【AI大数据工程师特训笔记】第03讲:运算符
目录
第一章 Schema 与 SQL 查询关键字
1.1 Schema 基础
Schema 是数据库内部的“命名空间”,用于组织数据库对象(如表、视图、函数等)。每个数据库都有一个默认的public schema。
1.1.1 创建 Schema
-- 创建schema(所有者默认为当前用户)
CREATE SCHEMA hr;
-- 条件创建(避免重复报错)
CREATE SCHEMA IF NOT EXISTS sales;
-- 指定所有者
CREATE SCHEMA finance AUTHORIZATION postgres;1.1.2 修改 Schema
-- 重命名schema
ALTER SCHEMA hr RENAME TO human_resources;
-- 修改所有者
ALTER SCHEMA human_resources OWNER TO admin; -- 注意:需要先创建一个admin账户才能执行这行SQL1.1.3 删除 Schema
-- 删除空schema
DROP SCHEMA human_resources;
-- 级联删除(删除schema及其所有对象)
DROP SCHEMA finance CASCADE;
-- 安全删除
DROP SCHEMA IF EXISTS temp_schema;1.1.4 访问路径 search_path
search_path决定 PostgreSQL 查找对象的顺序。
-- 查看当前search_path
SHOW search_path;
-- 设置search_path
SET search_path = hr, public;
-- 永久设置(针对当前数据库)
ALTER DATABASE mydb SET search_path = hr, public; -- 注意:需要先创建数据库才能设置1.1.5 实践案例:创建完整的练习环境
-- 创建hr schema
CREATE SCHEMA IF NOT EXISTS hr;
-- 创建departments表
CREATE TABLE hr.departments (
department_id INTEGER PRIMARY KEY,
department_name VARCHAR(100) NOT NULL,
manager_id INTEGER,
location_id INTEGER
);
-- 创建employees表
CREATE TABLE hr.employees (
employee_id INTEGER PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
phone_number VARCHAR(20),
hire_date DATE NOT NULL,
job_id VARCHAR(20),
salary NUMERIC(10,2),
commission_pct NUMERIC(3,2),
manager_id INTEGER,
department_id INTEGER
);
-- 插入部门数据
INSERT INTO hr.departments (department_id, department_name, manager_id, location_id) VALUES
(10, 'Administration', 200, 1700),
(20, 'Marketing', 201, 1800),
(30, 'Purchasing', 114, 1700),
(40, 'Human Resources', 203, 2400),
(50, 'Shipping', 121, 1500),
(60, 'IT', 103, 1400),
(70, 'Public Relations', 204, 2700),
(80, 'Sales', 145, 2500),
(90, 'Executive', 100, 1700),
(100, 'Finance', 108, 1700);
-- 插入员工数据(仅展示部分,完整数据见前文)
INSERT INTO hr.employees (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id) VALUES
(100, 'Steven', 'King', 'SKING', '515.123.4567', '2003-06-17', 'AD_PRES', 24000.00, NULL, NULL, 90),
(101, 'Neena', 'Kochhar', 'NKOCHHAR', '515.123.4568', '2005-09-21', 'AD_VP', 17000.00, NULL, 100, 90),
(102, 'Lex', 'De Haan', 'LDEHAAN', '515.123.4569', '2001-01-13', 'AD_VP', 17000.00, NULL, 100, 90);
(103, 'Alexander', 'Hunold', 'AHUNOLD', '590.423.4567', '2006-01-03', 'IT_PROG', 9000.00, NULL, 102, 60),
(104, 'Bruce', 'Ernst', 'BERNST', '590.423.4568', '2007-05-21', 'IT_PROG', 6000.00, NULL, 103, 60),
(105, 'David', 'Austin', 'DAUSTIN', '590.423.4569', '2005-06-25', 'IT_PROG', 4800.00, NULL, 103, 60),
(106, 'Valli', 'Pataballa', 'VPATABAL', '590.423.4560', '2006-02-05', 'IT_PROG', 4800.00, NULL, 103, 60),
(107, 'Diana', 'Lorentz', 'DLORENTZ', '590.423.5567', '2007-02-07', 'IT_PROG', 4200.00, NULL, 103, 60),
(108, 'Nancy', 'Greenberg', 'NGREENBE', '515.124.4569', '2002-08-17', 'FI_MGR', 12000.00, NULL, 101, 100),
(109, 'Daniel', 'Faviet', 'DFAVIET', '515.124.4169', '2002-08-16', 'FI_ACCOUNT', 9000.00, NULL, 108, 100),
(110, 'John', 'Chen', 'JCHEN', '515.124.4269', '2005-09-28', 'FI_ACCOUNT', 8200.00, NULL, 108, 100),
(111, 'Ismael', 'Sciarra', 'ISCIARRA', '515.124.4369', '2005-09-30', 'FI_ACCOUNT', 7700.00, NULL, 108, 100),
(112, 'Jose Manuel', 'Urman', 'JURMAN', '515.124.4469', '2006-03-07', 'FI_ACCOUNT', 7800.00, NULL, 108, 100),
(113, 'Luis', 'Popp', 'LPOPP', '515.124.4567', '2007-12-07', 'FI_ACCOUNT', 6900.00, NULL, 108, 100),
(114, 'Den', 'Raphaely', 'DRAPHEAL', '515.127.4561', '2002-12-07', 'PU_MAN', 11000.00, NULL, 100, 30),
(115, 'Alexander', 'Khoo', 'AKHOO', '515.127.4562', '2003-05-18', 'PU_CLERK', 3100.00, NULL, 114, 30),
(116, 'Shelli', 'Baida', 'SBAIDA', '515.127.4563', '2005-12-24', 'PU_CLERK', 2900.00, NULL, 114, 30),
(117, 'Sigal', 'Tobias', 'STOBIAS', '515.127.4564', '2005-07-24', 'PU_CLERK', 2800.00, NULL, 114, 30),
(118, 'Guy', 'Himuro', 'GHIMURO', '515.127.4565', '2006-11-15', 'PU_CLERK', 2600.00, NULL, 114, 30),
(119, 'Karen', 'Colmenares', 'KCOLMENA', '515.127.4566', '2007-08-10', 'PU_CLERK', 2500.00, NULL, 114, 30),
(120, 'Matthew', 'Weiss', 'MWEISS', '650.123.1234', '2004-07-18', 'ST_MAN', 8000.00, NULL, 100, 50),
(121, 'Adam', 'Fripp', 'AFRIPP', '650.123.2234', '2005-04-10', 'ST_MAN', 8200.00, NULL, 100, 50),
(122, 'Payam', 'Kaufling', 'PKAUFLIN', '650.123.3234', '2003-05-01', 'ST_MAN', 7900.00, NULL, 100, 50),
(123, 'Shanta', 'Vollman', 'SVOLLMAN', '650.123.4234', '2005-10-10', 'ST_MAN', 6500.00, NULL, 100, 50),
(124, 'Kevin', 'Mourgos', 'KMOURGOS', '650.123.5234', '2007-11-16', 'ST_MAN', 5800.00, NULL, 100, 50),
(125, 'Julia', 'Nayer', 'JNAYER', '650.124.1214', '2005-07-16', 'ST_CLERK', 3200.00, NULL, 120, 50),
(126, 'Irene', 'Mikkilineni', 'IMIKKILI', '650.124.1224', '2006-09-28', 'ST_CLERK', 2700.00, NULL, 120, 50),
(127, 'James', 'Landry', 'JLANDRY', '650.124.1334', '2007-01-14', 'ST_CLERK', 2400.00, NULL, 120, 50),
(128, 'Steven', 'Markle', 'SMARKLE', '650.124.1434', '2008-03-08', 'ST_CLERK', 2200.00, NULL, 120, 50),
(129, 'Laura', 'Bissot', 'LBISSOT', '650.124.5234', '2005-08-20', 'ST_CLERK', 3300.00, NULL, 121, 50),
(130, 'Mozhe', 'Atkinson', 'MATKINSO', '650.124.6234', '2005-10-30', 'ST_CLERK', 2800.00, NULL, 121, 50),
(131, 'James', 'Marlow', 'JAMRLOW', '650.124.7234', '2005-02-16', 'ST_CLERK', 2500.00, NULL, 121, 50),
(132, 'TJ', 'Olson', 'TJOLSON', '650.124.8234', '2007-04-10', 'ST_CLERK', 2100.00, NULL, 121, 50),
(133, 'Jason', 'Mallin', 'JMALLIN', '650.127.1934', '2004-06-14', 'ST_CLERK', 3300.00, NULL, 122, 50),
(134, 'Michael', 'Rogers', 'MROGERS', '650.127.1834', '2006-08-26', 'ST_CLERK', 2900.00, NULL, 122, 50),
(135, 'Ki', 'Gee', 'KGEE', '650.127.1734', '2007-12-12', 'ST_CLERK', 2400.00, NULL, 122, 50),
(136, 'Hazel', 'Philtanker', 'HPHILTAN', '650.127.1634', '2008-02-06', 'ST_CLERK', 2200.00, NULL, 122, 50),
(137, 'Renske', 'Ladwig', 'RLADWIG', '650.121.1234', '2003-07-14', 'ST_CLERK', 3600.00, NULL, 123, 50),
(138, 'Stephen', 'Stiles', 'SSTILES', '650.121.2034', '2005-10-26', 'ST_CLERK', 3200.00, NULL, 123, 50),
(139, 'John', 'Seo', 'JSEO', '650.121.2019', '2006-02-12', 'ST_CLERK', 2700.00, NULL, 123, 50),
(140, 'Joshua', 'Patel', 'JPATEL', '650.121.1834', '2006-04-06', 'ST_CLERK', 2500.00, NULL, 123, 50),
(141, 'Trenna', 'Rajs', 'TRAJS', '650.121.8009', '2003-10-17', 'ST_CLERK', 3500.00, NULL, 124, 50),
(142, 'Curtis', 'Davies', 'CDAVIES', '650.121.2994', '2005-01-29', 'ST_CLERK', 3100.00, NULL, 124, 50),
(143, 'Randall', 'Matos', 'RMATOS', '650.121.2874', '2006-03-15', 'ST_CLERK', 2600.00, NULL, 124, 50),
(144, 'Peter', 'Vargas', 'PVARGAS', '650.121.2004', '2006-07-09', 'ST_CLERK', 2500.00, NULL, 124, 50),
(145, 'John', 'Russell', 'JRUSSEL', '011.44.1344.429268', '2004-10-01', 'SA_MAN', 14000.00, 0.4, 100, 80),
(146, 'Karen', 'Partners', 'KPARTNER', '011.44.1344.467268', '2005-01-05', 'SA_MAN', 13500.00, 0.3, 100, 80),
(147, 'Alberto', 'Errazuriz', 'AERRAZUR', '011.44.1344.429278', '2005-03-10', 'SA_MAN', 12000.00, 0.3, 100, 80),
(148, 'Gerald', 'Cambrault', 'GCAMBRAU', '011.44.1344.619268', '2007-10-15', 'SA_MAN', 11000.00, 0.3, 100, 80),
(149, 'Eleni', 'Zlotkey', 'EZLOTKEY', '011.44.1344.429018', '2008-01-29', 'SA_MAN', 10500.00, 0.2, 100, 80),
(150, 'Peter', 'Tucker', 'PTUCKER', '011.44.1344.129268', '2005-01-30', 'SA_REP', 10000.00, 0.3, 145, 80),
(151, 'David', 'Bernstein', 'DBERNSTE', '011.44.1344.345268', '2005-03-24', 'SA_REP', 9500.00, 0.25, 145, 80),
(152, 'Peter', 'Hall', 'PHALL', '011.44.1344.478968', '2005-08-20', 'SA_REP', 9000.00, 0.25, 145, 80),
(153, 'Christopher', 'Olsen', 'COLSEN', '011.44.1344.498718', '2006-03-30', 'SA_REP', 8000.00, 0.2, 145, 80),
(154, 'Nanette', 'Cambrault', 'NCAMBRAU', '011.44.1344.987668', '2006-12-09', 'SA_REP', 7500.00, 0.2, 145, 80),
(155, 'Oliver', 'Tuvault', 'OTUVAULT', '011.44.1344.486508', '2007-11-15', 'SA_REP', 7000.00, 0.15, 145, 80),
(156, 'Janette', 'King', 'JKING', '011.44.1345.429268', '2004-01-30', 'SA_REP', 10000.00, 0.35, 146, 80),
(157, 'Patrick', 'Sully', 'PSULLY', '011.44.1345.929268', '2004-03-04', 'SA_REP', 9500.00, 0.35, 146, 80),
(158, 'Allan', 'McEwen', 'AMCEWEN', '011.44.1345.829268', '2004-08-01', 'SA_REP', 9000.00, 0.35, 146, 80),
(159, 'Lindsey', 'Smith', 'LSMITH', '011.44.1345.729268', '2005-03-10', 'SA_REP', 8000.00, 0.3, 146, 80),
(160, 'Louise', 'Doran', 'LDORAN', '011.44.1345.629268', '2005-12-15', 'SA_REP', 7500.00, 0.3, 146, 80),
(161, 'Sarath', 'Sewall', 'SSEWALL', '011.44.1345.529268', '2006-11-03', 'SA_REP', 7000.00, 0.25, 146, 80),
(162, 'Clara', 'Vishney', 'CVISHNEY', '011.44.1346.129268', '2005-11-11', 'SA_REP', 10500.00, 0.25, 147, 80),
(163, 'Danielle', 'Greene', 'DGREENE', '011.44.1346.229268', '2007-03-19', 'SA_REP', 9500.00, 0.15, 147, 80),
(164, 'Mattea', 'Marvins', 'MMARVINS', '011.44.1346.329268', '2008-01-24', 'SA_REP', 7200.00, 0.1, 147, 80),
(165, 'David', 'Lee', 'DLEE', '011.44.1346.529268', '2008-02-23', 'SA_REP', 6800.00, 0.1, 147, 80),
(166, 'Sundar', 'Ande', 'SANDE', '011.44.1346.629268', '2008-03-24', 'SA_REP', 6400.00, 0.1, 147, 80),
(167, 'Amit', 'Banda', 'ABANDA', '011.44.1346.729268', '2008-04-21', 'SA_REP', 6200.00, 0.1, 147, 80),
(168, 'Lisa', 'Ozer', 'LOZER', '011.44.1343.929268', '2005-03-11', 'SA_REP', 11500.00, 0.25, 148, 80),
(169, 'Harrison', 'Bloom', 'HBLOOM', '011.44.1343.829268', '2006-03-23', 'SA_REP', 10000.00, 0.2, 148, 80),
(170, 'Tayler', 'Fox', 'TFOX', '011.44.1343.729268', '2006-01-24', 'SA_REP', 9600.00, 0.2, 148, 80),
(171, 'William', 'Smith', 'WSMITH', '011.44.1343.629268', '2007-02-23', 'SA_REP', 7400.00, 0.15, 148, 80),
(172, 'Elizabeth', 'Bates', 'EBATES', '011.44.1343.529268', '2007-03-24', 'SA_REP', 7300.00, 0.15, 148, 80),
(173, 'Sundita', 'Kumar', 'SKUMAR', '011.44.1343.329268', '2008-04-21', 'SA_REP', 6100.00, 0.1, 148, 80),
(174, 'Ellen', 'Abel', 'EABEL', '011.44.1644.429267', '2004-05-11', 'SA_REP', 11000.00, 0.3, 149, 80),
(175, 'Alyssa', 'Hutton', 'AHUTTON', '011.44.1644.429266', '2005-03-19', 'SA_REP', 8800.00, 0.25, 149, 80),
(176, 'Jonathon', 'Taylor', 'JTAYLOR', '011.44.1644.429265', '2006-03-24', 'SA_REP', 8600.00, 0.2, 149, 80),
(177, 'Jack', 'Livingston', 'JLIVINGS', '011.44.1644.429264', '2006-04-23', 'SA_REP', 8400.00, 0.2, 149, 80),
(178, 'Kimberely', 'Grant', 'KGRANT', '011.44.1644.429263', '2007-05-24', 'SA_REP', 7000.00, 0.15, 149, NULL),
(179, 'Charles', 'Johnson', 'CJOHNSON', '011.44.1644.429262', '2008-01-04', 'SA_REP', 6200.00, 0.1, 149, 80),
(180, 'Winston', 'Taylor', 'WTAYLOR', '650.507.9876', '2006-01-24', 'SH_CLERK', 3200.00, NULL, 120, 50),
(181, 'Jean', 'Fleaur', 'JFLEAUR', '650.507.9877', '2006-02-23', 'SH_CLERK', 3100.00, NULL, 120, 50),
(182, 'Martha', 'Sullivan', 'MSULLIVA', '650.507.9878', '2007-06-21', 'SH_CLERK', 2500.00, NULL, 120, 50),
(183, 'Girard', 'Geoni', 'GGEONI', '650.507.9879', '2008-02-03', 'SH_CLERK', 2800.00, NULL, 120, 50);1.2 SQL 查询中的核心关键字
1.2.1 关键字一览表
|
关键字 |
作用 |
说明 |
|---|---|---|
|
|
选择列 |
指定要查询的列或计算字段 |
|
|
数据来源 |
指定表、视图或子查询 |
|
|
行级过滤 |
在分组前过滤行 |
|
|
分组 |
按列分组,常与聚合函数配合 |
|
|
分组过滤 |
对分组后的结果进行过滤 |
|
|
排序 |
对最终结果排序 |
|
|
分页 |
限制返回的行数 |
1.2.2 SQL 执行顺序(重中之重)
书写顺序 ≠ 执行顺序。实际执行顺序为:
-
FROM– 确定数据来源 -
WHERE– 过滤行(分组前) -
GROUP BY– 分组 -
HAVING– 过滤组(分组后) -
SELECT– 选择列、计算、起别名 -
ORDER BY– 排序 -
LIMIT– 限制行数
重要规则:SELECT子句中定义的别名,只能在ORDER BY中使用,不能在WHERE、GROUP BY、HAVING中使用。
1.2.3 综合案例
需求:查询员工数超过 2 人的部门及其平均工资(排除无效工资数据),按平均工资降序,只显示前 2 个。
SELECT department_id
,COUNT(*) AS emp_count
,AVG(salary) AS avg_salary
FROM hr.employees
WHERE salary > 0
GROUP BY department_id
HAVING COUNT(*) > 2
ORDER BY avg_salary DESC
LIMIT 2;1.2.4 常见错误示例
-- ❌ 错误:在WHERE中使用别名
SELECT salary * 1.1 AS new_salary
FROM hr.employees
WHERE new_salary > 10000;
-- ✅ 正确:重复表达式
SELECT salary * 1.1 AS new_salary
FROM hr.employees
WHERE salary * 1.1 > 10000;第二章 运算符详解
2.1 算术运算符
|
运算符 |
含义 |
示例 |
|---|---|---|
|
|
加法 |
|
|
|
减法 |
|
|
|
乘法 |
|
|
|
除法 |
|
|
|
取余(模) |
|
案例 2.1:计算涨薪 10%后的新工资
SELECT first_name
,last_name
,salary
,salary * 1.10 AS new_salary
FROM hr.employees;案例 2.2:计算年薪+年终奖
SELECT first_name
,last_name
,salary
,(salary * 12) + 1000 AS annual_income
FROM hr.employees;案例 2.3:查询员工 ID 为偶数的员工
SELECT employee_id
,first_name
,last_name
FROM hr.employees
WHERE employee_id % 2 = 0;2.2 比较运算符
|
运算符 |
含义 |
示例 |
|---|---|---|
|
|
等于 |
|
|
|
不等于 |
|
|
|
大于 |
|
|
|
小于 |
|
|
|
大于等于 |
|
|
|
小于等于 |
|
案例 2.4:查询部门 90 的员工
SELECT first_name
,last_name
,department_id
FROM hr.employees
WHERE department_id = 90;案例 2.5:查询工资高于 15000 的员工
SELECT first_name
,last_name
,salary
FROM hr.employees
WHERE salary > 15000;案例 2.6:查询不是 IT 程序员的员工
SELECT first_name
,last_name
,job_id
FROM hr.employees
WHERE job_id != 'IT_PROG';2.3 逻辑运算符
|
运算符 |
含义 |
示例 |
|---|---|---|
|
|
且 |
|
|
|
或 |
|
|
|
非 |
|
案例 2.7:部门 50 且工资高于 6000
SELECT first_name
,last_name
,salary
,department_id
FROM hr.employees
WHERE department_id = 50
AND salary > 6000;案例 2.8:职位是销售代表或副总裁
SELECT first_name
,last_name
,job_id
FROM hr.employees
WHERE job_id = 'SA_REP'
OR job_id = 'AD_VP';案例 2.9:使用括号组合复杂条件
SELECT first_name
,last_name
,salary
,department_id
FROM hr.employees
WHERE (department_id = 50 OR department_id = 60)
AND salary > 7000;2.4 特殊运算符
2.4.1 IS NULL / IS NOT NULL
-- 查询没有佣金的员工
SELECT first_name
,last_name
,commission_pct
FROM hr.employees
WHERE commission_pct IS NULL;
-- 查询有佣金的员工
SELECT first_name
,last_name
,commission_pct
FROM hr.employees
WHERE commission_pct IS NOT NULL;2.4.2 LIKE 模糊匹配
-
%:匹配任意个字符(包括 0 个) -
_:匹配单个字符
-- 名字以S开头
SELECT first_name
FROM hr.employees
WHERE first_name LIKE 'S%';
-- 名字第二个字母是o
SELECT first_name
FROM hr.employees
WHERE first_name LIKE '_o%';
-- 邮箱以s结尾
SELECT email
FROM hr.employees
WHERE email LIKE '%s';2.5 运算符优先级(从高到低)
-
括号
() -
乘除
*/% -
加减
+- -
比较运算符(
=、>、<等) -
NOT -
AND -
OR
建议:当不确定优先级时,使用括号明确表达意图。
第三章 pg_trgm 扩展详解
3.1 Trigram 概念
pg_trgm是 PostgreSQL 官方扩展,通过 Trigram(三字母组)技术实现高效模糊查询和相似度搜索。Trigram 是从字符串中提取的连续三个字符的组。
例如字符串"cat"的 trigram 集合为:{" c", " ca", "cat", "at "}。
3.2 安装 pg_trgm
3.2.1 安装操作系统包
大多数 Linux 发行版的默认软件源都比较保守,不会第一时间收录最新版的 PostgreSQL。要安装最新的 17 版本,必须先手动添加 PostgreSQL 官方的 APT 仓库,然后在 Ubuntu 系统中通过 contrib 包来获取扩展
第 1 步:添加 PostgreSQL 官方 APT 仓库
# 导入官方仓库的签名密钥
sudo apt install -y curl ca-certificates
sudo install -d /usr/share/postgresql-common/pgdg
sudo curl -o /usr/share/postgresql-common/pgdg/apt.postgresql.org.asc --fail https://www.postgresql.org/media/keys/ACCC4CF8.asc
# 添加官方仓库配置
sudo sh -c 'echo "deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
第 2 步:更新软件包列表并安装 Contrib 包
# 刷新软件包列表,让系统知道新加的仓库里有哪些软件
sudo apt update
# 安装与 PostgreSQL 17 配套的扩展包
sudo apt install -y postgresql-contrib-17注意:你需要安装的是 postgresql-contrib-17,而不是 postgresql-17-pgtrgm。这是 PostgreSQL 官方为 17 版本专门提供的扩展集合包,pg_trgm 就包含在其中。
第 3 步:在数据库中启用 pg_trgm 扩展
安装完成后,使用 DBeaver 连接到你的数据库,并在 SQL 窗口中执行创建扩展的 SQL 命令:
-- 先连接到你的目标数据库,然后执行
CREATE EXTENSION IF NOT EXISTS pg_trgm;
-- 验证是否启用成功
SELECT extname, extversion FROM pg_extension WHERE extname = 'pg_trgm';CREATE EXTENSION IF NOT EXISTS pg_trgm; 只需要在同一个数据库中执行一次,之后在该数据库的所有会话中就可以永久使用 pg_trgm 提供的函数(如 similarity)、运算符(如 %、<->)以及索引方法(gin_trgm_ops、gist_trgm_ops),无需重复执行。
几个关键点提醒:
-
作用范围是单个数据库:扩展是安装在当前连接的数据库内的。如果你在
test数据库里执行了这条命令,那么在test库里就能一直用;但如果切换到postgres或其他数据库,依然用不了,需要再执行一次。 -
已经存在时不会重复安装:
IF NOT EXISTS会判断扩展是否已经存在,如果存在就不再重复创建,也不会报错,所以多次执行也没有副作用。 -
权限要求:只有数据库的拥有者或者具有
CREATE权限的用户才能安装扩展。
验证是否已安装:
如果返回一行 pg_trgm,说明已经安装成功,可以直接使用了。
问题:postgresql-contrib-17中有哪些扩展?
postgresql-contrib-17 软件包里包含了大约 70 个由 PostgreSQL 官方维护的扩展,可以按功能分为以下几大类:
常用扩展分类速查
|
分类 |
扩展 (单击官网链接查看) |
主要功能 |
|---|---|---|
|
性能加速 |
使用三元组匹配实现高效模糊查询,或为非标准数据类型提供 GIN/GiST 索引支持。 |
|
|
数据处理 |
存储键值对或树状结构数据,以及提供交叉表(如 |
|
|
数据类型 |
提供大小写不敏感的文本类型,或支持多维几何、线段等特殊数据运算。 |
|
|
全文搜索 |
辅助 |
|
|
模糊匹配 |
提供 |
|
|
地理/几何 |
计算地球表面两点间的大圆距离,或支持完整的地理空间数据。 |
|
|
其他实用 |
提供基于 Bloom 过滤器的索引,用于跨库访问、检查数据库底层存储结构等。 |
|
|
编程语言 |
plpgsql, plperl, pltcl, plpython3u |
在数据库内部使用不同的过程语言编写函数和存储过程。 |
常用扩展功能与用例
接下来,我们结合实际场景,看看这些扩展能解决什么问题。
|
扩展 |
典型用例 |
|---|---|
|
|
搜索时容忍输入错误(“ |
|
|
在一个字段里灵活存储产品的可扩展属性,无需频繁变更表结构。 |
|
|
高效存储和查询树状结构路径,如查询整个 |
|
|
当查询涉及 |
|
|
将行列数据进行转换,例如把按月份的销售数据变成“产品\月”的交叉表。 |
|
|
让 |
|
|
在大量数据上对多个 |
|
|
编写复杂的业务逻辑函数,如自动更新“最后更新时间”戳的触发器、数据校验等。 |
查看已经启用的扩展
直接在psql命令行中执行 \dx 命令,即可列出当前数据库中所有已安装和可用的扩展。
# 进入 psql
sudo -u postgres psql
# 查看已经启用的扩展
\dx
# 退出psql
\q输出如下内容:
查看数据库中所有扩展:
SELECT name
,default_version
,installed_version
,comment
FROM pg_available_extensions
ORDER BY name;输出如下内容:
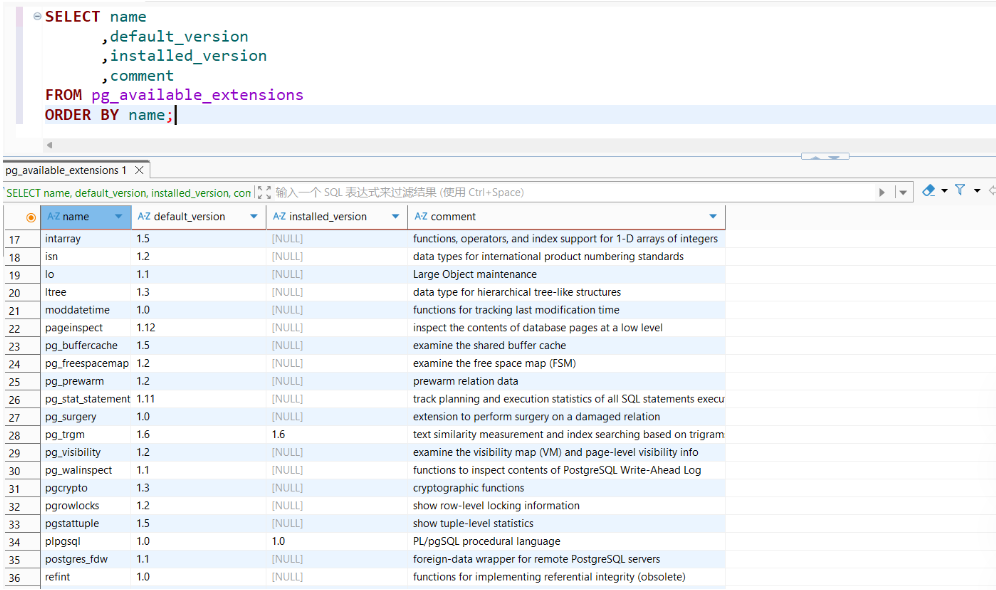
3.3 核心函数与运算符
3.3.1 函数说明
|
函数 |
用途 |
返回值范围 |
|---|---|---|
|
|
计算两个字符串相似度 |
0 ~ 1 |
|
|
显示字符串的 trigram 数组 |
text[] |
|
|
a 与 b 中任意子串的最大相似度 |
0 ~ 1 |
|
|
严格单词边界匹配 |
0 ~ 1 |
示例:
SELECT similarity('postgres', 'postgre'); -- 约 0.7
SELECT show_trgm('hello'); -- {" h"," he","hel","ell","llo","lo "}
SELECT word_similarity('word', 'two words'); -- 约0.8
select strict_word_similarity('word', 'two words') -- 0.5714286当然,下面我将逐个详细讲解 pg_trgm 扩展提供的这四个核心函数,包括它们的工作原理、参数含义、返回值细节、典型使用场景以及具体的 SQL 示例。
( 1) similarity(a, b)
函数签名
similarity(text, text) → float8作用:计算两个字符串之间的整体相似度。值越大表示两个字符串越相似,1 表示完全相同,0 表示完全不相似。
底层原理
-
将两个输入字符串分别拆分成一组 trigram(三字母组)。
-
计算两个集合的交集大小和并集大小。
-
返回
交集大小 / 并集大小。
参数
-
a,b:任意文本(可以是英文、中文、数字等)。
返回值
一个 double precision 浮点数,范围 [0.0, 1.0]。
使用场景
-
判断两个完整的字符串是否“大致相同”(例如用户输入与数据库记录的匹配度)。
-
实现“也许你想找的是……”的候选推荐。
-
数据清洗:识别重复或高度相似的记录。
示例
-- 几乎相同的字符串
SELECT similarity('PostgreSQL', 'Postgresql');
-- 结果:0.875 (因为大小写不同导致 trigram 有差异)
-- 明显不同的字符串
SELECT similarity('cat', 'dog');
-- 结果:0.0 (没有共享的 trigram)
-- 中文相似度
SELECT similarity('你好世界', '你好中国');
-- 结果:约 0.4 (共享 "你好" 的部分 trigram)与 % 运算符的关系
a % b 本质上等价于 similarity(a, b) > pg_trgm.similarity_threshold(默认阈值 0.3)。
( 2) show_trgm(str)
函数签名
show_trgm(text) → text[]作用:将一个字符串转换成它对应的 trigram 数组。这个函数主要用于调试和理解 pg_trgm 的内部分词逻辑,不直接用于查询。
分词规则
-
字符串两侧会自动添加两个空格(用于处理开头的匹配)。
-
每三个连续字符组成一个 trigram。
-
非单词字符(如标点、空格、特殊符号)通常会被忽略或切割成单独的 trigram(取决于 PostgreSQL 版本和区域设置)。
参数:str:任意文本。
返回值
返回一个 text[] 数组,包含该字符串的所有 trigram(顺序无关)。
使用场景
-
学习 trigram 的生成规则。
-
诊断为什么两个字符串的相似度不如预期。
-
自定义分词逻辑的探索。
示例
-- 基础示例
SELECT show_trgm('cat');
-- 结果:{" c"," ca","cat","at "}
-- 单词前缀匹配
SELECT show_trgm('word');
-- 结果:{" w"," wo","wor","ord","rd "}
-- 包含空格的字符串
SELECT show_trgm('hello world');
-- 结果中包含空格产生的 trigram,例如 "l", "lo ", "o w" 等( 3) word_similarity(a, b)
函数签名
word_similarity(text, text) → float8作用
计算第一个字符串与第二个字符串中任意连续子串的最大相似度。换句话说,它试图判断 a 是否大致是 b 的一部分(不要求单词边界)。
计算方式
-
提取
a的 trigram 集合。 -
对
b的每个可能的连续子串(长度 ≥a的长度)计算相似度。 -
返回这些相似度中的最大值。
参数
-
a:较短的字符串(通常是关键词)。 -
b:较长的字符串(通常是目标文本)。
返回值
[0.0, 1.0] 之间的浮点数,表示 a 与 b 中最佳匹配子串的相似度。
使用场景
-
在一个长文本中搜索一个短关键词,允许关键词有拼写错误。
-
实现模糊的“包含”查询(类似于
LIKE '%keyword%'但容忍错误)。 -
自动补全、纠错建议。
示例
-- "word" 出现在 "two words" 中(作为 "words" 的一部分)
SELECT word_similarity('word', 'two words');
-- 结果:约 0.8
-- 因为 "word" 与 "words" 共享大量 trigram(" wor","ord","rds" vs "wor","ord","rd " 等)
-- 完全匹配
SELECT word_similarity('cat', 'catalog');
-- 结果:约 0.75
-- 因为 "cat" 与 "cata" 相似
-- 完全不匹配
SELECT word_similarity('dog', 'catalog');
-- 结果:0.0与 <% 运算符的关系
a <% b 等价于 word_similarity(a, b) > pg_trgm.word_similarity_threshold(默认阈值 0.6)。
( 4) strict_word_similarity(a, b)
函数签名
strict_word_similarity(text, text) → float8作用
与 word_similarity 类似,但要求匹配的子串必须是完整的单词边界。即,a 必须匹配 b 中的某个独立单词(前后由非字母数字字符分隔,如空格、标点、字符串开头/结尾),而不能匹配单词的一部分。
计算方式
-
将
b按非单词字符分割成多个单词。 -
对每个单词与
a计算similarity。 -
返回这些相似度中的最大值。
参数
-
a:关键词。 -
b:包含单词的文本。
返回值
[0.0, 1.0] 之间的浮点数,表示 a 与 b 中最佳匹配单词的相似度。
使用场景
-
需要精确匹配单词边界的场景(如人名、标签、代码标识符)。
-
避免将
"cat"匹配到"catalog"(因为后者不是独立单词)。 -
对名称、关键词、标签进行模糊匹配。
示例
-- 匹配整个单词 "words"
SELECT strict_word_similarity('word', 'two words');
-- 结果:约 0.571 (因为 "word" 与 "words" 相似,但 "words" 末尾有 's',所以相似度略低于 0.8)
-- 不匹配单词的一部分
SELECT strict_word_similarity('cat', 'catalog');
-- 结果:0.0
-- 因为 "catalog" 中的 "cata" 不是一个独立单词,它是单词内部的一部分
-- 匹配独立单词
SELECT strict_word_similarity('cat', 'my cat is cute');
-- 结果:1.0 (因为 "cat" 与 "cat" 完全相同)
-- 容忍拼写错误
SELECT strict_word_similarity('postges', 'postgres is a database');
-- 结果:约 0.857 (因为 "postges" 与 "postgres" 相似,且 "postgres" 是一个独立单词)与 <<% 运算符的关系
a <<% b 等价于 strict_word_similarity(a, b) > pg_trgm.strict_word_similarity_threshold(默认阈值 0.5)。
总结对比
|
函数 |
比较范围 |
单词边界要求 |
典型场景 |
|---|---|---|---|
|
|
两个完整字符串 |
无 |
整体相似度、记录去重 |
|
|
(调试用) |
无 |
查看 trigram 分词 |
|
|
短串 vs 长串中的任意子串 |
无 |
长文本中模糊搜索关键字 |
|
|
短串 vs 长串中的独立单词 |
有 |
名称、标签的模糊匹配 |
快速记忆:
-
similarity:两个整体比一比。 -
word_similarity:关键词 往 长文本 里模糊匹配(不分词边界)。 -
strict_word_similarity:同上,但必须匹配整个单词。
3.3.2 运算符说明
|
运算符 |
描述 |
|---|---|
|
|
相似度超过阈值(默认 0.3) |
|
|
左侧是右侧某个连续子串的相似匹配 |
|
|
相似度距离(1 - similarity) |
SELECT 'postgres' % 'postgre'; -- true
SELECT 'postgres' <-> 'postgre'; -- 距离值3.4 创建 Trigram 索引
-- GIN索引(推荐,查询速度快)
CREATE INDEX idx_content_trgm ON your_table USING GIN (column_name gin_trgm_ops);
-- GiST索引(适合频繁更新或KNN排序)
CREATE INDEX idx_content_gist ON your_table USING GiST (column_name gist_trgm_ops);3.5 性能对比案例
3.5.1 创建测试 Schema 和表
-- 创建测试schema
CREATE SCHEMA IF NOT EXISTS test;
-- 创建测试表
CREATE TABLE test.trgm_perf_test (
id SERIAL PRIMARY KEY,
content TEXT
);3.5.2 插入 100 万条测试数据
INSERT INTO test.trgm_perf_test (content)
SELECT md5(random()::text) || '_' || md5(random()::text)
FROM generate_series(1, 1000000);3.5.3 无索引时的模糊查询性能
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM test.trgm_perf_test
WHERE content LIKE '%abc123%';典型结果:全表扫描(Seq Scan),耗时约 800-1200ms。
执行计划如下:
Gather (cost=1000.00..18564.33 rows=100 width=70) (actual time=124.252..141.392 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=12346
-> Parallel Seq Scan on trgm_perf_test (cost=0.00..17554.33 rows=42 width=70) (actual time=56.994..119.846 rows=1 loops=3)
Filter: (content ~~ '%abc123%'::text)
Rows Removed by Filter: 333332
Buffers: shared hit=12346
Planning:
Buffers: shared hit=16
Planning Time: 0.380 ms
Execution Time: 141.413 ms3.5.4 创建 GIN 索引
GIN(Generalized Inverted Index,通用倒排索引)是一种专门用于加速“包含”类查询的索引结构,它将列中的每个元素(如数组中的元素、全文搜索的词素、或 pg_trgm 提取的三元组)作为键,记录包含该键的所有行位置。当执行 LIKE '%keyword%'、column @> array 或全文搜索匹配时,GIN 索引可以快速定位到可能匹配的行,避免全表扫描。它的缺点是索引体积较大、更新较慢(适合读多写少的场景),但对于模糊查询和多值类型检索,性能提升非常显著。
CREATE INDEX idx_content_trgm ON test.trgm_perf_test USING GIN (content gin_trgm_ops);3.5.5 有索引后的性能
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM test.trgm_perf_test
WHERE content LIKE '%abc123%';典型结果:Bitmap Index Scan + Bitmap Heap Scan。
执行计划如下:
Bitmap Heap Scan on trgm_perf_test (cost=118.30..492.55 rows=100 width=70) (actual time=3.445..3.562 rows=3 loops=1)
Recheck Cond: (content ~~ '%abc123%'::text)
Rows Removed by Index Recheck: 7
Heap Blocks: exact=10
Buffers: shared hit=33 read=12
-> Bitmap Index Scan on idx_content_trgm (cost=0.00..118.27 rows=100 width=0) (actual time=3.383..3.383 rows=10 loops=1)
Index Cond: (content ~~ '%abc123%'::text)
Buffers: shared hit=33 read=2
Planning:
Buffers: shared hit=14 read=11 dirtied=3
Planning Time: 2.705 ms
Execution Time: 3.598 ms未添加索引:Execution Time: 141.413 ms
添加索引后:Execution Time: 3.598 ms
性能提升:141.413 / 3.598 = 39.30
3.5.6 相似度排序查询(KNN)
相似度排序查询(KNN,即 K-Nearest Neighbors)利用 pg_trgm 扩展的 <-> 运算符,直接通过 GiST 索引计算字符串之间的“距离”(1 - 相似度),并按距离从小到大排序返回最相似的 K 条记录,从而避免了全表扫描和逐一计算相似度,使模糊搜索的排序性能提升数百倍。
SELECT content
,similarity(content, 'search_keyword') AS sim
FROM test.trgm_perf_test
WHERE content % 'search_keyword'
ORDER BY content <-> 'search_keyword'
LIMIT 10;3.6 相似度阈值调整
-- 查看当前阈值
SHOW pg_trgm.similarity_threshold; -- 默认0.3
SHOW pg_trgm.word_similarity_threshold; -- 默认0.6
SHOW pg_trgm.strict_word_similarity_threshold; -- 默认0.5
-- 调整阈值(更严格)
SET pg_trgm.similarity_threshold = 0.5;
SET pg_trgm.word_similarity_threshold = 0.7;3.7 使用场景与最佳实践
3.7.1 适用场景
-
模糊文本搜索(用户输入不完全准确)
-
错别字容忍搜索
-
自动补全
-
数据去重
-
简易推荐系统
3.7.2 注意事项
-
短字符串(少于 3 个字符)效果有限
-
GIN 索引占用额外存储(约原数据 15-20%)
-
区分语义搜索(tsvector)与模糊匹配(pg_trgm)
-
不要混用不同类型的索引
3.7.3 索引选择建议
|
需求 |
推荐索引 |
原因 |
|---|---|---|
|
查询为主,写入不频繁 |
GIN |
查询最快 |
|
频繁写入 |
GiST |
写入性能更好 |
|
KNN 相似度排序 |
GiST |
天然支持距离排序 |
|
存储空间受限 |
GiST |
索引更小 |
附录:pg_trgm 函数速查表
|
函数 |
示例 |
|---|---|
|
|
|
|
|
|
|
|
|
第四章 执行计划(Explain)详解
4.1 什么是执行计划?
当你向 PostgreSQL 提交一条 SQL 查询时,数据库并不会直接按照你写的顺序去执行。它会先经过“查询优化器”的分析,生成一个执行计划——也就是数据库实际执行查询的“路线图”。
执行计划会告诉你:
-
数据库是否使用了索引
-
扫描了多少数据行
-
各个操作的耗时
-
是否存在性能瓶颈
学会读懂执行计划,是写出高性能 SQL 的关键技能。
4.1.1 如何查看执行计划?
使用 EXPLAIN 命令即可查看执行计划,最常用的两种形式:
|
命令 |
作用 |
|---|---|
|
|
只显示计划,不实际执行(适合查看索引使用情况) |
|
|
实际执行查询,并返回真实的耗时和行数(最推荐) |
-- 基础用法
EXPLAIN SELECT * FROM hr.employees WHERE salary > 10000;
-- 实际执行并返回详细统计
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM hr.employees WHERE salary > 10000;注意:
EXPLAIN ANALYZE会真正执行 SQL,如果是UPDATE、DELETE等写操作,建议先放在事务中测试:BEGIN; EXPLAIN ANALYZE DELETE FROM test.temp WHERE id = 1; ROLLBACK;
4.2 执行计划的核心节点解读
执行计划是一个树状结构,从最内层的节点开始执行,数据逐层向上传递。常见的节点类型如下:
4.2.1 扫描方式(如何读取数据)
|
节点名称 |
含义 |
性能 |
|---|---|---|
|
Seq Scan |
全表顺序扫描,逐行读取 |
最慢,适合小表或返回大量行 |
|
Index Scan |
根据索引直接定位到行 |
快,适合点查或范围查询 |
|
Bitmap Index Scan + Bitmap Heap Scan |
先通过索引收集行指针,再回表读取 |
中等,适合通过索引筛选出较多行 |
|
Index Only Scan |
索引中已包含所有需要的数据,无需回表 |
最快 |
4.2.2 连接方式(多表关联时)
|
节点名称 |
含义 |
|---|---|
|
Nested Loop |
嵌套循环连接,外层表每行去内层表匹配 |
|
Hash Join |
先对内层建哈希表,再匹配外层 |
|
Merge Join |
两个有序结果集合并 |
4.2.3 其他常用节点
|
节点名称 |
含义 |
|---|---|
|
Sort |
对结果进行排序 |
|
GroupAggregate / HashAggregate |
分组聚合 |
|
Limit |
限制行数 |
|
Subquery Scan |
子查询 |
4.3 执行计划输出字段详解
执行 EXPLAIN (ANALYZE, BUFFERS) 后,输出中每个节点会包含以下关键信息:
|
字段 |
含义 |
如何判断好坏 |
|---|---|---|
|
|
实际执行时间(启动时间 ~ 总时间,单位 ms) |
越小越好 |
|
|
实际返回的行数 |
应与计划预估的 |
|
|
该节点被重复执行的次数 |
1 为正常,Nested Loop 内层可能多次 |
|
|
缓存命中、磁盘读取、脏页 |
|
|
|
生成执行计划的时间 |
通常 < 1ms |
|
|
实际执行查询的时间 |
核心关注指标 |
4.4 如何判断一个查询是否需要优化?
4.4.1 常见危险信号
|
信号 |
可能问题 |
|---|---|
|
|
缺少合适的索引 |
|
|
数据量大或未命中索引 |
|
|
统计信息过时 |
|
|
Nested Loop 内层扫描次数过多 |
|
|
大量磁盘 I/O,缓存不足 |
4.4.2 更新统计信息
当发现行数估计偏差很大时,可以更新表的统计信息:
ANALYZE hr.employees;PostgreSQL 的 autovacuum 后台进程会自动更新,但对于大批量数据变更后,手动执行 ANALYZE 能立刻改善计划质量。
4.5 针对模糊查询的索引选择指南
|
查询模式 |
推荐索引 |
原因 |
|---|---|---|
|
|
普通 B-tree 索引 |
支持前缀匹配 |
|
|
GIN (pg_trgm) |
需要 trigram 倒排 |
|
相似度排序 |
GiST (pg_trgm) |
支持 KNN 距离排序 |
|
中文字符模糊查询 |
GIN (pg_trgm) |
中文 trigram 同样有效 |
|
同时有精确匹配和模糊匹配 |
复合索引或分别建索引 |
根据实际查询决定 |
4.6 实用技巧汇总
(1)善用 EXPLAIN (ANALYZE, BUFFERS):这是最常用的诊断命令,能同时看到实际耗时和缓存命中情况。
(2)关注 actual time 的第一个数值:它代表该节点输出第一行的时间,对于 LIMIT 查询非常重要。
(3)比较 rows 估计值和实际值:相差过大说明统计信息陈旧,执行 ANALYZE。
(4)模糊查询性能差时优先考虑 pg_trgm + GIN/GiST:比全文搜索配置简单,效果立竿见影。
(5)对于必须全表扫描的查询(如需要大部分数据):考虑并行查询(SET max_parallel_workers_per_gather = 4;),或增加 work_mem 优化排序和哈希操作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)