第3节:第一行代码前,你该想清楚什么?
第3节:第一行代码前,你该想清楚什么?
这个课程我们最终是要通过Codex做出一个类似于Dify的简单叫做Gdify,但做一个简单版,其实这句话非常模糊,扣子有几十个功能,你做哪些不做哪些目标用户是谁,部署在哪里,要扛多大的量?
这些问题在你写代码前就应该想明白,如果不想清楚会发生以下两件事:
-
要么坐着做着范围膨胀收不住
-
要么开发到一半,发现方向不对,推倒重来
用AI编辑器更危险。比如你说帮我做一个智能体管理,它可能顺手把权限体系版本控制审计日志全给你加上。因为扣子有这些,你没有定边界,它就帮你定了
先搞清楚行业标杆在做什么
在做任何项目之前,第一步不要想我要做什么,而是要看行业最好的在做什么,不是要操,而是要整理这个领域的全貌。你连全貌都没有,怎么知道哪些是核新功能,哪些是边缘?
我们可以直接让AI编辑器帮忙,帮我梳理这个产品的核心功能,按类别分组,每个模块用一两句话说清楚他干了什么
帮我梳理 Dify(https://dify.ai/) 这个产品的核心功能模块,按类别分组,每个模块一两句话说明白他做了什么
可以看到这个答案非常完整。如果是了解Dify的人,那么其实就知道它比较完整。但是如果不了解的?此时的原则是:AI给的信息不能直接信你要验证。比如,我就拿这个清单和Dify官方文档,GitHub README对了一遍 修正了几个过时的描述,补上了它遗漏的东西。

功能取舍
现在核心功能的全景图有了,接下来的一步是最关键的,做哪些不做哪些。
我们先让AI编辑器帮我们分析一下
我要做一个基于 Dify 的一个简化版 AI Agent 的平台,叫做Ghify。 约束条件:个人开发,面对团队内部20人到50人使用本地部署 从刚刚的梳理中,帮我判断哪些是必须做的核心模块,哪些是可以砍除的,并给出每个理由 以表格的形式给我
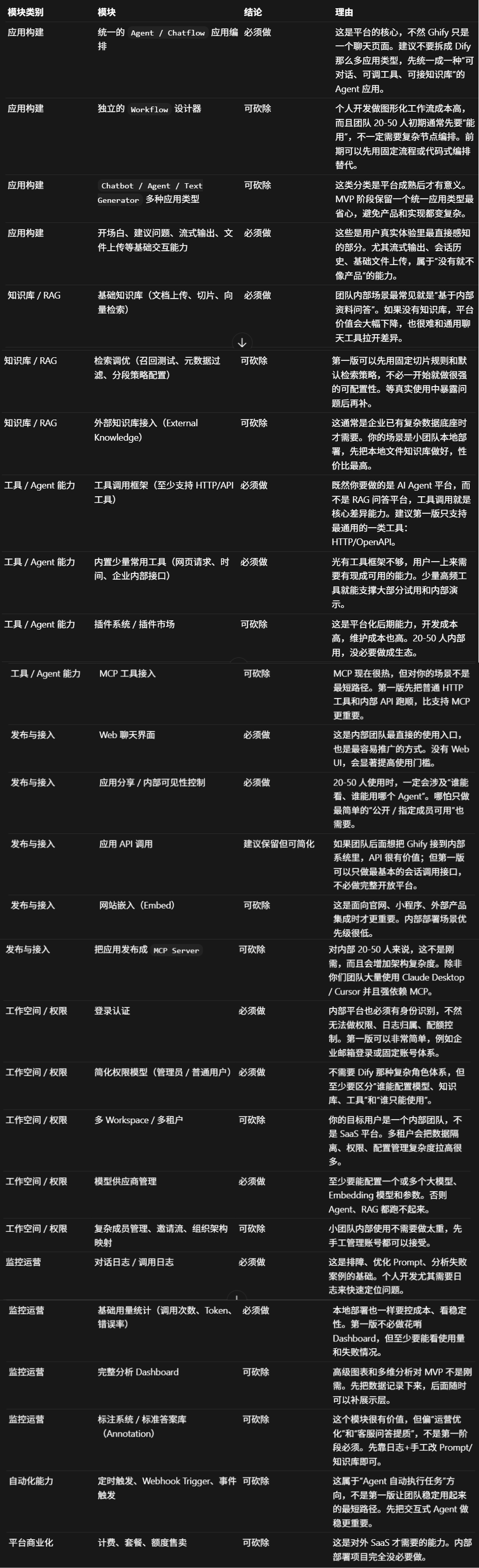

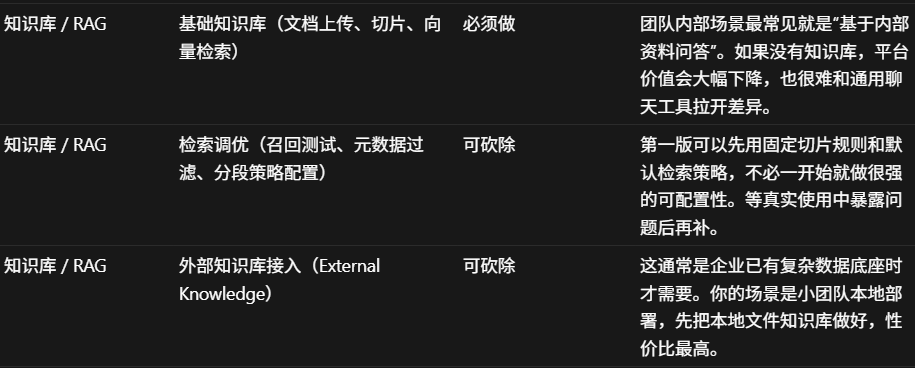
通过AI编辑器的输出,我们可以进行自己的思考。
原本知识库 + RAG这个模块我打算砍掉,整条链路太长了,一个人坐周期太长。但AI编辑器指出

他说的很对,如果只能通用对话,团队直接使用GPT就行。私有知识库的接入才是内部部署的核心价值。
工作流也类似,不做可视化拖拉拽,只支持JSON配置的线性流程条件分支
当然也有我不同意的。它建议做两级权限(管理员/普通用户),但50人内部团队大家互相认识,在系统外约定就行,不值得为此每个功能都多一层权限逻辑。否决。
可以使用三问裁剪法:
-
没有他产品还成立吗?区分核心和边缘。模型管理,Agent配置,对话引擎,工具集成,管理控制台,这5个功能砍掉任何一个产品都不成立。知识库和工作流砍掉,产品能用,但价值大打折扣,降级可做。可视化拖拉拽,多租户,插件市场,计费砍掉,不影响核心链路。
-
做到什么程度够用?核心功能不做满。模型管理只做CRUD连通信测试,agent配置只做选模型,绑工具,设提示词。对话引擎只做流式+多轮。知识库只支持TXT+固定分块。工作流只支持JSON配置。管理控制台能用就行,不追求完美
-
一句话能说不说清楚?一个可本地部署的AI Agent开发平台,支持多模型管理,agent配置,知识库RAG简化版,工作流对话交互和MCP工具接入,面向团队内小部分使用。

技术选型
功能范围定了,接下来是技术选型,我同样让AI编辑器参与
Ghify是1个AIagent开发平台,一个人开发本地部署目标20人到50人使用。帮我对比一下技术方案的优劣,1.spring boot+vue,2.go+react,3.python fastAPI+react。重点考虑开发效率、生态成熟度、AI领域SDK支持运维复杂度
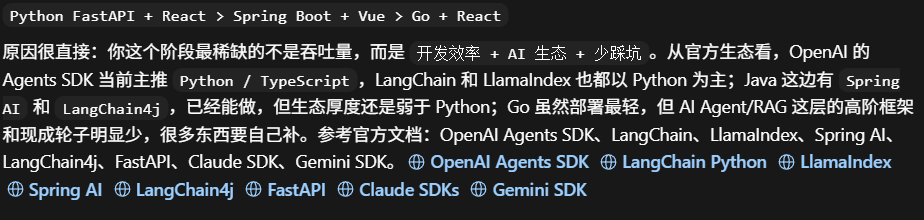

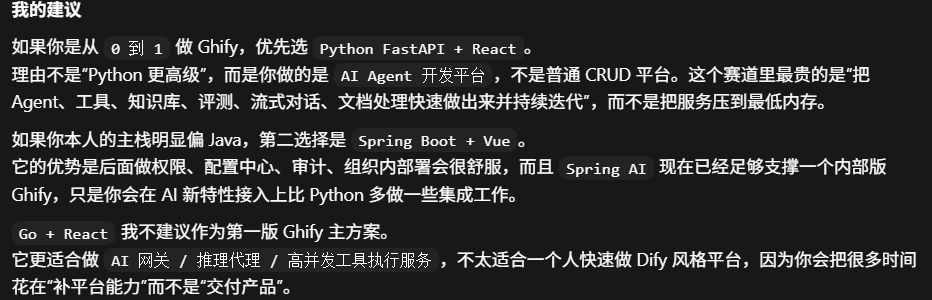
通过这份表单,我们可以发现一个很明确的结论:fastAPI在AI生态上碾压其他两个LangChain、LlamaIndex ,向量客户端都是python原生实现。java和go在这方面差距很大。他推荐fastAPI。
我主要是java技术站的,所以我就追加了一句
一个人做企业级后端,Spring Boot和FastAPI在工程化能力上差距有多大?考虑异常处理体系、事务管理这些方面。

所以综合考虑来看,我使用spring boot+Vue
-
个人最熟悉这个技术站,个人开发效率第一
-
java SDK版本够用
所以最终确定的技术栈
后端:Spring Boot 3.x + MyBatis-Plus + MySQL 8.x + Redis 7.x。工程化成熟,一个人能快速交付完整系统。 前端:Vue 3 + TypeScript + Element Plus。管理后台场景成熟度最高。 容器化:Docker + Docker Compose。最稳、最简。
提前想清楚怎么跑
很多人做项目只想功能,不响运维功能做完往服务器上一扔,等到出了问题才发现很多事情没有提前想。
Ghify是一个AI Agent平台,Docker本地部署,目标20-50同时在线,主要压力在对话接口(流式SSE)。帮我估算QPS,建议缓存策略,列出需要提前考虑的运维事项。
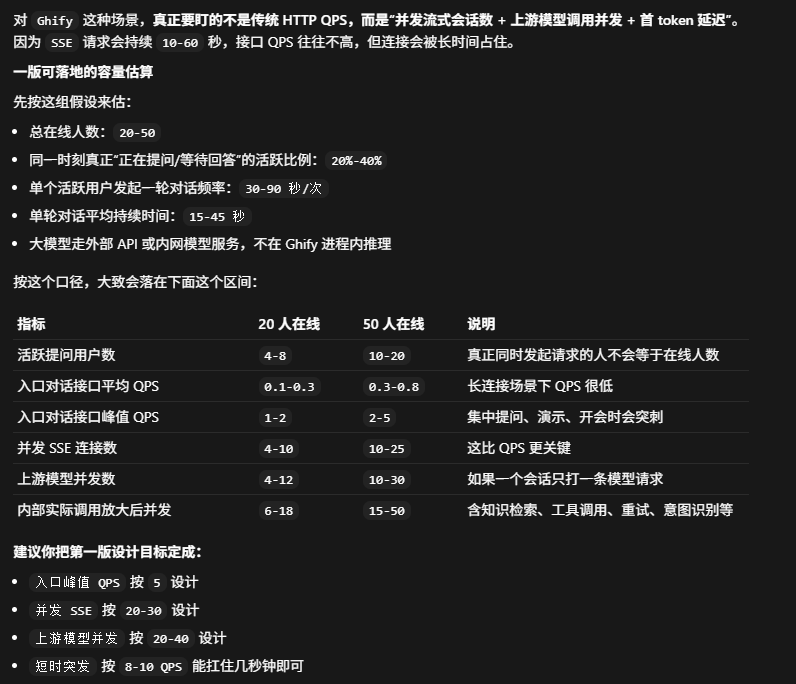
这里有一个很重要的环节,你得看得懂上面的建议。如果你看不懂,其实整个项目就会失控。比如,因为短期QPS不高,我放弃了做缓存,因为缓存会增加开发的复杂度。
最终运维预期:
部署方式:Docker Compose 一键启动。JVM内存设上限(-Xmx512m),防止容器被OOM Kill。 用户量:20-50人同时在线,单机部署够用。 QPS:峰值3-5QPS,瓶颈在LLM长连接不在并发。 监控:起步用Spring Boot Actuator + 日志,后期接Prometheus + Grafana。 扩容:一期单机。
判断不需要很精准,但它反映了技术选型和架构决策。所以,运维预期不是项目最后才想的事,它是从一开始就影响了你的每一个设计决策
写入AGENT.md
接下来我们要把所有的东西都落地成文字,写入AGENT.md
根据我们的讨论,帮我把Ghify的项目概述写进 AGENT.md的“项目概述”部分。包括产品定位、做什么、不做什么、技术栈、部署与运维预期。格式简洁明了。
AGENT.md不是一次性就写好的。随着项目推进,你对产品的理解会更加深入,可能会随调整功能范围改变技术决策,每次有变化回来更新。
# AGENT.md ## 项目概述 ### 产品定位 Ghify 是一个面向团队内部使用的轻量级 AI Agent 开发平台,目标是让 20-50 人规模的团队在本地部署环境中快速构建、配置和使用基于大模型的 Agent 应用。项目优先追求可落地、易维护和较高开发效率,而不是做成完整对标 Dify 的通用平台。 ### 做什么 - 提供统一的 AI Agent 应用形态,支持多轮对话、流式 SSE 输出、会话管理和基础应用配置。 - 支持知识库/RAG 能力,包括文档上传、切片、向量检索和基于内部资料的问答。 - 支持工具调用,至少覆盖 HTTP/API 工具和少量高频内置工具,满足 Agent 执行动作的基本需求。 - 提供 Web 管理与使用界面,支持团队成员登录、应用使用、基础权限控制和日志查看。 - 提供基础运维能力,包括对话日志、调用日志、Token/请求统计、错误监控和必要的限流保护。 ### 不做什么 - 不做复杂的图形化 Workflow 设计器,第一阶段以固定流程或代码式编排为主。 - 不做多种割裂的应用类型,优先统一为一种可接知识库和工具的 Agent 应用。 - 不做插件市场、多租户、多 Workspace、计费系统、外部商业化能力。 - 不优先做 MCP Server 发布、复杂 Embed 能力、外部知识库适配和高级标注运营系统。 - 不以高并发公网 SaaS 为目标,当前场景聚焦团队内部本地部署和中小规模并发。 ### 技术栈 - 后端:Python + FastAPI,优先服务 AI Agent、RAG、流式对话和快速迭代。 - 前端:React,提供管理后台与对话界面。 - 数据存储:PostgreSQL 作为主业务库,`pgvector` 作为向量检索方案。 - 缓存:Redis,用于会话态、热点配置、检索结果和限流计数。 - AI 能力:优先使用 Python 生态中的主流 SDK 与框架,如模型厂商官方 SDK、LangChain/LlamaIndex 等按需引入。 - 部署:基于 Docker / Docker Compose 进行本地化部署。 ### 部署与运维预期 - 默认部署形态为单机或单台服务器上的 Docker Compose,服务规模面向 20-50 人团队内部使用。 - 核心压力在对话接口的流式 SSE 连接与上游模型调用并发,容量规划优先关注并发会话数、首 Token 延迟和上游模型稳定性,而不是纯 HTTP QPS。 - 推荐基础组件包括反向代理、Web/API 服务、后台 Worker、PostgreSQL、Redis 和文件持久化卷。 - 必须提前考虑 SSE 超时与心跳、限流、日志追踪、模型调用重试、后台任务隔离、数据库备份和配置密钥管理。 - 第一阶段追求可观测、可恢复、可迭代的工程基线,而不是过度设计的分布式架构。
总结
在动代码第一行把产品的边界想清楚了
你会发现这其实是一个问对问题鉴别问题的过程。其实最难的是这一步,怎么问对问题,怎么鉴别问题,这都是需要积累的
整个五步过程:调研杠杆,功能取舍,技术选型,运维预期,落成文字

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)