【矩阵系列·第四篇】奇异值分解(SVD):最重要的矩阵分解,图像压缩、推荐系统、LoRA 的数学基础
【矩阵系列·第四篇】奇异值分解(SVD):最重要的矩阵分解,图像压缩、推荐系统、LoRA 的数学基础
作者:技术博主 | 更新时间:2026-05-17 | 阅读时长:约 26 分钟
系列:矩阵完全指南(共 6 篇)
环境:Python 3.12 + NumPy + PyTorch
标签:SVD奇异值分解低秩近似图像压缩LoRA推荐系统伪逆深度学习矩阵分解
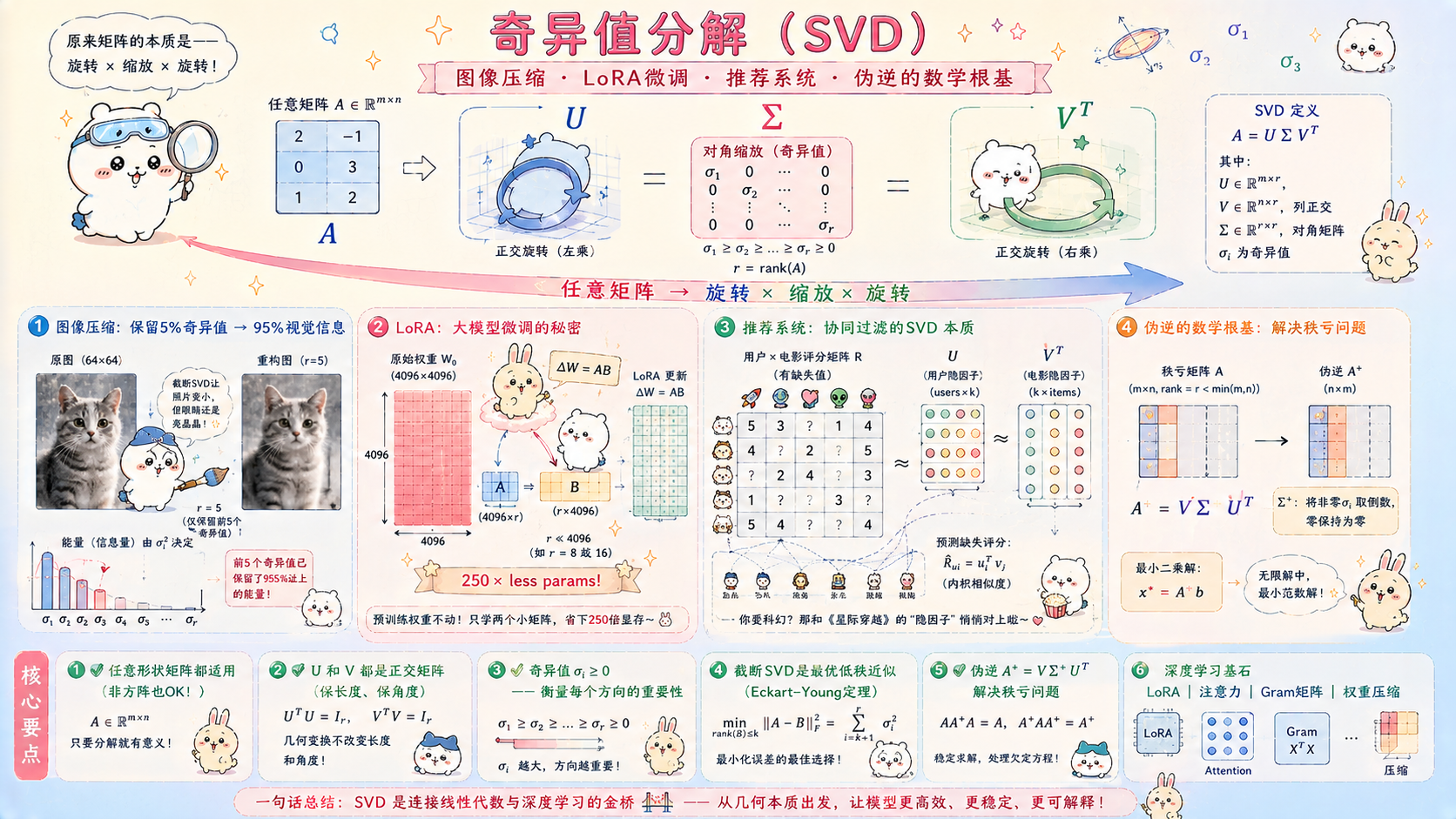
🔥 本篇目标:SVD(奇异值分解)是线性代数中最强大的工具,没有之一。它把任意矩阵分解为"旋转 × 缩放 × 旋转",揭示了矩阵的本质结构——哪些方向重要、哪些方向是噪声。更重要的是,它直接支撑了现代深度学习的多个核心技术:LoRA(大模型微调)用低秩 SVD 近似权重更新;注意力机制的权重矩阵本质是低秩结构;图像压缩用截断 SVD 以 5% 的存储保留 95% 的视觉信息。本篇把 SVD 的数学推导和深度学习应用串在一起,让每一行公式都有落地场景。
系列进度
| 篇次 | 主题 | 状态 |
|---|---|---|
| 第一篇 | 矩阵是什么:线性变换的语言 | ✅ 已发布 |
| 第二篇 | 矩阵分解:LU、QR、Cholesky | ✅ 已发布 |
| 第三篇 | 特征值与特征向量:矩阵的"骨架" | ✅ 已发布 |
| 第四篇(本篇) | 奇异值分解:图像压缩、LoRA、推荐系统 | — |
| 第五篇 | 矩阵在深度学习中:从线性层到注意力机制 | 即将发布 |
| 第六篇 | 数值线性代数:条件数、稀疏矩阵、GPU 计算 | 即将发布 |
目录
- 一、SVD 的几何直觉:任意矩阵 = 旋转 × 缩放 × 旋转
- 二、SVD 的数学推导
- 三、三种 SVD 形式:完全、简化、截断
- 四、低秩近似:Eckart-Young 定理
- 五、深度学习应用1:图像压缩与重建
- 六、深度学习应用2:LoRA——大模型微调的秘密
- 七、深度学习应用3:推荐系统中的矩阵分解
- 八、伪逆:秩亏矩阵的最小二乘解
- 九、SVD 与特征分解的关系
- 十、完整代码汇总
- 十一、面试高频问题
一、SVD 的几何直觉:任意矩阵 = 旋转 × 缩放 × 旋转
1.1 从特征分解的局限说起
import numpy as np
import torch
import torch.nn as nn
# 第三篇的特征分解 A = P Λ P^{-1}
# 局限:
# ① 只适用于方阵
# ② P 不一定是正交矩阵(P^{-1} ≠ P^T)
# ③ 特征值可能是复数
# 典型的深度学习场景:权重矩阵 W ∈ R^{m×n},m ≠ n
W = np.random.randn(512, 768) # 线性层权重(非方阵)
# 无法对 W 做特征分解!
# SVD 的突破:对任意形状矩阵都适用
U, s, Vt = np.linalg.svd(W, full_matrices=False)
print(f"W 形状:{W.shape}")
print(f"U 形状:{U.shape}") # (512, 512)
print(f"s 形状:{s.shape}") # (512,) 奇异值向量
print(f"Vt 形状:{Vt.shape}") # (512, 768)
print(f"重建误差:{np.abs(W - U @ np.diag(s) @ Vt).max():.2e}")
1.2 几何三步分解
对 2D 变换矩阵 A(m×n),SVD 说:
A = U Σ V^T
对任意向量 v,变换 Av 可以分三步理解:
Step 1:V^T v
用 V^T(正交矩阵)做旋转/反射
把输入向量旋转到奇异向量坐标系
Step 2:Σ(V^T v)
用对角矩阵 Σ 做缩放
每个方向被独立地放大/缩小(奇异值 σ₁ ≥ σ₂ ≥ ... ≥ 0)
Step 3:U(Σ V^T v)
用 U(正交矩阵)再做旋转/反射
把结果旋转到输出坐标系
核心洞察:
矩阵的"大小"体现在奇异值上
σ₁ 最大:V 的第1列方向是输入中"最重要"的方向
对应 U 的第1列是输出中"最重要"的方向
越小的奇异值对应越"不重要"的方向
# 可视化 SVD 的三步分解(2×2 例子)
A = np.array([[3., 1.],
[1., 3.]])
U, s, Vt = np.linalg.svd(A)
Sigma = np.diag(s)
print(f"A = U Σ V^T")
print(f"U =\n{U.round(4)}")
print(f"Σ = diag({s.round(4)})")
print(f"V^T =\n{Vt.round(4)}")
# 验证:U 和 V 都是正交矩阵
print(f"\nU^T U(应为I):\n{(U.T @ U).round(4)}")
print(f"V^T V(应为I):\n{(Vt.T @ Vt).round(4)}") # V = Vt.T
# 验证重建
print(f"\n重建误差:{np.abs(A - U @ Sigma @ Vt).max():.2e}")
# 奇异值与特征值的关系(对称正定矩阵时)
eigenvalues = np.linalg.eigvalsh(A)[::-1] # 降序
print(f"\n奇异值:{s.round(4)}")
print(f"特征值:{eigenvalues.round(4)}")
# 对对称正定矩阵,奇异值 = 特征值
print(f"对于此对称矩阵,奇异值 = 特征值?{np.allclose(s, eigenvalues)}")
二、SVD 的数学推导
2.1 从 A^T A 和 A A^T 出发
# SVD 的推导路径:
# 1. A^T A 是对称半正定矩阵(第三篇的谱定理适用)
# 2. A^T A 的特征向量就是 SVD 中的 V(右奇异向量)
# 3. 奇异值 σᵢ = √λᵢ(A^T A 的特征值的平方根)
# 4. 左奇异向量 u_i = A v_i / σᵢ
def svd_from_scratch(A: np.ndarray) -> tuple:
"""
从 A^T A 的特征分解推导 SVD
A = U @ Sigma @ Vt
"""
m, n = A.shape
# Step 1:计算 A^T A((n×n) 对称半正定矩阵)
AtA = A.T @ A
# Step 2:特征分解 A^T A = V Λ V^T
eigenvalues, V = np.linalg.eigh(AtA) # 按升序返回
# 按降序排列(最大奇异值在前)
idx = np.argsort(eigenvalues)[::-1]
eigenvalues = eigenvalues[idx]
V = V[:, idx]
# Step 3:奇异值 = 特征值的平方根(截断负数误差)
singular_values = np.sqrt(np.maximum(eigenvalues, 0))
# Step 4:左奇异向量 u_i = A v_i / σ_i
r = np.sum(singular_values > 1e-10) # 数值秩
U = np.zeros((m, r))
for i in range(r):
U[:, i] = A @ V[:, i] / singular_values[i]
# 如果 m > r,补充正交基(完全 SVD 需要)
# 简化版:只返回简化 SVD
Sigma = singular_values[:r]
Vt = V[:, :r].T
return U, Sigma, Vt
# 验证
A = np.random.randn(5, 3)
U_scratch, s_scratch, Vt_scratch = svd_from_scratch(A)
A_reconstructed = U_scratch @ np.diag(s_scratch) @ Vt_scratch
print(f"自实现 SVD 重建误差:{np.abs(A - A_reconstructed).max():.2e}")
# 与 NumPy 对比
U_np, s_np, Vt_np = np.linalg.svd(A, full_matrices=False)
print(f"奇异值比较:{np.allclose(s_scratch, s_np)}")
2.2 奇异值的物理意义
# 奇异值 σᵢ 表示矩阵在第 i 个"模式"上的强度
# 例:用随机矩阵演示
np.random.seed(42)
A_rand = np.random.randn(100, 50)
_, s_rand, _ = np.linalg.svd(A_rand, full_matrices=False)
# 随机矩阵:奇异值分布相对均匀(Marchenko-Pastur 定律)
print("随机矩阵的前10个奇异值:")
print(s_rand[:10].round(3))
print(f"最大/最小奇异值比(条件数):{s_rand[0]/s_rand[-1]:.2f}")
# 低秩结构矩阵:奇异值快速衰减
# 模拟神经网络权重矩阵(实际中通常有低秩结构)
rank_5_matrix = np.random.randn(100, 5) @ np.random.randn(5, 50)
noise = 0.01 * np.random.randn(100, 50)
A_lowrank = rank_5_matrix + noise
_, s_lr, _ = np.linalg.svd(A_lowrank, full_matrices=False)
print("\n低秩(真实秩=5)矩阵的前10个奇异值:")
print(s_lr[:10].round(4))
print("(前5个大,后5个接近噪声水平)")
# 这揭示了 LoRA 的本质:
# 预训练权重矩阵 → 低秩结构(大部分信息在前几个奇异值)
# 微调只需更新低秩部分(ΔW = AB,A∈R^{m×r},B∈R^{r×n})
三、三种 SVD 形式:完全、简化、截断
m, n = 6, 4 # m > n 的常见情形
A = np.random.randn(m, n)
# ── 完全 SVD(Full SVD)──────────────────────────────────────
# U: (m×m),Σ: (m×n)(右下角全零),V: (n×n)
U_full, s_full, Vt_full = np.linalg.svd(A, full_matrices=True)
Sigma_full = np.zeros((m, n))
Sigma_full[:n, :n] = np.diag(s_full)
print(f"完全 SVD:U{U_full.shape} × Σ{Sigma_full.shape} × V^T{Vt_full.shape}")
print(f" 重建误差:{np.abs(A - U_full @ Sigma_full @ Vt_full).max():.2e}")
# ── 简化 SVD(Thin/Economy SVD)──────────────────────────────
# U: (m×k),Σ: (k,),V: (k×n),其中 k = min(m,n)
U_thin, s_thin, Vt_thin = np.linalg.svd(A, full_matrices=False)
print(f"\n简化 SVD:U{U_thin.shape} × Σ{(len(s_thin),)} × V^T{Vt_thin.shape}")
print(f" 重建误差:{np.abs(A - U_thin @ np.diag(s_thin) @ Vt_thin).max():.2e}")
# ── 截断 SVD(Truncated SVD)─────────────────────────────────
# 只保留前 r 个奇异值(低秩近似)
r = 2 # 秩
U_r = U_thin[:, :r]
s_r = s_thin[:r]
Vt_r = Vt_thin[:r, :]
A_approx = U_r @ np.diag(s_r) @ Vt_r
error = np.linalg.norm(A - A_approx, 'fro')
total = np.linalg.norm(A, 'fro')
print(f"\n截断 SVD(r={r}):U{U_r.shape} × Σ{(r,)} × V^T{Vt_r.shape}")
print(f" Frobenius 误差:{error:.4f}(占总范数的 {error/total*100:.1f}%)")
print(f" 保留信息比例:{(1 - error/total)*100:.1f}%")
# 节省的存储空间
original_params = m * n
approx_params = m * r + r + r * n # U_r + s_r + Vt_r
print(f"\n 原始参数数:{original_params}")
print(f" 近似参数数:{approx_params}(压缩比 {original_params/approx_params:.1f}×)")
四、低秩近似:Eckart-Young 定理
4.1 定理内容
min rank ( B ) ≤ r ∥ A − B ∥ F = ∥ A − A r ∥ F = σ r + 1 2 + σ r + 2 2 + ⋯ + σ k 2 \min_{\text{rank}(B) \leq r} \|A - B\|_F = \|A - A_r\|_F = \sqrt{\sigma_{r+1}^2 + \sigma_{r+2}^2 + \cdots + \sigma_k^2} rank(B)≤rmin∥A−B∥F=∥A−Ar∥F=σr+12+σr+22+⋯+σk2
截断 SVD 给出的秩- r r r 近似,是所有秩- r r r 矩阵中距离 A A A 最近的。
def low_rank_approx(A: np.ndarray, r: int) -> np.ndarray:
"""最优秩-r 近似(Eckart-Young 定理)"""
U, s, Vt = np.linalg.svd(A, full_matrices=False)
return U[:, :r] @ np.diag(s[:r]) @ Vt[:r, :]
def approx_error(A: np.ndarray, r: int) -> float:
"""秩-r 近似的理论误差(奇异值的尾部范数)"""
_, s, _ = np.linalg.svd(A, full_matrices=False)
return np.sqrt((s[r:]**2).sum())
# 验证 Eckart-Young 定理
A = np.random.randn(8, 6)
_, s, _ = np.linalg.svd(A, full_matrices=False)
print("Eckart-Young 定理验证:")
print(f"{'秩r':^5} {'理论误差':^12} {'实际误差':^12} {'一致?':^8}")
print("─" * 42)
for r in range(1, len(s)):
theory = approx_error(A, r)
actual = np.linalg.norm(A - low_rank_approx(A, r), 'fro')
match = "✅" if np.allclose(theory, actual, rtol=1e-5) else "❌"
print(f"{r:^5} {theory:^12.6f} {actual:^12.6f} {match:^8}")
# 关键推论:保留多少奇异值 = 保留多少信息
def explained_energy(s: np.ndarray, r: int) -> float:
"""前 r 个奇异值解释的"能量"比例"""
return (s[:r]**2).sum() / (s**2).sum()
A = np.random.randn(50, 30)
_, s, _ = np.linalg.svd(A, full_matrices=False)
print("\n奇异值能量分布:")
for r in [1, 3, 5, 10, 20, 30]:
energy = explained_energy(s, r)
bar = "█" * int(energy * 30)
print(f" 前{r:2d}个奇异值:{energy*100:.1f}% {bar}")
五、深度学习应用1:图像压缩与重建
import torch
import numpy as np
def compress_image_channel(channel: np.ndarray, r: int) -> np.ndarray:
"""
用截断 SVD 压缩图像的单个通道
channel:二维灰度图像矩阵 (H, W)
r:保留的奇异值数量(秩)
返回:压缩后重建的图像
"""
U, s, Vt = np.linalg.svd(channel, full_matrices=False)
# 截断:只保留前 r 个奇异值
compressed = U[:, :r] @ np.diag(s[:r]) @ Vt[:r, :]
# 截断到 [0,255] 范围
return np.clip(compressed, 0, 255)
def analyze_compression(H: int = 64, W: int = 64):
"""
分析不同压缩率下的图像质量
用随机合成图像演示(真实场景替换为实际图像)
"""
# 生成合成图像(低频主导,模拟真实图像的特性)
x = np.linspace(0, 4*np.pi, W)
y = np.linspace(0, 4*np.pi, H)
XX, YY = np.meshgrid(x, y)
image = (128 + 64*np.sin(XX) + 32*np.cos(2*YY) +
16*np.sin(3*XX + YY) + 8*np.random.randn(H, W))
image = np.clip(image, 0, 255)
U, s, Vt = np.linalg.svd(image, full_matrices=False)
total_singular_values = len(s)
print(f"图像尺寸:{H}×{W},总像素:{H*W}")
print(f"奇异值数量:{total_singular_values}")
print(f"\n{'秩r':^6} {'存储比例':^10} {'PSNR(dB)':^10} {'压缩比':^10} {'信息保留':^10}")
print("─" * 52)
for r in [1, 2, 5, 10, 20, total_singular_values]:
# 压缩后的存储量(H×r + r + r×W 个数)
compressed_size = H*r + r + r*W
original_size = H * W
storage_ratio = compressed_size / original_size
compression_ratio= original_size / compressed_size
# 重建质量(PSNR)
reconstructed = compress_image_channel(image, r)
mse = ((image - reconstructed)**2).mean()
psnr = 10 * np.log10(255**2 / (mse + 1e-10))
# 信息保留比例(奇异值能量)
info_retained = (s[:r]**2).sum() / (s**2).sum()
marker = " ← 原图" if r == total_singular_values else ""
print(f" r={r:3d} {storage_ratio:^10.3f} {psnr:^10.1f} "
f"{compression_ratio:^10.1f}× {info_retained*100:^8.1f}%{marker}")
print(f"\n实际图像(如照片)的典型规律:")
print(f" r = 总秩的 5% → PSNR ≈ 30dB(视觉可接受)")
print(f" r = 总秩的 10% → PSNR ≈ 35dB(高质量)")
print(f" r = 总秩的 20% → 视觉几乎无损")
analyze_compression(H=64, W=64)
# ── 彩色图像:对 RGB 三通道分别压缩 ──────────────────────────
def compress_rgb_image(image_rgb: np.ndarray, r: int) -> np.ndarray:
"""
对 RGB 图像的每个通道独立做 SVD 压缩
image_rgb:(H, W, 3) uint8
r:保留的奇异值数量
"""
compressed = np.zeros_like(image_rgb, dtype=float)
for c in range(3): # R、G、B 三个通道
compressed[:, :, c] = compress_image_channel(
image_rgb[:, :, c].astype(float), r
)
return np.clip(compressed, 0, 255).astype(np.uint8)
# 与深度学习的联系:
# 卷积神经网络的权重张量 W ∈ R^{C_out × C_in × kH × kW}
# 可以展平为矩阵后做 SVD 压缩
# 实际的神经网络权重压缩方案(如 Monarch Matrices)正是基于此思想
def compress_conv_weight(weight: torch.Tensor, rank_ratio: float = 0.5) -> dict:
"""
用 SVD 压缩卷积层权重
weight:(C_out, C_in, kH, kW)
rank_ratio:保留的秩比例
"""
C_out, C_in, kH, kW = weight.shape
# 展平为 2D 矩阵
W_2d = weight.view(C_out, -1).numpy() # (C_out, C_in*kH*kW)
r = max(1, int(min(W_2d.shape) * rank_ratio))
U, s, Vt = np.linalg.svd(W_2d, full_matrices=False)
U_r, s_r, Vt_r = U[:, :r], s[:r], Vt[:r, :]
original_params = W_2d.size
compressed_params = C_out*r + r + r*W_2d.shape[1]
compression = original_params / compressed_params
return {
"U": torch.tensor(U_r, dtype=torch.float32),
"s": torch.tensor(s_r, dtype=torch.float32),
"Vt": torch.tensor(Vt_r, dtype=torch.float32),
"rank": r,
"compression": compression,
"energy": (s_r**2).sum() / (s**2).sum(),
}
# 测试
conv_layer = nn.Conv2d(64, 128, kernel_size=3)
result = compress_conv_weight(conv_layer.weight.data, rank_ratio=0.25)
print(f"\n卷积权重 SVD 压缩(秩比例 25%):")
print(f" 保留秩:{result['rank']}")
print(f" 压缩比:{result['compression']:.1f}×")
print(f" 保留能量:{result['energy']*100:.1f}%")
六、深度学习应用2:LoRA——大模型微调的秘密
6.1 LoRA 的核心思想
问题:微调大语言模型(LLaMA-70B 有 700 亿参数)
全量微调:更新所有 700 亿参数 → 需要几百 GB 显存
→ 普通 GPU 根本跑不起来
LoRA 的关键洞察(Hu et al. 2021):
预训练权重矩阵 W₀ ∈ R^{m×n} 的更新量 ΔW 是低秩的!
ΔW 的大部分奇异值接近 0,只有少数方向有效
因此用低秩分解近似 ΔW:
ΔW = A @ B^T,A ∈ R^{m×r},B ∈ R^{n×r},r << min(m,n)
前向传播:y = W₀ x + ΔW x = W₀ x + A (B^T x)
只有 A 和 B 需要更新(参数量:m*r + n*r << m*n)
参数节省:
原始参数:m × n = 4096 × 4096 ≈ 1670 万
LoRA 参数:r × (m + n) = 8 × 8192 ≈ 6.6 万(节省约 250 倍)
6.2 LoRA 的完整实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class LoRALinear(nn.Module):
"""
带 LoRA 的线性层
论文:LoRA: Low-Rank Adaptation of Large Language Models
"""
def __init__(
self,
in_features: int,
out_features: int,
r: int = 8, # LoRA 秩
lora_alpha: float = 16.0, # 缩放因子(实际缩放 = alpha/r)
lora_dropout: float = 0.1,
merge_weights: bool = False, # 推理时合并权重
):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.r = r
self.scaling = lora_alpha / r # 论文中的 α/r 缩放
# 原始预训练权重(冻结,不更新)
self.weight = nn.Parameter(
torch.randn(out_features, in_features), requires_grad=False
)
# LoRA 权重(只更新这两个矩阵)
if r > 0:
# A:用高斯初始化(确保初始 ΔW 有信号)
self.lora_A = nn.Parameter(torch.randn(r, in_features))
# B:初始化为全零(确保训练开始时 ΔW = 0,不破坏预训练)
self.lora_B = nn.Parameter(torch.zeros(out_features, r))
self.lora_dropout = nn.Dropout(lora_dropout)
# 初始化 A(标准正态 / √fan_in)
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
self.merged = False
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 原始权重的输出(W₀ x)
result = F.linear(x, self.weight)
if self.r > 0 and not self.merged:
# LoRA 增量输出:(B @ A @ x^T)^T × scaling
# = x @ A^T @ B^T × scaling
lora_output = (
self.lora_dropout(x) @ self.lora_A.T @ self.lora_B.T
) * self.scaling
result = result + lora_output
return result
def merge_lora_weights(self):
"""
推理加速:把 LoRA 权重合并到主权重
合并后 ΔW = B @ A,计算量与原始线性层相同
"""
if self.r > 0 and not self.merged:
self.weight.data += (self.lora_B @ self.lora_A) * self.scaling
self.merged = True
print(f"LoRA 权重已合并(秩={self.r},缩放={self.scaling:.2f})")
def unmerge_lora_weights(self):
"""撤销合并(恢复可训练状态)"""
if self.r > 0 and self.merged:
self.weight.data -= (self.lora_B @ self.lora_A) * self.scaling
self.merged = False
# ── 参数量对比 ────────────────────────────────────────────────
def compare_lora_parameters():
in_dim, out_dim = 4096, 4096
# 标准线性层
standard_linear = nn.Linear(in_dim, out_dim)
std_params = sum(p.numel() for p in standard_linear.parameters())
# LoRA 线性层(不同秩)
print(f"输入维度:{in_dim},输出维度:{out_dim}")
print(f"标准线性层参数量:{std_params:,}")
print(f"\n{'LoRA 秩r':^10} {'LoRA参数':^12} {'节省比例':^12} {'LoRA占比':^10}")
print("─" * 48)
for r in [1, 2, 4, 8, 16, 32, 64]:
lora_layer = LoRALinear(in_dim, out_dim, r=r)
trainable = sum(p.numel() for p in lora_layer.parameters()
if p.requires_grad)
saving_ratio = 1 - trainable / std_params
lora_ratio = trainable / std_params
print(f" r={r:4d} {trainable:^12,} {saving_ratio*100:^10.1f}% {lora_ratio*100:^8.2f}%")
compare_lora_parameters()
# ── LoRA 的 SVD 解释 ──────────────────────────────────────────
def analyze_lora_from_svd():
"""
从 SVD 角度理解 LoRA:
为什么低秩近似 ΔW 是合理的?
"""
print("\nLoRA 的 SVD 视角:")
print("="*55)
# 模拟一次微调过程:全量微调前后的权重差
torch.manual_seed(42)
W_pretrained = torch.randn(256, 256) # 预训练权重
# 模拟微调(实际中是梯度更新后的权重)
# 关键假设:真实的 ΔW 是低秩的
true_rank = 5
delta_W_true = (torch.randn(256, true_rank) @
torch.randn(true_rank, 256)) * 0.1 + \
0.01 * torch.randn(256, 256) # 低秩 + 小噪声
# 分析 ΔW 的奇异值分布
U, s, Vt = torch.linalg.svd(delta_W_true)
energy = (s**2).cumsum(0) / (s**2).sum()
print("ΔW 的奇异值能量累积(低秩结构验证):")
for r in [1, 2, 5, 10, 20, 50]:
print(f" 前{r:3d}个奇异值覆盖能量:{energy[r-1]*100:.1f}%")
# LoRA 近似质量
for r in [2, 5, 10]:
delta_W_lora = U[:, :r] @ torch.diag(s[:r]) @ Vt[:r, :]
err = (delta_W_true - delta_W_lora).norm() / delta_W_true.norm()
print(f"\n LoRA(r={r}) 近似相对误差:{err*100:.2f}%")
analyze_lora_from_svd()
七、深度学习应用3:推荐系统中的矩阵分解
7.1 协同过滤的矩阵视角
# 用户-物品评分矩阵(大量缺失值)
# 行 = 用户,列 = 电影,值 = 评分(0 = 未评分)
# 矩阵分解的目标:
# R ≈ U @ V^T
# U ∈ R^{n_users × k}:用户的隐向量表示(k 维偏好)
# V ∈ R^{n_items × k}:物品的隐向量表示(k 维特征)
# k:隐因子数量(类似 SVD 的秩)
# 用户 i 对物品 j 的预测评分:u_i · v_j(点积)
class MatrixFactorization(nn.Module):
"""
矩阵分解推荐模型
学习用户和物品的低维嵌入
"""
def __init__(
self,
n_users: int,
n_items: int,
n_factors: int = 32, # 隐因子数(对应 SVD 的秩)
dropout: float = 0.1,
):
super().__init__()
# 用户嵌入 U:(n_users, n_factors)
self.user_embed = nn.Embedding(n_users, n_factors)
# 物品嵌入 V:(n_items, n_factors)
self.item_embed = nn.Embedding(n_items, n_factors)
# 偏置(用户的整体评分偏好、物品的平均热度)
self.user_bias = nn.Embedding(n_users, 1)
self.item_bias = nn.Embedding(n_items, 1)
self.dropout = nn.Dropout(dropout)
# 初始化
nn.init.normal_(self.user_embed.weight, std=0.01)
nn.init.normal_(self.item_embed.weight, std=0.01)
nn.init.zeros_(self.user_bias.weight)
nn.init.zeros_(self.item_bias.weight)
def forward(
self,
user_ids: torch.Tensor, # (batch,)
item_ids: torch.Tensor, # (batch,)
) -> torch.Tensor:
# 用户和物品的嵌入向量
u = self.dropout(self.user_embed(user_ids)) # (batch, k)
v = self.dropout(self.item_embed(item_ids)) # (batch, k)
# 点积(用户对物品的兴趣强度)
dot = (u * v).sum(dim=-1) # (batch,)
# 加偏置
bias = self.user_bias(user_ids).squeeze() + self.item_bias(item_ids).squeeze()
# 预测评分(通常限制在 1-5 范围)
return torch.sigmoid(dot + bias) * 4 + 1 # 映射到 [1, 5]
# ── 合成数据测试 ──────────────────────────────────────────────
def train_mf_demo():
torch.manual_seed(42)
n_users, n_items = 100, 200
n_factors = 16
# 生成合成评分数据(低秩结构)
true_k = 5 # 真实隐因子数
U_true = torch.randn(n_users, true_k)
V_true = torch.randn(n_items, true_k)
# 生成观测到的评分(不是所有用户都评了所有物品)
R_true = torch.clamp(U_true @ V_true.T + 3, 1, 5)
# 随机采样 20% 的评分作为训练集
all_indices = [(i, j) for i in range(n_users) for j in range(n_items)]
np.random.shuffle(all_indices)
n_train = int(0.2 * len(all_indices))
train_idx = all_indices[:n_train]
user_ids = torch.tensor([i for i,j in train_idx])
item_ids = torch.tensor([j for i,j in train_idx])
ratings = torch.tensor([R_true[i,j].item() for i,j in train_idx])
# 训练
model = MatrixFactorization(n_users, n_items, n_factors)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)
criterion = nn.MSELoss()
model.train()
for epoch in range(200):
optimizer.zero_grad()
pred = model(user_ids, item_ids)
loss = criterion(pred, ratings)
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
rmse = torch.sqrt(loss).item()
print(f" Epoch {epoch+1}: RMSE = {rmse:.4f}")
return model
print("矩阵分解推荐模型训练:")
model = train_mf_demo()
# 分析学到的嵌入(SVD 视角)
with torch.no_grad():
U_learned = model.user_embed.weight.numpy()
V_learned = model.item_embed.weight.numpy()
# 这些嵌入本质上是用户-物品矩阵的近似低秩分解
_, s_U, _ = np.linalg.svd(U_learned, full_matrices=False)
print(f"\n用户嵌入的奇异值(前5):{s_U[:5].round(3)}")
print(f"(奇异值的分布反映了隐因子的重要性)")
八、伪逆:秩亏矩阵的最小二乘解
8.1 伪逆的定义与 SVD 计算
def pseudoinverse_via_svd(A: np.ndarray, tol: float = None) -> np.ndarray:
"""
用 SVD 计算 Moore-Penrose 伪逆 A⁺
A⁺ = V Σ⁺ U^T
其中 Σ⁺:把 Σ 的非零奇异值取倒数(零奇异值保持为零)
"""
U, s, Vt = np.linalg.svd(A, full_matrices=False)
# 数值阈值(处理接近 0 的奇异值)
if tol is None:
tol = max(A.shape) * np.finfo(float).eps * s.max()
# 奇异值的倒数(小于阈值的置为 0)
s_inv = np.where(s > tol, 1.0 / s, 0.0)
# A⁺ = V @ diag(s_inv) @ U^T
return Vt.T @ np.diag(s_inv) @ U.T
# ── 验证四个 Moore-Penrose 条件 ──────────────────────────────
# ① A A⁺ A = A
# ② A⁺ A A⁺ = A⁺
# ③ (A A⁺)^T = A A⁺(对称)
# ④ (A⁺ A)^T = A⁺ A(对称)
A = np.random.randn(5, 3) # 过定方程组(m > n)
A_pinv = pseudoinverse_via_svd(A)
print("Moore-Penrose 伪逆验证:")
print(f" ① A A⁺ A = A?{np.allclose(A @ A_pinv @ A, A)}")
print(f" ② A⁺ A A⁺ = A⁺?{np.allclose(A_pinv @ A @ A_pinv, A_pinv)}")
print(f" ③ (A A⁺)^T = A A⁺?{np.allclose((A @ A_pinv).T, A @ A_pinv)}")
print(f" ④ (A⁺ A)^T = A⁺ A?{np.allclose((A_pinv @ A).T, A_pinv @ A)}")
# 与 NumPy 内置伪逆对比
A_pinv_np = np.linalg.pinv(A)
print(f"\n 与 NumPy pinv 差异:{np.abs(A_pinv - A_pinv_np).max():.2e}")
# ── 伪逆的三种场景 ────────────────────────────────────────────
def demo_pseudoinverse():
b = np.array([1., 2., 3., 4., 5.])
# 情况1:超定(m > n,过定方程组)→ 最小范数最小二乘解
A1 = np.random.randn(5, 3)
x1 = np.linalg.pinv(A1) @ b
print(f"\n超定方程组 (5×3):")
print(f" ||Ax - b|| = {np.linalg.norm(A1 @ x1 - b):.4f}(最小二乘)")
print(f" ||x|| = {np.linalg.norm(x1):.4f}(最小范数解)")
# 情况2:欠定(m < n,欠定方程组)→ 无穷多解中范数最小的
A2 = np.random.randn(3, 5)
b2 = A2 @ np.ones(5) # 确保有解
x2 = np.linalg.pinv(A2) @ b2
print(f"\n欠定方程组 (3×5):")
print(f" ||Ax - b|| = {np.linalg.norm(A2 @ x2 - b2):.6f}(满足方程组)")
print(f" ||x|| = {np.linalg.norm(x2):.4f}(最小范数解)")
# 情况3:方阵但奇异
A3 = np.array([[1., 2.], [2., 4.]]) # 秩亏方阵
b3 = np.array([1., 2.]) # b 在列空间中
x3 = np.linalg.pinv(A3) @ b3
print(f"\n奇异方阵 (2×2,秩=1):")
print(f" 解 x = {x3.round(4)}")
print(f" ||Ax - b|| = {np.linalg.norm(A3 @ x3 - b3):.6f}")
# 深度学习联系:
# 梯度下降在过参数化网络(参数 >> 数据)中
# 会隐式找到伪逆解(最小范数解)
# 这解释了为什么过参数化模型泛化好(bias-complexity tradeoff)
demo_pseudoinverse()
九、SVD 与特征分解的关系
# 核心关系:
# 如果 A = U Σ V^T(SVD),那么:
# A^T A = V Σ^T U^T U Σ V^T = V (Σ^T Σ) V^T = V Σ² V^T
# → A^T A 的特征向量 = A 的右奇异向量(V 的列)
# → A^T A 的特征值 = A 的奇异值的平方(σᵢ²)
# 同理:
# A A^T = U Σ² U^T
# → A A^T 的特征向量 = A 的左奇异向量(U 的列)
A = np.random.randn(4, 3)
U, s, Vt = np.linalg.svd(A, full_matrices=False)
# 验证:A^T A 的特征分解
AtA = A.T @ A
evals_AtA, evecs_AtA = np.linalg.eigh(AtA)
evals_AtA = evals_AtA[::-1]
evecs_AtA = evecs_AtA[:, ::-1]
print("SVD 与特征分解的关系验证:")
print(f"\nA 的奇异值²:{(s**2).round(4)}")
print(f"A^T A 的特征值:{evals_AtA.round(4)}")
print(f"一致?{np.allclose(s**2, evals_AtA)}")
print(f"\nA 的右奇异向量(V)列绝对值:")
print(np.abs(Vt.T).round(4))
print(f"A^T A 的特征向量列绝对值:")
print(np.abs(evecs_AtA).round(4))
print(f"一致?{np.allclose(np.abs(Vt.T), np.abs(evecs_AtA), atol=1e-6)}")
# ── 深度学习中的 Gram 矩阵 ───────────────────────────────────
# 卷积神经网络的风格迁移(Gram matrix style)
# G = F F^T,F ∈ R^{C×HW}(特征图展平)
# G 的大特征值/奇异值对应主要的纹理风格
# Transformer 的注意力矩阵也是类似的结构
# Attention(Q,K,V) = softmax(QK^T/√d_k)V
# QK^T 是两个矩阵的积,其秩受 d_k 限制
def analyze_attention_rank():
"""分析注意力矩阵的秩结构"""
batch, heads, seq_len, d_k = 1, 8, 64, 32
Q = torch.randn(batch, heads, seq_len, d_k)
K = torch.randn(batch, heads, seq_len, d_k)
# 注意力分数矩阵 QK^T
scores = Q @ K.transpose(-2, -1) / math.sqrt(d_k) # (1, 8, 64, 64)
scores_np = scores[0, 0].detach().numpy() # 第一个头
U, s, Vt = np.linalg.svd(scores_np)
print(f"\n注意力分数矩阵的奇异值分析:")
print(f" 矩阵形状:{scores_np.shape}")
print(f" 理论最大秩:min({seq_len}, {seq_len}) = {min(seq_len, seq_len)}")
print(f" 有效秩(s > 0.01 × s_max):{(s > 0.01*s[0]).sum()}")
print(f" 前5个奇异值:{s[:5].round(3)}")
print(f" (实际中经过 softmax 后,注意力矩阵通常更低秩)")
import math
analyze_attention_rank()
十、完整代码汇总
"""
svd_complete.py
SVD 的核心功能:分解、低秩近似、伪逆、LoRA
"""
import numpy as np
import torch
import torch.nn as nn
def svd_analysis(A: np.ndarray, name: str = "A") -> dict:
"""
对矩阵 A 做完整的 SVD 分析
返回:奇异值、左右奇异向量、秩、条件数、各秩的近似误差
"""
U, s, Vt = np.linalg.svd(A, full_matrices=False)
rank = np.sum(s > 1e-10 * s[0])
cond_num = s[0] / s[rank-1] if rank > 0 else np.inf
print(f"\nSVD 分析:{name}(形状 {A.shape})")
print(f" 数值秩:{rank}")
print(f" 条件数:{cond_num:.2f}")
print(f" 最大奇异值:{s[0]:.4f}")
print(f" 最小非零奇异值:{s[rank-1]:.4f}")
# 奇异值能量分布
energy = (s**2).cumsum() / (s**2).sum()
thresholds = [0.5, 0.8, 0.9, 0.95, 0.99]
print(f" 达到各能量阈值所需的秩:")
for thresh in thresholds:
r_needed = np.searchsorted(energy, thresh) + 1
print(f" {thresh*100:.0f}%:r = {r_needed}(占总秩 {r_needed/rank*100:.0f}%)")
return {
"U": U, "s": s, "Vt": Vt,
"rank": rank, "condition_number": cond_num,
"energy": energy,
}
def low_rank_error_curve(A: np.ndarray) -> list[tuple]:
"""计算每个秩值的近似误差(Frobenius 范数)"""
_, s, _ = np.linalg.svd(A, full_matrices=False)
total = np.linalg.norm(A, 'fro')
results = []
for r in range(1, len(s)+1):
err = np.sqrt((s[r:]**2).sum())
ratio = err / total
results.append((r, err, ratio))
return results
def apply_lora(
W: torch.Tensor, # 原始权重(冻结)
x: torch.Tensor, # 输入
A: torch.Tensor, # LoRA 下投影
B: torch.Tensor, # LoRA 上投影
alpha: float,
r: int,
) -> torch.Tensor:
"""LoRA 前向传播"""
scaling = alpha / r
return x @ W.T + (x @ A.T @ B.T) * scaling
# ── 运行完整演示 ──────────────────────────────────────────────
if __name__ == "__main__":
np.random.seed(42)
# 1. 神经网络权重矩阵分析
W_linear = np.random.randn(256, 512)
result = svd_analysis(W_linear, "线性层权重 W")
# 2. 低秩近似误差曲线
errors = low_rank_error_curve(W_linear)
print("\n低秩近似误差(前10个秩):")
print(f"{'秩':^6} {'误差':^10} {'相对误差':^12}")
for r, err, ratio in errors[:10]:
print(f"{r:^6} {err:^10.4f} {ratio*100:^10.2f}%")
# 3. LoRA 参数效率
in_dim, out_dim = 4096, 4096
print(f"\nLoRA 参数效率({in_dim}×{out_dim} 权重矩阵):")
for r in [4, 8, 16, 32]:
lora_params = r * (in_dim + out_dim)
full_params = in_dim * out_dim
print(f" r={r:3d}: LoRA参数={lora_params:,},节省 {(1-lora_params/full_params)*100:.1f}%")
# 4. 伪逆
A_rect = np.random.randn(10, 5)
b_rect = np.random.randn(10)
x_pinv = np.linalg.pinv(A_rect) @ b_rect
print(f"\n伪逆最小二乘:||Ax-b|| = {np.linalg.norm(A_rect@x_pinv-b_rect):.4f}")
十一、面试高频问题
Q:SVD 和特征分解有什么区别?什么时候用哪个?
特征分解 A = P Λ P − 1 A = P\Lambda P^{-1} A=PΛP−1:只适用于方阵, P P P 不一定正交,特征值可以是复数,要求矩阵可对角化。SVD A = U Σ V ⊤ A = U\Sigma V^\top A=UΣV⊤:适用于任意形状矩阵, U U U 和 V V V 都是正交矩阵,奇异值都是实数且非负,永远存在。深度学习中:权重矩阵通常是长方形( d o u t × d i n d_{out} \times d_{in} dout×din),特征分解不可用;SVD 是唯一选择。对称正定矩阵(如协方差矩阵、 A ⊤ A A^\top A A⊤A)两者都可用,且奇异值等于特征值,用
eigh(更快更稳定)。
Q:LoRA 为什么用低秩矩阵,而不是稀疏矩阵更新?
低秩矩阵 Δ W = A B \Delta W = AB ΔW=AB( A ∈ R m × r A \in \mathbb{R}^{m \times r} A∈Rm×r, B ∈ R r × n B \in \mathbb{R}^{r \times n} B∈Rr×n)有几个关键优势:①结构连续:低秩矩阵在参数空间中是连续流形,梯度下降可以自然优化;稀疏矩阵需要选择哪些位置非零,是离散优化问题。②SVD 理论支撑:Eckart-Young 定理证明低秩矩阵是最优的"信息压缩"方式,对于具有低秩结构的真实 Δ W \Delta W ΔW,低秩近似的误差最小。③GPU 友好: A B AB AB 是两次标准矩阵乘法,GPU GEMM 天然高效;稀疏矩阵乘法需要专门的稀疏算子,不如稠密矩阵乘法快。
Q:截断 SVD 是最优低秩近似,但为什么图像压缩通常用 DCT(JPEG)而不是 SVD?
SVD 给出针对特定图像的最优低秩近似,但有两个工程问题:①编码开销:SVD 需要存储 U U U( m × r m \times r m×r)、 σ \sigma σ( r r r)、 V ⊤ V^\top V⊤( r × n r \times n r×n),并且 U U U 和 V V V 都是浮点矩阵,无法用整数量化;DCT 基函数是固定的(余弦函数),不需要存储,只需存储系数。②无法流式处理:SVD 需要看到整张图才能计算,不支持分块编码;JPEG 对 8 × 8 8 \times 8 8×8 的块独立做 DCT,可以流式处理。在矩阵理论层面,DCT 是 SVD 的特殊情况——对于"平滑的自然图像",DCT 基函数近似是协方差矩阵的特征向量,实践效果接近最优 SVD。
Q:矩阵的条件数和奇异值有什么关系?为什么大条件数意味着数值不稳定?
条件数 κ ( A ) = σ max / σ min \kappa(A) = \sigma_{\max} / \sigma_{\min} κ(A)=σmax/σmin(最大奇异值除以最小非零奇异值)。直觉:矩阵在 σ max \sigma_{\max} σmax 方向放大很多,在 σ min \sigma_{\min} σmin 方向放大很少,这两个方向的比值越大,矩阵越"形状极端"。求解 A x = b Ax = b Ax=b 时, b b b 的相对误差 δ b / ∥ b ∥ \delta b / \|b\| δb/∥b∥ 会被放大 κ ( A ) \kappa(A) κ(A) 倍到解 x x x 的相对误差。如果条件数是 10 10 10^{10} 1010,而浮点精度是 10 − 16 10^{-16} 10−16,那么解的有效数字只剩 16 − 10 = 6 16 - 10 = 6 16−10=6 位——数值灾难。病态矩阵(大条件数)在深度学习中对应:Hessian 矩阵病态 → 梯度方向不准确 → 训练震荡;这正是 BatchNorm 和适应性学习率(Adam)要解决的核心问题。
预告:第五篇
《矩阵系列·第五篇》矩阵在深度学习中:从线性层到注意力机制,每个操作背后的线性代数
将覆盖:
- 线性层 y = W x + b y = Wx + b y=Wx+b:矩阵乘法视角下的特征变换
- BatchNorm 的矩阵几何:投影到超球面
- 注意力机制 softmax ( Q K ⊤ / d k ) V \text{softmax}(QK^\top/\sqrt{d_k})V softmax(QK⊤/dk)V:秩、条件数与稳定性
- 反向传播是矩阵链式法则:Jacobian 矩阵的传递
- 权重初始化:为什么 He 初始化保持奇异值在合理范围
💬 你在工作中用过 LoRA 或其他低秩微调方法吗?选择秩 r 的经验是什么? 欢迎评论区分享!
🙏 如果这篇帮到你,点赞 + 收藏,系列更新中!
本文为原创技术分享。代码在 Python 3.12 + NumPy + PyTorch 下验证。最后更新:2026-05-17

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献235条内容
已为社区贡献235条内容

所有评论(0)