把 Layout 时序知识教给 RTL:RTLDistil 如何把预测提前到设计早期
论文解读:Bridging Layout and RTL: Knowledge Distillation based Timing Prediction
基于 ICML 2025 论文整理
芯片项目里,时序问题发现得越晚,修起来越贵。RTL 阶段改几行代码,也许就能改变模块结构;到了 Layout 阶段再发现关键路径卡住,代价往往变成重新综合、布局布线和多轮收敛。RTLDistil 这篇论文盯住的正是这个缝隙:能不能在 RTL 还很早的时候,就预测出更接近 Layout 真实结果的时序信息。
难点不在于再训练一个更大的模型。RTL 只有逻辑结构和抽象算子,Layout 才有电阻、电容、驱动强度、slew、delay 这些物理细节。论文的方案是让一个懂 Layout 的教师模型先学会高精度时序,再把物理知识分层传给一个轻量 RTL 学生模型。这个框架叫 RTLDistil。
一、为什么时序预测要提前到 RTL
传统 EDA 流程像一条瀑布。设计从 RTL 描述出发,经过综合、布局、布线,最后在物理实现之后做静态时序分析 STA。STA 能给出高保真的 arrival time、worst negative slack 和 total negative slack,因为它看得见工艺库、单元延迟、互连 RC 和真实布局信息。问题也在这里。它来得晚,算得重,不适合作为早期反复试错的反馈信号。
时序预测要回答的不是单个门延迟有多大,而是整条路径能否在时钟边沿前稳定下来。AT 描述信号到达某个寄存器的时间,WNS 看最差路径还欠多少 slack,TNS 则把所有负 slack 累加起来,反映设计整体时序风险。工程师真正关心的是这些指标背后的改动方向:要不要插寄存器,要不要拆逻辑,要不要换微架构。
RTL 阶段最适合做这类结构性调整。等到布局布线结束,路径延迟已经被单元摆放、线长、拥塞和缓冲器策略绑在一起,很多修复都变成局部补丁。早期模型只要能稳定指出高风险路径和模块,就有机会减少后端反复收敛的次数。RTLDistil 所追求的不是给签核盖章,而是让早期判断更像后端结果。
EDA left-shift 想把这类反馈前移。工程师在 RTL 仍可调整拓扑、寄存器位置和模块实现方式时,就能大致知道哪些路径会成为瓶颈。早一点发现风险,后面少一点返工。论文在 Figure 1 中把这个矛盾画得很直观:Layout 模型更准,但慢且靠后;RTL 模型更快,但缺少物理知识。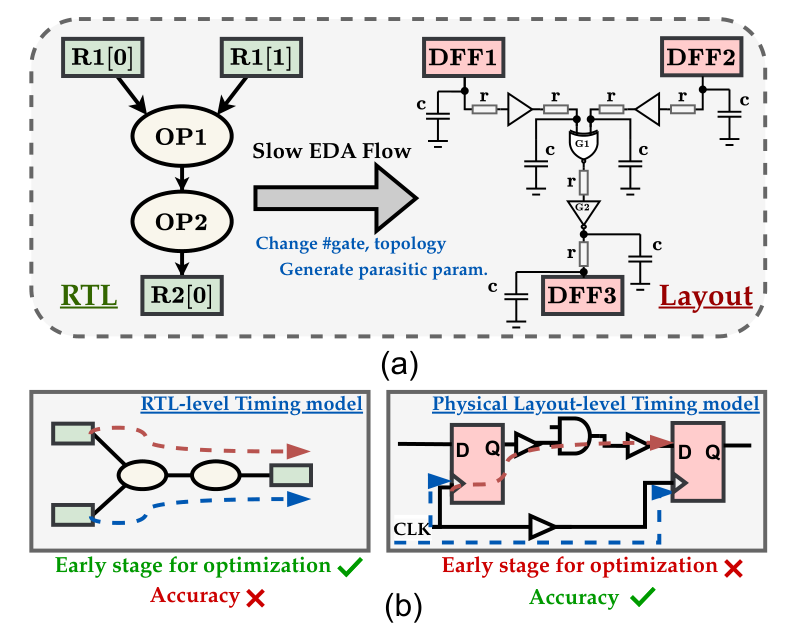
图1:芯片设计从 RTL 到 Layout 的抽象差距,也是 RTLDistil 要跨过的信息鸿沟。
来源:原论文 Figure 1,裁剪自 PDF 第 1 页,仅用于论文解读与学术交流。
已有 RTL 级方法已经能做一些估计。MasterRTL 使用 bit-level Simple Operator Graph 和多阶段机器学习模型估算 TNS、WNS;RTL-Timer 用更细粒度的图结构和定制损失,把 slack 标到 Verilog 相关结构上。它们的共同短板是物理信息不足。论文在引言中提到,即使用当前较强的 RTL 模型直接学习 Layout 标签,Layout 级时序预测准确度仍大约只有六成。
二、RTL 与 Layout 差的不只是图的大小
RTLDistil 把问题拆成两个图。RTL 侧使用 Simple Operator Graph,节点是加法器、逻辑门、寄存器等算子或存储单元,边描述数据流关系。每个节点只有 16 维特征,主要包括算子类型、fanin、fanout、Depth Per Input 和 Depth Per Output。这个图足够早,足够轻,但它看不见寄生参数。
Layout 侧使用 Netlist Graph,节点特征扩展到 96 维,包含 gate cell type、gate input pins、cell drive strength、fanout capacitance、fanout resistance、input slew、output slew 和 delay。这里的信息更接近真实 STA,能解释同一段逻辑为什么在不同物理实现下出现不同延迟。
表1里的维度差距很直白。RTL SOG 总共 16 维,更多是逻辑抽象;Layout Netlist Graph 有 96 维,里面大量是物理量。fanout capacitance 和 fanout resistance 会改变负载,input slew 和 output slew 会改变边沿传播,cell drive strength 又决定单元能推多重的下游。对于 STA 来说,这些都是基本输入;对于 RTL 来说,它们通常还不存在。
同一段 RTL 逻辑,后端可能映射成不同标准单元,也可能因为约束和拥塞被摆到不同位置。逻辑深度相同不代表时序相同,扇出数量相同也不代表负载相同。已有 RTL 模型容易在这里吃亏,因为它们能看到结构,却看不到结构在物理世界中的代价。
这也解释了为什么简单把 RTL 图丢给更深的 GNN 并不够。信息不在图里,模型再复杂也只能猜。RTLDistil 的判断很务实:让学生模型在 RTL 阶段保持轻量,把缺失的物理经验从教师模型里学过来,而不是假装 RTL 自己拥有这些信息。
三、教师懂物理,学生跑得早
整个流程分四步。先从 RTL 抽取 SOG,从 Layout 抽取 Netlist Graph。再用 Layout 数据训练教师模型,让它利用完整物理特征产生高精度 AT。第三步做知识蒸馏,把教师模型内部学到的物理时序表示传给学生模型。学生模型之后还会在下游任务上微调,用来预测 AT、WNS、TNS 等指标。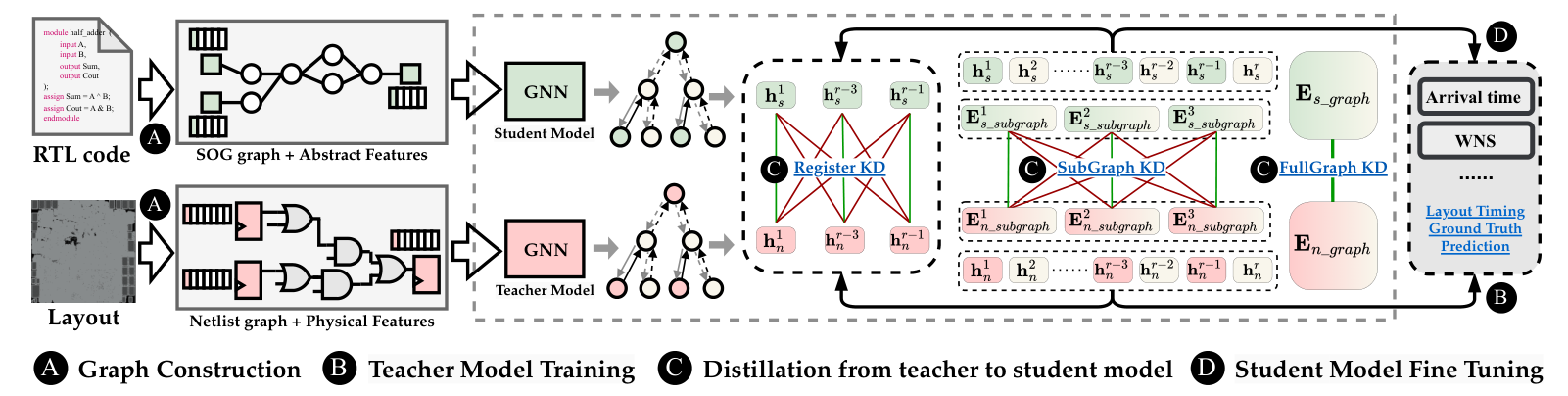
图2:RTLDistil 的双模型流程,教师模型读取 Layout 物理特征,学生模型在 RTL 图上完成快速预测。
来源:原论文 Figure 2,裁剪自 PDF 第 5 页,仅用于论文解读与学术交流。
图2里的关键不只是教师和学生两个模型并排训练,而是两种阶段知识被放在同一条学习链路里。教师模型接受 Layout 图和真实时序标签,学习物理特征到 AT 的映射;学生模型接受 RTL 图,训练时被要求靠近教师的中间表示。这样,学生推理时仍然只需要 RTL 数据,训练时却借用了后端阶段的高保真经验。
学生学到的不是显式寄生参数表。论文没有让模型凭空恢复每条线的 RC,而是让它学习哪些 RTL 结构在教师表示空间里接近高风险时序模式。这个选择更适合早期预测,因为 RTL 阶段无法保证未来布局的每个细节,却可以学习跨设计稳定出现的物理趋势。
两边都用图神经网络,但容量不同。教师模型是更大的 GAT,输出 512 维嵌入,并进行三轮前向和反向异步传播,用来模拟长路径上的延迟累积以及周围电路环境的影响。学生模型也是 GAT,但只输出 128 维嵌入,通常只做两轮前向反向传播,目标是在 RTL 阶段快速推理。
这套设计承认了一个现实:早期预测不是替代 STA。学生模型拿不到完整 Layout 细节,也不该被期待给出 sign-off 结果。它的价值在于把较可信的物理趋势提前给工程师,帮助他们在 RTL 优化中筛出高风险设计。
四、前向反向传播让模型更像在读时序
电路时序不是普通图分类。一个寄存器的 arrival time 受扇入逻辑影响,slack 又和后续路径、约束和负载有关。只沿一个方向传播,容易只看到局部路径,漏掉下游约束。论文因此设计了异步 forward-reverse propagation。前向传播累积路径延迟,反向传播把周围电路和 sink 端反馈带回来。
从信号传播角度看,前向更新把源端到汇端的影响往后传,适合累积路径上的逻辑和延迟;反向更新把汇端附近的约束和负载影响往回带,帮助上游节点理解自己所在路径的压力。普通图神经网络也会聚合邻居,但这里的方向和轮次更贴近电路时序语义。
论文使用异步更新,是因为不同节点在电路拓扑中的深度并不一致。简单同步堆叠消息传递层,可能让某些节点过早或过晚接收关键信息。面向 DPI 和 DPO 的传播安排,把路径深度纳入模型更新节奏,让表示学习更贴近时序传播过程。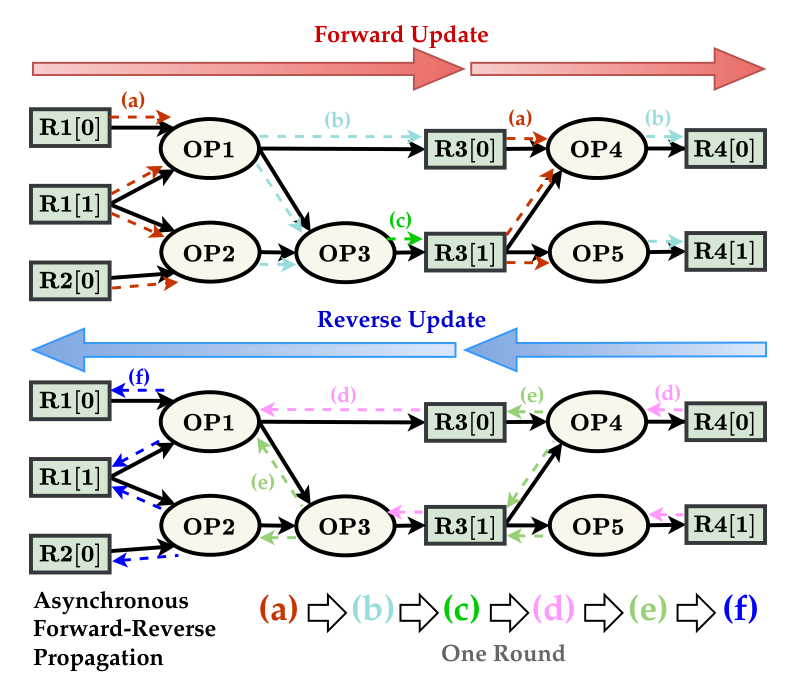
图3:前向和反向异步传播让图神经网络同时看到扇入路径和下游约束。
来源:原论文 Figure 3,裁剪自 PDF 第 5 页,仅用于论文解读与学术交流。
附录 Table 5 进一步说明,传播轮数不是越多越好。两轮 forward plus reverse 在多项相关性指标上更平衡;五轮反而可能放大噪声,TNS 的 MAPE 从 40.18% 增加到 41.58%。这对工程使用很重要。模型不只追求更深,也要控制推理代价和泛化风险。
五、三层蒸馏把物理知识压进 RTL 表示
普通知识蒸馏常让学生模仿教师输出。RTLDistil 没有停在输出层,因为 RTL 和 Layout 的特征空间差得太远。论文把蒸馏拆成三层:寄存器节点、扇入子图、全局电路。三层分别对应时序预测里的三个尺度。
为什么必须分三层?单个寄存器表示能抓住局部属性,但关键路径通常穿过一段组合逻辑;扇入子图能表达局部上下文,却仍可能忽略整张电路的规模和负载分布;全局图表示能校正系统性偏差,但它太粗,不能替代节点级细节。三者组合后,学生模型才有机会同时学到点、线、面的时序线索。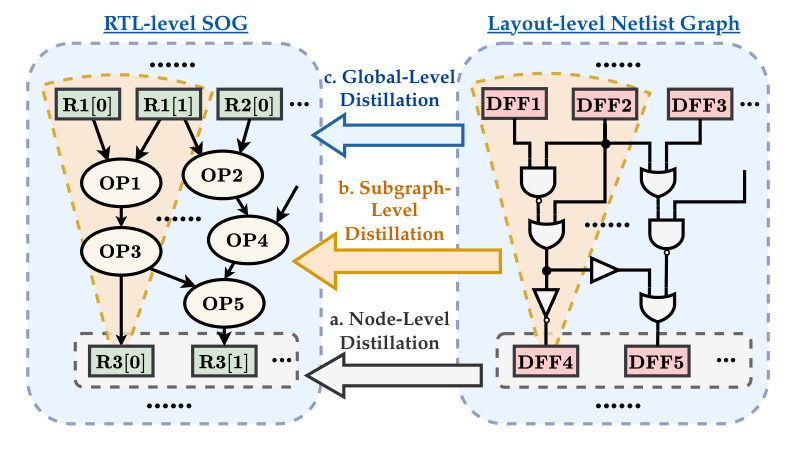
图4:多粒度蒸馏把寄存器、扇入子图和全局电路三层知识传给学生模型。
来源:原论文 Figure 4,裁剪自 PDF 第 6 页,仅用于论文解读与学术交流。
节点级蒸馏对齐每个寄存器或 DFF 的表示。教师输出 512 维,学生输出 128 维,中间用两层 MLP 把学生嵌入映射到教师空间,再用 smooth L1 loss 拉近两者。这个层次让学生学到单个寄存器附近的物理时序属性。
子图级蒸馏关注 fan-in cone。对目标寄存器来说,扇入锥包含一个时钟周期内影响它的组合逻辑。论文用 mean pooling 聚合子图嵌入,再对齐教师和学生表示。这个层次弥补单点对齐的不足,因为时序瓶颈往往不是某个孤立节点,而是一段逻辑结构。
全局级蒸馏处理电路整体分布。不同设计规模、拓扑和关键路径密度会造成系统性偏差,只看局部容易校不准。全局图表示把这类信息纳入训练。最终损失由监督 AT 损失和三类蒸馏损失组成,论文用网格搜索选择节点、子图、全局三项权重,并报告等权重在多任务平均上表现更好。
这里的 fan-in cone 很适合向非算法读者解释。对一个目标寄存器来说,所有能在当前时钟周期内影响它的组合逻辑,都属于这个扇入锥。它相当于工程师看关键路径时会自然圈出来的一片局部电路。RTLDistil 把这片局部电路当成蒸馏对象,避免模型只盯着寄存器本身。
全局级蒸馏则解决另一类问题。两个设计可能局部路径相似,但规模、拓扑密度和关键路径分布不同,最终 WNS 和 TNS 的形态也会不同。把整图表示对齐教师,可以让学生对设计级时序分布有更稳定的判断。
六、实验数字说明了什么
数据集规模不小。论文收集了 2004 个 RTL 设计,来源包括 GitHub、Hugging Face、OpenCore 和 RISC-V 项目,覆盖小型算术模块、DSP 模块和 RISC-V 子系统等。后端流程使用 Synopsys Design Compiler 和 Cadence Innovus,并尝试多组密度、布线约束和时钟约束,直到布局密度不再增加且时序指标稳定收敛。训练、验证、测试按 80%、10%、10% 划分。
实验平台为 8 张 NVIDIA A100 GPU,模型基于 PyTorch 和 PyTorch Geometric,优化器为 Adam,初始学习率 2e-4,batch size 为 8。评价指标覆盖 AT、WNS、TNS,每个任务用 PCC、R2 和 MAPE 衡量。PCC 和 R2 越高越好,MAPE 越低越好。
这个数据构造方式比只跑一个固定后端配置更接近真实项目。实际物理设计不会停在第一版约束上,工程师会试密度、时钟、布线约束和优化开关,直到指标收敛到可接受状态。论文把这种多轮探索纳入数据生成过程,使标签更像一个经过优化后的物理实现结果,而不是某个随意配置下的瞬时结果。
三个指标各有含义。PCC 反映预测和真实值的线性相关性,适合评估模型能否把高低风险排对。R2 衡量模型解释方差的能力,能看整体拟合质量。MAPE 直接看百分比误差,更接近数值精度。早期优化常常先要找出相对风险,因此 PCC 和 R2 对筛选任务很重要;若要给具体余量留安全边界,MAPE 仍然不能忽视。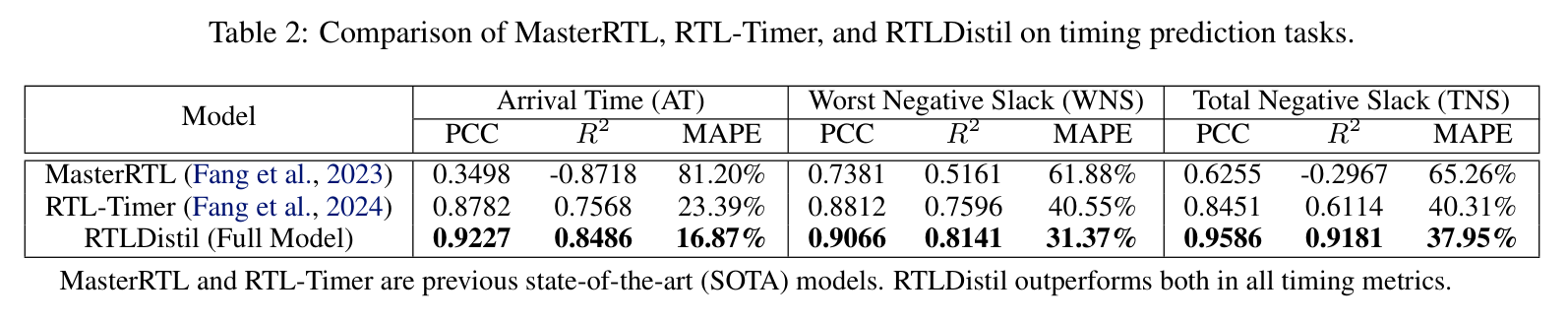
图5:主结果表展示 AT、WNS、TNS 三类任务上的相关性和误差对比。
来源:原论文 Table 2,裁剪自 PDF 第 8 页,仅用于论文解读与学术交流。
MasterRTL 在 AT 上的 R2 为负值,说明它在这个数据集上不仅误差大,解释能力也不稳定。RTL-Timer 把 AT PCC 提到 0.8782,已经明显改善,但 RTLDistil 继续降低 AT MAPE 到 16.87%。这组对比支撑了论文的核心判断:单靠 RTL 结构可以做一部分预测,要接近 Layout 趋势,还需要来自物理阶段的知识迁移。
附录的相关性图提供了另一种观察方式。MasterRTL 和 RTL-Timer 的散点更分散,离理想一比一直线较远;无蒸馏的 RTLDistil 已经收敛一些,加入多粒度蒸馏后点云进一步贴近真实值。散点图比单个表格更直观,因为它能显示模型是否只在平均误差上好看,还是对不同样本都更稳定。
主结果里,RTLDistil 在 AT 上达到 PCC 0.9227、R2 0.8486、MAPE 16.87%。RTL-Timer 对应为 0.8782、0.7568、23.39%,MasterRTL 则为 0.3498、-0.8718、81.20%。在 WNS 上,RTLDistil 的 PCC 是 0.9066,MAPE 是 31.37%;在 TNS 上,PCC 达到 0.9586,R2 达到 0.9181,MAPE 为 37.95%。相对 RTL-Timer,TNS 的 PCC 提升最明显。
Table 3 把教师模型和学生模型拆开看。Layout 教师模型在 AT 上 PCC 0.9797、MAPE 11.20%,代表更接近物理信息上界的表现。没有蒸馏的学生模型 AT MAPE 为 22.04%;完成蒸馏但不微调时降到 17.77%;完整模型进一步到 16.87%。这组数字说明,物理知识迁移确实在补 RTL 信息缺口。
结果也不是每一列都单调变好。Table 3 中,无微调版本的 TNS MAPE 为 33.30%,完整模型为 37.95%,但完整模型在 TNS 的 PCC 和 R2 上更高。对工程读者来说,这意味着不同目标之间存在权衡。若任务更重视排序相关性,完整模型更有吸引力;若某个场景只盯住百分比误差,还需要结合目标指标重新校准。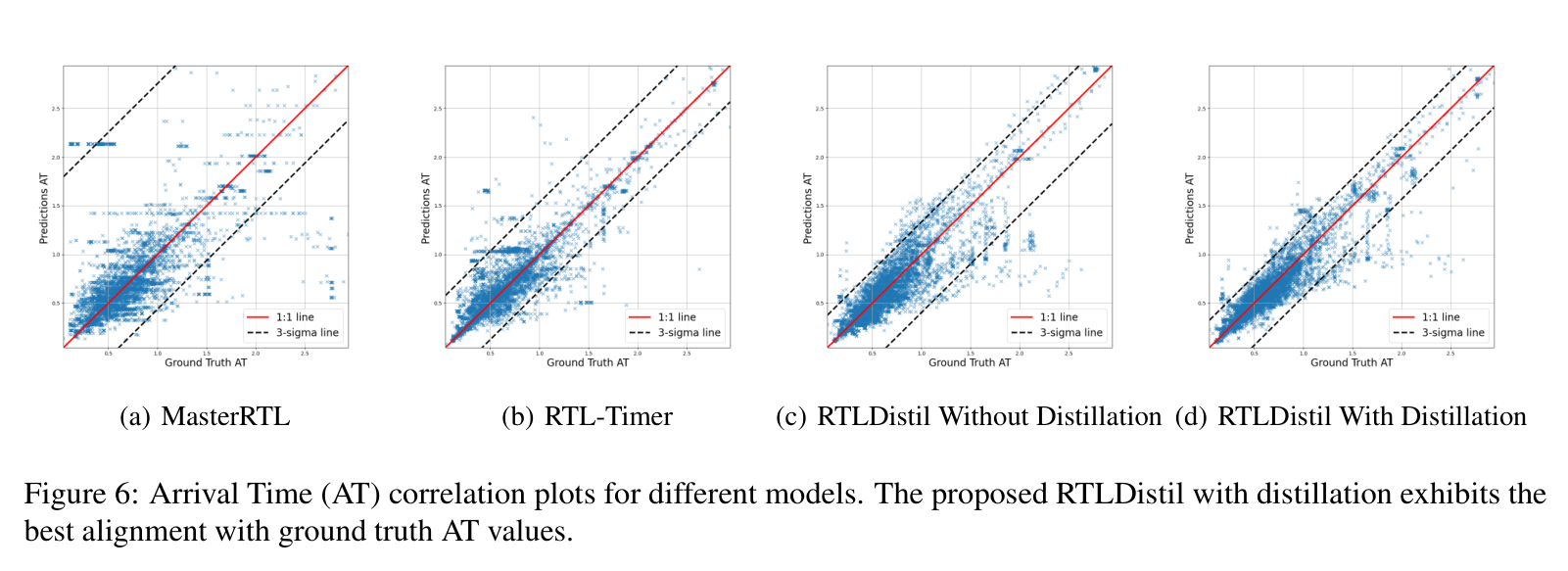
图6:AT 相关性散点图显示,加入蒸馏后的 RTLDistil 与真实值贴合更紧。
来源:原论文 Figure 6,裁剪自 PDF 第 13 页,仅用于论文解读与学术交流。
七、价值和边界
RTLDistil 的价值不在于宣布 RTL 阶段可以替代物理签核,而在于把设计反馈提前。它让早期模型不再只依赖逻辑抽象,而是从 Layout 教师那里继承一部分物理时序经验。对于需要快速筛选 RTL 版本、比较微架构实现、提前定位潜在关键路径的团队,这类模型能缩短探索周期。
把它放进工程流程里,可以想象成一个早期时序雷达。RTL 工程师在多个实现版本之间选择时,可以先用这类模型筛掉明显高风险的结构;架构团队做模块划分时,也能更早看到某些数据通路的压力。后端团队仍然要用 STA 和物理实现确认结果,但早期搜索空间已经被压小。
落地时还有一个现实问题:模型质量依赖训练数据。论文里的数据经过商业工具后端流程生成,并在多组配置下探索到收敛状态。企业内部若要复用类似框架,需要积累与自身工艺库、约束风格和 IP 类型匹配的数据。否则,教师模型学到的物理经验可能和目标项目分布不一致。
消融实验也支持三层蒸馏的必要性。Table 4 显示,完整模型相对无蒸馏基线在三类任务上带来最高的相关性增益,PCC 增益最高 0.0486,R2 增益最高 0.1222。单独使用节点级蒸馏在某些 MAPE 上改善很大,但相关性不如完整组合稳定。子图和全局信息补上了局部方法看不见的上下文。
论文结尾也给出边界:未来还要扩展到更大的 SoC 设计,纳入多时钟域约束,并和功耗、面积等多目标优化结合。工业环境里,工具版本、工艺库、约束写法、设计风格都会改变数据分布。RTLDistil 提供的是一条可行路径,真正落地仍需要围绕目标流程积累高质量训练数据。
结语:早期预测不等于替代 STA
这篇论文最有意思的地方,是它没有把 RTL 时序预测看成一个纯黑盒回归任务。作者把芯片设计流程中的阶段差异显式建模:Layout 教师负责学习真实物理效应,RTL 学生负责在早期快速给出可用判断,三层蒸馏负责把两者连起来。
从结果看,多粒度蒸馏比单纯堆模型更关键。节点、扇入子图和全局电路分别对应工程师分析时序时会看的三个尺度。把这些尺度显式放进训练目标,学生模型才不只是拟合一个标签,而是在学习后端时序分析中真正有用的结构信号。
对 EDA left-shift 来说,这种思路比单纯追求更大的模型更接近工程现实。早期模型不必拥有全部物理细节,但它需要知道哪些物理因素会改变时序趋势。RTLDistil 的贡献就在这里:它把后端阶段昂贵而准确的经验,压缩成 RTL 阶段可以消费的预测能力。
参考资料
图片和表格均裁剪或改编自论文 Bridging Layout and RTL: Knowledge Distillation based Timing Prediction,仅用于论文解读与学术交流。所有方法、实验设置和关键数字均依据原论文整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)