AI应用---网络机器人
网络机器人---概述
网络机器人:就是爬虫,是一种按照约定预设规则,自动浏览并抓取网络数据的程序或脚本。

数据清洗:是指对采集到的原始数据进行处理,修正,转换和标准化的过程,目的是让数据更加规范,准确。
网络机器人---合规性(robots协议)
robots协议:又称爬虫协议、爬虫规则,是指在网页根目录下放置一份文本文件robots.txt,用于告知爬虫哪些页面可以抓取,哪些页面不能抓取(君子协议)
一份robots协议允许定制多份规则
网站域名+/+robots.txt可以查看该网站的robots协议
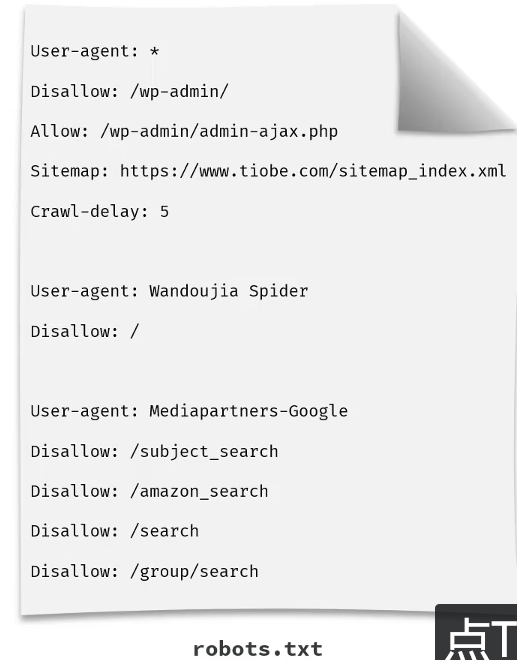
/所有资源
*代表的事任何网络机器人
user-Agent :用户代理,通过该请求头确认爬虫的类型
Dissalow :禁止访问的资源
Allow :允许访问的资源
Sitemap :网站地图,方便爬虫更高效的获取网站的内容
Crawl-delay:抓取间隔时间,避免频繁访问造成网络压力过大
前端网页结构
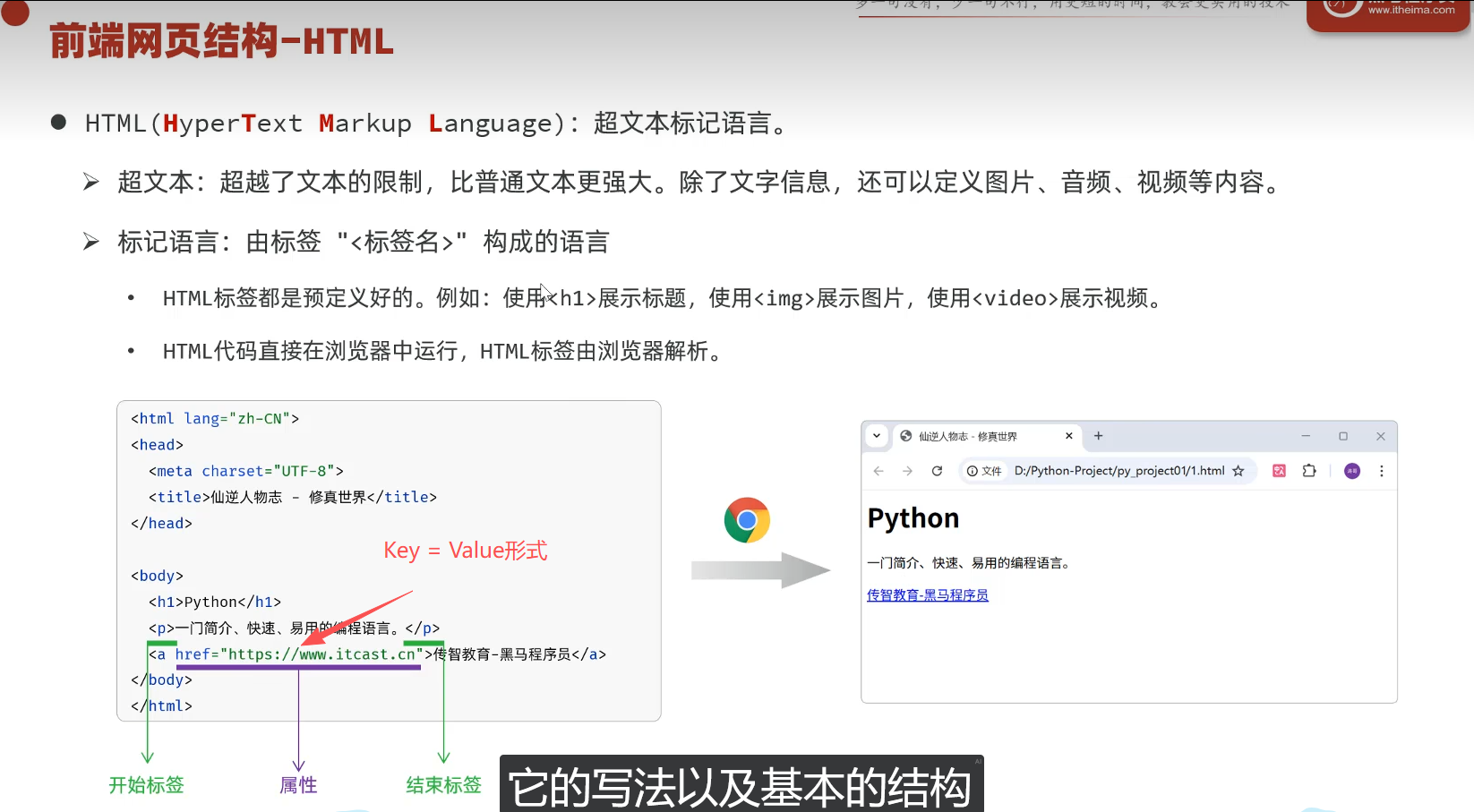
一个网页由三个部分组成:HTML , CSS , JS(JavaScript)
HTML :超文本标记语言,由一堆预设的标签(<h1>一级标题<h1>)构成,HTML负责网页的结构(页面元素和内容)
CSS :层叠样式表。CSS负责网页的外观(页面元素的位置外观,颜色,大小字体的颜色大小)
JS : 负责网页的行为(交互效果)
HTML是骨架,CSS是皮囊,JS是灵魂
网络解析-入门
lxml :是一个高性能的HTML/XML文档的解析库,支持基于Xpath语法来解析和获取的网页数据
Xpath: 是一种用于在HTML/XML文档中的导航或定位元素的查询语言,让你能够精准的查询到文档中的定位元素、属性或文本。
安装方法:pip install lxml
导入方法:from lxml import html
from lxml import html
import os
# 读取同目录下的html文件
html_path = os.path.join(os.path.dirname(__file__), 'resources', '仙逆人物志.html')
with open(html_path, 'r', encoding='utf-8') as f:
html_text = f.read()
#print(html_text)
#解析html文本,将其转化为一个文档
document = html.fromstring(html_text)
# 解析表头 - Xpath语法
th_list = document.xpath('//table/thead/tr/th/text()')
print(th_list)
#遍历tr
td_list = document.xpath('//table/tbody/tr[1]/td/text()')
print(td_list)
#遍历tr中的每一个
tr_list = document.xpath('//table/tbody/tr')
for tr in tr_list :
td_list = tr.xpath('./td/text()')
print(td_list)
Xpath语法总结

爬取电影网站数据实例
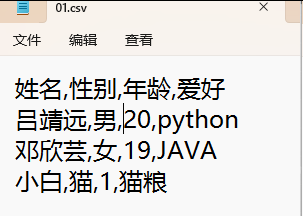
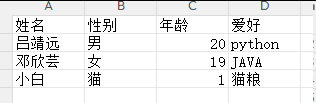
CSV
CSV(Comma-Separted Values,逗号分隔值):是一种简单、通用的文本格式,用于储存表格数据,可以直接用Excel打开。(要用英文逗号,csv后缀,系统编码保存)
import os
import csv
script_dir = os.path.dirname(os.path.abspath(__file__))
csv_dir = os.path.join(script_dir, "csv_data")
os.makedirs(csv_dir, exist_ok=True)
#csv操作1: 创建csv文件
# with open(os.path.join(csv_dir, "01.csv"), "w", encoding="utf-8", newline='') as f:
# f.write("姓名,性别,年龄,爱好\n")
# f.write("小王,男,18,'football,java'\n")
# f.write("小李,女,19,basketball\n")
# f.write("小张,男,20,swimming\n")
# f.write("小王,女,21,runa\n")
# 读取
# with open(os.path.join(csv_dir, "01.csv"), "r", encoding="utf-8") as f:
# for line in f:
# print(line.strip())
#csv操作2:
#写入
with open(os.path.join(csv_dir, "02.csv"), "w", encoding="utf-8", newline='') as f:
writer = csv.DictWriter(f, fieldnames=["姓名","性别","年龄","爱好"])
writer.writeheader()
writer.writerow({"姓名":"小王","性别":"男","年龄":"18","爱好":"football,java"})
writer.writerow({"姓名":"小李","性别":"女","年龄":"19","爱好":"basketball"})
writer.writerow({"姓名":"小张","性别":"男","年龄":"20","爱好":"swimming"})
writer.writerow({"姓名":"小王","性别":"女","年龄":"21","爱好":"ran"})
#读取
with open(os.path.join(csv_dir, "02.csv"), "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
print(row)代码总结
import requests
import csv
from lxml import html
#常量
MOVIE_LIST_FILE = 'csv_data/movies_list.csv'
TMDB_BASE_URL = 'https://www.themoviedb.org'
TMDB_TOP_URL = 'https://www.themoviedb.org/movie/top-rated'
#主函数,定义核心逻辑
#保存电影数据
def save_all_movies(all_movies):
with open(MOVIE_LIST_FILE, 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=["电影名", "上映年份", "上映日期", "类型", "时长", "评分", "语言", "导演", "作者", "宣传语", "简介"])
writer.writeheader()
writer.writerows(all_movies)
#获取电影详情
def get_movie_info(movie_url):
#发送请求,获取电影详情数据
movie_response = requests.get(movie_url,timeout = 60)
print(f"发送请求{movie_url},获取电影详情数据成功")
#解析数据,获取电影详情
movie_doc = html.fromstring(movie_response.text)
names = movie_doc.xpath('//meta[@property="og:title"]/@content')[0]
years = movie_doc.xpath('//span[contains(@class, "release_date")]/text()')
dates = movie_doc.xpath('//span[@class="release"]/text()')
tags = movie_doc.xpath('//a[contains(@href, "/genre/")]/text()')
cost_times = movie_doc.xpath('//span[@class="runtime"]/text()')
scores = movie_doc.xpath('//div[contains(@class, "user_score")]/@data-percent')
lang_ps = movie_doc.xpath('//section[contains(@class, "facts")]//p[contains(., "默认语言")]')
# 导演、作者
crew_names = movie_doc.xpath('//li[contains(@class, "profile")]//a/text()')
crew_roles = movie_doc.xpath('//li[contains(@class, "profile")]//p/text()')
directors = [crew_names[i] for i, r in enumerate(crew_roles) if 'Director' in r]
writers = [crew_names[i] for i, r in enumerate(crew_roles) if any(w in r for w in ['Screenplay', 'Novel', 'Writer'])]
# 宣传语
taglines = movie_doc.xpath('//*[contains(@class, "tagline")]/text()')
# 简介
overviews = movie_doc.xpath('//meta[@property="og:description"]/@content')
movie_name = names
movie_year = years[0].strip("()") if years else ""
movie_date = dates[0].strip() if dates else ""
movie_tags = tags
movie_runtime = cost_times[0].strip() if cost_times else ""
movie_score = scores[0] if scores else ""
movie_language = lang_ps[0].xpath('string()').replace("默认语言", "").strip() if lang_ps else ""
movie_director = directors[0] if directors else ""
movie_writer = writers[0] if writers else ""
movie_tagline = taglines[0].strip() if taglines else ""
movie_overview = overviews[0] if overviews else ""
# print(movie_name)
# print(f" 年份: {movie_year}")
# print(f" 上映日期: {movie_date}")
# print(f" 类型: {movie_tags}")
# print(f" 时长: {movie_runtime}")
# print(f" 评分: {movie_score}%")
# print(f" 语言: {movie_language}")
# print(f" 导演: {movie_director}")
# print(f" 作者: {movie_writer}")
# print(f" 宣传语: {movie_tagline}")
# print(f" 简介: {movie_overview[:80]}...")
#3、返回电影详情
movie_info = {
"电影名": movie_name,
"上映年份": movie_year,
"上映日期": movie_date,
"类型": ",".join(movie_tags) if movie_tags else "",
"时长": movie_runtime,
"评分": movie_score,
"语言": movie_language,
"导演": movie_director,
"作者": movie_writer,
"宣传语": movie_tagline,
"简介": movie_overview
}
# print(movie_info)
return movie_info
def main():
#1、发送请求,获得电影榜单数据
response = requests.get(TMDB_TOP_URL,timeout = 60)
#2、解析数据,获取电影列表
document = html.fromstring(response.text)
movie_list = document.xpath('//div[contains(@class, "poster-card")]')
#3、遍历电影列表,获取电影详情
all_movies = []
for movie in movie_list:
movie_urls = movie.xpath(".//a[contains(@href, '/movie/')]/@href")
if movie_urls:
movie_info_url = TMDB_BASE_URL + movie_urls[0]
#发送请求,获取电影详情数据
movie_info = get_movie_info(movie_info_url)
all_movies.append(movie_info)
#4、保存数据,写入csv文件
print("保存数据中...")
save_all_movies(all_movies)
if __name__ == '__main__':
main()
代码解析
# 🛠️ 环境准备
# 在开始之前,请确保你的Python环境中安装了以下第三方库:
# pip install requests lxml
# 注:csv 和 os 是Python内置库,无需额外安装。
#
# 🧠 核心逻辑拆解
# 整个爬虫项目的流程可以分为四个标准步骤:
# 发送请求 -> 解析列表页 -> 解析详情页 -> 保存数据
# ==============================================================================
import requests
import csv
import os
from lxml import html
# ================= 1. 常量定义与目录准备 =================
# 首先定义好我们要抓取的URL和文件保存路径。
MOVIE_LIST_FILE = 'csv_data/movies_list.csv'
TMDB_BASE_URL = 'https://www.themoviedb.org'
TMDB_TOP_URL = 'https://www.themoviedb.org/movie/top-rated'
# 确保保存数据的目录存在,防止写入CSV时报错
os.makedirs('csv_data', exist_ok=True)
# ================= 4. 数据持久化:保存为CSV =================
# 使用Python内置的 csv.DictWriter,可以直接将字典列表写入CSV,非常适合这种结构化的爬虫数据。
# 💡 笔记重点:这里编码使用了 utf-8-sig 而不是 utf-8,这是为了防止用Excel打开CSV文件时出现中文乱码!
def save_all_movies(all_movies):
"""将电影数据列表保存为CSV文件"""
with open(MOVIE_LIST_FILE, 'w', encoding='utf-8-sig', newline='') as f:
# 定义表头
fieldnames = ["电影名", "上映年份", "上映日期", "类型", "时长", "评分", "语言", "导演", "作者", "宣传语", "简介"]
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # 写入表头
writer.writerows(all_movies) # 批量写入数据
print(f"✅ 成功保存 {len(all_movies)} 条数据至 {MOVIE_LIST_FILE}")
# ================= 3. 详情页解析:XPath大显身手 =================
# 这是整个项目最核心、最难的部分。TMDB的详情页包含大量信息,我们需要用XPath精准定位。
#
# 重点XPath语法解析:
# - 获取电影名:利用Meta标签的OG协议获取。 //meta[@property="og:title"]/@content
# - 获取上映年份:利用 contains 模糊匹配class名。 //span[contains(@class, "release_date")]/text()
# - 获取导演和编剧:这里用了一个巧妙的列表推导式。先分别提取所有主创的名字和职位,
# 然后通过索引对应,筛选出职位包含 "Director" 或 "Writer" 的人。
#
# 数据清洗与容错处理:
# 网页数据往往是不规范的,或者某些电影缺少某项数据(比如没有宣传语)。
# 因此我们在提取后必须做判空和去空格处理。
def get_movie_info(movie_url, headers):
"""获取并解析单部电影的详情数据"""
try:
movie_response = requests.get(movie_url, headers=headers, timeout=60)
movie_response.raise_for_status() # 检查请求是否成功
print(f"🔍 正在抓取: {movie_url}")
movie_doc = html.fromstring(movie_response.text)
# 1. 基础信息提取
names = movie_doc.xpath('//meta[@property="og:title"]/@content')
years = movie_doc.xpath('//span[contains(@class, "release_date")]/text()')
dates = movie_doc.xpath('//span[@class="release"]/text()')
tags = movie_doc.xpath('//a[contains(@href, "/genre/")]/text()')
cost_times = movie_doc.xpath('//span[@class="runtime"]/text()')
scores = movie_doc.xpath('//div[contains(@class, "user_score")]/@data-percent')
# 2. 语言提取 (注意:如果是中文界面是"默认语言",英文界面是"Original Language")
lang_ps = movie_doc.xpath('//section[contains(@class, "facts")]//p[contains(., "默认语言") or contains(., "Original Language")]')
# 3. 导演与作者提取 (列表推导式应用)
crew_names = movie_doc.xpath('//li[contains(@class, "profile")]//a/text()')
crew_roles = movie_doc.xpath('//li[contains(@class, "profile")]//p/text()')
directors = [crew_names[i] for i, r in enumerate(crew_roles) if 'Director' in r]
writers = [crew_names[i] for i, r in enumerate(crew_roles) if any(w in r for w in ['Screenplay', 'Novel', 'Writer'])]
# 4. 宣传语与简介
taglines = movie_doc.xpath('//*[contains(@class, "tagline")]/text()')
overviews = movie_doc.xpath('//meta[@property="og:description"]/@content')
# 5. 数据清洗与组装 (判空和去空格处理,例如:如果years列表有值,取第一个并去掉括号;否则返回空字符串)
movie_info = {
"电影名": names[0] if names else "",
"上映年份": years[0].strip("()") if years else "",
"上映日期": dates[0].strip() if dates else "",
"类型": ",".join(tags) if tags else "",
"时长": cost_times[0].strip() if cost_times else "",
"评分": scores[0] if scores else "",
"语言": lang_ps[0].xpath('string()').replace("默认语言", "").replace("Original Language", "").strip() if lang_ps else "",
"导演": directors[0] if directors else "",
"作者": writers[0] if writers else "",
"宣传语": taglines[0].strip() if taglines else "",
"简介": overviews[0] if overviews else ""
}
return movie_info
except Exception as e:
print(f"❌ 抓取失败 {movie_url}, 错误信息: {e}")
return None
# ================= 2. 主函数:统筹全局 =================
# 主函数负责控制整体流程。首先请求排行榜页面,提取出所有电影的详情页链接,然后循环请求详情页。
def main():
# 1. 添加请求头,伪装成浏览器,防止被基础反爬拦截
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
print("🚀 开始抓取TMDB高分电影排行榜...")
response = requests.get(TMDB_TOP_URL, headers=headers, timeout=60)
# 2. 解析列表页,获取电影详情链接
document = html.fromstring(response.text)
movie_list = document.xpath('//div[contains(@class, "poster-card")]')
# 3. 遍历列表,抓取详情
all_movies = []
for movie in movie_list:
# 提取相对路径并拼接成完整URL
movie_urls = movie.xpath(".//a[contains(@href, '/movie/')]/@href")
if movie_urls:
movie_info_url = TMDB_BASE_URL + movie_urls[0]
movie_info = get_movie_info(movie_info_url, headers)
if movie_info:
all_movies.append(movie_info)
# 4. 保存数据
if all_movies:
print("数据抓取完毕,正在保存...")
save_all_movies(all_movies)
else:
print("⚠️ 未抓取到任何数据,请检查网络或XPath规则。")
# 修复了原代码中 if name == 'main': 的拼写错误,正确的Python标准写法是 __name__ == '__main__'
if __name__ == '__main__':
main()💡 踩坑与进阶建议
在跟着老师敲完代码后,我自己总结了几点可以优化的方向,这也是从“初学者”向“进阶者”迈进的关键:
1. **修正语法错误**:原代码结尾写的是 `if name == 'main':`,这会导致主函数根本不会执行!正确的Python标准写法是 `if __name__ == '__main__':`(注意前后各有两个下划线)。
2. **反爬虫对抗**:TMDB有一定的反爬机制。如果不加 `User-Agent`,请求很容易被拒绝(返回403)。在优化版代码中我加上了请求头。如果抓取频率过高,建议加入 `time.sleep(2)` 进行延时,或者使用代理IP。
3. **异常处理(Try-Except)**:网络请求是不稳定的,如果某一部电影请求超时,原代码会导致整个程序崩溃。我在 `get_movie_info` 中加入了 `try-except`,保证一部电影失败不影响其他电影的抓取。
4. **语言本地化问题**:TMDB的网页语言会根据你的IP或Cookie变化。代码中提取语言时使用了 `contains(., "默认语言")`,如果你的网络环境默认是英文网页,这里需要改成 `Original Language`(优化版代码中已做兼容处理)。
5. **Excel乱码问题**:使用 `utf-8` 保存CSV时,用Excel打开中文会乱码。将编码改为 `utf-8-sig`(带BOM的UTF-8)就能完美解决。
## 🎯 总结
通过这个实战项目,我深刻理解了 请求-解析-存储 经典三步曲。特别是 `lxml` 的 `XPath` 语法,虽然一开始看那些 `//`、`contains` 觉得像天书,但掌握后发现它比正则表达式在解析HTML时好用太多了!
我们下一个项目见!👋

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)