OpenAI工程师翁家翌:AI困扰学界30年的死结,被一段代码解开了
OpenAI工程师翁家翌:AI困扰学界30年的死结,被一段代码解开了
2016年AlphaGo打败李世石之后,我记得有篇报道里夹着一句话,大意是:它下完这盘棋,明天就不记得了。
当时觉得无所谓。现在才知道,那句话戳的是AI最深的伤。
“灾难性遗忘”——AI学了新任务,旧能力就没了。不是变差,是直接清空。这个问题困扰了整个学界30年,无数算法试过,最好的结果也就是"缓解"。我曾经真的以为这辈子等不到答案。
上周看到OpenAI工程师翁家翌发的一篇文章,《超越梯度的学习》。他不是在解这个问题——他绕过去了。

为什么AI会忘记?
过去十几年,AI学习的底层逻辑只有一条:调整神经网络的权重。
深度学习也好,ChatGPT微调也好,本质都是梯度下降。给一批新数据,反向传播,把参数往好的方向推一把。
麻烦就在这里。神经网络的所有"知识",都压在那堆参数里。你往新任务方向调,旧任务对应的参数就被顶走了。
就像在白纸上反复擦写。新的写上去,旧的就磨没了。
30年来学界的努力,基本上都是在想"怎么写了新的还能留住旧的"。但白纸就那么大,互相挤,这是结构性的问题。
翁家翌的思路是:换一张纸。

一个偷懒的念头
翁家翌在OpenAI之外,业余时间维护一个叫EnvPool的强化学习开源项目。遇到一个很实际的烦恼:每次测试游戏环境有没有跑对,都要启动一遍神经网络策略,成本太高,在持续集成流程里根本划不来。
他就想:能不能写几段简单规则,让AI在游戏里动起来,够测试用就行?不训练任何神经网络,用编码Agent来写规则策略——一种能自主写代码、改代码的AI程序。
几轮迭代之后,结果让他自己都没预料到。
Atari打砖块游戏,纯代码策略,分数从387爬到864。864是这个游戏的理论最高分。
MuJoCo四足蚂蚁机器人,先摸出有节奏的步态,再加短程规划,得分破了6000,跟顶级深度强化学习算法持平。
Atari57综合测试——57个游戏,342条搜索轨迹,全程没有人工干预,没有训练任何神经网络——在100万步时,代码策略的中位数得分已经压过PPO这类主流基线。
Agent整个过程只做了一件事:维护一套可以持续生长的代码系统。
这就是他后来正式提出的名字:启发式学习(Heuristic Learning)。
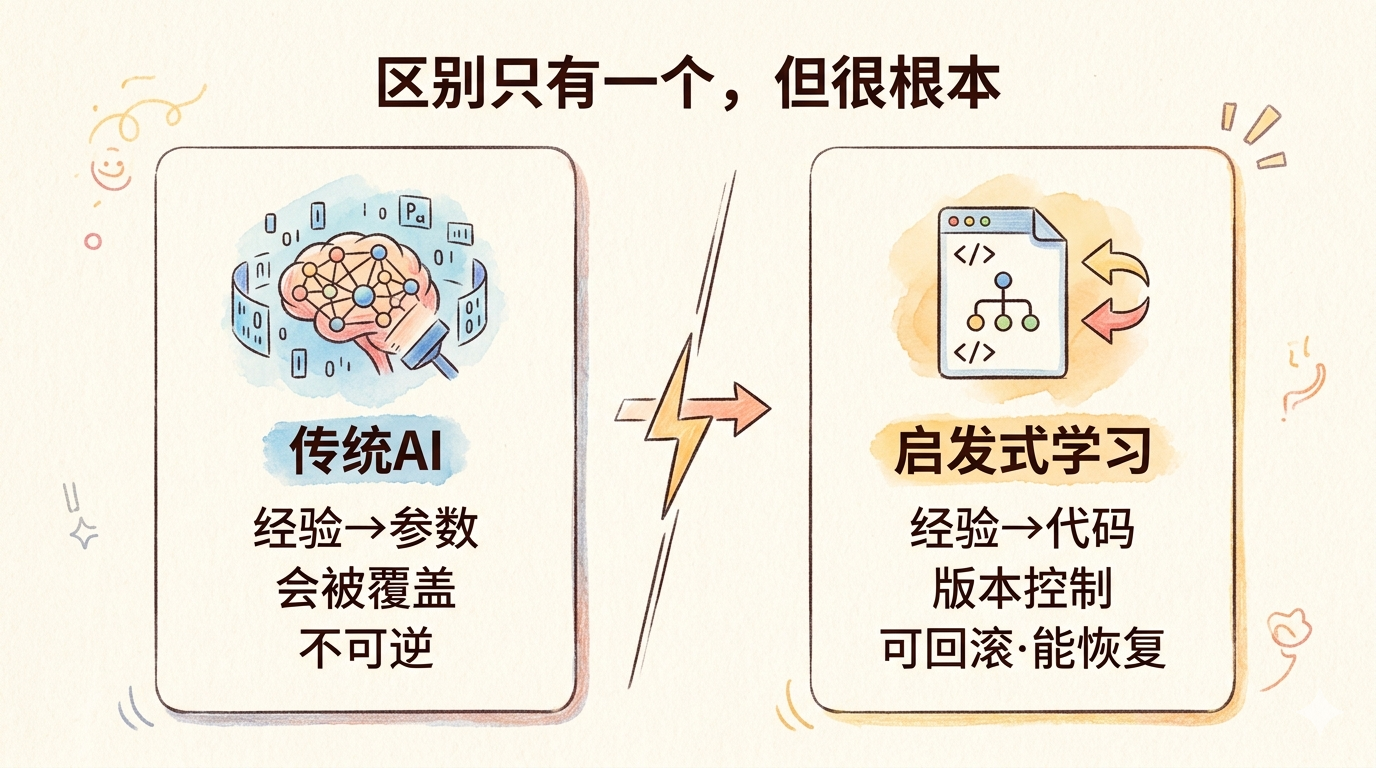
和传统AI,到底哪里不同
区别说起来很简单:传统AI把经验压进参数,启发式学习把经验写进代码。
参数里的东西,新训练一来就被覆盖,没有备份,出了问题不知道从哪里查。代码里的东西,有版本控制,可以回滚,可以逐行读,可以重建。
反馈渠道也不一样。传统AI只接受一种信号——奖励分数的高低。启发式学习可以接收测试用例有没有通过、日志报了什么错、人类哪里说不对,宽了好几倍。
更新速度更不用比。梯度下降需要大量样本缓慢收敛;直接改代码,一次有效的修改就能从差策略跳到好策略。
遗忘的方式则完全相反。传统AI忘掉旧能力,是参数被覆盖,不可逆,没有退路。启发式学习的旧能力固化在测试用例和规则集里,忘了可以查,可以恢复,起码知道哪里坏了。
那专家系统当年为什么死了?
读到这里很多人会想:用规则代替神经网络,这不就是几十年前的专家系统?当年不是失败了吗?
翁家翌的答案很直接:规则没问题,是人类养不起。
人工维护启发式规则,进入的是一个死循环。今天加一条规则修了A,明天发现B坏了,后天再加个判断,大后天所有人都不敢动任何一行代码。整个系统最终变成一个没人敢碰的"代码怪物",慢慢腐烂报废。
他用了个比喻——人工维护专家系统,就像工业革命前的手工纺纱。一个人可以纺得很好,但规模一大,维护成本就成了越不过去的墙。
纺织机改变了纺纱的生产曲线。编码Agent改变了启发式系统的维护曲线。
现在编码Agent可以自动读失败日志,自动改策略代码,自动跑测试确认没有破坏旧能力,自动把结果写进实验记录,然后接着下一轮。
以前人扛不住的维护成本,现在变成机器的无限循环。
有一个坑必须说清楚
启发式学习也会腐化,只是方式不同。
如果编码Agent只知道往系统里堆补丁,不整理,代码越积越多,最终连Agent自己都维护不了——又变回了代码怪物。
健康的启发式系统必须同时做两件事:吸收反馈,把新的失败案例、错误日志持续写进来;压缩历史,定期把零散的补丁整合成更简洁的架构,能合并的合并,没用的删掉。
只增长不压缩,早晚变屎山。这条规律程序员对代码库早就知道,对AI系统也一样成立。
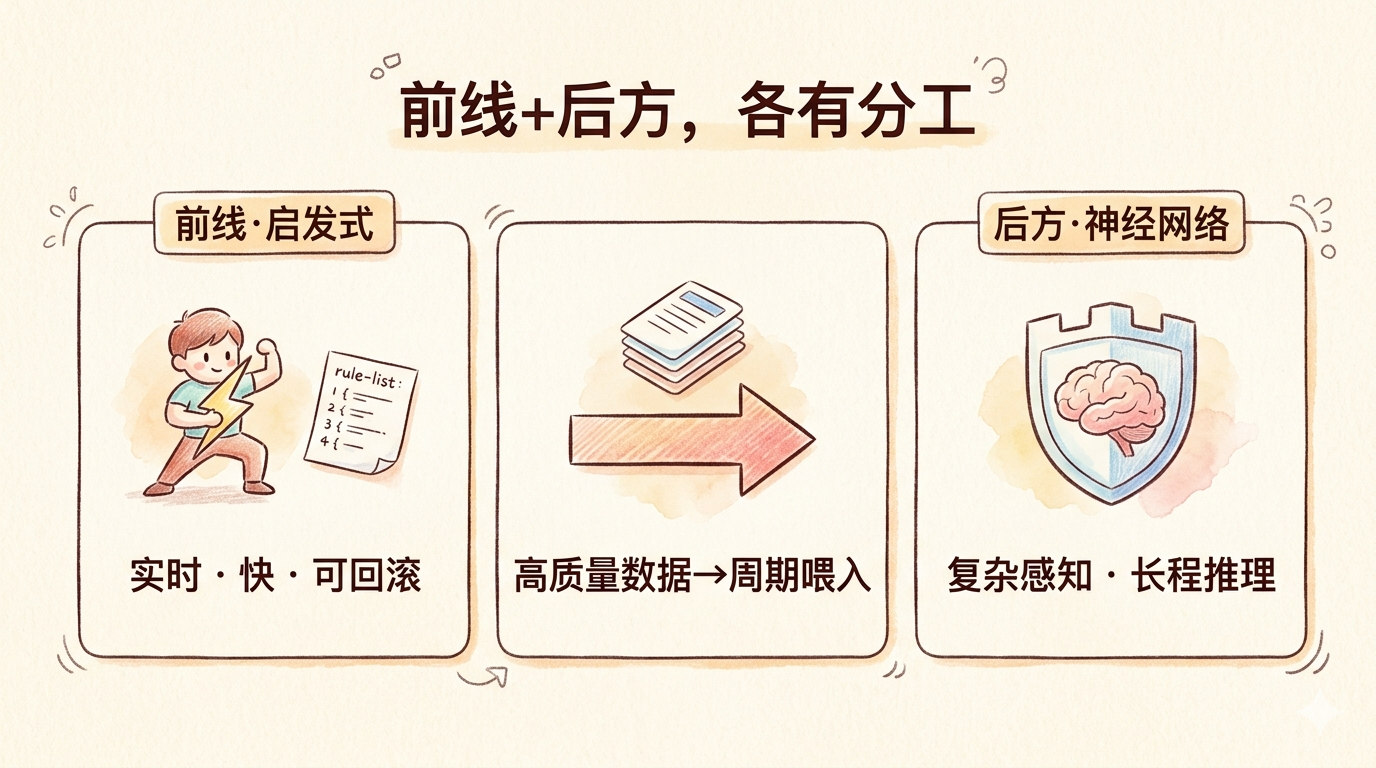
两套系统,各有分工
说清楚一件事:启发式学习不会消灭神经网络。
让AI认出一张猫的照片,或者理解一段复杂对话,纯代码规则做不到,这些地方神经网络是不可替代的。
翁家翌说的,是两套系统分工合作。启发式学习在前线:处理实时数据,执行规则,跑测试,快速恢复局部故障,速度快,成本低,出了问题能查能回滚。神经网络在后方:处理复杂感知,做长程推理,能力强但慢,改一次训练成本高。
启发式学习快速积累经验,把高质量数据整理好,周期性喂给神经网络更新。
翁家翌在文章末尾说了一句话,我觉得是全篇核心:持续学习的问题,从"怎么更新神经网络参数",变成了"怎么维护一个能持续吸收反馈的软件系统"。
但我也有一点没想明白
翁家翌的实验很漂亮,但主要集中在Atari游戏和机器人控制这类场景——规则边界清晰,反馈信号干净。
现实问题往往更乱,边界模糊,噪音多。能不能在复杂真实场景里稳定跑通,目前还没有足够的验证。而且这套方案高度依赖编码Agent自身的质量,模型越强,能维护的系统才越复杂。上限在哪里,现在没人知道。
说"范式已经切换",现在还早。但方向是对的,值得盯着。
最后
这件事真正让我在意的,不是"AI又进步了"那种标题。
而是AI学习的路径,正在越来越接近软件工程的工作方式。规则、测试、日志、版本控制、重构——这些软件工程的基本动作,可能正在成为AI系统迭代的核心。
门槛最低的起步:每次让AI帮你完成一件事,试着多想一步——如果它答错了,我怎么发现?
建立这个习惯,比学任何工具都有用。
翁家翌原文(中文版):https://trinkle23897.github.io/learning-beyond-gradients/#zh

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)