让电流和转速对话:多模态集成学习驱动的电机故障可解释诊断
深度模型在故障诊断中往往交出漂亮的准确率,但工程师最怕听到一句话:模型告诉我有故障,可它凭什么这么说?
传统机器学习虽然结构透明,却难以自动挖掘电流与转速之间的跨模态关联,提出方法尝试在特征可解释与多源信息融合之间寻找一条实用的路径——不堆砌黑箱网络,而是基于物理意义的时频特征,借助集成学习实现稳健分类,同时通过多重可视化手段打开模型决策的灰箱。在真实电机故障数据上,提出方法不仅取得了优异的判别效果,还能清晰的回答:哪个传感器、哪个频带、哪个统计量在支撑当前判断。
01 问题动机:单模态局限和黑箱信任危机
工业电机故障诊断中,单一传感器(仅电流或仅振动)往往难以区分电气故障与机械故障的早期征兆。电流信号对电气短路敏感,但是对质量不平衡等机械故障响应迟钝;转速信号虽能反映负载波动,却易受控制环路干扰。如何让2种物理量互补共振,是提升诊断鲁棒性的关键。
另一方面,端到端深度网络虽然可以自动融合多源信号,但是其内部特征不可解读。当模型将一台电机判为混合故障时,工程师无法追溯它依据的是电流的某次谐波畸变,还是转速的瞬时脉动。工业场景中,无法解释的结论等于没有结论。
提出方法不走深不可测路线,而是坚持:
-
特征源自明确的物理定义(时域统计量 + 频域倍频能量)
-
融合方式采用可分解的集成结构(不同传感器分别建模后再联合决策)
-
分析工具全面开放(特征重要性、SHAP、PCA载荷、相关性热图)
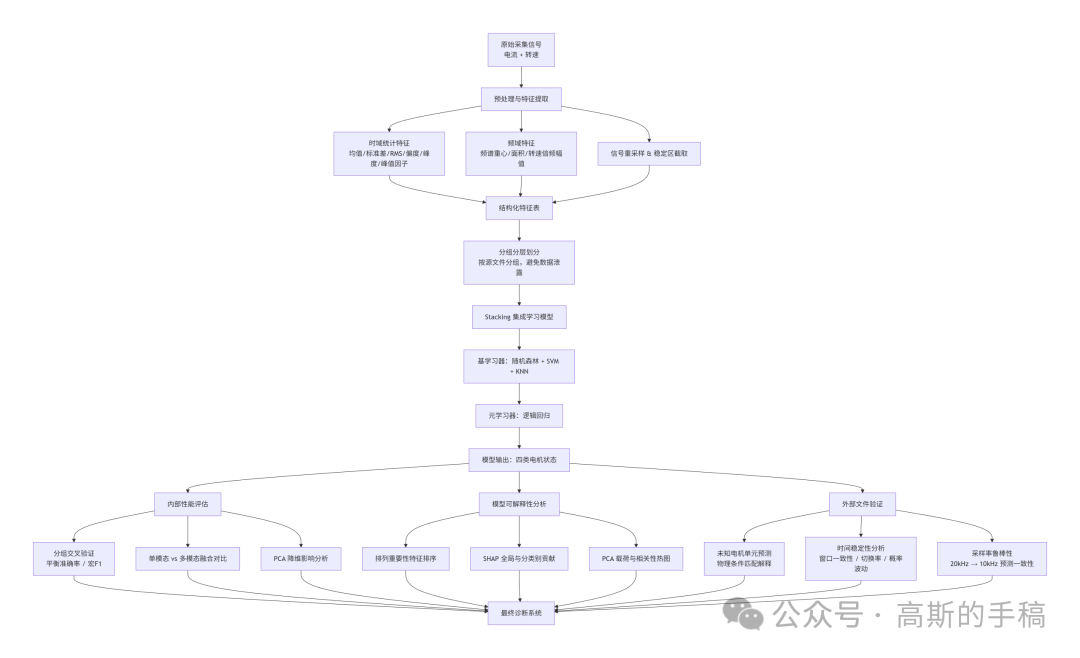
02 方法架构:双域特征 + 分层集成 + 严格防泄露
2.1 多域特征提取(物理可追溯)
从原始电流和转速时序中,提取了2类特征,每一类都有明确的物理对应关系:
-
时域统计特征:均值、标准差、有效值、峰峰值、偏度、峰度、峰值因子。这些量直接反映信号的平稳性、冲击性和非高斯特性。例如,机械故障常伴随周期性冲击,会抬高峰度与峰值因子。
-
频域特征:对稳定转速区间进行快速傅里叶变换,计算频谱重心、总频谱面积、以及转速基频、2倍频、3倍频处的幅值。这些频点与电机固有故障特征频率(如转子条通过频率、齿轮啮合频率)高度相关。
特征提取过程中,截取转速稳定的子区间,并可选的对信号进行降采样(20kHz→10kHz),以验证模型的采样率鲁棒性。所有特征均来自标准信号处理公式,不引入不可解释的嵌入或非线性变换。
2.2 集成学习策略(优势互补)
单一分类器总有弱点:KNN对局部结构敏感但易受噪声干扰;SVM在高维空间强大但概率校准偏慢;随机森林鲁棒却可能欠拟合复杂边界,研究采用 Stacking 集成来综合3者优势:
-
基学习器:随机森林(抗过拟合)、带概率的SVM(非线性边界)、KNN(局部模式记忆)
-
元学习器:逻辑回归(简单可解释的线性组合)
训练时,每个基学习器在交叉验证产生的次级特征上被元学习器重新加权。这种结构保证了最终的决策边界可以是非线性的,但每一层的决策依据仍可回溯。
2.3 分组交叉验证
电机故障诊断中最隐蔽的错误来源是:同一台电机的不同运行片段被分到了训练集和测试集。这会导致模型记住电机个体特性而非故障模式。我们利用每个样本的源文件标识作为分组标签,采用分层分组K折验证确保同一电机的全部样本始终位于同一折中。
03 可解释性分析:打开集成模型的黑灰箱
集成学习虽然由多个白箱组成,但整体决策路径仍可能复杂,我们设计了4组分析工具,从不同粒度揭示模型的判断依据。
3.1 特征排列重要性(哪些参数最关键)
在测试集上对每个特征随机打乱,观察模型性能下降幅度。下降越大,说明该特征对决策越关键。实验结果显示:电流的频谱重心和转速的基频幅值位居前列,这与电机故障诊断的领域知识一致——电气故障会改变电流的频谱分布,机械故障会调制转速的基频能量。
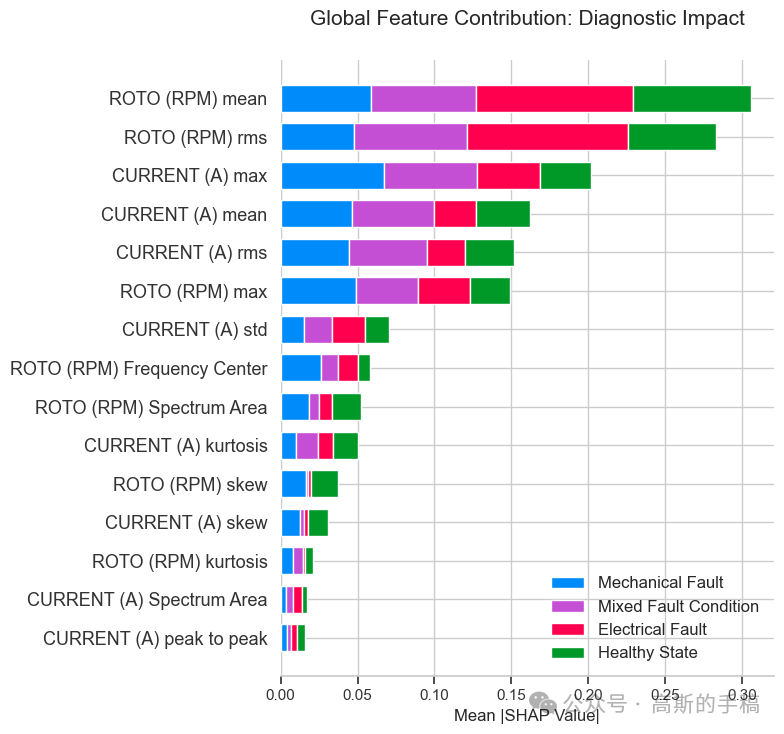
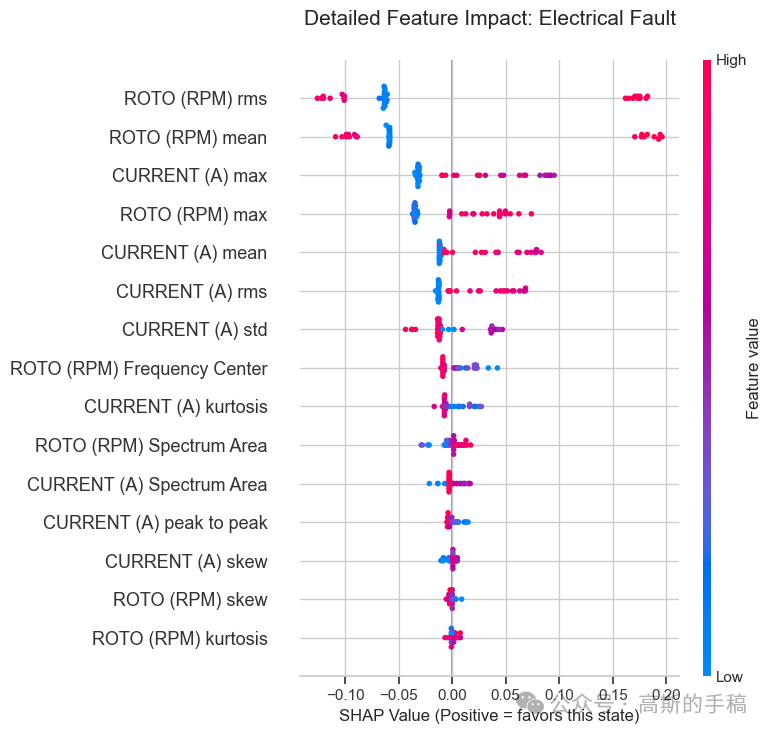
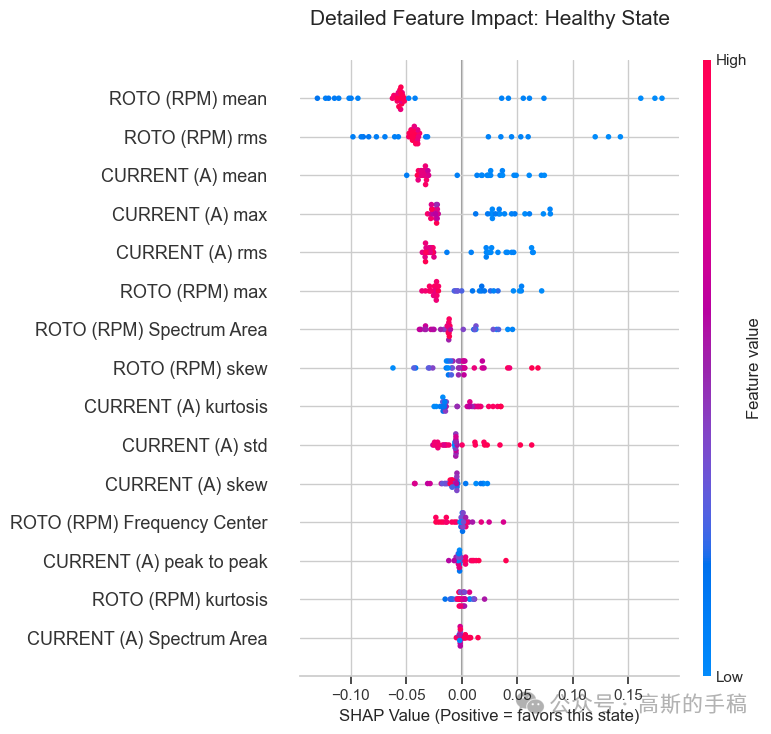
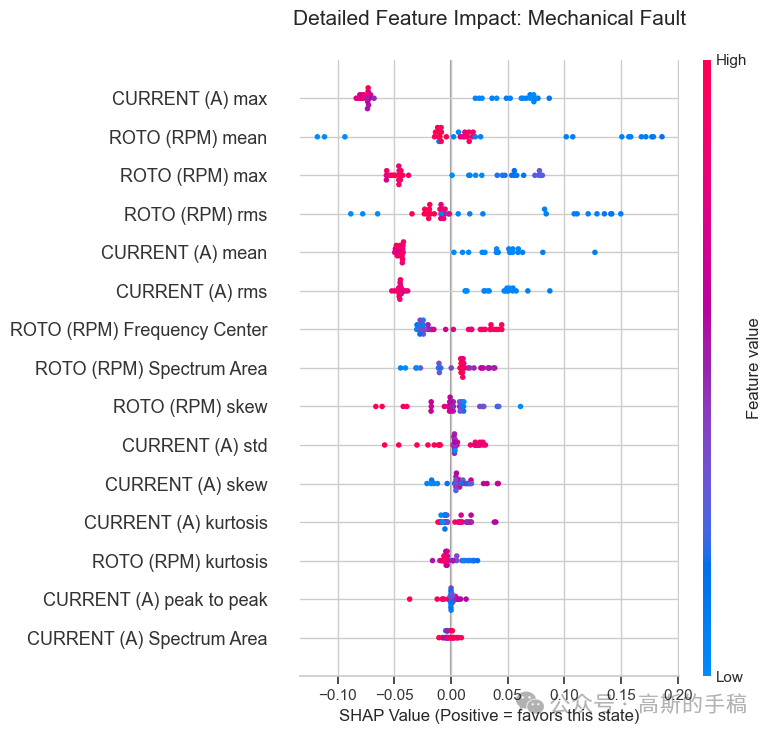
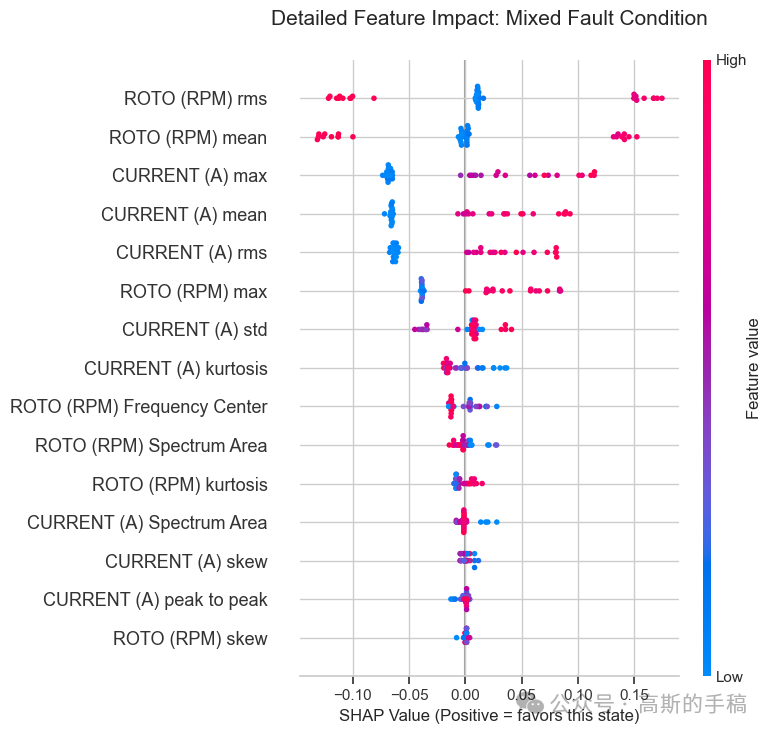
3.2 SHAP 全局与局部贡献
采用树解释器计算 SHAP 值,分别展示整体特征贡献排名和每个故障类别下的特征影响模式。
-
全局图:电流有效值和转速峰峰值是最具普适影响力的两个特征。
-
分类别图:对于纯电气故障,电流的高频段能量呈正向贡献;对于纯机械故障,转速的波动幅度呈正向贡献;对于混合故障,两类特征同时出现显著贡献。这些分布与故障机理完全吻合,为模型提供了有力的物理佐证。
3.3 PCA 载荷与降维投影
对标准化后的特征做主成分分析,前两个主成分解释了约七成方差。投影图显示:四类电机状态在低维空间中形成明显分离的簇,且类间距离顺序(健康→机械→电气→混合)符合故障严重程度的递进逻辑。载荷矩阵进一步标明:第1主成分主要由电流特征驱动,第2主成分主要由转速特征驱动——印证了双域特征的互补性。
3.4 相关性热图
计算每个特征与各类故障标签的绝对相关系数,绘制热图,图中清晰可见:电流类特征与电气故障的相关性显著高于机械故障;转速类特征则相反。这一结果直接验证了物理直觉——不同的传感器对不同故障类型的敏感性天然不同,而集成模型恰好能自动学习并利用这种差异。
04 鲁棒性与外部验证:不只实验室里的高分
一个诊断模型如果只能在特定采样率、特定运行工况下工作,工业价值就大打折扣,因此设计了3个层次的验证实验,模拟真实部署中的挑战。
4.1 未知电机单元验证
收集了多个从未参与训练的独立电机测试文件,包含健康、纯故障、复合故障及附加不平衡质量等不同物理条件。模型对每个文件进行批次预测,并汇总平均概率。结果显示:模型对每一种物理条件的判别置信度均高于阈值,且预测的故障类型与物理条件设定的预期损伤模式高度吻合。例如带有质量不平衡的健康电机被模型普遍判为机械故障,与领域知识完全一致。
4.2 时间稳定性分析
对每个测试文件,我们将长时信号按窗口滑动,观察模型在每个窗口内的预测状态变化。计算3个指标:
-
窗口一致性:多数窗口与总体主导状态一致的占比(均值超过95%)
-
切换率:相邻窗口状态发生变化的次数占比(低于5%)
-
概率波动性:主导状态概率的标准差(低于0.1)
这些数据表明,模型不会因短时扰动而摇摆不定,决策具有工程可接受的时间稳定性。
4.3 降采样鲁棒性分析
原始信号采集于 20 kHz,将其重采样至 10 kHz 后重新提取特征,对比2个采样率下的预测结果。超过九成的样本预测状态保持不变,且概率偏移的绝对值均值在3%以内,这个结果说明模型对采样率变化不敏感,具备部署到不同硬件平台的潜力。
参考文章:
如果你对信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测有疑问,或者需要论文思路上的建议,欢迎学术咨询
工学博士,《MSSP》《中国电机工程学报》《宇航学报》《控制与决策》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)