【SpringBoot 3.x 第234节】夯爆了,MQ 消费端并发模型设计!

🏆本文收录于《滚雪球学SpringBoot 3.x》,专门攻坚指数提升,本年度国内最系统+最专业+最详细(永久更新)。
该专栏致力打造最硬核 SpringBoot3 从零基础到进阶系列学习内容,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…欢迎大家订阅持续学习。 如果想快速定位学习,可以看这篇【SpringBoot3教程导航帖】,你想学习的都被收集在内,快速投入学习!!两不误。
若还想学习更多,可直接订阅 《Spring Boot实战合集》,一次订阅,持续学习,后续更新内容无需重复付费,适合长期收藏与系统进阶。
演示环境说明:
- 开发工具:IDEA 2021.3
- JDK版本: JDK 17(推荐使用 JDK 17 或更高版本,因为 Spring Boot 3.x 系列要求 Java 17,Spring Boot 3.5.4 基于 Spring Framework 6.x 和 Jakarta EE 9,它们都要求至少 JDK 17。)
- Spring Boot版本:3.5.4(于25年7月24日发布)
- Maven版本:3.8.2 (或更高)
- Gradle:(如果使用 Gradle 构建工具的话):推荐使用 Gradle 7.5 或更高版本,确保与 JDK 17 兼容。
- 操作系统:Windows 11
全文目录:
- 一、为什么 MQ 消费端并发模型不是“线程越多越好”?
- 二、Spring Boot 3.x 下 MQ 消费端的基础认知
- 三、并发数是否越大越好:从吞吐、延迟、稳定性三个维度拆解
- 四、顺序消费与并行消费的权衡
- 五、幂等设计:如何让“重复消息”变成“正常现象”?
- 六、重试策略:什么时候重试,重试多少次,失败后怎么办?
- 七、积压治理:如何面对流量洪峰、下游抖动和消费回落
- 八、线程池与消费容器调优:参数不是背答案,而是算出来的
- 九、Spring Boot 3.x + RabbitMQ 实战工程
- 十、代码:依赖、配置、消息模型与基础设施
- 十一、代码:生产者、串行消费者、并行消费者
- 十二、代码:幂等、重试、死信记录
- 十三、代码:线程池与消费容器的联动调优
- 十四、模型图:让设计思路一眼看懂!
- 十五、代码解析:为什么这套设计能跑得稳?
- 十六、常见误区与排障方法
- 十七、生产落地建议清单
- 十八、设计结论
- 十九、结语
- 🧧 学习福利 · 限时开放 🧧
- 🫵 Who am I?
一、为什么 MQ 消费端并发模型不是“线程越多越好”?
很多同学第一次配置 MQ 消费端时,最容易犯的错误就是把并发数开得很大:
concurrentConsumers = 16maxConcurrentConsumers = 32- 线程池直接拉满
prefetch也跟着加大
看起来很猛,实际上非常容易把系统推入另一种“更隐蔽的瓶颈”:
- CPU 飙高,但吞吐并没有提升。
- DB 连接池耗尽,消费线程都在等连接。
- 下游接口被打爆,消息积压更严重。
- 业务逻辑出现乱序,重复消费放大事故。
- 监控上看起来“线程很忙”,但业务结果并不好。
MQ 消费端并发模型的核心,不是“尽可能多地启动线程”,而是“让每一条消息在合适的顺序、合适的并发、合适的节奏下完成处理”。
换句话说,真正重要的是:
- 让系统整体吞吐最大化,而不是单个组件忙碌度最大化;
- 让关键业务保持正确性,而不是把顺序、幂等、重试全交给运气;
- 让资源使用稳定,而不是高峰期偶发性冲垮线程池、数据库和外部服务。
MQ 消费端并发的本质,是一个“端到端资源协同问题”。它同时涉及:
- Broker 的投递与确认节奏;
- 消费端容器线程模型;
- 业务线程池的隔离;
- DB、Redis、HTTP 调用等下游资源;
- 失败重试与死信兜底;
- 监控、告警与压测数据反馈。
如果只看消费者线程数,就像只看汽车的发动机转速而不看路况、轮胎和刹车一样,很容易得出错误结论。
二、Spring Boot 3.x 下 MQ 消费端的基础认知
Spring Boot 3.x 对消息消费的支持主要还是靠 Spring AMQP、Spring Kafka、Spring Cloud Stream 等生态完成。本文为了便于讲清“消费端并发模型设计”,采用 Spring Boot 3.x + RabbitMQ 作为示例。原因很简单:
- Spring Boot 3.x + Spring AMQP 的消费者容器配置清晰;
concurrentConsumers、maxConcurrentConsumers、prefetchCount这些参数非常适合讲并发模型;- 代码小而完整,适合零基础同学从工程结构理解问题。
说明:如果你用的是 Kafka、RocketMQ、Pulsar,底层机制不同,但“并发、顺序、幂等、重试、积压治理”的设计思路高度一致。
2.1 Spring Boot 3.x 的几个关键背景
Spring Boot 3.x 有几个基础前提,会直接影响你写 MQ 消费代码:
- Java 17+ 是主流基线:很多现代写法可以直接用 record、switch 表达式等特性;
- Jakarta 命名空间迁移:
javax.*已经逐步迁移到jakarta.*; - Actuator/Observation 更强:更适合做消费端监控;
- 更适合模块化与云原生部署:容器化后,消费端调优更依赖“数据驱动”。
所以,本文示例统一按照:
- Java 17
- Spring Boot 3.x
- Spring AMQP 3.x
- JPA / H2(用于演示幂等和状态更新)
来设计。
2.2 MQ 消费端的标准链路
消费者并不是“收到消息就直接执行业务”这么简单。一个完整链路通常是:
- Broker 投递消息到消费者;
- 消费容器接收消息;
- 进入业务处理逻辑;
- 进行幂等判断;
- 调用数据库、Redis、HTTP 等下游;
- 成功后 ACK;
- 失败后进入重试或死信;
- 监控、日志、告警系统记录状态。
整个过程中,真正影响并发模型的,不是“消息本身有多少”,而是“每条消息在系统里停留多久”。
可以把消费时延拆成下面几个部分:
T_net:网络与 broker 投递耗时;T_queue:在消费端等待线程的耗时;T_idempotent:幂等检查耗时;T_business:核心业务耗时;T_downstream:DB/Redis/接口调用耗时;T_ack:确认消息耗时。
真正决定并发是否有效的,是这些时延中哪些属于 CPU 密集,哪些属于 IO 密集,哪些是 锁等待,哪些是 资源竞争。
三、并发数是否越大越好:从吞吐、延迟、稳定性三个维度拆解
这是本文最关键的一章。很多人以为并发越大越好,其实并不是。
3.1 先明确一个事实:并发提升不等于吞吐线性提升
理想情况下,如果所有任务都是独立、无锁、无 IO、无下游瓶颈的纯计算任务,增加并发确实能提升吞吐。但真实的 MQ 消费不是这样,它通常是“混合型任务”:
- 有网络 IO;
- 有数据库读写;
- 有外部服务调用;
- 有事务提交;
- 有锁竞争;
- 有 JVM GC;
- 有容器调度;
- 有 broker 的投递与确认开销。
因此,吞吐曲线往往是这样的:
- 前期随着并发增加,吞吐明显提升;
- 中期达到平台期;
- 后期继续增加并发,吞吐几乎不再提升,甚至下降;
- 再往后,系统稳定性下降,失败率上升。
这就是典型的“边际收益递减”。
3.2 并发数过大的常见副作用
1)数据库连接池耗尽
如果每条消息都要写库,且每个消费者线程都在抢连接,那么线程数一旦超过连接池大小,就会出现大量等待:
- 消费线程阻塞;
- ACK 延迟变长;
- Broker 未确认消息增加;
- 队列反而堆积得更快。
2)下游接口被打爆
很多消费逻辑并不是简单落库,而是要调用订单、库存、风控、支付等系统。并发上去后,下游接口的响应时间会迅速拉长,甚至直接超时。于是:
- 重试增多;
- 重复消息增多;
- 线程池排队增多;
- 延迟进一步放大。
3)JVM 和 OS 开销上升
线程越多,不只是“并发更高”,还意味着:
- 上下文切换更多;
- 线程栈内存占用更多;
- CPU cache 命中率变差;
- GC 压力可能增加。
如果你的处理逻辑本身不是 IO 密集型,而是 CPU + 锁密集型,盲目加线程通常只会把系统拖慢。
4)消费顺序更容易被打乱
如果业务需要顺序消费,而你把同一业务键的消息丢进多个线程并发处理,就会出现:
- 先到的消息后执行;
- 后到的消息先提交;
- 状态机倒退;
- 最终数据错误。
5)重试风暴
高并发下,一旦下游异常,失败消息数量会指数级放大。重试如果不受控,系统会形成“自我攻击”:
- 消费越多,失败越多;
- 失败越多,重试越多;
- 重试越多,资源越紧张;
- 资源越紧张,失败更严重。
这就是典型的重试风暴。
3.3 并发数该怎么估算?
并发数没有统一答案,但可以用下面的思路估算:
第一层:按任务性质粗判
- CPU 密集型:并发数通常接近 CPU 核数或略高;
- IO 密集型:并发数可以高于核数,但必须受下游资源限制;
- 混合型任务:优先按“最弱资源”来定上限。
第二层:按瓶颈资源倒推
假设每条消息平均消耗:
- 1 次 DB 写;
- 1 次 Redis 读写;
- 1 次外部 HTTP 调用;
- 平均耗时 120ms。
那么并发上限至少要参考:
- DB 连接池最大值;
- Redis 连接池最大值;
- HTTP 客户端连接池最大值;
- 下游服务 QPS 承载能力;
- MQ broker 的投递能力。
不是“线程池多大就开多大”,而是“整个链路能承受多大”。
第三层:通过压测数据校准
真正合理的并发值,一定是压测出来的。你要观察:
- QPS 是否稳定上升;
- P95 / P99 延迟是否可接受;
- GC 是否异常;
- 连接池是否打满;
- 消息是否出现大量重投;
- 下游是否开始抖动。
最终找到的是一个“拐点”而不是一个“最大值”。
3.4 一个非常实用的判断原则
对于大多数业务系统,可以先从下面的保守策略起步:
- 先从 1 到 2 个消费者线程开始;
- 观察单线程吞吐和下游耗时;
- 再逐步增加到 4、8、16;
- 每次只调整一个参数;
- 每次压测都记录成功率、延迟和失败类型。
这比一上来开 32 个线程更容易找到真正的平衡点。
四、顺序消费与并行消费的权衡
并发模型设计的第二个关键问题,就是顺序和并行的取舍。
4.1 什么场景必须顺序消费
如果你的业务依赖“前一条消息处理完,后一条才能继续”,那就必须顺序消费。典型场景包括:
- 订单状态变更:创建、支付、发货、完成;
- 账户余额变更:先扣减再冻结或解冻;
- 库存流水:入库、锁定、出库;
- 审批流状态推进;
- 同一业务对象的状态机变更。
在这类场景中,顺序不是性能问题,而是业务正确性问题。
4.2 什么场景适合并行消费
如果消息之间没有强依赖,或者依赖可以通过业务键分片隔离,那么并行消费更合适:
- 用户画像更新;
- 日志分析;
- 异步通知;
- 统计聚合;
- 可独立幂等执行的批处理任务。
并行消费的核心价值是:
- 提高吞吐;
- 减少堆积;
- 更好地利用多核 CPU;
- 对高峰流量更有弹性。
4.3 顺序消费的代价
顺序消费看似简单,其实代价也很明显:
- 单队列单线程会限制吞吐;
- 一个慢消息会阻塞后面的所有消息;
- 任何一次下游抖动都会把队列拖长;
- 容错空间更小。
因此,顺序消费一般不建议做“全局顺序”,而是做“局部顺序”。
局部顺序的意思
比如按 orderId 维度保证顺序:
- 同一个订单的消息必须顺序;
- 不同订单之间可以并行。
这就是生产系统里最常见的设计:把强顺序要求收缩到业务键维度。
4.4 最常见的折中方案:按业务键分片
真正成熟的做法通常不是“全局顺序”或“完全并行”,而是:
- 以业务键为 Hash 分片;
- 同一个业务键固定路由到同一个分片队列;
- 每个分片队列内部保持顺序;
- 不同分片之间并行消费。
这样既保留了顺序,又提升了吞吐。
例如:
- 订单消息按
orderId % 8路由到 8 个队列; - 同一个订单一定进入同一个队列;
- 8 个队列可以并行消费;
- 单个队列内部仍可按顺序执行。
这是一种非常适合 Spring Boot 3.x 实战的设计。
五、幂等设计:如何让“重复消息”变成“正常现象”?
MQ 的世界里,重复消息不是异常,而是常态。
你需要默认接受下面几个事实:
- Broker 可能重复投递;
- 消费者可能超时后重试;
- 应用可能在 ACK 之前宕机;
- 网络抖动可能导致状态不一致;
- 人工补偿也可能造成重放。
所以,幂等不是“有最好”,而是“必须有”。
5.1 幂等的几种常见做法
方案一:业务状态机幂等
适用于“状态推进”类业务。
例子:订单从 UNPAID 到 PAID,只允许执行一次。如果当前状态已经是 PAID,那重复消息直接忽略。
优点:
- 简单直观;
- 可读性强;
- 很适合订单、库存、审批流。
方案二:唯一业务键幂等
适用于“同一业务事件只处理一次”的场景。
例子:以 messageId 或 bizId 作为唯一键,第一次处理成功后写入消费日志,后续重复消息直接跳过。
优点:
- 适合通用消息;
- 对下游逻辑依赖少。
方案三:分布式锁幂等
适用于并发很高、且同一业务键短时间内可能重复到达的场景。
但要注意:锁不是幂等本身,它只是保护幂等逻辑的一种手段。
方案四:数据库唯一约束幂等
适合“以表为准”的业务:
- 插入订单明细;
- 插入支付流水;
- 插入消费日志;
- 插入补偿记录。
唯一约束可以非常有效地挡住重复写入。
5.2 设计幂等时要记住的一句话
幂等不是让消息不重复,而是让重复执行的结果不重复。
这句话非常重要。
你不一定要让消息“只消费一次”,因为那在分布式系统里成本很高;但你必须让消息“重复消费也不产生重复副作用”。
六、重试策略:什么时候重试,重试多少次,失败后怎么办?
重试是把失败转成成功的重要手段,但重试也最容易被滥用。
6.1 先分清两类错误
1)可重试错误
典型包括:
- 数据库短暂不可用;
- 下游超时;
- 网络抖动;
- 资源繁忙;
- 临时限流。
这些错误通常过一会儿会恢复,适合重试。
2)不可重试错误
典型包括:
- 参数非法;
- 业务规则不允许;
- 数据不存在;
- 状态已经不可逆;
- 逻辑代码 bug。
这类错误再重试也没有意义,应该直接进入失败处理或死信。
6.2 重试不是越多越好
很多团队喜欢设置很大的重试次数,比如 10 次、20 次。看似“更稳”,实际可能更差。
原因是:
- 错误会被重复放大;
- 线程被占住;
- 下游压力更大;
- 用户感知延迟变得不可接受;
- 积压队列越来越长。
通常更合理的做法是:
- 小次数快速重试:2~3 次;
- 指数退避:每次延迟略增;
- 超过阈值后进入死信;
- 死信再由人工或定时任务补偿处理。
6.3 重试和幂等要一起设计
如果没有幂等,重试就是放大器;
如果没有重试,临时失败就会变成永久失败;
如果两者都没有,系统看起来“没报错”,实际上数据已经悄悄丢失。
所以,成熟的设计一定是:
- 幂等负责“重复不出错”;
- 重试负责“短暂失败自动恢复”;
- 死信负责“错误兜底和人工处理”。
6.4 一个实用原则
对于绝大多数业务:
- 参数错误、状态错误:直接失败,不重试;
- 超时、连接失败:短重试;
- 持续失败:进入死信;
- 失败告警:一定要有。
七、积压治理:如何面对流量洪峰、下游抖动和消费回落
消息积压不是一个单点问题,它通常意味着:
- 消费能力不足;
- 消费逻辑太重;
- 下游变慢;
- 并发配置不合理;
- 业务高峰超过系统承载。
7.1 先识别积压的来源
积压可能来自这些地方:
- 生产端突然暴增;
- 消费端线程不足;
- 下游 DB 变慢;
- 外部接口超时;
- 某个消息处理特别慢;
- 单条大事务阻塞;
- 重试风暴把正常消费挤掉了。
所以,看到“队列长度增长”,不能直接把并发拉满。你要先定位“是谁拖慢了谁”。
7.2 治理积压的基本套路
方案一:临时扩容消费者
适合短时洪峰。
比如:
- 消费实例从 2 个扩到 6 个;
- 并发线程从 4 调到 8;
- 在总资源允许的前提下提高处理能力。
方案二:削峰填谷
把高峰时段的流量通过 MQ 缓冲,把消费能力平滑化。这个思路在批量任务、秒杀后置处理、异步通知等场景非常有效。
方案三:拆分慢消息
如果某类消息特别慢,可以把它单独拆队列、单独消费者、单独资源池,避免拖累主链路。
方案四:限流和降级
当积压开始严重时,不要继续“硬扛”。可以考虑:
- 降低非核心任务优先级;
- 关闭部分次要功能;
- 暂停某些重试;
- 对下游做熔断。
方案五:批量消费
适用于支持批量处理的场景。一次消费多条消息,可以显著减少 IO 次数和事务开销。
但批量消费也有代价:
- 失败重试粒度变粗;
- 代码复杂度提高;
- 单批次失败影响面更大。
7.3 积压治理的目标不是“清零”,而是“可控”
很多人看到积压就焦虑,想立刻把队列打到 0。实际上,生产系统里“绝对清零”未必是最优目标。
真正重要的是:
- 延迟是否在 SLA 内;
- 是否会持续恶化;
- 是否出现不可恢复的堆积;
- 是否有明显抖动和重试风暴。
如果队列积压是可预期的、稳定的、并且业务可接受,那未必是问题。
八、线程池与消费容器调优:参数不是背答案,而是算出来的
这是很多 Spring Boot 3.x 初学者最容易忽略的一部分:
MQ 消费容器线程 和 业务线程池 是两回事。
它们各自承担不同职责,不能混为一谈。
8.1 消费容器线程的作用
以 RabbitMQ 为例,消费容器线程负责:
- 从 Broker 拉取消息;
- 触发监听方法;
- 协助 ACK/NACK;
- 管理并发消费。
这部分线程如果配置不合理,会直接影响消息投递节奏。
8.2 业务线程池的作用
业务线程池负责:
- 把一些耗时操作异步化;
- 隔离下游慢调用;
- 减少监听线程阻塞;
- 控制业务并发上限。
但注意:如果你为了“快”把所有消息都丢进线程池,实际很容易出现:
- 消费线程先 ACK 了,业务还没真正完成;
- 任务堆积在本地内存;
- 应用宕机后消息丢失;
- 幂等和异常处理更加复杂。
所以是否使用业务线程池,必须看你能不能接受“消息处理从 MQ 语义变成本地异步任务语义”。
8.3 线程池调优的几个关键参数
核心线程数
影响系统的基础并发能力。对 IO 密集型任务,可以略高于 CPU 核数;对 CPU 密集型任务,则不宜太高。
最大线程数
决定突发时的扩容能力,但不是越大越好。过大意味着更多上下文切换和资源争抢。
队列容量
队列过小,任务容易被拒绝;队列过大,延迟容易失控,还会掩盖问题。
拒绝策略
不要默认忽略。对于 MQ 消费而言,拒绝策略一定要明确:
- 是进入重试;
- 还是进入死信;
- 还是打告警后人工处理。
线程命名
一定要给线程池命名,排障时非常有帮助。
8.4 消费容器参数调优
以 RabbitMQ 消费容器为例,常见参数有:
concurrentConsumers:基础并发数;maxConcurrentConsumers:动态上限;prefetchCount:一次向消费者预取多少消息;acknowledgeMode:自动确认还是手动确认;defaultRequeueRejected:失败后是否重新入队。
参数的含义要理解透
concurrentConsumers
这是容器最基础的并发消费者数。它决定了有多少个线程可以同时处理消息。
maxConcurrentConsumers
当消息堆积或任务繁忙时,容器可以动态增加消费者。但这个值不是魔法,前提是你有足够资源支撑。
prefetchCount
这个参数非常重要。它表示 Broker 一次预取多少条消息给消费者。
prefetch太小:吞吐可能不够;prefetch太大:消费者可能拿了很多消息却处理不过来,导致其他消费者不均衡。
通常建议:
- 顺序消费:prefetch 较小,常见为 1;
- 并行消费:prefetch 可以适度提高,但要结合业务耗时和容器数量一起评估。
手动 ACK
对于重要业务,推荐手动 ACK。因为你需要在业务真正成功之后再确认消息,否则容易出现“消息已确认但业务没落地”的风险。
九、Spring Boot 3.x + RabbitMQ 实战工程
下面开始进入实战。为了让同学们更容易理解,我们构建一个“订单支付事件消费”的 demo。
9.1 业务目标
假设系统在用户支付成功后,会投递一条 OrderPaidEvent 消息,消费者需要完成:
- 幂等检查;
- 订单状态推进;
- 消费日志记录;
- 失败重试;
- 超过阈值后写入死信表。
我们同时演示两种模式:
- 串行消费:同一订单强顺序处理;
- 分片并行消费:按
orderId分片提高吞吐。
9.2 工程结构
mq-consumer-concurrency-demo
├── src/main/java/com/example/mq
│ ├── MqApplication.java
│ ├── config
│ │ ├── RabbitConfig.java
│ │ ├── ThreadPoolConfig.java
│ │ └── RetryConfig.java
│ ├── constant
│ │ └── MqConstants.java
│ ├── dto
│ │ └── OrderPaidEvent.java
│ ├── entity
│ │ ├── ConsumeLog.java
│ │ └── DeadLetterMessage.java
│ ├── repository
│ │ ├── ConsumeLogRepository.java
│ │ └── DeadLetterMessageRepository.java
│ ├── service
│ │ ├── OrderPaidProcessService.java
│ │ └── MessageAuditService.java
│ ├── consumer
│ │ ├── SerialOrderPaidConsumer.java
│ │ └── ParallelOrderPaidConsumer.java
│ └── producer
│ └── OrderEventProducer.java
└── src/main/resources
└── application.yml
十、代码:依赖、配置、消息模型与基础设施
10.1 Maven 依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.x.x</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>mq-consumer-concurrency-demo</artifactId>
<version>1.0.0</version>
<name>mq-consumer-concurrency-demo</name>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<!-- Web 仅用于演示接口触发生产消息 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- RabbitMQ -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!-- JPA:用于消费日志、死信日志和幂等状态演示 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- H2:为了让示例可直接运行,避免依赖外部数据库 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Retry:用于业务重试 -->
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
<!-- AOP:支持 @Retryable -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- 参数校验 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
10.2 application.yml
server:
port: 8080
spring:
application:
name: mq-consumer-concurrency-demo
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
acknowledge-mode: manual
default-requeue-rejected: false
datasource:
url: jdbc:h2:mem:mqdemo;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=false
driver-class-name: org.h2.Driver
username: sa
password:
jpa:
hibernate:
ddl-auto: update
show-sql: true
properties:
hibernate:
format_sql: true
h2:
console:
enabled: true
path: /h2-console
logging:
level:
com.example.mq: info
org.springframework.amqp: info
10.3 启动类
package com.example.mq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.retry.annotation.EnableRetry;
@EnableRetry // 开启 Spring Retry
@SpringBootApplication
public class MqApplication {
public static void main(String[] args) {
SpringApplication.run(MqApplication.class, args);
}
}
10.4 常量类
package com.example.mq.constant;
public final class MqConstants {
private MqConstants() {
}
// 串行消费相关
public static final String SERIAL_EXCHANGE = "order.serial.exchange";
public static final String SERIAL_QUEUE = "order.serial.queue";
public static final String SERIAL_ROUTING_KEY = "order.serial";
// 分片并行消费相关
public static final String PARALLEL_EXCHANGE = "order.parallel.exchange";
public static final int PARALLEL_SHARD_COUNT = 8;
public static final String PARALLEL_QUEUE_PREFIX = "order.parallel.queue.";
public static final String PARALLEL_ROUTING_KEY_PREFIX = "order.parallel.";
// 业务重试和死信
public static final String DEAD_LETTER_TABLE = "dead_letter_message";
}
10.5 消息模型:使用 record
package com.example.mq.dto;
import jakarta.validation.constraints.NotNull;
import java.math.BigDecimal;
import java.time.Instant;
public record OrderPaidEvent(
@NotNull String messageId, // 消息唯一标识,用于幂等和排障
@NotNull Long orderId, // 订单 ID,作为分片依据
@NotNull Long userId, // 用户 ID
@NotNull BigDecimal amount, // 支付金额
@NotNull Instant paidAt // 支付时间
) {
}
说明:Spring Boot 3.x 对 record 的支持非常适合消息 DTO。只要 Jackson 配置正常,序列化与反序列化都很自然。
10.6 RabbitMQ 配置
package com.example.mq.config;
import com.example.mq.constant.MqConstants;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.listener.RabbitListenerContainerFactoryConfigurer;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.DependsOn;
import org.springframework.util.backoff.FixedBackOff;
import java.util.ArrayList;
import java.util.List;
@Configuration
public class RabbitConfig {
@Bean
public MessageConverter messageConverter(ObjectMapper objectMapper) {
// 使用 Jackson 统一序列化消息,避免手写 JSON
return new Jackson2JsonMessageConverter(objectMapper);
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory, MessageConverter messageConverter) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(messageConverter);
return rabbitTemplate;
}
@Bean
public DirectExchange serialExchange() {
return new DirectExchange(MqConstants.SERIAL_EXCHANGE, true, false);
}
@Bean
public Queue serialQueue() {
return QueueBuilder.durable(MqConstants.SERIAL_QUEUE).build();
}
@Bean
public Binding serialBinding(Queue serialQueue, DirectExchange serialExchange) {
return BindingBuilder.bind(serialQueue).to(serialExchange).with(MqConstants.SERIAL_ROUTING_KEY);
}
@Bean
public DirectExchange parallelExchange() {
return new DirectExchange(MqConstants.PARALLEL_EXCHANGE, true, false);
}
@Bean
public List<Queue> parallelQueues() {
List<Queue> queues = new ArrayList<>();
for (int i = 0; i < MqConstants.PARALLEL_SHARD_COUNT; i++) {
queues.add(QueueBuilder.durable(MqConstants.PARALLEL_QUEUE_PREFIX + i).build());
}
return queues;
}
@Bean
public List<Binding> parallelBindings(List<Queue> parallelQueues, DirectExchange parallelExchange) {
List<Binding> bindings = new ArrayList<>();
for (int i = 0; i < parallelQueues.size(); i++) {
String routingKey = MqConstants.PARALLEL_ROUTING_KEY_PREFIX + i;
bindings.add(BindingBuilder.bind(parallelQueues.get(i)).to(parallelExchange).with(routingKey));
}
return bindings;
}
@Bean(name = "serialListenerContainerFactory")
public SimpleRabbitListenerContainerFactory serialListenerContainerFactory(
ConnectionFactory connectionFactory,
RabbitListenerContainerFactoryConfigurer configurer) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
configurer.configure(factory, connectionFactory);
factory.setConcurrentConsumers(1); // 严格顺序:单消费者
factory.setMaxConcurrentConsumers(1);
factory.setPrefetchCount(1); // 严格顺序:一次只拿一条
factory.setDefaultRequeueRejected(false);
return factory;
}
@Bean(name = "parallelListenerContainerFactory")
public SimpleRabbitListenerContainerFactory parallelListenerContainerFactory(
ConnectionFactory connectionFactory,
RabbitListenerContainerFactoryConfigurer configurer) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
configurer.configure(factory, connectionFactory);
factory.setConcurrentConsumers(4); // 基础并发
factory.setMaxConcurrentConsumers(12); // 上限可按压测结果调整
factory.setPrefetchCount(20); // 并行消费可适度提高预取
factory.setDefaultRequeueRejected(false);
return factory;
}
}
十一、代码:生产者、串行消费者、并行消费者
11.1 生产者:按照业务键分片路由
package com.example.mq.producer;
import com.example.mq.constant.MqConstants;
import com.example.mq.dto.OrderPaidEvent;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
@Service
public class OrderEventProducer {
private final RabbitTemplate rabbitTemplate;
public OrderEventProducer(RabbitTemplate rabbitTemplate) {
this.rabbitTemplate = rabbitTemplate;
}
public void sendSerialEvent(OrderPaidEvent event) {
// 串行消费:路由到单队列
rabbitTemplate.convertAndSend(
MqConstants.SERIAL_EXCHANGE,
MqConstants.SERIAL_ROUTING_KEY,
event
);
}
public void sendParallelEvent(OrderPaidEvent event) {
// 按 orderId 分片,确保同一订单固定进入同一队列
int shard = Math.floorMod(event.orderId().hashCode(), MqConstants.PARALLEL_SHARD_COUNT);
String routingKey = MqConstants.PARALLEL_ROUTING_KEY_PREFIX + shard;
rabbitTemplate.convertAndSend(
MqConstants.PARALLEL_EXCHANGE,
routingKey,
event
);
}
}
11.2 串行消费者:严格保证顺序
package com.example.mq.consumer;
import com.example.mq.constant.MqConstants;
import com.example.mq.dto.OrderPaidEvent;
import com.example.mq.service.OrderPaidProcessService;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class SerialOrderPaidConsumer {
private final OrderPaidProcessService processService;
public SerialOrderPaidConsumer(OrderPaidProcessService processService) {
this.processService = processService;
}
@RabbitListener(queues = MqConstants.SERIAL_QUEUE, containerFactory = "serialListenerContainerFactory")
public void onMessage(OrderPaidEvent event, Message message, Channel channel) throws IOException {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
// 严格串行:任何异常都由业务层统一处理
processService.process(event);
channel.basicAck(deliveryTag, false);
} catch (Exception ex) {
// 失败后不重新入队,避免无限循环;交给业务重试和死信兜底
channel.basicNack(deliveryTag, false, false);
}
}
}
11.3 并行消费者:提高吞吐,但保留业务键局部顺序
package com.example.mq.consumer;
import com.example.mq.constant.MqConstants;
import com.example.mq.dto.OrderPaidEvent;
import com.example.mq.service.OrderPaidProcessService;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class ParallelOrderPaidConsumer {
private final OrderPaidProcessService processService;
public ParallelOrderPaidConsumer(OrderPaidProcessService processService) {
this.processService = processService;
}
@RabbitListener(
queues = {
MqConstants.PARALLEL_QUEUE_PREFIX + "0",
MqConstants.PARALLEL_QUEUE_PREFIX + "1",
MqConstants.PARALLEL_QUEUE_PREFIX + "2",
MqConstants.PARALLEL_QUEUE_PREFIX + "3",
MqConstants.PARALLEL_QUEUE_PREFIX + "4",
MqConstants.PARALLEL_QUEUE_PREFIX + "5",
MqConstants.PARALLEL_QUEUE_PREFIX + "6",
MqConstants.PARALLEL_QUEUE_PREFIX + "7"
},
containerFactory = "parallelListenerContainerFactory"
)
public void onMessage(OrderPaidEvent event, Message message, Channel channel) throws IOException {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
// 并行消费:同一个 orderId 始终在同一分片里,所以局部顺序仍然成立
processService.process(event);
channel.basicAck(deliveryTag, false);
} catch (Exception ex) {
channel.basicNack(deliveryTag, false, false);
}
}
}
十二、代码:幂等、重试、死信记录
这部分是最值钱的内容。很多系统“消费失败”不是因为 MQ 不行,而是因为幂等和重试没有设计好。
12.1 消费日志实体
package com.example.mq.entity;
import jakarta.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "consume_log", uniqueConstraints = {
@UniqueConstraint(name = "uk_consume_message_id", columnNames = "message_id")
})
public class ConsumeLog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "message_id", nullable = false, length = 64)
private String messageId;
@Column(name = "status", nullable = false, length = 16)
private String status; // PROCESSING / SUCCESS / FAILED
@Column(name = "retry_count", nullable = false)
private Integer retryCount;
@Column(name = "last_error", length = 2000)
private String lastError;
@Column(name = "created_at", nullable = false)
private LocalDateTime createdAt;
@Column(name = "updated_at", nullable = false)
private LocalDateTime updatedAt;
public Long getId() {
return id;
}
public String getMessageId() {
return messageId;
}
public void setMessageId(String messageId) {
this.messageId = messageId;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public Integer getRetryCount() {
return retryCount;
}
public void setRetryCount(Integer retryCount) {
this.retryCount = retryCount;
}
public String getLastError() {
return lastError;
}
public void setLastError(String lastError) {
this.lastError = lastError;
}
public LocalDateTime getCreatedAt() {
return createdAt;
}
public void setCreatedAt(LocalDateTime createdAt) {
this.createdAt = createdAt;
}
public LocalDateTime getUpdatedAt() {
return updatedAt;
}
public void setUpdatedAt(LocalDateTime updatedAt) {
this.updatedAt = updatedAt;
}
}
12.2 死信实体
package com.example.mq.entity;
import jakarta.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "dead_letter_message")
public class DeadLetterMessage {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "message_id", nullable = false, length = 64)
private String messageId;
@Column(name = "payload", nullable = false, length = 4000)
private String payload;
@Column(name = "reason", nullable = false, length = 2000)
private String reason;
@Column(name = "created_at", nullable = false)
private LocalDateTime createdAt;
public Long getId() {
return id;
}
public String getMessageId() {
return messageId;
}
public void setMessageId(String messageId) {
this.messageId = messageId;
}
public String getPayload() {
return payload;
}
public void setPayload(String payload) {
this.payload = payload;
}
public String getReason() {
return reason;
}
public void setReason(String reason) {
this.reason = reason;
}
public LocalDateTime getCreatedAt() {
return createdAt;
}
public void setCreatedAt(LocalDateTime createdAt) {
this.createdAt = createdAt;
}
}
12.3 仓库接口
package com.example.mq.repository;
import com.example.mq.entity.ConsumeLog;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.Optional;
public interface ConsumeLogRepository extends JpaRepository<ConsumeLog, Long> {
Optional<ConsumeLog> findByMessageId(String messageId);
}
package com.example.mq.repository;
import com.example.mq.entity.DeadLetterMessage;
import org.springframework.data.jpa.repository.JpaRepository;
public interface DeadLetterMessageRepository extends JpaRepository<DeadLetterMessage, Long> {
}
12.4 消费审计服务:幂等入口
package com.example.mq.service;
import com.example.mq.dto.OrderPaidEvent;
import com.example.mq.entity.ConsumeLog;
import com.example.mq.repository.ConsumeLogRepository;
import com.example.mq.repository.DeadLetterMessageRepository;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import jakarta.transaction.Transactional;
import org.springframework.dao.DataIntegrityViolationException;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
@Service
public class MessageAuditService {
private final ConsumeLogRepository consumeLogRepository;
private final DeadLetterMessageRepository deadLetterMessageRepository;
private final ObjectMapper objectMapper;
public MessageAuditService(ConsumeLogRepository consumeLogRepository,
DeadLetterMessageRepository deadLetterMessageRepository,
ObjectMapper objectMapper) {
this.consumeLogRepository = consumeLogRepository;
this.deadLetterMessageRepository = deadLetterMessageRepository;
this.objectMapper = objectMapper;
}
@Transactional
public boolean startConsume(OrderPaidEvent event) {
// 先查再插是为了更容易理解;正式系统中可结合乐观锁/唯一约束/悲观锁进一步加强
return consumeLogRepository.findByMessageId(event.messageId())
.map(log -> {
if ("SUCCESS".equals(log.getStatus())) {
// 已成功消费,直接视为幂等命中
return false;
}
// 如果是 FAILED 或 PROCESSING,可重新标记为 PROCESSING
log.setStatus("PROCESSING");
log.setRetryCount(log.getRetryCount() + 1);
log.setUpdatedAt(LocalDateTime.now());
consumeLogRepository.save(log);
return true;
})
.orElseGet(() -> {
try {
ConsumeLog log = new ConsumeLog();
log.setMessageId(event.messageId());
log.setStatus("PROCESSING");
log.setRetryCount(0);
log.setCreatedAt(LocalDateTime.now());
log.setUpdatedAt(LocalDateTime.now());
consumeLogRepository.saveAndFlush(log);
return true;
} catch (DataIntegrityViolationException ex) {
// 并发重复插入时,唯一键会拦住。再查一次,走幂等判断。
return consumeLogRepository.findByMessageId(event.messageId())
.map(log -> !"SUCCESS".equals(log.getStatus()))
.orElse(false);
}
});
}
@Transactional
public void markSuccess(String messageId) {
consumeLogRepository.findByMessageId(messageId).ifPresent(log -> {
log.setStatus("SUCCESS");
log.setUpdatedAt(LocalDateTime.now());
consumeLogRepository.save(log);
});
}
@Transactional
public void markFailed(String messageId, String reason) {
consumeLogRepository.findByMessageId(messageId).ifPresent(log -> {
log.setStatus("FAILED");
log.setLastError(reason);
log.setUpdatedAt(LocalDateTime.now());
consumeLogRepository.save(log);
});
}
@Transactional
public void saveDeadLetter(OrderPaidEvent event, String reason) {
try {
var dlq = new com.example.mq.entity.DeadLetterMessage();
dlq.setMessageId(event.messageId());
dlq.setPayload(objectMapper.writeValueAsString(event));
dlq.setReason(reason);
dlq.setCreatedAt(LocalDateTime.now());
deadLetterMessageRepository.save(dlq);
} catch (JsonProcessingException e) {
throw new IllegalStateException("死信消息序列化失败", e);
}
}
}
代码解读:
startConsume负责幂等入口;SUCCESS状态表示已经处理完成,重复消息直接跳过;PROCESSING和FAILED可以重新进入处理流程;saveAndFlush配合唯一约束,可以挡住并发重复写入;- 这是一种很常见的“消费日志幂等”方案。
12.5 业务处理服务:重试 + 失败兜底
package com.example.mq.service;
import com.example.mq.dto.OrderPaidEvent;
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Recover;
import org.springframework.retry.annotation.Retryable;
import org.springframework.stereotype.Service;
@Service
public class OrderPaidProcessService {
private final MessageAuditService auditService;
public OrderPaidProcessService(MessageAuditService auditService) {
this.auditService = auditService;
}
public void process(OrderPaidEvent event) {
// 幂等入口:如果已成功处理,直接返回
boolean needProcess = auditService.startConsume(event);
if (!needProcess) {
return;
}
try {
doBusinessWithRetry(event);
auditService.markSuccess(event.messageId());
} catch (Exception ex) {
auditService.markFailed(event.messageId(), ex.getMessage());
throw ex;
}
}
@Retryable(
retryFor = TransientProcessingException.class,
maxAttempts = 3,
backoff = @Backoff(delay = 500, multiplier = 2)
)
public void doBusinessWithRetry(OrderPaidEvent event) {
// 模拟业务逻辑:这里可以替换成订单状态推进、库存扣减、积分发放等逻辑
// 你可以在这里故意抛出异常来观察重试效果
if (event.orderId() % 13 == 0) {
throw new TransientProcessingException("模拟临时故障:下游服务不可用");
}
if (event.orderId() % 17 == 0) {
throw new IllegalArgumentException("模拟永久错误:业务参数非法");
}
// 真正业务逻辑:例如更新订单状态、写审计表、通知下游
System.out.println("处理成功,messageId=" + event.messageId() + ", orderId=" + event.orderId());
}
@Recover
public void recover(TransientProcessingException ex, OrderPaidEvent event) {
// 超过重试次数后进入死信兜底
auditService.saveDeadLetter(event, ex.getMessage());
}
}
12.6 临时异常类
package com.example.mq.service;
public class TransientProcessingException extends RuntimeException {
public TransientProcessingException(String message) {
super(message);
}
}
说明:
@Retryable只对“可重试异常”生效;TransientProcessingException模拟临时故障;IllegalArgumentException代表永久错误,不应重试。
十三、代码:线程池与消费容器的联动调优
13.1 自定义业务线程池
package com.example.mq.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
public class ThreadPoolConfig {
@Bean("mqBusinessExecutor")
public Executor mqBusinessExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(8);
executor.setMaxPoolSize(16);
executor.setQueueCapacity(200);
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("mq-business-");
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setAwaitTerminationSeconds(20);
executor.initialize();
return executor;
}
}
13.2 什么时候需要业务线程池
如果你的监听方法里包含大量阻塞操作,比如:
- 调外部 HTTP 接口;
- 大量数据库访问;
- 文件落盘;
- 复杂聚合计算;
那么你可以考虑把真正耗时的部分移到业务线程池中处理。但一定要注意:
- 不能因为异步化而放弃消息可靠性;
- 不能提前 ACK 导致任务丢失;
- 不能让线程池队列无限增长。
一个更稳妥的方案是:
- 监听线程只做轻量校验和调度;
- 核心业务仍然在可控的事务边界中完成;
- 高耗时、低关键性的任务再异步化。
13.3 容器参数的调优思路
串行消费场景
建议:
concurrentConsumers = 1prefetchCount = 1manual ack
适用于:
- 订单状态机;
- 库存锁定;
- 账务流水。
并行消费场景
建议从:
concurrentConsumers = 4maxConcurrentConsumers = 12prefetchCount = 20
开始压测,再根据实际结果调节。
调优的核心是“看瓶颈”
请重点观察:
- 消费线程是否等待 DB;
- 线程池队列是否不断上涨;
- ACK 是否延迟过高;
- 重试是否明显增加;
- 队列积压是否持续扩大。
如果任何一个指标失控,优先找瓶颈,而不是继续加线程。
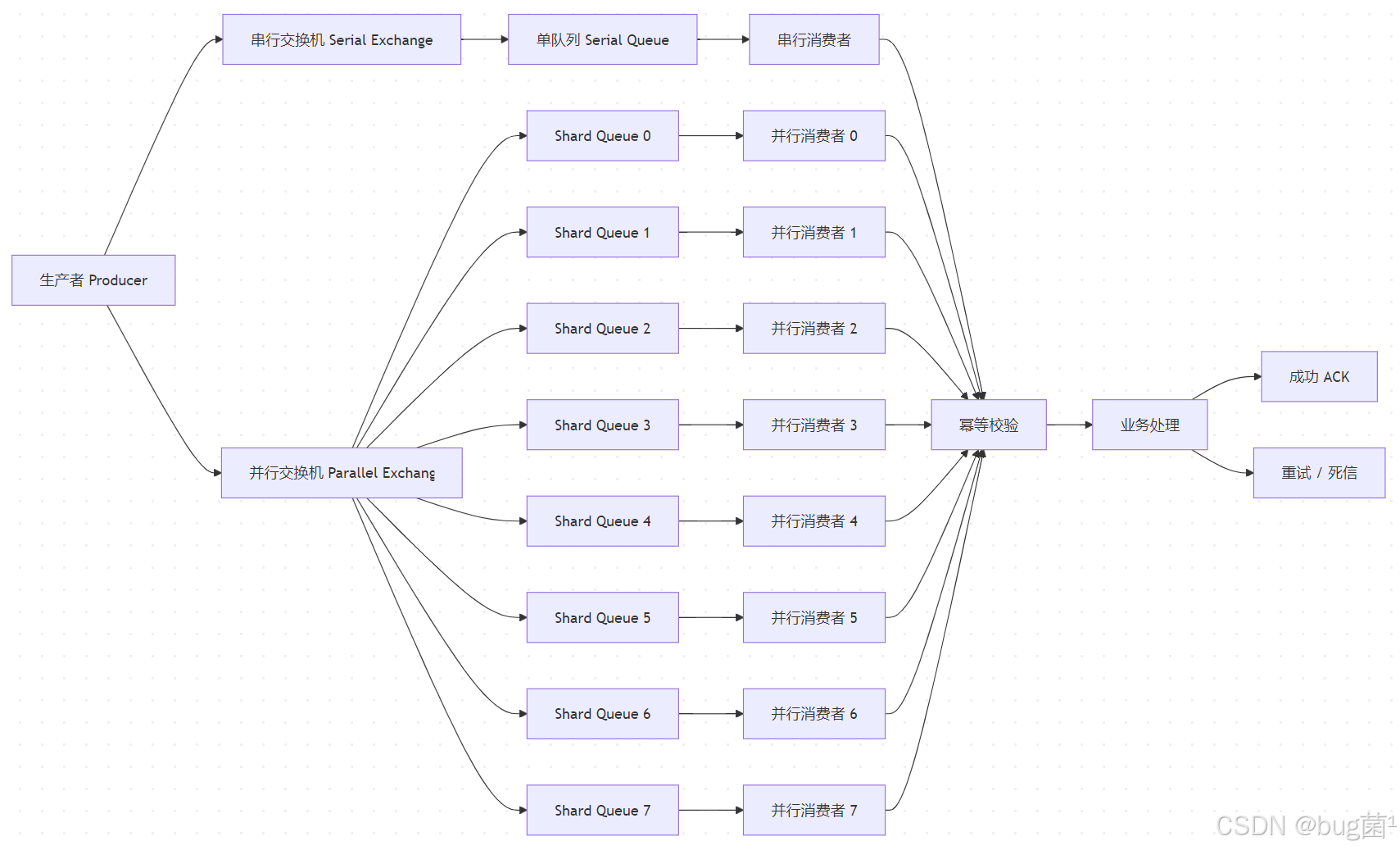
十四、模型图:让设计思路一眼看懂!
14.1 总体架构图
示意图绘制如下,仅供参考:
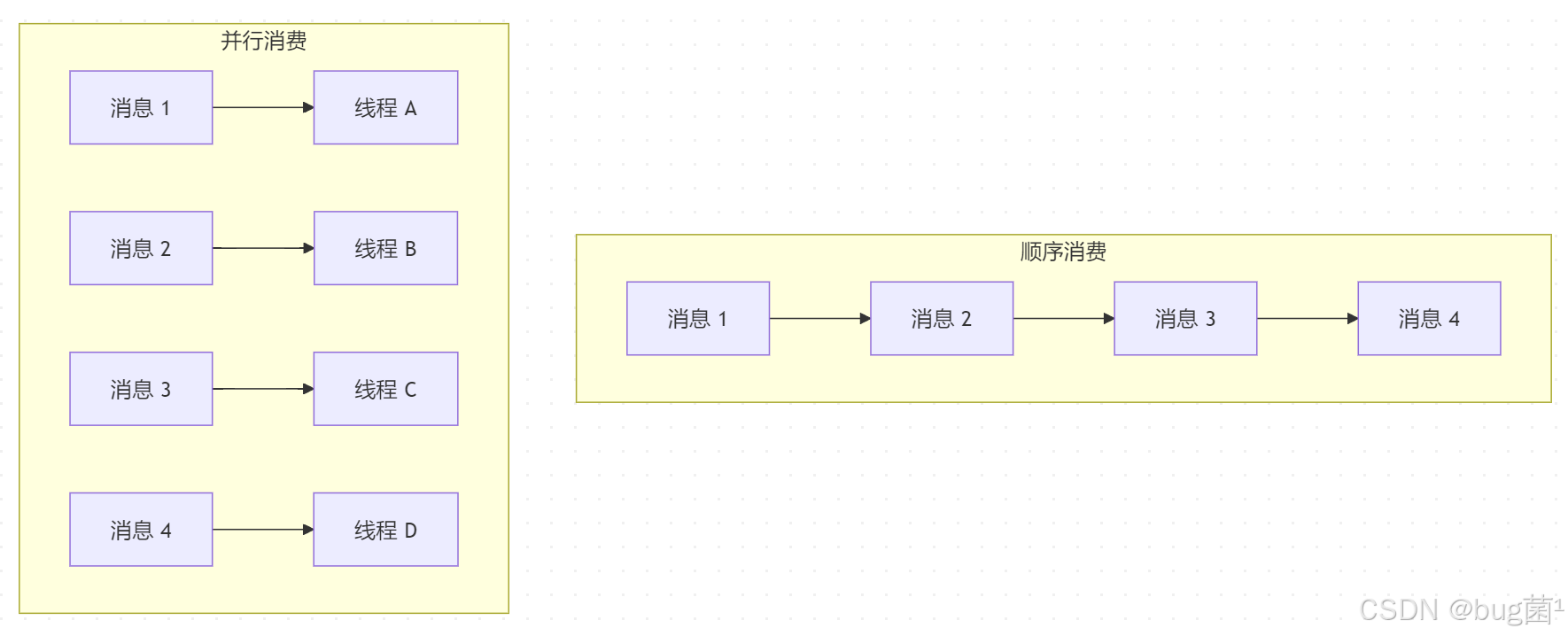
14.2 顺序消费与并行消费对比图
示意图绘制如下,仅供参考:
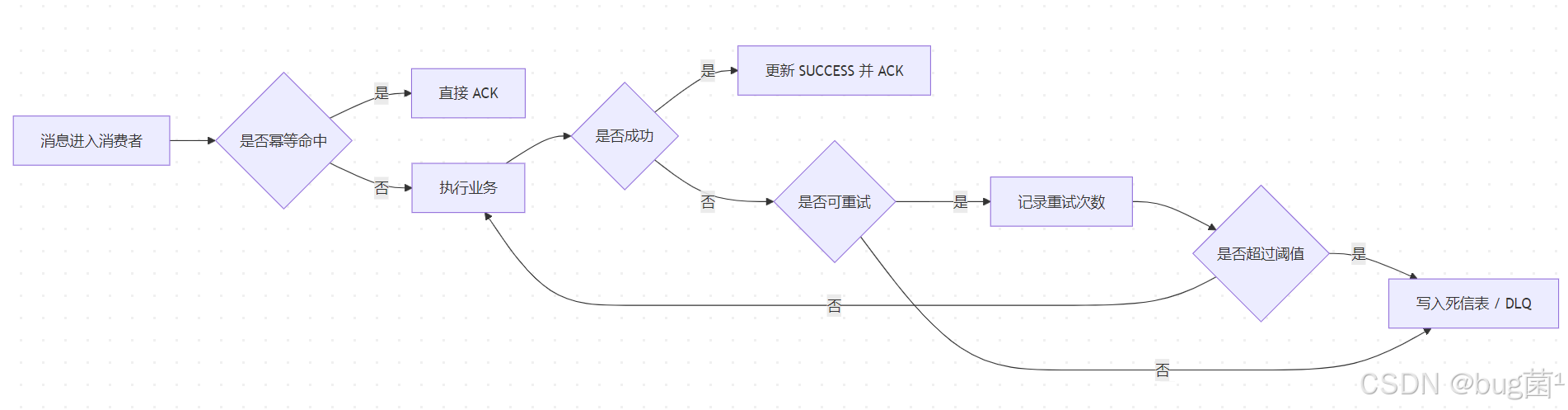
14.3 重试与死信流程图
示意图绘制如下,仅供参考:
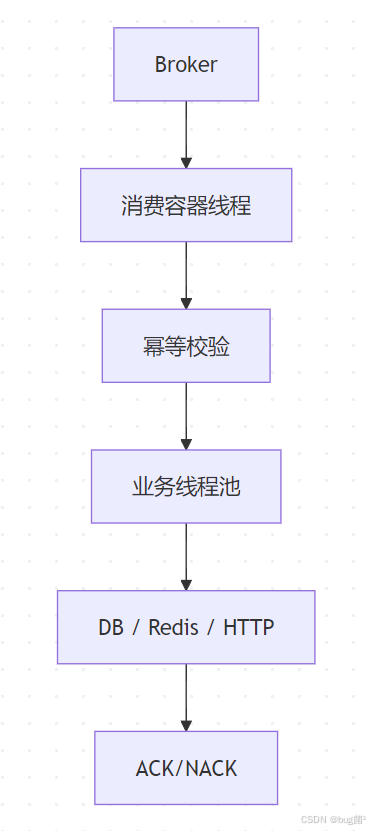
14.4 线程池与容器关系图
示意图绘制如下,仅供参考:
十五、代码解析:为什么这套设计能跑得稳?
15.1 为什么串行消费者只开 1 个线程?
因为串行消费者的目标不是“快”,而是“绝不乱序”。
只要你有以下需求,就应该优先把顺序放在第一位:
- 订单状态流转;
- 账务变更;
- 库存状态;
- 审批节点;
- 任何会被前后消息影响结果的链路。
单线程 + prefetch=1 的组合是最稳妥的基础版本。
15.2 为什么并行消费要做分片?
并行不是把同一条业务链路交给所有线程竞争,而是让不同业务键互不干扰。
分片的价值在于:
- 同一个订单永远在同一个队列;
- 队列内部仍保持顺序;
- 不同队列可并行;
- 吞吐能力随队列数增长;
- 出问题时定位更容易。
这比“一个大队列 + 一堆消费者线程”更可控。
15.3 幂等日志为什么很重要?
没有幂等日志时,你很难回答下面这些问题:
- 这条消息到底处理过没有?
- 如果失败了,是业务失败还是网络失败?
- 这次重试是第几次?
- 失败消息现在去哪了?
有了消费日志后,你至少可以做到:
- 查重;
- 看状态;
- 看重试次数;
- 看失败原因;
- 看是否进入死信。
这对于排障非常关键。
15.4 为什么要把“可重试错误”和“不可重试错误”分开?
因为它们的处理策略完全不同。
- 可重试错误:给系统一点时间,往往会恢复;
- 不可重试错误:无论重试多少次,结果都不会变。
把两者混在一起,只会导致重试风暴或者永久丢单。
十六、常见误区与排障方法
16.1 误区一:并发数越大,吞吐一定越高
不对。
并发到一定程度后,瓶颈会从“线程不足”转为“资源争抢”。
16.2 误区二:失败就无限重试,迟早会成功
不对。
参数错误、数据缺失、状态错误,重试只会浪费资源。
16.3 误区三:只要有 MQ,就不会丢消息
也不对。
如果消费端在 ACK 之前宕机、代码没有幂等、重试和死信又没做好,数据仍然会出问题。
16.4 误区四:线程池调大就能解决积压
不一定。
如果下游是瓶颈,线程池调大只会把更多线程送去排队等待。
16.5 排障优先看什么
建议排查顺序如下:
- 队列是否持续增长;
- 消费端是否报错;
- 重试次数是否升高;
- DB/Redis/HTTP 是否慢;
- 线程池是否打满;
- GC 是否异常;
- ACK 延迟是否过高;
- 是否出现重复消费或顺序错乱。
十七、生产落地建议清单
下面给你一份可以直接拿去做系统设计评审的清单。
17.1 架构层面
- 是否明确了业务是否允许乱序;
- 是否按业务键做了分片;
- 是否区分了核心消息和非核心消息;
- 是否有死信兜底;
- 是否有失败告警;
- 是否做了消费日志。
17.2 代码层面
- 是否手动 ACK;
- 是否在 ACK 前完成关键业务;
- 是否有幂等校验;
- 是否区分可重试异常;
- 是否有
@Recover或 DLQ 处理; - 是否有中文注释和统一 DTO。
17.3 运维层面
- 是否有队列堆积监控;
- 是否有消费延迟监控;
- 是否有错误率监控;
- 是否有线程池监控;
- 是否有下游资源监控;
- 是否定期压测并校准参数。
17.4 调参建议
可以按照这个节奏来:
- 先跑通单线程串行消费;
- 加入幂等与重试;
- 压测确认单线程极限;
- 做分片并行;
- 逐步增加并发;
- 观察下游是否成为新瓶颈;
- 根据指标回调参数。
十八、设计结论
如果你只想记住几句话,那就记住下面这些:
- 并发数不是越大越好,而是越贴近系统真实瓶颈越好。
- 顺序消费和并行消费不是对立关系,而是按业务键做平衡。
- 幂等不是可选项,是 MQ 消费端的底线。
- 重试不是万能药,死信兜底才是最后一道防线。
- 容器线程和业务线程池必须分开思考。
- 参数调优不能拍脑袋,必须看压测和监控。
十九、结语
MQ 消费端并发模型设计,说到底是在做三件事:
- 让系统更快;
- 让系统更稳;
- 让系统在出错时依然可控。
Spring Boot 3.x 给我们提供了非常清晰的工程化基础:
- 现代 Java 语法更简洁;
jakarta.*生态更统一;- Starter、Actuator、Retry、JPA 这些能力组合起来非常适合构建生产级消费端。
但真正决定系统质量的,不是框架本身,而是你如何设计:
- 业务顺序;
- 幂等边界;
- 重试边界;
- 容器边界;
- 线程边界;
- 资源边界。
这篇文章的核心目的,不是教你“把参数调大”,而是让你知道:什么时候该顺序,什么时候该并行,什么时候该重试,什么时候该停止重试。
只要把这些边界想清楚,MQ 消费端就不再是“看天吃饭”的黑盒,而会变成一套可以预测、可以压测、可以优化的工程系统。
…
ok,同学们,本节课就上到这儿,下课~
🧧 学习福利 · 限时开放 🧧
当然,无论你是计算机专业在读学生,还是对编程充满兴趣的入门者,都强烈建议系统学习SpringBoot全体系专栏:👉 「滚雪球学 Spring Boot」;涵盖SpringBoot所有教学内容。
该专栏以“循序渐进 + 实战驱动”为核心理念,从基础到进阶到就业到架构师逐层展开,帮助你快速建立完整的 Spring Boot 技术体系,带你玩转SpringBoot框架。
📌 学习承诺:
通过该专栏,你将能够:
- 快速掌握 Spring Boot 核心开发能力
- 构建完整的后端项目认知体系
- 实现从“入门”到“独立开发”的跃迁
就像“滚雪球”一样,知识不断积累、能力持续放大,实现指数级成长 🚀
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注技术号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G PDF编程电子书、简历模板、技术文章Markdown文档等海量资料。
ps:本文涉及所有源代码,均已上传至Gitee开源,供同学们直接对照学习 Gitee传送门,同时,原创开源不易,欢迎给个star🌟,想体验下被🌟的感jio,非常感谢❗
🫵 Who am I?
我是 bug菌,一名深耕 Java 后端领域数十年的一线研发老兵,曾担任独角兽企业后端技术经理、研发架构师等职位,长期专注于 Java 后端、分布式架构、微服务治理、高并发系统、工程效能与研发管理等方向。
目前活跃于多个主流技术社区,包括:
CSDN|稀土掘金|InfoQ|51CTO|华为云开发者社区|阿里云开发者社区|腾讯云开发者社区|开源中国|博客园|墨天轮 等平台。
曾获得:
- CSDN 博客之星 Top30
- 华为云多年度十佳博主 & 卓越贡献奖
- 掘金多年度人气作者 Top40
- CSDN、掘金、InfoQ、51CTO 等平台签约作者 / 优质作者
截至目前,全网技术内容累计影响读者众多,全网粉丝已超过 30w+。
如果你也关注 Java 后端、架构设计、技术成长、职场进阶与研发管理,欢迎关注我的技术内容合集入口:👉 点击查看 👈️
硬核技术号 「猿圈奇妙屋」 期待你的加入。
这里不仅分享技术干货,也记录一线研发人的成长、踩坑、思考与进阶路径。
愿我们一起打怪升级,在技术路上持续进阶。

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)