基于 Python + LangChain + React 实现前端项目生成器
前言
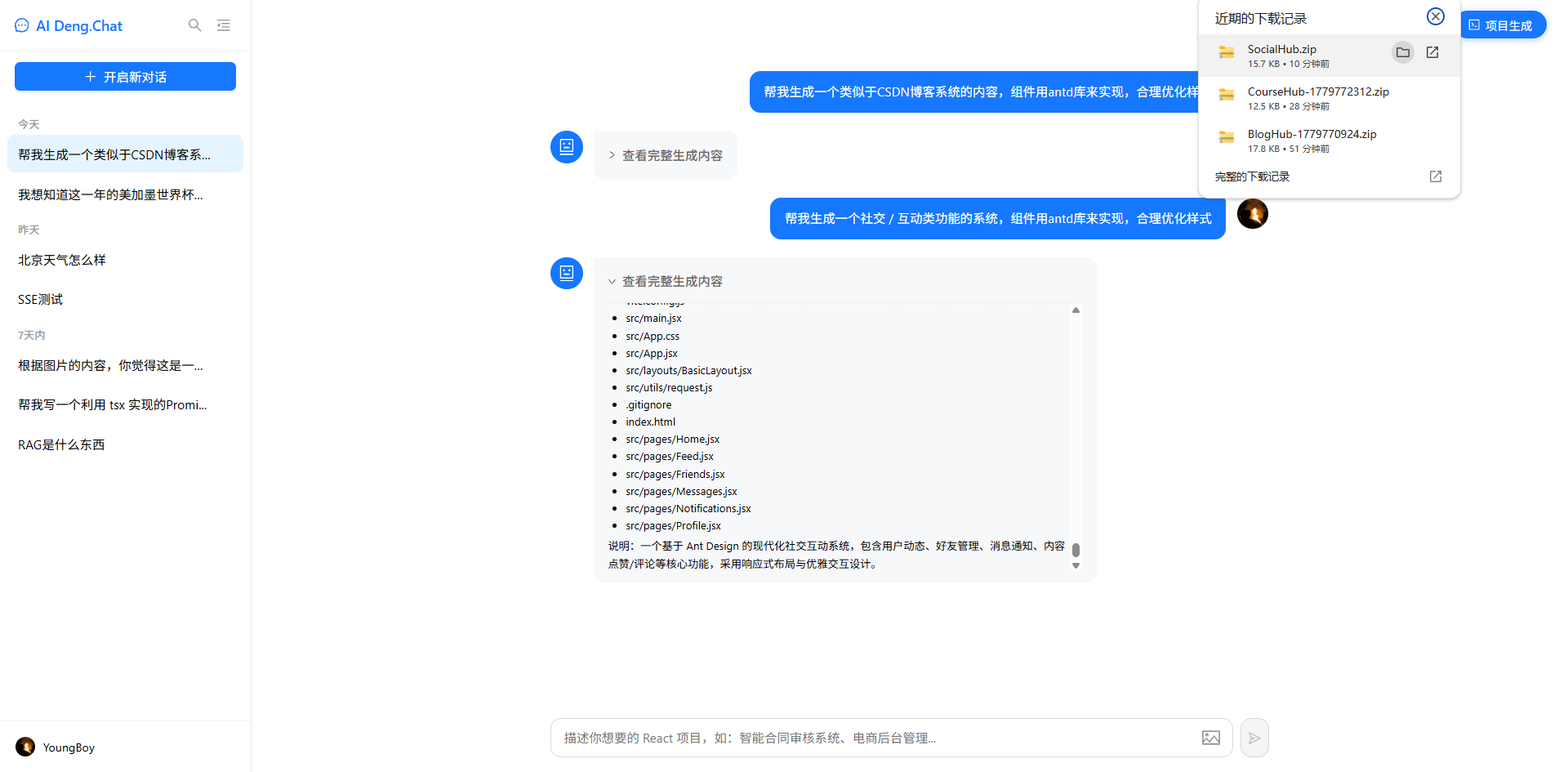
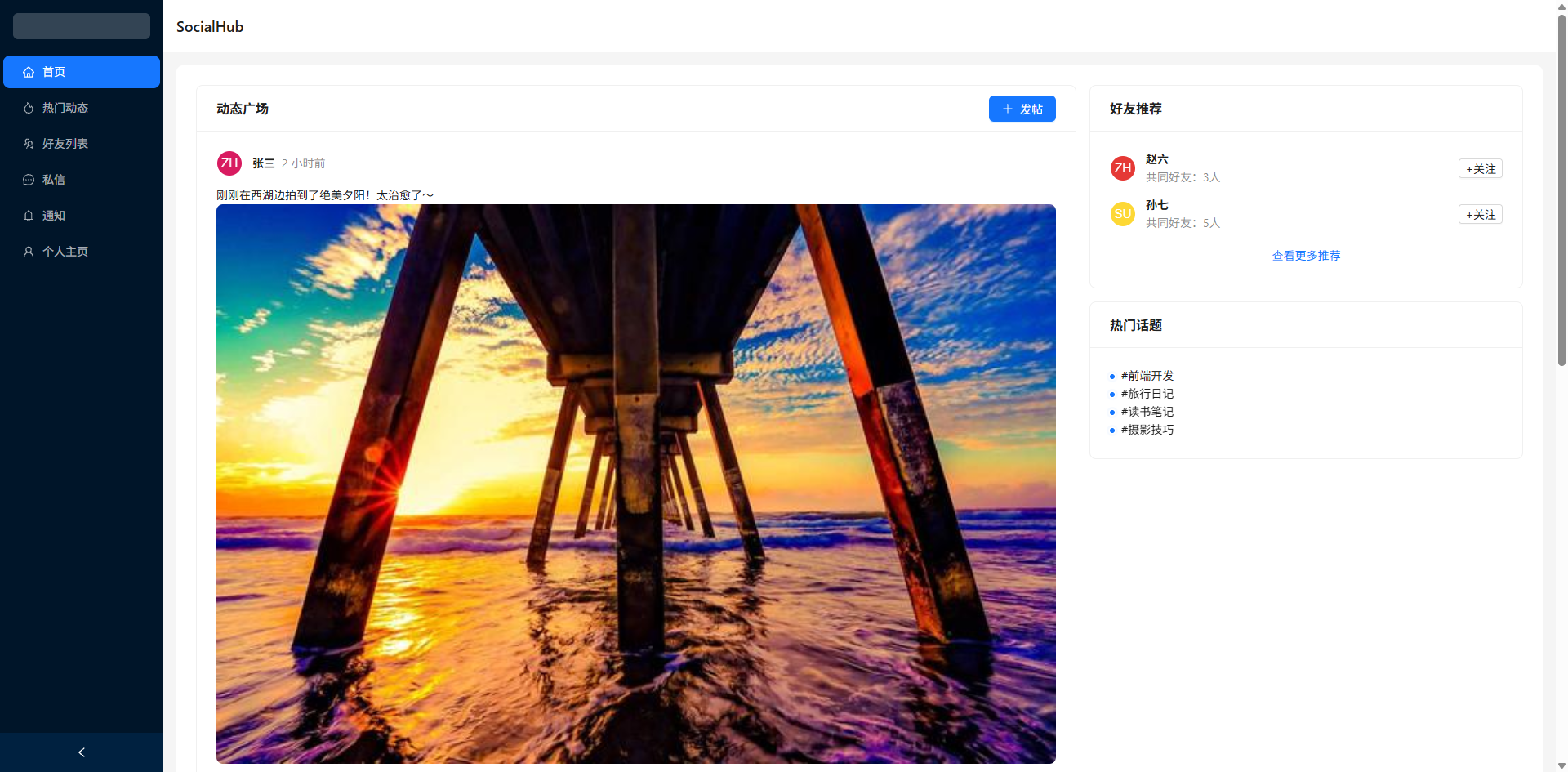
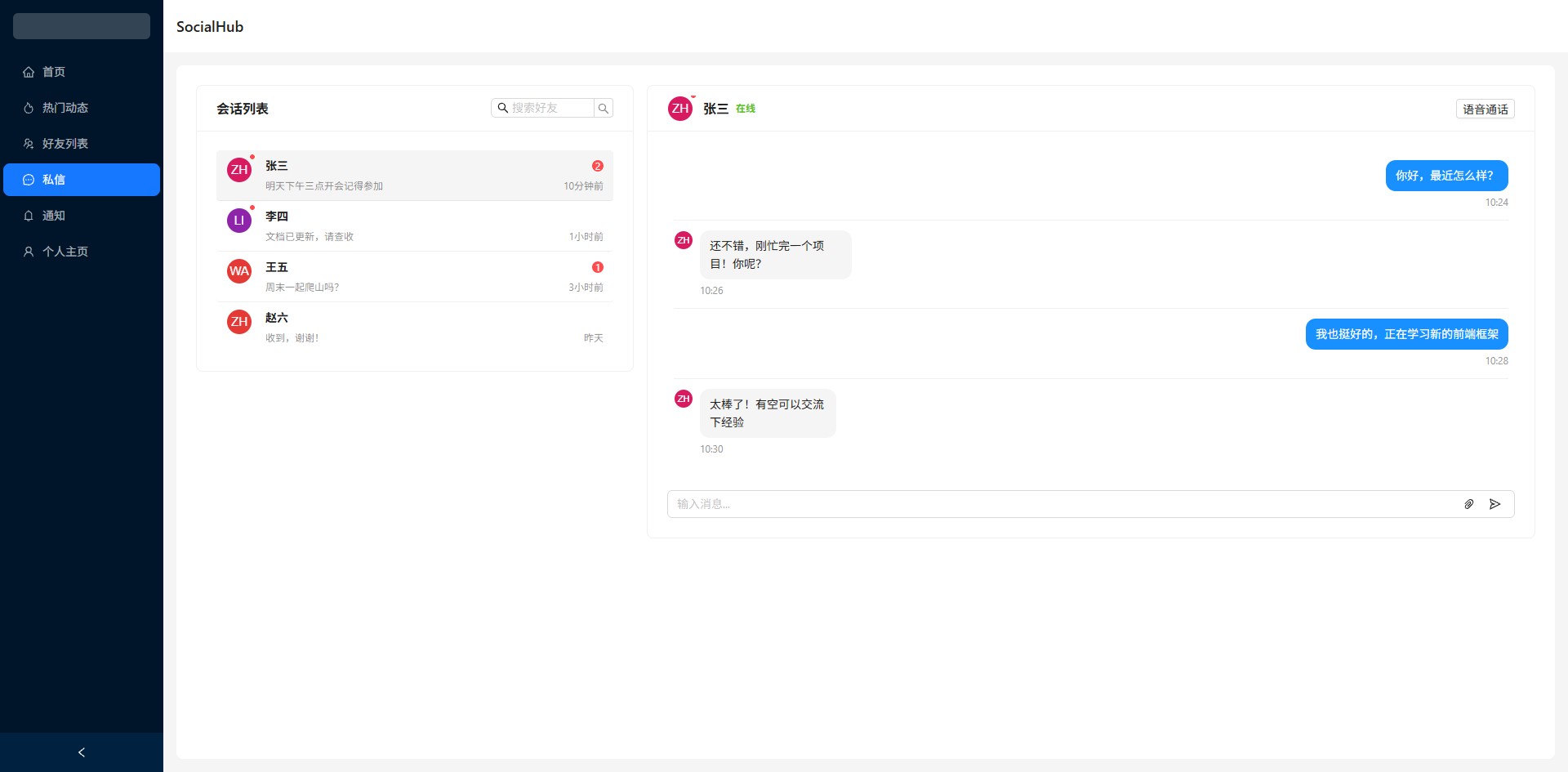
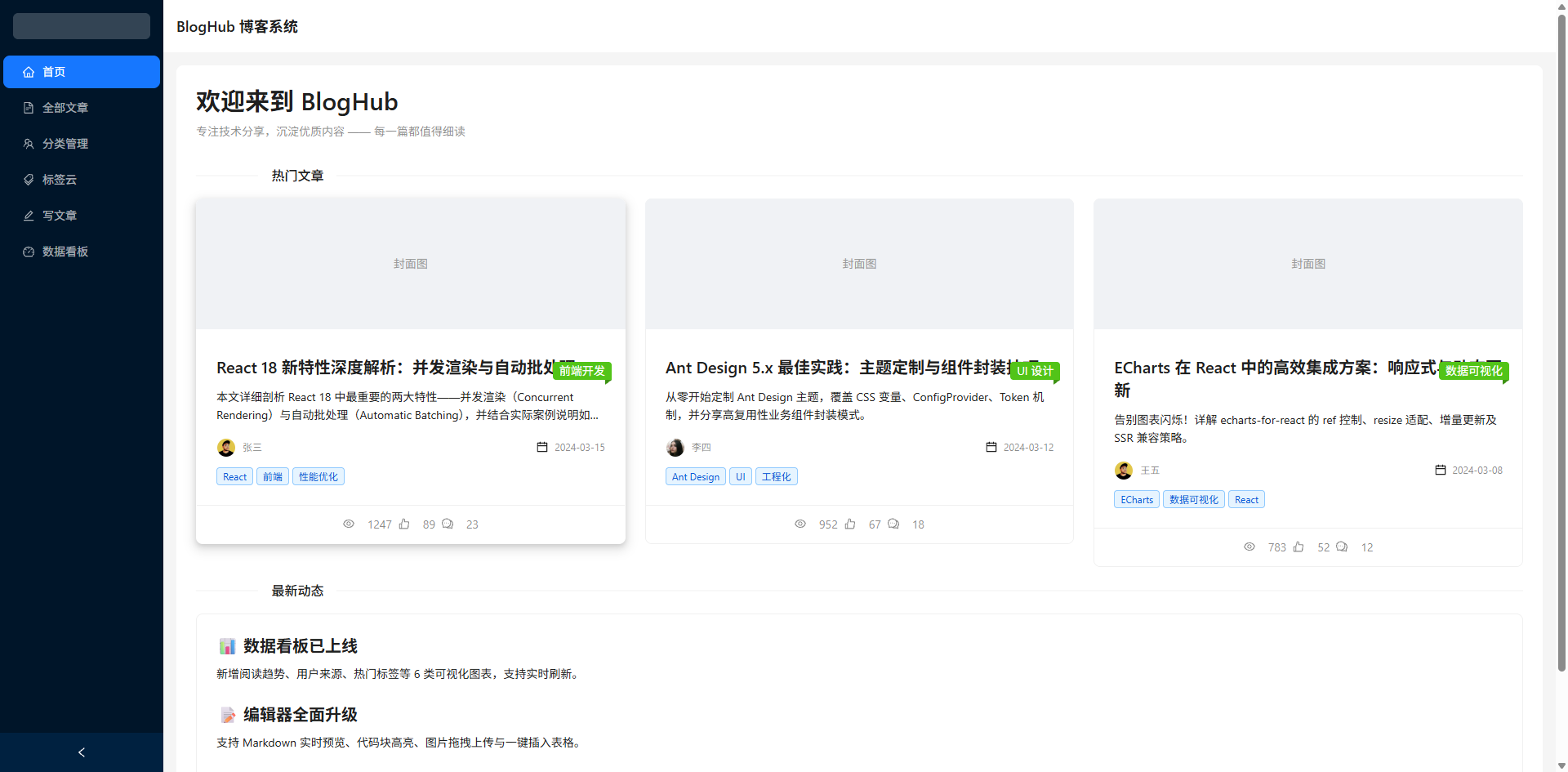
在 AI 辅助开发日益普及的今天,如何让大模型不只是回答问题,而是直接生成可运行的项目代码?本文将介绍如何基于 Python + LangChain + React,实现一个前端项目生成器:用户用自然语言描述需求,AI 自动生成完整的 React + Vite + Ant Design 项目文件并打包下载,npm install && npm run dev 即可运行。
注意:npm run dev成功运行之后可能会存在一定的前端的编译错误(插件未导入、标签等),这是因为:
LLM 生成不保证 100% 准确 — 无论提示词写多详细的规则,模型在生成长代码时仍然会遗漏导入、写错组件名。这是大模型的固有限制,尤其在生成长文件时上下文注意力会衰减。
修复即可!!!!!!
1. 创建后端 project_generator.py 模块
这是整个功能的核心模块,负责:构造系统提示词、流式调用 LLM、解析 JSON、自动修复导入问题、打包 ZIP 文件。
1.1 系统提示词设计
系统提示词需要严格约束 LLM 的输出格式和依赖版本,确保生成的项目可以正常运行:
PROJECT_SYSTEM_PROMPT = (
"你是一个专业的前端项目生成器。根据用户描述生成可运行的 React 项目。\n\n"
"## 依赖(只用这些,不加其他包)\n"
"dependencies: react@^18.2.0, react-dom@^18.2.0, antd@^5.12.0, "
"react-router-dom@^6.21.0, axios@^1.6.0, zustand@^4.4.0, "
"@ant-design/icons@^5.2.0, dayjs@^1.11.0, echarts@^5.5.0, echarts-for-react@^3.0.2\n"
"devDependencies: vite@^5.0.0, @vitejs/plugin-react@^4.2.0\n\n"
# ... 核心文件模板 ...
"## 返回格式(纯 JSON,无 markdown)\n"
'{"project_name": "英文项目名", "description": "描述", '
'"files": [{"path": "路径", "content": "完整内容"}]}\n'
)
关键设计点:
- 锁定依赖版本 — 避免生成不存在的包(如
@ant-design/plots@^1.2.9) - 固定框架文件模板 —
vite.config.js、main.jsx、App.jsx、BasicLayout.jsx等核心文件用固定模板,LLM 只填充路由和页面 - 图表用 echarts — 通过
echarts-for-react统一处理,避免 LLM 导入不存在的 recharts 组件
1.2 流式调用 LLM
使用 llm.stream() 而非 llm.invoke(),实现实时流式输出,避免长时间阻塞导致 SSE 超时:
def generate_project_stream(message: str, llm):
from langchain_core.messages import SystemMessage, HumanMessage
parts = []
for chunk in llm.stream([
SystemMessage(content=PROJECT_SYSTEM_PROMPT),
HumanMessage(content=message),
]):
token = chunk.content
if token:
parts.append(token)
yield token
generate_project_stream.result = "".join(parts)
1.3 JSON 解析容错
LLM 返回的 JSON 可能被 markdown 代码块包裹,需要多层容错解析:
def parse_project_json(raw: str) -> dict:
raw = raw.strip()
# 尝试直接解析
try:
return json.loads(raw)
except json.JSONDecodeError:
pass
# 尝试去除 markdown 代码块
code_match = re.search(r"```(?:json)?\s*([\s\S]*?)```", raw)
if code_match:
try:
return json.loads(code_match.group(1).strip())
except json.JSONDecodeError:
pass
# 尝试提取最外层 JSON 对象
brace_match = re.search(r"\{[\s\S]*\}", raw)
if brace_match:
try:
return json.loads(brace_match.group(0))
except json.JSONDecodeError:
pass
raise ValueError(f"无法解析 JSON:{raw[:500]}")
1.4 自动修复导入问题(核心难点)
LLM 生成的代码或多或少会有导入缺失、重复声明等问题。我们通过 fix_file_imports 函数在打包 ZIP 之前自动修复:
def fix_file_imports(content: str, filepath: str) -> str:
# 预扫描:收集文件中所有已声明的变量名
declared = set()
for m in re.finditer(r"import\s*\{([^}]*)\}\s*from", content):
declared.update(n.strip() for n in m.group(1).split(",") if n.strip())
for m in re.finditer(r"const\s*\{([^}]*)\}\s*=", content):
declared.update(n.strip() for n in m.group(1).split(",") if n.strip())
# 0. 补全缺失的 antd 组件导入(排除已声明的,避免重复)
# 1. 补全缺失的 @ant-design/icons 图标导入
# 2. 移除黑名单组件(Comment、BackTop、PageHeader 等)
# 3. 移除不存在的第三方库导入(recharts、@ant-design/charts 等)
# 4. 补全 React 导入
核心逻辑:先扫描所有已声明的变量(import + const 解构),补全时排除已声明的,从根源解决重复声明问题。
1.5 ZIP 打包
def create_project_zip(project_data: dict) -> tuple:
project_data = fix_project_files(project_data) # 打包前自动修复
os.makedirs(STATIC_DIR, exist_ok=True)
project_name = sanitize_filename(project_data.get("project_name", "react-project"))
zip_filename = f"{project_name}-{int(time.time())}.zip"
# ... 使用 zipfile + BytesIO 在内存中打包 ...
return zip_filename, zip_filepath
1.6 完整代码
"""React 项目生成器 - 根据用户描述生成完整的项目初始化文件"""
import os
import re
import io
import json
import time
import zipfile
STATIC_DIR = os.path.join(os.path.dirname(__file__), "static", "generated")
PROJECT_SYSTEM_PROMPT = (
"你是一个专业的前端项目生成器。根据用户描述生成可运行的 React 项目。\n\n"
"## 依赖(只用这些,不加其他包)\n"
"dependencies: react@^18.2.0, react-dom@^18.2.0, antd@^5.12.0, react-router-dom@^6.21.0, axios@^1.6.0, zustand@^4.4.0, @ant-design/icons@^5.2.0, dayjs@^1.11.0, echarts@^5.5.0, echarts-for-react@^3.0.2\n"
"devDependencies: vite@^5.0.0, @vitejs/plugin-react@^4.2.0\n\n"
"## 核心规则\n"
"- 只从 antd 导入常用组件(Button, Input, Table, Form, Select, Modal, Card, Row, Col, Tag, Space, Typography, Divider, Tabs, Menu, Dropdown, Badge, Avatar, Upload, message, Popconfirm, Tooltip, Pagination, DatePicker, Statistic, List, Progress, Spin, Empty, Result, Steps, Alert, Image, Layout, Collapse, Descriptions, Timeline, Switch, Radio, Checkbox, Slider, Rate, ConfigProvider, Anchor, Affix)\n"
"- 禁止从 antd 导入:Comment, BackTop, PageHeader, CartesianGrid 等不存在的组件\n"
"- 图表用 echarts-for-react:import ReactECharts from 'echarts-for-react'; 然后用 <ReactECharts option={...} />\n"
"- 每个使用的 @ant-design/icons 图标都要 import\n"
"- 所有导入只从 antd / @ant-design/icons / react / react-router-dom / echarts-for-react / zustand / axios 中取\n\n"
"## 固定的框架文件(必须原样使用,只替换标记处)\n\n"
"### vite.config.js(固定)\n"
"import { defineConfig } from 'vite';\n"
"import react from '@vitejs/plugin-react';\n"
"export default defineConfig({ plugins: [react()], server: { port: 3000, open: true } });\n\n"
"### src/main.jsx(固定)\n"
"import React from 'react';\n"
"import ReactDOM from 'react-dom/client';\n"
"import { BrowserRouter } from 'react-router-dom';\n"
"import App from './App';\n"
"import './App.css';\n"
"ReactDOM.createRoot(document.getElementById('root')).render(\n"
" <React.StrictMode><BrowserRouter><App /></BrowserRouter></React.StrictMode>\n"
");\n\n"
"### src/App.jsx(模板,替换 PAGE_IMPORTS 和 PAGE_ROUTES)\n"
"import React from 'react';\n"
"import { Routes, Route, Navigate } from 'react-router-dom';\n"
"import BasicLayout from './layouts/BasicLayout';\n"
"/* __PAGE_IMPORTS__ */\n"
"function App() {\n"
" return (\n"
" <Routes>\n"
" <Route path=\"/\" element={<BasicLayout />}>\n"
" /* __PAGE_ROUTES__ */\n"
" <Route path=\"*\" element={<Navigate to=\"/\" replace />} />\n"
" </Route>\n"
" </Routes>\n"
" );\n"
"}\n"
"export default App;\n\n"
"### src/layouts/BasicLayout.jsx(模板,替换 ICON_IMPORTS, MENU_ITEMS, PROJECT_TITLE)\n"
"import React, { useState } from 'react';\n"
"import { Layout, Menu } from 'antd';\n"
"import { Outlet, useNavigate, useLocation } from 'react-router-dom';\n"
"/* __ICON_IMPORTS__ */\n"
"const { Header, Sider, Content } = Layout;\n"
"const menuItems = [/* __MENU_ITEMS__ */];\n"
"function BasicLayout() {\n"
" const navigate = useNavigate();\n"
" const location = useLocation();\n"
" const [collapsed, setCollapsed] = useState(false);\n"
" return (\n"
" <Layout style={{ minHeight: '100vh' }}>\n"
" <Sider collapsible collapsed={collapsed} onCollapse={setCollapsed}>\n"
" <div style={{ height: 32, margin: 16, background: 'rgba(255,255,255,0.2)', borderRadius: 6 }} />\n"
" <Menu theme=\"dark\" selectedKeys={[location.pathname]} mode=\"inline\" items={menuItems} onClick={({ key }) => navigate(key)} />\n"
" </Sider>\n"
" <Layout>\n"
" <Header style={{ background: '#fff', padding: '0 16px', fontSize: 18, fontWeight: 600 }}>__PROJECT_TITLE__</Header>\n"
" <Content style={{ margin: 16, padding: 24, background: '#fff', borderRadius: 8, minHeight: 280 }}>\n"
" <Outlet />\n"
" </Content>\n"
" </Layout>\n"
" </Layout>\n"
" );\n"
"}\n"
"export default BasicLayout;\n\n"
"### src/App.css(固定)\n"
"* { margin: 0; padding: 0; box-sizing: border-box; }\n"
"body { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif; }\n\n"
"### src/utils/request.js(固定)\n"
"import axios from 'axios';\n"
"import { message } from 'antd';\n"
"const request = axios.create({ baseURL: '/api', timeout: 10000 });\n"
"request.interceptors.request.use((config) => { const token = localStorage.getItem('token'); if (token) config.headers.Authorization = `Bearer ${token}`; return config; }, (error) => Promise.reject(error));\n"
"request.interceptors.response.use((response) => response.data, (error) => { message.error(error.response?.data?.message || '请求失败'); return Promise.reject(error); });\n"
"export default request;\n\n"
"### .gitignore(固定)\n"
"node_modules\ndist\n.env\n.DS_Store\n\n"
"### index.html(替换 PROJECT_TITLE)\n"
"<!DOCTYPE html>\n<html lang=\"zh-CN\">\n<head><meta charset=\"UTF-8\" /><meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" /><title>__PROJECT_TITLE__</title></head>\n<body><div id=\"root\"></div><script type=\"module\" src=\"/src/main.jsx\"></script></body>\n</html>\n\n"
"## 你需要生成的文件\n"
"1. package.json(含 scripts: dev/build/preview)\n"
"2. 以上框架文件(替换占位符)\n"
"3. src/pages/ 下的页面组件(完整可运行,用 antd 构建,含 mock 数据)\n\n"
"## 页面组件要求\n"
"- 必须有 export default\n"
"- 使用 antd 组件 + antd icons\n"
"- Table 要有 columns 和 mock data\n"
"- Form 要有完整的表单字段\n"
"- 每个组件完整可渲染,无 TODO 或空函数体\n\n"
"## 返回格式(纯 JSON,无 markdown)\n"
'{"project_name": "英文项目名", "description": "描述", "files": [{"path": "路径", "content": "完整内容"}]}\n'
)
def generate_project_stream(message: str, llm):
"""流式调用 LLM 生成项目文件,yield 每个 token,流结束后可通过 .result 获取完整文本"""
from langchain_core.messages import SystemMessage, HumanMessage
parts = []
for chunk in llm.stream([
SystemMessage(content=PROJECT_SYSTEM_PROMPT),
HumanMessage(content=message),
]):
token = chunk.content
if token:
parts.append(token)
yield token
# 流结束后,把完整文本存到生成器对象的属性上
generate_project_stream.result = "".join(parts)
def parse_project_json(raw: str) -> dict:
"""解析 LLM 返回的 JSON 文本,容错处理"""
raw = raw.strip()
try:
return json.loads(raw)
except json.JSONDecodeError:
pass
code_match = re.search(r"```(?:json)?\s*([\s\S]*?)```", raw)
if code_match:
try:
return json.loads(code_match.group(1).strip())
except json.JSONDecodeError:
pass
brace_match = re.search(r"\{[\s\S]*\}", raw)
if brace_match:
try:
return json.loads(brace_match.group(0))
except json.JSONDecodeError:
pass
raise ValueError(f"LLM 返回的内容无法解析为 JSON。原始内容前 500 字符:{raw[:500]}")
def sanitize_filename(name: str) -> str:
"""清理项目名称为合法的文件名"""
name = re.sub(r"[^a-zA-Z0-9\-_]", "-", name)
name = re.sub(r"-+", "-", name).strip("-")
return name or "react-project"
# antd v5 中已移除或不存在的组件黑名单
ANTD_BLACKLIST = {
"Comment", "BackTop", "PageHeader", "Mention", "LocaleProvider",
"CartesianGrid", "LineChart", "BarChart", "PieChart", "AreaChart",
"ResponsiveContainer", "RadarChart", "RadialBarChart", "ScatterChart",
"TreemapChart", "SunburstChart", "HeatmapChart", "SankeyChart",
"FunnelChart", "GaugeChart", "GraphChart", "ThemeMapping",
"Chart", "ChartCanvas",
}
# antd v5 真实存在的组件(用于自动补全导入)
ANTD_COMPONENTS = {
"Button", "Input", "InputNumber", "Search", "TextArea",
"Table", "Form", "Select", "Modal", "Card",
"Row", "Col", "Tag", "Space", "Typography", "Divider", "Tabs",
"Menu", "Dropdown", "Badge", "Avatar", "Upload",
"Popconfirm", "Tooltip", "Breadcrumb", "Pagination",
"Switch", "Radio", "Checkbox", "DatePicker", "TimePicker",
"Slider", "Rate", "Progress", "Spin", "Empty", "Result",
"Statistic", "Descriptions", "Timeline", "Steps", "Alert",
"Image", "Calendar", "Cascader", "Transfer", "TreeSelect",
"Tree", "Layout", "List", "Collapse", "Anchor", "Affix",
"ConfigProvider", "Popover", "AutoComplete", "Mentions",
"Segmented", "Watermark", "Tour", "FloatButton", "QRCode",
"ColorPicker", "Notification",
# Typography 子组件
"Title", "Text", "Paragraph",
# 其他常见子组件
"Option", "TabPane", "RangePicker", "Item", "Group",
"Header", "Sider", "Content", "Footer",
"Panel", "Item", "Meta",
}
# HTML 标签(不应该是 antd 组件)
HTML_TAGS = {
"div", "span", "p", "a", "img", "h1", "h2", "h3", "h4", "h5", "h6",
"ul", "ol", "li", "table", "tr", "td", "th", "thead", "tbody", "tfoot",
"form", "input", "button", "select", "option", "textarea", "label",
"section", "article", "header", "footer", "nav", "main", "aside",
"br", "hr", "strong", "em", "code", "pre", "blockquote",
"iframe", "video", "audio", "source", "canvas", "svg", "path",
}
def fix_file_imports(content: str, filepath: str) -> str:
"""自动修复单个文件的导入问题"""
if not filepath.endswith(('.jsx', '.js', '.tsx', '.ts')):
return content
# 预扫描:收集文件中所有已声明的变量名(import 和 const 解构)
declared = set()
# 从 import 语句中收集
for m in re.finditer(r"import\s*\{([^}]*)\}\s*from", content):
declared.update(n.strip() for n in m.group(1).split(",") if n.strip())
# 从 const 解构中收集:const { X, Y } = Something
for m in re.finditer(r"const\s*\{([^}]*)\}\s*=", content):
declared.update(n.strip() for n in m.group(1).split(",") if n.strip())
# 从 const/function 声明中收集:const Xxx = / function Xxx
for m in re.finditer(r"(?:const|let|var|function)\s+(\w+)", content):
declared.add(m.group(1))
# 0. 扫描 JSX 中使用的 antd 组件,自动补全缺失的 import(跳过已声明的)
jsx_tag_pattern = re.compile(r'<([A-Z][A-Za-z]*)[\s/>.]')
used_components = set(jsx_tag_pattern.findall(content))
used_antd = used_components & ANTD_COMPONENTS - ANTD_BLACKLIST - HTML_TAGS
used_antd = {c for c in used_antd if not (c.endswith('Outlined') or c.endswith('Filled') or c.endswith('TwoTone'))}
# 排除已声明的变量名,避免重复
used_antd -= declared
if used_antd:
existing_antd_import = re.search(r"import\s*\{([^}]*)\}\s*from\s*['\"]antd['\"]", content)
existing_antd = set()
if existing_antd_import:
existing_antd = {name.strip() for name in existing_antd_import.group(1).split(",") if name.strip()}
missing_antd = used_antd - existing_antd
if missing_antd:
all_antd = sorted(existing_antd | missing_antd)
new_import = f"import {{ {', '.join(all_antd)} }} from 'antd';"
if existing_antd_import:
content = content[:existing_antd_import.start()] + new_import + content[existing_antd_import.end():]
else:
first_import = re.search(r"import\s", content)
if first_import:
insert_pos = content.index('\n', first_import.start()) + 1
content = content[:insert_pos] + new_import + '\n' + content[insert_pos:]
# 1. 扫描图标,同样排除已声明的
icon_pattern = re.compile(r'<(\w+(?:Outlined|Filled|TwoTone))[\s/>]')
used_icons = set(icon_pattern.findall(content)) - declared
icon_pattern = re.compile(r'<(\w+(?:Outlined|Filled|TwoTone))[\s/>]')
used_icons = set(icon_pattern.findall(content))
if used_icons:
existing_icon_import = re.search(r"import\s*\{([^}]*)\}\s*from\s*['\"]@ant-design/icons['\"]", content)
existing_icons = set()
if existing_icon_import:
existing_icons = {name.strip() for name in existing_icon_import.group(1).split(",") if name.strip()}
missing_icons = used_icons - existing_icons
if missing_icons:
all_icons = sorted(existing_icons | missing_icons)
new_import = f"import {{ {', '.join(all_icons)} }} from '@ant-design/icons';"
if existing_icon_import:
content = content[:existing_icon_import.start()] + new_import + content[existing_icon_import.end():]
else:
first_import = re.search(r"import\s", content)
if first_import:
insert_pos = content.index('\n', first_import.start()) + 1
content = content[:insert_pos] + new_import + '\n' + content[insert_pos:]
# 2. 移除从 antd 导入的黑名单组件
antd_import_match = re.search(r"import\s*\{([^}]*)\}\s*from\s*['\"]antd['\"]", content)
if antd_import_match:
imported = [name.strip() for name in antd_import_match.group(1).split(",") if name.strip()]
cleaned = [name for name in imported if name not in ANTD_BLACKLIST]
if len(cleaned) < len(imported):
if cleaned:
new_import = f"import {{ {', '.join(cleaned)} }} from 'antd';"
content = content[:antd_import_match.start()] + new_import + content[antd_import_match.end():]
else:
line_start = content.rfind('\n', 0, antd_import_match.start()) + 1
line_end = content.index('\n', antd_import_match.end())
content = content[:line_start] + content[line_end + 1:]
# 3. 移除黑名单组件在代码中的使用
for comp in ANTD_BLACKLIST:
content = re.sub(rf'<{comp}(\s[^>]*)?>(.*?)</{comp}>', r'<Card>\2</Card>', content, flags=re.DOTALL)
content = re.sub(rf'<{comp}\s[^>]*/>', '<Card>占位</Card>', content)
# 4. 确保有 React 导入
if filepath.endswith('.jsx') and 'import React' not in content and 'from "react"' not in content and "from 'react'" not in content:
content = "import React from 'react';\n" + content
# 5. 移除不存在的第三方库导入
for pattern in [
r"import\s+.*from\s*['\"]@ant-design/charts['\"];?\n?",
r"import\s+.*from\s*['\"]@ant-design/plots['\"];?\n?",
r"import\s+.*from\s*['\"]@ant-design/comment['\"];?\n?",
r"import\s+.*from\s*['\"]recharts['\"];?\n?",
]:
content = re.sub(pattern, '', content)
return content
def fix_project_files(project_data: dict) -> dict:
"""对所有生成的文件执行自动修复"""
for file_info in project_data.get("files", []):
path = file_info.get("path", "")
content = file_info.get("content", "")
if content:
file_info["content"] = fix_file_imports(content, path)
return project_data
def create_project_zip(project_data: dict) -> tuple:
"""将项目数据打包为 ZIP 文件,返回 (filename, filepath)"""
project_data = fix_project_files(project_data)
os.makedirs(STATIC_DIR, exist_ok=True)
project_name = sanitize_filename(project_data.get("project_name", "react-project"))
timestamp = int(time.time())
zip_filename = f"{project_name}-{timestamp}.zip"
zip_filepath = os.path.join(STATIC_DIR, zip_filename)
buffer = io.BytesIO()
with zipfile.ZipFile(buffer, "w", zipfile.ZIP_DEFLATED) as zf:
for file_info in project_data.get("files", []):
path = file_info.get("path", "")
content = file_info.get("content", "")
if path:
zf.writestr(f"{project_name}/{path}", content)
with open(zip_filepath, "wb") as f:
f.write(buffer.getvalue())
return zip_filename, zip_filepath
def cleanup_old_projects(max_age_seconds: int = 3600):
"""清理超过指定时间的生成文件"""
if not os.path.exists(STATIC_DIR):
return
now = time.time()
for filename in os.listdir(STATIC_DIR):
if filename == ".gitkeep":
continue
filepath = os.path.join(STATIC_DIR, filename)
if os.path.isfile(filepath) and (now - os.path.getmtime(filepath)) > max_age_seconds:
try:
os.remove(filepath)
except OSError:
pass
2. 在 server.py 中添加 /api/project/generate 端点
新增 SSE 流式端点,流式推送 LLM token,完成后返回 ZIP 下载链接:
# ========== 项目生成接口 ==========
@app.route("/api/project/generate", methods=["POST"])
def api_project_generate():
"""根据用户描述生成 React 项目文件,返回 SSE 流,完成后提供 ZIP 下载"""
data = request.json or {}
message = data.get("message", "")
session_id = data.get("session_id")
if not message.strip():
return jsonify({"code": 400, "msg": "消息不能为空"}), 400
def generate():
try:
# 创建或获取对话
conv_id = get_or_create_conversation(session_id)
save_message(conv_id, "user", message)
# 自动设置标题
existing = get_messages(conv_id)
if len(existing) <= 1:
update_title(conv_id, message[:20])
yield f"data: {json.dumps({'token': '正在生成项目文件,请稍候...\n\n'})}\n\n"
# 流式调用 LLM,逐 token 推送给前端
llm = get_chat_model()
for token in generate_project_stream(message, llm):
yield f"data: {json.dumps({'token': token})}\n\n"
# 流结束,获取完整响应并解析
raw_text = generate_project_stream.result or ""
project_data = parse_project_json(raw_text)
file_count = len(project_data.get("files", []))
file_list = "\n".join(f" - {f['path']}" for f in project_data.get("files", []))
summary = (
f"\n\n---\n**项目「{project_data.get('project_name', 'project')}」生成完成!**\n"
f"共 {file_count} 个文件:\n{file_list}\n\n"
f"说明:{project_data.get('description', '')}"
)
yield f"data: {json.dumps({'token': summary})}\n\n"
# 打包 ZIP
cleanup_old_projects()
zip_filename, _ = create_project_zip(project_data)
# 保存助手回复
save_message(conv_id, "assistant", raw_text + summary)
yield f"data: {json.dumps({'done': True, 'session_id': conv_id, 'download_url': f'/static/generated/{zip_filename}', 'file_count': file_count, 'project_name': project_data.get('project_name', 'project')})}\n\n"
except ValueError as e:
yield f"data: {json.dumps({'error': str(e)})}\n\n"
except Exception as e:
import traceback
traceback.print_exc()
yield f"data: {json.dumps({'error': f'项目生成失败: {str(e)}'})}\n\n"
resp = Response(stream_with_context(generate()), mimetype="text/event-stream")
resp.headers["Cache-Control"] = "no-cache"
resp.headers["X-Accel-Buffering"] = "no"
return resp3. 前端 chatStore 添加 mode 状态
在 Zustand store 中添加项目生成相关状态:
// 新增状态
mode: 'chat', // 'chat' | 'project'
projectGenerating: false, // 是否正在生成
projectResult: null, // { downloadUrl, fileCount, projectName }
// 新增 actions
setMode: (mode) => set({ mode }),
startProjectGeneration: () => set({ projectGenerating: true, projectResult: null }),
finishProjectGeneration: (result) => set({ projectGenerating: false, projectResult: result }),
// 持久化到 localStorage
partialize: (state) => ({
currentConversationId: state.currentConversationId,
useRag: state.useRag,
mode: state.mode,
projectResult: state.projectResult, // 刷新后下载按钮不消失
}),
4. 前端 chatService 添加 generateProject 方法
仿照 streamChat 实现 SSE 流式读取,并在完成后触发文件下载:
/**
* SSE 项目生成
* @param {string} message - 项目描述
* @param {string|null} sessionId - 对话 ID
* @param {Object} callbacks - { onToken, onDone, onError }
* @returns {AbortController}
*/
generateProject(message, sessionId, callbacks) {
const { onToken, onDone, onError } = callbacks;
const controller = new AbortController();
fetch(`${BASE_URL}/api/project/generate`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
message,
session_id: sessionId || null,
}),
signal: controller.signal,
})
.then(async (response) => {
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const parts = buffer.split('\n\n');
buffer = parts.pop();
for (const part of parts) {
for (const line of part.split('\n')) {
if (!line.startsWith('data: ')) continue;
const raw = line.slice(6);
try {
const parsed = JSON.parse(raw);
if (parsed.error) {
onError(new Error(parsed.error));
return;
}
if (parsed.token) {
onToken(parsed.token);
}
if (parsed.done) {
onDone({
sessionId: parsed.session_id,
downloadUrl: parsed.download_url,
fileCount: parsed.file_count,
projectName: parsed.project_name,
});
return;
}
} catch {
// 忽略解析失败的行
}
}
}
}
onDone(null);
})
.catch((err) => {
if (err.name !== 'AbortError') {
onError(err);
}
});
return controller;
}
/**
* 下载项目 ZIP 文件
*/
async downloadProject(downloadUrl, fileName) {
try {
const response = await fetch(`${BASE_URL}${downloadUrl}`);
if (!response.ok) throw new Error('下载失败');
const blob = await response.blob();
const url = window.URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = url;
link.download = fileName || 'project.zip';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
window.URL.revokeObjectURL(url);
} catch (err) {
console.error('下载项目失败:', err);
}
}5. 修改 Chat.jsx 添加模式切换
在 mainArea 顶部添加自定义胶囊切换按钮,替代 Antd 的 Segmented:
<div className={styles.modeToggleBar}>
<div className={`${styles.modeTab} ${mode === 'chat' ? styles.modeTabActive : ''}`}
onClick={() => setMode('chat')}>
<MessageOutlined />
<span>AI 对话</span>
</div>
<div className={`${styles.modeTab} ${mode === 'project' ? styles.modeTabActive : ''}`}
onClick={() => setMode('project')}>
<CodeOutlined />
<span>项目生成</span>
</div>
</div>
6. 修改 ChatInput.jsx 支持项目生成模式
在 handleSend 中根据 mode 分流:
if (mode === 'project') {
startProjectGeneration();
abortRef.current = chatService.generateProject(text, convId, {
onToken: (token) => appendStreamContent(token),
onDone: (result) => {
finishStreaming();
finishProjectGeneration(result);
if (result?.downloadUrl) {
chatService.downloadProject(result.downloadUrl, `${result.projectName}.zip`);
}
},
onError: (err) => {
cancelStreaming();
finishProjectGeneration(null);
},
});
} else {
// 原有的 streamChat 逻辑
}
7. 修改 ChatMessages.jsx 适配项目模式
7.1 欢迎页根据模式切换
{mode === 'project' ? <CodeOutlined /> : <RobotOutlined />}
<h2>{mode === 'project' ? 'React 项目生成器' : 'AI Chat 助手'}</h2>
<p>{mode === 'project'
? '描述你想要的 React 项目,AI 将为你生成完整的项目代码并打包下载'
: '点击「开启新对话」或直接输入消息开始聊天'}</p>
7.2 流式内容默认折叠
项目模式下 LLM 输出的是 JSON,内容很长。使用 <details> 标签默认折叠,点击展开:
{mode === 'project' ? (
<details className={styles.streamingDetails}>
<summary className={styles.streamingSummary}>
<RightOutlined className={styles.detailsArrow} />
正在生成项目文件...
</summary>
<div className={styles.streamingCode}>
<ReactMarkdown>{streamingContent}</ReactMarkdown>
</div>
</details>
) : (
<ReactMarkdown>{streamingContent}</ReactMarkdown>
)}
7.3 下载卡片
生成完成后展示下载卡片,支持重新下载:
{projectResult && mode === 'project' && (
<div className={styles.projectResultCard}>
<div>
<div className={styles.projectResultTitle}>
{projectResult.projectName}.zip
</div>
<div className={styles.projectResultInfo}>
共 {projectResult.fileCount} 个文件
</div>
</div>
<Button type="primary" icon={<DownloadOutlined />}
onClick={() => chatService.downloadProject(...)}>
重新下载
</Button>
</div>
)}
8. 添加 SCSS 样式
模式切换按钮
.modeToggleBar {
padding: 12px 24px;
display: flex;
justify-content: flex-end;
gap: 4px;
}
.modeTab {
display: flex;
align-items: center;
gap: 6px;
padding: 6px 16px;
border-radius: 20px;
font-size: 14px;
color: #8c8c8c;
cursor: pointer;
transition: all 0.25s ease;
&:hover { color: #1677ff; background: #f0f5ff; }
}
.modeTabActive {
color: #fff;
background: #1677ff;
box-shadow: 0 2px 8px rgba(22, 119, 255, 0.3);
}
折叠样式
.streamingDetails {
summary {
cursor: pointer;
list-style: none;
&::-webkit-details-marker { display: none; }
}
&[open] .detailsArrow { transform: rotate(90deg); }
}
.streamingCode {
max-height: 300px;
overflow-y: auto;
margin-top: 8px;
padding-top: 8px;
border-top: 1px dashed #e8e8e8;
font-size: 12px;
}
下载卡片
.projectResultCard {
max-width: 800px;
margin: 12px auto 0;
padding: 14px 20px;
background: #f6ffed;
border: 1px solid #b7eb8f;
border-radius: 10px;
display: flex;
align-items: center;
justify-content: space-between;
}
总结
整个功能的实现流程:
用户描述需求 → 前端 SSE 流式请求 → 后端 LangChain 流式生成
→ JSON 解析容错 → 自动修复导入问题 → ZIP 打包
→ 返回下载链接 → 前端自动下载 + 展示下载卡片
核心难点与解决方案:
| 难点 | 方案 |
|---|---|
| LLM 生成不存在的依赖 | 锁定依赖版本 + 代码自动修复兜底 |
| 导入缺失(图标、组件) | 正则扫描 JSX 用法,自动补全 import |
| 重复声明(Typography 解构) | 预扫描所有已声明变量,补全时排除 |
| SSE 超时 | llm.stream() 替代 llm.invoke() |
仅供参考!!!!!!谢谢

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)