Unigram LM 分词算法
一、EM 算法训练 Unigram LM
语料的对数似然函数给定一个语料库C={s1,s2,...,sM},其中每个句子s是一个字符序列。对于每个句子s,我们用T(s)表示它的所有可能分词方式的集合。
在 Unigram 假设下,句子s的概率是它所有可能分词方式的概率之和:
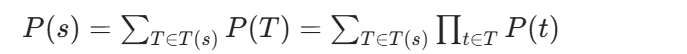
整个语料库的对数似然函数就是所有句子对数概率的和:
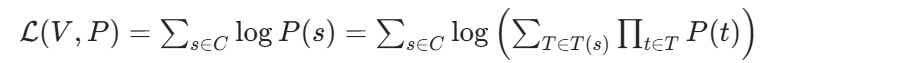
我们的训练目标是:
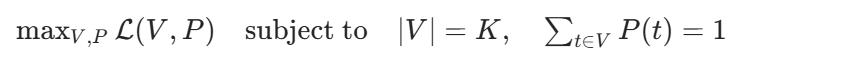
其中K是目标词汇表大小,V是当前词表。
为什么需要 EM 算法?这个优化问题有两个难点:
隐变量存在:我们不知道每个句子的正确分词方式T
组合优化问题:词汇表V是离散的,无法直接用梯度下降求解
E 步:前向 - 后向算法计算期望出现次数
实际实现中,我们使用前向 - 后向算法(Forward-Backward Algorithm),可以在O(nL)的时间复杂度内计算出所有 token 的期望出现次数。
前向算法(Forward Algorithm)定义前向变量α(i)为:句子前i个字符的所有可能分词方式的概率和。
初始化:α(0)=1(空字符串的概率为 1)
递推公式:
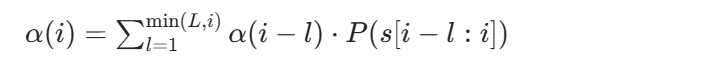
其中L是词汇表中最长 token 的长度,s[i−l:i]表示从位置i−l到i的子串。
后向算法(Backward Algorithm)定义后向变量β(i)为:句子从第i个字符到末尾的所有可能分词方式的概率和。
初始化:β(n)=1(空字符串的概率为 1)
递推公式:
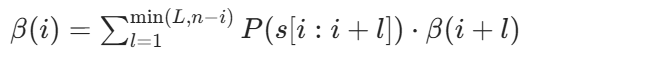
期望出现次数的计算公式有了前向和后向变量,我们可以直接计算 token t在句子s中出现在位置i的概率:
P(t 出现在位置 i∣s)=α(n)α(i)⋅P(t)⋅β(i+∣t∣)
其中∣t∣是 tokent的长度,α(n)就是整个句子的概率P(s)。
然后,token t在句子s中的期望出现次数就是所有位置概率的和:

最后,token t在整个语料中的期望出现次数就是所有句子期望次数的和:
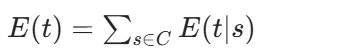
M 步:更新 token 概率M 步的目标是:在给定期望出现次数E(t)的情况下,找到一组新的概率P(t),使得语料的对数似然最大。
构造拉格朗日函数来求解这个带约束的优化问题:
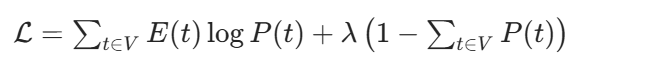
对P(t)求偏导并令其等于 0:

所以最终的更新公式就是: 
token 损失计算的推导 EM 迭代收敛后,我们需要计算每个 token 的损失,以决定删除哪些 token。
损失的精确计算公式tokent的损失定义为:删除 tokent后,语料对数似然的下降量。
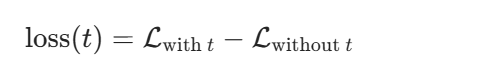
其中: Lwith t:包含 tokent时的语料对数似然
Lwithout t:删除 tokent后的语料对数似然
直接计算这个损失需要对每个 token 都重新运行一次前向算法,时间复杂度是O(∣V∣⋅nL),这在词汇表很大时是不可接受的。
SentencePiece 中的高效近似计算
这个近似基于以下观察:删除一个 tokent对语料对数似然的影响,主要来自于那些包含t的分词方式。近似损失的计算公式:
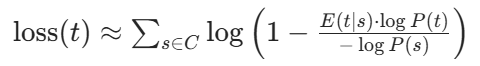 或者更简单的近似(SentencePiece 实际使用的):
或者更简单的近似(SentencePiece 实际使用的):
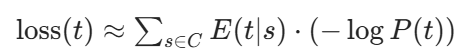 这个近似的直观理解是:
这个近似的直观理解是:
token t的损失等于它在语料中的期望出现次数乘以它的负对数概率。
出现次数多的 token,损失大
概率低的 token(负对数概率大),损失大
SentencePiece 中 EM 算法的实现细节
只迭代 1-2 次 EM:
EM 算法收敛非常快:在 Unigram LM 分词问题中,EM 算法通常在 1-2 次迭代后就已经收敛到了一个很好的局部最优解
后续迭代收益递减:第 3 次及以后的迭代对对数似然的提升非常小(通常小于 0.1%),但会显著增加训练时间
平滑项的具体形式为了防止过拟合和概率为 0 的情况,SentencePiece 在 M 步会添加一个小的加性平滑项:
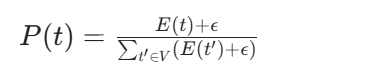
其中ϵ通常设置为10−5。这个平滑项确保了即使一个 token 的期望出现次数为 0,它也不会被分配 0 概率。
初始词汇表构建的详细过程
1.统计语料中所有字符的出现频率
2.按照频率从高到低排序字符
3.选择前C个字符,使得它们的总出现频率达到character_coverage(通常是 0.9995)
4.对于剩下的字符,不加入初始词汇表,而是使用 byte_fallback 处理
5.然后统计所有 1-6 gram 的出现频率
6.过滤掉出现频率低于阈值的 n-gram(通常是 2)
7.将所有单个字符和保留的 n-gram 合并,得到初始词汇表
二. Viterbi 算法
Viterbi 算法解决的是:给定一个句子s和词汇表V,找到概率最大的分词方式T∗。
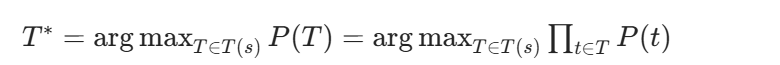
如前所述,我们将其转化为最短路径问题:
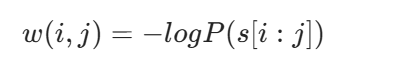
节点:0,1,...,n(n是句子长度) 边:i→j,当且仅当s[i:j]∈V 边权重:w(i,j)=−logP(s[i:j])
目标:找到从0到n的最短路径
Viterbi 的动态规划公式:

|
阶段 |
算法 |
处理方式 |
目的 |
|
训练阶段 |
前向-后向算法 |
把所有切法都加起来 |
估计每个 token 的期望出现次数 |
|
使用阶段 |
Viterbi 算法 |
只找概率最大的一种切法 |
输出最终分词结果 |
边界条件处理
Viterbi 算法的正确性完全依赖于边界条件的严谨处理,任何疏漏都会导致分词错误或程序崩溃。以下是三个必须正确处理的边界情况:
无法到达的位置
- 问题描述:在状态转移过程中,某些位置
i可能没有任何分词方式能够到达,此时dp[i]会保持初始值∞。 - 处理方式:在遍历每个位置
i时,首先检查dp[i]是否为∞。如果是,直接跳过该位置,不进行任何状态转移。
无法分词的异常情况
- 问题描述:在回溯阶段,如果发现
prev[current] = -1,说明从位置current无法回溯到起点。这通常发生在词汇表中缺少某个字符,或者句子包含无法识别的符号时。 - 处理方式:采用 "回退到单个字符" 的策略。当遇到无法回溯的位置时,强制将当前字符作为一个单独的 token,然后继续回溯。
byte_fallback 机制的集成
- 问题描述:当开启
byte_fallback=True时,词汇表中包含 256 个 UTF-8 字节 token。对于不在词汇表中的字符,需要将其拆分为对应的字节 token 进行处理。 - 处理方式:在 Viterbi 算法中增加一个特殊分支。如果一个子串不在词汇表中,检查它是否是一个单个字符。如果是,将其拆分为 UTF-8 字节,然后使用字节 token 的概率进行计算。
Viterbi 算法的性能优化技巧
Viterbi 算法的时间复杂度为O(nL),其中n是句子长度,L是最长 token 长度。在处理长文本或大词汇表时,可以通过以下技巧进一步提升性能:
前缀树(Trie)加速查找
- 问题:使用哈希表判断子串是否在词汇表中,每次查找都需要创建一个字符串对象,开销较大。
- 优化:将词汇表存储在一个前缀树中。在状态转移时,从当前位置
i开始,沿着前缀树的边逐个字符匹配,直到无法继续为止。 - 效果:可以将查找时间从O(L)降低到O(1)(平均情况),并且避免了创建大量临时字符串。
提前终止剪枝
- 问题:在状态转移过程中,某些位置
i的dp[i]值已经非常大,即使加上最小可能的 token 成本,也无法超过当前已经找到的最优路径。 - 优化:预先计算词汇表中所有 token 的最小负对数概率
min_cost。在处理位置i时,如果dp[i] + min_cost >= dp[n],则可以提前终止对该位置的处理。 - dp[n] 当前已经找到的完整分词路径的总代价。
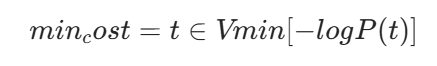 词表里所有 token 中,最小的 token 代价。
词表里所有 token 中,最小的 token 代价。 - 效果:在处理长句子时,可以显著减少需要处理的位置数量。
并行化处理
- 问题:Viterbi 算法的状态转移是顺序执行的,无法直接并行化。
- 优化:虽然状态转移本身是顺序的,但可以将长文本分割成多个独立的句子,然后并行处理每个句子。此外,在处理单个句子时,对于每个位置
i,可以并行检查所有可能的 token 长度l。 - 效果:在多核 CPU 上,可以获得接近线性的加速比。
三、常见误区
1. 为什么 Unigram LM 的 token 概率和为 1,但同一句子的所有分词方式概率和不为 1?
这是理解 Unigram LM 最关键的一个误区。Unigram LM 是一个生成式语言模型,它的概率归一化是针对所有可能的 token 序列,而不是针对同一个句子的不同分词方式。它假设文本是通过以下随机过程生成的:
- 从词汇表中随机选择一个 token,概率为P(t)
- 重复步骤 1,直到生成一个终止符(或达到最大长度)
在这个生成过程中:
- 所有可能的 token 序列(包括不同长度的句子)的概率之和为 1
- 同一个句子的不同分词方式只是所有可能序列中的一个子集,它们的概率之和自然不为 1
这就是为什么我们在计算句子概率时,需要对所有可能的分词方式求和:P(s)=T∈T(s)∑P(T)
2. 为什么训练过程中永远不删除单个字符 token?
这是 Unigram LM 分词器的一个基本设计原则,目的是保证分词器的完备性。
- 如果我们删除了某个单个字符 token,那么任何包含这个字符的句子都无法被正确分词
- 即使这个字符非常生僻,我们也必须保留它,或者使用 byte_fallback 机制来处理它
- 在 SentencePiece 的实现中,单个字符 token 会被标记为 "不可删除",在计算损失和删除 token 时会被自动跳过

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)