英伟达开源深度研究引擎:企业级数据不出门,研究自动做
Harness擅长管理会话、调用工具、响应指令,但在处理多文档信息聚合、长周期分析时则力不从心。
面对海量企业级数据,既要保证来源可追溯,又要兼顾合规安全。
NVIDIA 新推出的 AI-Q Blueprint(AI-Q 蓝图),巧妙化解了当前困境。
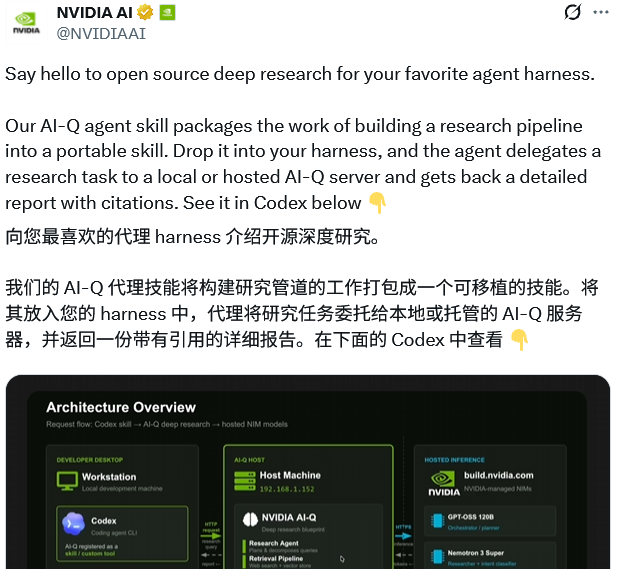

系统将繁复的深度研究流水线打包成便携的 Agent Skill,只需一行指令,就能给框架加装独立的分析引擎。
代理框架可以直接向 AI-Q 服务器派发任务并接收结构化报告,企业敏感数据始终安全留在本地。
告别重复造轮子
Claude Code、Codex、LangChain Deep Agents 等框架是优秀的任务调度员。它们负责管理对话上下文、串联功能模块、高效执行代码,表现无可挑剔。一旦面对企业级深度研究任务,局限性立刻显露无疑。
跨越不同数据源的信息合成、附带来源归因的长周期分析,往往超出了通用调度的范畴。
工程师只好亲自下场,处理庞杂的数据连接逻辑。
他们需要编写路由模块,打通各个加密的企业数据库;需要手动处理复杂的身份验证,确保每一次调用都符合安全规范;还要反复微调提示词,设计完善的评估机制,并且小心翼翼地保留每一次结果输出的引用出处。
全部流程不仅耗费大量精力,后期维护成本也十分高昂。
AI-Q 蓝图刚好填补了技术空白。系统将繁杂的底层逻辑打包成开源的深度研究模块,作为通用技能直接提供给调度平台。
代理框架只需把任务直接委托给本地或云端托管的服务器,随后就能坐收一份结构化且带有详细引用的研究报告。
开发者不再需要死磕底层的研究管线。敏感的源数据安稳地留在企业内部。对医疗、金融、政府、国防等强监管行业来说,一套免接触源数据的方法尤为关键。
安装过程十分轻量。
以 Claude Code 框架为例,使用两条命令即可将技能链接到工作区:
mkdir -p .claude/skillsln -s ../../.agents/skills/aiq-research .claude/skills/aiq-research若希望跨代码库通用,直接执行用户级安装即可:
mkdir -p ~/.claude/skillscp -R .agents/skills/aiq-research ~/.claude/skills/aiq-research对于 Codex 用户,只需将相关文件复制到配置目录,重启会话即可完成部署:
mkdir -p <codex-skills-dir>cp -R .agents/skills/aiq-research <codex-skills-dir>/aiq-researchOpenCode 的逻辑同样直白,把文件放进用户配置夹即可生效:
mkdir -p ~/.config/opencode/skillscp -R .agents/skills/aiq-research ~/.config/opencode/skills/aiq-research部署完毕后,通过一行测试代码验证连通性:
python3 scripts/aiq.py# Usage: aiq.py <command> [args]平台此时便多了一项强悍的深度研究能力。输入类似检索内部政策文档并生成合规备忘录的指令,请求会自动经由技能模块路由至服务器。繁琐的检索、规划、合成与引用逻辑全被隐藏在幕后。
守护核心数据资产
企业级应用的另一大痛点在于数据读取的安全与便捷。AI-Q 原生支持连接已认证的 MCP 服务器。研究管线可以直接读取智能体现有使用的企业内部系统数据,彻底省去了重复搭建平行检索栈的麻烦。
由于整个架构建立在 NeMo Agent Toolkit(NeMo智能体工具包)基础之上,所有的远端服务器都能以功能组的形式无缝插入。
官方文档清晰列举了3种端到端的集成模式。表1梳理了常见的身份验证场景与对应映射。
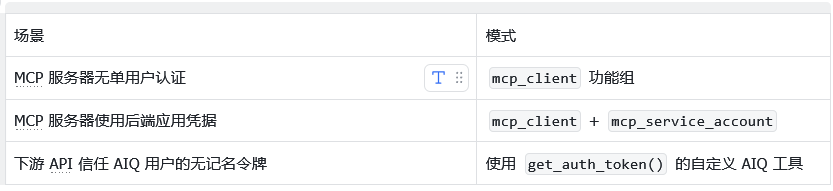
无认证的服务节点处理起来最为省心。只要将 mcp_client 功能组指向目标地址,系统便会自动发现并把远端工具注册进可用列表。
function_groups: mcp_financial_tools: _type: mcp_client server: transport: streamable-http url: ${MCP_SERVER_URL:-http://localhost:9901/mcp}推荐在新部署或生产认证环境中使用 streamable-http 传输协议,它比传统的服务器发送事件响应更为稳定可靠。
在持续集成、批处理作业或共享企业数据源等应用层级管控权限的场景中,基于服务账号的认证模式成为首选。
function_groups: mcp_enterprise_tools: _type: mcp_client server: transport: streamable-http url: ${ENTERPRISE_MCP_URL} auth_provider: enterprise_service_account authentication: enterprise_service_account: _type: mcp_service_account client_id: ${SERVICE_ACCOUNT_CLIENT_ID} client_secret: ${SERVICE_ACCOUNT_CLIENT_SECRET} token_url: ${SERVICE_ACCOUNT_TOKEN_URL} scopes: - enterprise.read部分网关可能要求同时提供 OAuth2 令牌与特定服务的委托凭据。系统同样支持通过 service_token 模块在外部调用时附加第二重请求头。
面对下游 API 已经信任当前用户无记名令牌的场景,直接转发用户的登录身份即可。
系统暴露了 aiq_agent.auth.get_auth_token() 方法,在提交作业的瞬间捕捉请求凭证,并在异步 Dask 工作进程中予以恢复。
漫长的研究过程里,用户身份上下文始终得以保留。待下一个版本加入进程内的刷新机制后,长时间运行任务的稳定性将进一步提升。
驻扎在数据源头
完整的代码库被打包成 Docker Compose 和 Helm charts。一套相同的蓝图,可以在开发者的笔记本电脑上跑,可以在本地数据中心的 Kubernetes 集群上跑,甚至能在完全物理隔离的机房里平稳运行。
数据在哪里,研究管线就部署在哪里。
模型直接读取本地文件、执行检索、合成报告。原始文档从始至终都没有离开过企业防火墙的视线。框架最后拿到手的,仅仅是一份带有精确引用的文本输出。对数据主权要求严格的企业,悬着的心彻底放了下来。
不仅管线可以本地部署,底层的模型也完全支持私有化。
NVIDIA Nemotron 开源模型通过 NIM(NVIDIA推理微服务)在本地环境飞速运转。云端的前沿大模型依然是随时可调用的备选项。业务团队手握绝对的自主权,复杂的任务编排可以交给云端,触及核心商业机密的研究全部交由本地模型处理,既满足合规审查,又兼顾了计算成本。
系统天生具备透明可查的基因。产出的每一份报告都附带着详细的来源归因,底层的工具包持续输出 OpenTelemetry(开源遥测)追踪记录。审查团队调出日志,哪一行结论引用了哪一份文件、检索逻辑经过了怎样的推演,全程一目了然。
专为深度研究打磨
通用的调度平台应对日常检索绰绰有余,但面对复杂的企业级多源信息合成,输出质量往往忽高忽低。
AI-Q 的管道专门为高质量深度研究设计。每一次查询,都要经过4个严苛的阶段过滤。
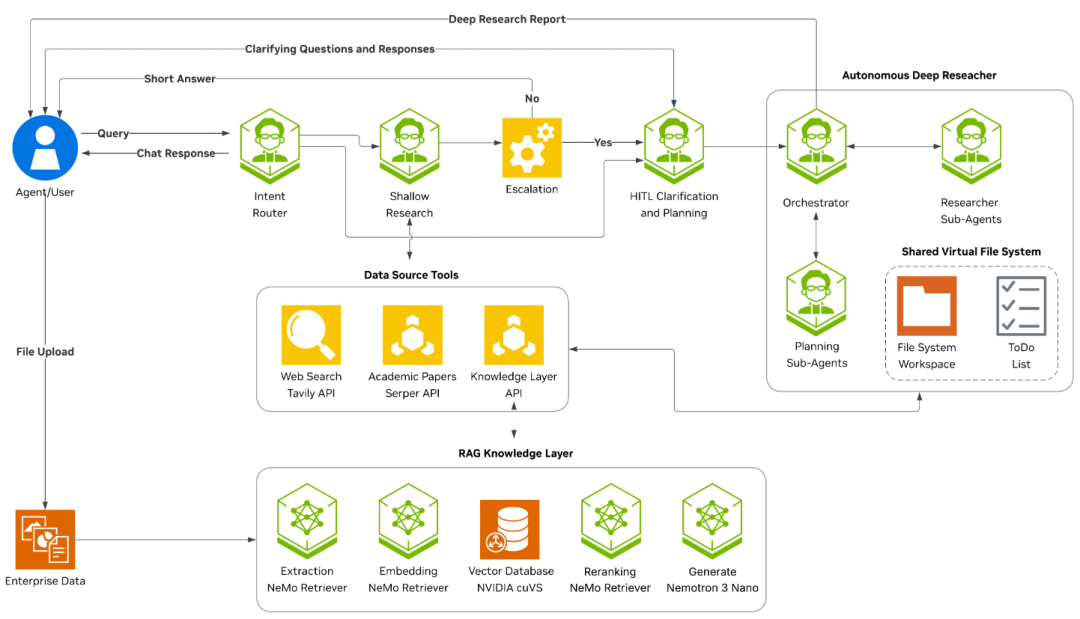
意图分类器充当大脑,精准判断当前问题需要钻取多深。遇到模糊不清的指令,系统自带的人工介入环节会主动要求澄清,绝不盲目开始检索。边界清晰的基础问题交由浅层研究员迅速搞定。错综复杂的跨源数据合成,则由深层研究员接管,进行长程视角的深度剖析。
每一个阶段都经过了 FreshQA、Deep Research Bench 以及 DeepSearchQA 等权威基准测试的独立调优。配套的评估工具也会随蓝图一并交付,企业随时可以用专有数据对系统进行跑分验证。
灵活的混合模型架构让性能与成本达到完美平衡。Nemotron 模型扛起规划与合成的大旗,部分高度依赖特定能力的环节则由可配置的路由器转发给云端处理。
整套经过反复打磨的开源蓝图已经正式向开发者开放。
戴尔 AI 工厂也完成了全面验证。基于 Dell AI Data Platform 的 Dell-NVIDIA AI-Q 2.0 参考架构,将一切最佳实践固化为生产可用的工作流。
金融服务、公共部门、制造研发等强监管行业,只需点击部署,就能立刻拥有一个高效稳定的研究助手。
参考资料:
https://developer.nvidia.com/blog/add-a-specialized-deep-research-skill-to-agent-harnesses
https://github.com/NVIDIA-AI-Blueprints/aiq
https://x.com/NVIDIAAI/status/2057855521193881773

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)