重磅首发!混凝土材料领域再创新高度!开启智能建造新纪元!
重磅首发!混凝土材料领域再创新高度!开启智能建造新纪元!![]() https://mp.weixin.qq.com/s/XJV2RTYWTalEiIBcKI1orA点此链接查看详情!
https://mp.weixin.qq.com/s/XJV2RTYWTalEiIBcKI1orA点此链接查看详情!
机器学习与混凝土性能预测
学习目标
本课程的主要目标是帮助学员建立“混凝土材料问题—数据集构建—机器学习建模—性能预测—模型解释—配合比优化—论文表达”的完整研究思路。
通过本课程学习,学员将能够理解机器学习在混凝土设计和性能预测中的基本原理,掌握混凝土数据集的构建、清洗、标准化和特征选择方法,能够使用线性回归、决策树、随机森林、支持向量机、XGBoost和神经网络等模型预测混凝土性能。同时,学员还将学习如何使用交叉验证、网格搜索、随机搜索和Optuna等方法进行模型调参,如何利用SHAP等可解释性方法分析模型结果,并进一步掌握机器学习辅助混凝土配合比优化和论文结果表达的方法。
课程结束后,学员应能够独立完成一个混凝土性能预测案例,包括数据处理、模型训练、结果评价、图表绘制和论文分析文字撰写。
讲师介绍
来自国内重点高校,长期从事人工智能、机器学习与土木工程材料及结构检测交叉领域研究,研究方向涵盖混凝土性能预测、智能配合比设计、结构健康监测、无损检测、信号处理、深度学习及数字孪生等。近年来,围绕混凝土材料性能建模、工程结构状态评估与智能检测方法开展了系统研究,在多个国际高水平期刊发表 SCI 论文多篇,具有扎实的理论基础和丰富的科研实践经验。他的授课方式注重理论与工程案例结合,能够将复杂的机器学习方法、混凝土设计问题和检测分析流程讲解得清晰易懂
培训对象
本课程适合土木工程、建筑材料、结构工程、智能建造、材料科学与工程、道路工程、桥梁工程、隧道工程、水利工程以及相关交叉学科领域的研究生、科研人员、高校教师和工程技术人员参加。 课程也适合正在从事高性能混凝土、低碳混凝土、再生混凝土、纤维增强混凝土、地聚物混凝土、纳米改性水泥基材料、混凝土耐久性、结构健康监测和智能建造研究的人员学习。对于希望将人工智能方法用于SCI论文写作、基金申请、工程数据分析和材料设计优化的学员,本课程也具有较强的实用价值。
第一天:混凝土数据基础、工具环境与机器学习入门
上午
·使学员理解混凝土性能预测为什么需要机器学习方法。
·使学员明确混凝土抗压强度预测是一个监督学习中的回归问题。
·使学员理解输入变量X、输出变量Y、样本、特征和标签等基本概念。
·使学员掌握Python、Anaconda和Jupyter Notebook的基本操作。
·使学员了解NumPy、Pandas、Matplotlib和Scikit-learn等常用库的基本用途。
·使学员能够读取混凝土数据集,并完成数据查看、统计分析和缺失值检查。
·使学员能够完成训练集、测试集划分和标准化处理。
下午
·理解线性回归模型的基本思想;
·知道什么是损失函数;
·理解过拟合和正则化的基本概念;
·掌握Ridge、Lasso、ElasticNet 的区别;
·能够用Python 建立四种线性模型;
·能够用R^2、MAE、MSE、RMSE 评价预测结果;
·能够比较不同线性模型在混凝土抗压强度预测中的表现。
第二天 经典非线性机器学习模型在混凝土设计预测中的应用
第二天的主要目标是让学生从第一天的线性模型进一步过渡到非线性机器学习模型。本日课程介绍混凝土设计预测中常用的经典非线性机器学习模型,包括 KNN、SVM/SVR、Random Forest 和 AdaBoost。上午部分重点讲解 KNN 的邻近样本预测思想、距离度量和标准化要求,以及 SVR 的 ε-不敏感损失函数、支持向量和核函数方法。下午部分重点介绍 Random Forest 和 AdaBoost 两类集成学习模型,讲解 Bagging、Boosting、随机采样、特征随机选择和样本权重更新等核心概念。结合混凝土抗压强度预测案例,学生将完成数据处理、模型训练、性能评价和结果对比,并理解不同模型在混凝土配合比设计与强度预测中的适用性、优势和局限。
·理解非线性模型在混凝土抗压强度预测中的必要性;
·掌握 KNN、AdaBoost、Random Forest 和 SVM 的基本原理;
·理解不同模型对数据标准化、参数设置和过拟合控制的要求;
·能够使用 Python 建立四类经典机器学习回归模型;
·能够使用R^2、MAE、MSE、RMSE 对模型进行评价;
·能够比较线性模型与非线性模型的预测性能;
·能够从工程角度解释不同模型的优点与局限。
上午
非线性机器学习模型概述,涉及模型:KNN, SVM/SVR , Random Forest, AdaBoost
·KNN 的邻近样本预测思想;欧氏距离与样本相似性;邻居数量 K 的选择;标准化对 KNN 的影响;KNN 在混凝土抗压强度预测中的实操;KNN 模型的优点与局限.
·SVM 与 SVR 的区别; -不敏感损失函数;支持向量的概念;线性核、多项式核和 RBF 核;参数、、 的作用; SVR 在混凝土抗压强度预测中的实操;SVR 模型的优点与局限
下午
·决策树基本思想回顾;Bagging 集成学习方法;随机采样与特征随机选择;多棵树平均预测机制主要参数:n_estimators、max_depth、max_features特征重要性分析;Random Forest 在混凝土强度预测中的实操Random Forest 模型的优点与局限
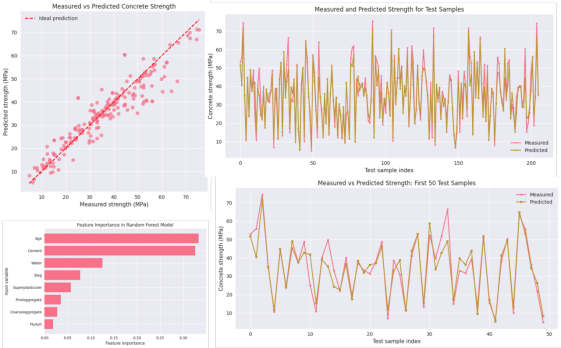
·AdaBoost 回归模型原理;参数 n_estimators 和 learning_rate 的作用;AdaBoost 在混凝土强度预测中的实操;AdaBoost 与 Random Forest 的结果比较
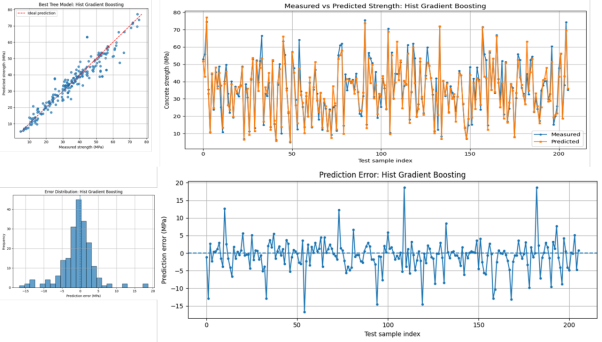
第三天:神经网络、集成学习、超参数优化与可解释性分析
本日课程围绕混凝土设计预测中的高级机器学习建模方法展开,重点介绍 MLP 神经网络、集成学习方法、贝叶斯优化超参数调优以及 SHAP 可解释性分析。课程以混凝土抗压强度预测为主线,讲解如何进一步提高模型预测性能,并分析模型如何利用混凝土配合比变量进行预测。
·理解MLP 神经网络在混凝土性能预测中的基本建模思想;
·掌握神经网络中的输入层、隐藏层、输出层、激活函数和损失函数;
·理解集成学习如何提高模型稳定性和预测精度;
·掌握贝叶斯优化在超参数调优中的基本作用;
·理解SHAP 方法在机器学习模型解释中的意义;
·能够使用Python 建立 MLP 和集成模型;
·能够利用贝叶斯优化搜索较优超参数组合;
·能够利用SHAP 分析混凝土配合比变量对预测结果的贡献。
上午
·MLP: 基础理论;人工神经网络基本结构;输入层、隐藏层与输出层;激活函数与损失函数;反向传播与模型训练;MLP 回归模型; 神经网络在小样本混凝土数据中的注意事项
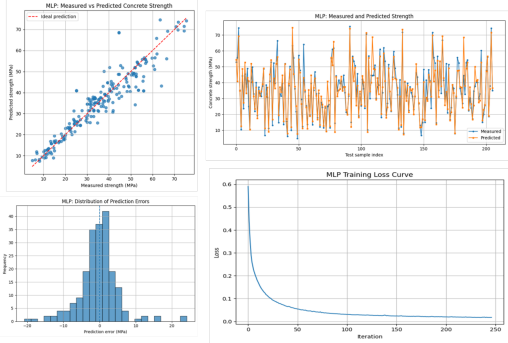
·集成学习:单模型与集成模型的区别;’Bagging 思想;Boosting 思想; Stacking 思想; Voting/Averaging 集成方法;集成学习在混凝土强度预测中的优势;集成模型的预测结果比较
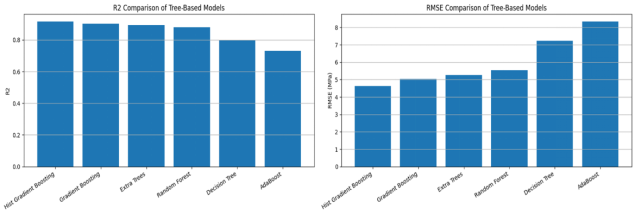
下午
·超参数优化:超参数与模型参数的区别;手动调参的问题;Grid Search 与 Random Search;Bayesian Optimization 的基本思想;代理模型与采集函数;使用贝叶斯优化调节 MLP、Random Forest 或 SVR;优化前后模型性能对比。
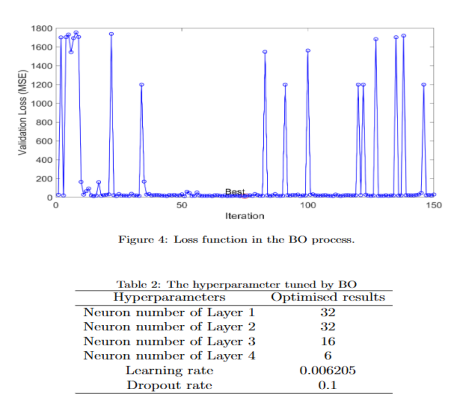
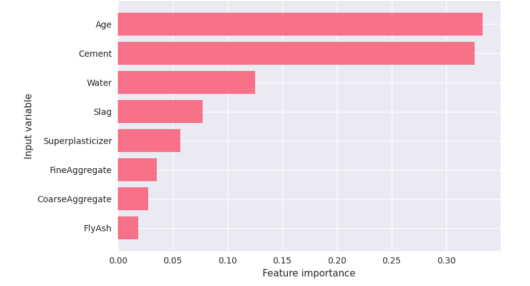
·可解释分析:全局特征重要性分析;单个样本预测解释;特征影响方向分析
;特征交互作用分析;SHAP 结果的工程解释。
第四天物理驱动神经网络介绍;论文复现;Q&A
上午
·解释PINNs 的基本思想;区分数据驱动模型和物理约束模型;说明 PINNs 损失函数的组成;理解物理残差、边界条件和初始条件在模型训练中的作用;
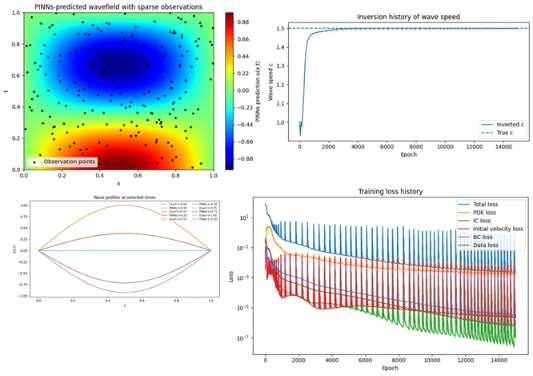
·论文复现
Jai Srivastava & Tushar Bansal. Smart monitoring of nano-engineered concrete via piezoelectric sensors and EMI technique. Nondestructive Testing and Evaluation 0:0, pages 1-30.
下午
·论文复现 Tipu, R.K., Rathi, P., Pandya, K.S. and Panchal, V.R., 2025. Optimizing sustainable blended concrete mixes using deep learning and multi-objective optimization. Scientific Reports, 15(1), p.16356.
·提问交流

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)