LangChain 实战指南:聊天模型与工具调用全解析

🎬 博主简介:

文章目录
前言
大语言模型(LLM)虽然在文本生成、翻译、问答等任务中表现出色,但它本质上是一个封闭的知识系统: 知识存在截止日期,无法获取实时信息,无法执行外部操作(如计算、数据库查询、API 调用),复杂任务容易出现逻辑错误或幻觉。LangChain 的出现完美解决了这些问题。它通过聊天模型接口标准化了不同 LLM 的调用方式,通过工具调用机制让 LLM 具备了与外部世界交互的能力。本文将从最基础的聊天模型定义开始,一步步带你实现一个能实时搜索天气的 AI 助手。
一. 定义聊天模型
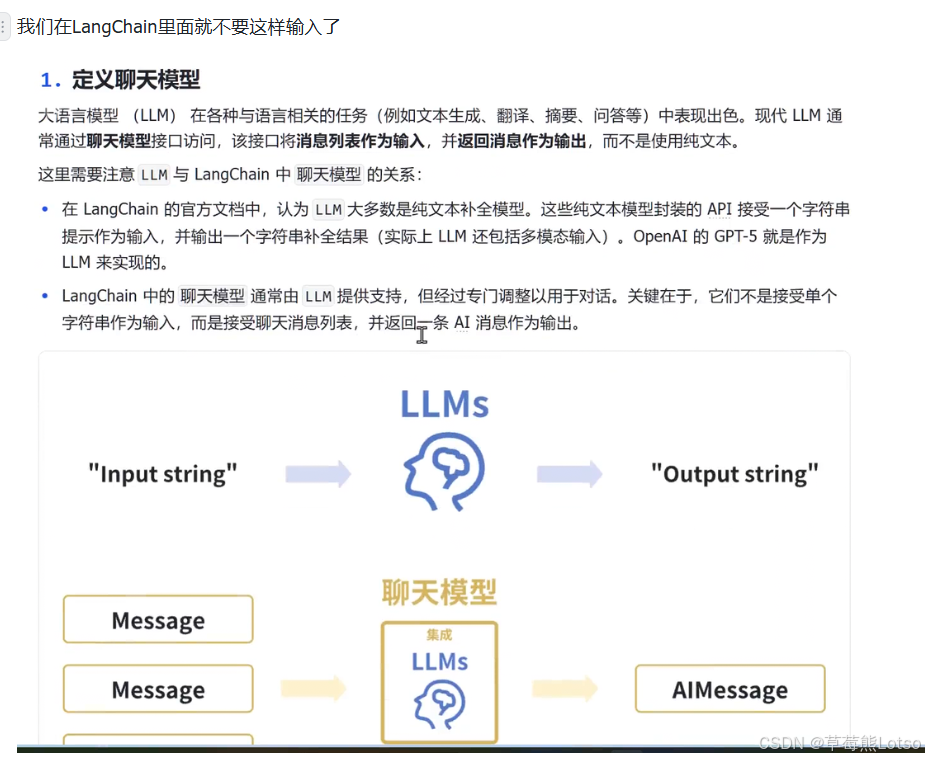
LangChain 提供了统一的聊天模型接口,让你可以无缝切换 OpenAI、DeepSeek、Ollama 等不同模型提供商,无需修改业务逻辑。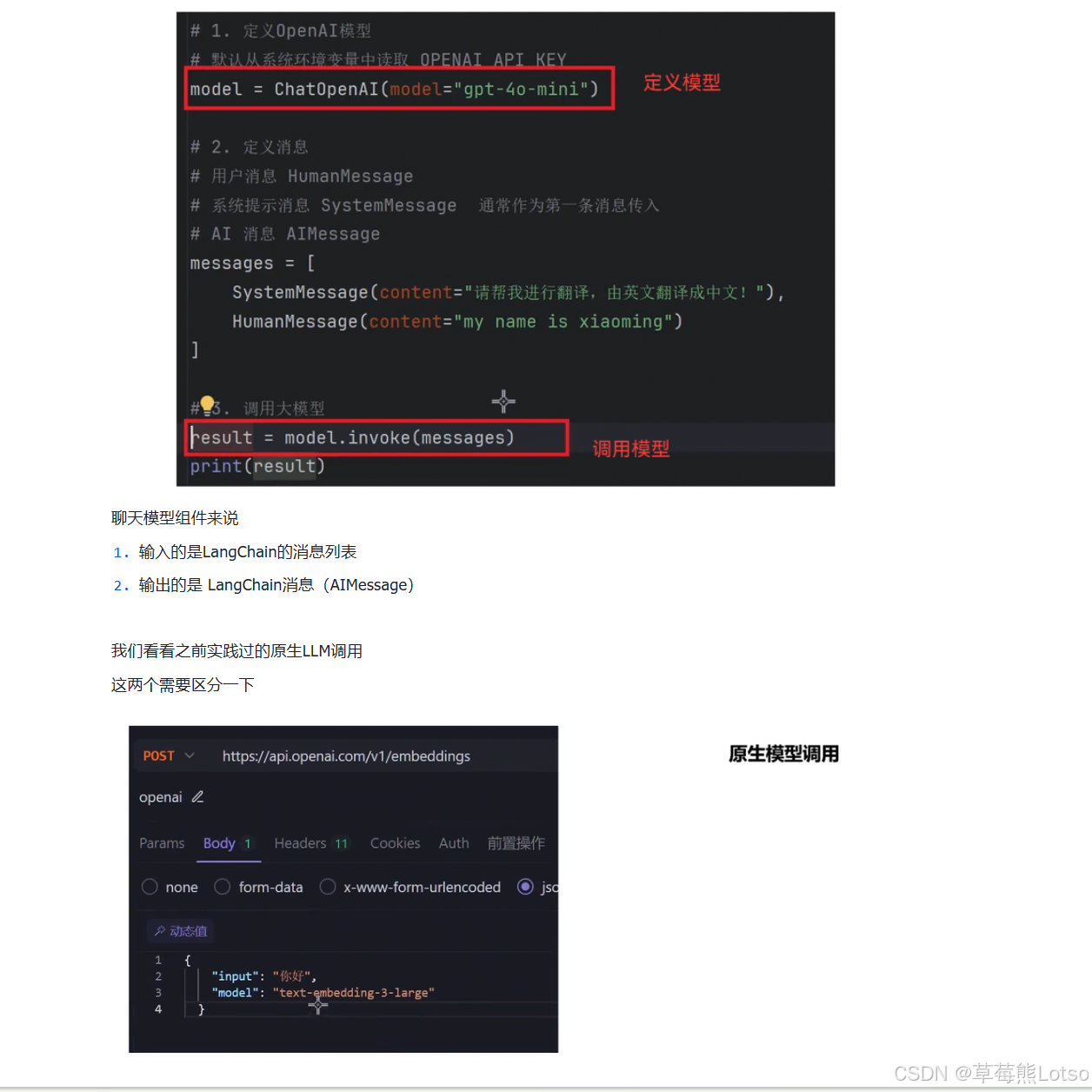
1.1 ChatOpenAI:最常用的模型实现
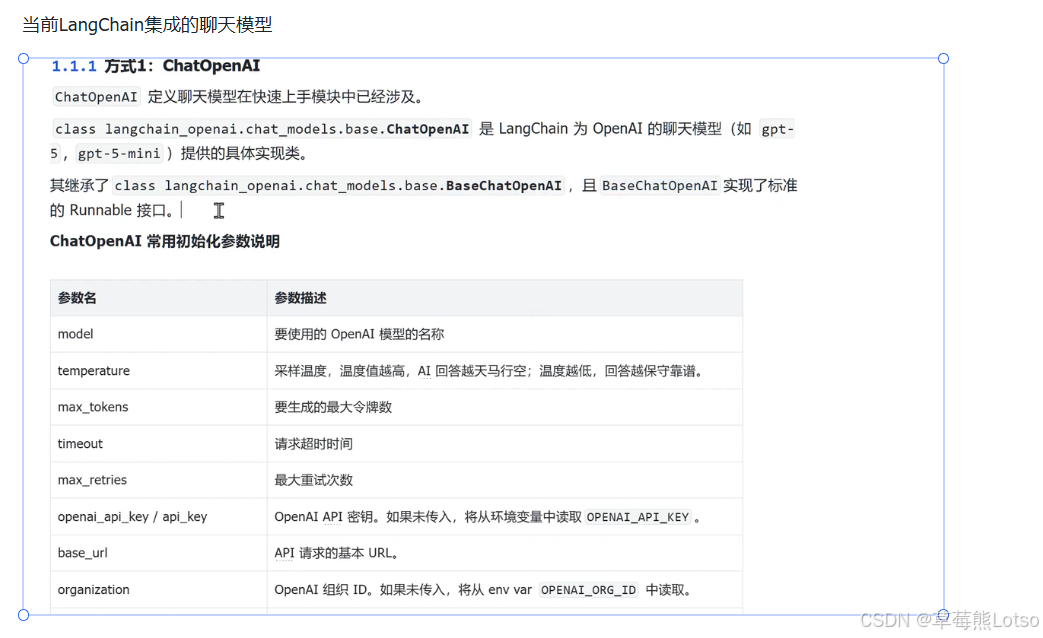
ChatOpenAI 是 LangChain 为 OpenAI 聊天模型提供的官方实现,它继承自 BaseChatOpenAI 并实现了标准的 Runnable 接口。
核心初始化参数详解
from langchain_openai import ChatOpenAI
# 完整参数示例
model = ChatOpenAI(
model="gpt-4o-mini", # 模型名称
temperature=0, # 采样温度,0-2
max_tokens=None, # 最大生成令牌数
timeout=None, # 请求超时时间
max_retries=2, # 最大重试次数
# api_key="你的API_KEY", # 不写则自动从环境变量读取
# base_url="代理地址", # 国内访问需要配置
# organization="组织ID" # OpenAI 组织 ID
)
关键参数深度解析:
- temperature:控制输出的随机性
0:完全确定,适合代码生成、事实问答0.1-0.5:轻微变化,适合技术文档、写作0.5-1:平衡创意,适合日常对话1-2:高度随机,适合创意创作>2:不推荐,通常输出无意义内容
- max_tokens:限制模型生成的最大长度
- Token 是 LLM 处理文本的基本单位
- 中文:1 个汉字 ≈ 1.5-2 个 Token
- 英文:1 个 Token ≈ 4 个字符或 0.75 个单词
基础调用示例
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# 定义消息列表
messages = [
SystemMessage(content="请帮我进行翻译,由英文翻译成中文!"),
HumanMessage(content="my name is xiaoming")
]
# 定义输出解析器,提取 AIMessage 中的 content
parser = StrOutputParser()
# 构建链
chain = model | parser
# 调用并打印结果
print(chain.invoke(messages)) # 输出:我的名字是小明
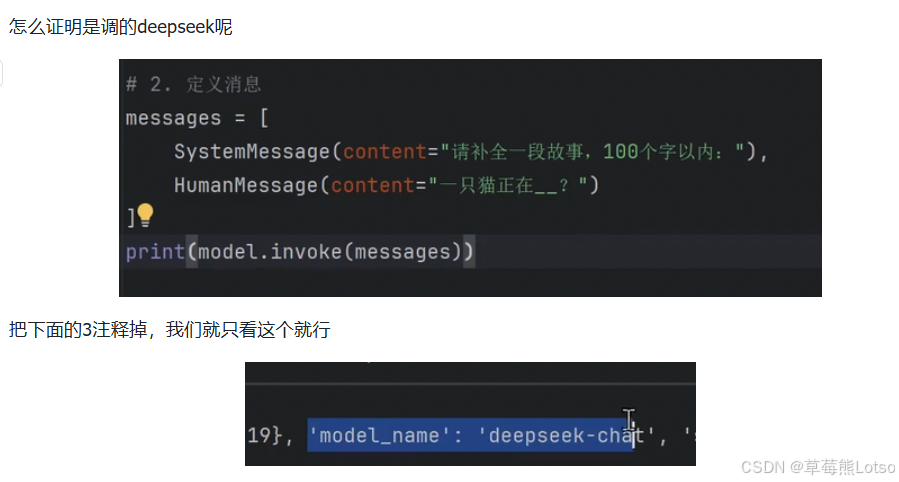
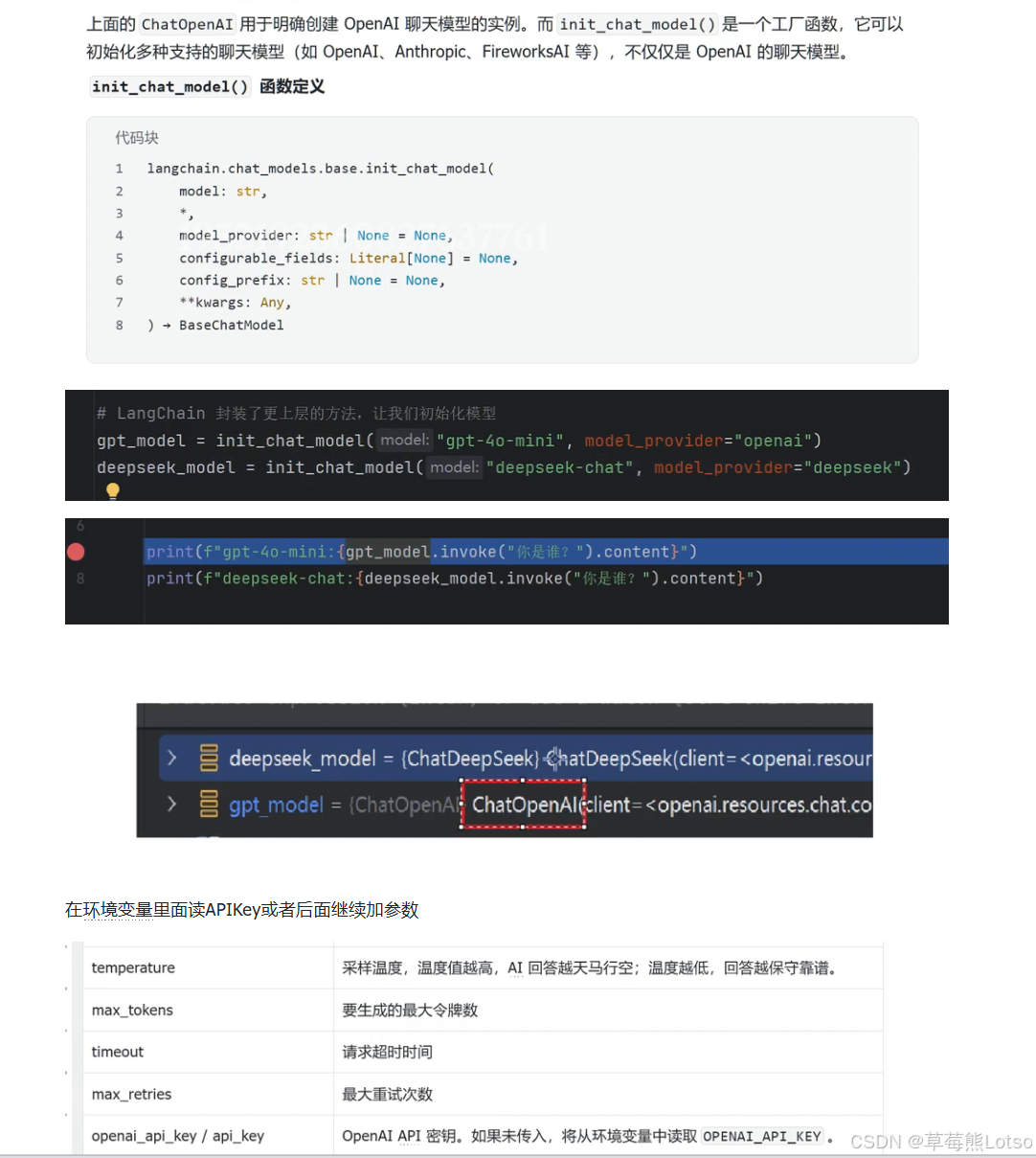
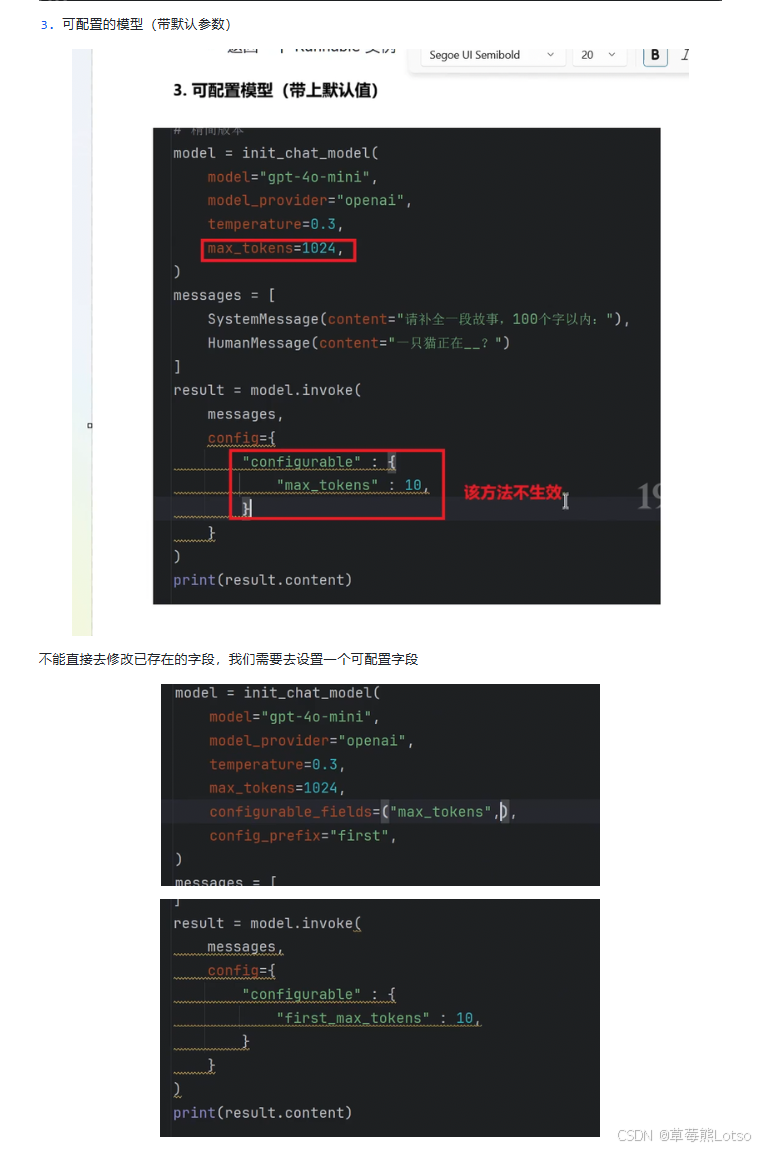
1.2 init_chat_model:通用模型工厂函数
init_chat_model() 是一个更上层的工厂函数,支持一键初始化多种聊天模型,无需导入不同的模型类。
from langchain.chat_models.base import init_chat_model
# 初始化 OpenAI 模型
gpt_model = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
temperature=0.3
)
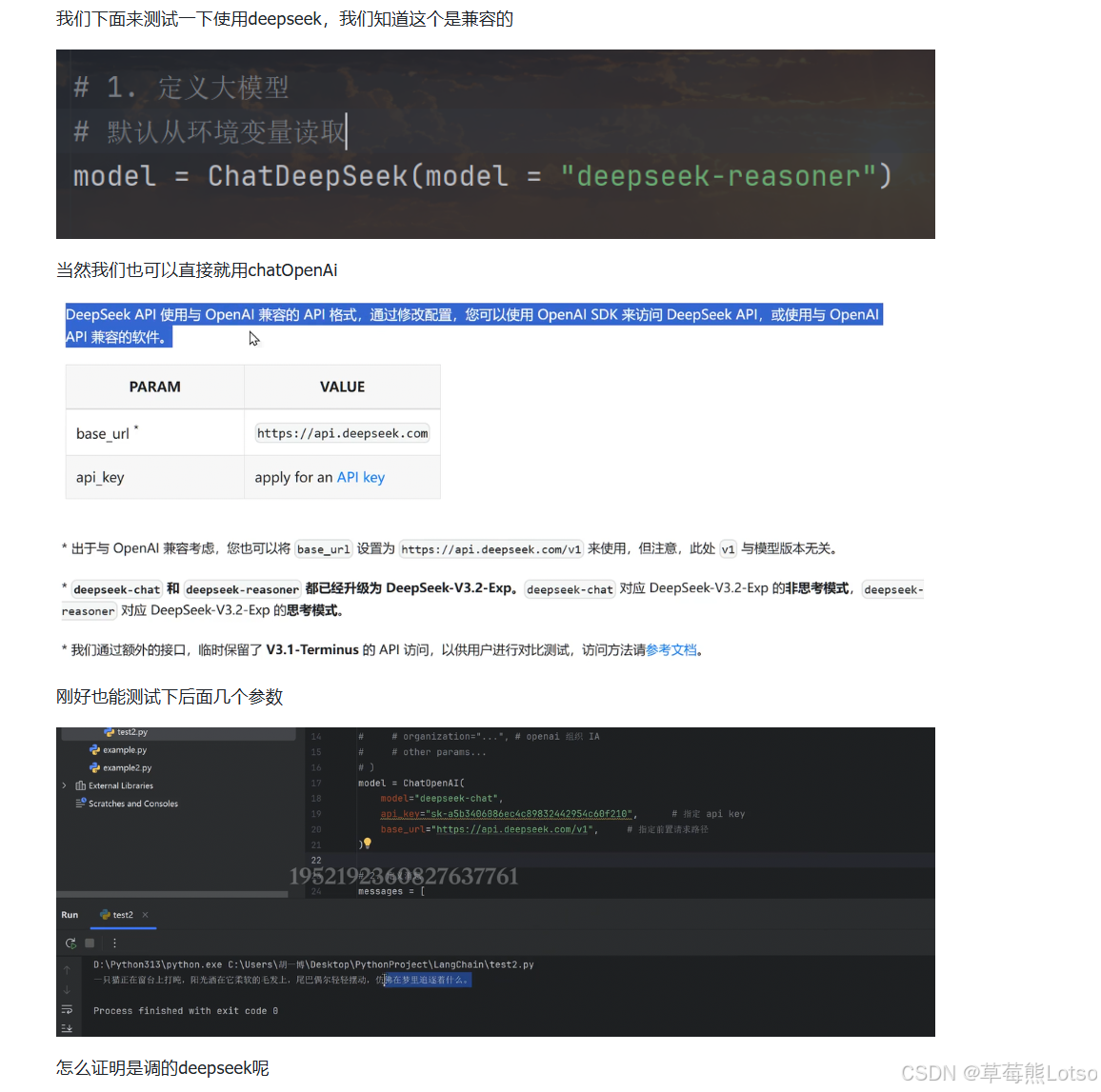
# 初始化 DeepSeek 模型(兼容 OpenAI API)
deepseek_model = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key="你的DeepSeek_API_KEY",
base_url="https://api.deepseek.com/v1"
)
# 测试调用
print(f"GPT-4o-mini: {gpt_model.invoke('你是谁?').content}")
print(f"DeepSeek: {deepseek_model.invoke('你是谁?').content}")
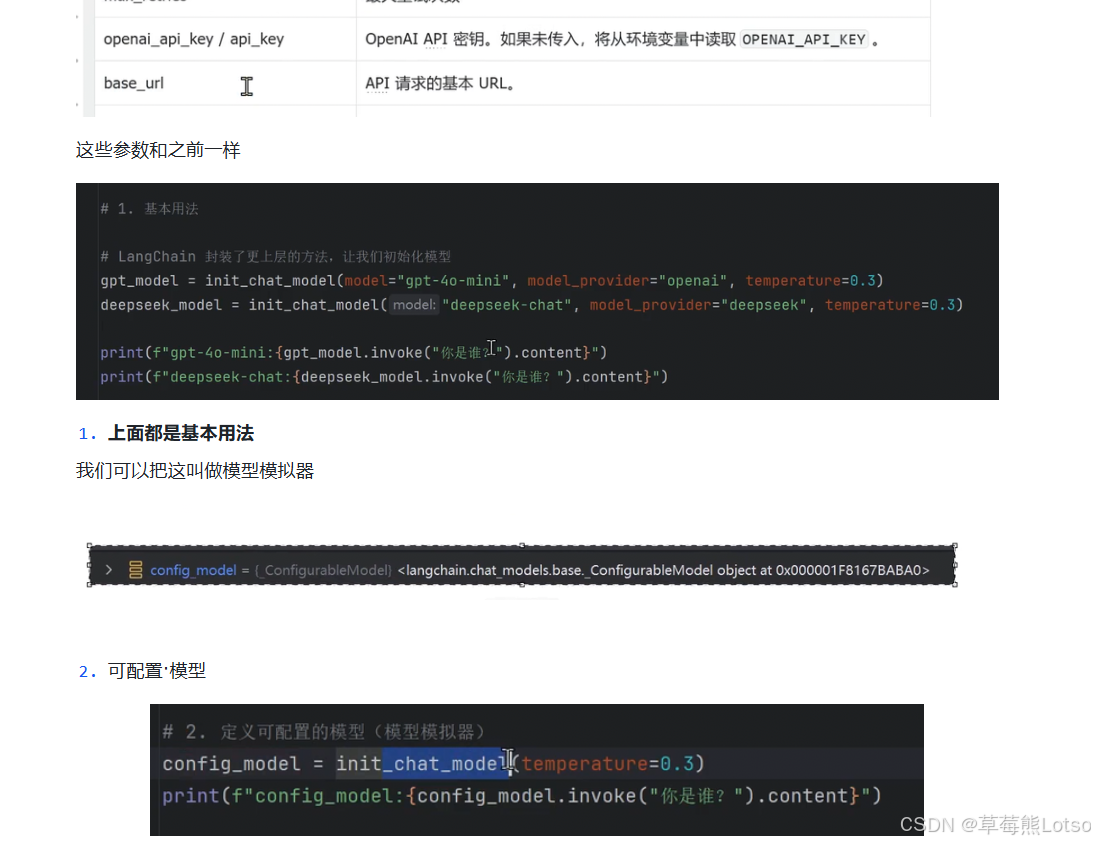

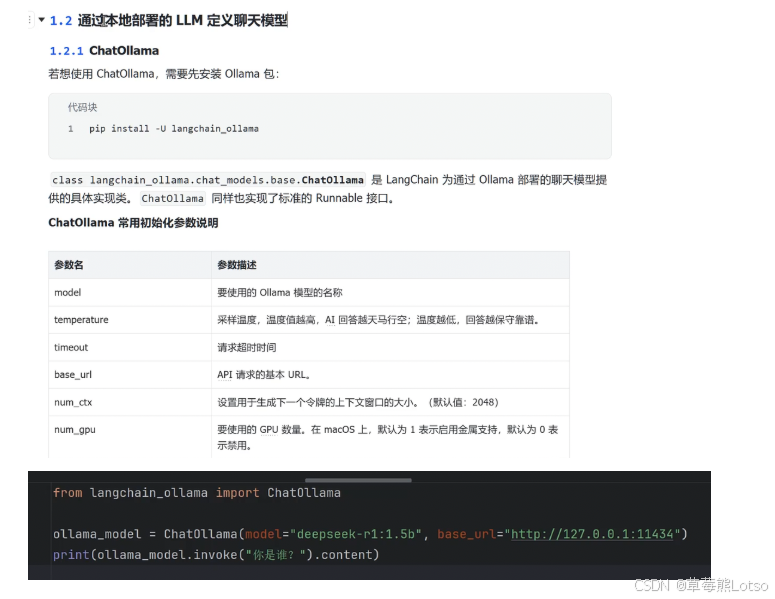
1.3 ChatOllama:本地部署模型支持
如果你想使用本地部署的开源模型(如 Llama 3、DeepSeek-R1),LangChain 提供了 ChatOllama 支持。
前置准备:
- 安装 Ollama:https://ollama.com/
- 拉取模型:
ollama pull deepseek-r1:1.5b
from langchain_ollama import ChatOllama
# 初始化本地模型
ollama_model = ChatOllama(
model="deepseek-r1:1.5b",
base_url="http://127.0.0.1:11434",
temperature=0.3
)
# 测试调用
print(ollama_model.invoke("你是谁?").content)
二、工具调用:让 LLM 连接外部世界
工具调用是 LangChain 最强大的功能之一,它让 LLM 从一个 “只会说话的模型” 变成了一个 “能做事的助手”。
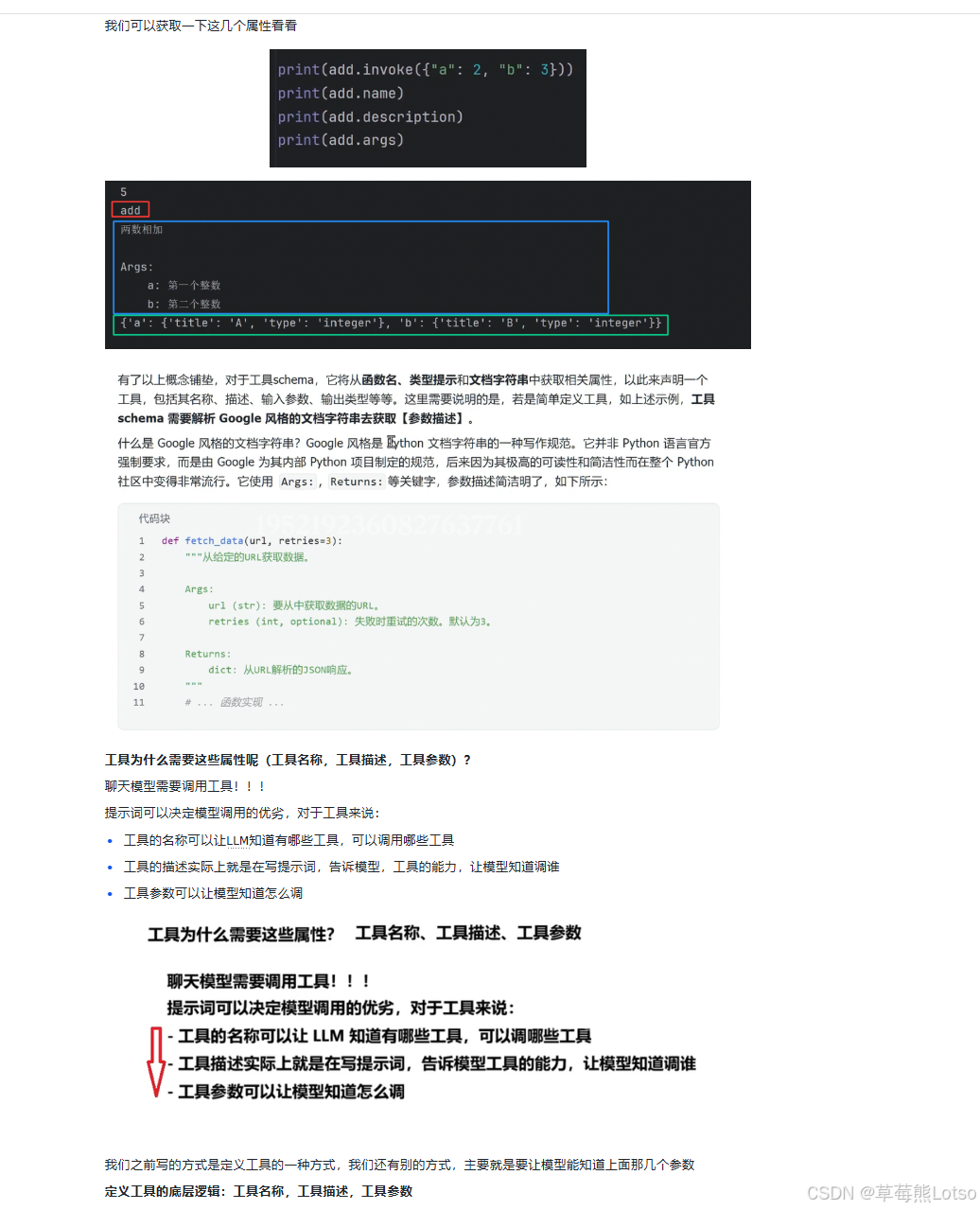
2.1 工具调用的核心作用
- 扩展能力边界:让 LLM 执行数学计算、搜索网络、操作数据库等自身无法完成的任务
- 保证信息实时性:获取训练数据中不存在的最新信息
- 处理复杂任务:将复杂请求分解为多个步骤,依次调用不同工具协同完成
- 连接现有系统:将企业内部 API、数据库封装成工具,让 LLM 成为自然语言驱动的统一接口


2.2 定义工具的三种方式
LangChain 提供了多种定义工具的方式,核心是让 LLM 知道工具名称、工具描述、工具参数这三个关键信息。
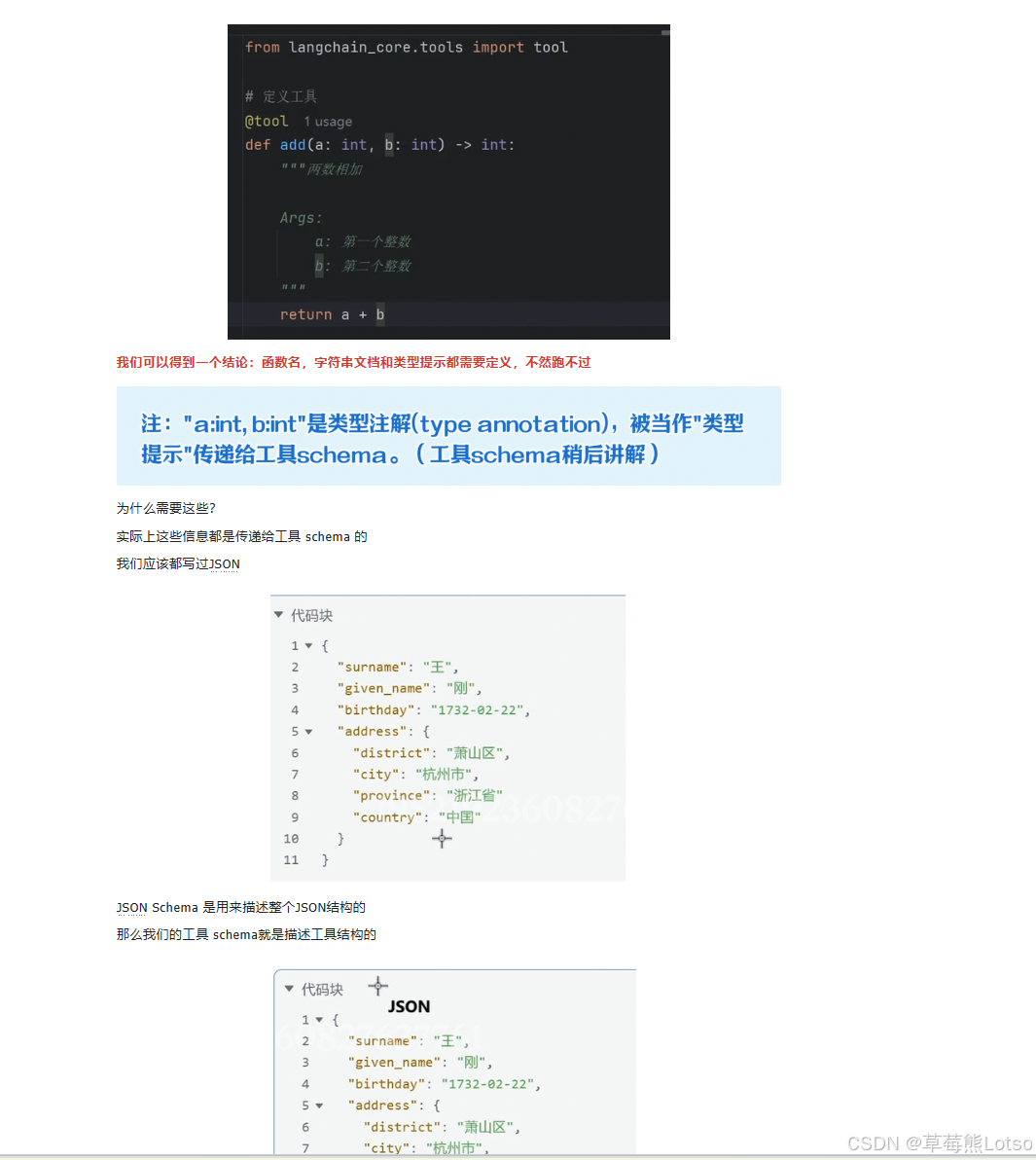
2.2.1 方式一:@tool 装饰器(推荐)
这是最简单、最常用的工具定义方式,支持两种参数描述模式。
模式 1:Google 风格文档字符串
from langchain_core.tools import tool
from typing_extensions import Annotated
@tool
def add(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
# 查看工具信息
print(add.name) # add
print(add.description) # 两数相加
print(add.args) # {'a': {'type': 'integer', 'description': '第一个整数'}, ...}
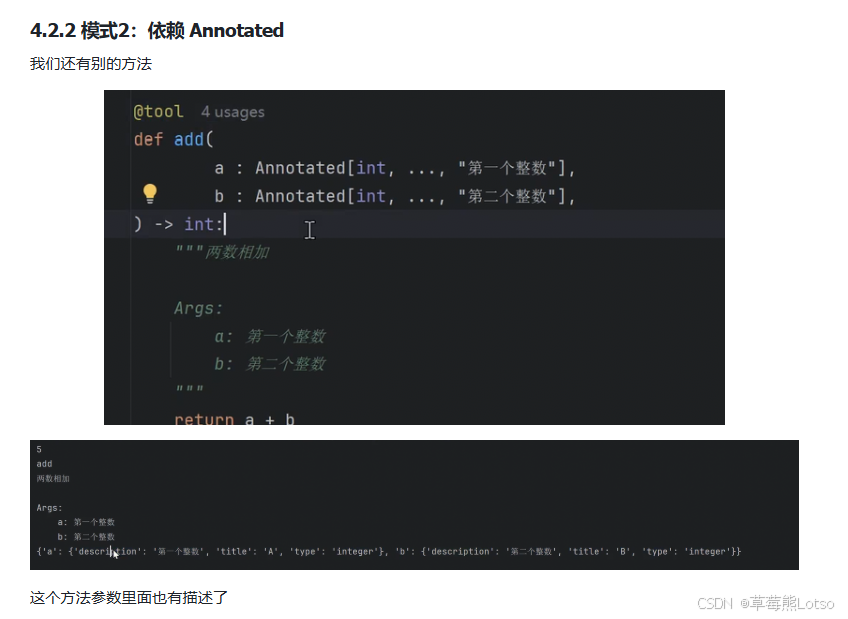
模式 2:依赖 Pydantic 类 如果工具参数比较复杂,推荐使用 Pydantic 类定义参数 schema,提供更强的类型检查和描述能力。
from pydantic import BaseModel, Field
class AddInput(BaseModel):
"""两数相加"""
a: int = Field(..., description="第一个整数")
b: int = Field(..., description="第二个整数")
@tool(args_schema=AddInput)
def add(a: int, b: int) -> int:
return a + b

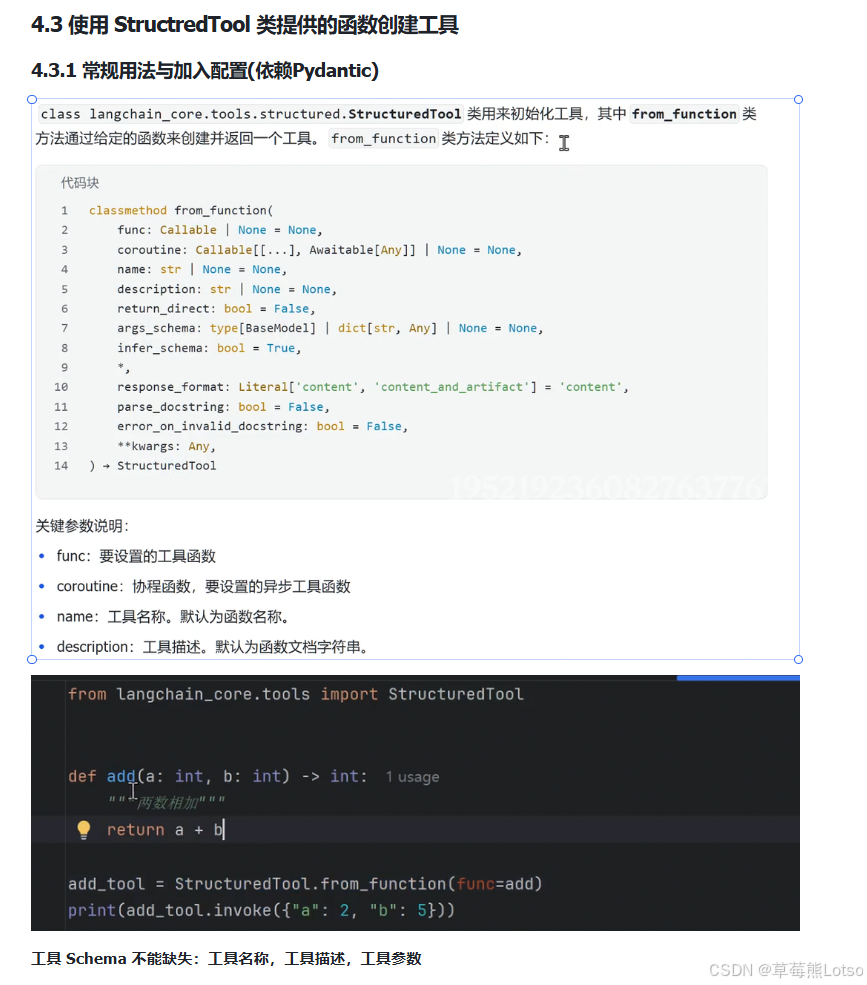
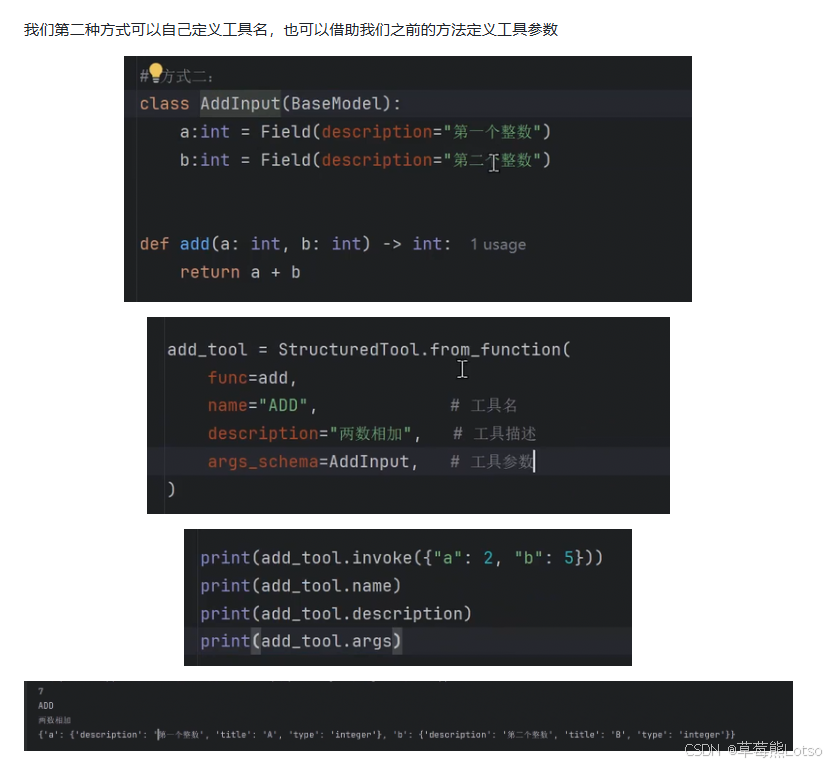
2.2.2 方式二:StructuredTool 类
如果你需要更灵活的工具定义(如异步工具、自定义响应格式),可以使用 StructuredTool.from_function()。
from langchain_core.tools import StructuredTool
from typing import Tuple, List
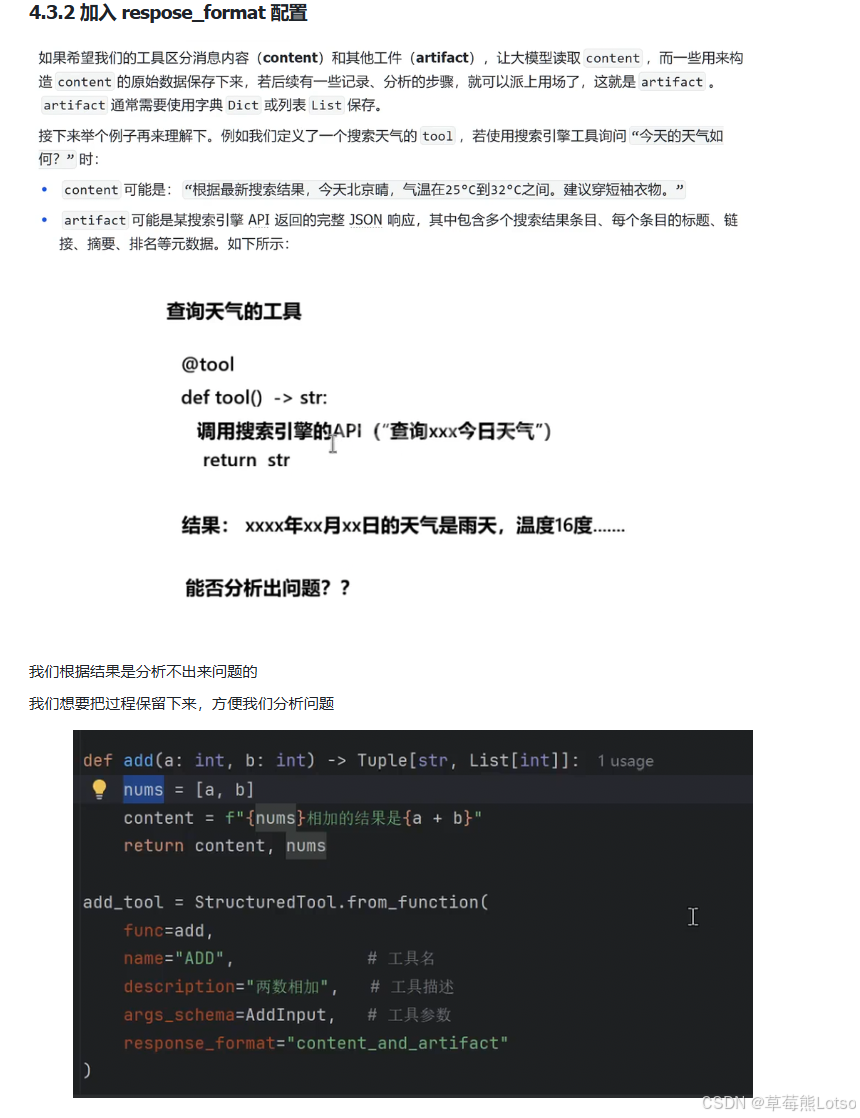
def add(a: int, b: int) -> Tuple[str, List[int]]:
"""两数相加"""
nums = [a, b]
content = f"{nums}相加的结果是{a+b}"
return content, nums
# 创建工具,区分 content 和 artifact
add_tool = StructuredTool.from_function(
func=add,
name="ADD",
description="两数相加",
args_schema=AddInput,
response_format="content_and_artifact"
)
# 模拟大模型调用方式
result = add_tool.invoke({
"name": "ADD",
"args": {"a": 3, "b": 4},
"type": "tool_call",
"id": "111"
})
print(result)
# 输出:ToolMessage(content='[3, 4]相加的结果是7', name='ADD', tool_call_id='111', artifact=[3, 4])
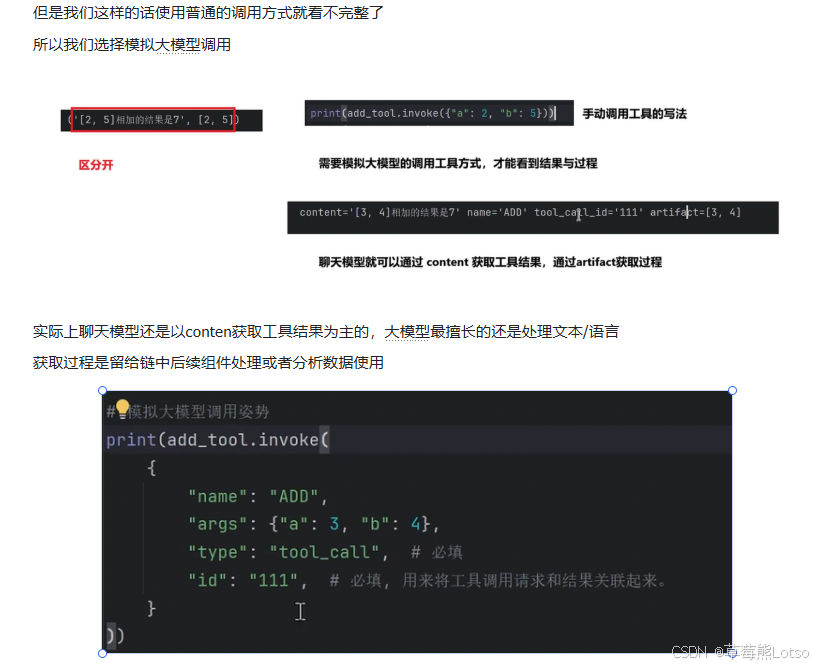
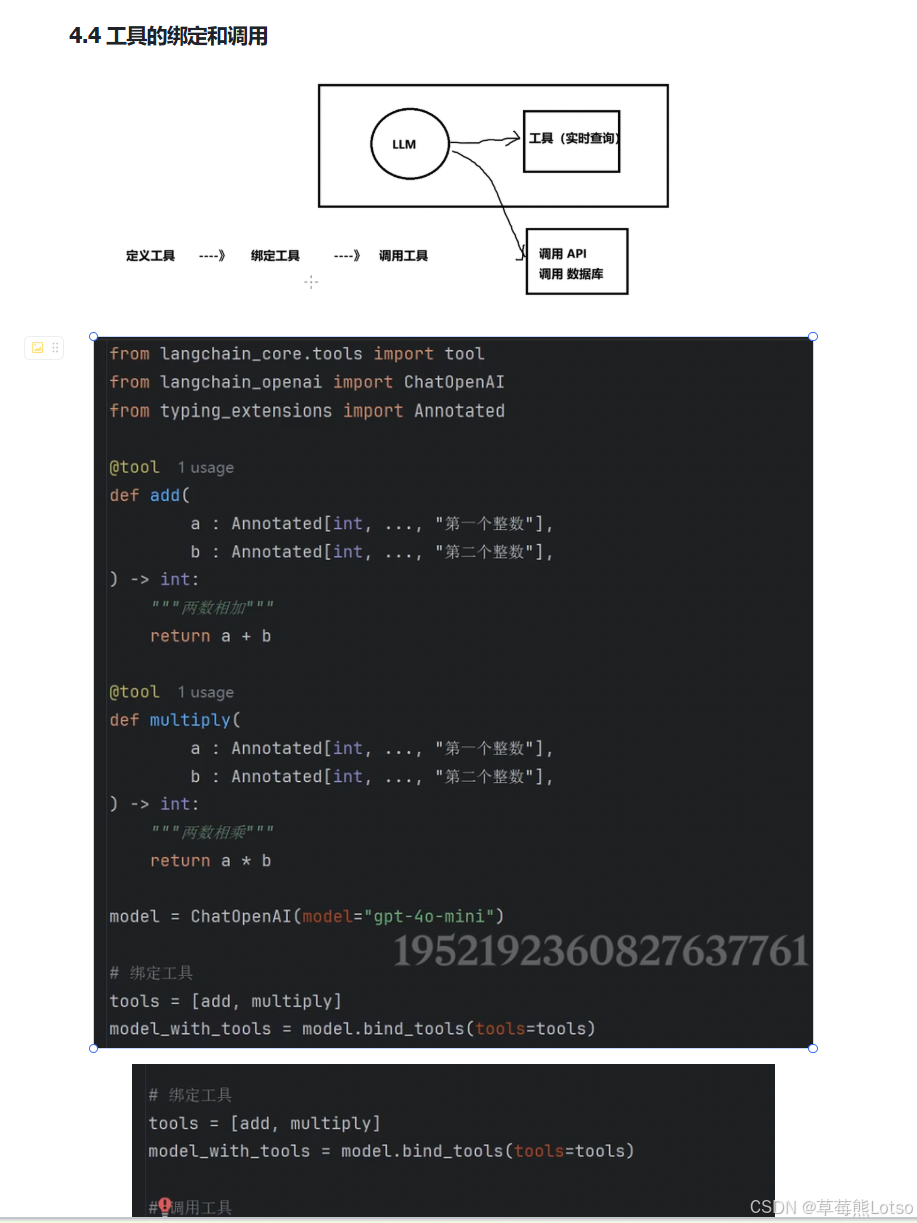
2.3 工具的绑定与调用
定义好工具后,需要将工具绑定到聊天模型,然后按照 “工具选择 → 工具执行 → 结果总结” 的流程调用。
完整工具调用流程
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# 定义两个工具
@tool
def add(a: int, b: int) -> int:
"""两数相加"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""两数相乘"""
return a * b
# 1. 绑定工具到模型
tools = [add, multiply]
model_with_tools = model.bind_tools(tools=tools)
# 2. 第一步:让模型选择工具
messages = [HumanMessage(content="2乘3等于多少?")]
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg)
# 查看模型返回的工具调用信息
print(ai_msg.tool_calls)
# 输出:[{'name': 'multiply', 'args': {'a': 2, 'b': 3}, 'id': 'call_xxx', 'type': 'tool_call'}]
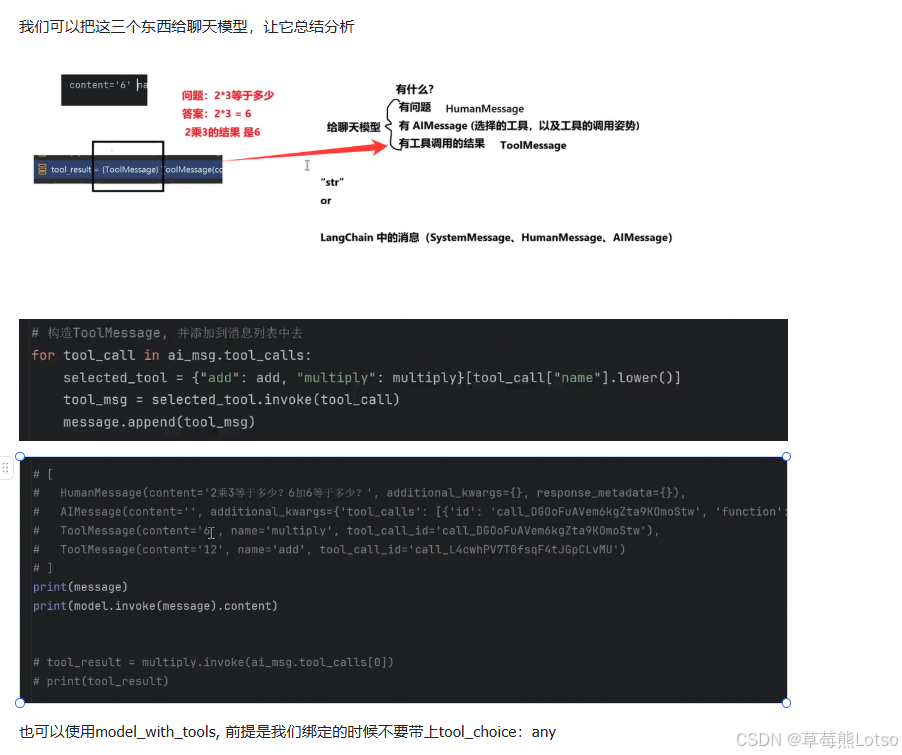
# 3. 第二步:执行工具调用
for tool_call in ai_msg.tool_calls:
# 根据工具名称选择对应的工具
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
messages.append(tool_msg)
# 4. 第三步:让模型根据工具结果生成最终回答
final_result = model_with_tools.invoke(messages)
print(final_result.content)
# 输出:2乘3等于6。

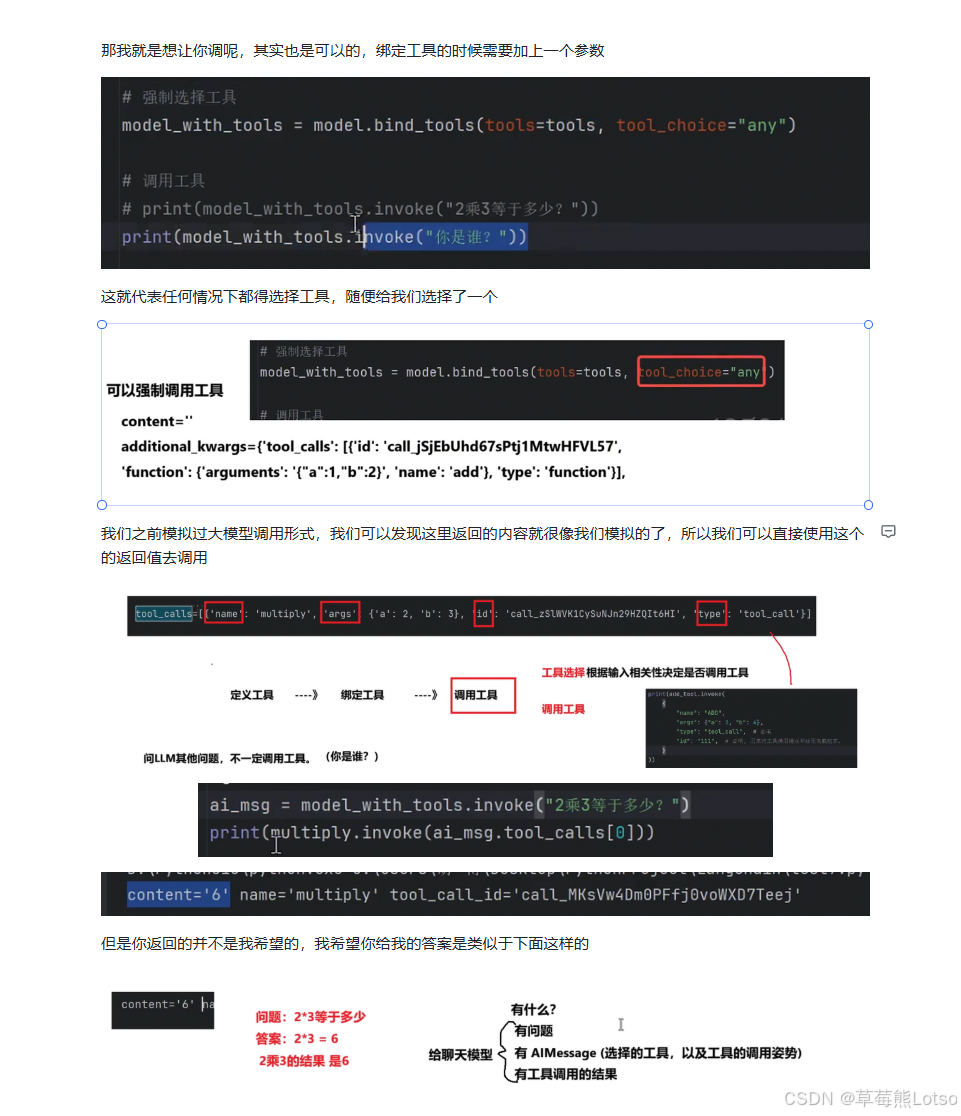
强制调用工具
默认情况下,模型会根据输入内容自动决定是否调用工具。如果你想强制模型调用某个工具,可以使用 tool_choice 参数。
# 强制调用任意一个工具
model_with_tools = model.bind_tools(tools=tools, tool_choice="any")
# 强制调用指定工具
model_with_tools = model.bind_tools(tools=tools, tool_choice={"type": "function", "function": {"name": "add"}})
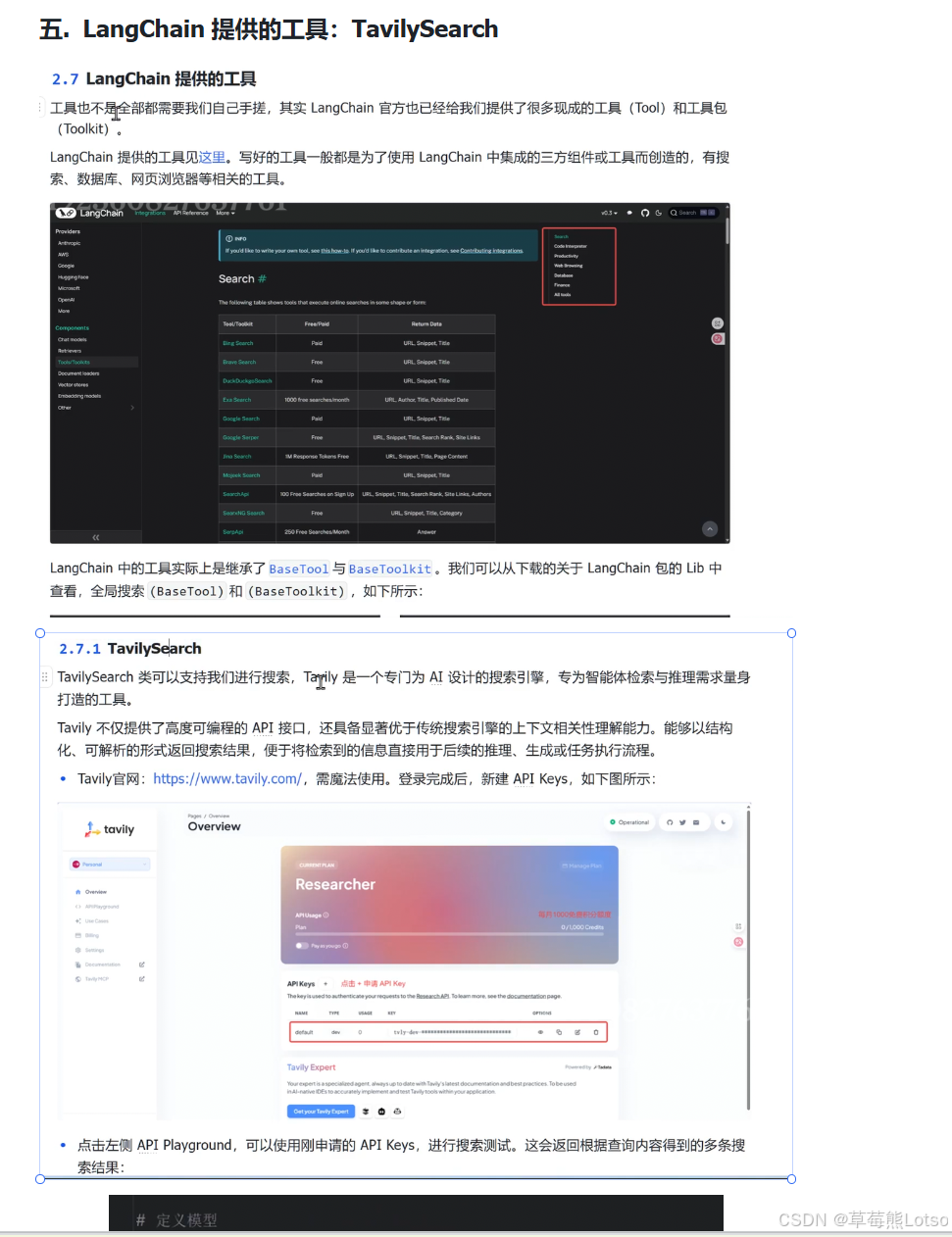
三、实战:集成 Tavily 搜索引擎实现实时天气查询
Tavily 是一个专门为 AI 设计的搜索引擎,专为智能体检索与推理需求量身打造,能够以结构化形式返回搜索结果。
3.1 环境准备
- 注册 Tavily 账号并获取 API Key:https://www.tavily.com/
- 配置系统环境变量
TAVILY_API_KEY为你的 API Key - 安装依赖包:
pip install langchain-tavily langchain-openai
3.2 完整代码实现
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_tavily import TavilySearch
# 1. 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义搜索工具,最多返回4条结果
tool = TavilySearch(max_results=4)
# 3. 绑定工具到模型
model_with_tools = model.bind_tools([tool])
# 4. 第一步:用户提问,模型选择调用搜索工具
messages = [
HumanMessage("中国西安今天的天气怎么样?")
]
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg)
# 5. 第二步:执行搜索工具
for tool_call in ai_msg.tool_calls:
tool_msg = tool.invoke(tool_call)
messages.append(tool_msg)
# 6. 第三步:模型根据搜索结果生成最终回答
result = model_with_tools.invoke(messages)
print(result.content)
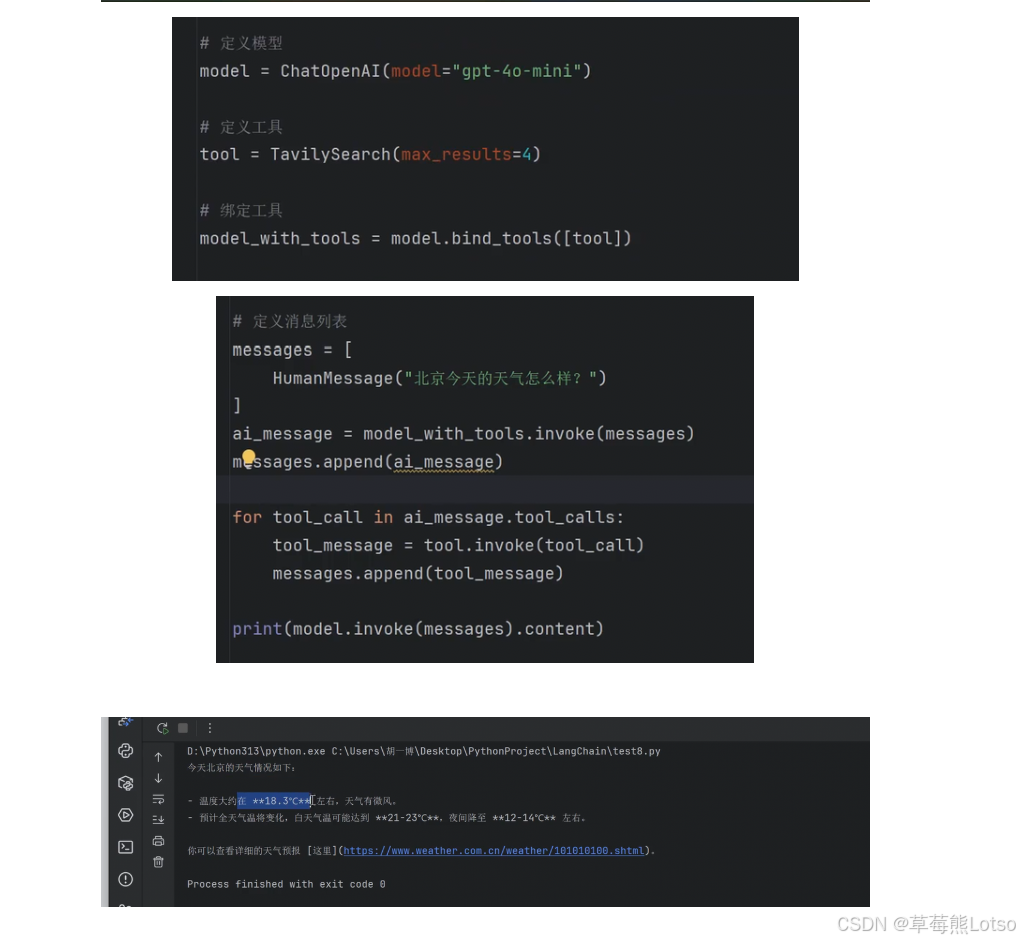
3.3 输出结果示例
今天西安的天气情况如下:
- **天气**:晴天转多云
- **最高气温**:约31℃
- **最低气温**:约21℃
- 预计在晚上会有降雨。
有关更详细的信息,你可以查看[中国气象局的天气预报](https://weather.cma.cn/web/weather/V8870.html)或其他相关天气网站。
四、核心知识点总结
- 聊天模型:
- 使用
ChatOpenAI初始化 OpenAI 模型,重点掌握temperature和max_tokens参数 - 使用
init_chat_model()实现多模型统一初始化 - 使用
ChatOllama调用本地部署的开源模型
- 使用
- 工具调用:
- 工具的核心三要素:名称、描述、参数 schema
- 推荐使用
@tool装饰器定义工具,简单高效 - 工具调用流程:工具选择 → 工具执行 → 结果总结
- 可以通过
tool_choice参数强制模型调用指定工具
- Tavily 搜索:
- Tavily 是专为 AI 设计的搜索引擎,返回结构化结果
- 只需配置 API Key 即可快速集成,实现实时信息获取
结尾
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!
结语:本文我们从最基础的聊天模型定义开始,逐步深入到工具调用的底层逻辑,并最终实现了一个能实时搜索天气的 AI 助手。这只是 LangChain 强大功能的冰山一角,后续我们还将学习结构化输出、流式传输、RAG 检索增强生成等高级功能,带你一步步构建生产级的 LLM 应用。如果本文对你有帮助,欢迎点赞、收藏、关注!有任何问题都可以在评论区留言交流。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)