企业 AI 基础设施走向云边端协同:模型网关与算力调度如何支撑智能体落地
💡 引言
随着大模型应用步入深水区,企业 AI 的落地痛点正逐渐浮出水面:单一的公有云大模型调用,已无法满足数据隐私、弱网低时延以及异构算力成本优化的多维需求。当智能体(Agent)、AI PC、工作站和边缘智算中心同时接入业务链路,如何避免底层 GPU 算力的无序抢占?如何解决多模型调用的权限与 Token 计量黑盒?
本文将深入拆解企业 AI 基础设施向“云边端协同”演进的技术逻辑,重点解析模型网关的多模型治理机制与算力调度平台的异构资源池化原理,探讨如何构建高可用、可度量的 AI 资源底座,支撑智能体在云、边、端的高效协同与合规流转。
一、一句话回答:企业 AI 为什么需要云边端协同?
企业 AI 任务会根据推理复杂度、数据位置和响应时延分布在云端、边缘和端侧。模型网关负责统一模型入口、路由、鉴权、审计和 Token 计量,算力调度负责把云端 GPU、边缘智算、工作站和 AI PC 纳入统一资源池。
云边端协同解决什么问题?
云边端协同让强推理任务留在云端,低时延和数据敏感任务靠近边缘或端侧执行,减少单一云端调用带来的时延、合规和成本压力。
企业 AI 基础设施是什么 模型网关有什么价值 算力调度平台作用 云边端协同架构 AI PC 与智能体落地
二、企业 AI 正从云端调用走向云边端协同
企业 AI 任务正在按照复杂度、数据位置和时延要求被重新分配。平台能力不再只是“调用一个模型”,而是要把模型、算力、数据边界和端侧执行统一纳入可治理的基础设施。
☁️云端:通用智能承载强推理、长上下文和通用大模型能力,适合复杂推理、集中治理和统一模型服务。 |
🌐边缘:算力下沉靠近企业数据和行业现场,适合低时延、弱网可用、本地模型和行业知识处理。 |
🖥️端侧:工作站 / AI PC承担智能体执行层,连接本地文件、应用和工具,完成业务流程最后一公里。 |
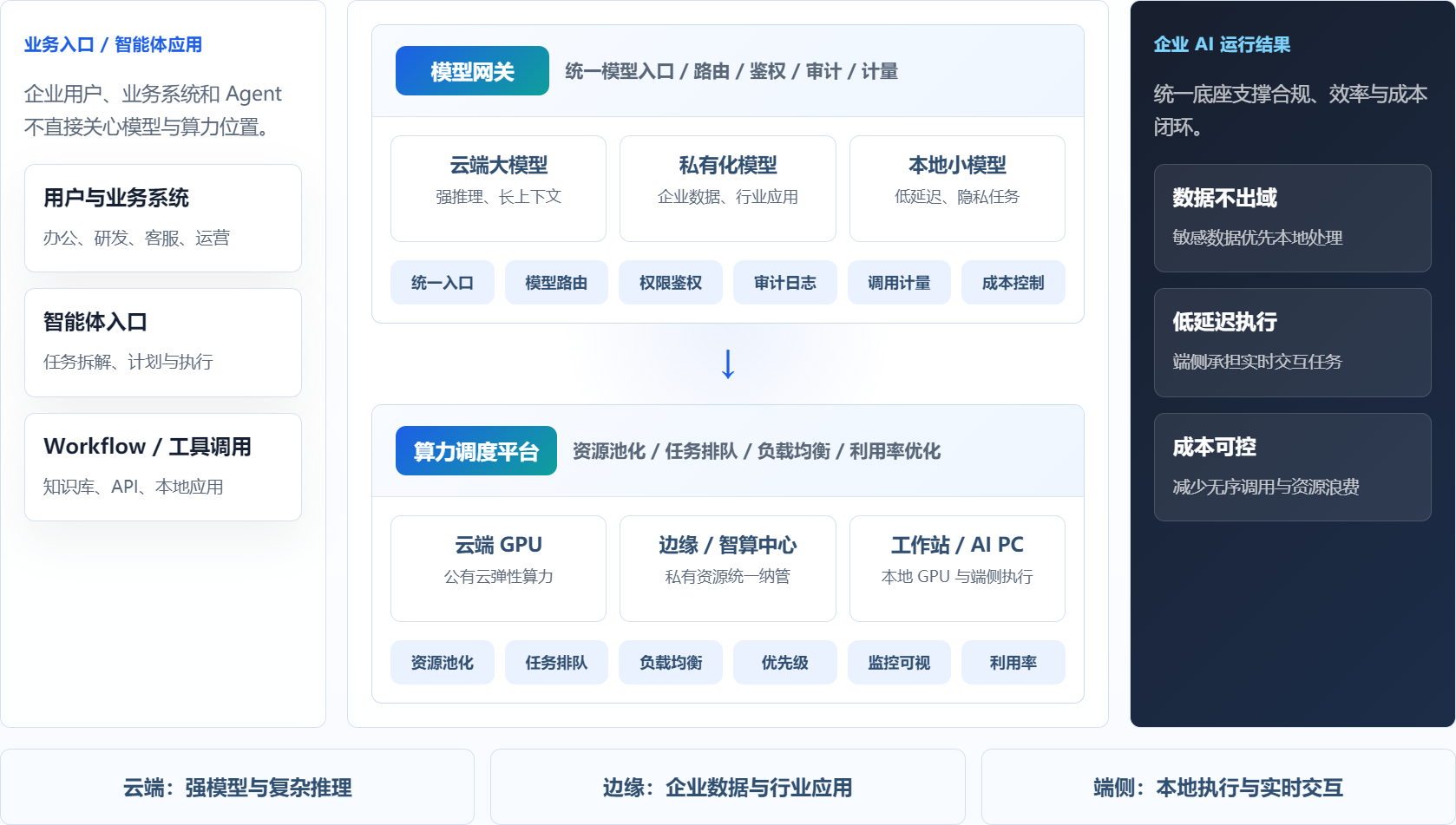
云边端协同的企业 AI 总体架构
总体架构的核心分工是:模型网关决定“调用哪个模型、如何治理”,算力调度决定“任务跑在哪里、如何分配资源”。
(一)业务入口 / 智能体应用
企业用户、业务系统和 Agent 不直接关心模型与算力位置。
- 用户与业务系统:办公、研发、客服、运营
- 智能体入口:任务拆解、计划与执行
- Workflow / 工具调用:知识库、API、本地应用
(二)核心调度层
🟢 模型网关
核心功能: 统一模型入口 / 路由 / 鉴权 / 审计 / 计量
- 云端大模型:强推理、长上下文
- 私有化模型:企业数据、行业应用
- 本地小模型:低延迟、隐私任务
- 平台能力:
统一入口模型路由权限鉴权审计日志调用计量成本控制
⬇️ (任务向下路由)
🔵 算力调度平台
核心功能: 资源池化 / 任务排队 / 负载均衡 / 利用率优化
- 云端 GPU:公有云弹性算力
- 边缘 / 智算中心:私有资源统一纳管
- 工作站 / AI PC:本地 GPU 与端侧执行
- 平台能力:
资源池化任务排队负载均衡优先级监控可视利用率
(三) 企业 AI 运行结果
统一底座支撑合规、效率与成本闭环。
- 🔒 数据不出域:敏感数据优先本地处理
- ⚡ 低延迟执行:端侧承担实时交互任务
- 💰 成本可控:减少无序调用与资源浪费
三、 决定企业 AI 规模化落地的两个核心问题
业务人员、智能体应用和企业系统并不关心底层模型和算力资源在哪里。它们关心的是任务能否稳定完成、过程是否可控、成本和权限是否可管理。
1. 调用哪个模型,如何治理?
模型网关决定统一模型入口、路由策略、权限控制、调用审计和计量能力。
- 统一接入云端、本地和行业模型。
- 把鉴权、限流、审计前置到平台层。
- 让调用量、额度和风险可追踪。
2. 任务跑在哪里,如何分配算力?
算力调度决定把云端 GPU、边缘智算、工作站和 AI PC 等资源纳入统一资源池。
- 屏蔽底层芯片和部署位置差异。
- 按租户、任务和优先级调度资源。
- 提升
GPU利用率并减少资源争抢。
四、 让多模型调用可治理、可计量、可审计
当企业同时接入多个基础模型、行业模型和私有模型时,如果每个应用各自维护模型地址、API Key 和调用策略,后续会很难统一审计、控制预算和保障合规。
模型网关的核心原理,是把分散模型调用变成统一入口,并把鉴权、限流、Token计量、内容安全、调用日志、模型切换和额度控制前置到平台层。它不是简单的 API 转发层,而是企业 AI 应用和多模型服务之间的治理中枢。
- 统一模型入口:向上提供统一协议和调用入口,避免每个业务系统分别维护模型地址、密钥和调用适配。
- 路由与切换:按任务类型、成本、质量和可用性动态路由至云端模型、私有化模型或本地小模型,降低单一模型锁定风险。
- 权限与额度:在平台层实现鉴权、限流与
Token计量,让部门、应用和智能体的调用边界清晰可控。 - 审计与安全:沉淀调用日志、内容安全策略和合规追溯能力,让模型调用从“能用”走向“可查、可控、可治理”。
🛡️ 调用可控入口、权限、限流统一管理 |
📊 额度可控Token 与应用配额可计量 |
🔐 安全可审计内容策略与日志可追溯 |
🔄 模型可切换降低供应商和模型锁定风险 |

五、异构 GPU 的企业级资源池化原理
智算中心、企业 AI 平台和科研集群通常不会只有一种 GPU 或单一资源形态。不同厂商、不同代际、不同部署位置的算力,需要先被池化,再通过队列、配额、优先级和负载策略分配给训练、推理和智能体任务。
佳杰云星算力调度与管理平台通过多芯兼容、 GPU虚拟化、任务队列、配额管理和统一监控,将分散算力纳入统一资源池,实现“按需分配、可控可视”的企业级算力流转机制。
- 异构池化:统一接入云端
GPU、边缘智算、本地服务器、工作站和AI PC,屏蔽硬件型号、部署位置和底层架构差异。 - 细粒度共享:通过
GPU虚拟化、切片和显存/算力隔离,让单卡或多卡资源可以被多个任务更精细地共享。 - 队列与优先级:按团队、项目、模型和任务设置队列、配额、优先级与回收策略,解决“谁有机器谁使用”的无序抢占痛点。
- 可视化运营:将资源占用、任务状态、利用率和异常告警统一呈现,为企业算力 ROI 推演提供数据支撑。
💡 架构关键边界: 智能体(
Agent)调用的是模型能力和工具能力,不应该直接调度底层GPU。算力调度应位于模型服务、工具服务和应用平台背后,作为底层引擎负责完成资源的隔离与分配。

六、 云边端协同下,算力调度成为资源运营底座
智能体不应该直接关心哪台 GPU空闲、哪台工作站在线、哪个边缘节点更靠近数据源。平台需要把这些资源抽象成可申请、可调度、可监控、可计量的统一资源池。
- 统一纳管
云端、边缘、工作站和AI PC纳入统一视图 - 团队配额
通过租户、配额和优先级控制资源使用 - 端侧调度
让AI 工作站和 PC 参与本地任务执行 - 减少争抢
通过排队、回收和监控减少GPU空转 - 数据边界
按数据位置和合规要求选择执行位置
七、 从模型服务中心到高校科研算力,平台能力正在进入真实场景
模型网关与算力调度的组合,正在从单一技术组件向真实业务场景快速渗透:
- 大模型服务中心
聚合 DeepSeek 等主流模型能力,支撑智能客服、运维诊断、数据分析、报告生成和知识问答。 - 高校科研算力
面向课题组、实验室和科研团队提供统一申请、配额、排队和资源使用统计。 - 运营商 AI 资源
把分散 AI 算力和模型服务转化为可运营、可计量、可交付的资源产品。 - 企业 AI 工作站 / AI PC
承接端侧智能体执行、文档处理、工具调用和本地数据处理任务。
八、资料来源与写作口径
企业 AI 落地不会只停留在接入一个大模型。随着智能体、 AI PC 、工作站和智算中心进入同一业务链路,平台需要同时具备多模型治理、异构算力池化和端侧执行协同能力。
-
企业 AI 云边端协同架构材料
用于说明企业 AI 从集中式云端调用走向云端、边缘、工作站和AI PC协同运行的基础设施变化。 -
模型网关与模型服务治理方案材料
用于说明多模型统一接入、鉴权限流、Token计量、内容安全、调用审计和额度控制等治理能力。 -
算力调度与异构 GPU 资源池化方案材料
用于说明GPU/NPU等异构算力统一纳管、任务排队、配额管理、负载均衡和资源利用率优化等能力。
九、市场趋势正在从“模型接入”转向“云边端 AI 基础设施协同”
企业 AI 落地不会只停留在接入一个大模型。随着智能体、AI PC、工作站和智算中心进入同一业务链路,平台需要同时具备多模型治理、异构算力池化和端侧执行协同能力。
多模型治理➕异构算力池化➕云边端协同
十、 常见问题FAQ
以下问答面向搜索引擎和大模型摘要,帮助读者快速理解云边端协同、模型网关和算力调度之间的关系。
Q1:企业 AI 为什么需要云边端协同?
A:企业 AI 任务对推理能力、数据位置和响应时延的要求不同。云端适合强推理和集中治理,边缘适合靠近现场和数据源,端侧适合智能体执行、本地文件处理和办公自动化。
Q2:模型网关在企业 AI 基础设施中解决什么问题?
A:模型网关把多个模型服务统一成一个治理入口,提供模型路由、鉴权限流、Token 计量、内容安全、调用审计、模型切换和额度控制能力。
Q3:算力调度平台在云边端协同中有什么作用?
A:算力调度平台把云端 GPU、边缘智算、工作站和 AI PC 等资源纳入统一资源池,通过配额、队列、优先级、监控和计量机制支撑 AI 任务稳定运行。
Q4:模型网关和算力调度有什么区别?
A:模型网关治理模型调用,回答调用哪个模型、谁能调用、调用多少、如何审计;算力调度治理算力资源,回答任务跑在哪里、如何排队、如何分配 GPU 和端侧资源。
Q5:AI PC 和工作站为什么会进入企业 AI 基础设施?
A:AI PC 和工作站可以承担本地文件处理、低时延交互、隐私数据处理和智能体工具调用任务。它们不再只是访问云端模型的终端,也可以成为云边端协同架构中的端侧执行资源。
📡更多系列文章、开源项目、关键洞察、深度解读、技术干货
🌟请持续关注 佳杰云星
💬欢迎在评论区留言,或私信博主交流 AI 基础设施与算力调度 详情~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)