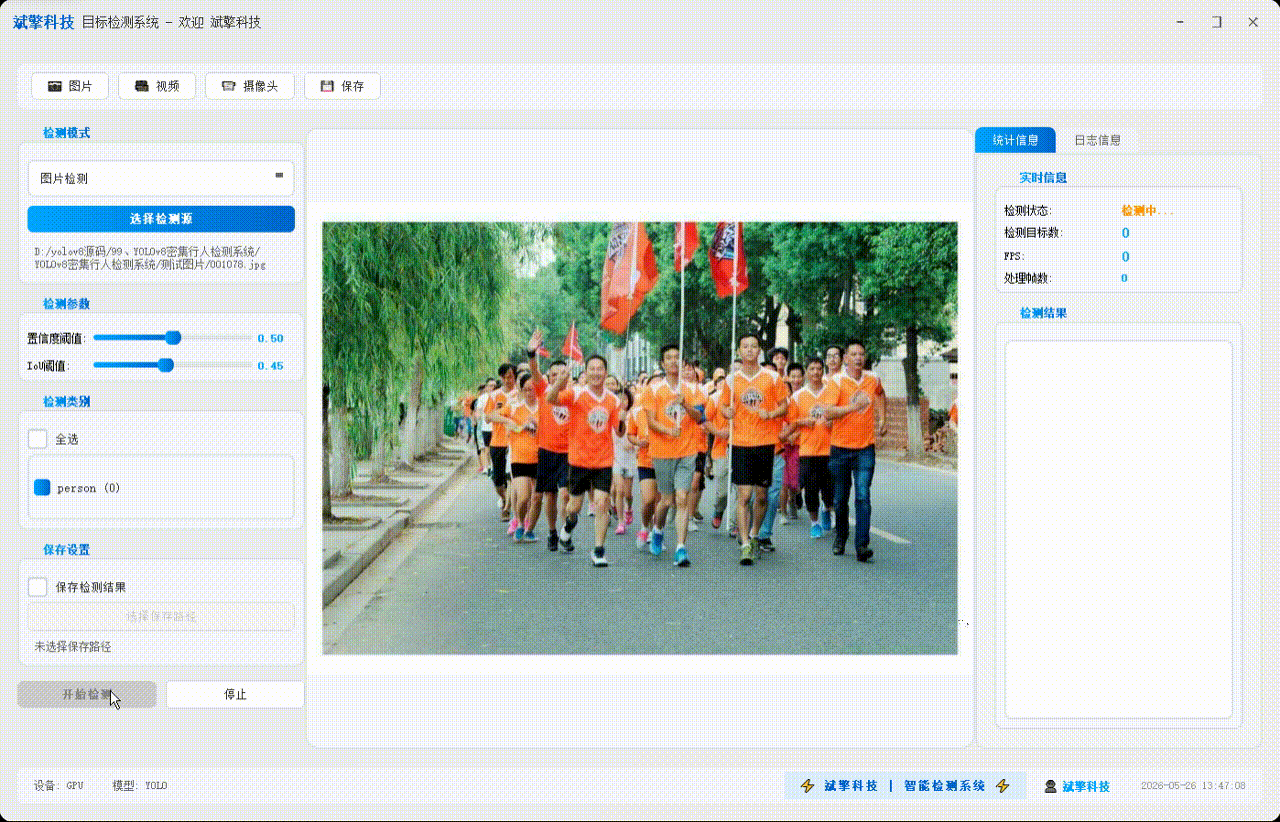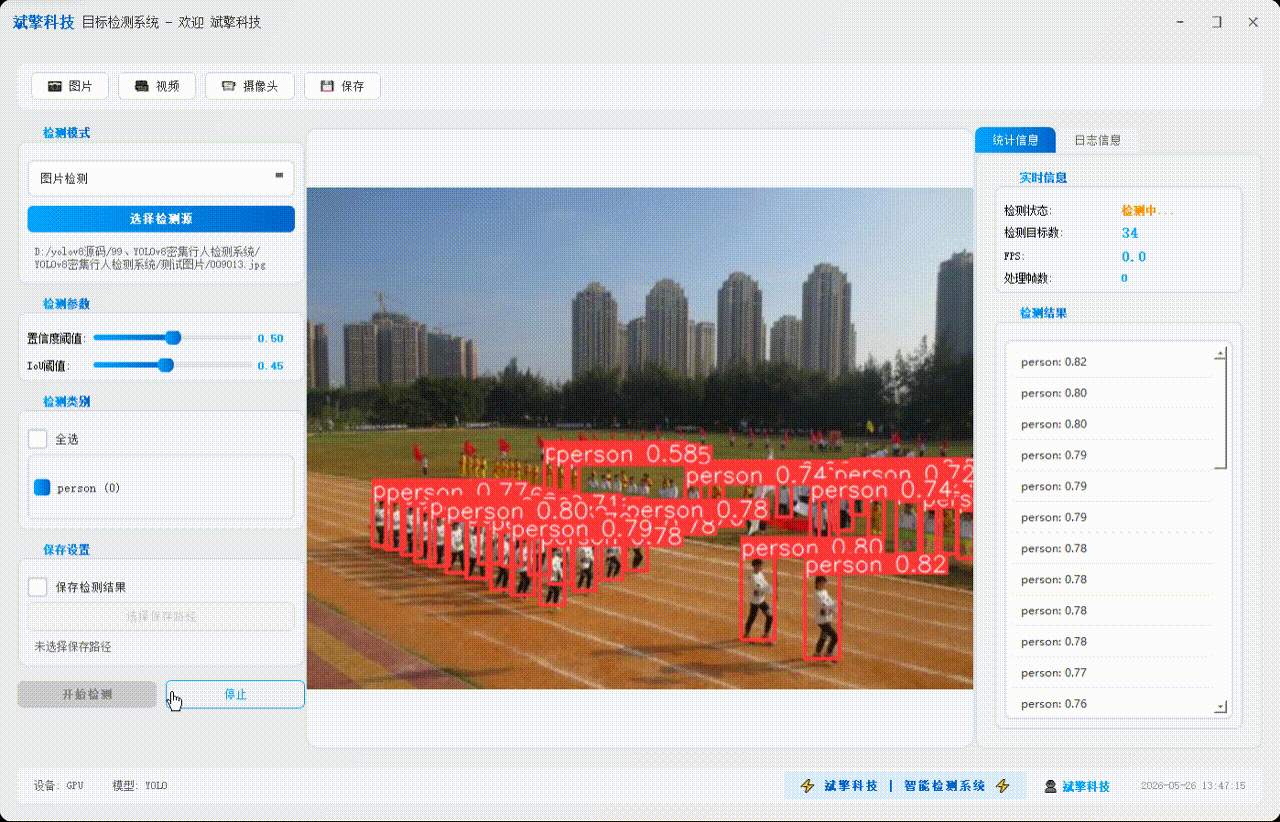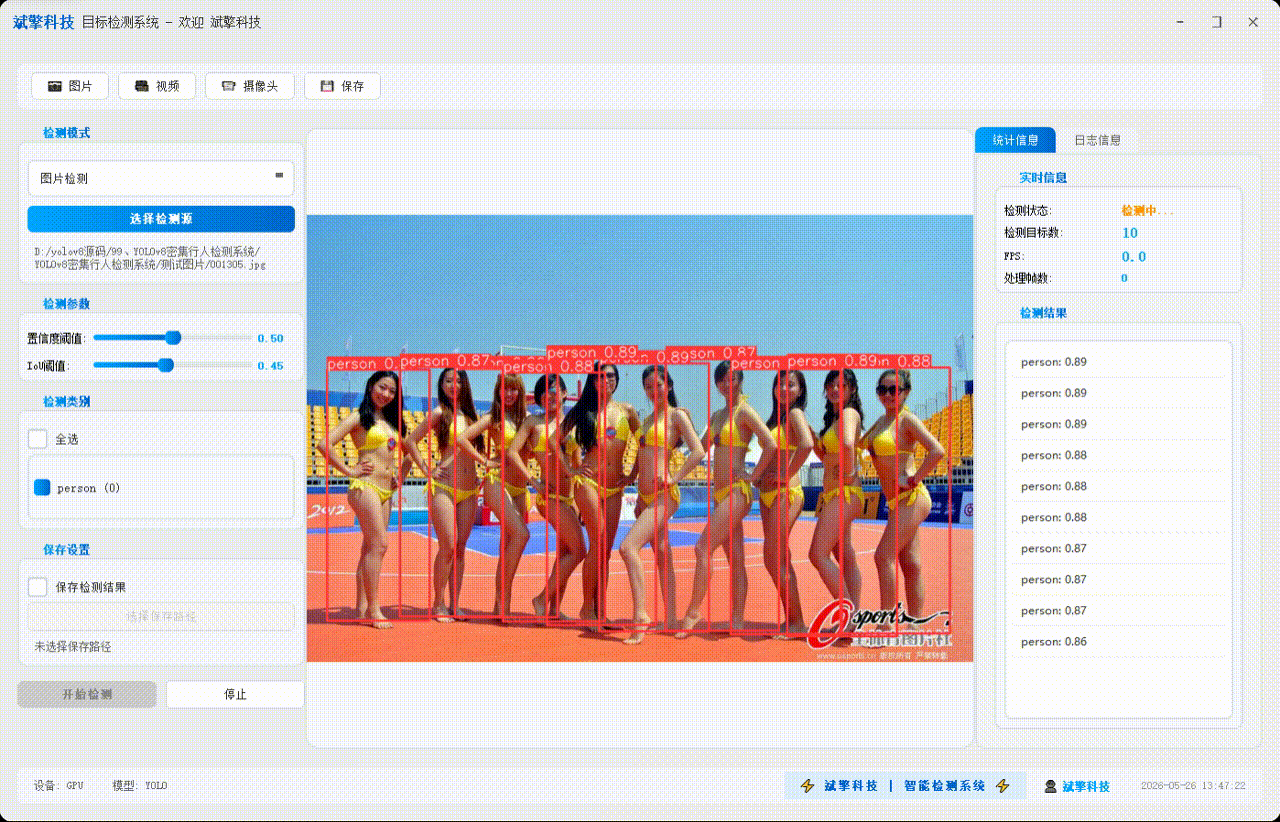
✅参数实时调节(置信度和IoU阈值)
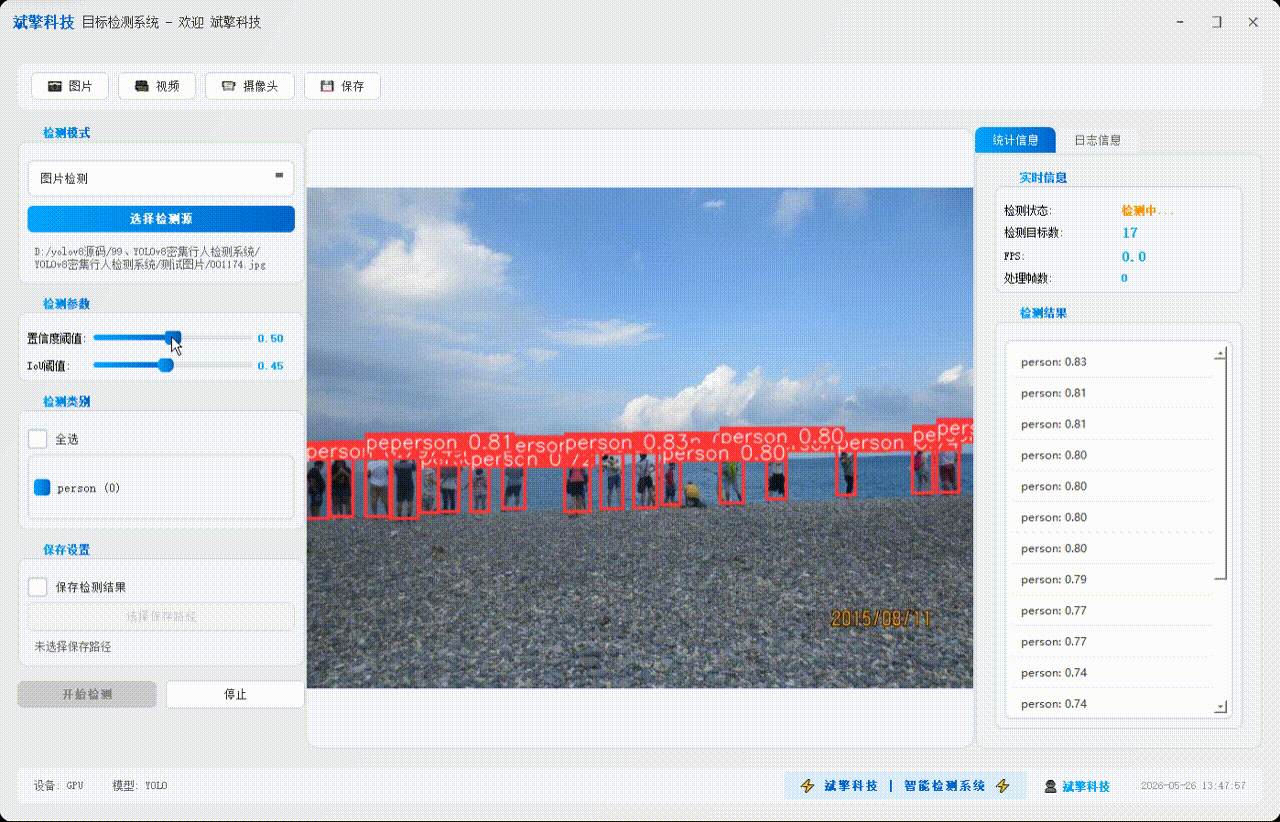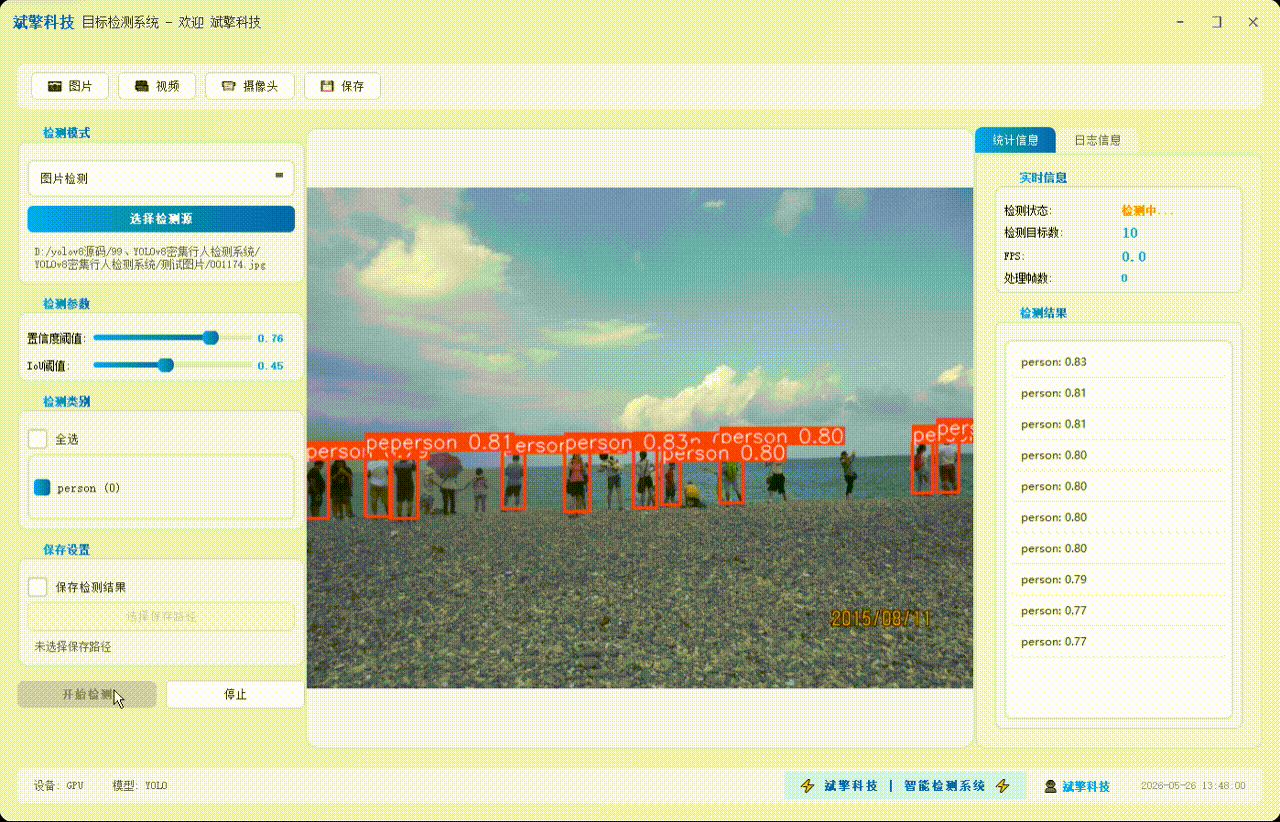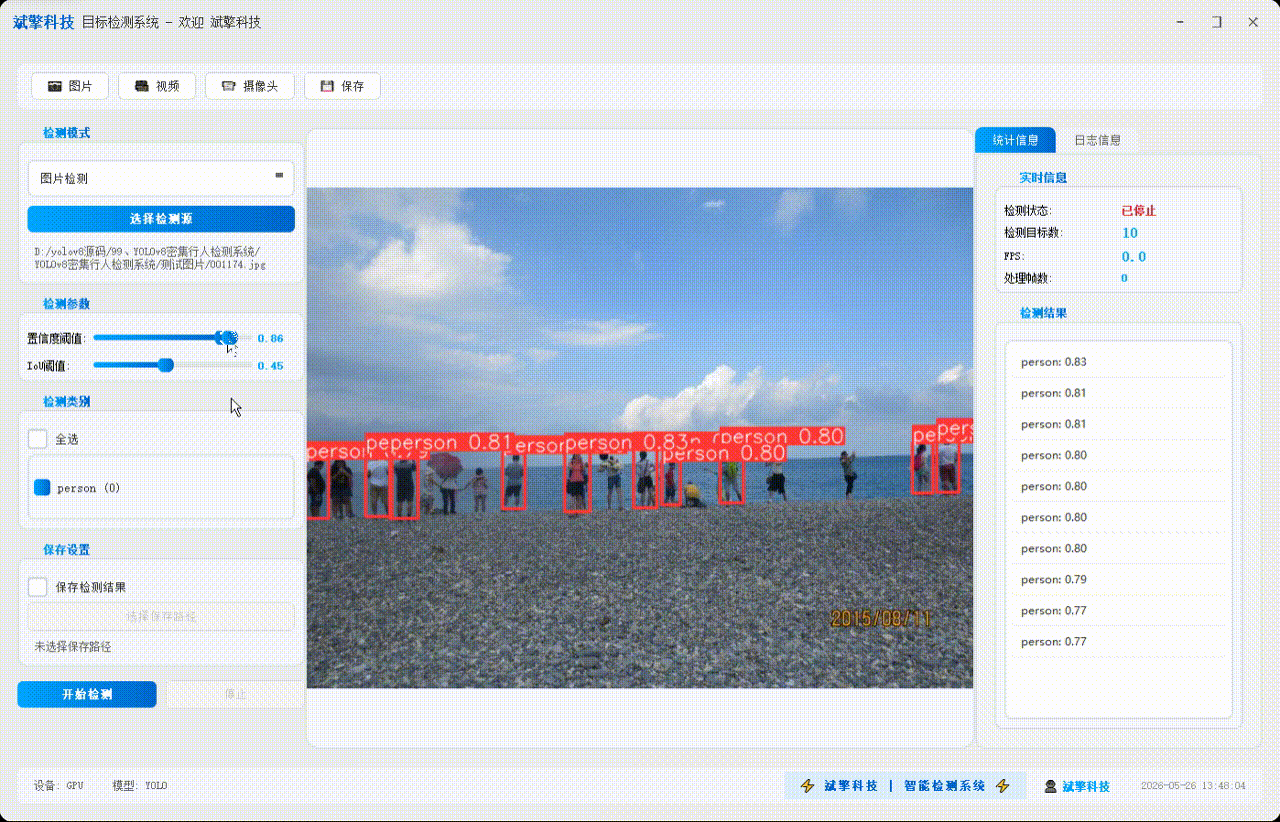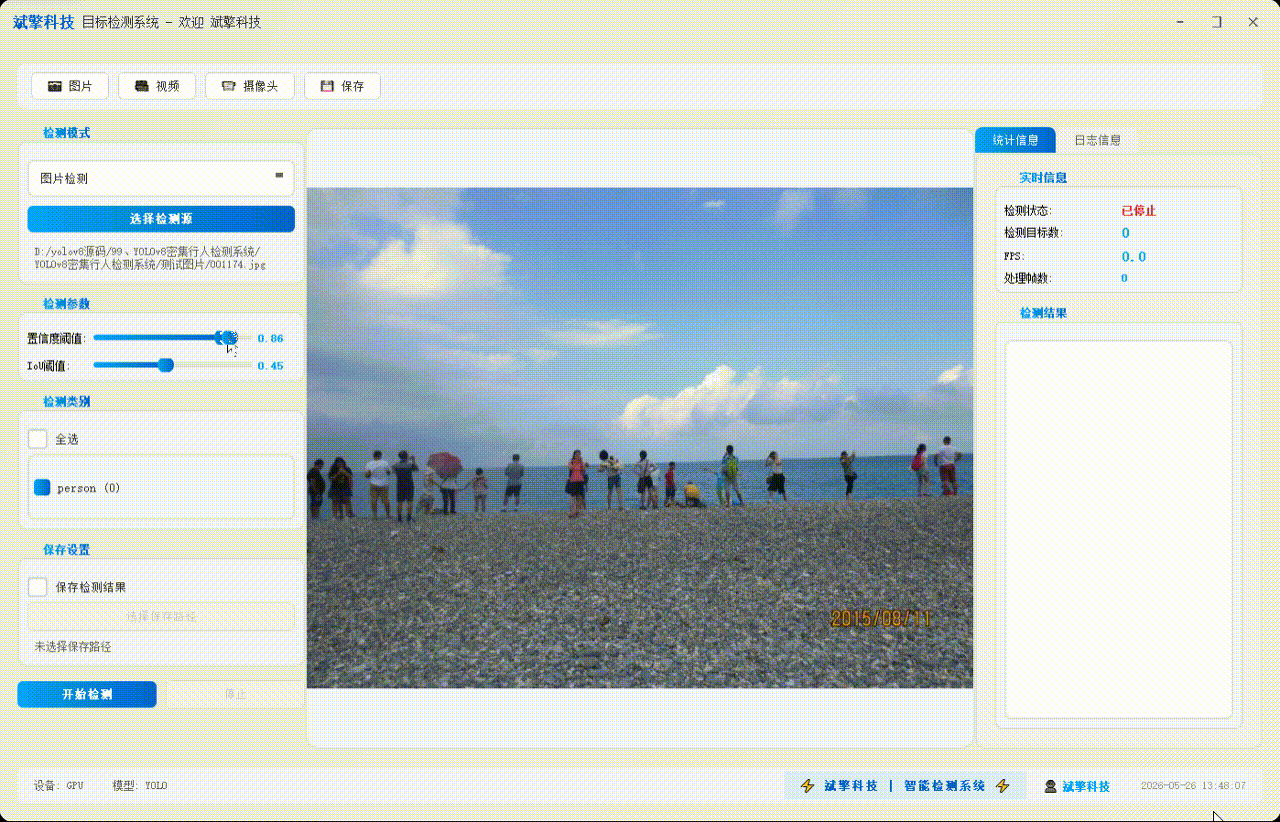
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。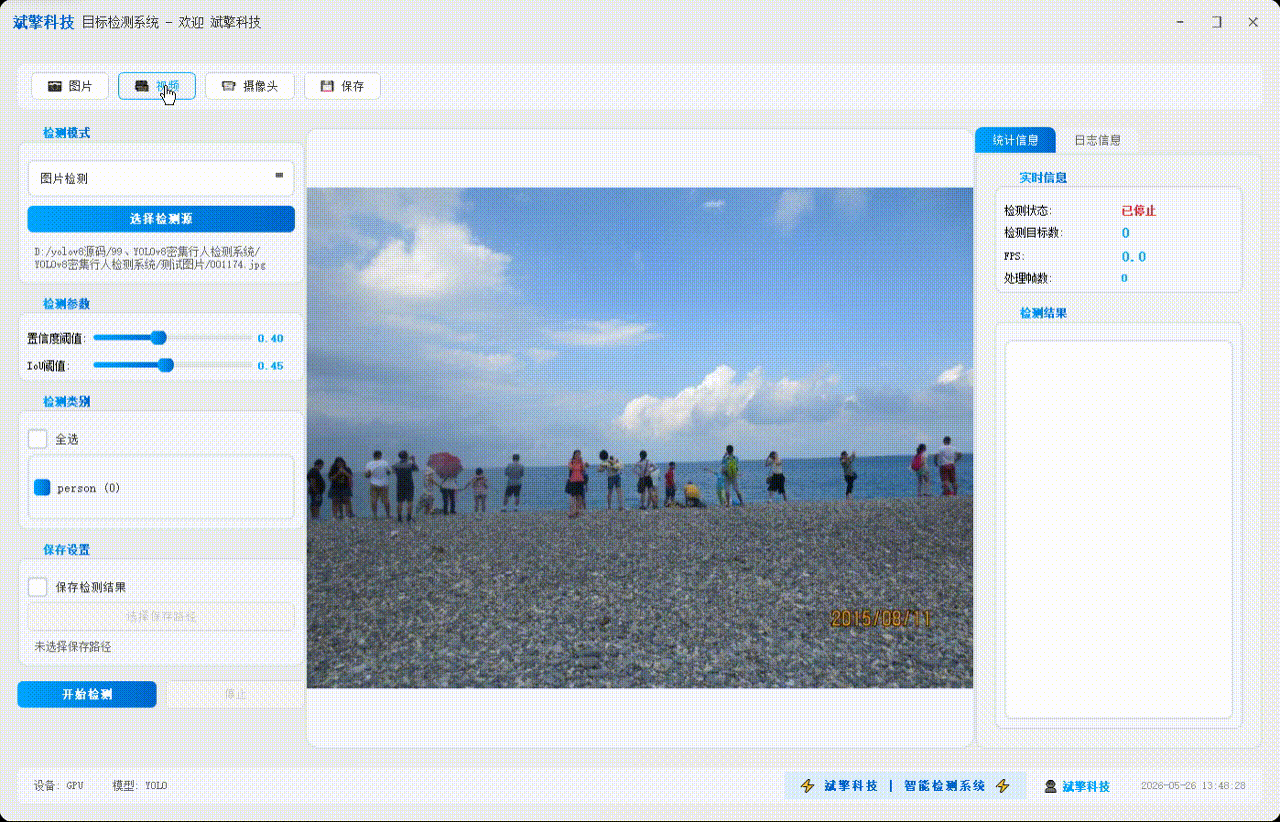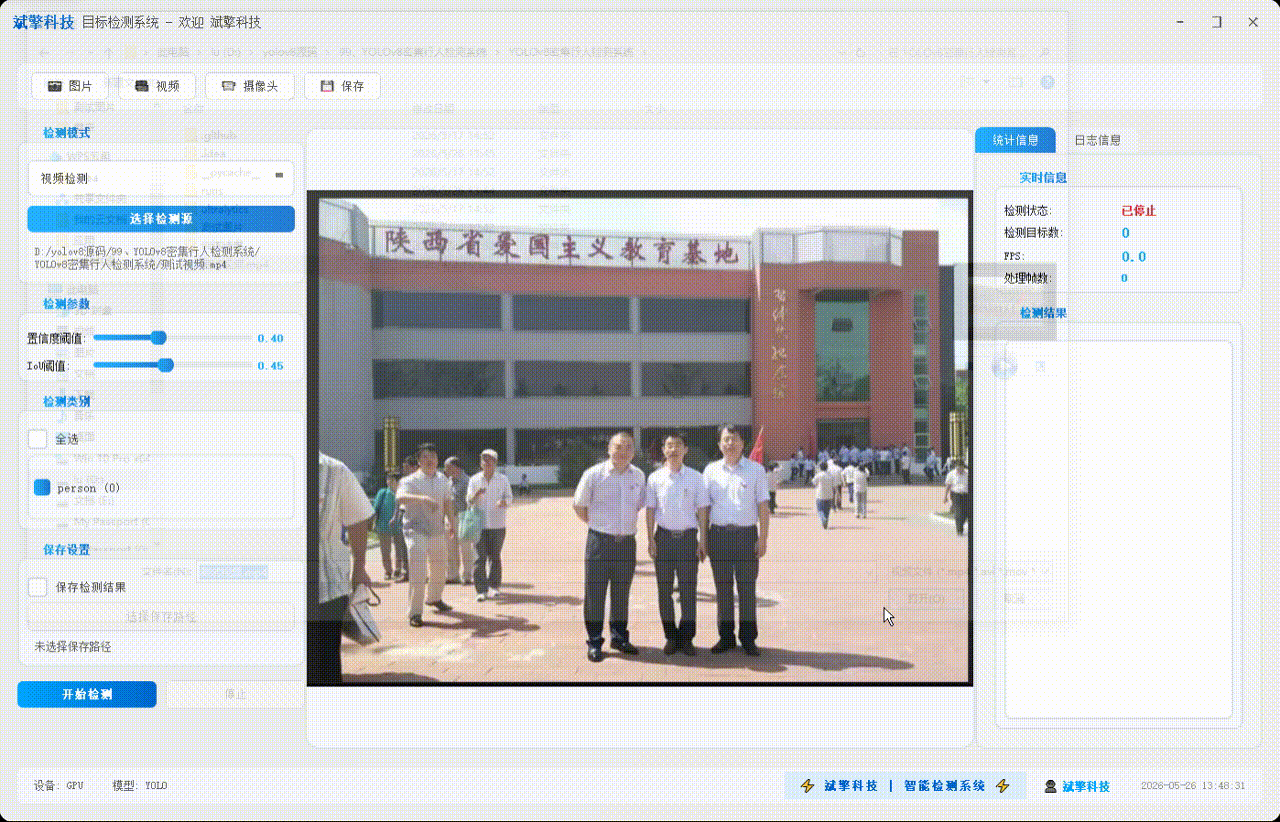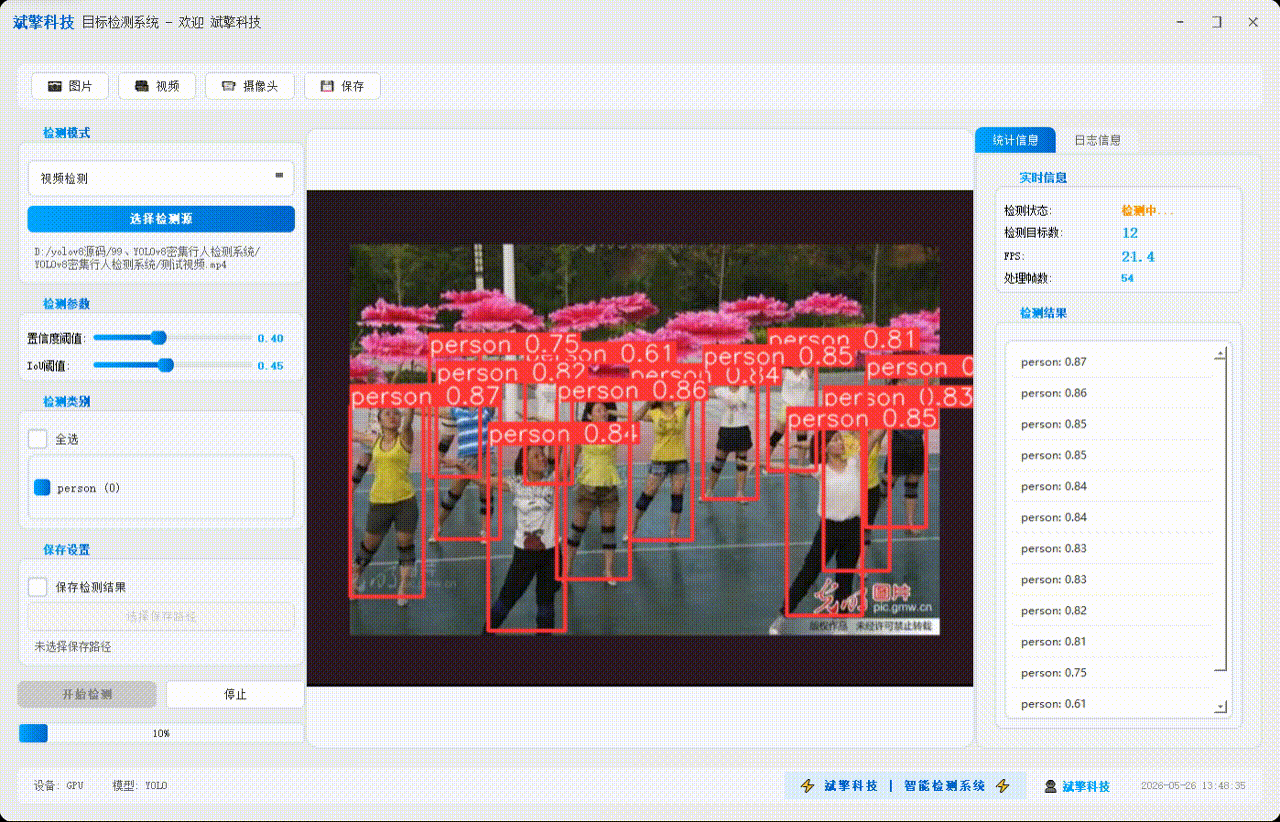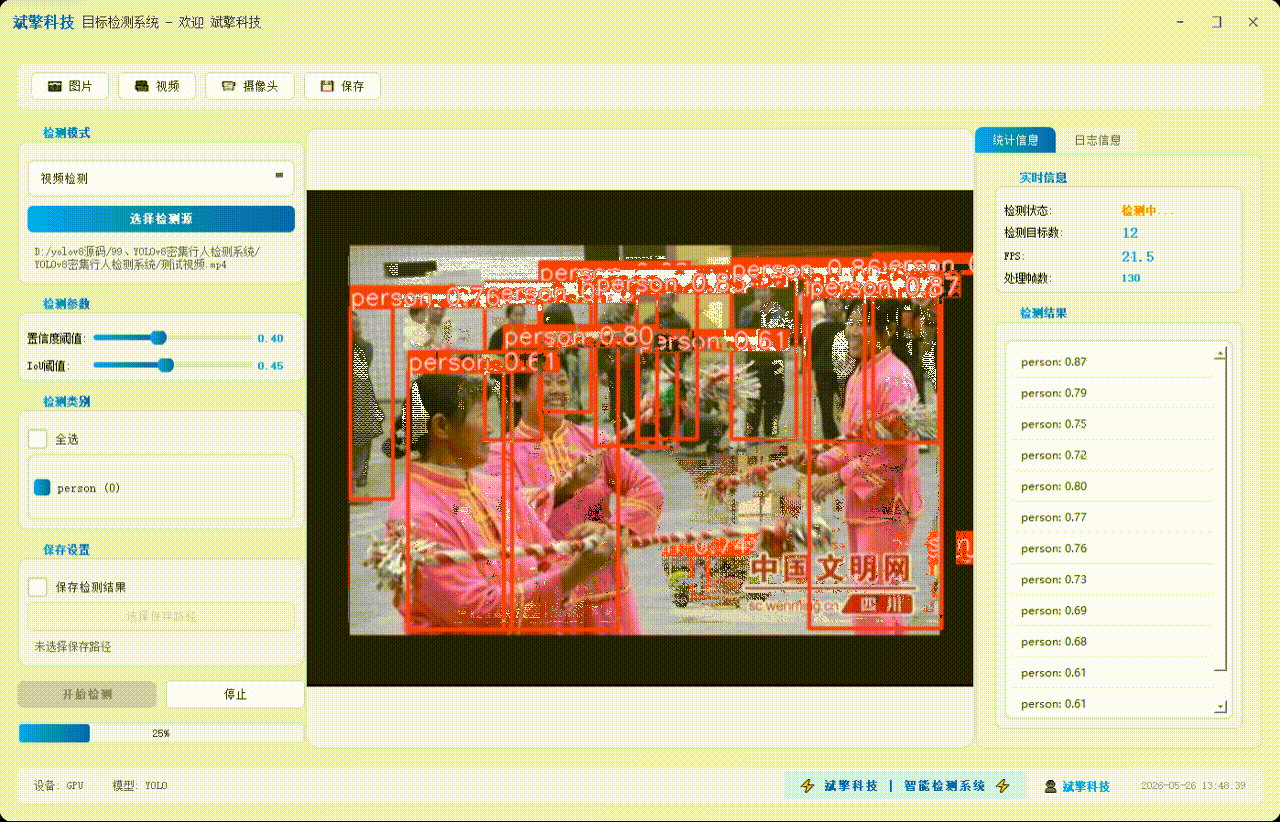
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测。
✅日志记录:日志标签页记录操作和错误信息,带时间戳
✅结果保存模块:支持图片/视频/摄像头检测结果保存
1、用户管理模块
| 功能 | 描述 |
|---|---|
| 用户注册 | 用户名、密码、确认密码、邮箱(选填)注册,密码SHA256加密存储 |
| 用户登录 | 用户名密码验证,自动跳转主界面 |
| 用户数据存储 | JSON文件存储用户信息(密码加密、注册时间、邮箱) |
| 登录状态 | 主界面显示当前登录用户名 |
2、界面与交互模块
| 功能 | 描述 |
|---|---|
| 玻璃效果界面 | 半透明毛玻璃背景,圆角边框,现代化视觉风格 |
| 无边框窗口 | 自定义标题栏,支持窗口拖动、最小化、最大化、关闭 |
| 响应式布局 | 主窗口三栏布局(左侧控制区、中央显示区、右侧信息区) |
| 状态栏 | 显示设备信息、模型状态、当前用户、实时时间 |
3、检测源管理模块
| 功能 | 描述 |
|---|---|
| 图片检测 | 支持JPG/JPEG/PNG/BMP格式图片载入 |
| 视频检测 | 支持MP4/AVI/MOV/MKV格式视频载入 |
| 摄像头检测 | 实时调用摄像头(默认ID 0)进行检测 |
| 检测源切换 | 下拉菜单切换三种检测模式,自动更新界面状态 |
4、检测参数配置模块
| 功能 | 描述 |
|---|---|
| 置信度阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| IoU阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| 类别选择 | 动态生成检测类别复选框,支持全选/取消全选 |
| 参数同步 | 参数实时同步到检测器核心 |
5、YOLO检测核心模块
| 功能 | 描述 |
|---|---|
| 模型加载 | 加载best.pt模型文件,自动检测GPU可用性,支持CPU/GPU切换 |
| 多模式检测 | 图片检测、视频检测、摄像头实时检测 |
| 检测线程 | 基于QThread的多线程处理,避免界面卡顿 |
| 检测结果 | 返回目标类别、置信度、边界框坐标 |
| FPS计算 | 实时计算处理帧率 |
| 进度反馈 | 视频处理进度条实时更新 |
6、结果显示模块
| 功能 | 描述 |
|---|---|
| 实时画面 | 中央区域显示检测结果图像(带标注框) |
| 统计信息 | 检测状态、目标数量、FPS、处理帧数实时更新 |
| 检测列表 | 右侧列表显示当前帧所有检测到的目标(类别+置信度) |
| 日志记录 | 日志标签页记录操作和错误信息,带时间戳 |
| 占位显示 | 未选择检测源时显示系统LOGO和提示文字 |
7、结果保存模块
| 功能 | 描述 |
|---|---|
| 保存开关 | 复选框控制是否保存检测结果 |
| 路径选择 | 自定义保存路径,支持图片/视频格式自动识别 |
| 自动命名 | 保存文件自动添加时间戳(detection_result_20240101_120000.jpg) |
| 视频保存 | 支持检测结果视频录制(MP4格式) |
| 手动保存 | 工具栏保存按钮可随时保存当前画面 |
| 保存反馈 | 保存成功弹窗提示,日志记录保存路径 |
8、工具栏功能
| 功能 | 描述 |
|---|---|
| 图片按钮 | 快速切换到图片检测模式并打开文件选择器 |
| 视频按钮 | 快速切换到视频检测模式并打开文件选择器 |
| 摄像头按钮 | 快速切换到摄像头检测模式 |
| 保存按钮 | 手动保存当前显示画面 |
9、辅助功能
| 功能 | 描述 |
|---|---|
| 错误处理 | 统一错误弹窗提示,日志记录错误详情 |
| 资源清理 | 检测停止时自动释放摄像头、视频文件、视频写入器资源 |
| 时间显示 | 状态栏实时显示系统时间 |
| 模型状态 | 状态栏显示模型加载状态和当前设备(CPU/GPU) |
10、数据校验模块
| 功能 | 描述 |
|---|---|
| 注册验证 | 用户名长度≥3,密码长度≥6,密码一致性检查,邮箱格式验证 |
| 协议确认 | 注册前需勾选同意用户协议 |
| 文件校验 | 模型文件存在性检查,文件大小验证(≥6MB) |
| 输入非空 | 登录/注册时必填项非空检查 |
背景
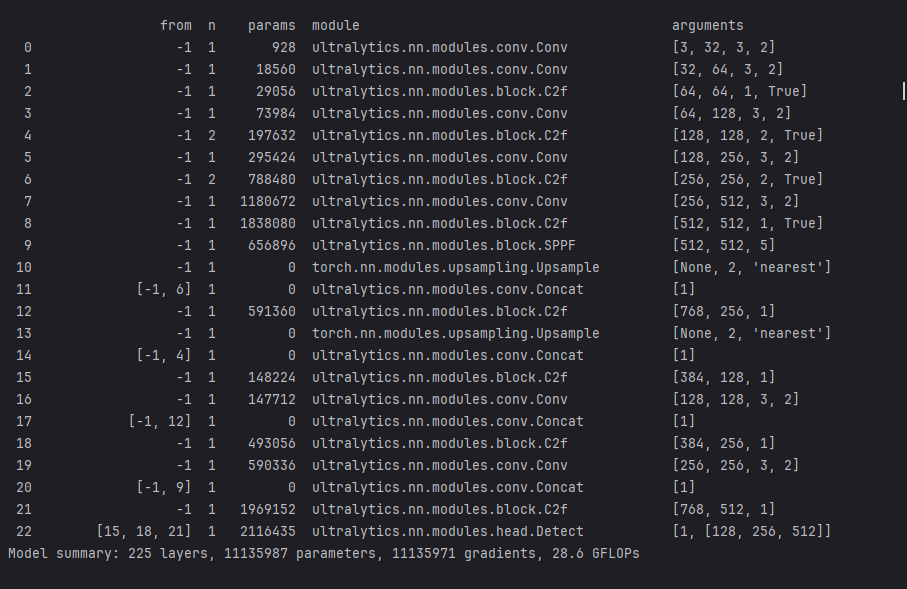
目标检测技术的发展经历了从传统手工特征(如HOG+SVM)到深度学习方法的演进。以R-CNN系列为代表的两阶段检测器通过区域提议加细分类的方式获得较高精度,但计算效率受限;以YOLO系列为代表的单阶段检测器将检测建模为回归问题,实现了实时检测能力。YOLOv8在先前版本基础上引入了更高效的特征提取网络(CSPDarknet)、无锚框(Anchor-Free)检测头以及优化的损失函数(DFL与CIoU Loss),进一步提升了检测精度与训练效率。
密集行人检测作为细分类别的人体检测任务,其特殊性在于:第一,行人属于非刚性目标,姿态变化多样;第二,密集场景中的遮挡导致目标部分可见,特征不完备;第三,透视效应使得行人尺度跨度大(从数像素到数百像素)。这些特性要求检测器具备更强的特征表征能力、更精细的定位能力以及更鲁棒的密集匹配策略。当前主流解决方案包括引入注意力机制、多尺度特征融合、可变形卷积以及专用的遮挡处理策略。
数据集介绍
本研究所用数据集为专用密集行人检测数据集,涵盖多样化的真实场景,包括城市街道、商场入口、人行横道、公交站点等人流密集区域。数据集总计包含9,000张标注图像,按照8:2的比例划分为训练集(7,200张)和验证集(1,800张)。

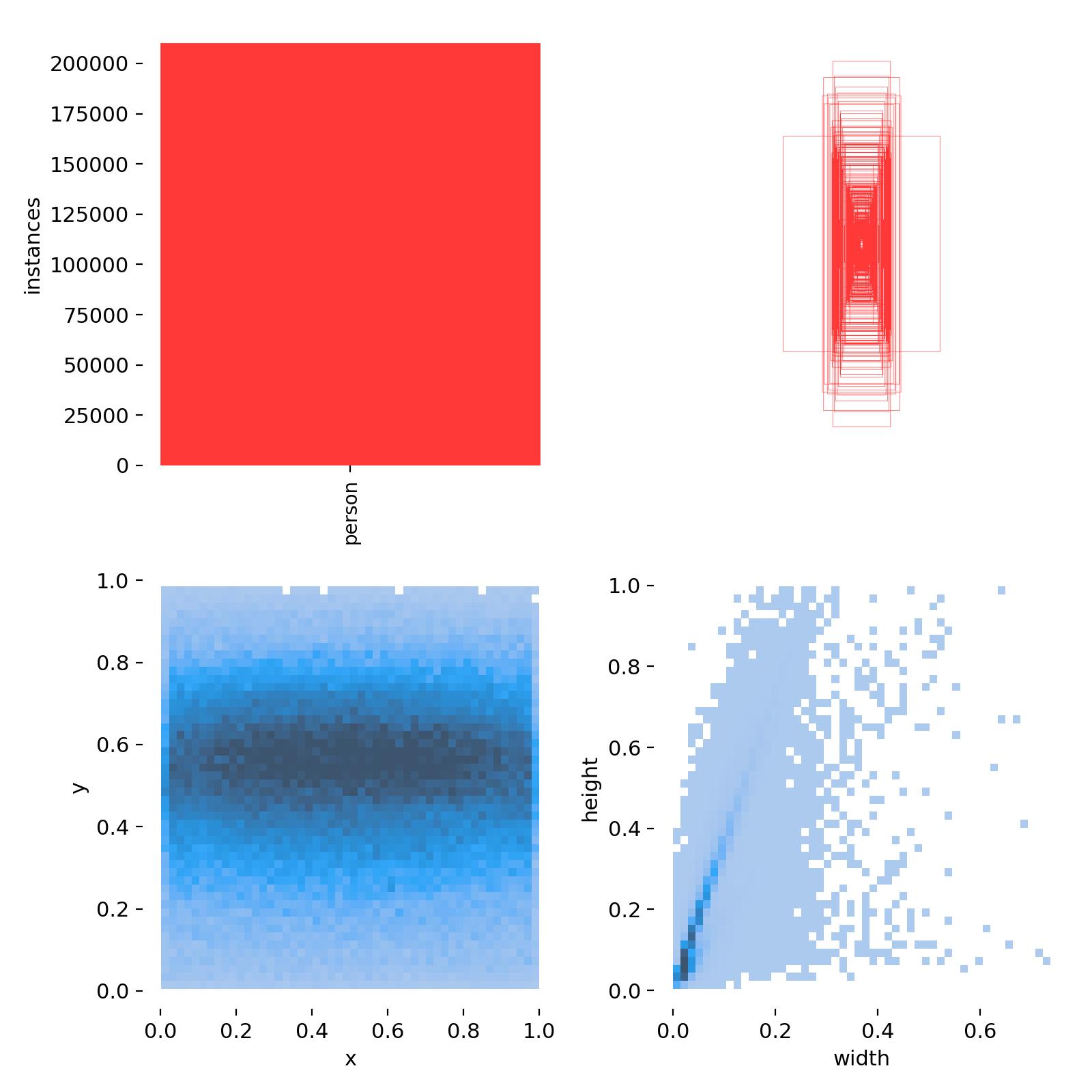


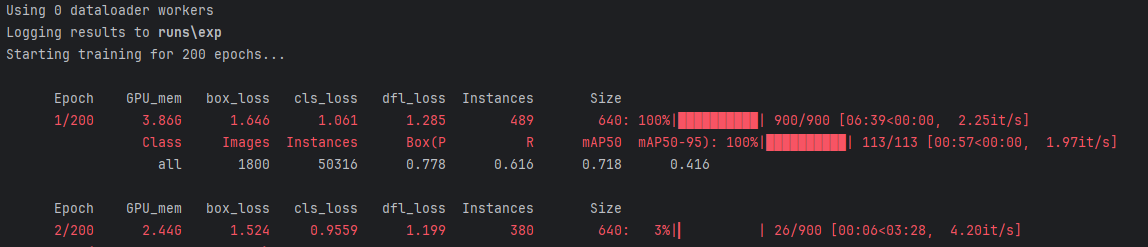
训练过程
训练结果
核心性能指标(总体评价)
| 指标 | 数值 | 评价 |
|---|---|---|
| mAP50 | 0.760 | 中等偏上,在密集场景下尚可 |
| mAP50-95 | 0.477 | 偏低,说明边界框定位精度不足 |
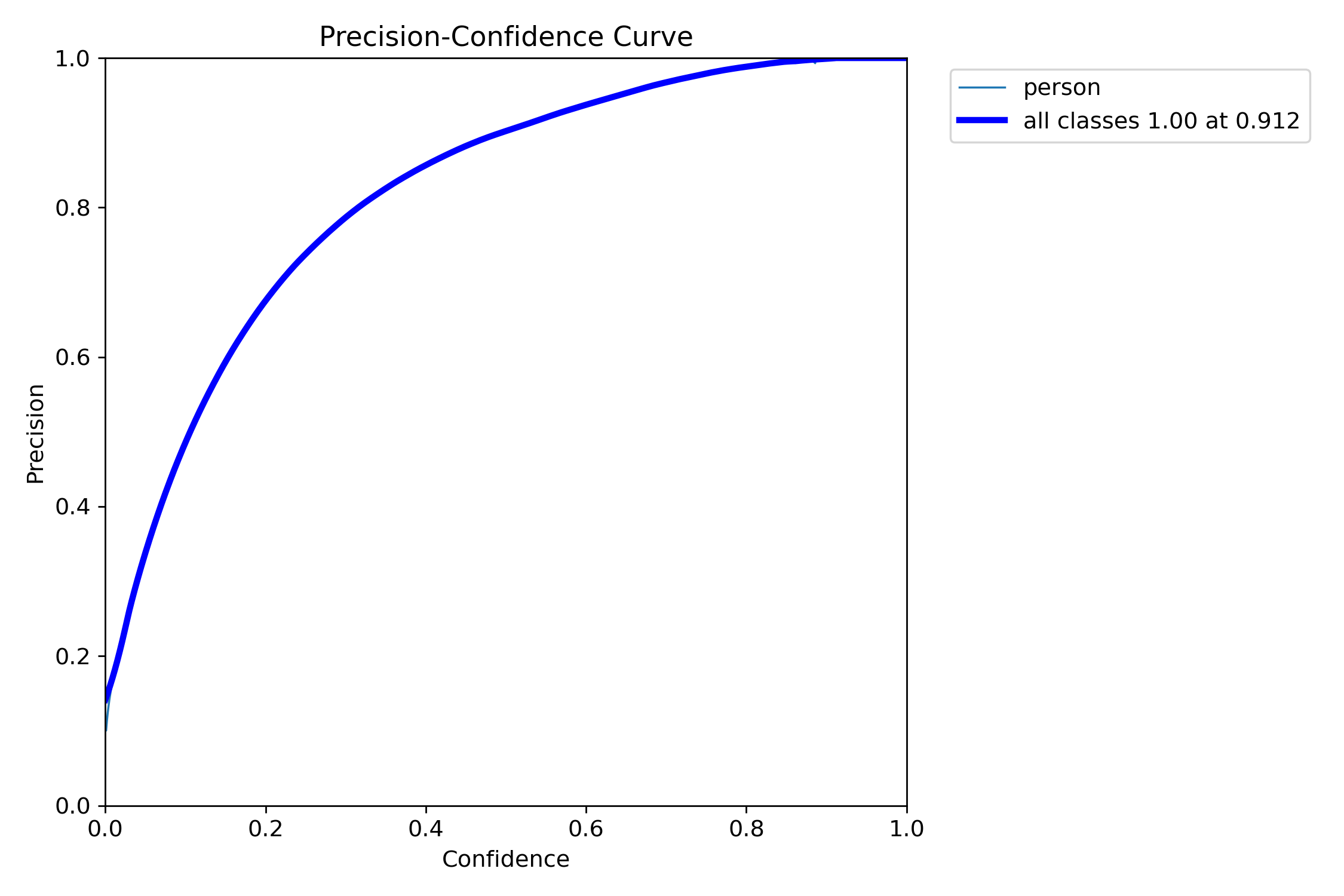
| Precision | 0.792 | 较好,误检率可控 |
| Recall | 0.658 | 偏低,漏检较多 |
| F1-score(最佳) | ~0.73(@置信度0.12) | 平衡点一般 |
结论:模型有一定检测能力,但在密集行人场景下漏检问题较突出,且定位精度有待提升。



常用标注工具
假设您现在准备好进行标注。有几种开源工具可以帮助简化数据标注流程。以下是一些有用的开放标注工具:
Label Studio:一个灵活的工具,支持各种标注任务,并包含用于管理项目和质量控制的功能。 CVAT:一个强大的工具,支持各种标注格式和可定制的工作流程,使其适用于复杂的项目。 Labelme:一个简单易用的工具,可以快速标注带有多边形的图像,非常适合简单的任务。 LabelImg: 一款易于使用的图形图像标注工具,特别适合以 YOLO 格式创建边界框标注。
这些开源工具经济实惠,并提供一系列功能来满足不同的标注需求。
界面核心代码:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)