超节点技术深度篇六:超节点工程化技术:从无损网络、RAS 到任务级可观测性

目录
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告》
- 中兴《超节点技术白皮书》
- H3C《超节点技术白皮书》
本文你会看懂什么
- 为什么超节点故障不能只按“单机坏了”来处理,而要按
任务影响来建模。 PFC、ECN、链路自愈、训前巡检和拓扑感知调度分别解决什么工程问题。- 如何从
step time、MFU、链路误码、队列水位一路定位到根因。
前五篇分别拆了 Scale-Up、统一内存、并行通信、MoE 和 KV Cache。最后这一篇讲工程化。
先解释
超节点工程化 的意思是:让一个由大量 GPU/NPU、高速互联、交换芯片、液冷供电、通信库、调度器和训练/推理框架组成的系统,能够长期稳定地承载真实业务,而不是只在理想环境里跑通一次。
它和普通运维的区别在于,超节点里的很多问题会直接进入训练或推理关键路径。
链路误码、队列水位、某张卡降频、固件版本不一致、调度跨了错误拓扑,都可能表现为 step time 抖动、MFU 下降、TPOT 上升或任务中断。
可以先把工程化分成四个层面。
| 层面 | 要解决的问题 |
|---|---|
| 可靠性 | 器件、链路、系统和任务是否能承受故障 |
| 可观测性 | 能否从业务现象追到硬件、网络或软件根因 |
| 可恢复性 | 故障后能否隔离、切换、迁移、断点续训 |
| 可调度性 | 调度器是否理解拓扑、链路健康和模型并行结构 |
所以本文讲工程化,不是泛泛讨论“怎么运维机房”,而是讨论超节点如何从硬件能力变成可持续运行的 AI 基础设施。
关键术语先解释
| 术语 | 技术含义 | 报告中的使用方式 |
|---|---|---|
RAS |
Reliability、Availability、Serviceability,可靠性、可用性、可维护性。 | 华为报告将 RAS 作为应对万级处理器故障常态化的关键系统能力。 |
PFC |
Priority-based Flow Control,基于优先级的流控。 | H3C 术语表称其是 RoCE 实现无损以太网的核心能力之一。 |
ECN |
Explicit Congestion Notification,显式拥塞通知。 | H3C 术语表称其用于让发送端及时调整速率,避免拥塞加剧。 |
DCB |
Data Center Bridging,数据中心桥接。 | H3C 术语表将其解释为包含 ETS、PFC 等子技术,支撑无损传输和 QoS。 |
BER |
Bit Error Rate,误码率。 | H3C 术语表将其作为衡量数据传输可靠性的重要指标。 |
FEC |
Forward Error Correction,前向纠错。 | H3C 报告把它和链路可靠性、误码控制放在一起讨论。 |
LLR |
Link Layer Retransmission,链路层重传。 | H3C 报告在 Scale-Up 协议可靠性中提到链路层重试机制。 |
训前巡检 |
训练启动前对设备、链路、拓扑、版本、带宽和环境进行检查。 | H3C 报告将其作为降低训练任务环境故障、提升训练效率的能力。 |
自愈 |
故障后自动隔离、切换、恢复或重调度。 | H3C 报告把故障自愈作为 AD-DC 智算版运维平台的核心能力之一。 |
任务级可观测性 |
把硬件、网络、系统、通信库和训练/推理指标关联起来定位问题。 | H3C 报告用全栈可观测和智能闭环来描述这一类能力。 |
这些术语的共同点是:它们都不只是运维词,而是会直接影响模型训练和推理的有效吞吐。比如 PFC 配置不当会导致队列暂停扩散,BER 升高会触发重传,拓扑错误会让 TP/EP 进入慢路径。
报告中的技术表述
| 来源 | 技术表述 | 本文如何使用 |
|---|---|---|
华为报告第 19-21 页 |
RAS 覆盖可靠器件、可靠网络、可靠系统;分级故障恢复包括算子级秒级恢复和节点/作业级分钟级恢复。 | 用来建立可靠性分层和恢复粒度。 |
华为报告第 20 页 |
超节点集群光模块数量相较传统服务器显著增加,网络失效率挑战更高。 | 用来解释为什么链路可靠性和动态修复重要。 |
H3C 报告第 286 页 |
运维对象覆盖 AI 加速芯片、计算 tray、交换 tray、光模块、线缆、传感器、供电、液冷等。 | 用来定义超节点运维的硬件范围。 |
H3C 报告第 288 页 |
高速互联网络层需要流量动态调度、拥塞防控、故障链路快速自愈与隔离。 | 用来解释 Scale-Up 网络运维不是普通端口监控。 |
H3C 报告第 292 页 |
智能运维采用“三层感知+两层决策+一层执行”,覆盖硬件、网络、系统和业务秒级指标。 | 用来建立任务级可观测性和自愈闭环。 |
H3C 报告第 300-302 页 |
AD-DC 智算版强调 Scale-Up 网络监控、根因分析、故障自愈、训前巡检和训中作业监控。 | 用来落到平台化工程实践。 |
中兴报告第 29 页 |
全栈可观测性与智能运维可构建芯片、节点、集群多级监控体系,并支持故障预测和根因分析。 | 用来补充跨厂商共同结论。 |
工程化不是系列的“收尾杂项”,而是超节点能否进入生产环境的分水岭。因为在大模型训练和在线推理里,真正的目标不是跑一次 benchmark,而是连续数周训练、7×24 小时推理、故障可定位、任务可恢复、资源可调度。
华为报告第 19-21 页把稳定性放在超节点关键能力里讨论,并提到在万卡训练规模下故障会成为常态;H3C 报告第 286 页以后则把硬件、网络、系统软件、业务算力服务拆成多层运维对象。把这些内容合起来看,超节点工程化的核心是:把硬件故障、网络抖动、软件版本、调度策略和训练任务放进同一个闭环里。
一、先定义故障模型:不是坏没坏,而是影响哪条关键路径
普通服务器集群里,故障常被描述为“某台机器坏了”。超节点里,这个描述太粗。
更有用的故障模型应该按关键路径拆:
| 故障类型 | 可能表现 | 影响路径 |
|---|---|---|
| GPU/NPU 异常 | 掉卡、ECC、降频、显存错误 | 计算、显存、并行组完整性 |
| Scale-Up 链路异常 | 误码、降速、链路中断、时延抖动 | TP、EP、P2P、All-to-All |
| Scale-Out 网络异常 | 拥塞、丢包、重传、队列堆积 | DP、跨 HBD 通信、Checkpoint |
| 交换芯片异常 | 端口错误、转发表异常、固件不一致 | HBD 内全局通信 |
| 液冷供电异常 | 温度升高、功耗波动、漏液、供电切换 | 降频、宕机、整柜可用性 |
| 软件版本异常 | 驱动、固件、通信库、内核参数不一致 | 性能抖动、任务失败 |
| 调度错误 | TP/EP 跨低带宽路径、资源碎片 | step time 变长、MFU 下降 |
也就是说,超节点故障排查不是“看哪台服务器红了”,而是要回答:
- 哪个并行组受影响?
- 哪条通信原语变慢?
- 是平均性能下降,还是 p99 尾时延增加?
- 这个问题会导致当前 job 重试、迁移、降级,还是必须中断?
华为报告提到超节点集群中光模块数量相较传统服务器显著增加,网络失效率挑战更高;这也意味着工程化不能只靠被动告警,而要主动发现隐性链路异常。
二、可靠性要分层设计
华为报告把可靠性拆成可靠器件、可靠网络和可靠系统。这个拆法适合落成工程检查表。

图源:华为《超节点发展报告》第 19 页,图 4.3。用途:说明超节点可靠性需要从器件、链路、系统多层设计。
这张图要按“故障影响范围”来读:器件可靠性降低故障发生概率,网络可靠性降低故障扩散概率,系统可靠性降低任务中断和恢复成本。对于长周期训练,真正重要的是故障出现后是否能被限制在最小影响域内。
可以进一步映射为四层。
| 层级 | 核心目标 | 技术手段 |
|---|---|---|
| 器件层 | 降低单点失效概率 | 高可靠器件、老化测试、冗余电源、液冷监控 |
| 链路层 | 避免链路问题拖垮通信域 | FEC、LLR、备用链路、链路隔离 |
| 系统层 | 故障后保持资源可用 | 逻辑超节点切分、备份节点、拓扑重排 |
| 任务层 | 尽量不中断或少回滚 | 算子级恢复、断点续训、任务迁移 |
华为报告提到的恢复策略也可以按粒度理解:
- 算子级故障尽量秒级恢复。
- 节点或作业故障优先由超节点内备份节点接管。
- 如果缺少备份节点,再进行逻辑超节点迁移,目标是分钟级恢复。
这比“故障后重启 job”更接近生产系统要求。
三、无损网络不是一个开关,而是一组约束
很多训练网络会强调无损以太或 RoCE,但 无损网络 不是打开 PFC 就结束。
它至少涉及:
| 技术点 | 作用 | 风险 |
|---|---|---|
PFC |
按优先级暂停流量,减少丢包 | 配置不当会引发 HOL Blocking |
ECN |
显式拥塞通知,让端侧调速 | 阈值不当会反应过慢或过度降速 |
DCB/ETS |
流量分类和带宽保障 | 多类流量混部时需要精细配置 |
FEC |
前向纠错,降低误码影响 | 会引入额外时延 |
LLR |
链路层重传,处理局部错误 | 高错误率下可能导致尾时延上升 |
| QoS | 区分控制面、存储面、训练面 | 分类错误会让关键流量被挤压 |
H3C 报告在高速互联网络层运维中强调流量动态调度、拥塞防控、故障链路快速自愈与隔离,并提到误码超标或链路中断时 30 秒内自动切换备用链路,硬件类链路异常 4 小时内完成光模块或线缆更换。
这说明网络运维需要从“端口 up/down”升级为“链路质量是否仍满足训练关键路径”。
H3C 报告的系统与软件栈层运维图可以放在这里理解网络、固件、驱动、通信库之间的耦合。
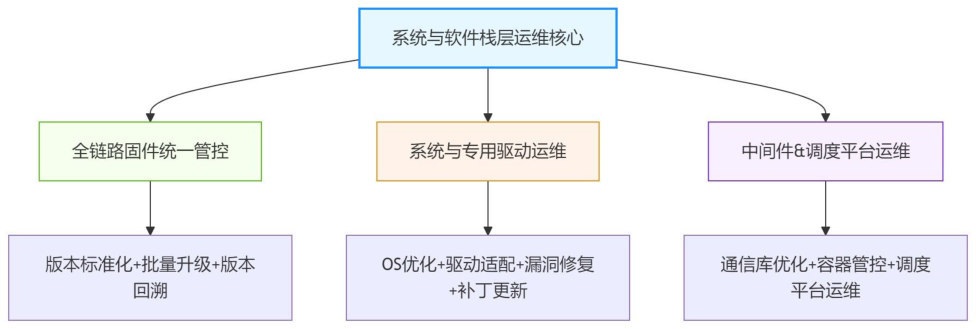
图源:H3C《超节点技术白皮书》第 288 页,图 181。用途:说明超节点运维对象不仅包含硬件,也包含固件、驱动、通信库和系统参数一致性。
这张图的技术含义是“版本和参数也是性能变量”。驱动、固件、通信库、内核参数不一致,可能不会表现为设备离线,但会表现为通信算法选择变化、队列行为变化或训练 step 抖动。
四、拓扑感知调度要把模型并行结构作为输入
超节点调度不能只做资源 bin packing。
对于训练任务,调度器至少要知道:
- 哪些卡属于同一个
HBD。 - 哪些链路当前
健康,哪些链路误码偏高。 TP group、EP group、PP stage、DP group分别是什么。- 哪些通信是
关键路径,哪些可以跨域。 - 故障后哪些资源可以
替换,替换后拓扑是否仍满足带宽要求。
H3C 报告中的 Scale-Up 拓扑运维图,展示了拓扑可视化的重要性。
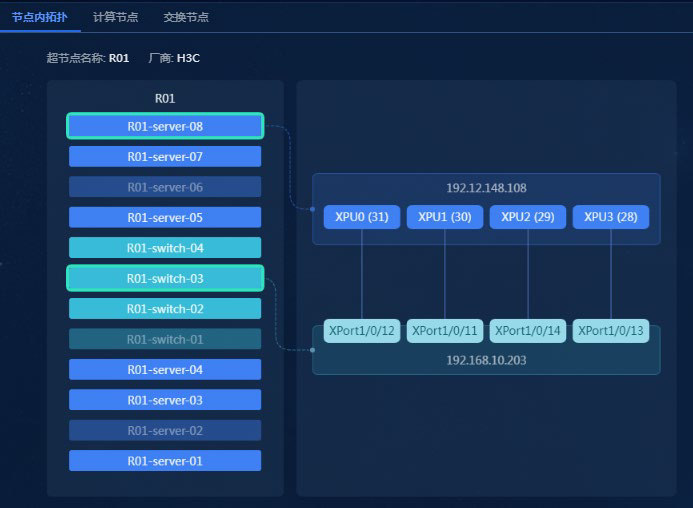
图源:H3C《超节点技术白皮书》第 301 页,图 186。用途:说明调度和运维都需要看到真实 Scale-Up 拓扑。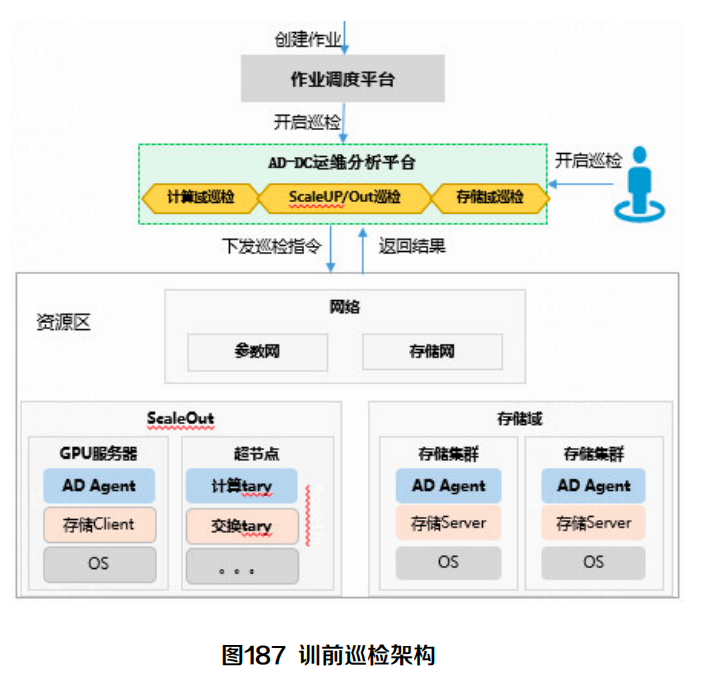
“拓扑作为运维对象”。超节点里的 Scale-Up 拓扑不是普通网络路径,它决定 TP/EP 是否走高带宽低时延链路。拓扑偏移、链路异常或端口降速,都可能直接改变模型并行组的性能。
把模型并行结构映射到拓扑,可以形成下面的调度约束:
| 并行结构 | 调度约束 |
|---|---|
TP |
强约束在同一 HBD 或极低跳数路径 |
EP |
优先同域,避免专家 All-to-All 跨弱链路 |
PP |
相邻 stage 尽量拓扑临近 |
DP |
可以跨 HBD,但要做分层归约 |
CP/SP |
结合序列切分和 KV/激活位置 |
推理 PD 分离 |
Prefill 与 Decode 之间要有高速 KV 传输路径 |
如果调度器没有这些输入,就可能出现“资源分配成功,但任务性能很差”的情况。
五、训前巡检要验证训练关键路径
大模型训练最怕跑起来以后才发现环境不对。
训前巡检不是简单查看设备在线,而是要验证训练关键路径是否达标。
H3C 报告提到,训前巡检支持普通巡检、深度巡检、Scale-Up 网络单独巡检,以及 Scale-Up 叠加 Scale-Out 网络整体巡检。
图源:H3C《超节点技术白皮书》第 302 页,图 187。用途:说明训练启动前需要对设备、链路、拓扑和环境做系统验证。
这张图可以理解为训练任务的“启动前验收”。巡检不是为了生成一份报告,而是为了确认训练关键路径的算力、网络、软件版本和环境基线都达标,避免训练跑几个小时后才暴露基础环境问题。
巡检清单可以按下面组织。
| 检查对象 | 关键检查项 |
|---|---|
| 加速卡 | 型号、数量、温度、功耗、显存、ECC、降频、驱动状态 |
| Scale-Up 链路 | up/down、链路速率、误码、延迟、拓扑一致性 |
| Scale-Out 网络 | PFC/ECN、RDMA 连通性、带宽基线、队列水位 |
| 软件栈 | OS、驱动、固件、通信库、框架版本一致性 |
| 存储 | Checkpoint 带宽、数据集读取、元数据服务 |
| 液冷供电 | 供回水温差、流量、电导率、漏液、功耗波动 |
| 调度配置 | 资源池、配额、优先级、故障隔离策略 |
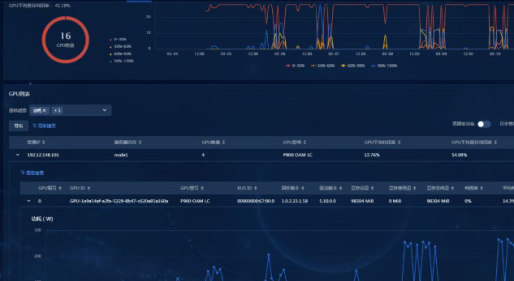
H3C 报告中的训前巡检指标图可以作为更细的指标清单。
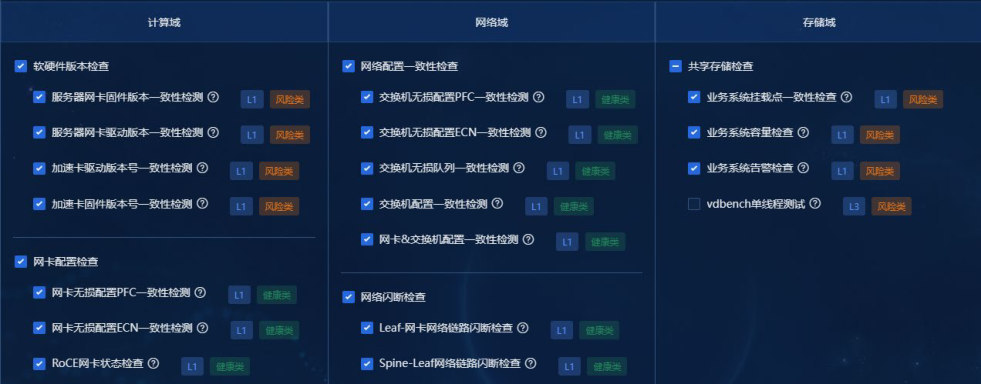
图源:H3C《超节点技术白皮书》第 302 页,图 188。用途:展开训前巡检的具体指标项。
这张图适合在发布时放大展示。它把巡检从“设备是否在线”扩展到交换机、网络、GPU、服务器、存储等对象,尤其是 pool/headroom 水线、拥塞丢包、ECC、xpulink 状态等指标,更接近训练实际故障根因。
六、训中观测要从 step time 追到链路和队列
训练过程中最有价值的观测,不是单个指标,而是跨层关联。
比如 step time 变长,可能有多种原因:
- 数据加载慢。
- 某个 TP 组跨了弱链路。
- MoE 专家负载不均。
- All-to-All 进入拥塞路径。
- 某张卡温度高导致降频。
- 某条链路误码增加触发重传。
- PFC 阈值导致队列暂停扩散。
- 通信库版本不一致导致算法选择变化。
所以需要建立“任务级可观测性”。
| 任务现象 | 需要关联的底层指标 |
|---|---|
| step time 抖动 | All-Reduce/All-to-All p95、链路队列水位、慢卡 |
| MFU 下降 | 计算利用率、通信等待、数据加载、降频 |
| MoE step 变慢 | 每专家 token 数、Dispatch/Combine 耗时、热点链路 |
| 推理 TPOT 上升 | KV 远端访问、Decode batch、链路尾时延 |
| 训练中断 | ECC、掉卡、链路中断、进程崩溃、Checkpoint 状态 |
H3C 报告的智能运维架构使用“三层感知+两层决策+一层执行”,感知硬件、网络、系统和业务秒级指标,再由决策层做故障预测、任务编排和故障自愈。
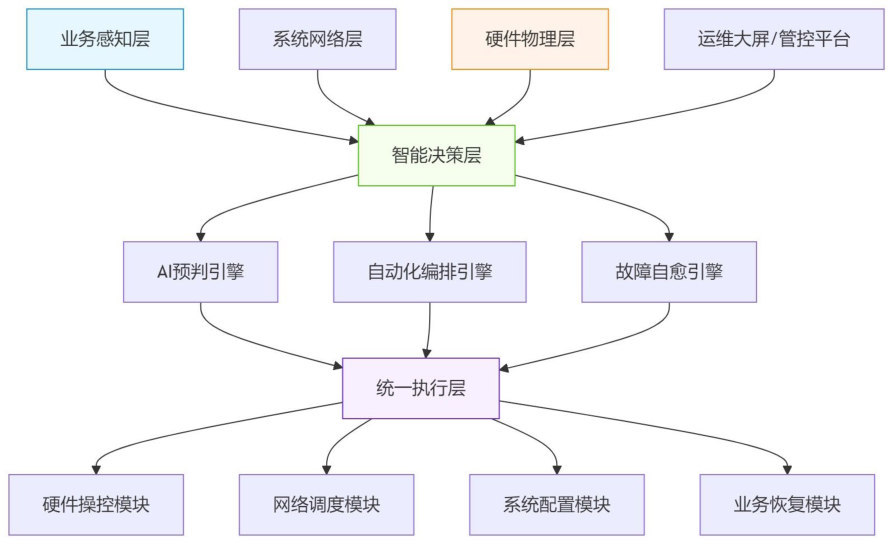
图源:H3C《超节点技术白皮书》第 292 页,图 183。用途:说明全栈指标如何进入故障预测、任务编排和自愈闭环。
这张图的重点是闭环:感知层采集硬件、网络、系统、业务指标;决策层做故障预测、任务编排、自愈判断;执行层完成链路切换、配置刷新、任务重启等动作。没有执行闭环,可观测性就只停留在看板层。
这个架构的技术重点不是“有一个大屏”,而是指标之间能不能互相解释。
七、自愈闭环要和调度、通信库联动
故障自愈不能只停留在“发现异常后报警”。
完整闭环应包含:
异常发现
-> 根因定位
-> 影响面评估
-> 资源隔离
-> 拓扑重排或备份切换
-> 任务恢复
-> 复测和审计
H3C 报告中的 AD-DC 智算版,把超节点运维聚焦在自动化部署、全域纳管、Scale-Up 网络监控、智能根因分析和故障自愈,并强调与上层智算作业调度平台联动,形成“故障感知-根因定位-资源隔离-任务自愈-进度接续”闭环。
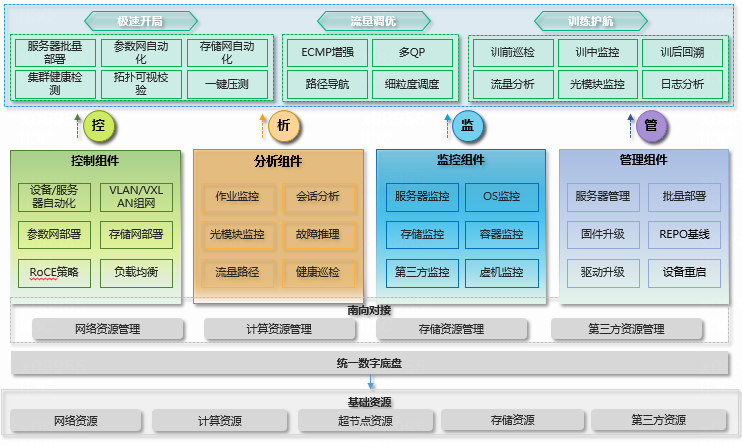
图源:H3C《超节点技术白皮书》第 300 页,图 185。用途:说明超节点运维平台需要和调度、根因分析、自愈联动。
这张图对应的是平台化实践:Scale-Up 网络监控、智能根因分析、故障自愈必须和作业调度平台联动。否则即使定位到链路问题,也无法自动把任务迁出故障域或重排并行组。
从工程实现上看,至少需要三类联动:
| 联动对象 | 要做什么 |
|---|---|
| 调度器 | 标记故障资源、迁移任务、重排并行组 |
| 通信库 | 避开故障链路、切换 QP、重新选择通信算法 |
| 训练框架 | 保存和恢复状态、处理重试、接续 checkpoint |
如果只有硬件告警,没有调度器和通信库参与,故障仍然会表现为任务卡住或性能持续抖动。
八、硬件基础设施指标不能被忽略
超节点高密度部署后,液冷、供电、光模块、线缆这些基础设施会直接影响训练效果。
H3C 报告的硬件基础设施层运维模块,把 AI 加速芯片、计算 tray、交换 tray、正交无背板高密机箱、200G/400G/800G 光模块、芯片级直连线缆、传感器等都纳入运维对象。
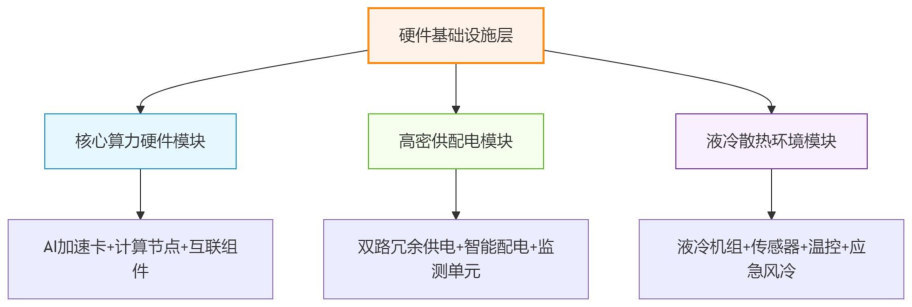
图源:H3C《超节点技术白皮书》第 286 页,图 180。用途:说明超节点硬件运维不仅看 GPU,也要看供电、液冷、光模块和线缆。
这张图体现的是超节点硬件范围的变化:运维对象从服务器扩展到整柜,包括 AI 加速芯片、交换 tray、光模块、直连线缆、液冷、供电和传感器。任何一个对象异常,都可能通过降频、重传、链路切换或整柜保护影响任务。
报告列出的指标非常工程化,包括:
- 芯片温度、显存温度、实时功耗、功耗偏差。
- ECC UE/CE、降频时长、资源利用率、固件版本。
- 光功率、模块温度、偏置电流、误码率、时延抖动、端口利用率。
- 电压波动、负载率、支路电流、冗余切换时长。
- 供回水温差、流量波动、电导率、漏液信号、露点温差。
这些指标看似偏机房,但会直接影响训练:
- 温度导致降频,MFU 会下降。
- 误码导致重传,All-to-All 尾时延会上升。
- 供电切换不稳定,任务可能中断。
- 液冷异常会扩大故障域。
所以超节点可观测性必须把“水、电、网、卡、任务”放在同一张因果图里。
九、工程化评估清单
评估一个超节点系统是否可长期运营,可以按下面这张清单追问。
| 维度 | 关键问题 |
|---|---|
| 拓扑可见性 | 是否能看到真实 Scale-Up/Scale-Out 拓扑和链路健康状态 |
| 训前巡检 | 是否能验证设备、链路、版本、带宽、拓扑和液冷供电 |
| 无损网络 | PFC、ECN、QoS、FEC、LLR 是否有基线和变更管控 |
| 通信观测 | 是否能看到 All-Reduce、All-to-All、P2P 的耗时和尾时延 |
| 任务关联 | step time、MFU、loss、Checkpoint 是否能和底层指标关联 |
| 故障隔离 | 掉卡、链路异常、交换模块异常是否能自动隔离 |
| 调度联动 | 调度器是否能避开故障资源并保持并行组拓扑合理 |
| 自愈能力 | 是否支持秒级发现、分钟级恢复、断点续训或任务迁移 |
| 配置一致性 | 固件、驱动、内核参数、通信库版本是否全局一致 |
| 运维审计 | 变更、告警、处置、回滚是否可追踪 |
这张表比“峰值带宽多少”更能判断一个超节点是否适合生产。
十、系列总结
这一组技术深度文章,从六个层次拆了超节点。
第一篇讲 Scale-Up 和 HBD:高频通信为什么需要更大的高带宽域。
第二篇讲统一内存编址:数据访问如何从显式搬运走向可寻址资源。
第三篇讲并行通信:DP、TP、PP、EP、CP 如何映射到不同网络压力。
第四篇讲 MoE:专家路由、All-to-All 和在网计算为什么检验系统能力。
第五篇讲 KV Cache:长上下文推理为什么变成缓存、内存和调度问题。
第六篇讲工程化:超节点能否长期运行,取决于网络、调度、RAS 和可观测性闭环。
把三份报告放在一起看,超节点不是单一硬件产品,也不是简单把更多 GPU/NPU 放到一个机柜里。它更像 AI 基础设施的一次系统重构:计算、互联、内存、通信库、调度器、推理框架和运维平台都要一起变化。
真正值得关注的,也不是“超节点这个词会不会流行”,而是它背后的工程方向:让大规模 AI 任务从松散集群,走向更高带宽、更低时延、更强协同、更可运营的系统形态。
核心术语表
| 术语 | 含义 |
|---|---|
RAS |
Reliability、Availability、Serviceability,可靠性、可用性、可维护性。 |
PFC |
Priority Flow Control,按优先级暂停流量的以太网流控机制。 |
ECN |
Explicit Congestion Notification,显式拥塞通知,用于让端侧感知拥塞并调速。 |
FEC |
Forward Error Correction,前向纠错,用于降低链路误码影响。 |
LLR |
Link Layer Retransmission,链路层重传,用于处理局部链路错误。 |
HBD |
High-Bandwidth Domain,高带宽域,适合承载 TP、EP 等高频通信。 |
MFU |
Model FLOPs Utilization,模型有效算力利用率。 |
训前巡检 |
训练开始前对设备、链路、版本、拓扑和环境的系统检查。 |
拓扑感知调度 |
调度器根据物理拓扑、链路健康和模型并行结构放置任务。 |
自愈 |
系统自动完成故障发现、隔离、切换、恢复或任务迁移的能力。 |
本系列参考的三份报告如下:
- 华为《超节点发展报告》
- 中兴《超节点技术白皮书》
- H3C《超节点技术白皮书》
上述参考报告,可在公众号后台私信回复"超节点"获得。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)