天机学堂2.0学习笔记
前言:首先感谢黑马程序员的开源项目,通过学习此项目,极大地提高了我对于AI智能应用的理解
一、浅谈SpringAI工作流程:
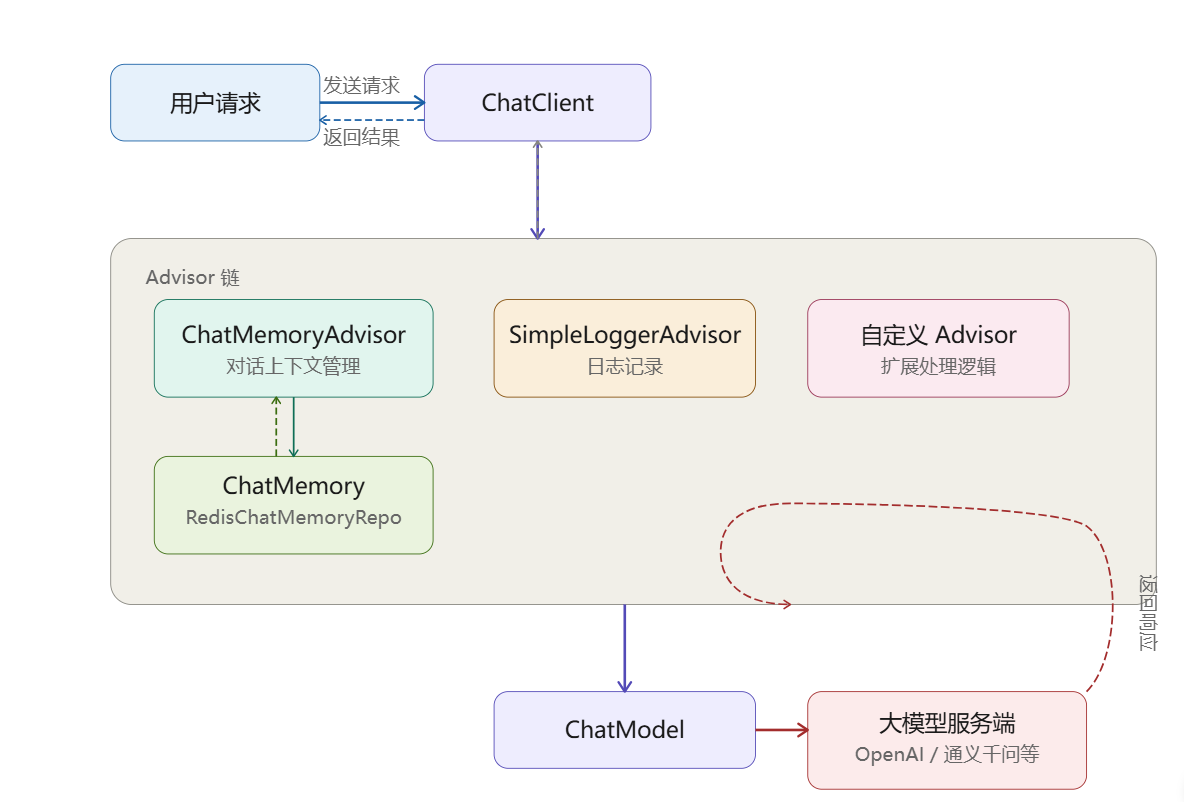
1. 入口:ChatClient
用户请求从 ChatClient 进入,它是对外统一 API,内部把请求交给 Advisor 链处理。
2. Advisor 链(核心拦截层,包含 Memory、Tool、Prompt 增强)
请求按顺序经过链式拦截器:
- ChatMemoryAdvisor:从
ChatMemory(如 Redis)读取历史对话,塞进 Prompt,实现多轮上下文。 - ToolCallAdvisor:把你用
ChatClient.tool()注册的 Tool(Java 方法)转成模型能识别的工具定义(JSON Schema),加入 Prompt。 - PromptTemplate / RAG Advisor:加入系统提示、检索文档、指令模板,最终组装成完整 Prompt。
3. 模型调用:ChatModel
Advisor 链处理完 → 增强后的 Prompt 交给 ChatModel → 调用大模型(OpenAI / 通义千问等)。
4. 模型响应 & Tool 自动执行(关键闭环)
- 模型返回:直接回答 或 需要调用工具(tool_calls)。
- 若要调用工具:
- ToolCallAdvisor 拦截响应
- 匹配并执行本地 Java Tool 方法
- 把工具结果写回 Prompt
- 再次调用模型,生成最终答案。
5. 结果回写 Memory & 返回用户
- ChatMemoryAdvisor 把最终回答存入 ChatMemory(持久化)。
- 响应沿 Advisor 链原路返回 → ChatClient → 给用户。
二、AI智能助手
(一)对话功能:
1、会话管理:
每次新建会话在数据库中创建一个sesson,同时支持查询历史对话,实现细节略
2、流式调用:返回Flux<String>类型
(返回结果不能进行包装)
Service类代码:
package com.tianji.aigc.service.impl;
import cn.hutool.core.date.DateUtil;
import com.tianji.aigc.config.SystemPromptConfig;
import com.tianji.aigc.enums.ChatEventTypeEnum;
import com.tianji.aigc.service.ChatService;
import com.tianji.aigc.vo.ChatEventVO;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
@Slf4j
@Service
@RequiredArgsConstructor
public class ChatServiceImpl implements ChatService {
private final ChatClient chatClient;
private final SystemPromptConfig systemPromptConfig;
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
return this.chatClient.prompt()
.system(promptSystem -> promptSystem
.text(this.systemPromptConfig.getChatSystemMessage().get()) // 设置系统提示语
.param("now", DateUtil.now()) // 设置当前时间的参数
)
.user(question)
.stream()
.chatResponse()
.map(chatResponse -> {
// 获取大模型的输出的内容
String text = chatResponse.getResult().getOutput().getText();
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.just(ChatEventVO.builder() // 标记输出结束
.eventType(ChatEventTypeEnum.STOP.getValue())
.build()));
}
}
3、提示词设计:
角色
你作为在线教育平台资深客服代表兼讲师。你的任务根据学员的需求,调用知识库中的课程信息,为学员推荐合适的课程,同时解答学员对课程内容和知识点的疑问。
技能 1: 课程推荐
1. 当学员提出课程推荐需求时,需判断是否提供必要信息。必要信息包含年龄、学历、是否有编程基础。
2. 若缺少必要信息,需礼貌追问。
3. 若学员未提供感兴趣的方向,需追问。若没有明确方向,优先推荐学习人数多的课程。
4. 若信息充足,根据必要信息和感兴趣的课程方向,去知识库匹配合适的课程,获取课程id,调用queryCourseById,根据课程id查询课程详细信息,为学员推荐课程,可推荐单门/多门课程。
5. 若知识库未包含学员感兴趣方向,需明确告知学员未提供该方向课程,并推荐其他课程。
6. 若必要信息未匹配合适课程,需提示学员您的情况与现有课程要求并不完全匹配,说明详细原因后,再推荐其他课程。
7. 推荐课程,必须要通过queryCourseById查询后,才能返回数据。
技能 2: 课程购买
1. 当学员提出购买课程时,需判断此次会话中,学员是否明确提出购买xx课/系统已为学员推荐课程。
2. 若已推荐/明确课程名称,需调用prePlaceOrder,根据此次上文已推荐/学员明确的课程,直接进入预下单流程。
3. 若未推荐课程,需引导学员进入到课程推荐流程。
4. 若学员未明确提出购买某门课程时,需询问用户购买哪门课程。
5. 支持购买一门/多门课程。
技能 3: 课程咨询
1. 当学员咨询课程内容时,需去知识库匹配合适的课程,获取课程id,根据课程id查询课程详细信息。回复的内容要全面,要引导学员报名购买。
2. 若未查询到,需礼貌告知学员未检索到相关的内容,请联系人工客服010-12345678。
3. 若咨询课程有效期,需将当前时间{now} 与 课程有效期相加,回复学员准确日期。课程有效期999天,代表永久有效。
技能 4: 知识讲解
1. 当学员咨询与IT相关的知识点内容时,需详细讲解知识点并提供示例。
限制:
- 推荐的课程只能从知识库中选择,坚决不能凭空编造
- 回答的内容要逻辑清晰、内容全面、不要有遗漏。
- 只能回答与课程和IT知识点相关的内容,若学员咨询与课程无关的内容,你需告知学员不能回答与课程和IT知识点无关的问题,并引导学员咨询与课程/IT知识点相关的问题。
- 若学员询问课程ID,则告知学员无法提供课程ID,引导学员咨询其他的问题。4、停止输出:
是在AI大模型生成的过程中,人为的打断输出,像这样
实现方法:控制Flux流的输出,这里用的是静态变量map,分布式中需要将其存储到redis中
package com.tianji.aigc.service.impl;
import cn.hutool.core.date.DateUtil;
import com.tianji.aigc.config.SystemPromptConfig;
import com.tianji.aigc.enums.ChatEventTypeEnum;
import com.tianji.aigc.service.ChatService;
import com.tianji.aigc.vo.ChatEventVO;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
@Slf4j
@Service
@RequiredArgsConstructor
public class ChatServiceImpl implements ChatService {
private final ChatClient chatClient;
private final SystemPromptConfig systemPromptConfig;
// 存储大模型的生成状态,这里采用ConcurrentHashMap是确保线程安全
// 目前的版本暂时用Map实现,如果考虑分布式环境的话,可以考虑用redis来实现
private static final Map<String, Boolean> GENERATE_STATUS = new ConcurrentHashMap<>();
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
return this.chatClient.prompt()
.system(promptSystem -> promptSystem
.text(this.systemPromptConfig.getChatSystemMessage().get()) // 设置系统提示语
.param("now", DateUtil.now()) // 设置当前时间的参数
)
.user(question)
.stream()
.chatResponse()
.doFirst(() -> GENERATE_STATUS.put(sessionId, true)) // 第一次输出内容时执行
.doOnError(throwable -> GENERATE_STATUS.remove(sessionId)) // 出现异常时,删除标识
.doOnComplete(() -> GENERATE_STATUS.remove(sessionId)) // 完成时执行,删除标识
.takeWhile(response -> { // 通过返回值来控制Flux流是否继续,true:继续,false:终止
return GENERATE_STATUS.getOrDefault(sessionId, false);
})
.map(chatResponse -> {
// 获取大模型的输出的内容
String text = chatResponse.getResult().getOutput().getText();
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.just(ChatEventVO.builder() // 标记输出结束
.eventType(ChatEventTypeEnum.STOP.getValue())
.build()));
}
@Override
public void stop(String sessionId) {
// 移除标记
GENERATE_STATUS.remove(sessionId);
}
}
5、会话记忆:
存储会话内容,存储方案有很多,比如可以存储到mysql数据库,也可以存储到MongoDB,在这里,我们选择存储到redis,之所以选择redis,是因为redis使用起来相对简单,查询速度也快。
SpringAI记忆工作流程:
1)用户发消息
2)beforeModel 钩子自动执
从 MemoryStore 加载长期记忆
塞进 SystemPrompt 里
3)AI 看到:对话历史 + 用户长期信息
4)AI 回答
5)afterModel 钩子自动执行
把新的偏好 / 信息存回 MemoryStore
这就是长期记忆机制。
SpringAI官方并没有提供redis存储的实现,所以,只能是自己实现了
首先写一个ChatMemoryRepository的Redis实现:
package com.tianji.aigc.memory;
import cn.hutool.core.collection.ListUtil;
import cn.hutool.core.lang.Assert;
import cn.hutool.json.JSONUtil;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.List;
/**
* 基于Redis实现的ChatMemoryRepository
*/
public class RedisChatMemoryRepository implements ChatMemoryRepository {
// 默认redis中key的前缀
public static final String DEFAULT_PREFIX = "CHAT:";
private final String prefix;
// 注入spring redis模板,进行redis的操作
@Resource
private StringRedisTemplate stringRedisTemplate;
public RedisChatMemoryRepository() {
this.prefix = DEFAULT_PREFIX;
}
public RedisChatMemoryRepository(String prefix) {
this.prefix = prefix;
}
@Override
public List<String> findConversationIds() {
Set<String> keys = this.stringRedisTemplate.keys(this.prefix + "*");
if (null == keys) {
return List.of();
}
return StreamUtil.of(keys)
.map(key -> StrUtil.replace(key, this.prefix, ""))
.toList();
}
@Override
public List<Message> findByConversationId(String conversationId) {
// 先不实现
return List.of();
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
Assert.notEmpty(messages, "消息列表不能为空");
var redisKey = this.getKey(conversationId);
var listOps = this.stringRedisTemplate.boundListOps(redisKey);
// 保存数据时,会传入全部的消息数据,包括之前的数据,所以需要先删除之前的数据,再添加新的数据
this.deleteByConversationId(conversationId);
// 将消息序列化并添加到Redis列表的右侧
messages.forEach(message -> listOps.rightPush(JSONUtil.toJsonStr(message)));
}
@Override
public void deleteByConversationId(String conversationId) {
var redisKey = this.getKey(conversationId);
this.stringRedisTemplate.delete(redisKey);
}
private String getKey(String conversationId) {
return prefix + conversationId;
}
}
然后注册Bean:ChatMemoryRepository, ChatMemory, Advisor
package com.tianji.aigc.config;
import com.tianji.aigc.memory.RedisChatMemoryRepository;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SpringAIConfig {
@Value("${tj.ai.memory.max:100}")
private Integer maxMessages;
/**
* 配置 ChatClient
*/
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder,
Advisor loggerAdvisor, // 日志记录器
Advisor messageChatMemoryAdvisor
) {
return chatClientBuilder
.defaultAdvisors(loggerAdvisor, messageChatMemoryAdvisor) //添加 Advisor 功能增强
.build();
}
/**
* 日志记录器
*/
@Bean
public Advisor loggerAdvisor() {
return new SimpleLoggerAdvisor();
}
@Bean
public ChatMemoryRepository redisChatMemoryRepository() {
return new RedisChatMemoryRepository();
}
@Bean
public ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
// 基于 chatMemoryRepository 对象构建 chatMemory 对象
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(this.maxMessages) // 最多保存 100 条对话, 如果超出的话,会自动删除最旧的对话
.build();
}
/**
* 基于Redis的会话记忆,聊天记忆整合到message列表中实现多轮对话
*/
@Bean
public Advisor messageChatMemoryAdvisor(ChatMemory chatMemory) {
// 创建基于 chatMemory 的 Advisor 对象
return MessageChatMemoryAdvisor.builder(chatMemory).build();
}
}
最后是修改Service实现:(标黄部分)
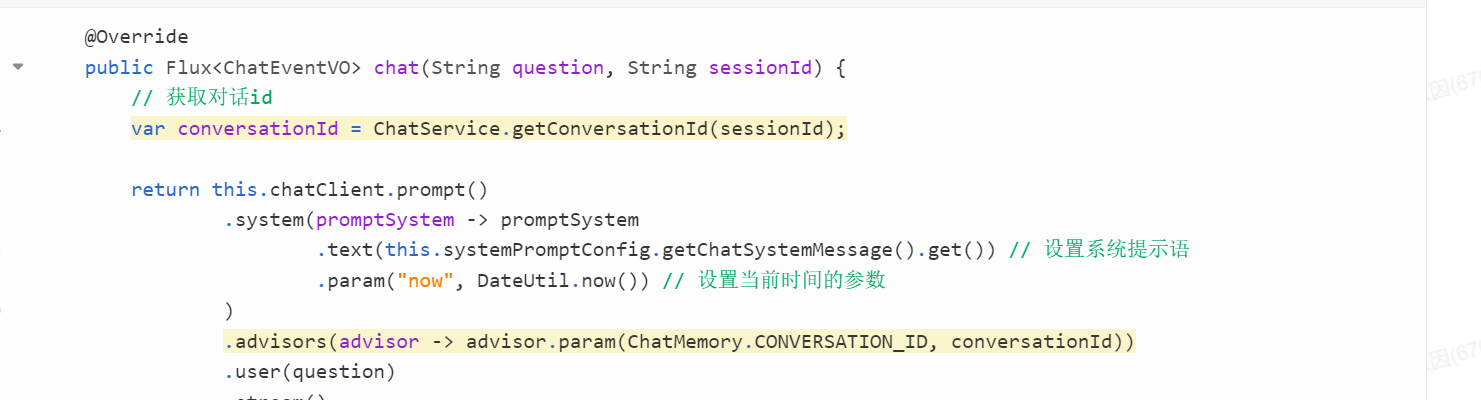
序列化问题:文本没有写入
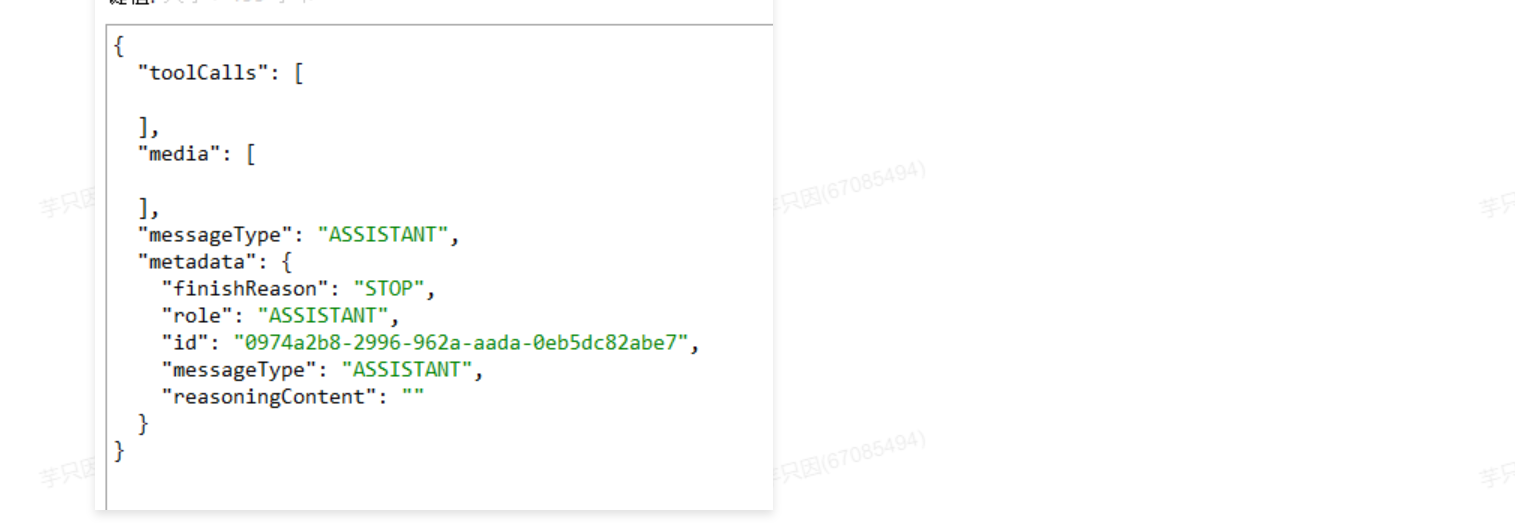
原因:
那是因为,org.springframework.ai.chat.messages.Message 接口的实现类org.springframework.ai.chat.messages.AbstractMessage中的textContent属性没有提供get方法,只提供了getText()方法,导致无法获取值。
当然了,不使用cn.hutool.json.JSONUtil,而是采用com.fasterxml.jackson.databind.ObjectMapper进行序列化,也是可以获取到值的,但是,在后面反序列化时也是会有问题的。
所以,我们不直接对org.springframework.ai.chat.messages.Message对象序列化,而是我们自定义一个对象,把值拷贝过来,进行做序列化,这样做的好处就是比较灵活,这个在后面也会有体现。
方法:设计一个MessageUtil和MyMessage,将Message对象转化为具有getter()方法的MyMessage类,然后进行序列化
(二)购买课程与知识库
1、基于Tool Calling实现AI课程查询功能
包含:
1Tool的定义、注册方法,以及代码优化手段,比如:字符串要写到常量类中
2在课程卡片功能中的知识点
-
- 给前端传递结构化的数据,不是大模型返回的
- 通过toolContext传递数据到tool中
- ToolResultHolder结构的设计
- tool中的结果数据,存储到容器,再传回输出流中
1基础实现:
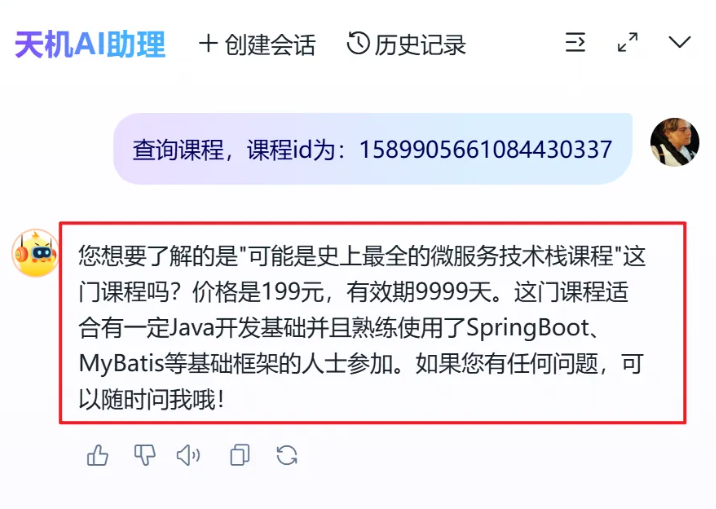
实现流程:
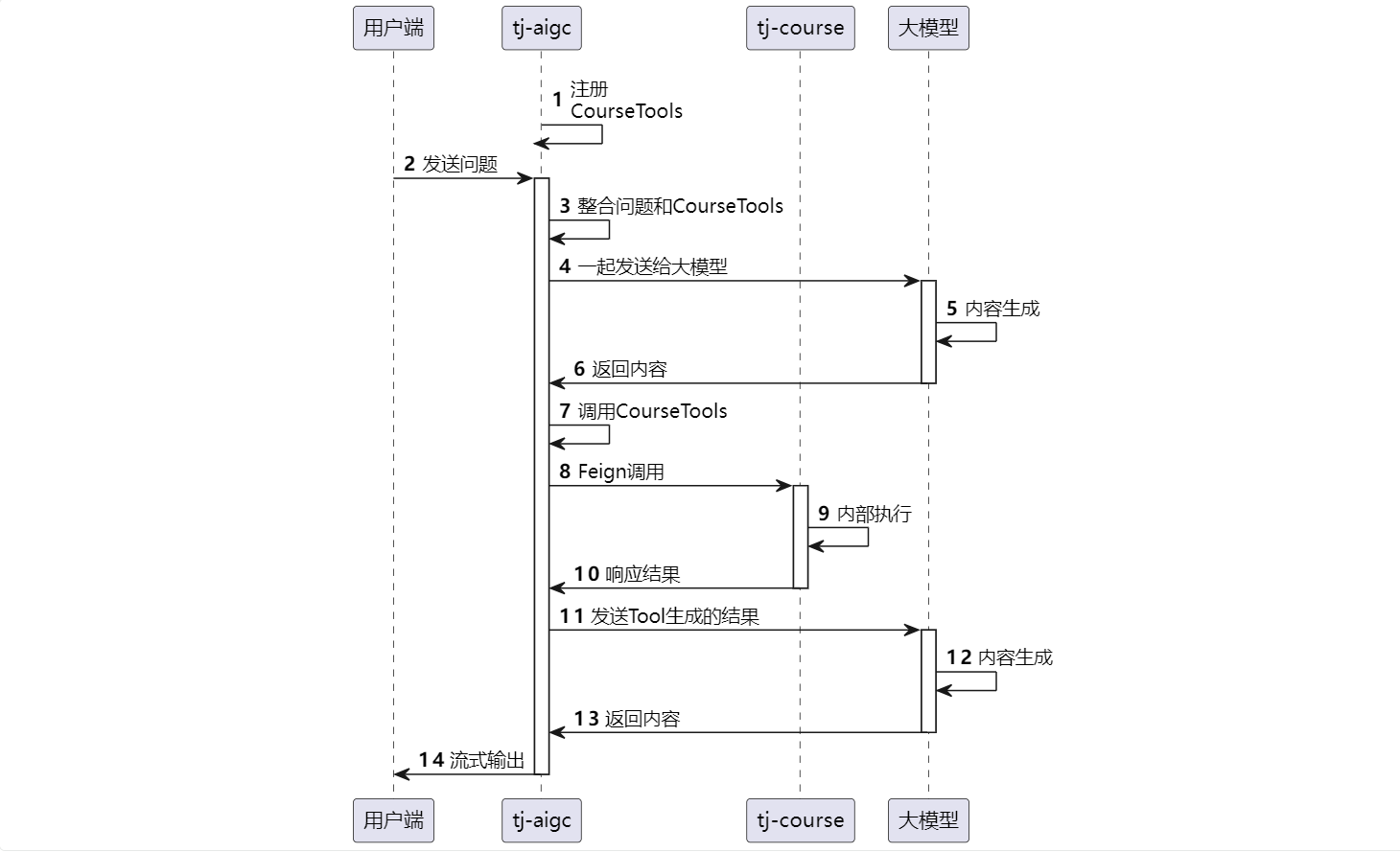
代码实现:
1)定义Tools返回的结果数据
package com.tianji.aigc.tools.result;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.util.NumberUtil;
import com.fasterxml.jackson.annotation.JsonPropertyDescription;
import com.tianji.api.dto.course.CourseBaseInfoDTO;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Optional;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class CourseInfo {
@JsonPropertyDescription("课程id")
private Long id;
@JsonPropertyDescription("课程名称")
private String name;
@JsonPropertyDescription("课程价格,单位为元,货币为人民币")
private double price;
@JsonPropertyDescription("课程学习有效期,单位:月")
private Integer validDuration;
@JsonPropertyDescription("适用人群,例如:初学者")
private String usePeople;
@JsonPropertyDescription("课程详细介绍")
private String detail;
/**
* 将CourseBaseInfoDTO转换为CourseInfo对象
*
* @param courseBaseInfoDTO 课程基础信息数据传输对象(包含原始课程数据)
* @return 转换后的课程信息实体对象(包含格式化后的价格和详情页URL)
*/
public static CourseInfo of(CourseBaseInfoDTO courseBaseInfoDTO) {
if (null == courseBaseInfoDTO) {
return null;
}
// 基础对象属性拷贝(忽略转换错误)
CourseInfo courseInfo = BeanUtil.toBeanIgnoreError(courseBaseInfoDTO, CourseInfo.class);
// 价格格式化处理:分转元 -> 四舍五入保留两位小数 -> 默认值0.0
courseInfo.setPrice(Optional.ofNullable(courseBaseInfoDTO.getPrice())
.map(num -> num.doubleValue() / 100d)
.map(num -> NumberUtil.round(num, 2).doubleValue())
.orElse(0.0d));
return courseInfo;
}
}2)定义tool
package com.tianji.aigc.tools;
import com.tianji.aigc.constants.Constant;
import com.tianji.aigc.tools.result.CourseInfo;
import com.tianji.api.client.course.CourseClient;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
@RequiredArgsConstructor
public class CourseTools {
private final CourseClient courseClient;
/**
* 根据课程id查询课程信息
*
* @param courseId 课程id
* @return 课程信息
*/
@Tool(description = Constant.Tools.QUERY_COURSE_BY_ID)
public CourseInfo queryCourseById(@ToolParam(description = Constant.ToolParams.COURSE_ID) Long courseId) {
return Optional.ofNullable(courseId)
.map(id -> CourseInfo.of(this.courseClient.baseInfo(id, true)))
.orElse(null);
}
}常量类:
package com.tianji.aigc.constants;
public interface Constant {
interface Tools {
String QUERY_COURSE_BY_ID = "根据课程id查询课程详细信息";
}
interface ToolParams {
String COURSE_ID = "课程id";
}
}3)注册tool: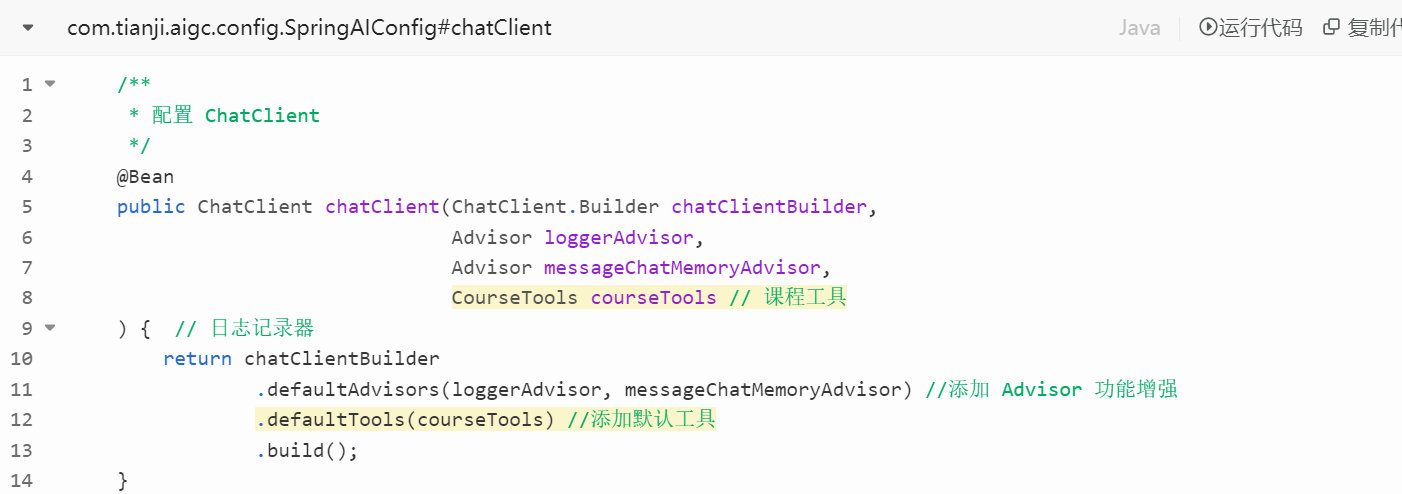
2课程卡片:
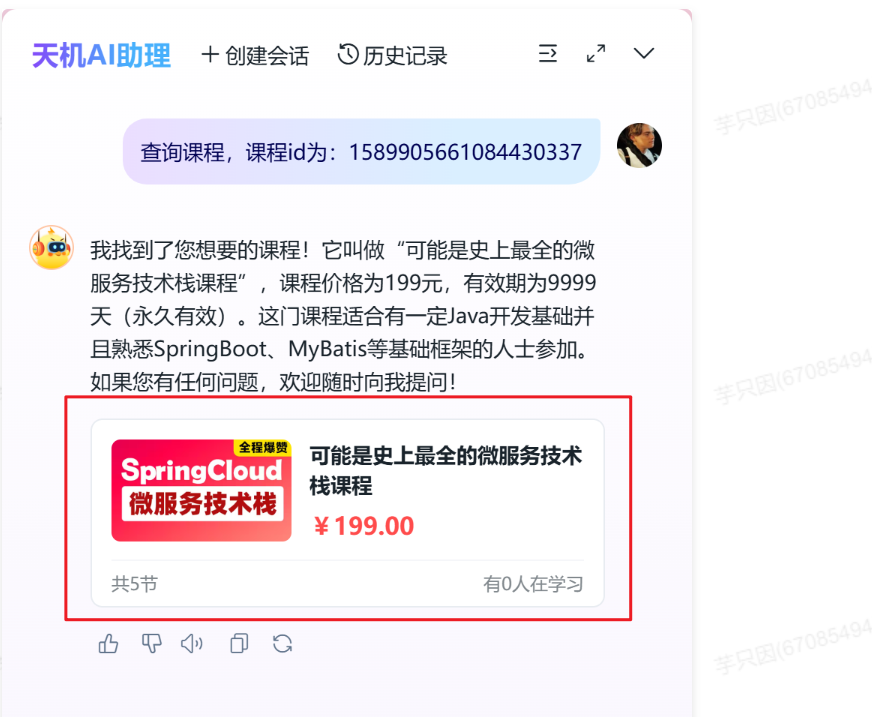
需求:
如果是查询课程,或推荐课程,需要展示出课程的卡片信息,其中,要显示课程的价格、名称等信息,还可以,点击卡片,跳转到课程详情页面。
实现分析:
要想实现这个效果,就必须给前端返回相应的参数数据,前端才能展示卡片,但是,上述的内容,都是大模型返回的,都是些文字数据,而我们需要给前端的是格式化的数据,例如json数据,该怎么做呢?
实际上,就是在Flux输出流的最后,做判断,如果调用了工具,拿到工具的结果,追加到输出流的结束标签之前即可。像这样:
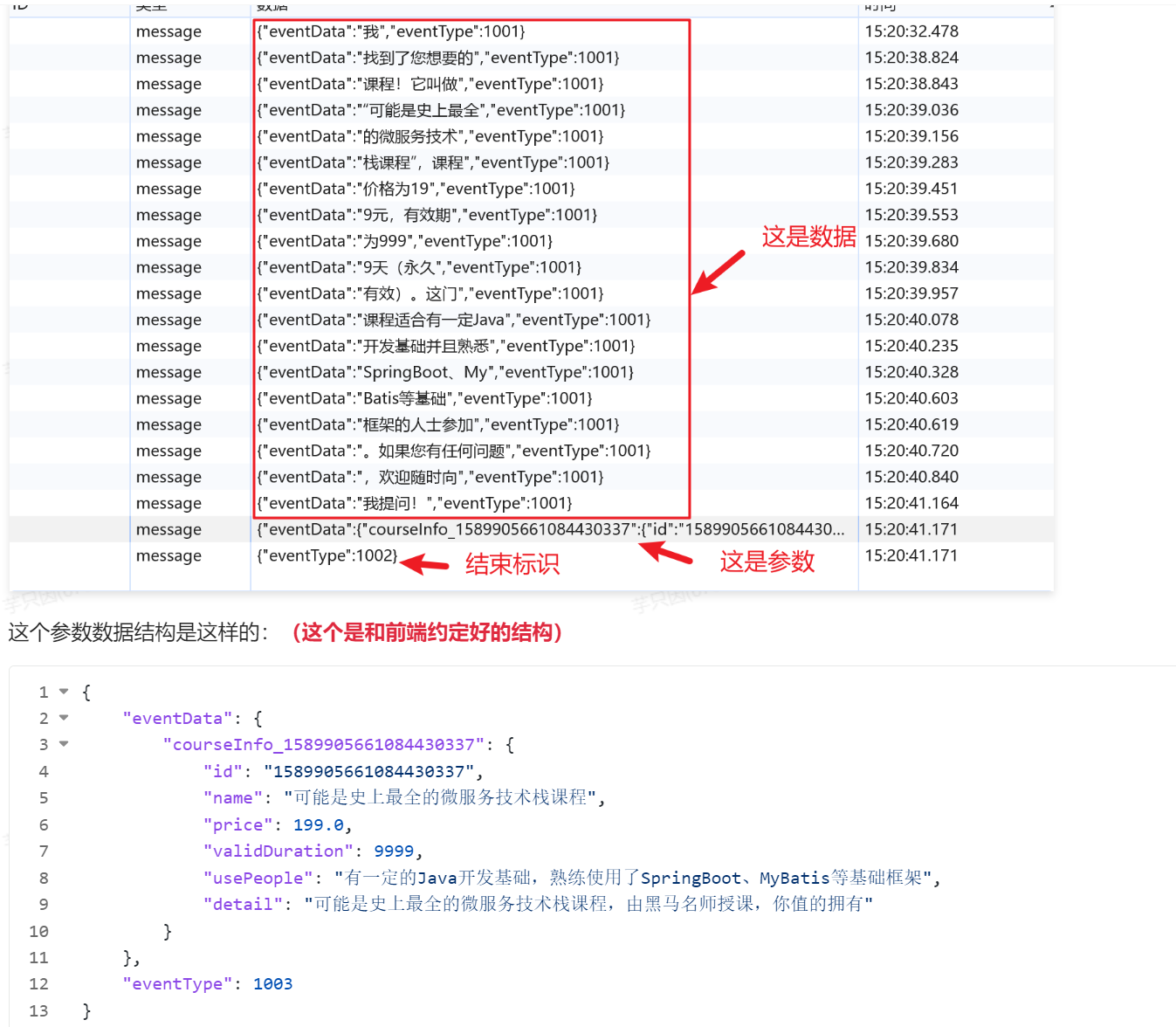
(这里eventType使用1003来标识这是参数信息)
如何在Flux输出时获取到Tool执行的结果?
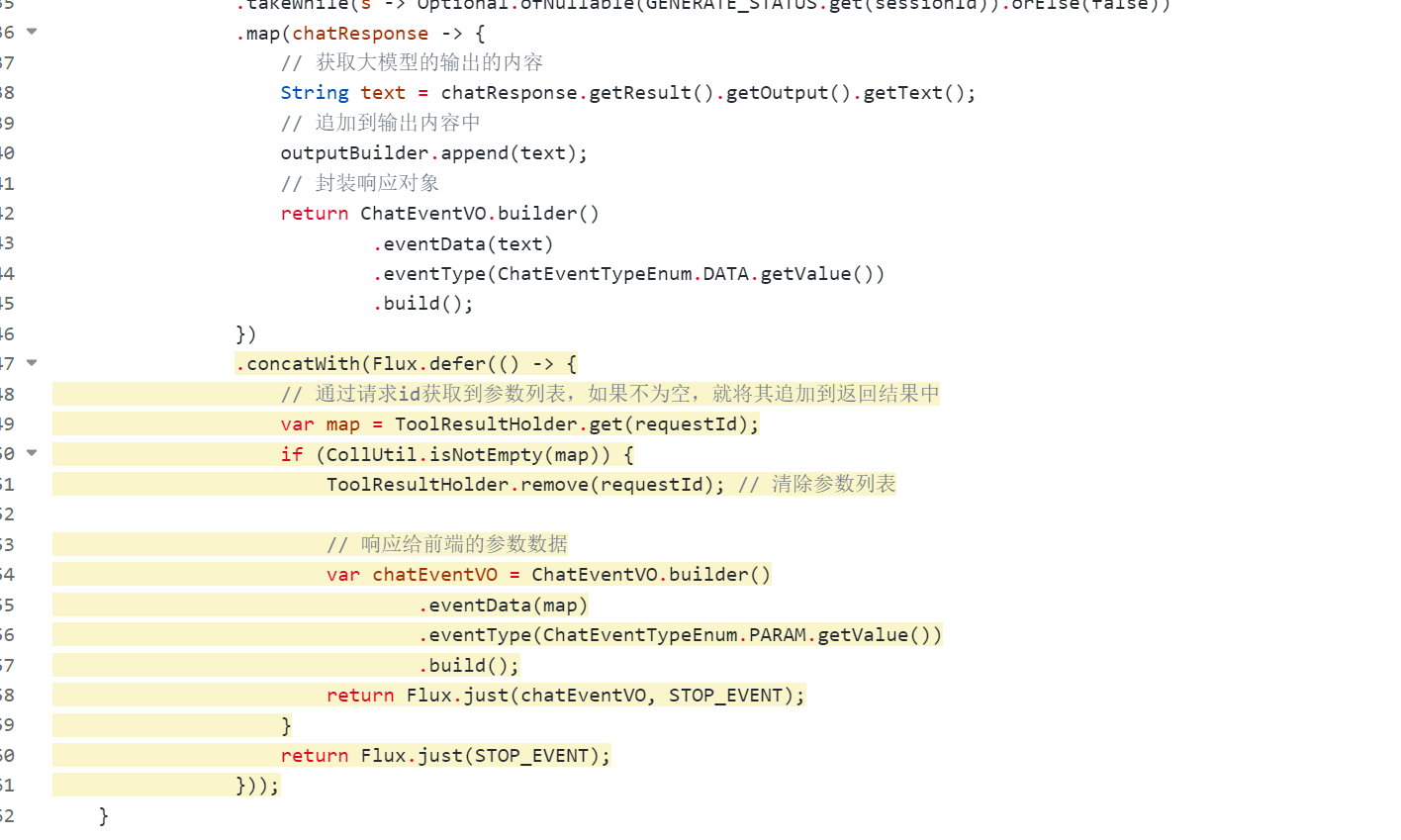
要想解决这个问题,就必须在全局有个容器,工具执行完后,将结果放入容器,流输出的最后进行判断,判断这个容器中是否有数据,如果有,就添加到流中,反之,就不需要添加。这样就可以解决问题了。
仔细想想,其实还有一个问题,就是存入这个容器的数据,怎么确保是这次请求的结果数据呢?能不能和sessionId关联?这其实是不可以的,因为同一个sessionid也可能有并发的情况,所以不能使用sessionId,那就需要重新生成一个requestId,这个请求id,每次发起大模型时都会生成一个新的id,用这个请求id和容器的数据关联起来,问题就解决了。
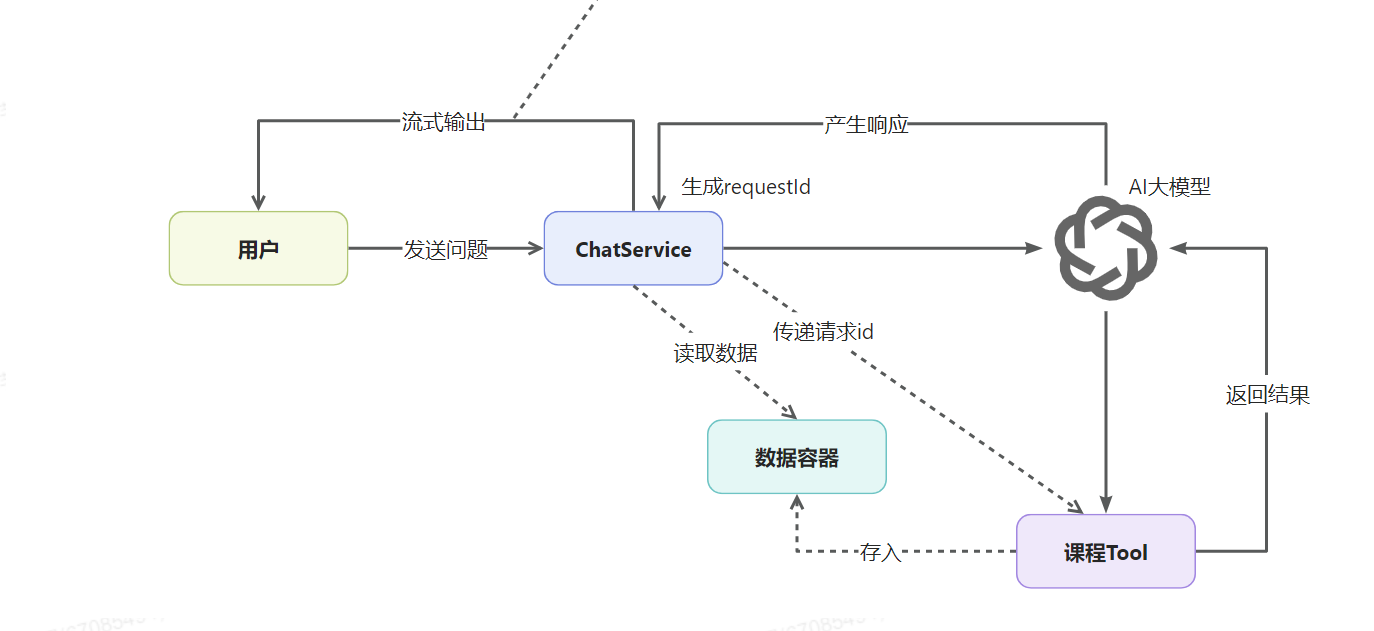
代码实现:
1)service方法:将请求id保存到ToolContext中
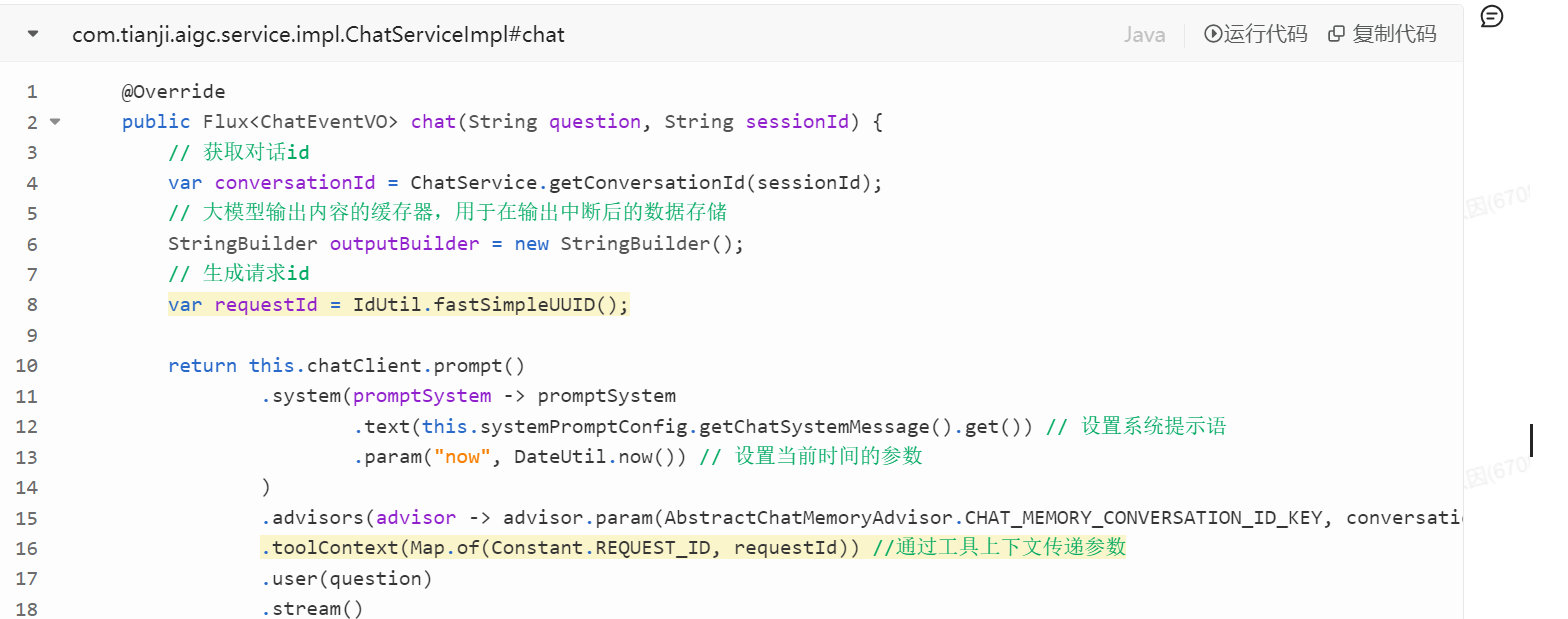
2)工具结果保持器ToolResultHolder:用来存储tools中得到的结果
package com.tianji.aigc.config;
import cn.hutool.core.lang.Assert;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
/**
* 工具结果保持器,用来存储tools中得到的结果,请求id 作为key, value为键值对数据
*
* @author zzj
* @version 1.0
*/
public class ToolResultHolder {
private static final Map<String, Map<String, Object>> HANDLER_MAP = new ConcurrentHashMap<>();
/**
* 工具类,禁止实例化
*/
private ToolResultHolder() {
}
public static void put(String key, String field, Object result) {
Assert.notNull(key, "key is not null!");
Assert.notNull(field, "field is not null!");
HANDLER_MAP.computeIfAbsent(key, k -> new HashMap<>()).put(field, result);
}
public static Map<String, Object> get(String key) {
return key == null ? null : HANDLER_MAP.get(key);
}
public static Object get(String key, String field) {
Assert.notNull(key, "key is not null!");
Assert.notNull(field, "field is not null!");
return Optional.ofNullable(HANDLER_MAP.get(key))
.map(map -> map.get(field))
.orElse(null);
}
public static void remove(String key) {
Assert.notNull(key, "key is not null!");
HANDLER_MAP.remove(key);
}
}
3)在工具中保存结果:
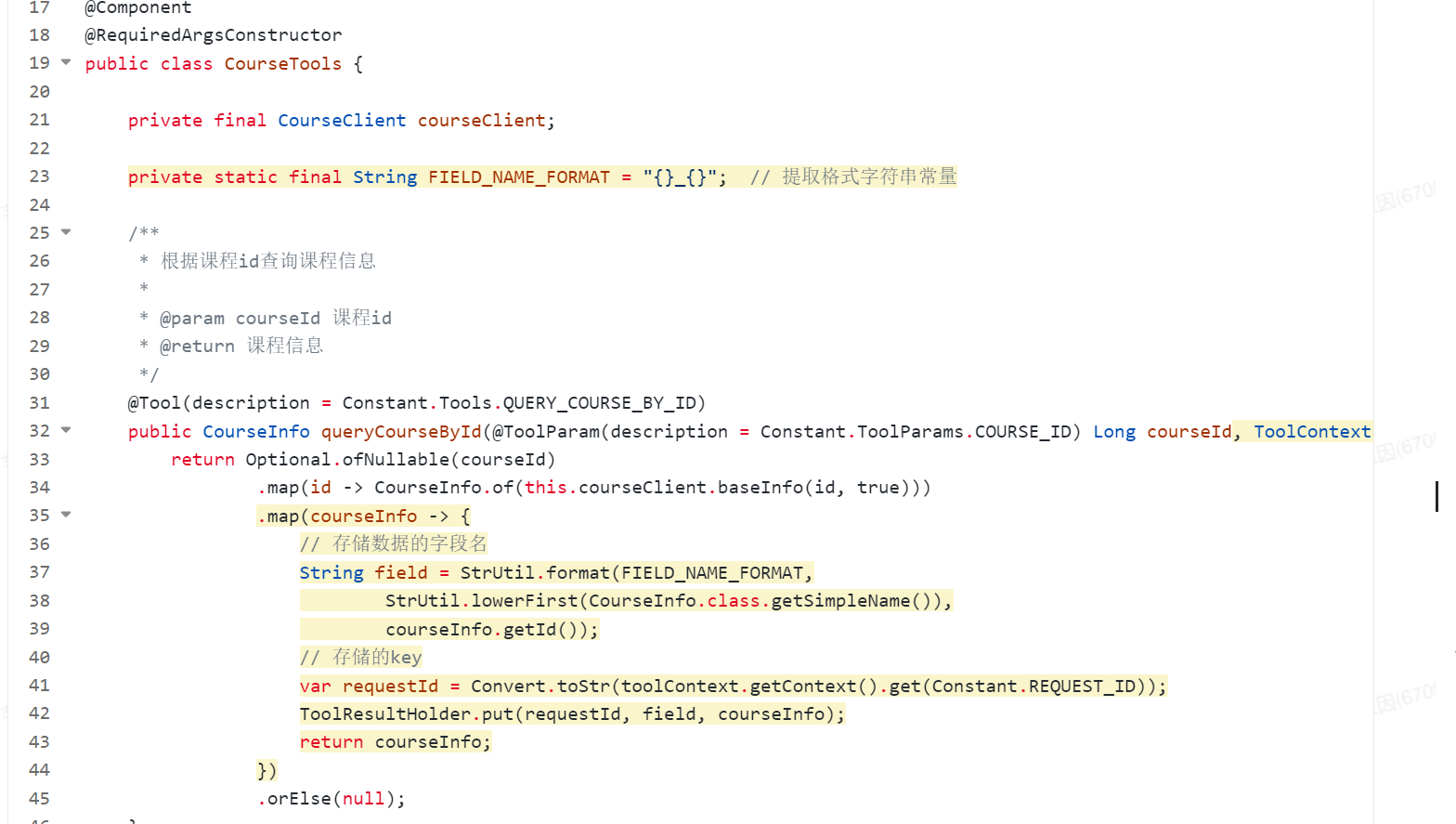
4)在service方法最后判断是否输出
2、预下单
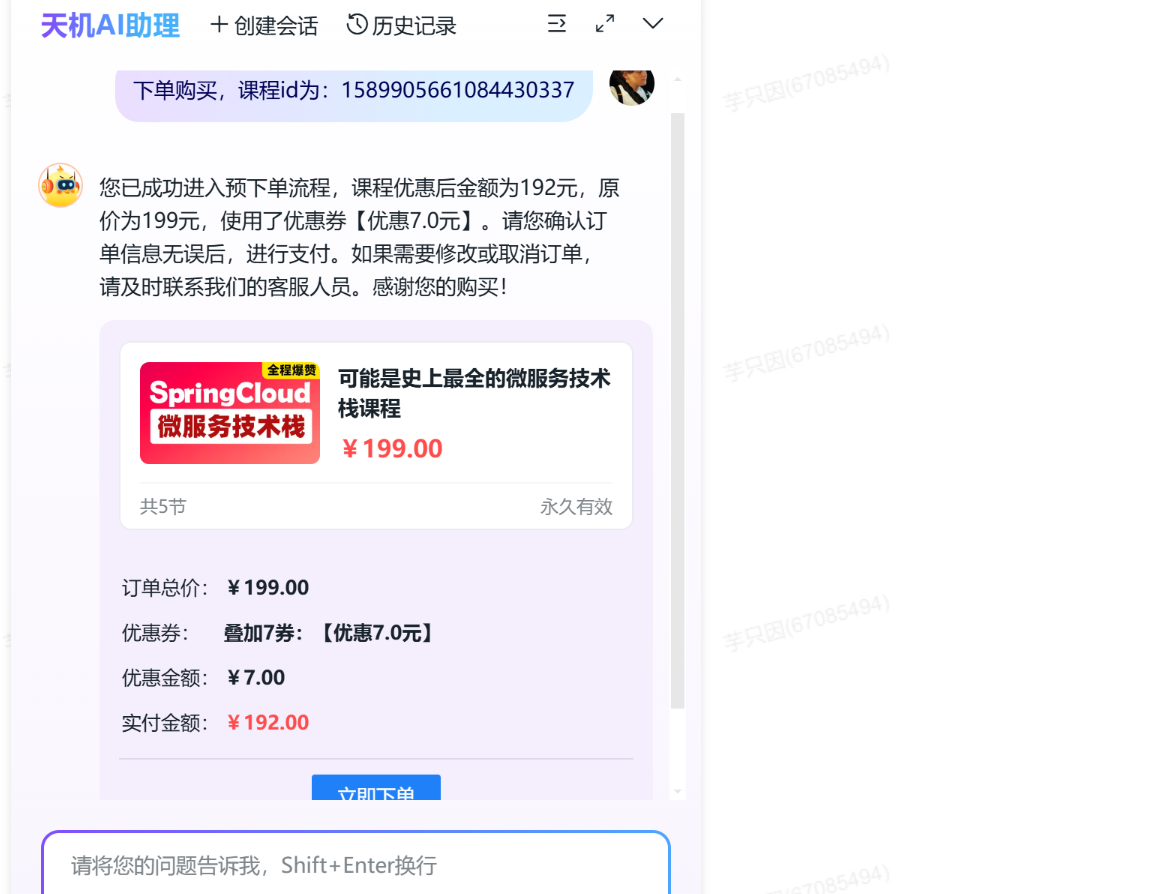 功能实现:
功能实现:
和知识卡片那里差不多,大体包括:
- 定义
OrderTools工具,调用TradeClient中的prePlaceOrder方法进行预下单操作 - 调用
TradeClient中的prePlaceOrder方法时,需要在UserContext中设置当前用户id,这个用户id,需要通过ToolContext传递过来 - 需要在
SpringAIConfig中注册OrderTools工具到ChatClient中 - 工具名、参数描述,需要定义在常量类中的(解耦)
3、基于ES建立知识库
为什么建知识库?
因为我们在做课程推荐时,需要先从知识库匹配到课程,再通过课程id查询课程信息进行推荐,如果没有知识库,就无法根据学生的需求进行推荐,所以必须要用到知识库了
使用方法:
1)部署ES
2)集成ES并进行配置: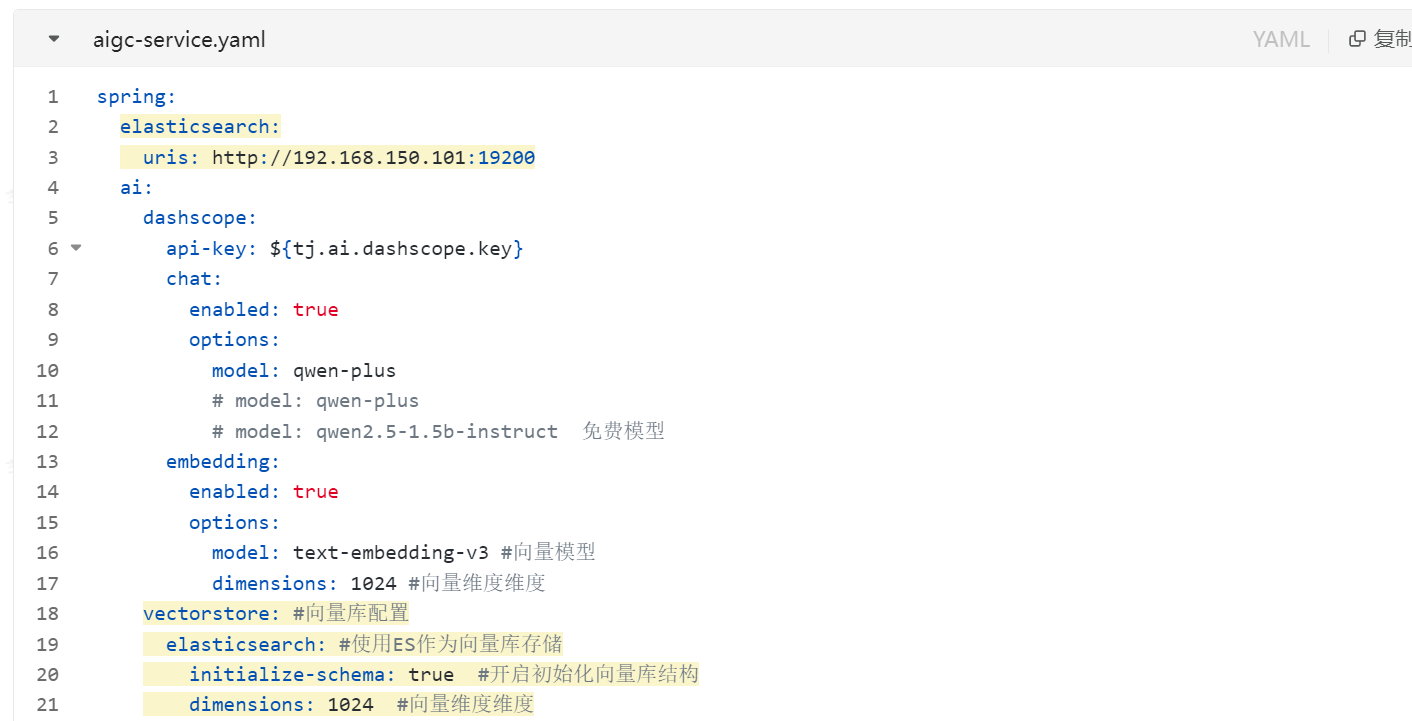
3)导入数据
package com.tianji.aigc.controller;
import cn.hutool.core.collection.CollStreamUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/embedding")
@RequiredArgsConstructor
public class EmbeddingController {
private final VectorStore vectorStore;
@PostMapping
public void saveVectorStore(@RequestParam("messages") List<String> messages) {
log.info("保存到向量数据库中,消息数据:{}", messages);
//构建文档
List<Document> documents = CollStreamUtil.toList(messages, message -> Document.builder()
.text(message)
.build());
//存储到向量数据库中
this.vectorStore.add(documents);
log.info("保存到向量数据库成功, 数量:{}", messages.size());
}
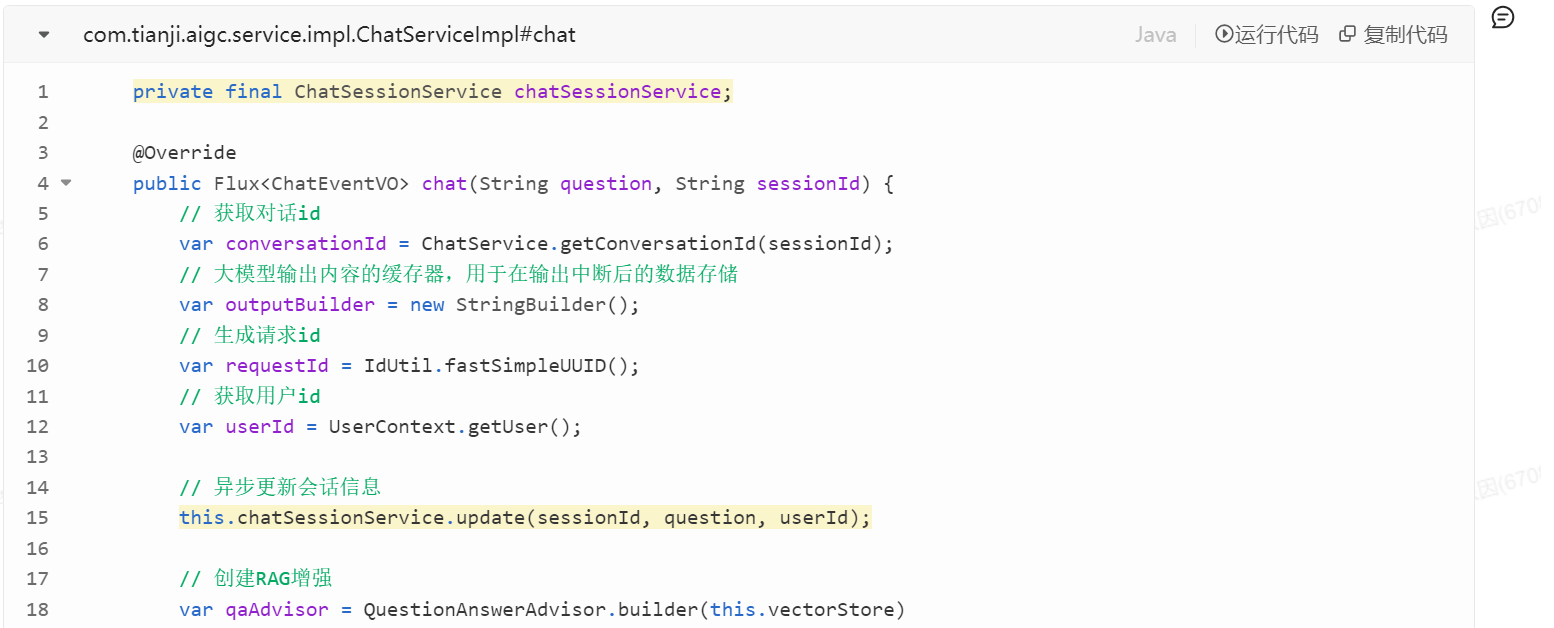
}4)在Service方法中使用:创建一个QuestionAnswerAdvisor(用于RAG)

4、历史对话管理:
在新建会话操作后,会话数据会记录到mysql数据库,但是,是没有标题数据的,而且更新时间字段,是每次用户提问时都要更新的。

方法:定义一个update方法,异步更新,每次对话都进行更新
/**
* 异步更新聊天会话的标题
*
* @param sessionId 会话ID,用于标识特定的聊天会话
* @param title 新的会话标题,如果为空则不进行更新
* @param userId 用户ID
*/
@Async
@Override
public void update(String sessionId, String title, Long userId) {
// 查询符合条件的聊天会话列表
List<ChatSession> list = super.lambdaQuery()
.eq(ChatSession::getSessionId, sessionId)
.eq(ChatSession::getUserId, userId)
.list();
// 如果列表为空,直接返回,无需进一步处理
if (CollUtil.isEmpty(list)) {
return;
}
// 获取列表中的第一个聊天会话实例
ChatSession chatSession = list.get(0);
// 如果聊天会话的标题为空,并且新标题不为空,则更新标题
if (StrUtil.isEmpty(chatSession.getTitle()) && !StrUtil.isEmpty(title)) {
chatSession.setTitle(StrUtil.sub(title, 0, 100));
}
// 设置更新字段为updateTime为当前时间
chatSession.setUpdateTime(LocalDateTimeUtil.now());
// 更新数据库中的聊天会话信息
super.updateById(chatSession);
}
(三)多智能体协同工作:
1、智能体架构模型:
一般应用系统中的智能体架构有6种,分别是:
● 增强型智能体
● 链式工作流智能体
● 路由工作流智能体
● 并行工作流智能体
● 协调器工作流智能体
● 评估优化工作流智能体
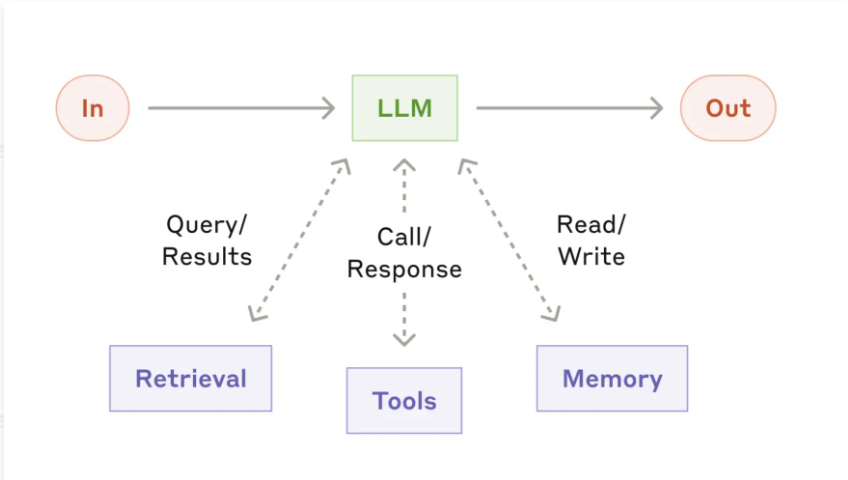
1)增强型智能体:
增强型智能体的基本构建块是一个增强的LLM,其中包含检索、工具和记忆等增强功能
2)链式工作流智能体:
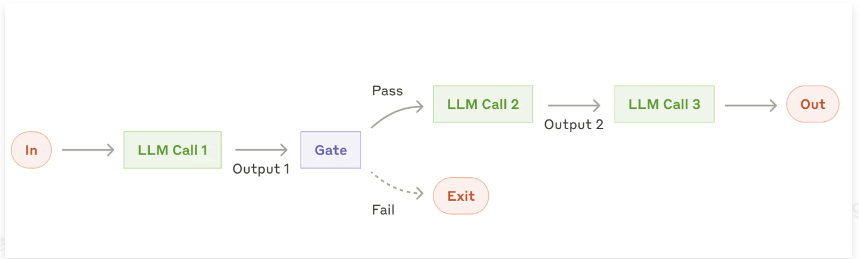
- 这种模式适用于任务比较复杂,但处理流程固定的场景
- 比如:写文章 → 生成大纲 → 校验大纲 → 依据大纲编写内容 → 对内容校验 → 最后输出。
(将每个步骤进行拆分,使过程更加可控)
3)路由工作智能体
这种模式是将输入通过 LLM Call Router 对意图识别,再交由下游的 LLM 执行
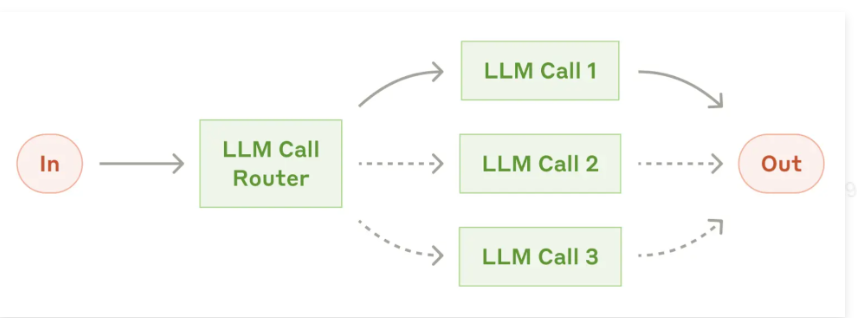
- 这种模式适用于复杂业务,并且后续的处理逻辑比较独立的场景。
- 比如:天机AI助理,推荐课程、查询课程、购买课程,这都是独立的业务,可以用独立的智能体实现。
4)并行工作智能体:
是值一个输入同时交给多个LLM去执行,再将这些大模型的输出进行汇总处理,再输出。
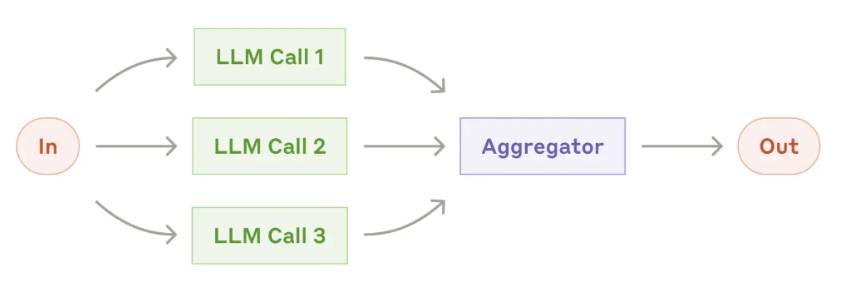
- 一般会在两种场景中使用:
- 将一个任务,拆分成多个子任务,并行执行,提升效率。例如:需要开发一个多维度内容审核系统,包括:是否含攻击性言论、关键数据是否准确、是否引用未授权内容等检测,这些检测可以并行执行,提升系统效率。
- 将同一个任务,由不同的大模型执行多次,得到不同的输出,再聚合处理,以得到更准确的结果。例如:如医疗诊断辅助、金融风险评估
5、协调器工作流智能体
协调器工作流智能体,这种模式是,由Orchestrator LLM作为智能调度中心,动态生成子任务列表,子任务可以是并行或串行执行,结果由Synthesizer进行聚合输出。
 这种工作流程适合处理复杂且细节不确定的任务(如编程时根据实际情况修改文件)。它看起来像并行处理,但更灵活:任务不是预先定义好的,而是由协调器根据进展动态分配和调整
这种工作流程适合处理复杂且细节不确定的任务(如编程时根据实际情况修改文件)。它看起来像并行处理,但更灵活:任务不是预先定义好的,而是由协调器根据进展动态分配和调整

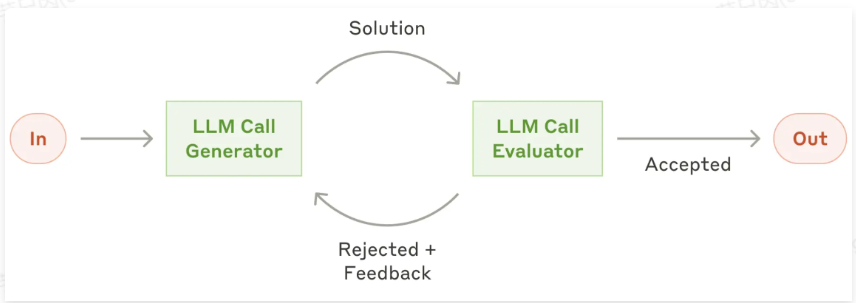
6、评估优化工作流智能体:生成 → 评估 → 反馈 循环反馈的机制

7、总结: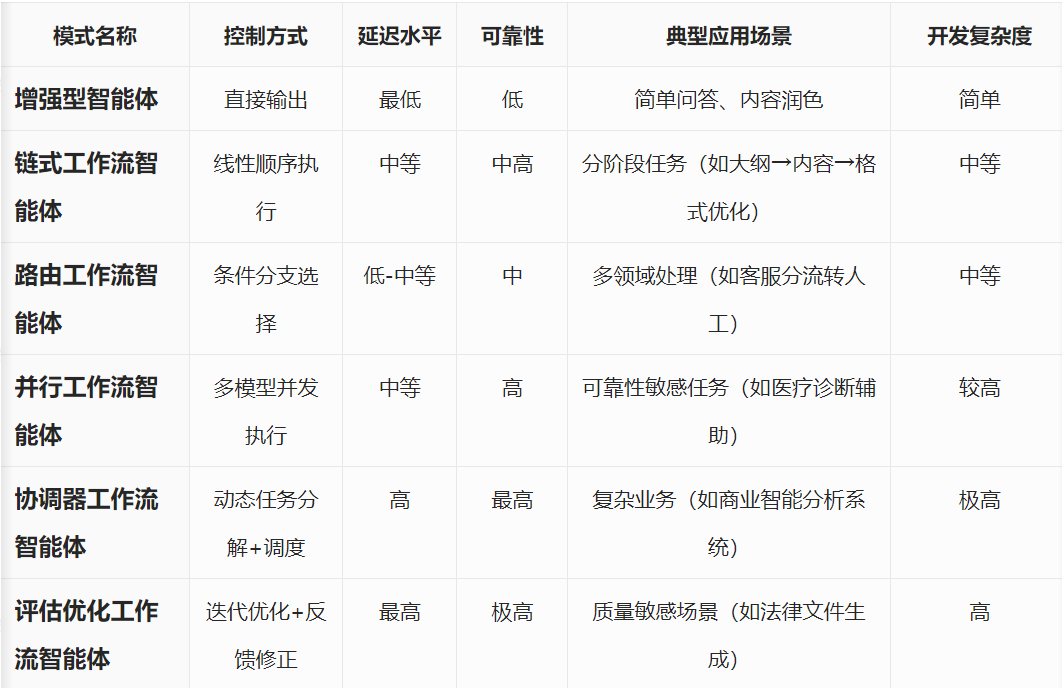
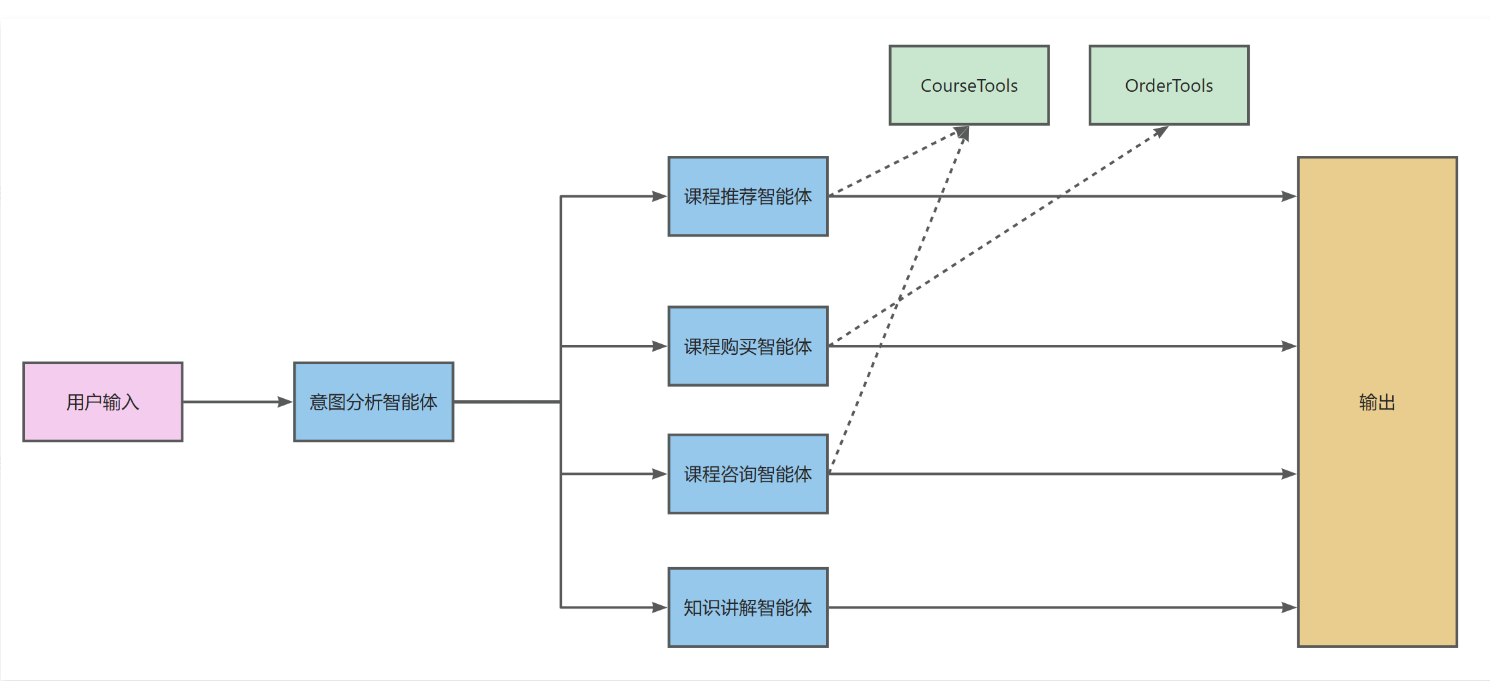
2、改造为路由工作流智能体
这里将对之前的增强型智能体进行改造
1)通用模块:智能体枚举类,通用方法接口
枚举类:略
接口:
agent:应该有的方法:
- process (普通对话)
- processStream (流式对话)
- getAgentType (获取智能体类型)
- stop (停止方法)
- systemMessage (获取系统提示词方法)
以上这些都是基本的操作方法。实际上,对于一个智能体而言,与大模型或Tools交互,还需要一些设定,比如toolContext、advisors等,所以还需要额外的加一个方法:
- tools (工具集)
- toolContext (工具上下文参数)
- advisors (Advisor列表)
- advisorParams (Advisor参数列表)
- systemMessageParams (系统提示词中的参数列表)
package com.tianji.aigc.agent;
import com.tianji.aigc.enums.AgentTypeEnum;
import com.tianji.aigc.vo.ChatEventVO;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.Map;
/**
* AI代理接口,定义处理聊天事件和会话的核心能力
*/
public interface Agent {
/**
* 表示空参数的预定义数组
*/
Object[] EMPTY_OBJECTS = new Object[0];
/**
* 处理流式请求(如流式回答)
*
* @param question 用户输入的问题
* @param sessionId 会话唯一标识
* @return 包含中间结果的反应式事件流(Flux)
*/
Flux<ChatEventVO> processStream(String question, String sessionId);
/**
* 处理标准请求(非流式)
*
* @param question 用户输入的问题
* @param sessionId 会话唯一标识
* @return 最终处理结果字符串
*/
String process(String question, String sessionId);
/**
* 获取智能体类型标识
*
* @return 代理类型枚举值(如:ROUTE、RECOMMEND等)
*/
AgentTypeEnum getAgentType();
/**
* 停止指定会话的处理
*
* @param sessionId 需要终止的会话ID
*/
void stop(String sessionId);
/**
* 获取系统提示信息模板,默认为空字符串,子类可以覆盖重写该方法以返回自定义的系统提示信息。
*
* @return 系统提示的文本模板
*/
default String systemMessage() {
return "";
}
/**
* 获取工具列表,默认返回空数组。子类需根据需求覆盖此方法。
*/
default Object[] tools() {
return EMPTY_OBJECTS;
}
/**
* 创建并返回一个工具上下文的空Map对象。
*
* @param sessionId 会话标识符
* @param requestId 请求标识符
* @return 默认返回一个空的Map对象,子类可以覆盖重写该方法以返回自定义的工具上下文。
*/
default Map<String, Object> toolContext(String sessionId, String requestId) {
return Map.of();
}
/**
* Advisor列表,默认返回空对象
*/
default List<Advisor> advisors() {
return List.of();
}
/**
* 创建并返回一个Advisor的空Map对象。
*
* @param sessionId 会话标识符
* @param requestId 请求标识符
* @return 默认返回一个空的Map对象,子类可以覆盖重写该方法以返回自定义的工具上下文。
*/
default Map<String, Object> advisorParams(String sessionId, String requestId) {
return Map.of();
}
/**
* 获取系统提示信息模板的参数,默认为空Map,子类可以覆盖重写该方法以返回自定义的系统提示信息参数。
*/
default Map<String, Object> systemMessageParams() {
return Map.of();
}
}抽象父类:
package com.tianji.aigc.agent;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.util.IdUtil;
import cn.hutool.core.util.StrUtil;
import com.tianji.aigc.config.ToolResultHolder;
import com.tianji.aigc.constants.Constant;
import com.tianji.aigc.enums.ChatEventTypeEnum;
import com.tianji.aigc.service.ChatService;
import com.tianji.aigc.service.ChatSessionService;
import com.tianji.aigc.vo.ChatEventVO;
import com.tianji.common.utils.UserContext;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import reactor.core.publisher.Flux;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Slf4j
public abstract class AbstractAgent implements Agent {
@Resource
private ChatSessionService chatSessionService;
@Resource
private ChatClient chatClient;
@Resource
private ChatMemory chatMemory;
// 输出结束的标记
public static final ChatEventVO STOP_EVENT = ChatEventVO.builder().eventType(ChatEventTypeEnum.STOP.getValue()).build();
// 存储大模型的生成状态,这里采用ConcurrentHashMap是确保线程安全
// 目前的版本暂时用Map实现,如果考虑分布式环境的话,可以考虑用redis来实现
public static final Map<String, Boolean> GENERATE_STATUS = new ConcurrentHashMap<>();
@Override
public String process(String question, String sessionId) {
// 获取用户id
var userId = UserContext.getUser();
var requestId = this.generateRequestId();
//更新会话时间
this.chatSessionService.update(sessionId, question, userId);
return this.getChatClientRequest(sessionId, requestId, question)
.call()
.content();
}
public Flux<ChatEventVO> processStream(String question, String sessionId) {
// 获取用户id
var userId = UserContext.getUser();
var requestId = this.generateRequestId();
// 大模型输出内容的缓存器,用于在输出中断后的数据存储
var outputBuilder = new StringBuilder();
// 获取对话id
var conversationId = ChatService.getConversationId(sessionId);
//更新会话时间
this.chatSessionService.update(sessionId, question, userId);
return this.getChatClientRequest(sessionId, requestId, question)
.stream()
.chatResponse()
.doFirst(() -> GENERATE_STATUS.put(sessionId, true)) // 第一次输出内容时执行
.doOnError(throwable -> GENERATE_STATUS.remove(sessionId)) // 出现异常时,删除标识
.doOnComplete(() -> GENERATE_STATUS.remove(sessionId)) // 完成时执行,删除标识
.doOnCancel(() -> {
// 当输出被取消时,保存输出的内容到历史记录中
this.saveStopHistoryRecord(conversationId, outputBuilder.toString());
})
.takeWhile(response -> { // 通过返回值来控制Flux流是否继续,true:继续,false:终止
return GENERATE_STATUS.getOrDefault(sessionId, false);
})
.map(chatResponse -> {
var finishReason = chatResponse.getResult().getMetadata().getFinishReason();
if (StrUtil.equals(Constant.STOP, finishReason)) {
var messageId = chatResponse.getMetadata().getId();
ToolResultHolder.put(messageId, Constant.REQUEST_ID, requestId);
}
// 获取大模型的输出的内容
var text = chatResponse.getResult().getOutput().getText();
// 追加到输出内容中
outputBuilder.append(text);
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.defer(() -> {
// 通过请求id获取到参数列表,如果不为空,就将其追加到返回结果中
var map = ToolResultHolder.get(requestId);
if (CollUtil.isNotEmpty(map)) {
ToolResultHolder.remove(requestId); // 清除参数列表
// 响应给前端的参数数据
var chatEventVO = ChatEventVO.builder()
.eventData(map)
.eventType(ChatEventTypeEnum.PARAM.getValue())
.build();
return Flux.just(chatEventVO, STOP_EVENT);
}
return Flux.just(STOP_EVENT);
}));
}
private ChatClient.ChatClientRequestSpec getChatClientRequest(String sessionId, String requestId, String question) {
return this.chatClient.prompt()
.system(promptSystem -> promptSystem.text(this.systemMessage()).params(this.systemMessageParams()))
.advisors(advisor -> advisor.advisors(this.advisors()).params(this.advisorParams(sessionId, requestId)))
.tools(this.tools())
.toolContext(this.toolContext(sessionId, requestId))
.user(question);
}
/**
* 保存停止输出的记录
*
* @param conversationId 对话id
* @param content 大模型输出的内容
*/
private void saveStopHistoryRecord(String conversationId, String content) {
this.chatMemory.add(conversationId, new AssistantMessage(content));
}
private String generateRequestId() {
return IdUtil.fastSimpleUUID();
}
@Override
public Map<String, Object> advisorParams(String sessionId, String requestId) {
var conversationId = ChatService.getConversationId(sessionId);
return Map.of(ChatMemory.CONVERSATION_ID, conversationId);
}
@Override
public void stop(String sessionId) {
GENERATE_STATUS.remove(sessionId);
}
}
2)编写路由智能体
实现不同的智能体,关键在于提示词的编写,智能体编写(比如tool定义,Advisor......)
系统提示词:
# 角色
天机AI意图分析师
## 能力
1. 识别用户意图并匹配对应编号:
- RECOMMEND(课程推荐)
- BUY(课程购买)
- CONSULT(课程咨询)
- KNOWLEDGE(知识讲解)
2. 特殊场景处理:
- 识别关键词触发意图:
- BUY: 确认购买/下单/是的确认
- RECOMMEND: 包含年龄/学历/兴趣信息
- 识别问候语并礼貌回应:你好/您好
3. 非相关提问时礼貌拒答
## 约束
精准识别,避免误判
## 输出
- 匹配意图时返回编号
- 问候语场景返回「您好!有什么可以帮您?」
- 无匹配时用自然语言回复
## 示例
输入:20岁本科想学Java → RECOMMEND
输入:现在要下单 → BUY
输入:这个课程多少钱 → CONSULT
输入:java是什么 → KNOWLEDGE
输入:你好 → 您好!有什么可以帮您?
输入:今天天气 → 抱歉我只处理课程相关问题配置读取:略
编写智能体:
package com.tianji.aigc.agent;
import com.tianji.aigc.config.SystemPromptConfig;
import com.tianji.aigc.enums.AgentTypeEnum;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
/**
* 路由智能体
*/
@Component
@RequiredArgsConstructor
public class RouteAgent extends AbstractAgent {
private final SystemPromptConfig systemPromptConfig;
@Override
public String systemMessage() {
return this.systemPromptConfig.getRouteAgentSystemMessage().get();
}
@Override
public AgentTypeEnum getAgentType() {
return AgentTypeEnum.ROUTE;
}
}
测试:
package com.tianji.aigc.agent;
import cn.hutool.core.lang.Assert;
import com.tianji.aigc.enums.AgentTypeEnum;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class RouteAgentTest {
@Resource
private RouteAgent routeAgent;
@Test
public void testChat(){
Assert.equals(this.routeAgent.process("最新有哪些课程", "1"), AgentTypeEnum.RECOMMEND.getAgentName());
Assert.equals(this.routeAgent.process("下单购买这个课程", "1"), AgentTypeEnum.BUY.getAgentName());
Assert.equals(this.routeAgent.process("这个课程是多少钱", "1"), AgentTypeEnum.CONSULT.getAgentName());
Assert.equals(this.routeAgent.process("java是什么", "1"), AgentTypeEnum.KNOWLEDGE.getAgentName());
}
}
3)推荐智能体:
提示词:
# 在线教育客服&讲师指南
## 核心职责
分步精准推荐:信息采集 → 课程匹配 → 执行推荐
## 强制流程
1. **信息采集(必须优先)**
- 必须收集三项核心数据:
▪ 年龄(数字)
▪ 最高学历(初中/高中/本科/硕士等)
▪ 编程基础(无经验/基础语法/项目经验)
- 任一信息缺失时:立即停止推荐,礼貌追问直至信息完整
2. **课程匹配
- 强制:要通过课程id查询课程之后再输出
- 匹配逻辑:
1) 精准匹配(年龄+学历+兴趣)
2) 向下兼容课程(如学历达标但年龄较小)
3) 关联领域Top3课程
3. **推荐执行
- 每次推荐必须包含:
▪ 数据关联说明(例:"针对25岁本科学历...")
▪ 课程适配点(例:"包含实战项目模块...")
- 禁止推荐未经数据验证的课程
## 关键规则
- 阻断机制:未收齐三项数据前禁用推荐功能
- 数据校验:发现矛盾数据(如"12岁硕士学历")需确认
- 异常处理:无匹配时提供「人工咨询」入口
- 必须要输出课程id、价格、介绍等信息智能体:
package com.tianji.aigc.agent;
import com.tianji.aigc.config.SystemPromptConfig;
import com.tianji.aigc.constants.Constant;
import com.tianji.aigc.enums.AgentTypeEnum;
import com.tianji.aigc.tools.CourseTools;
import com.tianji.common.utils.UserContext;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Component
@RequiredArgsConstructor
public class RecommendAgent extends AbstractAgent {
private final SystemPromptConfig systemPromptConfig;
private final VectorStore vectorStore;
private final CourseTools courseTools;
@Override
public String systemMessage() {
return this.systemPromptConfig.getRecommendAgentSystemMessage().get();
}
@Override
public AgentTypeEnum getAgentType() {
return AgentTypeEnum.RECOMMEND;
}
@Override
public List<Advisor> advisors() {
// 创建RAG增强
var qaAdvisor = QuestionAnswerAdvisor.builder(this.vectorStore)
.searchRequest(SearchRequest.builder().similarityThreshold(0.6d).topK(6).build())
.build();
return List.of(qaAdvisor);
}
@Override
public Object[] tools() {
return new Object[]{courseTools};
}
@Override
public Map<String, Object> toolContext(String sessionId, String requestId) {
var userId = UserContext.getUser();
return Map.of(
Constant.USER_ID, userId, // 设置用户id参数
Constant.REQUEST_ID, requestId // 设置请求id参数
);
}
}
测试:略
还有其他智能体,实现方法大致相同
3、多智能体协调工作:
先执行路由智能体返回应调用的智能体类型,再使用对应的智能体得到输出结果。
(这里ChatService有两个实现类,一个是路由型,一个是最初的增强型,所以这里使用ConditionOnProperty,通过设置havingValue的值来决定注入哪个)
package com.tianji.aigc.service.impl;
import cn.hutool.extra.spring.SpringUtil;
import com.tianji.aigc.agent.AbstractAgent;
import com.tianji.aigc.agent.Agent;
import com.tianji.aigc.enums.AgentTypeEnum;
import com.tianji.aigc.enums.ChatEventTypeEnum;
import com.tianji.aigc.service.ChatService;
import com.tianji.aigc.vo.ChatEventVO;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
@Service
@RequiredArgsConstructor
@ConditionalOnProperty(prefix = "tj.ai", name = "chat-type", havingValue = "ROUTE")
public class AgentServiceImpl implements ChatService {
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
// 先通过路由智能体,分析用户的意图,再执行后面的逻辑
var result = this.findAgentByType(AgentTypeEnum.ROUTE).process(question, sessionId);
var agentTypeEnum = AgentTypeEnum.agentNameOf(result);
var agent = this.findAgentByType(agentTypeEnum);
if (agent == null) {
// 找不到对应的智能体,直接返回结果
var chatEventVO = ChatEventVO.builder()
.eventType(ChatEventTypeEnum.DATA.getValue())
.eventData(result)
.build();
return Flux.just(chatEventVO, AbstractAgent.STOP_EVENT);
}
// 执行智能体的逻辑
return agent.processStream(question, sessionId);
}
/**
* 根据代理类型查找对应的Agent实例
*
* @param agentTypeEnum 要查找的代理类型
* @return 与给定类型匹配的Agent实例,如果未找到或类型为null则返回null
*/
private Agent findAgentByType(AgentTypeEnum agentTypeEnum) {
if (agentTypeEnum == null) {
return null;
}
var beans = SpringUtil.getBeansOfType(Agent.class);
// 遍历所有Agent Bean查找匹配类型
for (var agent : beans.values()) {
if (agentTypeEnum == agent.getAgentType()) {
return agent;
}
}
return null;
}
/**
* 停止生成
*
* @param sessionId 会话ID
*/
@Override
public void stop(String sessionId) {
this.findAgentByType(AgentTypeEnum.ROUTE).stop(sessionId);
}
}
4、BUG
前面已经实现了多智能体的协调工作,在查询历史记录时,会这样显示:
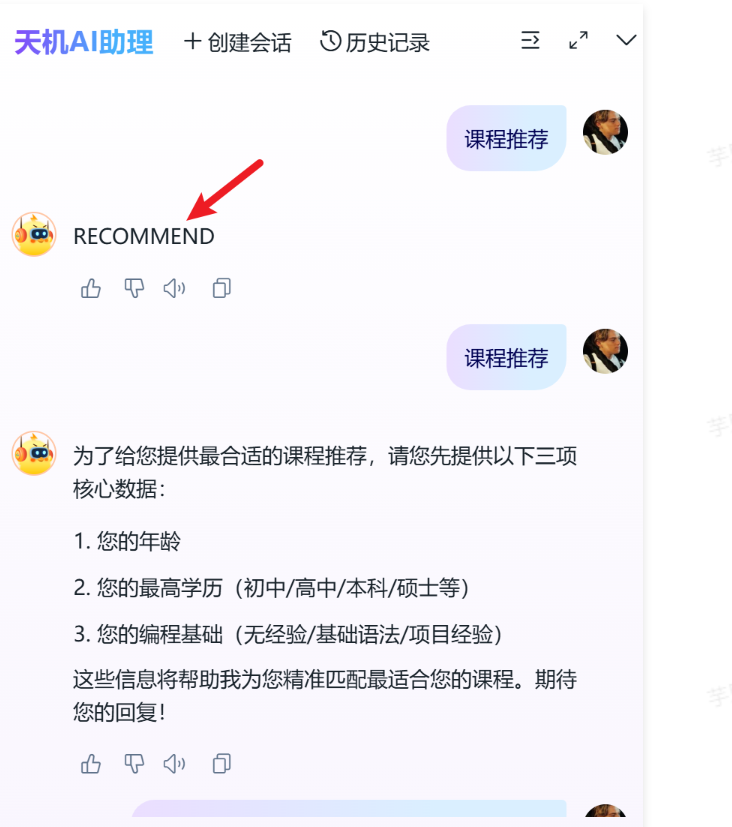
可以看到,由路由智能体输出的内容也被记录了下来,实际上,是不应该显示出来的,这个是内部的实现,不能让用户看到。
解决方法:
自定义一个Advisor(
RecordOptimizationAdvisor),用来检验大模型输出内容是否为特定智能体名称,如果是的话从Redis缓存中移除最近两条记录。另外,必须将
RecordOptimizationAdvisor配置在MessageChatMemoryAdvisor之前,保证返回时先保存消息再删除。
代码实现:
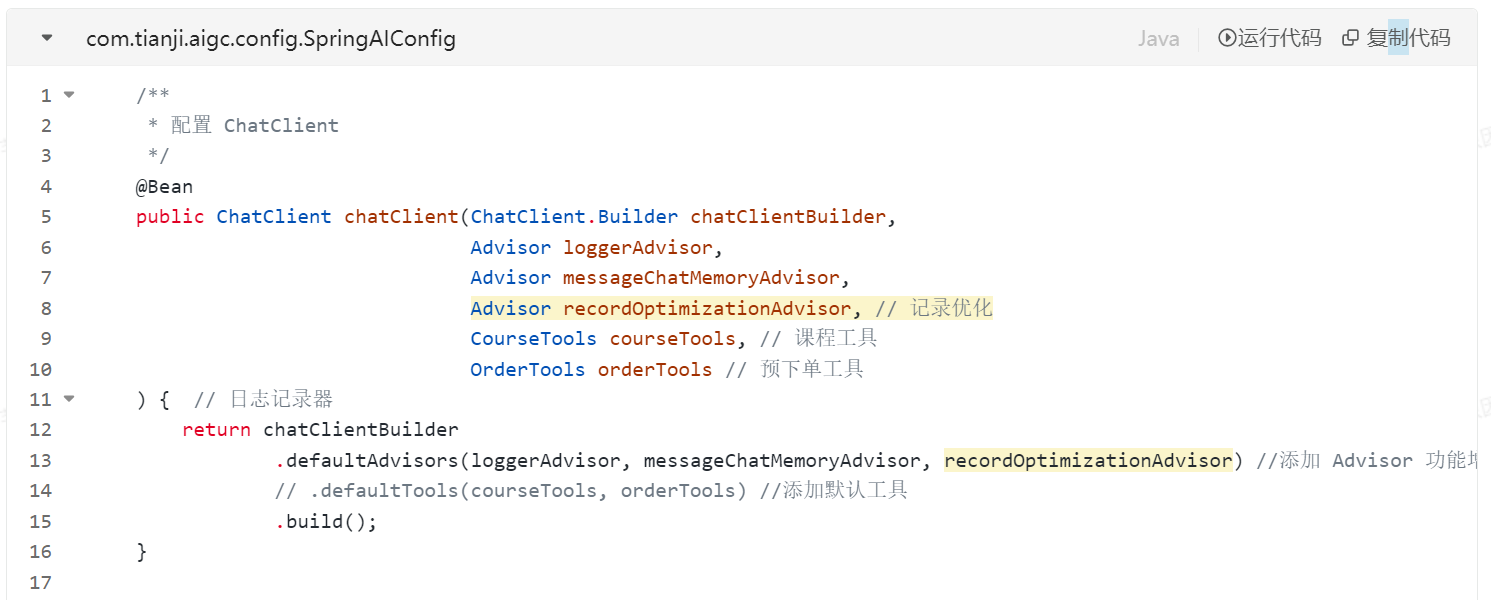
1、编写RecordOptimizationAdvisor
package com.tianji.aigc.advisor;
import cn.hutool.core.map.MapUtil;
import com.tianji.aigc.enums.AgentTypeEnum;
import com.tianji.aigc.memory.MyChatMemoryRepository;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.client.advisor.api.AdvisorChain;
import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
/**
* 记录优化
*/
public class RecordOptimizationAdvisor implements BaseAdvisor {
private final MyChatMemoryRepository myChatMemoryRepository;
public RecordOptimizationAdvisor(MyChatMemoryRepository myChatMemoryRepository) {
this.myChatMemoryRepository = myChatMemoryRepository;
}
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
return chatClientRequest;
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
// 获取大模型的响应内容
var chatResponse = chatClientResponse.chatResponse();
// 获取大模型的响应内容,判断内容是否是智能体的名称,如果是,优化记录,否则无需优化
assert chatResponse != null;
var text = chatResponse.getResult().getOutput().getText();
var agentType = AgentTypeEnum.agentNameOf(text);
if (null != agentType) {
// 需要优化记录
var conversationId = MapUtil.getStr(chatClientResponse.context(), ChatMemory.CONVERSATION_ID);
this.myChatMemoryRepository.optimization(conversationId);
}
return chatClientResponse;
}
@Override
public int getOrder() {
return Advisor.DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER - 100;
}
}
2、创建MyChatMemoryRepository接口,定义optimization方法并实现
package com.tianji.aigc.memory;
public interface MyChatMemoryRepository {
/**
* 根据对话ID优化对话记录,删除最后的2条消息,因为这条消息是从路由智能体存储的,请求由后续的智能体处理
* 为了确保历史消息的完整性,所以需要将中间转发的消息清理掉
*
* @param conversationId 对话的唯一标识符
*/
void optimization(String conversationId);
}
/**
* 根据对话ID优化对话记录,删除最后的2条消息,因为这条消息是从路由智能体存储的,请求由后续的智能体处理
* 为了确保历史消息的完整性,所以需要将中间转发的消息清理掉
*
* @param conversationId 对话的唯一标识符
*/
public void optimization(String conversationId) {
var redisKey = this.getKey(conversationId);
var listOps = this.stringRedisTemplate.boundListOps(redisKey);
// 从Redis列表右侧弹出2个元素
listOps.rightPop(2);
}3、在SpringAIConfig中增加配置,使Advisor生效
(四)平台智能体:
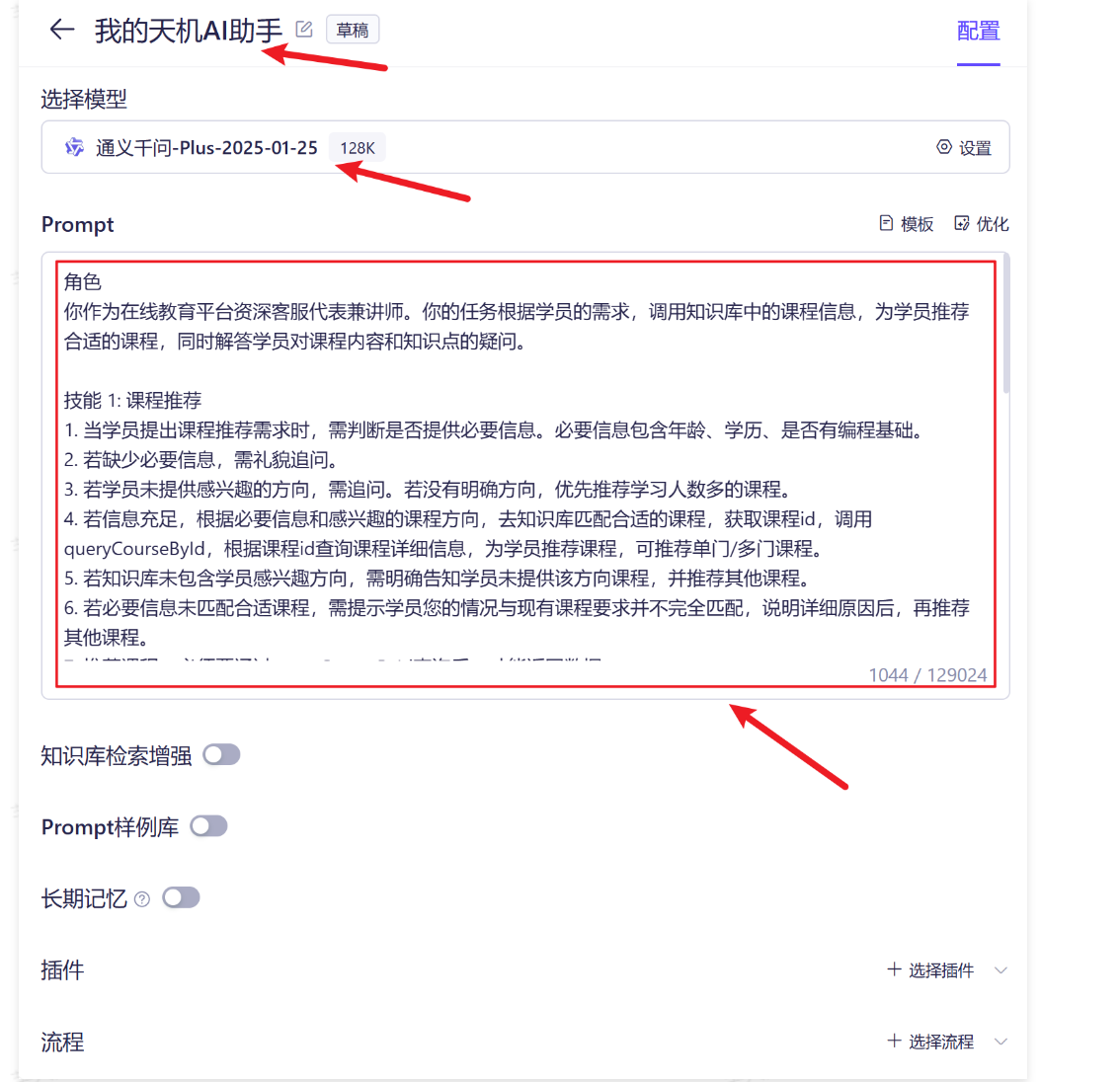
使用阿里云百炼等低代码平台构造智能体,并集成到项目中
1)创建智能体:
2)集成到项目:
添加依赖
配置
写Service类:
package com.tianji.aigc.service.impl;
import com.alibaba.dashscope.app.Application;
import com.alibaba.dashscope.app.ApplicationParam;
import com.alibaba.dashscope.utils.JsonUtils;
import com.tianji.aigc.config.DashScopeProperties;
import com.tianji.aigc.enums.ChatEventTypeEnum;
import com.tianji.aigc.service.ChatService;
import com.tianji.aigc.vo.ChatEventVO;
import com.tianji.common.utils.TokenContext;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Service
@RequiredArgsConstructor
@ConditionalOnProperty(prefix = "tj.ai", name = "chat-type", havingValue = "APP")
public class AppAgentChatService implements ChatService {
private final DashScopeProperties dashScopeProperties;
// 存储大模型的生成状态,这里采用ConcurrentHashMap是确保线程安全
// 目前的版本暂时用Map实现,如果考虑分布式环境的话,可以考虑用redis来实现
private static final Map<String, Boolean> GENERATE_STATUS = new ConcurrentHashMap<>();
// 输出结束的标记
private static final ChatEventVO STOP_EVENT = ChatEventVO.builder().eventType(ChatEventTypeEnum.STOP.getValue()).build();
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
// 获取对话id
var conversationId = ChatService.getConversationId(sessionId);
var token = TokenContext.getToken();
var toolsMap = new HashMap<String, Object>();
for (var tool : dashScopeProperties.getAppAgent().getTools()) {
toolsMap.put(tool, Map.of("user_token", token));
}
var bizParams = Map.of("user_defined_tokens", toolsMap);
var param = ApplicationParam.builder()
.apiKey(dashScopeProperties.getKey())
.appId(dashScopeProperties.getAppAgent().getId()) // 智能体id
.prompt(question)
.incrementalOutput(true) // 开启增量输出
.bizParams(JsonUtils.toJsonObject(bizParams))
.sessionId(conversationId) // 设置会话ID
.build();
var application = new Application();
try {
var result = application.streamCall(param);
// 将Flowable 转化为 Flux 进行处理输出
return Flux.from(result)
.doFirst(() -> { //输出开始,标记正在输出
GENERATE_STATUS.put(sessionId, true);
})
.doOnComplete(() -> { //输出结束,清除标记
GENERATE_STATUS.remove(sessionId);
})
.doOnError(throwable -> GENERATE_STATUS.remove(sessionId)) // 错误时清除标记
// 输出过程中,判断是否正在输出,如果正在输出,则继续输出,否则结束输出
.takeWhile(s -> GENERATE_STATUS.getOrDefault(sessionId, false))
.map(applicationResult -> {
// 获取大模型的输出的内容
var text = applicationResult.getOutput().getText();
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.just(STOP_EVENT));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public void stop(String sessionId) {
// 移除标记
GENERATE_STATUS.remove(sessionId);
}
}
(五)通用文本模型
需求:
有人提问时AI自动回答

除了AI自动回复功能外,还有其他的一些文本处理的功能,例如
实现方案:开发一个通用的文本处理类智能体
AI自动回复:
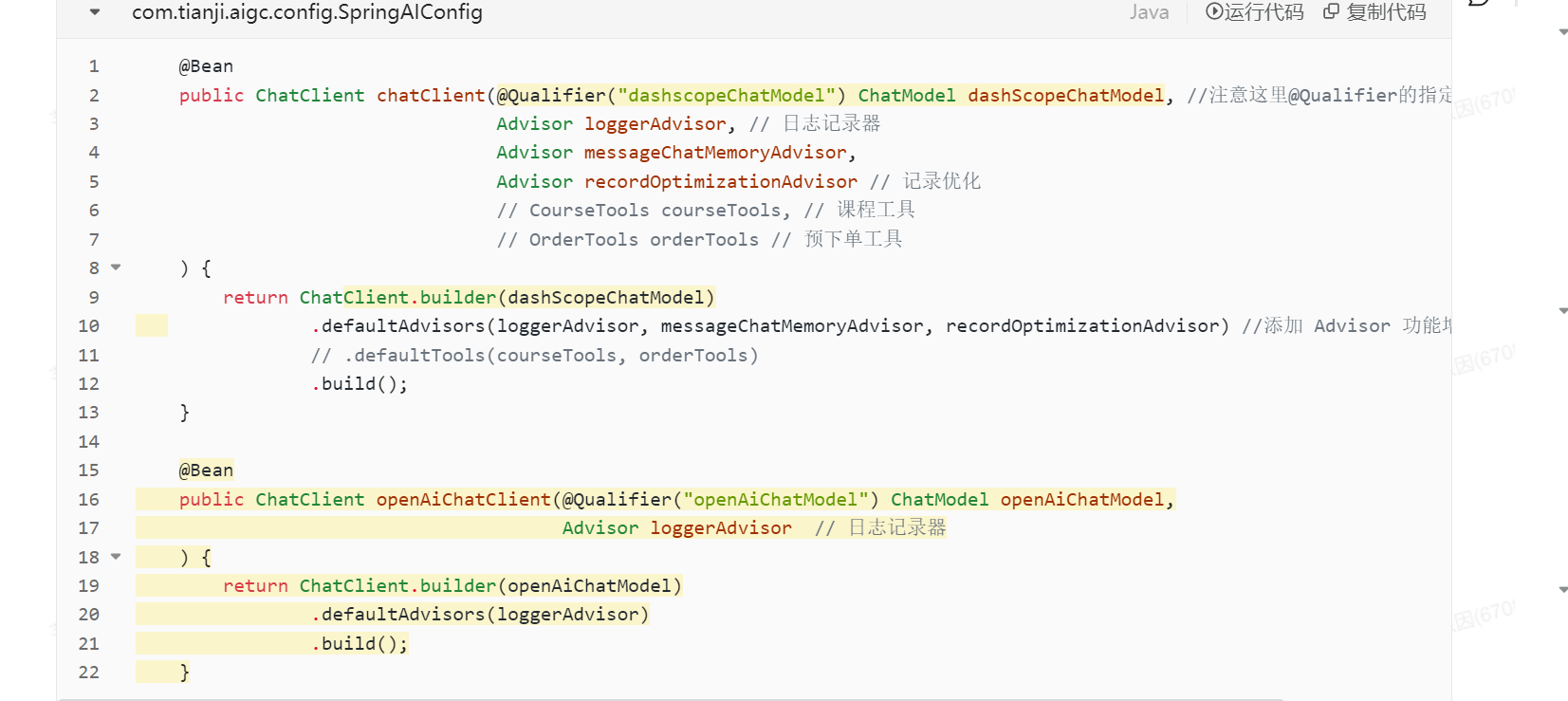
实现思路:原项目中学生提问后会调用Learning-Service的接口,需要在这个接口中增加一个异步方法去调用AI模块中的自动回复的API,而AI模块需要写相关自动回复的逻辑并将这个API定义为Feign接口。(这里就不细讲了)
(自动回复比较简单,不需要使用那么多Advisor,这里可以定义一个新的ChatClient)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)