【AI大数据工程师特训笔记】第02讲:PostgreSQL数据库生态全景
目录
3.4 SQL Server / Sybase → tds_fdw
3.11 DocumentDB → documentdb_fdw
4.2 pg_timeseries → pg_timeseries
4.3 temporal_tables → temporal_tables
4.6 table_version → table_version(图中写 table_versic T,应为 typo)
9.3 gzip / zstd → pg_compression
PostgreSQL 是全球最先进的开源关系型数据库之一。你可以把它理解为“数据库界的瑞士军刀”:它既具备 MySQL 那样的基础关系型存储能力,又原生支持处理 JSON 文档、地理空间数据、全文搜索、甚至AI向量等高级功能,无需安装额外插件。与灵活但有时不够严谨的 MySQL 相比,PostgreSQL 严格遵循 SQL 标准,特别强调数据一致性和高并发下的读写安全,是金融、政府、地理信息等对数据准确性要求极高的场景的首选。在AI大模型时代,它凭借插件 pgvector 直接变身向量数据库,让你在同一套系统里既能存业务数据,又能做语义搜索,极大简化了技术架构。
官网链接:PostgreSQL Extension
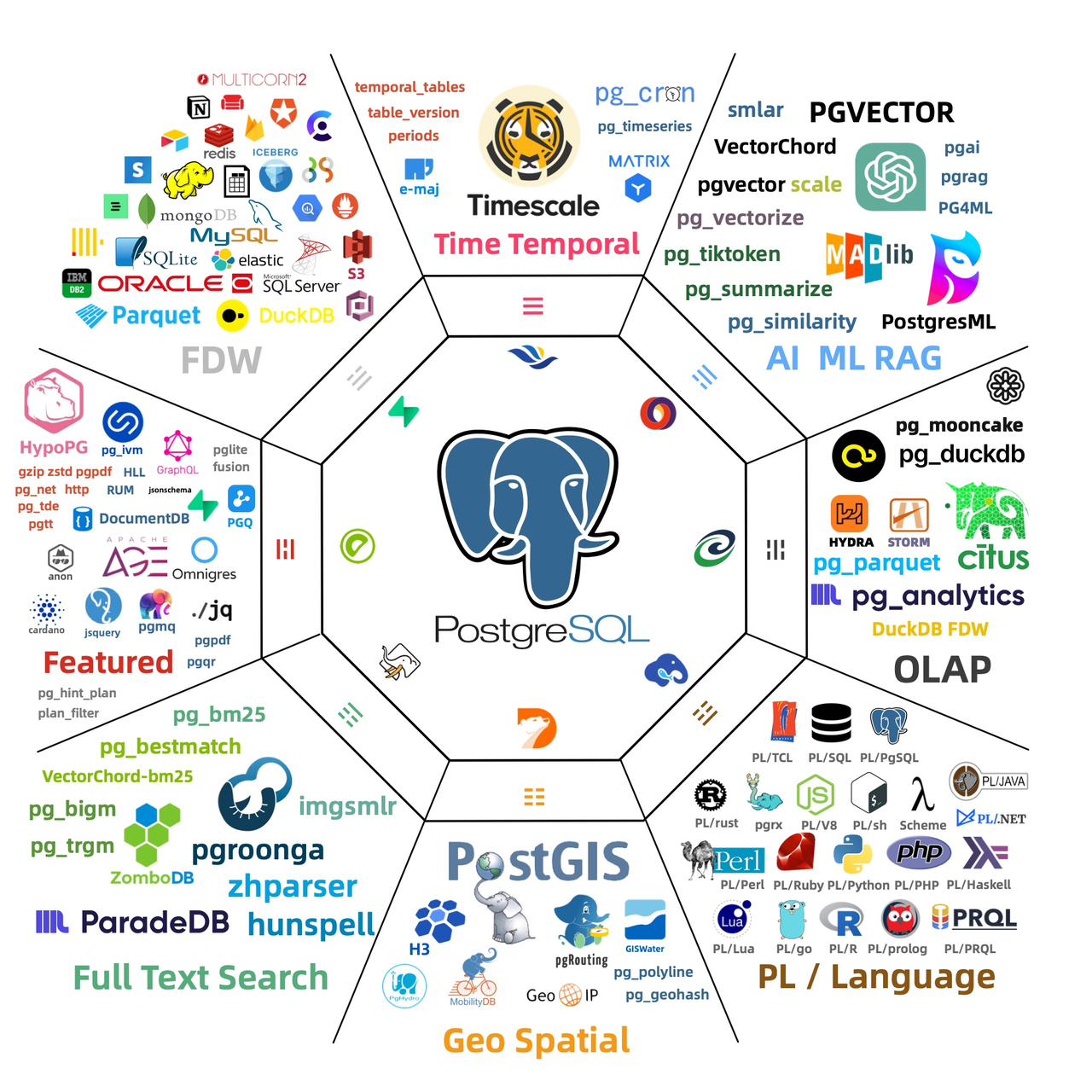
这张图是一张「PostgreSQL 第三方扩展生态全景图」,它把目前社区里 最活跃、最热门 的扩展(含外围工具、FDW、AI/向量、时序、分布式、语言绑定等)用标签云 + Logo的方式堆在一起,方便一眼看清「PG 现在已经能干什么」。
下面按图中从左到右、从上到下的顺序,把每个名字对应的真实扩展/项目、一句话能力、安装方式、官网/仓库逐一解释(冷门或已更名也给出了现用名)。
如果你以后想试用某个能力,直接搜「扩展名 + PostgreSQL」即可找到 rpm/deb 或 docker 镜像。
第一章:生态基石
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
PostgresML |
postgresml |
在 SQL 里训练 XGBoost/LightGBM/LLM,一行 |
|
|
Timescale |
timescaledb |
时序自动分区+压缩+连续聚合,PB 级写入 |
|
|
Citus |
citus |
水平分片分布式 PG,线性扩展 TP/AP |
|
|
PostGIS |
postgis |
地理空间 3000+ 函数、栅格、拓扑、3D |
|
|
pgvector |
pgvector |
高维向量 ANN 搜索,支撑 LLM 语义检索 |
|
1.1 PostgresML
-
扩展名:
postgresml -
核心能力:在 SQL 中直接完成机器学习模型的训练与推理,支持 XGBoost、LightGBM 以及 LLM(大语言模型)。只需执行类似
SELECT train()的单行 SQL 即可触发训练。 -
详解:
-
它将机器学习工作流(特征处理、训练、评估、预测)集成到数据库内部,避免了数据导出到 Python/R 等外部环境的开销和延迟。
-
对于 LLM,可以加载
Hugging Face模型,在 SQL 中调用pgml.embed()生成向量,或使用pgml.transform()进行文本生成、情感分析等。 -
适合希望在数据不离库的前提下快速搭建推荐、分类、回归等模型的场景。
-
Hugging Face 是全球最大的 AI 模型开源社区与协作平台,可以通俗地理解为“AI 界的 GitHub + 应用商店”。它的核心是让开发者能够像下载手机 App 一样,轻松获取、分享和微调数十万个预训练好的 Transformer 模型,覆盖文本、图像、音频等多模态任务。通过其配套的 Transformers、Datasets 等 Python 库,用户只需几行代码即可调用顶尖模型,而无需从头训练。此外,它还提供了模型托管、数据集版本管理、在线推理 API 以及社区协作功能,极大降低了 AI 开发的门槛。
1.2 Timescale
-
扩展名:
timescaledb -
核心能力:面向时间序列数据(如 IoT、监控、金融 tick 数据)的专业优化,提供 自动分区(按时间)、高压缩比、连续聚合,支持 PB 级写入。
-
详解:
-
自动将超大规模时序表拆分为“块”(chunk),每个块按时间间隔(如一天)自动创建,底层仍是 PostgreSQL 表。
-
压缩算法可将时序数据压缩 90% 以上,且支持在压缩数据上直接查询。
-
连续聚合:自动维护物化视图,按小时、天等粒度预计算统计值(均值、最大、最小等),查询速度提升数百倍。
-
写入吞吐可达每秒数百万个数据点,非常适合监控、物联网、DevOps 等场景。
-
1.3 Citus
-
扩展名:
citus -
核心能力:将 PostgreSQL 转换为分布式数据库,通过水平分片(sharding) 将一张表的数据分布到多个节点上,支持线性扩展事务处理(TP)和分析查询(AP)。
-
详解:
-
采用“分片表+协调节点”架构:协调节点接收 SQL,将其拆分为针对各分片的子查询,并行发送给工作节点。
-
支持引用表(全节点复制的小表)与分布表(分片存储的大表),优化 JOIN 性能。
-
对应用透明,大多数标准 SQL 和 ACID 特性仍可保持。
-
能横向扩展至上百节点,处理 TB 至 PB 级数据,适用于 SaaS 多租户、实时分析等场景。
-
1.4 PostGIS
-
扩展名:
postgis -
核心能力:业界最强大的开源地理空间数据库扩展,提供 3000+ 函数 用于空间对象存储、关系判断、测量、投影转换,支持栅格数据、拓扑结构、三维(3D) 模型。
-
详解:
-
定义了
geometry和geography类型,可存储点、线、多边形、几何集合等。 -
空间索引(R-Tree 变体 GIST)实现高效近邻查询、范围搜索。
-
栅格支持:遥感影像、DEM 等网格数据的存储和分析。
-
拓扑扩展:处理共享几何边界(如道路网络、行政区划),避免数据冗余。
-
3D 支持:包含 Z 坐标和 ZM(带测量值)的类型,支持体积计算、三维空间关系。
-
广泛应用于 GIS 系统、位置服务、城市规划、导航等。
-
1.5 pgvector
-
扩展名:
pgvector -
核心能力:为 PostgreSQL 添加高维向量类型及近似最近邻(ANN)搜索能力,常用于 LLM 生成的
embedding的语义检索。 -
详解:
-
提供
vector数据类型(最大支持 16,000 维),以及<=>(余弦距离)、<->(欧氏距离)、<#>(内积)等距离操作符。 -
支持精确搜索(暴力全量计算)与 ANN 索引(IVFFlat、HNSW),大幅加速 top-K 查询。
-
典型用法:将文档、段落或问答对通过 LLM 转为向量存入数据库,用户查询时也转为同一向量空间,然后
ORDER BY 向量距离 LIMIT n快速找到语义最相似的内容。 -
轻量、纯 SQL 接口,无需引入 Elasticsearch 或专用向量数据库,即可在 PostgreSQL 内完成 RAG(检索增强生成)流水线。
-
第二章:AI / 向量 / RAG 区域(蓝色气泡)
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
pgai |
pgai |
把 OpenAI/Claude/HuggingFace 封装成 SQL 函数 |
|
|
pgvector-scale |
pgvectorscale |
基于 DiskANN 的 10 亿级 向量索引 |
|
|
pg_vectorize |
pg_vectorize |
一键 **embedding + 向量索引**(调用 OpenAI) |
|
|
pg_tiktoken |
pg_tiktoken |
在 SQL 里做 tiktoken 分词(GPT 同款) |
|
|
pg_mooncake |
mooncake |
列存+向量混合 OLAP 引擎(大学项目) |
源码 |
|
VectorChord |
vectorchord |
Rust 实现的 HNSW 向量索引,比 pgvector 快 5× |
|
|
pg_bestmatch / pg_bm25 |
paradedb 子扩展 |
Elasticsearch 级 BM25 全文排名 |
|
|
pg_summarize |
pg_summarize |
用 LLM 给长文本生成摘要(SQL 函数) |
|
|
pg_similarity |
pg_similarity |
十余种 **相似度算法**(Jaccard、Cosine、Dice) |
|
|
RAG |
无单独扩展 |
图中泛指 pgvector + 全文 + LLM 组合方案 |
— |
2.1 pgai
-
真实扩展:
pgai -
一句话能力:把 OpenAI / Claude / Hugging Face 等 AI 模型封装成 SQL 函数,在数据库内直接调用。
-
详解:
-
该扩展由 Timescale 团队开发,旨在将大语言模型(LLM)的能力引入 PostgreSQL,而无需额外编排 Python 服务。
-
提供一系列 SQL 函数,例如
ai.generate_text()、ai.embed()、ai.moderation()等,底层通过 API 调用第三方模型。 -
可以方便地将表中数据批量传给 LLM(如情感分类、翻译、摘要),并将结果存回字段,实现 数据增强 或 ETL 流程的 AI 化。
-
支持 OpenAI(GPT‑4、GPT‑3.5)、Claude(Anthropic)、Hugging Face 推理端点等。
-
典型用法:
SELECT ai.generate_text('gpt-4', 'Summarize: ' || content) FROM articles;
-
2.2 pgvectorscale
-
真实扩展:
pgvectorscale(图中写作pgvector-scale) -
一句话能力:基于 DiskANN 算法,构建可处理 10 亿级 向量的高性价比索引。
-
详解:
-
由 Timescale 开发,作为
pgvector的补充扩展,专门解决超大向量集合下的内存瓶颈问题。 -
DiskANN(Disk-based Approximate Nearest Neighbor)是微软提出的 ANN 算法,允许索引主要存储在磁盘上,而非常驻内存,从而支持 10 亿级 的向量规模。
-
相比
pgvector内置的HNSW(常驻内存),pgvectorscale大幅降低了内存成本,同时保持高查询精度和较低的延迟。 -
与
pgvector兼容:复用vector数据类型,但提供独立的索引访问方法(diskann),可通过CREATE INDEX直接创建。 -
适合数据量极大、内存受限的生产环境,如全量商品 embedding、亿级用户画像等场景。
-
2.3 pg_vectorize
-
真实扩展:
pg_vectorize -
一句话能力:一键完成 embedding 生成 + 向量索引构建(默认调用 OpenAI API)。
-
详解:
-
由
Tembo团队开发,目标是简化RAG(检索增强生成)应用的搭建流程。 -
提供
vectorize函数和自动化管道:用户只需提供“待索引的表”、“文本字段”、“唯一 ID”,扩展就会自动调用OpenAItext-embedding-3-small(或其他模型)生成向量,并在pgvector上创建向量索引。 -
同时支持搜索:
SELECT * FROM vectorize.search('job', 'query text', limit => 5); -
内置批处理、重试、进度跟踪,将原本需要数百行 Python 代码的工作简化为几条 SQL。
-
也支持使用
Hugging Face模型或自定义embedding端点。 -
适合快速原型搭建、不希望自己管理
embedding管道的开发者。
-
2.4 pg_tiktoken
-
真实扩展:
pg_tiktoken -
一句话能力:在 SQL 里执行 tiktoken 分词——即 GPT 系列模型使用的同款 tokenizer。
-
详解:
-
tiktoken是 OpenAI 开源的 BPE(字节对编码)分词库,用于计算一段文本对应多少个 token(GPT‑4、GPT‑3.5 等计价单位)。 -
pg_tiktoken将其包装为 PostgreSQL 函数(如tiktoken_count()、tiktoken_encode()),可以直接在 SQL 中计算 token 长度。 -
用途广泛:
-
估算调用 LLM API 的成本(输入/输出 token 数)。
-
提前截断文本以适应模型的上下文窗口。
-
分析数据集中 token 分布,优化 prompt。
-
-
支持多种编码:
cl100k_base(GPT‑4)、p50k_base、r50k_base等。 -
例如:
SELECT tiktoken_count('cl100k_base', 'Hello world!')→ 返回 token 个数。
-
2.5 pg_mooncake
-
真实扩展:
mooncake(图中写作pg_mooncake) -
一句话能力:列存 + 向量混合 OLAP 引擎,目前为 大学研究项目。
-
详解:
-
由清华大学等机构合作开发,目标是在 PostgreSQL 内部提供 高性能分析查询 和 向量检索 的统一引擎。
-
核心特性:
-
列式存储:将表按列存储,配合向量化执行引擎,极大提升聚合扫描效率。
-
向量检索集成:针对 embedding 字段提供优化的近似搜索(如 HNSW 变种),并可与列存数据混合查询。
-
例如:
SELECT * FROM embeddings WHERE vec <-> '[0.1,0.2,...]' < 0.5 AND category = 'A',同时利用列存过滤和向量索引。
-
-
目前状态是“大学项目”,尚未广泛生产使用,但代表 PostgreSQL 在 HTAP(混合事务/分析处理)+ 向量领域的探索方向。
-
2.6 VectorChord
-
真实扩展:
vectorchord -
一句话能力:用 Rust 实现的 HNSW 向量索引,比原生
pgvector的 HNSW 快 5 倍。 -
详解:
-
由 RisingWave 实验室开发,基于 Rust 编写的 PostgreSQL 扩展,旨在提供极致性能的向量索引。
-
使用 HNSW(层次化可导航小世界图)算法,但通过 Rust 的内存管理、SIMD 指令优化、并发控制,获得了比
pgvector的 C++ 实现更优的性能。 -
基准测试显示,在相同召回率(~0.99)下,VectorChord 的查询延迟和吞吐量可达到
pgvectorHNSW 的 5 倍左右。 -
完全兼容
pgvector的vector类型和距离操作符,应用可以无缝切换索引类型。 -
适合对查询速度极度敏感的实时向量检索场景(如推荐系统、动态
embedding搜索)。
-
2.7 pg_bestmatch / pg_bm25
-
真实扩展:属于 ParadeDB 的子扩展(图中写
paradedb 子扩展) -
一句话能力:提供 Elasticsearch 级别的 BM25 全文排名 功能。
-
详解:
-
ParadeDB是一个基于 PostgreSQL 的搜索与分析平台,其核心组件包括pg_bm25(原名pg_bestmatch)。 -
与 PostgreSQL 自带的全文搜索(基于 tsvector/tsquery + TF‑IDF 变体)不同,
pg_bm25实现了完整的 BM25(Okapi BM25) 相关度排名算法,这是现代搜索引擎(如 Elasticsearch、Lucene)的标准。 -
提供
bm25索引类型(基于 GIN 或自定义存储),支持多字段加权、短语搜索、模糊匹配等高级全文功能。 -
可以结合
pgvector做 混合搜索:全文 BM25 得分 + 向量相似度得分,统一排序输出。 -
典型的 RAG 场景:先用 BM25 召回关键词相关的文档,再用向量召回语义相似的文档,最后融合重排。
-
例子:
SELECT * FROM search_idx.search('description:fast database') ORDER BY rank DESC;
-
2.8 pg_summarize
-
真实扩展:
pg_summarize -
一句话能力:使用 LLM 为长文本生成摘要,以 SQL 函数 形式提供。
-
详解:
-
一个轻量级扩展,封装了对大语言模型(如 OpenAI、本地模型)的文本摘要调用。
-
典型函数:
summarize(text, max_length)或summarize_with_model(text, model_name, max_tokens)。 -
执行流程:在 SQL 中直接调用,后台异步或同步请求 LLM API,返回摘要结果。
-
可以结合触发器或定时任务,自动为数据库中的新闻、日志、用户评论生成摘要并存储。
-
注意:依赖外部 LLM 服务,需自行管理 API 密钥和成本;部分版本支持本地模型(如 Ollama)。
-
2.9 pg_similarity
-
真实扩展:
pg_similarity -
一句话能力:提供 十余种字符串相似度算法(Jaccard、Cosine、Dice、Levenshtein…),以 SQL 运算符形式使用。
-
详解:
-
早于 AI 热潮的传统扩展,专注于字符串和集合的相似度比较。
-
支持的相似度函数/运算符:
-
基于集合:Jaccard、Cosine、Dice、Tanimoto
-
基于编辑距离:Levenshtein、Hamming、Monge‑Elkan
-
其他:Q‑Gram、Soundex(语音相似)等
-
-
使用方式:
SELECT 'hello' % 'helo'(%运算符默认代表 Jaccard 相似度阈值)或显式调用similarity_jaccard(text, text)。 -
常用于数据清洗、模糊匹配、实体链接、重复检测等传统数据质量任务。
-
索引支持:可结合 GIN 上的
pg_similarity_trgm加速。
-
2.10 RAG
-
真实扩展:无单独扩展,图中泛指一种 组合方案
-
一句话能力:图中示意 pgvector + 全文搜索 + LLM 三者的结合,实现检索增强生成。
-
详解:
-
RAG(
Retrieval‑Augmented Generation)是一种流行的大模型应用架构:先从知识库中检索与用户问题相关的文档或片段,然后将这些片段作为上下文交给 LLM 生成最终答案。 -
在 PostgreSQL 生态中实现 RAG 通常包括:
-
使用
pgvector存储文档embedding,进行语义检索。 -
使用
pg_bm25(ParadeDB)或 PostgreSQL 原生全文搜索进行关键词检索。 -
将两类检索结果融合(RRF、加权求和等),得到更精准的候选文档。
-
使用
pgai或pg_summarize调用 LLM 生成最终答案。
-
-
图中将“RAG”单独列出,是为了强调整个表格中的工具可以协同工作,最终搭建一个完整而强大的 数据库内 RAG 系统,无需额外引入专用向量数据库或搜索引擎。
-
总结
这一批扩展聚焦于 AI 工程化(生成、嵌入、分词、摘要)和 搜索增强(BM25、多种相似度、高性能向量索引)。它们与上一张图中的 PostGIS、Timescale、Citus 等经典扩展形成互补,让 PostgreSQL 成为能够同时处理 关系型数据、时序、地理空间、向量、全文、LLM 交互 的超级数据库。
第三章:联邦连接器 FDW 区域(橙色气泡)
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
MongoDB |
mongo_fdw |
把 Mongo 集合 当表 JOIN |
|
|
MySQL |
mysql_fdw |
MySQL 表实时联邦查询 |
|
|
SQLite |
sqlite_fdw |
本地 SQLite 文件映射成外表 |
|
|
SQL Server |
tds_fdw |
联机查询 SQL Server / Sybase |
|
|
Oracle |
oracle_fdw |
联机查询 Oracle(支持绑定变量) |
|
|
Redis |
redis_fdw |
Redis 键值当表 GET/SET |
|
|
S3 |
aws_s3 |
|
|
|
Parquet |
pg_parquet |
读写 Parquet 列存文件 |
|
|
Iceberg |
iceberg_fdw |
查询 Iceberg 湖仓表 |
|
|
DuckDB |
duckdb_fdw |
零 ETL 读写 DuckDB 表 |
|
|
DocumentDB |
DocumentDB_fdw |
Azure CosmosDB DocumentDB 兼容接口 |
源码安装 |
这张表格列出了用于 PostgreSQL 与其他数据源/格式之间互联 的 FDW(Foreign Data Wrapper,外部数据包装器)或专用扩展。通过这些工具,PostgreSQL 可以直接查询、Join 甚至写入异构数据源,实现数据虚拟化与联邦查询。
分别用一句话解释 数据虚拟化和联邦查询的含义
数据虚拟化是一种数据整合架构,它的核心思想是“数据不动,逻辑统一”。你可以把它想象成一个超级智能的“数据黄页”或“中间层”,它连接着公司里各种异构的数据源——比如传统的关系型数据库、Hadoop数据湖、云上的对象存储,甚至实时的API接口。当用户发起查询时,这个虚拟层并不会去搬运物理数据,而是实时地将查询指令翻译、拆解并推送到各个底层数据源去执行,最后将返回的结果在内存中聚合、关联,再呈现给用户一个完整的答案。这样一来,数据分析师或应用程序看到的只是一个统一的“虚拟数据库”,完全不用关心原始数据实际存在哪里、是什么格式,从而避免了繁琐的ETL搬运工作和数据冗余。
联邦查询则是指数据库引擎本身所具备的一种高级查询能力,它的重点是“跨源关联,一站完成”。你可以在一条SQL语句中,同时查询来自本地PostgreSQL的用户表、远程MySQL的订单表,甚至是MinIO对象存储里的CSV日志文件,并直接对这些异构数据进行JOIN、过滤和聚合,就像它们在同一个库里一样。这背后得益于FDW这类插件,它像一个“翻译官”,将你SQL中的那部分请求转换成各数据源能懂的方言去执行,然后将各自的结果集取回到PostgreSQL中进行最终的计算汇总。它本质上是在一个查询入口下,实现了跨数据源的关系代数运算。
下面逐项详解:
3.1 MongoDB → mongo_fdw
-
一句话能力:把 MongoDB 集合 当成 PostgreSQL 的外表(foreign table),支持 JOIN。
-
详解:
-
mongo_fdw是 PostgreSQL 的 MongoDB 外部数据包装器,可将 MongoDB 中的每个集合映射为一张外表。 -
支持查询条件下推(WHERE 子句转换为 MongoDB 查询语法),减少网络传输。
-
支持读写操作(INSERT/UPDATE/DELETE),但事务行为受限于 MongoDB 的特性。
-
典型场景:在 PostgreSQL 中通过 SQL 联合查询关系表(如用户订单)和 MongoDB 中的半结构化文档(如用户行为日志)。
-
需要安装 MongoDB C 驱动(libmongoc)并编译扩展。
-
3.2 MySQL → mysql_fdw
-
一句话能力:对 MySQL 表进行实时联邦查询。
-
详解:
-
官方或社区提供的 FDW,允许 PostgreSQL 直接读取(或写入)MySQL 中的表,如同本地表一样。
-
支持 WHERE 条件下推、列裁剪,能利用 MySQL 的索引。
-
支持写操作(需开启对应选项),但分布式事务和两阶段提交能力有限。
-
常用于将 MySQL 中的业务核心表与 PostgreSQL 中的分析/报表表无缝结合,避免 ETL 管道。
-
配置需要指定 MySQL 连接信息、表名及列映射。
-
3.3 SQLite → sqlite_fdw
-
一句话能力:将本地的 SQLite 文件映射为 PostgreSQL 的外部表。
-
详解:
-
允许 PostgreSQL 直接查询
.db或.sqlite文件中的 SQLite 表,无需导入数据。 -
只读还是可写取决于编译版本,多数实现支持读写(注意 SQLite 的锁机制较简单)。
-
非常适用于处理嵌入式应用或桌面软件生成的 SQLite 数据(如浏览器历史、手机备份),让 PostgreSQL 能够利用其高级分析函数(窗口函数、并行查询等)对 SQLite 数据进行加工。
-
配置时在 PostgreSQL 中指定 SQLite 文件路径及表名。
-
3.4 SQL Server / Sybase → tds_fdw
-
一句话能力:联机查询 SQL Server 或 Sybase 数据库。
-
详解:
-
tds_fdw使用 TDS(Tabular Data Stream)协议,这是 SQL Server、Sybase 以及 Azure SQL Database 使用的网络协议。 -
支持跨数据库的只读查询(部分版本也支持写入,但有限制),并能进行 WHERE 条件与 ORDER BY 的下推。
-
可以像本地表一样与 PostgreSQL 的表进行 JOIN,实现异构数据库联邦。
-
典型应用:将 SQL Server 中的遗留业务数据与 PostgreSQL 的数据湖或数仓结合,无需购买昂贵的中间件。
-
需要 FreeTDS 库支持。
-
3.5 Oracle → oracle_fdw
-
一句话能力:联机查询 Oracle 数据库,支持绑定变量以优化性能。
-
详解:
-
由 PGXN 或第三方提供的 FDW,利用 Oracle 的 OCI(Oracle Call Interface)驱动。
-
支持 WHERE 条件、列裁剪、ORDER BY 等下推,并能利用 Oracle 的函数索引。
-
绑定变量支持:能重用 SQL 执行计划,减少 Oracle 端硬解析开销,提升大量小查询的性能。
-
支持读写操作(INSERT/UPDATE/DELETE),但需要正确配置事务行为。
-
常用于将 Oracle 核心交易系统与 PostgreSQL 分析引擎集成,或逐步从 Oracle 迁移到 PostgreSQL 时的混合运行阶段。
-
3.6 Redis → redis_fdw
-
一句话能力:将 Redis 的键值对当成表,通过 SQL 执行
GET/SET操作。 -
详解:
-
redis_fdw将 Redis 中不同数据结构(String、Hash、List、Set、ZSet)映射为 PostgreSQL 的“表”视图。 -
例如:一个 Redis Hash 可映射为一张两列的表(field 和 value);一个 String 键映射为单行单列表。
-
支持简单查询:
SELECT get('user:1001')或SELECT * FROM redis_hash WHERE key = 'user:1001'。 -
通常为只读或有限写入(取决于实现),适合在 SQL 中实时查询 Redis 中的热数据(如 Session、缓存数据),并与 PostgreSQL 中的持久化数据关联。
-
需要 Redis 协议支持(hiredis 客户端库)。
-
3.7 S3 → aws_s3
-
一句话能力:使用 COPY 命令直接读写 S3 对象存储中的文件。
-
详解:
-
aws_s3是 Amazon RDS for PostgreSQL 及 Aurora 提供的扩展,也以aws_s3形式存在于某些自建 PostgreSQL(通过aws_commons辅助)。 -
提供
aws_s3.table_import_from_s3()等函数,允许将 S3 上的 CSV、JSON、Parquet 等格式文件直接导入到 PostgreSQL 表中;反之用aws_s3.query_export_to_s3()将查询结果导出到 S3。 -
性能优秀,支持并行导入/导出,且支持数据压缩和加密。
-
典型用法:数据湖架构中,PostgreSQL 作为 SQL 引擎,直接从 S3 拉取分析数据,避免本地存储膨胀。
-
注意:非 AWS 环境也可通过
s3_fdw实现类似功能,但aws_s3是 AWS 生态最原生的方式。
-
3.8 Parquet → pg_parquet
-
一句话能力:读写 Parquet 列存文件(一种高效的大数据列式存储格式)。
-
详解:
-
pg_parquet扩展允许 PostgreSQL 直接在数据库内部读取和写入 Parquet 文件(本地文件系统或 S3 等)。 -
支持谓词下推(根据 WHERE 条件跳过文件中的 Row Group),列裁剪,因此对分析查询非常高效。
-
可以将 Parquet 文件映射为外表(外部表),查询时实时解析;也可以执行
CREATE TABLE AS将 Parquet 数据导入到 PostgreSQL 本地存储。 -
适用于数据湖架构:Spark、Pandas、DuckDB 等生成的 Parquet 文件可以被 PostgreSQL 直接查询,无需转换。
-
性能比
file_fdw(只处理 CSV/TEXT)强得多,因为利用 Parquet 的元数据和压缩。
-
3.9 Iceberg → iceberg_fdw
-
一句话能力:查询 Apache Iceberg 湖仓表(一种大型分析表格式,支持 ACID 和快照隔离)。
-
详解:
-
iceberg_fdw让 PostgreSQL 能够读取 Iceberg 格式的数据湖表(通常存储在 S3、HDFS 或本地文件系统)。 -
支持 Iceberg 的元数据管理、分区裁剪、列级统计信息下推,从而高效扫描所需数据。
-
由于 Iceberg 常被 Spark、Trino、Flink 等引擎使用,该 FDW 使 PostgreSQL 可以作为“轻量级查询引擎”直接分析数据湖中的数据,适合 BI 报表或即席查询。
-
目前更多见于实验性或商业版本(如 Dremio 的 PostgreSQL 接口),但社区也在完善。
-
3.10 DuckDB → duckdb_fdw
-
一句话能力:零 ETL 读写 DuckDB 数据库文件(.duckdb),实现两种单机分析引擎的无缝交互。
-
详解:
-
DuckDB 是一个嵌入式列式 SQL 引擎,擅长单机 OLAP。
duckdb_fdw允许 PostgreSQL 访问 DuckDB 中的表,反之亦然。 -
支持将 DuckDB 表映射为外表,在 PostgreSQL 中执行
SELECT、INSERT等操作。DuckDB 的列式扫描和压缩不会丢失,PostgreSQL 依然可以下推过滤条件。 -
“零 ETL”意味着不需要将 DuckDB 数据导入 PostgreSQL 或导出 CSV 再加载,直接通过 FDW 桥接。
-
典型场景:数据科学家用 DuckDB 快速预处理大数据集后,业务分析师用 PostgreSQL(通过 FDW)直接查询结果,避免数据搬迁。
-
3.11 DocumentDB → documentdb_fdw
-
一句话能力:连接 Azure Cosmos DB 的 DocumentDB 兼容接口(NoSQL JSON 文档数据库)。
-
详解:
-
Azure Cosmos DB 的 DocumentDB API 是一种 JSON 文档存储,支持 SQL-like 查询。
-
documentdb_fdw将 DocumentDB 中的“文档集合”映射为外表,支持 PostgreSQL 中SELECT查询(通常转换为 DocumentDB 的查询语法)。 -
可以抽取文档中的特定字段,映射为表的列(JSON 路径提取),并支持 WHERE 条件下推。
-
适用于在 PostgreSQL 中统一查询关系数据和 Azure 云上的 NoSQL 数据,实现混合数据治理。
-
注意:该扩展可能由第三方维护,不如 AWS 的 S3 集成成熟,但对于 Azure 用户很有价值。
-
总结
这一组 FDW 和扩展将 PostgreSQL 变成了数据联邦的中枢,能够连接包括 NoSQL(MongoDB、Redis、DocumentDB)、关系型(MySQL、SQL Server、Oracle、SQLite)、云存储(S3)、列式格式(Parquet、Iceberg)、嵌入式分析引擎(DuckDB)在内的多种数据源。通过 SQL 统一访问,无需复制或迁移数据,大大降低了数据孤岛问题,非常适合数据虚拟化、湖仓一体和混合云架构。
第四章:时序 / 分区 / 临时表
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
Timescale |
timescaledb |
见上文 |
— |
|
pg_timeseries |
pg_timeseries |
轻量级 时间桶 + 连续聚合(无需 Timescale) |
|
|
temporal_tables |
temporal_tables |
AS OF 时点查询,自动记录有效期 |
|
|
periods |
pg_periods |
SQL:2011 SYSTEM_TIME / APPLICATION_TIME 周期表 |
|
|
pgtt |
pgtt |
Oracle 风格 全局临时表 |
|
|
table_version |
table_version |
行级 版本历史 + 闪回(类似 Oracle Flashback) |
|
|
e-maj |
emaj |
快照式 表级回滚,误删恢复 |
|
上述表格展示了 PostgreSQL 在时间序列、临时表、数据版本控制与闪回 等领域的扩展,补足了原生数据库在“记录变更历史、时态查询、临时数据隔离”方面的不足。下面逐项详解:
4.1 Timescale → timescaledb
-
一句话能力:见第一张图详解(时序自动分区+压缩+连续聚合,PB级写入)。
-
简述:业界最成熟的时间序列扩展,提供超表(hypertable)、压缩、连续聚合等高级功能。由于前文已详细说明,此处不再重复。
4.2 pg_timeseries → pg_timeseries
-
一句话能力:轻量级时间桶 + 连续聚合,无需安装 Timescale 即可实现基础时序能力。
-
详解:
-
pg_timeseries是一个更简单、轻量的时序数据扩展,不依赖 Timescale 的复杂机制。 -
核心功能:
-
时间桶(Time Bucket):提供
time_bucket()函数,将时间戳按任意间隔(1分钟、1小时等)分组,方便聚合统计。 -
连续聚合:支持物化视图或自动更新的聚合表(但实现比 Timescale 简化)。
-
自动分区:基于时间范围的分区管理(可结合原生声明式分区)。
-
-
适合不需要 Timescale 全部特性(如压缩、高级 chunk 管理)的场景,仅需简单的时间分组和滚动聚合。
-
通常作为纯 SQL 函数集合,依赖少,易于嵌入。
-
4.3 temporal_tables → temporal_tables
-
一句话能力:实现 AS OF 时点查询,自动记录行级有效期(valid time)。
-
详解:
-
该扩展实现 事务时间(transaction time) 或 有效时间(valid time) 的时态表。
-
工作原理:为表自动增加
sys_start和sys_end两个时间戳列,记录每一行的有效期。当对行进行 UPDATE 或 DELETE 时,旧行不会物理删除,而是将sys_end设为当前时间(表示失效),并插入新行(带新的有效期)。 -
查询时使用
AS OF <timestamp>语法,自动过滤出在指定时间点有效的行。 -
例如:
SELECT * FROM accounts AS OF '2025-01-01' WHERE id = 100;返回该账户在 2025 年 1 月 1 日时的状态。 -
与 PostgreSQL 原生的
system-versioned不同,此扩展完全由触发器实现,不依赖FOR ALL SYSTEM_TIME(PG 16+ 实验性功能)。 -
常用于审计、历史追溯、慢变维度(SCD Type 2)等场景。
-
4.4 periods → pg_periods
-
一句话能力:支持 SQL:2011 标准的 SYSTEM_TIME 和 APPLICATION_TIME 周期表。
-
详解:
-
pg_periods是第三方扩展,对标 SQL 标准中的 时态表(temporal tables) 概念,比temporal_tables更接近标准。 -
提供两种周期:
-
SYSTEM_TIME:由数据库自动维护行的事务时间(即行的版本有效期),一般通过隐藏列row_start/row_end实现。 -
APPLICATION_TIME:用户定义的业务有效时间(如保险合同生效期、商品促销时段),列由用户显式声明。
-
-
支持标准语法:
-
FOR SYSTEM_TIME AS OF ... -
FOR SYSTEM_TIME BETWEEN ... AND ... -
FOR PORTION OF ...(用于修改特定时间范围内的行)
-
-
使用
PERIOD定义周期,并利用排除约束避免时间重叠。 -
目前尚未完全集成到 PostgreSQL 内核,需要该扩展来获得符合 SQL:2011 的体验,适合需要严格遵守标准的企业应用。
-
4.5 pgtt → pgtt
-
一句话能力:提供 Oracle 风格的全局临时表(Global Temporary Table)。
-
详解:
-
PostgreSQL 原生支持会话级临时表(
CREATE TEMP TABLE),但每次会话都需要创建,且表定义随会话结束可能消失(取决于配置)。 -
pgtt模拟 Oracle 的全局临时表行为:-
表定义是持久的(所有会话可见),但数据是会话隔离的。
-
支持两种清理模式:
-
ON COMMIT DELETE ROWS:事务提交后清空数据。 -
ON COMMIT PRESERVE ROWS:会话结束才清空数据。
-
-
不同会话插入的数据互相不可见。
-
-
适合存储中间计算结果、ETL 过程临时数据,避免多个会话重复创建相同结构的临时表。
-
实现方式:使用后台进程和本地临时表模拟,性能接近原生临时表。
-
4.6 table_version → table_version(图中写 table_versic T,应为 typo)
-
一句话能力:实现行级版本历史 + 闪回(Flashback),类似 Oracle 的 Flashback Query。
-
详解:
-
该扩展记录表中每一行的完整变更历史(通过触发器在单独的版本表中存储旧行)。
-
核心能力:
-
闪回查询:可以查询任意历史时间点的数据状态,如
SELECT * FROM accounts AS OF TIMESTAMP '2025-01-01 10:00:00'; -
行级版本号:每行附带
version字段,可查看某行随时间的演变。 -
恢复到历史点:支持将表整体恢复到过去某个时刻的快照(需结合备份或 undo 日志)。
-
-
与
temporal_tables不同在于:它更专注于“误操作恢复”,而非连续的时态查询。用户可启用“回收站”功能,DROP TABLE后还能闪回。 -
对于需要审计且不希望使用大规模 WAL 日志解析的场景很有用,但性能开销较大(每 DML 都写版本表)。
-
4.7 e-maj → emaj
-
一句话能力:快照式表级回滚,支持误删数据恢复,细粒度到表。
-
详解:
-
e-maj(Enhanced MAJ)是一个功能强大的表级日志与回滚扩展,由法国邮政等机构开发并用于生产。 -
工作原理:
-
对一组需要保护的“表组”启用记录,系统会通过触发器将所有变更(INSERT/UPDATE/DELETE)写入日志表。
-
可以创建命名快照(snapshot),记录表组在某个时刻的完整状态(逻辑备份,但增量存储)。
-
支持回滚到任意已创建的快照,甚至可以在回滚前预览差异。
-
-
主要特点:
-
支持细粒度选择:只记录特定表组,避免全部表开销。
-
提供
emaj_rollback()函数,可闪回表组到任意快照,覆盖误操作。 -
与 Oracle 的 Flashback Table 类似,但完全由 PostgreSQL 触发器实现,不依赖 undo 表空间。
-
日志可独立存储(另一 schema 或另一数据库)。
-
-
适用于需要经济、细粒度的 DML 灾难恢复,但不希望使用 PITR(点时间恢复)重放整个 WAL 的场景。
-
总结
这组扩展重点解决 PostgreSQL 在 时间序列存储(轻量 pg_timeseries vs 重型 timescaledb)、时态查询与标准周期表(temporal_tables、pg_periods)、临时表管理(pgtt)以及 数据版本与闪回(table_version、emaj)方面的需求。它们弥补了企业级应用中常见的审计、回滚、会话隔离数据等实用功能,丰富了 PostgreSQL 在数据生命周期管理上的能力。
第五章:分布式 / OLAP / 列存
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
Citus |
citus |
见上文 |
— |
|
Hydra |
hydra |
开源列存 + 向量执行,Snowflake 风格 |
|
|
OmniGres |
omnigres |
把 PG 变 **应用服务器**(JS、Web 框架) |
源码 |
|
pg_analytics |
hydra 子扩展 |
列存 + 向量化执行引 |
|
|
pg_mooncake |
mooncake |
大学项目,列存+向量混合 |
源码 |
|
STORM |
stormdb |
早期 GPU 加速 OLAP 分支 |
已归档,可忽略 |
|
DuckDBFDW |
duckdb_fdw |
见 FDW 区 |
— |
下面详细解释图中列出的每个扩展/项目,重点介绍其核心功能、技术特点及适用场景。部分条目(如 Citus、duckdb_fdw)在之前已有说明,此处会进行简要回顾并补充新的视角。
5.1 Citus
-
真实扩展:
citus -
一句话能力:见上文(水平分片分布式 PG,线性扩展 TP/AP)
-
补充详解:
-
Citus 将 PostgreSQL 转换为分布式数据库,通过分片表和协调节点实现水平扩展。
-
支持两种分布策略:哈希分片(适合多租户、实时分析)和引用表(小表全节点复制)。
-
对应用透明,兼容大多数 SQL 和 ACID 特性。
-
适用于 SaaS、物联网、实时数仓等需要横向扩展数据量和写入吞吐的场景。
-
商业版提供更多管理工具,但核心功能已在开源版中可用。
-
5.2 Hydra
-
真实扩展:
hydra(原 Hydra Database,现多指由 “Hydra 项目” 衍生的一整套列式存储与向量化执行能力) -
一句话能力:开源列存 + 向量执行,Snowflake 风格。
-
详细解释:
-
Hydra 是一个基于 PostgreSQL 的扩展集(早期为独立分支),核心目标是让 PostgreSQL 获得列式存储和向量化查询执行能力,以提升 OLAP 性能。
-
列式存储:数据按列而非行存储,适合分析查询(只读取需要的列,压缩率高)。
-
向量化执行:一次处理一批数据(例如 1024 行),利用 CPU 的 SIMD 指令加速,相比传统火山模型逐行处理有显著性能优势。
-
Snowflake风格指类似 Snowflake 等云数仓的架构:PostgreSQL 负责元数据和 SQL 解析,Hydra 扩展提供列存引擎。 -
实际形态:
Hydra项目已与pg_analytics扩展合并,后者作为独立的列存+向量化引擎,可被任何 PostgreSQL 数据库加载(见下一条)。 -
适合需要将 PostgreSQL 用于分析型负载,但又不想迁移到专用列存数据库的用户。
-
5.3 OmniGres
-
真实扩展/项目:
omnigres -
一句话能力:把 PostgreSQL 变成应用服务器(支持 JavaScript、Web 框架)。
-
详细解释:
-
OmniGres 是一个野心勃勃的项目,旨在让 PostgreSQL 不仅可以管理数据,还能直接运行应用逻辑,成为类似 Database as a Platform 的运行时。
-
核心组件:
-
内置 JavaScript 引擎:使用 Mozilla SpiderMonkey 或类似引擎,允许在数据库内执行 JS 函数。例如
CREATE FUNCTION hello() RETURNS text LANGUAGE js AS $$ return "Hello"; $$; -
Web 服务器:通过
omni_httpd扩展,让 PostgreSQL 直接监听 HTTP 端口,处理 REST API 请求。请求可以触发 SQL 查询并返回 JSON。 -
Web 框架:提供类似 Express.js 的路由、中间件、模板渲染等能力,完全在数据库进程中运行。
-
-
优势:消除应用与数据库之间的网络开销;利用数据库的事务、持久性、安全机制;简化架构(不需要单独的 Node.js/Java 应用服务器)。
-
局限:将计算和存储紧密耦合,可能影响扩展性;JS 执行稳定性需额外注意。
-
适用于边缘计算、嵌入式应用、内部工具等场景,也可以作为 “Database as a Service” 的控制平面。
-
5.4 pg_analytics
-
真实扩展:
pg_analytics(原为 Hydra 项目的子扩展,现已可独立使用) -
一句话能力:列存 + 向量化执行引擎(Hydra 的核心分析能力)。
-
详细解释:
-
pg_analytics是 Hydra 项目拆解出来的纯分析扩展,不依赖 Hydra 的其他部分。 -
提供 列式表(
CREATE TABLE ... USING columnar),数据按列存储并自动压缩,压缩比通常为 3-10 倍。 -
向量化执行:查询时采用批处理模型,利用 SIMD 指令加速扫描、聚合、过滤等操作。
-
支持与行存表混合使用,可以对列存表进行 UPDATE/DELETE(但性能不如行存)。
-
集成 PostgreSQL 的查询计划器,但对分析查询做了专门优化(如延迟物化、谓词下推到列扫描)。
-
性能对比:在典型星型模型查询中,比原生 PostgreSQL 行存快 5-20 倍,接近专用的 ClickHouse 或 DuckDB。
-
适合在同一个 PostgreSQL 实例中同时处理 OLTP(行存)和 OLAP(列存)的 HTAP 场景。
-
5.5 pg_mooncake
-
真实扩展:
mooncake(图中写作pg_mooncake) -
一句话能力:大学项目,列存 + 向量混合(已在上一张图详解过)。
-
补充强调:
-
是由清华大学等机构合作的研究项目,尚未进入生产阶段。
-
独特卖点:列式存储与向量检索深度融合,支持在一个表中既有普通列(列存)又有高维向量列,查询时能同时利用列存过滤和向量索引。
-
例如:
SELECT * FROM products WHERE price < 100 AND embedding <-> '[0.1,0.2,...]' < 0.5;可高效执行,而传统方案需要分别扫描或用两个数据库合并结果。 -
代表了 HTAP + 向量数据库的融合趋势,但稳定性和生态还需时间检验。
-
5.6 STORM
-
真实扩展/项目:
stormdb(图中写作STORM) -
一句话能力:早期 GPU 加速 OLAP 分支(已停滞)。
-
详细解释:
-
STORM 是约 2015-2018 年间的一个 PostgreSQL 分支(或补丁集),目标是在数据库内部利用 GPU(CUDA) 并行加速分析查询。
-
主要工作:修改执行器,将部分扫描、聚合、JOIN 操作编译为 GPU 内核,以数千个线程并行处理。
-
当时在 TPC-H 基准测试中取得了 10 倍以上加速,但受限于:
-
GPU 与 CPU 之间数据拷贝开销大。
-
需要 GPU 常驻,不适合云环境。
-
开发复杂度高,难以与 PostgreSQL 主分支合并。
-
-
最终项目不再维护,其思想被更现代的方法(如向量化 + SIMD)取代。
-
目前若要使用 GPU 加速 SQL 分析,更常见的是使用 Spark + RAPIDS 或专用数据库(如 OmniSci/HeavyDB),而非基于 PostgreSQL。
-
5.7 DuckDBFDW
-
真实扩展:
duckdb_fdw -
一句话能力:见 FDW 区(零 ETL 读写 DuckDB 表)。
-
补充详解:
-
如前所述,
duckdb_fdw让 PostgreSQL 能够直接查询 DuckDB 的数据库文件(.duckdb)。 -
DuckDB 本身是嵌入式列式分析引擎,处理本地 Parquet/CSV 效率很高。
-
结合 PG 的 FDW 机制,可以实现:
-
在 PostgreSQL 中联合查询 DuckDB 里的中间分析结果。
-
利用 DuckDB 读取 Parquet 文件,然后通过 FDW 暴露给 PG,绕过 PG 不能直接高效读 Parquet 的限制。
-
-
性能:由于 DuckDB 列式扫描速度快,并且 FDW 支持下推,许多查询可以完全在 DuckDB 中执行,只返回最终聚合结果给 PG。
-
非常适合分析工程师和 DBA 协作的场景:数据科学家用 DuckDB 做探索性分析,分析师用熟悉的 SQL 通过 PG 直接访问这些结果。
-
总结
这组扩展展示了 PostgreSQL 在分析能力扩展方面的多种探索路径:
-
分布式:Citus 将 PG 横向扩展。
-
列存/向量化:Hydra / pg_analytics 提供 Snowflake 风格分析引擎;pg_mooncake 增加向量混合;DuckDBFDW 借用外部列存引擎。
-
应用平台化:OmniGres 将 PG 变为应用服务器。
-
历史探索:STORM 尝试 GPU 加速但未成功。
这些项目(除 Citus 生产成熟外)大多处于早期或研究阶段,但它们共同预示着 PostgreSQL 在 HTAP、向量数据库、甚至在数据库内运行完整应用程序方面的未来潜力。
第六章:全文 / 相似度 / 搜索
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
pg_trgm |
pg_trgm |
三元索引,LIKE '%abc%' 提速百倍 |
|
|
pgroonga |
pgroonga |
多语言 全文 + 短语 + 排名 |
|
|
RUM |
rum |
全文+JSON 混合索引,phrase + ranking |
|
|
pg_bigm |
pg_bigm |
2-gram 加速 日文/中文 模糊搜索 |
|
|
zhparser |
zhparser |
结巴分词 + GIN 中文全文 |
|
|
hunspell |
hunspell_dict |
拼写纠错全文字典 |
|
|
smlar |
smlar |
多种 相似度聚合(Jaccard/Cosine) |
|
|
pg_similarity |
pg_similarity |
同上,算法更多 |
|
|
ZomboDB |
zombodb |
Elasticsearch 联合索引,SQL 直接返回 ES 排名 |
|
|
ParadeDB |
paradedb |
基于 Tantivy 的 Rust 全文引擎(BM25) |
|
这张表格主要涵盖 全文搜索、模糊匹配、相似度算法、拼写纠错 以及 与外部搜索引擎(ES)集成 的 PostgreSQL 扩展。这些工具增强了 PostgreSQL 在非结构化文本检索、多语言支持、近似字符串匹配等方面的能力,弥补了原生 tsvector/tsquery 的不足。下面逐项详解:
6.1 pg_trgm → pg_trgm
-
真实扩展:
pg_trgm -
一句话能力:利用 三元组(trigram)索引,让
LIKE '%abc%'类通配符查询提速百倍。 -
详解:
-
pg_trgm是 PostgreSQL 官方提供的扩展,将字符串分解为连续的三个字符的组(trigram),并建立 GIN 或 GiST 索引。 -
加速的查询模式包括:
-
LIKE '%keyword%'(前后都有通配符) -
ILIKE(大小写不敏感) -
正则表达式(简单情况)
-
文本相似度运算符
%、<%等。
-
-
原理:通过索引快速筛选出可能匹配的行(要求 trigram 重叠),再对候选行进行精确检查,避免全表扫描。
-
适用场景:用户输入搜索词、日志分析、代码片段查找等需要任意位置模糊匹配的场景。
-
限制:不支持像全文搜索那样的词干、排名;主要用于字符级的模糊匹配。
-
6.2 pgroonga → pgroonga
-
真实扩展:
pgroonga -
一句话能力:多语言 全文 + 短语 + 排名,支持日文、中文等没有自然单词边界的语言。
-
详解:
-
pgroonga是基于 Groonga 引擎的 PostgreSQL 扩展,提供远比原生tsvector强大的全文搜索能力。 -
关键特性:
-
所有语言支持:Groonga 本身支持日语、中文等,通过分词器(如 MeCab)正确处理中文、日文的词组边界。
-
短语搜索:支持
"exact phrase"原样搜索,而原生 tsquery 需要转换为phrase操作符(不够直观)。 -
高排名算法:支持 TF-IDF 和 BM25 加权排名,结果按相关度排序。
-
实时索引:数据插入后立即可查,无需等待
REINDEX。 -
多种数据类型:不仅能搜索文本,还可以对数组、JSON 等类型进行全文匹配。
-
-
性能:在几百万行数据上可实现毫秒级响应。
-
适用场景:需要强大全文搜索、支持多语言、实时性要求高的应用(如论坛、CMS、企业搜索)。
-
6.3 RUM → rum
-
真实扩展:
rum -
一句话能力:全文 + JSON 混合索引,支持 短语搜索(phrase) 和 排名(ranking),比 GIN 更优。
-
详解:
-
rum是对 PostgreSQL 原生 GIN 索引的增强,专为全文搜索设计,解决 GIN 索引中获取排名和短语位置时的性能问题。 -
主要优势:
-
加速排序:GIN 索引只返回匹配行,但排序需要重新计算相关性;RUM 索引在叶子节点中预先存储位置信息和权重,可以直接根据排名排序,避免回表。
-
加速短语搜索:对于
phrase(如foo <-> bar要求相邻),RUM 可以利用存储的位置信息快速判断,而 GIN 需要额外过滤。 -
支持 JSON/JSONB 的全文搜索:可以对 JSON 中的文本字段建立 RUM 索引,并进行短语和排名查询。
-
支持
tsvector+timestamp等混合排序:例如按全文匹配度 + 时间倒排的复合排序。
-
-
缺点:索引体积比 GIN 大,更新开销稍高。
-
适合高性能全文检索应用,尤其是需要按相关度排序且数据量大的场景。
-
6.4 pg_bigm → pg_bigm
-
真实扩展:
pg_bigm -
一句话能力:使用 2-gram(二元组) 加速日文、中文等语言的模糊搜索。
-
详解:
-
pg_bigm是面向 CJK(中日韩)字符优化的模糊搜索扩展,类似于pg_trgm但使用 2-gram 而非 3-gram。 -
为什么用 2-gram?
-
中文和日文字符数量巨大,且没有单词分隔符;2-gram 可以覆盖所有双字组合,而 3-gram 在短文本上匹配率较低,且索引更大。
-
对双字节字符集,2-gram 的区分度足够好。
-
-
支持与
pg_trgm类似的运算符:LIKE、ILIKE、%(相似度)、@@(全文搜索的简化版)。 -
索引类型:GIN 或 GiST。
-
性能:在处理中文用户输入(如搜索“数据仓库”时,允许漏字、错序)时比
pg_trgm更有效。 -
限制:只支持 UTF-8 编码,英文效果不如
pg_trgm。
-
6.5 zhparser
-
真实扩展:
zhparser -
一句话能力:基于结巴分词的
GIN中文全文解析器,使 PostgreSQL 原生全文搜索支持中文。 -
详解:
-
zhparser是一个自定义的tsconfig分词器,内部使用 结巴分词(jieba) 库将中文文本切分成词。 -
安装后,可以创建中文全文搜索配置:
CREATE TEXT SEARCH CONFIGURATION chinese (PARSER = zhparser); ALTER TEXT SEARCH CONFIGURATION chinese ADD MAPPING FOR n,v,a,i,e,l WITH simple; -
然后使用
to_tsvector('chinese', '我爱北京天安门')得到词位列表。 -
支持简体、繁体;可以配置用户字典,添加专业术语。
-
相比
pgroonga,zhparser更轻量,完全集成在 PG 的全文框架内,可以和tsquery、排名函数ts_rank协同工作。 -
适合需要中文全文检索,但又不想引入外部引擎(如 Elasticsearch)或额外扩展(如 pgroonga)的场景。
-
6.6 hunspell_dict → hunspell
-
真实扩展:
hunspell_dict(图中拼写为hunspehll_dict) -
一句话能力:提供拼写纠错全文字典,用于模糊匹配和自动建议。
-
详解:
-
PostgreSQL 的全文搜索支持使用 Ispell 或 Hunspell 字典。Hunspell 是开源拼写检查库(用于 OpenOffice、Firefox 等)。
-
通过创建
hunspell字典,可以在tsvector生成时进行:-
词形归并:将变体(如 “running”、“ran”)归并为基本形式(“run”)。
-
拼写错误纠正:内置常见错误映射,提高搜索召回率。
-
-
需要先安装 Hunspell 字典文件(如英语
en_us),并在 PostgreSQL 中配置:CREATE TEXT SEARCH DICTIONARY hunspell_en ( TEMPLATE = ispell, DictFile = en_us, AffFile = en_us, StopWords = english ); -
优点:提高全文搜索的鲁棒性,用户即使拼错个别字母也能匹配到正确文档。
-
缺点:只支持西方语言(有 Hunspell 字典的语言),不支持中文。
-
6.7 smlar → smlar
-
真实扩展:
smlar -
一句话能力:提供多种相似度聚合函数(Jaccard、Cosine),适用于数组或集合。
-
详解:
-
smlar是一个专门计算数组或向量之间相似度的扩展,常用于标签系统、特征向量匹配。 -
支持的相似度算法:
-
Jaccard:交集大小 / 并集大小(适合集合)
-
Cosine:余弦相似度(适合向量)
-
Dice:
2*|交集| / (|A|+|B|) -
Overlap:交集大小
-
-
提供的运算符:
%(Jaccard 相似度)、%%(Cosine)、@>、<@等。 -
索引支持:GIN 索引可以加速
%查询,例如筛选与目标数组相似度大于阈值的行。 -
典型用法:推荐系统(用户兴趣标签匹配)、搜索引擎(文档关键词集合相似度)、数据清洗(重复记录检测)。
-
注意:
smlar比pg_similarity更专注于数组/集合的相似度,而非字符串。
-
6.8 pg_similarity
-
真实扩展:
pg_similarity -
一句话能力:同上,但算法更多(已在第三张图详解过,此处简要补充)。
-
补充:
-
pg_similarity提供 十余种字符串相似度算法,包括 Jaccard、Cosine、Dice、Levenshtein、Hamming、Monge-Elkan、Q-Gram 等。 -
以 SQL 运算符形式使用,如
'hello' % 'helo'可自定义默认算法。 -
相比
smlar,pg_similarity更侧重字符串(text/varchar)的相似度,而非数组。 -
适合模糊字符串匹配、实体对齐、爬虫去重等任务。
-
6.9 ZomboDB → zombodb
-
真实扩展:
zombodb -
一句话能力:创建 Elasticsearch 联合索引,SQL 查询直接返回 ES 排名,无缝集成。
-
详解:
-
zombodb让 PostgreSQL 表在 Elasticsearch(或 OpenSearch)中自动建立索引,并提供统一的查询接口。 -
工作原理:
-
对 PostgreSQL 表创建
zombodb索引时,扩展会自动将表中的行异步发送到 Elasticsearch 建立索引。 -
之后,你可以使用 SQL 中的
WHERE zdb('table_name', 'query_string')或=>运算符进行全文搜索,排名结果直接从 ES 获取,并可与 PostgreSQL 的列过滤、JOIN 混合。
-
-
优势:
-
利用 ES 的强大全文能力(BM25、短语、模糊、高亮、聚合)。
-
数据仍以 PostgreSQL 为主存储,ES 只作为辅助索引,避免了双写一致性问题(通过逻辑解码或触发器同步)。
-
查询时自动合并 ES 返回的
_id与 PG 表的主键,支持排序、分页。
-
-
缺点:需要额外部署和维护 Elasticsearch 集群。
-
适用场景:需要在传统关系型数据上叠加全文搜索,且对搜索质量要求较高的应用(如电商搜索、日志分析)。
-
6.10 ParadeDB → paradedb
-
真实扩展:
paradedb -
一句话能力:基于 Tantivy(Rust 全文引擎)的 BM25 全文引擎,完全替代 Elasticsearch。
-
详解:
-
paradedb是一个新一代 PostgreSQL 扩展,内置 Tantivy 全文搜索引擎(类似 Lucene 但用 Rust 实现),不依赖外部服务。 -
提供
pg_bm25索引类型,支持:-
BM25 相关度排名
-
多字段加权查询
-
短语搜索、前缀搜索、模糊搜索
-
高亮、聚合、自动补全
-
-
与传统全文搜索(
tsvector)相比:-
排名更专业(BM25),而
tsvector采用简单的 TF-IDF 变体。 -
索引更新实时,不需
REINDEX。 -
支持更复杂的查询语法(如
description:fast AND (database OR search))。
-
-
与 ZomboDB 相比:无需外部 ES,部署简单;性能相当,甚至更快(因为 Tantivy 高度优化)。
-
适用场景:希望在 PostgreSQL 内部获得 Elasticsearch 级别的全文搜索,又不愿增加运维复杂性的场景。
-
注意:ParadeDB 仍处于快速迭代期,但已用于生产。
-
总结
这一组扩展覆盖了从 字符级模糊匹配(pg_trgm、pg_bigm)、中文分词(zhparser)、多语言全文引擎(pgroonga)、高排名短语搜索(rum)、拼写纠错(hunspell)、相似度算法(smlar、pg_similarity),到集成外部 ES(zombodb)以及 内置 Rust 全文引擎(paradedb)的完整解决方案。开发者可以根据数据特征、语言需求、性能要求和运维复杂度选择合适的工具组合。
第七章:地理 / mobility / 路网
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
PostGIS |
见上文 |
— |
— |
|
pgRouting |
pgrouting |
路网最短路径、TSP、VRP |
|
|
MobilityDB |
mobilitydb |
时空轨迹类型+索引,船舶/出租车 |
|
|
H3 |
h3 |
Uber 六边形网格 |
|
|
pg_geohash |
pg_geohash |
Geohash 编码/解码函数 |
|
|
GISWater |
giswater |
水务管网建模插件 |
|
|
pg_polyline |
pg_polyline |
多段线压缩存储 |
|
这张表格聚焦于 PostgreSQL 的地理空间与网络分析 扩展,涵盖了从基础空间计算(PostGIS)、路网规划(pgRouting)、时空轨迹(MobilityDB)、地理编码(H3、pg_geohash)、行业专用模型(GISWater)到存储优化(pg_polyline)等方向。下面逐项详解。
7.1 PostGIS
-
真实扩展:
postgis -
一句话能力:见第一张图详解(地理空间 3000+ 函数、栅格、拓扑、3D)
-
简要回顾:
-
PostGIS 是 PostgreSQL 最著名的空间扩展,提供完整的 OGC 简单要素规范支持。
-
包括空间数据类型(geometry/geography)、空间索引(GiST)、丰富的函数(ST_Intersects、ST_Distance 等)、栅格分析、拓扑管理、3D 支持。
-
广泛应用于 GIS 系统、位置服务、城市规划、环境监测等。
-
7.2 pgRouting → pgrouting
-
真实扩展:
pgrouting -
一句话能力:提供路网最短路径、TSP(旅行商问题)、VRP(车辆路径规划) 等图算法。
-
详解:
-
pgRouting扩展建立在 PostGIS 之上,专门处理网络拓扑分析,将道路、管道等抽象为有向/无向图。 -
核心功能包括:
-
最短路径:Dijkstra、A*、双向 Dijkstra、Shooting Star(带时间窗)。
-
多路径:KSP(K 条最短路径)、Yen 算法。
-
旅行商问题(TSP):近似最优路线排序。
-
车辆路径问题(VRP):带容量约束的车辆调度。
-
可达范围(Isodistance / Isochrones):给定时间或距离内能到达的区域。
-
成本矩阵:计算多个点之间的成对距离。
-
-
使用方式:将道路表转换为包含
source、target、cost字段的拓扑网络,然后调用pgr_dijkstra()等函数。 -
典型应用:导航系统、物流配送优化、应急响应分析、城市交通模拟。
-
优点:与 PostGIS 无缝集成,路径分析结果可以直接作为几何对象显示。
-
7.3 MobilityDB → mobilitydb
-
真实扩展:
mobilitydb -
一句话能力:时空轨迹类型 + 索引,专为船舶、出租车、GPS 设备等移动对象的轨迹管理设计。
-
详解:
-
MobilityDB是一个基于 PostGIS 的开源扩展,新增了时间维度的几何类型,例如tgeompoint(随时间变化的几何点)和tgeogpoint(地理点序列)。 -
核心能力:
-
存储完整的移动轨迹(带时间戳的点列),无需拆分成多行。
-
查询轨迹之间的关系:
tgeompoint <-> tgeompoint(相对运动)、atInstant()(特定时刻的位置)、intersects()(轨迹是否与区域相交)。 -
时空索引:利用 GiST 或专门索引加速时间范围 + 空间范围混合查询。
-
支持轨迹简化、压缩、插值。
-
-
数据类型符合移动数据库标准(Moving Features),并集成许多分析函数(例如速度、方向、停留点检测)。
-
典型场景:渔船监控(AIS 数据)、出租车 GPS 分析、运动员跑动热力图、新冠患者时空接触追溯。
-
性能:处理亿级时空点时可保持亚秒级响应。
-
7.4 H3 → h3(Uber 开源的六边形网格系统)
-
真实扩展:
h3-pg(或直接h3扩展) -
一句话能力:提供 Uber 六边形网格 的编码、解码、层次化聚合函数。
-
详解:
-
H3 是 Uber 设计的全球离散网格系统,使用正六边形(以及少量五边形)分割地球表面,支持 0-15 级分辨率,覆盖几个平方米到数千平方公里。
-
六边形的优势:相邻距离一致、没有正方形网格的方向偏差。
-
该扩展将 H3 核心库封装为 PostgreSQL 函数,例如:
-
h3_lat_lng_to_cell(lat, lng, resolution):坐标转 H3 网格索引。 -
h3_cell_to_boundary(cell):获取网格的边界多边形。 -
h3_grid_distance(cell1, cell2):网格间的步数距离。 -
h3_k_ring(cell, k):返回周围 k 层所有网格。 -
h3_polygon_to_cells(geometry, resolution):将多边形转换为内部网格集合(空间聚合)。
-
-
典型应用:
-
大规模地理分析(如 Uber 的供需热力)。
-
位置隐私保护:用网格而非精确坐标。
-
均匀的空间分区,便于分布式计算。
-
-
优势:无外部依赖,函数直接返回 H3 索引(64 位整数),可用于索引和分组。
-
7.5 pg_geohash → pg_geohash
-
真实扩展:
pg_geohash(或作为 PostGIS 的可选函数集) -
一句话能力:提供 Geohash 编码/解码 函数,支持精度可调的网格化。
-
详解:
-
Geohash 是一种将经纬度编码为短字符串的方法,字符串越长表示范围越精确。同一区域内的点具有相同前缀。
-
pg_geohash提供:-
geohash_encode(lon, lat, precision):将坐标转换为 Geohash 字符串(如wx4g0s8)。 -
geohash_decode(hash):返回该 Geohash 表示的矩形边界框(geometry)。 -
geohash_neighbors(hash):获取周围 8 个相邻 Geohash。
-
-
相比于 H3,Geohash 更简单,广泛用于缓存、轻量级空间索引(如 Redis)和简单的地理分组。
-
典型用途:
-
按位置快速分组统计(如统计每个 Geohash 单元格内的 POI 数量)。
-
实现“附近的人”功能时,先按 Geohash 前缀筛选候选。
-
与 PostGIS 结合使用时,可快速过滤后再精确计算距离。
-
-
精度:从 1 字符(约 5000 km)到 12 字符(约 3.7 cm)。
-
7.6 GISWater → giswater
-
真实扩展:
giswater -
一句话能力:专业的水务管网建模插件,用于供水、排水、雨水管网管理。
-
详解:
-
giswater是一个基于 PostgreSQL + PostGIS + pgRouting 的完整行业解决方案,主要用于水务基础设施的信息化管理。 -
核心功能模块:
-
管网拓扑管理:节点(阀门、消火栓、水表)、管道(材质、直径、埋深)、设备。
-
水力模拟:集成 EPANET 引擎(供水管网水力分析),可在数据库内执行水压、流量、水质模拟。
-
漏损检测:通过分析夜间最小流量、压力变化定位疑似漏点。
-
资产管理:GIS 地图展示、管网巡检、维修工单。
-
缓冲区分析:爆管后自动关阀方案(影响范围分析)。
-
-
数据模型遵循国际标准(如 WaterML、INSPIRE),支持 GIS 前端(QGIS、Leaflet)。
-
适用对象:水务公司、市政规划部门、环境咨询公司。
-
注意:这是一个完整的应用框架,不止是扩展;它依赖多个 PostgreSQL 扩展以及外部计算库。
-
7.7 pg_polyline → pg_polyline
-
真实扩展:
pg_polyline -
一句话能力:多段线压缩存储,降低长轨迹或道路几何的内存占用。
-
详解:
-
pg_polyline提供一种自定义数据类型polyline,专门用于存储折线(LineString),并支持多种压缩算法。 -
压缩原理:
-
使用 Ramer-Douglas-Peucker 或 Visvalingam-Whyatt 算法简化多段线,在保留形状的前提下大幅减少点数量。
-
存储时采用差量编码(例如 Google 的 Polyline 编码),将浮点数坐标转换为较短的字符串。
-
-
相比 PostGIS 原生的
geometry(LineString),压缩后体积可减少 70%-90%,尤其适合存储 GPS 轨迹、道路网络等高密度线数据。 -
提供解压函数
decompress(polyline)重新生成 PostGIS 几何,以便进行空间计算。 -
典型场景:
-
车载 GPS 设备长期存储行车轨迹。
-
道路导航应用中预先存储大量道路形状(路网几何压缩)。
-
移动端与服务器同步时减少带宽消耗。
-
-
局限性:压缩是有损的,不能完全恢复原始点序列;但适合大多数可视化与分析需求。
-
总结
这组地理相关扩展将 PostgreSQL + PostGIS 从一个基础的 GIS 数据库延伸至网络分析(pgRouting)、移动时空(MobilityDB)、网格编码(H3、geohash)、行业模型(GISWater)和存储优化(pg_polyline)。它们共同构成了一套完整的空间数据处理生态,覆盖了从基础设施管理(水务、道路)到实时轨迹分析(出租车、船舶)再到通用地理编码及压缩的广泛需求。
第八章:语言绑定(PL/*)区域
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
PL/Java |
pljava |
用 Java 写存储过程 |
|
|
PL/Rust |
plrust / pgrx |
Rust 写 UDF,内存安全 |
|
|
PL/Go |
plgo |
Go 写 UDF |
源码 |
|
PL/Python |
plpython3u |
Python3 写 UDF,可 import sklearn |
|
|
PL/R |
plr |
R 语言统计/绘图 |
|
|
PL/Perl |
plperl |
Perl 存储过程 |
|
|
PL/PHP |
plphp |
PHP 写 UDF |
PGXN |
|
PL/Ruby |
plruby |
Ruby 写 UDF |
PGXN |
|
PL/Lua |
pllua |
Lua 轻量级过程语言 |
|
|
PL/v8 |
plv8 |
JavaScript(ES 2022)+ npm 包 |
|
|
PL/sh |
plsh |
Shell 脚本 UDF |
|
|
PL/SQL |
无开源版 |
图中泛指 orafce 兼容包 |
|
|
PL/PRQL |
plprql |
PRQL 现代管道查询语言 |
源码 |
|
PL/TCL |
pltcl |
Tcl 存储过程 |
|
第九章:小工具 / 杂项
|
图上字样 |
真实扩展 |
一句话能力 |
安装示例 |
|---|---|---|---|
|
pgqr |
pgqr |
SQL 生成二维码 |
|
|
pgpdf |
pgpdf |
SQL 生成 PDF 报表 |
|
|
gzip / zstd |
pg_compression |
列级 压缩 存储 |
|
|
GraphQL |
graphql |
把表直接暴露成 GraphQL 端点 |
|
|
pg_net |
pg_net |
异步 HTTP 客户端(非阻塞) |
|
|
jsonschema |
jsonschema |
JSON 数据校验约束 |
|
|
imgsmlr |
imgsmlr |
图片感知哈希相似搜索 |
|
|
fusion |
fusion |
统一 日志、指标、追踪 输出 |
源码 |
|
pg_tde |
pg_tde |
透明数据加密(表级) |
源码(进入 PG 17 core) |
下面是这张表格里各项 PostgreSQL 扩展的详细解读,涵盖了二维码生成、PDF 报告、列级压缩、GraphQL、异步 HTTP、JSON 校验、图片相似度搜索、可观测性和透明数据加密等多种实用性功能:
9.1 pgqr → pgqr
-
一句话能力:直接在 SQL 中生成二维码。
-
详解:
-
pgqr是 PostgreSQL 的一个扩展,允许用户通过 SQL 直接生成二维码,主要是 BMP 格式的图像。 -
它提供了一个核心函数
pgqr(),有四个关键参数:-
text:要编码的字符串。 -
correction_level:纠错级别,整数 0-3 对应 7%、15%、25%、30%。 -
此外,还可以对输出图片的尺寸等细节进行配置。
-
-
这个扩展非常适合那些需要在 SQL 脚本或数据库触发器中动态生成二维码的场景,例如生成产品标签、活动门票或者带有校验信息的单据。
-
9.2 pgpdf → pgpdf
-
一句话能力:在 SQL 中生成 PDF 报表。
-
详解:
-
pgpdf为 PostgreSQL 引入了原生的pdf数据类型,让开发者可以直接在数据库中存储和操作 PDF 文档。 -
它基于
poppler库进行 PDF 解析。创建方式也非常简单,可以直接将文本路径或bytea类型的二进制数据转换为pdf类型。 -
结合
pg_net之类的网络扩展,还可以直接从数据库内部获取远程 PDF 并解析,打造完全自动化、SQL 驱动的文档处理流水线,免去应用层的繁琐逻辑。 -
需要注意的是,由于该功能在数据库内部直接解析 PDF,可能带来潜在的安全风险,这一点在社区中引发了相关讨论。
-
9.3 gzip / zstd → pg_compression
-
真实扩展:
pg_compression -
一句话能力:实现对特定列的列级压缩存储。
-
详解:
-
pg_compression扩展利用高效的算法(如 LZ4、Zstandard)对指定列进行压缩,从而显著降低磁盘占用。 -
使用时,你可以先创建扩展:
CREATE EXTENSION pg_compress;然后通过ALTER TABLE语句为特定列设置压缩方式:ALTER TABLE my_table ALTER COLUMN data SET COMPRESSION 'zstd'; -
尤其适合存储大文本、JSON 或二进制数据。相比 PostgreSQL 原生的 TOAST 压缩,它的灵活性和选择性更高,你可以只为表中最占空间的列开启高级压缩。
-
9.4 GraphQL → pg_graphql
-
真实扩展:
pg_graphql -
一句话能力:将数据库表结构直接暴露成 GraphQL 端点。
-
详解:
-
pg_graphql扩展会在数据库中构建一个完整的 GraphQL 服务引擎。它能自动将现有的 SQL 表、视图及其关系映射成功能完备的 GraphQL schema。 -
用户请求 GraphQL 查询时,扩展会将其解析、验证、并转换成优化的 SQL 查询执行,最后将结果集格式化回 GraphQL 响应。
-
这项技术是 Supabase 等现代 BaaS(后端即服务)平台的基石之一,能让开发者无需编写后端代码,就以标准化的 GraphQL 方式直接与数据库交互。
-
9.5 pg_net → pg_net
-
真实扩展:
pg_net -
一句话能力:提供异步、非阻塞的 HTTP 客户端能力。
-
详解:
-
pg_net是 Supabase 推出的扩展,允许 PostgreSQL 在 SQL 中发起 HTTP/HTTPS 请求,且默认就是异步的。 -
异步特性使其在触发器或存储过程这类阻塞函数中调用时,不会拖慢主事务的提交,非常适合发送 Webhook 通知、异步调用 API 或触发外部工作流。
-
与同步的
http扩展相比,pg_net的设计更适合现代云函数和事件驱动型架构。
-
9.6 jsonschema → pg_jsonschema
-
真实扩展:
pg_jsonschema -
一句话能力:在数据库层对 JSON 数据执行结构校验。
-
详解:
-
pg_jsonschema是一个 Rust 编写的扩展,为 PostgreSQL 内置的json和jsonb类型添加了 JSON Schema 校验能力。 -
它提供了
json_matches_schema()和jsonb_matches_schema()等函数,可以根据预设的 Schema 规则进行校验。 -
将校验逻辑直接放在数据库层,可以保证所有写入
json列的数据都符合应用规范,从源头预防脏数据,确保数据格式的一致性。
-
9.7 imgsmlr → imgsmlr
-
真实扩展:
imgsmlr -
一句话能力:基于感知哈希的图片相似度搜索。
-
详解:
-
imgsmlr扩展利用 Haar 小波变换 算法,提取 PNG、GIF 等图片的特征值(Signature),然后通过 GiST 索引来检索视觉上相似的图片。 -
它提供了
pattern和signature两种数据类型:pattern存储原始特征向量,signature是用于快速检索的简略版特征。查询时先利用 GiST 索引通过signature粗筛候选,再与pattern精确匹配得出最相似的结果。 -
需要注意的是,该库更侧重于演示和教学目的,或用于基础的相似度检索,并不是最前沿、最高准确率的算法。
-
9.8 fusion → fusion
-
真实扩展:
fusion(指向 pg_fusion) -
一句话能力:统一输出日志、指标、追踪等可观测性数据。
-
相关概念详解:
-
这是表格中的一个指代符号,它提醒我们,现代数据库的可观测性需要实现 Logs, Metrics, Traces 三大支柱的融合。
-
PostgreSQL 本身有
pg_stat_statements扩展来跟踪核心指标和慢查询。 -
在生产监控中,通常会用以下组合来满足“fusion”(融合)的需求:
-
Metrics(指标):由 Prometheus 抓取,用 Grafana 展示。
-
Logs(日志):收集到 Loki 等系统进行检索。
-
Traces(追踪):通过 OpenTelemetry 标准实现分布式追踪。
-
-
将这三类数据结合,可以通过“可观测性”体系,全面分析系统性能瓶颈或故障。
-
9.9 pg_tde → pg_tde
-
真实扩展:
pg_tde -
一句话能力:对数据进行透明的、无感知的表级加密。
-
详解:
-
它是 Percona 为 PostgreSQL 社区带来的首个开源、透明的数据加密(TDE)解决方案,旨在满足 GDPR 等数据合规性要求。
-
开启
pg_tde后,向表中写入的数据在落盘前会自动加密,读取时自动解密,对应用和用户完全透明,应用代码无需任何修改。 -
其默认的表访问方法是
tde_heap。启用加密后,数据文件和 WAL 日志写入磁盘时都会被加密,防止因磁盘或备份泄露导致数据丢失。
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)