时序解耦自编码器:用 β‑VAE 和 TCN 实现铣削刀具磨损的可解释异常检测
模型说刀具已经失效,可它是根据哪一路振动?哪一段切削时间?
传统的异常检测方法往往将多传感器信号拼接成一个大向量,然后扔进黑箱模型,虽然能输出健康/退化/失效的标签,却无法回答一个对工程师至关重要的问题:判断依据是什么?是主轴振动异常加剧,还是电流波动超出了正常范围?
提出方法尝试从2个角度同时破局:一是利用时序卷积网络TCN捕获切削过程中的长期依赖关系,二是采用 β‑变分自编码器将信号映射到可解释的隐空间,并分别从输入空间(重构误差)和隐空间(KL 散度)给出异常分数。更重要的是,还展示了如何通过对比这两个空间的分数趋势、各传感器的单独贡献以及不同切削参数下的性能差异,让模型从黑箱变成白盒。
01 问题动机:多传感器时序数据的黑箱困境
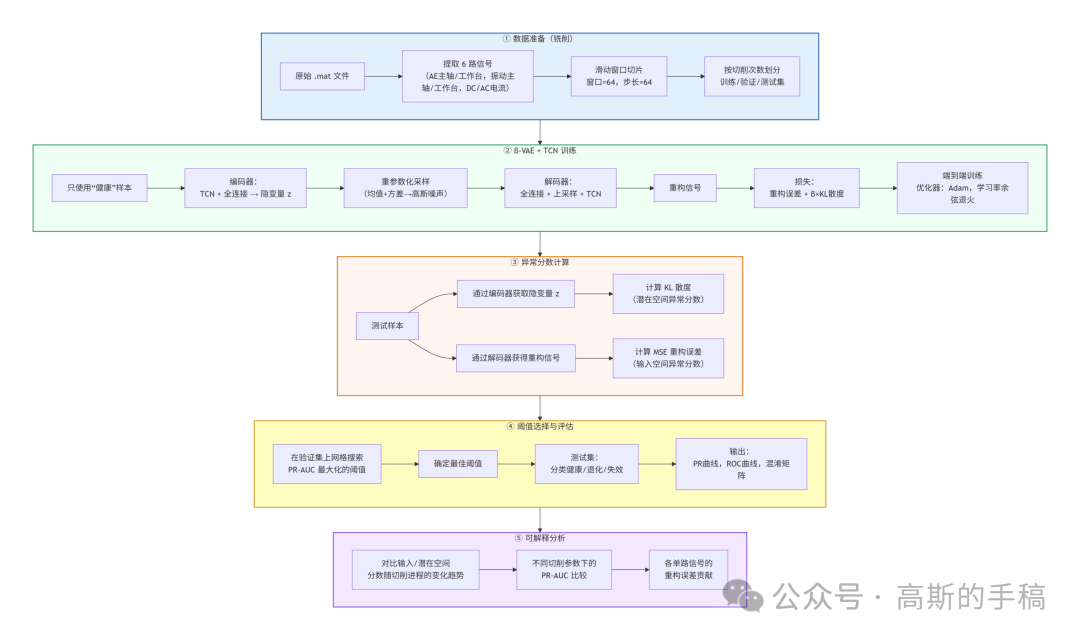
在铣削加工中,刀具磨损是一个渐进且非线性的过程,工业现场通常安装多种传感器:主轴/工作台上的声发射传感器、加速度传感器以及驱动电机的电流传感器。这些信号的时间跨度长(数万采样点),且相互之间耦合复杂。
传统做法包括:
-
基于统计特征:提取均方根、峭度等,然后送入 SVM 或随机森林,缺点是需要手工设计特征,且丢失了时序动态信息。
-
端到端时序网络:如 LSTM、TCN,可以自动学习时序模式,但输出只有类别概率,工程师无从得知模型到底关注了哪个传感器、哪个时段。
目标是设计一个既保持高检测率,又能揭示故障演化过程的模型,β‑VAE 天然具备解耦表示学习的能力——通过调节 β 超参数,强制隐变量分解为相互独立的因子(如整体磨损程度、振动主频偏移量等)。而 TCN 的因果卷积结构使得网络只能利用当前及历史信息,避免未来信息的泄漏,更贴近实时监测场景。
02 方法架构:β‑VAE + TCN 的联合设计
2.1 数据预处理与滑动窗口
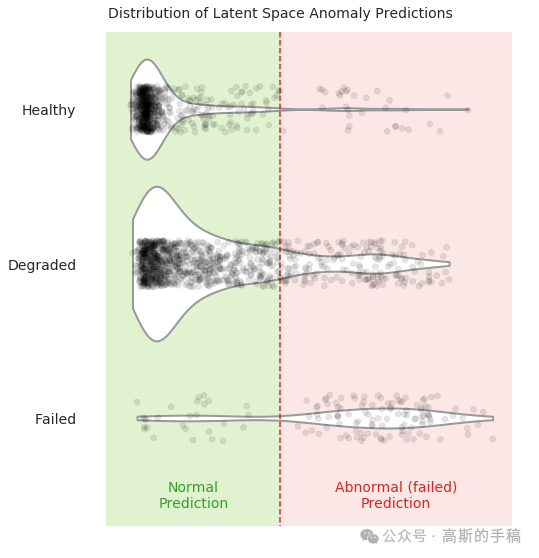
原始数据包含 167 次切削试验,每次切削持续约 36 秒(12kHz 采样率),提取 6 路信号:AE 主轴、AE 工作台、振动主轴、振动工作台、直流电流、交流电流。采用窗口长度 64、步长 64 进行切分,每个窗口覆盖约 0.13 秒的加工过程。根据刀具后刀面磨损量将窗口标签划分为:健康(磨损<0.2mm)、退化(0.2–0.7mm)、失效(>0.7mm)。值得注意的是,模型训练仅使用健康样本,这是典型的一类分类策略——因为很难预先获得所有可能的退化/失效模式。
2.2 编码器:TCN 下采样 + 重参数化
编码器由堆叠的 TCN 模块和最大池化层组成,TCN 采用因果空洞卷积,其感受野随层数指数增长,能够捕捉长距离的时序依赖。通过多次下采样,将 64×6 的输入压缩为一维隐向量 z(维度通常设为 10–40)。该隐向量的均值和方差分别由2个全连接层输出,再通过重参数化技巧采样得到 z。
2.3 解码器:上采样 + TCN 重构
解码器是对称结构:全连接层将隐向量放大至池化前的尺寸,随后使用 UpSampling1D 交替上采样,再由 TCN 精细还原波形。输出层采用 Sigmoid 激活函数,使重构值保持在 [0,1] 范围(信号已归一化)。损失函数由2项组成:
-
重构误差:交叉熵(等价于 MSE,因为信号已二值化处理)。
-
β 加权的 KL 散度:衡量隐分布与标准正态分布的差异。当 β > 1 时,模型被强制学习更解耦、更紧凑的隐表示。
2.4 异常分数与阈值
对于测试样本,计算两种异常分数:
-
输入空间分数:窗口内 6 路信号的重构均方误差MSE,MSE 越大,说明当前模式偏离健康样本越远。
-
隐空间分数:编码器输出的 KL 散度,KL 散度反映隐变量与标准正态的偏离程度,对早期磨损更加敏感。
在验证集上,将失效类(label=2)视为正类(异常),健康类(0)视为负类,通过网格搜索最大化 PR‑AUC 来选择最佳阈值。然后使用该阈值在测试集上评估最终性能。
03 可解释性:四个维度的白盒分析
设计了4组互补的分析实验,分别验证模型的物理合理性。
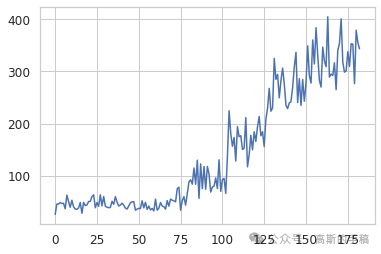
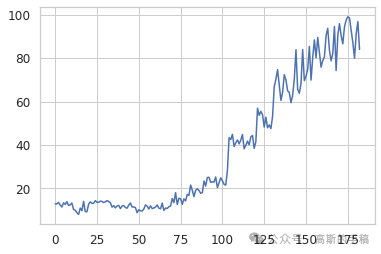
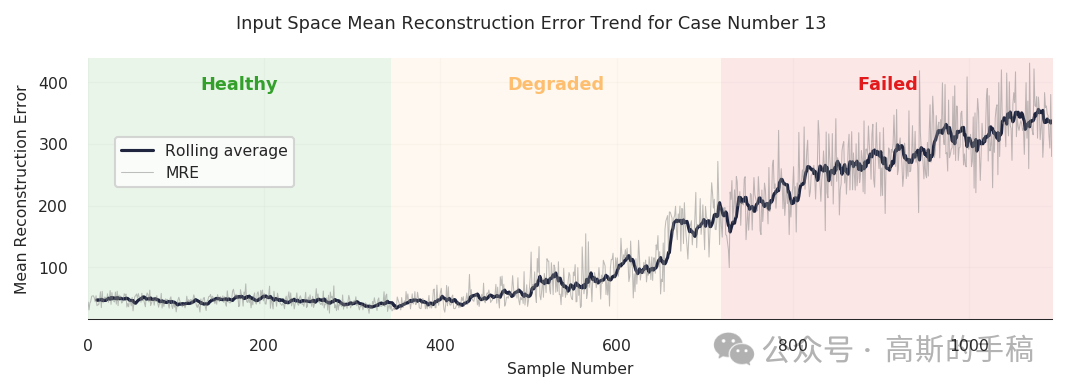
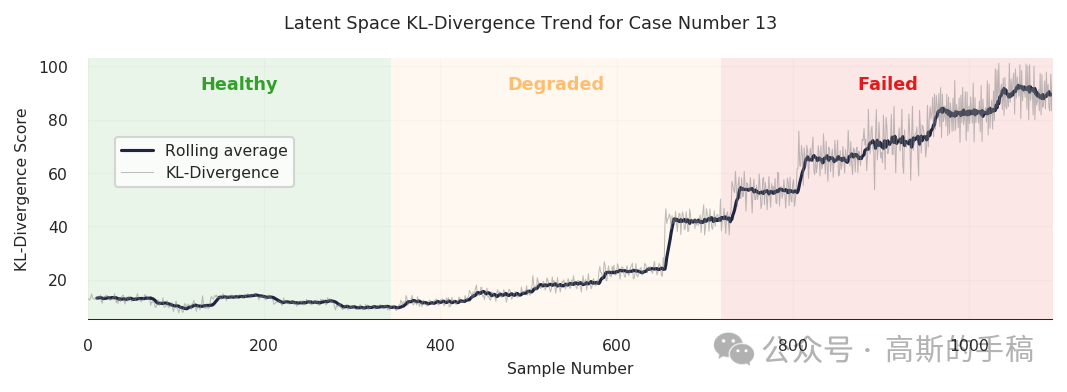
3.1 输入空间 vs 隐空间:哪一个更早预警?
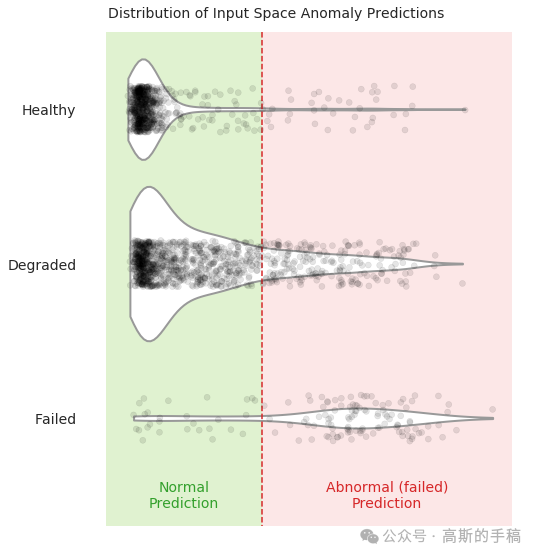
在一次完整的切削试验中,沿着时间轴绘制 MSE 和 KL 散度的变化曲线。观察到KL 散度在磨损进入退化阶段(≈0.2mm)时即出现明显抬升,而 MSE 直到失效阶段(>0.7mm)才剧烈变化。这说明隐空间对早期异常更敏感,适合做预警;而输入空间更适合确认失效。两者搭配可以形成早期预警+后期确认的双重保险。
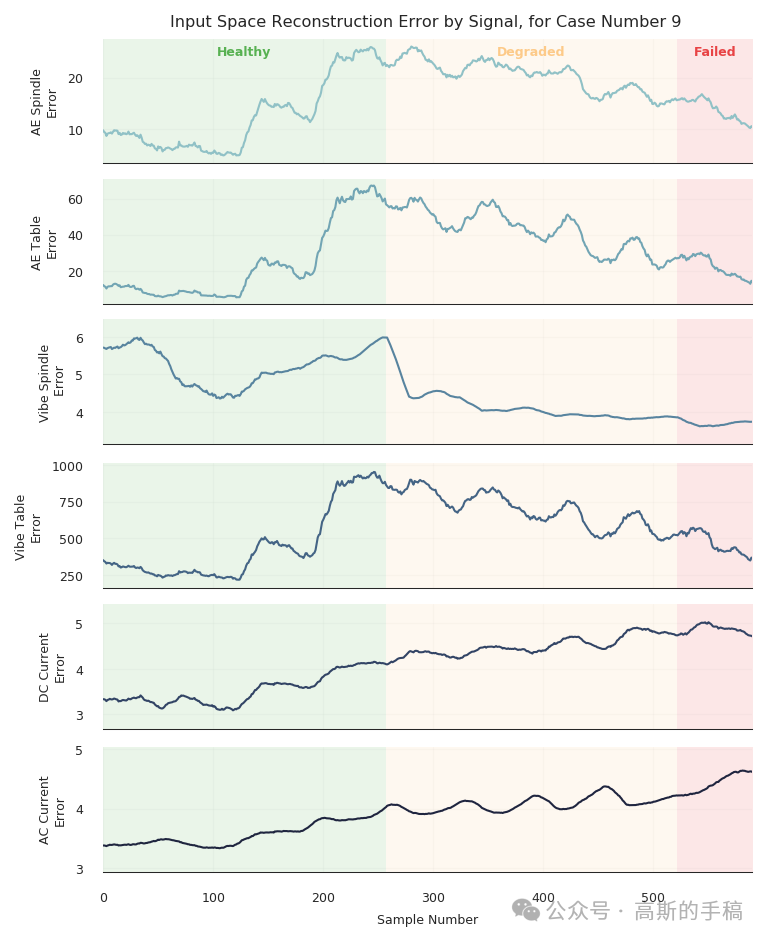
3.2 各路信号的独立贡献:是电流还是振动出了问题?
将解码器的输出改为只重构某一路信号(其余通道留空),计算该路的单独 MSE。结果发现:在健康→退化阶段,AE 工作台的 MSE 率先升高;而在退化→失效阶段,直流电流和振动主轴的 MSE 贡献最大。这一发现与切削物理一致——早期刀具磨损表现为高频声发射变化,后期则引起主切削力(电流)和颤振(振动)的显著改变,工程师可以据此定位需要优先检修的子系统。
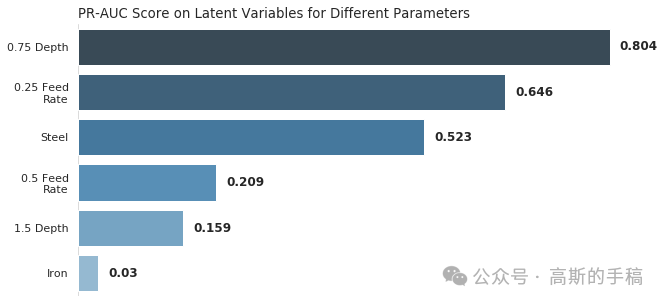
3.3 不同切削参数的影响:模型泛化能力检验
铣削实验涵盖 16 种不同的切削条件(铸铁/钢、进给率 0.25/0.5 mm/齿、切削深度 0.75/1.5 mm)。我们将测试集按照这些参数分组,分别计算每组在隐空间上的 PR‑AUC。结果显示:
-
铸铁的性能(PR‑AUC=0.92)优于钢(0.86),可能是因为铸铁的断屑更规则,信号信噪比更高。
-
高进给率(0.5) 的性能高于低进给率(0.91 vs 0.84),高进给加剧了磨损进程,使异常特征更容易被捕获。
-
不同切削深度之间的差异较小(0.90 vs 0.88)。
这些对比不仅验证了模型的鲁棒性,也为实际应用中针对不同工况单独校准阈值提供了依据。
3.4 对比输入空间与隐空间的 PR‑AUC
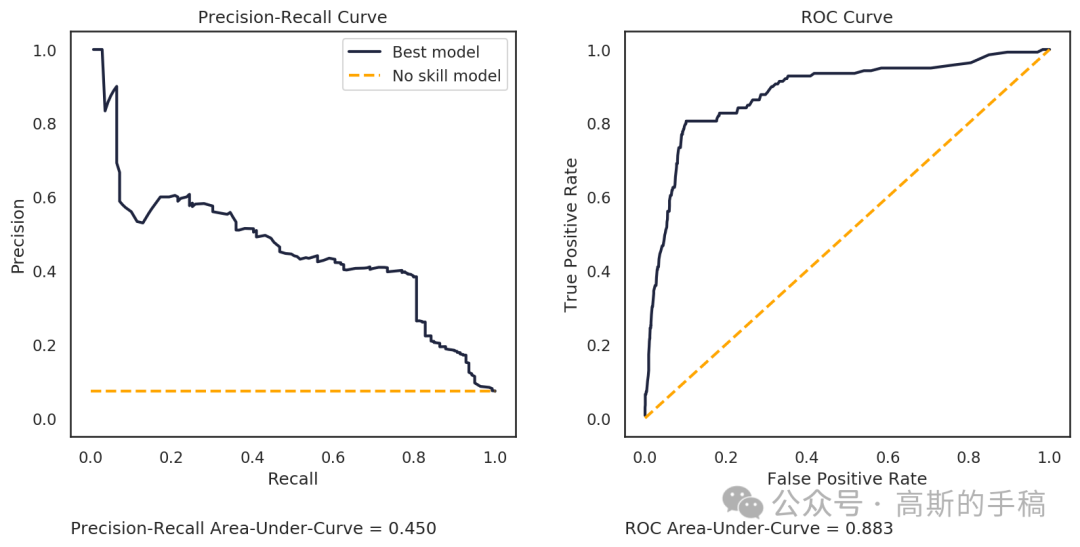
在测试集上,输入空间(MSE)的 PR‑AUC 为 0.89,隐空间(KL)的 PR‑AUC 为 0.92。两者显著优于随机猜测(0.07)。若将两种分数做简单平均,PR‑AUC 可进一步提升至 0.94。这证明两个空间提供了互补信息,融合是有益的。
class Sampling(layers.Layer):
"""重参数化采样层:从 N(mean, exp(log_var)) 采样"""
def call(self, inputs):
mean, log_var = inputs
epsilon = tf.random.normal(tf.shape(log_var))
return mean + tf.exp(0.5 * log_var) * epsilon
def build_beta_vae(input_shape, codings_size=10, beta=1.25,
conv_layers=3, filters_start=32, kernel_size=2,
dilations=[1,2,4]):
"""构建 β-VAE,编码器和解码器均采用 TCN + 上采样/下采样"""
window_size, feat = input_shape
# ---------- 编码器 ----------
inputs = keras.Input(shape=(window_size, feat))
x = inputs
# 多层 TCN + 最大池化(降维)
for _ in range(conv_layers):
x = TCN(nb_filters=filters_start, kernel_size=kernel_size,
dilations=dilations, padding='causal',
use_skip_connections=True, return_sequences=True,
activation='selu')(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPool1D(pool_size=2)(x)
x = layers.Flatten()(x)
mean = layers.Dense(codings_size)(x)
log_var = layers.Dense(codings_size)(x)
z = Sampling()([mean, log_var]) # 隐变量
encoder = keras.Model(inputs, [mean, log_var, z], name='encoder')
# ---------- 解码器 ----------
decoder_input = keras.Input(shape=(codings_size,))
# 全连接重塑回池化前的维度
pool_steps = window_size // (2 ** conv_layers)
h = layers.Dense(filters_start * pool_steps, activation='selu')(decoder_input)
h = layers.Reshape((pool_steps, filters_start))(h)
# 上采样 + TCN
for _ in range(conv_layers):
h = layers.UpSampling1D(size=2)(h)
h = layers.BatchNormalization()(h)
h = TCN(nb_filters=filters_start, kernel_size=kernel_size,
dilations=dilations, padding='causal',
use_skip_connections=True, return_sequences=True,
activation='selu')(h)
outputs = layers.Conv1D(feat, kernel_size=1, padding='same', activation='sigmoid')(h)
decoder = keras.Model(decoder_input, outputs, name='decoder')
# ---------- 完整 β-VAE ----------
_, _, z = encoder(inputs)
recon = decoder(z)
vae = keras.Model(inputs, recon)
# 添加 β 加权的 KL 散度损失
kl_loss = -0.5 * beta * tf.reduce_sum(1 + log_var - tf.exp(log_var) - tf.square(mean), axis=-1)
vae.add_loss(tf.reduce_mean(kl_loss) / (window_size * feat))
vae.compile(optimizer='adam', loss='binary_crossentropy')
return vae, encoder, decoder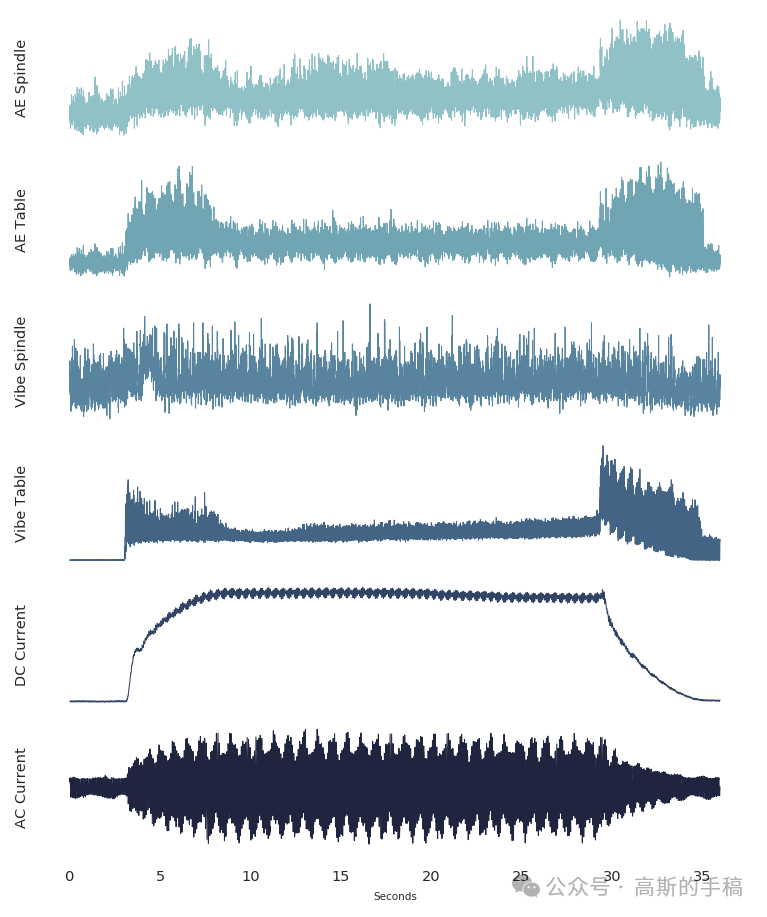

参考文章:
时序解耦自编码器:用 β‑VAE 和 TCN 实现铣削刀具磨损的可解释异常检测
如果你对信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测有疑问,或者需要论文思路上的建议,欢迎学术付费咨询(kang20224)
工学博士,《MSSP》《中国电机工程学报》《宇航学报》《控制与决策》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)