为了手写 OpenRouter Starter,我先读了 Spring AI 的源码(二)
解读源码
在上一章我们先是对 ChatClient 相关的参数构造进行了解析,接下来我们将进入顾问调用链的部分
我们看流式请求的例子:
/**
* 流式聊天
*
* @return
*/
@GetMapping(value = "/generateStream", produces = "text/event-stream;charset=utf-8")
public Flux<String> generateStream(@RequestParam(value = "message", defaultValue = "你是谁?") String message) {
// 创建 ChatClient
ChatClient.ChatClientRequestSpec chatClientRequestSpec = ChatClient.create(deepseekChatModel)
.prompt()
// 构建配置
.options(DeepSeekChatOptions.builder()
.model(DeepSeekApi.ChatModel.DEEPSEEK_CHAT)
.build())
.user(message);
// 创建 advisors
List<Advisor> advisors = new ArrayList<>();
// 添加自定义的 ChatMemoryAdvisor
advisors.add(new CustomChatMemoryAdvisor());
// 创建 tools
List<Object> tools = new ArrayList<>();
// 添加 DateTimeTools
tools.add(new DateTimeTools());
// 添加 advisors
chatClientRequestSpec.advisors(advisors);
chatClientRequestSpec.tools(tools);
return chatClientRequestSpec.stream()
.chatResponse()
.mapNotNull(chatResponse -> {
// 获取响应内容
DeepSeekAssistantMessage assistantMessage = (DeepSeekAssistantMessage) chatResponse.getResult().getOutput();
log.info("==> 输出内容: {}", assistantMessage.getText());
log.info("==> 思考内容: {}", assistantMessage.getReasoningContent());
return assistantMessage.getText();
});
}
接下来我们将解读 return 的这段代码在底层做了什么
return chatClientRequestSpec.stream()
.chatResponse()
.mapNotNull(chatResponse -> {
// 获取响应内容
DeepSeekAssistantMessage assistantMessage = (DeepSeekAssistantMessage) chatResponse.getResult().getOutput();
log.info("==> 输出内容: {}", assistantMessage.getText());
log.info("==> 思考内容: {}", assistantMessage.getReasoningContent());
return assistantMessage.getText();
});
stream()
我们先看stream() 方法,由于 stream() 方法是被 ChatClient.ChatClientRequestSpec 调用的,而 ChatClient.ChatClientRequestSpec 是个接口
public interface ChatClient {
// ... 省略
public interface ChatClientRequestSpec {
// ... 省略
}
// ... 省略
}
我们直接看实现类 DefaultChatClient.DefaultChatClientRequestSpec 里的 stream() 方法
public class DefaultChatClient implements ChatClient {
// ... 省略
public static class DefaultChatClientRequestSpec implements ChatClient.ChatClientRequestSpec {
// ... 省略
// 执行流式调用,返回一个用于处理流式响应的规范对象
public ChatClient.StreamResponseSpec stream() {
// 构建包含所有已注册顾问的处理链
BaseAdvisorChain advisorChain = this.buildAdvisorChain();
// 创建并返回默认流式响应规范,传入转化后的聊天客户端请求、顾问链和观测组件
return new DefaultStreamResponseSpec(
// 将当前请求规范转换为 ChatClientRequest
DefaultChatClientUtils.toChatClientRequest(this),
// 前面构建的顾问调用链
advisorChain,
// 可观测性注册表
this.observationRegistry,
// 观测约定
this.chatClientObservationConvention
);
}
// ... 省略
}
// ... 省略
}
我们可以看到 stream() 不直接调用模型,而是将请求包装成一个响应规范对象,把实际调用延迟到用户调用 .getContent() 或 .getFlux() 时才触发。
this.buildAdvisorChain()
我们深入查看一下 BaseAdvisorChain advisorChain = this.buildAdvisorChain()方法
// 私有方法,构建整个顾问调用链,负责将请求层层传递给最终的语言模型
private BaseAdvisorChain buildAdvisorChain() {
// 添加一个用于常规调用的聊天模型顾问到顾问列表末尾
// ChatModelCallAdvisor 是调用链的终点之一,它直接调用 chatModel.call()
this.advisors.add(
ChatModelCallAdvisor.builder()
.chatModel(this.chatModel)
.build()
);
// 添加一个用于流式调用的聊天模型顾问到顾问列表末尾
// ChatModelStreamAdvisor 是调用链的终点之一,它直接调用 chatModel.stream()
this.advisors.add(
ChatModelStreamAdvisor.builder()
.chatModel(this.chatModel)
.build()
);
// 构建并返回默认的环绕顾问链
// pushAll 将用户自定义的顾问 + 上面两个内置顾问压入链中
return DefaultAroundAdvisorChain.builder(this.observationRegistry)
// 设置观测约定
.observationConvention(this.advisorObservationConvention)
// 将所有顾问压入链
.pushAll(this.advisors)
.build();
}
通过 buildAdvisorChain() 源码得知在进行真正的请求调用之前,会将一个叫 ChatModelStreamAdvisor (当前例子为流式请求,因此 ChatModelCallAdvisor 不在讨论的范围中) 压入顾问调用链中,作为调用链的终点,最后将所有的顾问压入链中,构建 DefaultAroundAdvisorChain 对象进行返回。这里的 pushAll() 方法暗藏玄鸡了,他会在该方法进行一次对所有顾问的排序,我们会在后面的补充章节进行说明。
顾问调用链是什么?
我们可以来到 Spring AI 的官网中: Advisor 看到对 Advisor 的解释
Spring AI Advisor API 为拦截、修改和增强 Spring 应用中的 AI 交互提供了灵活强大的方式。通过该 API,开发者能构建更复杂、可复用且易维护的 AI 组件。
我们就简单概括一下,Advisor 的存在请求模型的整个过程中提供了相当大的扩展性,在底层中是使用了责任链模式(一个设计模式),通过责任链和 Stream 流式请求,让我们可以在调用模型前、调用模型时、调用模型后,都可以加上自定义的处理。
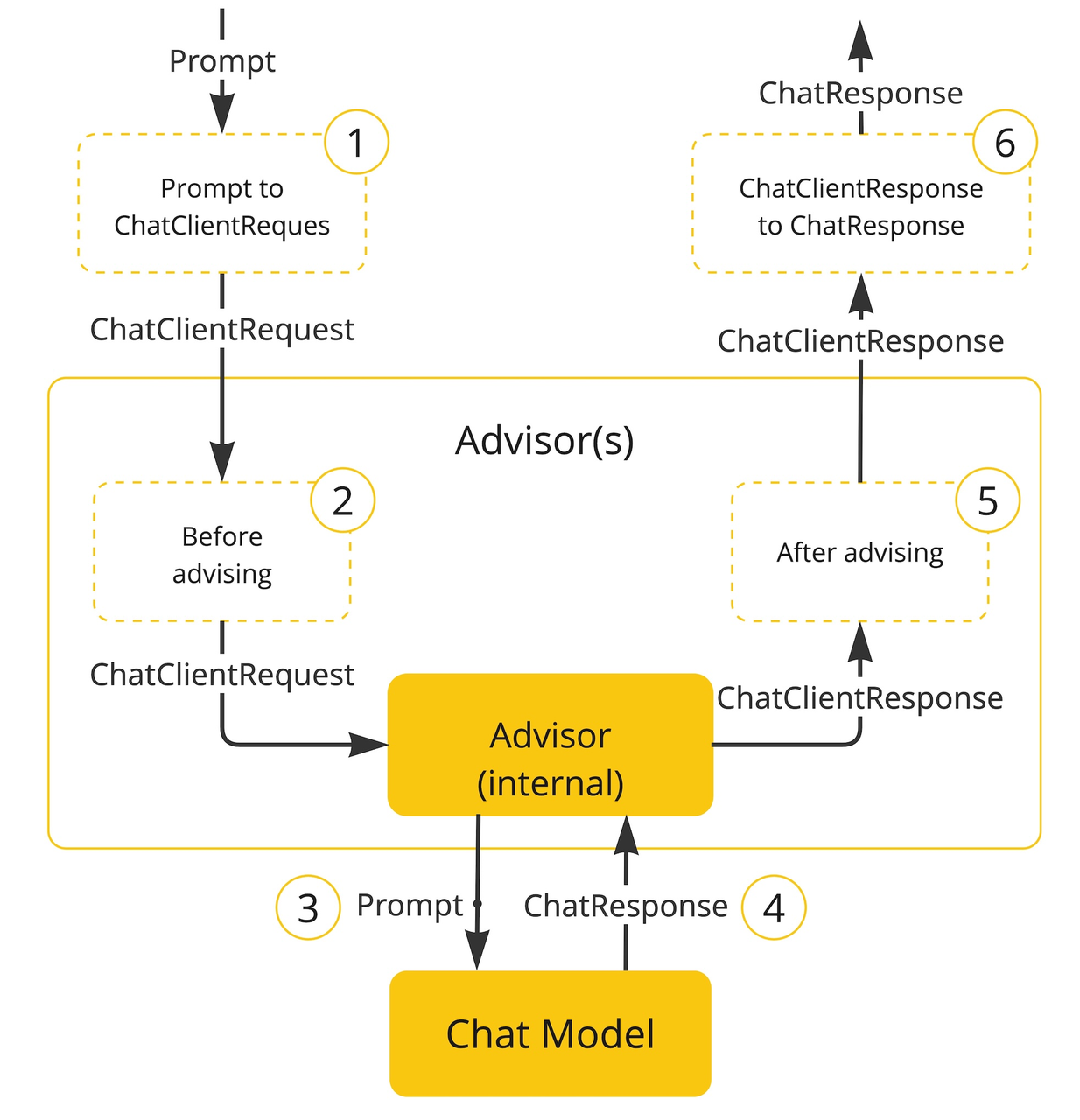
用官方中最经典的例子就是调用模型前,获取到对话窗口的前几条聊天记录,将聊天记录和用户发送的消息整合,一并发送给模型,详情可以看官方的实现:聊天记忆
ChatClientRequest toChatClientRequest(DefaultChatClient.DefaultChatClientRequestSpec)
源码中有一个工具类的方法调用可以将当前请求规范转换为 ChatClientRequest,我们继续深入研读一下,这是一个长代码,我们分段来看
static ChatClientRequest toChatClientRequest(DefaultChatClient.DefaultChatClientRequestSpec inputRequest) {
Assert.notNull(inputRequest, "inputRequest cannot be null");
List<Message> processedMessages = new ArrayList();
String processedSystemText = inputRequest.getSystemText();
if (StringUtils.hasText(processedSystemText)) {
if (!CollectionUtils.isEmpty(inputRequest.getSystemParams())) {
processedSystemText = PromptTemplate.builder().template(processedSystemText).variables(inputRequest.getSystemParams()).renderer(inputRequest.getTemplateRenderer()).build().render();
}
processedMessages.add(SystemMessage.builder().text(processedSystemText).metadata(inputRequest.getSystemMetadata()).build());
}
if (!CollectionUtils.isEmpty(inputRequest.getMessages())) {
processedMessages.addAll(inputRequest.getMessages());
}
String processedUserText = inputRequest.getUserText();
if (StringUtils.hasText(processedUserText)) {
if (!CollectionUtils.isEmpty(inputRequest.getUserParams())) {
processedUserText = PromptTemplate.builder().template(processedUserText).variables(inputRequest.getUserParams()).renderer(inputRequest.getTemplateRenderer()).build().render();
}
processedMessages.add(UserMessage.builder().text(processedUserText).media(inputRequest.getMedia()).metadata(inputRequest.getUserMetadata()).build());
}
ChatOptions processedChatOptions = inputRequest.getChatOptions();
if (!inputRequest.getToolNames().isEmpty() || !inputRequest.getToolCallbacks().isEmpty() || !inputRequest.getToolCallbackProviders().isEmpty() || !CollectionUtils.isEmpty(inputRequest.getToolContext())) {
if (processedChatOptions == null) {
processedChatOptions = new DefaultToolCallingChatOptions();
} else if (processedChatOptions instanceof DefaultChatOptions) {
DefaultChatOptions defaultChatOptions = (DefaultChatOptions)processedChatOptions;
processedChatOptions = (ChatOptions)ModelOptionsUtils.copyToTarget(defaultChatOptions, ChatOptions.class, DefaultToolCallingChatOptions.class);
}
}
if (processedChatOptions instanceof ToolCallingChatOptions toolCallingChatOptions) {
if (!inputRequest.getToolNames().isEmpty()) {
Set<String> toolNames = ToolCallingChatOptions.mergeToolNames(new HashSet(inputRequest.getToolNames()), toolCallingChatOptions.getToolNames());
toolCallingChatOptions.setToolNames(toolNames);
}
List<ToolCallback> allToolCallbacks = new ArrayList(inputRequest.getToolCallbacks());
for(ToolCallbackProvider provider : inputRequest.getToolCallbackProviders()) {
allToolCallbacks.addAll(List.of(provider.getToolCallbacks()));
}
if (!allToolCallbacks.isEmpty()) {
List<ToolCallback> toolCallbacks = ToolCallingChatOptions.mergeToolCallbacks(allToolCallbacks, toolCallingChatOptions.getToolCallbacks());
ToolCallingChatOptions.validateToolCallbacks(toolCallbacks);
toolCallingChatOptions.setToolCallbacks(toolCallbacks);
}
if (!CollectionUtils.isEmpty(inputRequest.getToolContext())) {
Map<String, Object> toolContext = ToolCallingChatOptions.mergeToolContext(inputRequest.getToolContext(), toolCallingChatOptions.getToolContext());
toolCallingChatOptions.setToolContext(toolContext);
}
}
return ChatClientRequest.builder().prompt(Prompt.builder().messages(processedMessages).chatOptions(processedChatOptions).build()).context(new ConcurrentHashMap(inputRequest.getAdvisorParams())).build();
}
创建消息列表
// 静态工具方法,将面向用户的请求规范转换为内部统一的请求对象
static ChatClientRequest toChatClientRequest(
// 接受用户通过 fluent API 构建的请求规范
DefaultChatClient.DefaultChatClientRequestSpec inputRequest
) {
// 断言输入不为空
Assert.notNull(inputRequest, "inputRequest cannot be null");
// 创建一个空的消息列表,用于存放最终处理后的消息
List<Message> processedMessages = new ArrayList();
处理系统提示文本
// 获取用户设置的系统提示文本
String processedSystemText = inputRequest.getSystemText();
// 如果系统文本有实际内容
if (StringUtils.hasText(processedSystemText)) {
// 如果有系统参数(模板变量),使用 PromptTemplate 进行渲染
if (!CollectionUtils.isEmpty(inputRequest.getSystemParams())) {
// 使用模板渲染器将占位符替换为实际值
// 例如 "You are a {role}" + {role: "assistant"} → "You are a assistant"
processedSystemText = PromptTemplate.builder()
.template(processedSystemText) // 模板字符串
.variables(inputRequest.getSystemParams()) // 变量映射
.renderer(inputRequest.getTemplateRenderer()) // 模板渲染器
.build()
.render(); // 执行渲染
}
// 将渲染后的系统文本封装为 SystemMessage 并添加到消息列表
processedMessages.add(
SystemMessage.builder()
.text(processedSystemText)
.metadata(inputRequest.getSystemMetadata())
.build()
);
}
处理历史消息
// 如果请求中包含了历史对话消息,直接全部添加到处理后的消息列表中
if (!CollectionUtils.isEmpty(inputRequest.getMessages())) {
processedMessages.addAll(inputRequest.getMessages());
}
处理用户文本
// 获取用户设置的提示文本
String processedUserText = inputRequest.getUserText();
// 如果用户文本有实际内容
if (StringUtils.hasText(processedUserText)) {
// 如果有用户参数,同样使用 PromptTemplate 进行模板渲染
if (!CollectionUtils.isEmpty(inputRequest.getUserParams())) {
// 渲染用户模板,例如 "Write a poem about {topic}"
processedUserText = PromptTemplate.builder()
.template(processedUserText)
.variables(inputRequest.getUserParams())
.renderer(inputRequest.getTemplateRenderer())
.build()
.render();
}
// 将渲染后的用户文本封装为 UserMessage,同时携带多媒体内容和元数据
processedMessages.add(
UserMessage.builder()
.text(processedUserText)
// 图片、音频等多媒体附件
.media(inputRequest.getMedia())
.metadata(inputRequest.getUserMetadata())
.build()
);
}
与系统文本的区别:UserMessage 额外携带了 media(多媒体内容),支持图文混合输入。
处理聊天选项(Tool Calling 相关)
// 获取用户设置的聊天选项(温度、模型等)
ChatOptions processedChatOptions = inputRequest.getChatOptions();
// 如果有任何工具相关的配置,需要确保 ChatOptions 支持 Tool Calling
// 有工具名称
if (!inputRequest.getToolNames().isEmpty()
// 有工具回调
|| !inputRequest.getToolCallbacks().isEmpty()
// 有工具回调提供者
|| !inputRequest.getToolCallbackProviders().isEmpty()
// 有工具上下文
|| !CollectionUtils.isEmpty(inputRequest.getToolContext())) {
if (processedChatOptions == null) {
// 如果还没有设置 ChatOptions,创建一个默认的 ToolCallingChatOptions
processedChatOptions = new DefaultToolCallingChatOptions();
} else if (processedChatOptions instanceof DefaultChatOptions) {
// 如果设置了基础 ChatOptions,将其升级为支持 Tool Calling 的版本
// copyToTarget 会将 DefaultChatOptions 的属性拷贝到 DefaultToolCallingChatOptions 中
DefaultChatOptions defaultChatOptions = (DefaultChatOptions) processedChatOptions;
processedChatOptions = (ChatOptions) ModelOptionsUtils.copyToTarget(
defaultChatOptions,
ChatOptions.class,
// 目标类型:支持工具调用
DefaultToolCallingChatOptions.class
);
}
}
关键设计:DefaultChatOptions 是基础的聊天选项(温度、topP 等),ToolCallingChatOptions 扩展了基础选项,增加了工具调用能力,当用户配置了工具但选项是基础版时,会自动升级为工具调用版
合并工具配置
// 如果处理后的选项支持 Tool Calling
if (processedChatOptions instanceof ToolCallingChatOptions toolCallingChatOptions) {
// 将用户在请求中指定的工具名称与默认工具名称合并
if (!inputRequest.getToolNames().isEmpty()) {
Set<String> toolNames = ToolCallingChatOptions.mergeToolNames(
new HashSet(inputRequest.getToolNames()),
toolCallingChatOptions.getToolNames()
);
toolCallingChatOptions.setToolNames(toolNames);
}
// 从直接设置的回调和提供者中收集所有 ToolCallback
List<ToolCallback> allToolCallbacks = new ArrayList(inputRequest.getToolCallbacks());
for (ToolCallbackProvider provider : inputRequest.getToolCallbackProviders()) {
// 遍历每个提供者,获取其提供的工具回调
allToolCallbacks.addAll(List.of(provider.getToolCallbacks()));
}
// 如果收集到了回调,与默认回调合并
if (!allToolCallbacks.isEmpty()) {
List<ToolCallback> toolCallbacks = ToolCallingChatOptions.mergeToolCallbacks(
allToolCallbacks,
toolCallingChatOptions.getToolCallbacks()
);
// 验证工具回调的合法性(如是否有重复名称等)
ToolCallingChatOptions.validateToolCallbacks(toolCallbacks);
toolCallingChatOptions.setToolCallbacks(toolCallbacks);
}
// 将请求中的工具上下文与默认工具上下文合并
if (!CollectionUtils.isEmpty(inputRequest.getToolContext())) {
Map<String, Object> toolContext = ToolCallingChatOptions.mergeToolContext(
inputRequest.getToolContext(),
toolCallingChatOptions.getToolContext()
);
toolCallingChatOptions.setToolContext(toolContext);
}
}
合并策略的真正含义:这里会先检查每个工具名称或回调是否已经存在于默认配置中。如果存在,优先使用默认配置中的版本(因为默认配置中的工具通常是完整注册的,参数更全面)。这种合并机制确保了用户请求级别的工具配置可以安全地叠加在默认配置之上,而不会因覆盖导致工具定义丢失关键信息。
构建最终的 ChatClientRequest
// 构建并返回最终的 ChatClientRequest 对象
return ChatClientRequest.builder()
.prompt(
Prompt.builder()
// 组装好的消息列表
.messages(processedMessages)
// 处理好的聊天选项
.chatOptions(processedChatOptions)
.build()
)
// 上下文使用 ConcurrentHashMap 包装顾问参数,确保线程安全
.context(new ConcurrentHashMap(inputRequest.getAdvisorParams()))
.build();
}
ChatClientRequest 封装了 Prompt(消息 + 选项)和 context(顾问共享上下文)。ConcurrentHashMap 的选择是为了保证流式场景下的线程安全性。
这个对象最终会被传给 DefaultStreamResponseSpec
总结
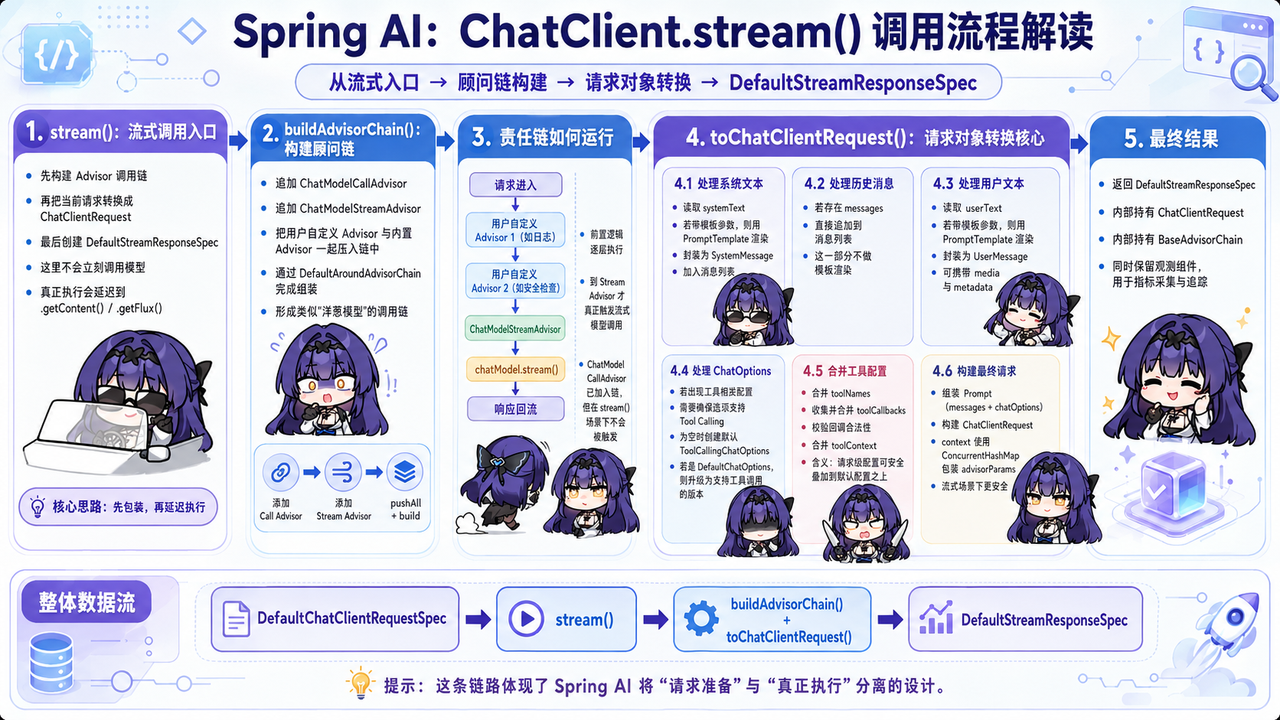
这一整个方法其实就是做一件事将 DefaultChatClientRequestSpec(面向用户的 API 构建产物)转换为 ChatClientRequest(面向内部的请求封装),我们可以用下面的图片描述完源码的流程
chatResponse()
接下来我们解读 chatResponse() 方法,它用于在 stream() 方法请求封装后,真正将请求发送到模型的方法
public interface StreamResponseSpec {
Flux<ChatClientResponse> chatClientResponse();
Flux<ChatResponse> chatResponse();
Flux<String> content();
}
我们看到 StreamResponseSpec 依然是个接口,我们直接看对应实现类 DefaultStreamResponseSpec 的 chatResponse() 方法
// 获取流式 ChatResponse,返回一个 Flux 流,可以逐个处理每次模型返回的响应块
public Flux<ChatResponse> chatResponse() {
// 调用核心方法获取被观测包装的 ChatClientResponse 流
// mapNotNull 过滤掉空值并提取内部的 chatResponse 对象
return this.doGetObservableFluxChatResponse(this.request)
.mapNotNull(ChatClientResponse::chatResponse);
}
该方法返回了 Reactor 的响应式流 ,doGetObservableFluxChatResponse 方法会返回 ChatClientResponse 类型对象,ChatClientResponse 是 Spring AI 的响应包装,包含更多元数据,这里只提取核心的 ChatResponse 返回给用户,并使用 mapNotNull 确保流中不会有空值污染下游。接下来我们将详细解读一下 doGetObservableFluxChatResponse(ChatClientRequest) 方法,在底层里他究竟干了些什么
doGetObservableFluxChatResponse(ChatClientRequest)
同样内容过多,我们分段解析,对于核心的调用方法和技术,我们会重点讨论
整体结构与 Flux.deferContextual
// 私有方法,创建被观测系统包装的流式响应
private Flux<ChatClientResponse> doGetObservableFluxChatResponse(
ChatClientRequest chatClientRequest // 之前组装好的请求对象
) {
// deferContextual 确保每次订阅时都重新执行内部逻辑
// 并且可以访问 Reactor 的 Context(上下文信息)
return Flux.deferContextual((contextView) -> {
为什么要使用 Flux.deferContextual 方法?
Flux.deferContextual()虽然每次订阅时都要重新创建,但是他支持访问 Reactor Context,非常适合在需要动态上下文(如当前场景中需要调用模型的观测信息)
构建观测上下文
// 构建观测上下文对象,记录当前请求的关键信息
ChatClientObservationContext observationContext = ChatClientObservationContext.builder()
// 原始请求
.request(chatClientRequest)
// 参与流式调用的顾问链
.advisors(this.advisorChain.getStreamAdvisors())
// 标记为流式调用
.stream(true)
.build();
ChatClientObservationContext 继承于 Micrometer 的 Observation.Context,这个 observationContext 是一个数据载体,它会被 Micrometer 观测系统使用:
-
在观测开始时可以记录请求信息
-
在观测结束时记录响应信息
-
可以将观测到的信息导出到
Prometheus、Zipkin等监控系统
该观测的层级也顾名思义,是 ChatClient 层的
Micrometer 观测系统是什么?
在 Java 领域,Micrometer 是一个为应用程序提供指标监控 (Metrics) 的门面库。它的核心作用是提供一套统一的 API,让你能像使用 SLF4J 一样,方便地记录和管理应用的各种性能指标,并将它们导出到不同的监控系统(如 Prometheus、Datadog 等)中。
在 Spring AI 官网中可以看到对 Observability 的描述: Observability
我们就对官网的内容总结一下,官网对 Observability 描述都是说在调用 Spring AI 支持的模型(包括聊天模型、嵌入模型等)、工具调用和模型操作相关的技术器等,开发者可以使用相关配置,来进行模型调用的信息观测。
创建并启动观测
// 创建一个 Observation 实例
Observation observation = ChatClientObservationDocumentation.AI_CHAT_CLIENT
.observation(
// 自定义约定(优先)
this.observationConvention,
// 默认约定
DefaultChatClient.DEFAULT_CHAT_CLIENT_OBSERVATION_CONVENTION,
// 延迟提供上下文
() -> observationContext,
// 注册表
this.observationRegistry
)
// 设置父观测:从 Reactor Context 中获取,实现分布式追踪链
.parentObservation(
(Observation)contextView.getOrDefault("micrometer.observation", null)
)
// 启动观测,开始计时和记录
.start();
这段代码,先检查用户是否自定义了 observationConvention,没有再使用默认约定
() -> observationContext 是 Supplier,在需要时才提供上下文,最后了父观测,从 Reactor Context 中获取,实现了跨线程的追踪链延续
执行顾问链并包装观测
// 真正的流式调用:通过顾问链执行请求
Flux var10000 = this.advisorChain.nextStream(chatClientRequest);
Objects.requireNonNull(observation);
// 对原始流进行观测包装
Flux<ChatClientResponse> chatClientResponse = var10000
// 错误处理:发生异常时记录到观测
.doOnError(observation::error)
// 结束处理:无论成功失败,都停止观测
.doFinally((s) -> observation.stop())
// 将观测对象注册到 Reactor Context,传递给下游
.contextWrite((ctx) -> ctx.put("micrometer.observation", observation));
在这段代码中开始了真正的流式调用 this.advisorChain.nextStream ,我们会在解说完当前方法的全部代码后,针对该方法进行解读,对于后面 var10000 的数据处理,也都是为了观测的。
聚合流式响应
// 获取全局的消息聚合器
ChatClientMessageAggregator var6 = DefaultChatClient.CHAT_CLIENT_MESSAGE_AGGREGATOR;
Objects.requireNonNull(observationContext);
// 对响应流进行聚合处理,并在聚合过程中更新观测上下文
return var6.aggregateChatClientResponse(
// 被观测包装的响应流
chatClientResponse,
// 回调:设置响应到观测上下文
observationContext::setResponse
);
});
}
在这里主要的就是对响应流进行了聚合处理,最后返回 Flux<ChatClientResponse> 类型
总结
该方法展示了stream() 调用后如何获取流式响应,以及观测系统的完整集成。我们可以用下面一张图展示一些方法得的整体

接下来,我们将针对里面的核心方法 this.advisorChain.nextStream(ChatClientRequest) 进行讲解
this.advisorChain.nextStream(ChatClientRequest);
该方法是准备真正流式调用的入口,我们 ctrl + 左键 进入查看一下
public interface StreamAdvisorChain extends AdvisorChain {
Flux<ChatClientResponse> nextStream(ChatClientRequest chatClientRequest);
List<StreamAdvisor> getStreamAdvisors();
}
可以看到 nextStream(ChatClientRequest) 方法在 StreamAdvisorChain 接口中,我们直接查找他的实现类 DefaultAroundAdvisorChain,找到 nextStream(ChatClientRequest) 方法
public Flux<ChatClientResponse> nextStream(ChatClientRequest chatClientRequest) {
Assert.notNull(chatClientRequest, "the chatClientRequest cannot be null");
return Flux.deferContextual((contextView) -> {
if (this.streamAdvisors.isEmpty()) {
return Flux.error(new IllegalStateException("No StreamAdvisors available to execute"));
} else {
StreamAdvisor advisor = (StreamAdvisor)this.streamAdvisors.pop();
AdvisorObservationContext observationContext = AdvisorObservationContext.builder().advisorName(advisor.getName()).chatClientRequest(chatClientRequest).order(advisor.getOrder()).build();
Observation observation = AdvisorObservationDocumentation.AI_ADVISOR.observation(this.observationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext, this.observationRegistry);
observation.parentObservation((Observation)contextView.getOrDefault("micrometer.observation", (Object)null)).start();
Flux<ChatClientResponse> chatClientResponse = Flux.defer(() -> {
Flux var10000 = advisor.adviseStream(chatClientRequest, this);
Objects.requireNonNull(observation);
return var10000.doOnError(observation::error).doFinally((s) -> observation.stop()).contextWrite((ctx) -> ctx.put("micrometer.observation", observation));
});
ChatClientMessageAggregator var10000 = CHAT_CLIENT_MESSAGE_AGGREGATOR;
Objects.requireNonNull(observationContext);
return var10000.aggregateChatClientResponse(chatClientResponse, observationContext::setChatClientResponse);
}
});
}
开始调用
// 流式调用链的下一个节点,返回被观测包装的 Flux<ChatClientResponse>
public Flux<ChatClientResponse> nextStream(ChatClientRequest chatClientRequest) {
// 请求参数的非空校验
Assert.notNull(chatClientRequest, "the chatClientRequest cannot be null");
// 使用 deferContextual 确保每次订阅时重新执行
// 并能访问 Reactor Context 中的观测信息
return Flux.deferContextual((contextView) -> {
责任链的终止条件
// 检查顾问链是否已空
if (this.streamAdvisors.isEmpty()) {
// 如果为空,说明链已耗尽但没有找到真正的调用者(如 ChatModelStreamAdvisor)
// 这是一个异常状态,返回错误信号
return Flux.error(
new IllegalStateException("No StreamAdvisors available to execute")
);
}
为什么会发生这种情况?
正常情况下,链的末端应该是 ChatModelStreamAdvisor,它负责真正调用 chatModel.stream(),并且不再调用 chain.nextStream(),从而终止递归。如果所有 Advisor 都选择继续往下传(都调用了 nextStream),递归就会一直进行直到链被耗尽。这是一种防御性编程,防止配置错误导致责任链空转。
从链中取出当前顾问
else {
// 按照 Order 排序后的索引顺序,取出当前应执行的 Advisor
// 不是栈的 pop,而是有序列表的顺序取出
StreamAdvisor advisor = (StreamAdvisor)this.streamAdvisors.pop();
取出责任链中的顾问,这里的 pop() 不是栈的后进先出,而是一个有序列表的顺序取出。所有 Advisor 在构建链时已经按定义好的 Order 的值从小到大排序,pop() 只是取出当前索引位置的元素并将索引前移。在补充章节里我们会详细说明一下,他是怎么进行排序的。
为当前 Advisor 创建观测
// 构建当前 Advisor 级别的观测上下文
AdvisorObservationContext observationContext = AdvisorObservationContext.builder()
// Advisor 的名称,用于日志和监控标识
.advisorName(advisor.getName())
// 当前请求的快照
.chatClientRequest(chatClientRequest)
// Advisor 的排序权重
.order(advisor.getOrder())
.build();
// 创建 Advisor 级别的 Observation 实例
Observation observation = AdvisorObservationDocumentation.AI_ADVISOR
.observation(
// 用户可以自定义的观测约定
this.observationConvention,
// 框架默认的观测约定(兜底)
DEFAULT_OBSERVATION_CONVENTION,
// Supplier:延迟提供上下文,避免过早创建
() -> observationContext,
// 注入的观测注册表
this.observationRegistry
)
// 从 Reactor Context 中获取父观测,建立父子追踪关系
.parentObservation(
(Observation)contextView.getOrDefault(
"micrometer.observation", null
)
)
// 开始计时,记录观测开始时间
.start();
在该段代码中,就是为了创建出 Advisor 级别的 Observation 实例,然后开始记录 Advisor 责任链调用时的信息,当前观测的层级则是 Advisor 的。
递归调用 Advisor
// 使用 Flux.defer 延迟执行当前 Advisor 的逻辑
Flux<ChatClientResponse> chatClientResponse = Flux.defer(() -> {
// 调用当前 Advisor 的 adviseStream 方法
// 第二个参数 this 是整个责任链对象,让 Advisor 可以调用 nextStream() 触发下一个
Flux var10000 = advisor.adviseStream(chatClientRequest, this);
Objects.requireNonNull(observation);
// 对当前 Advisor 返回的 Flux 流包装观测信号
return var10000
// 如果发生错误,记录到当前观测
.doOnError(observation::error)
// 无论成功/失败/取消,停止计时
.doFinally((s) -> observation.stop())
.contextWrite((ctx) ->
// 将当前观测写入 Context
ctx.put("micrometer.observation", observation)
);
});
这段代码是最主要的逻辑了,在 Flux.defer() 方法中,使用 Advisor 开始调用责任链中的对象,对 Advisor 返回的 Flux 流,包装观测信号。
Flux.defer() 确保 advisor.adviseStream() 在每次订阅时才执行,而不是在声明时立即执行。这在响应式编程中很关键,每次订阅都是一个新的请求,应该有独立的时间计数和观测。如果有重试机制,每次重试都会重新走一遍 Advisor 链。还避免在构建 Flux 管道时就触发副作用的执行。
advisor.adviseStream(chatClientRequest, this) 则是将 请求体 和 自己(整个Advisor链) 又传入了advisor.adviseStream(ChatClientRequest,StreamAdvisorChain) 中,让在 Advisor 做完自己需要处理的部分后,可以继续使用 StreamAdvisorChain 的 nextStream() 继续进行递归传递。
聚合响应并返回
// 获取全局的消息聚合器(单例)
ChatClientMessageAggregator var10000 = CHAT_CLIENT_MESSAGE_AGGREGATOR;
Objects.requireNonNull(observationContext);
// 对当前 Advisor 的响应流进行聚合
// 聚合器负责:收集完整响应内容、处理工具调用中间状态
// 通过回调更新观测上下文中的响应信息
return var10000.aggregateChatClientResponse(
// 当前 Advisor 的响应流
chatClientResponse,
// 更新观测上下文的回调
observationContext::setChatClientResponse
);
}
});
}
该段代码的作用,则是将流式返回的多个 ChatClientResponse 的 ChatResponse片段聚合成一个完整的 ChatResponse,同时在聚合过程中收集上下文信息,并通过回调通知外部更新观测数据。
总结
该段代码最主要的核心代码为 advisor.adviseStream(chatClientRequest, this),这句代码开始准备正式的调用模型了,将 请求体 和 自己(整个责任链) 传入了advisor.adviseStream(ChatClientRequest,StreamAdvisorChain) 中,让 Advisor 回调 nextStream(),实现递归传递。后面则是对 Advisor 的执行情况包装观测。

总结
通过 stream() 和 chatResponse() 方法,我们可以了解到在 stream() 中就是将面向用户的 API 构建产物转换为面向内部的请求封装。chatResponse() 则是开始准备正式的调用,处理Advisor链中的对象,最后对返回的 Flux 响应流开始观测。可以说这 stream() 和 chatResponse() 的前半部分,都是在构建责任链、创建观测、包装响应式操作符。所有事情都准备就绪后,等待最后调用模型时,整个管道才开始流动。
补充
在上面的 stream() 开篇中,我们就有提到过
通过
buildAdvisorChain()源码得知在进行真正的请求调用之前,会将一个叫ChatModelStreamAdvisor(当前例子为流式请求,因此ChatModelCallAdvisor不在讨论的范围中) 压入顾问调用链中,作为调用链的终点,最后将所有的顾问压入链中,构建DefaultAroundAdvisorChain对象进行返回。这里的pushAll()方法暗藏玄鸡了,他会在该方法进行一次对所有顾问的排序,我们会在后面的补充章节进行说明。
代码如下:
// 私有方法,构建整个顾问调用链,负责将请求层层传递给最终的语言模型
private BaseAdvisorChain buildAdvisorChain() {
// 添加一个用于常规调用的聊天模型顾问到顾问列表末尾
// ChatModelCallAdvisor 是调用链的终点之一,它直接调用 chatModel.call()
this.advisors.add(
ChatModelCallAdvisor.builder()
.chatModel(this.chatModel)
.build()
);
// 添加一个用于流式调用的聊天模型顾问到顾问列表末尾
// ChatModelStreamAdvisor 是调用链的终点之一,它直接调用 chatModel.stream()
this.advisors.add(
ChatModelStreamAdvisor.builder()
.chatModel(this.chatModel)
.build()
);
// 构建并返回默认的环绕顾问链
// pushAll 将用户自定义的顾问 + 上面两个内置顾问压入链中
return DefaultAroundAdvisorChain.builder(this.observationRegistry)
// 设置观测约定
.observationConvention(this.advisorObservationConvention)
// 将所有顾问压入链
.pushAll(this.advisors)
.build();
}
最后的 DefaultAroundAdvisorChain.builder(this.observationRegistry),调用了 pushAll() 方法,在这个方法中对责任链中的对象进行了递增排序,根据顾问对象的 Oredr 来进行。在 chatResponse() 方法中,就可以直接使用 pop() 方法,取出 Oredr 最小的顾问
代码如下:
else {
// 按照 Order 排序后的索引顺序,取出当前应执行的 Advisor
// 不是栈的 pop,而是有序列表的顺序取出
StreamAdvisor advisor = (StreamAdvisor)this.streamAdvisors.pop();
口说无用,我们来看看源代码究竟是怎样实现的
DefaultAroundAdvisorChain
从 stream() 方法,就可以知道 DefaultAroundAdvisorChain 是最核心的类,我们也直接查看他的实现
DefaultAroundAdvisorChain 是 Advisor 责任链的核心实现。它在 ChatClient 执行 call() 或 stream() 时,按照 Ordered 优先级依次执行每个 Advisor。同时,它为每一层Advisor 提供了独立的 Micrometer 观测,实现完整的可观测性。
类比:它像 Web 框架中的 Filter 链或拦截器链,请求层层进入,响应层层返回。
结构
public class DefaultAroundAdvisorChain implements BaseAdvisorChain {
// Advisor 观测的默认约定,当用户未自定义观测命名和标签格式时使用此默认实现
public static final AdvisorObservationConvention DEFAULT_OBSERVATION_CONVENTION = new DefaultAdvisorObservationConvention();
// 全局唯一的消息聚合器实例(单例模式),负责将流式响应中的多个 ChatResponse 片段拼接成完整响应
private static final ChatClientMessageAggregator CHAT_CLIENT_MESSAGE_AGGREGATOR = new ChatClientMessageAggregator();
// 原始 CallAdvisor 列表的不可变快照,用于 getCallAdvisors() 方法返回,防止外部修改影响内部工作队列
private final List<CallAdvisor> originalCallAdvisors;
// 原始 StreamAdvisor 列表的不可变快照,用于 getStreamAdvisors() 方法返回,防止外部修改影响内部工作队列
private final List<StreamAdvisor> originalStreamAdvisors;
// 工作用的 CallAdvisor 双端队列,ConcurrentLinkedDeque 保证线程安全
// pop() 从队首取出优先级最高的 Advisor 执行,每次取出后队列长度减一
private final Deque<CallAdvisor> callAdvisors;
// 工作用的 StreamAdvisor 双端队列,ConcurrentLinkedDeque 保证线程安全
// pop() 从队首取出优先级最高的 Advisor 执行,每次取出后队列长度减一
private final Deque<StreamAdvisor> streamAdvisors;
// Micrometer 观测注册表,用于创建和管理 Observation 实例,是整个观测系统的入口
private final ObservationRegistry observationRegistry;
// Advisor 级别的观测约定,控制观测的命名、标签和键值对格式,用户可自定义,无则使用默认约定
private final AdvisorObservationConvention observationConvention;
/**
* 私有构造器,由 Builder 调用创建实例。
* 接收已排序的 Advisor 队列,并创建不可变快照供外部查询。
*
* @param observationRegistry Micrometer 观测注册表,不能为空
* @param callAdvisors 已按 Order 排序的 CallAdvisor 双端队列,不能为空
* @param streamAdvisors 已按 Order 排序的 StreamAdvisor 双端队列,不能为空
* @param observationConvention Advisor 观测约定,可为空,为空时使用默认约定
*/
DefaultAroundAdvisorChain(ObservationRegistry observationRegistry, Deque<CallAdvisor> callAdvisors,
Deque<StreamAdvisor> streamAdvisors, @Nullable AdvisorObservationConvention observationConvention)
/**
* 静态工厂方法,创建 Builder 实例,开始构建 DefaultAroundAdvisorChain。
* Builder 模式允许链式调用 push / pushAll 等方法逐步添加 Advisor。
*
* @param observationRegistry Micrometer 观测注册表,用于后续创建所有 Advisor 级别的观测
* @return 新的 Builder 实例
*/
public static Builder builder(ObservationRegistry observationRegistry)
/**
* 同步调用的责任链入口。
* 从已排序的 callAdvisors 队列中取出优先级最高的 Advisor 执行,
* 并在该 Advisor 的观测范围内记录其执行过程(耗时、成功/失败状态等)。
* Advisor 内部通过调用 this.nextCall() 触发下一个 Advisor,形成递归调用链。
* 链的终点是 ChatModelCallAdvisor,它直接调用 chatModel.call() 终止递归。
*
* @param chatClientRequest 聊天客户端请求对象,包含消息、选项、工具配置等
* @return 当前 Advisor 处理后的 ChatClientResponse
* @throws IllegalStateException 如果 callAdvisors 队列为空,说明缺少终端 Advisor
*/
@Override
public ChatClientResponse nextCall(ChatClientRequest chatClientRequest)
/**
* 流式调用的责任链入口。
* 从已排序的 streamAdvisors 队列中取出优先级最高的 Advisor 执行,
* 并为该 Advisor 创建独立的观测(作为当前 Reactor Context 中父观测的子观测)。
* 使用 Flux.deferContextual 确保每次订阅时重新执行整条链,
* 同时通过 Reactor Context 传递观测信息,实现跨线程的追踪链。
* Advisor 内部通过调用 this.nextStream() 触发下一个 Advisor,形成递归调用链。
* 链的终点是 ChatModelStreamAdvisor,它直接调用 chatModel.stream() 终止递归。
* 返回的流式响应会经过消息聚合器拼接成完整响应。
*
* @param chatClientRequest 聊天客户端请求对象,包含消息、选项、工具配置等
* @return 被观测包装的 Flux<ChatClientResponse> 流式响应
*/
@Override
public Flux<ChatClientResponse> nextStream(ChatClientRequest chatClientRequest)
/**
* 创建当前责任链的一个子链(切片),从指定 Advisor 之后开始。
* 常用于重试场景:某个 Advisor 执行失败后,从该 Advisor 的下一个开始重新执行。
* 返回的新链是一个独立的 CallAdvisorChain,包含原链中 after 之后的所有 Advisor。
*
* @param after 作为切分点的 Advisor,子链将从它的下一个 Advisor 开始
* @return 新的 CallAdvisorChain,包含 after 之后的所有 Advisor
* @throws IllegalArgumentException 如果指定的 Advisor 不在当前链中
*/
@Override
public CallAdvisorChain copy(CallAdvisor after)
/**
* 获取当前链中所有 CallAdvisor 的列表(不可变快照)。
* 返回的是构造时保存的原始列表副本,不受内部 pop() 操作影响。
*
* @return CallAdvisor 的不可变列表
*/
@Override
public List<CallAdvisor> getCallAdvisors()
/**
* 获取当前链中所有 StreamAdvisor 的列表(不可变快照)。
* 返回的是构造时保存的原始列表副本,不受内部 pop() 操作影响。
*
* @return StreamAdvisor 的不可变列表
*/
@Override
public List<StreamAdvisor> getStreamAdvisors()
/**
* 获取当前链使用的观测注册表。
* 主要用于 copy() 方法中创建子链时传递相同的观测注册表。
*
* @return Micrometer ObservationRegistry 实例
*/
@Override
public ObservationRegistry getObservationRegistry()
/**
* DefaultAroundAdvisorChain 的建造者内部类。
* 使用建造者模式逐步构建责任链,支持链式调用。
* 核心功能:
* 1. 通过 push / pushAll 添加 Advisor
* 2. 自动按 Order 排序,保证执行优先级
* 3. 分离 CallAdvisor 和 StreamAdvisor,分别管理
*/
public static final class Builder {
// 观测注册表,所有 Advisor 共享
private final ObservationRegistry observationRegistry;
// 使用 ConcurrentLinkedDeque,线程安全的双端队列,暂存 CallAdvisor
private final Deque<CallAdvisor> callAdvisors;
// 使用 ConcurrentLinkedDeque,线程安全的双端队列,暂存 StreamAdvisor
private final Deque<StreamAdvisor> streamAdvisors;
// 允许为空,用户自定义的观测约定
@Nullable
private AdvisorObservationConvention observationConvention;
/**
* Builder 构造器。
* 初始化线程安全的双端队列,用于暂存待排序的 Advisor。
*
* @param observationRegistry Micrometer 观测注册表,不能为空
*/
public Builder(ObservationRegistry observationRegistry)
/**
* 设置 Advisor 级别的观测约定。
* 如果未设置,最终将使用 DEFAULT_OBSERVATION_CONVENTION。
*
* @param observationConvention 用户自定义的观测约定,可为空
* @return 当前 Builder 实例,支持链式调用
*/
public Builder observationConvention(@Nullable AdvisorObservationConvention observationConvention)
/**
* 添加单个 Advisor 到队列中。
* 内部调用 pushAll 处理,统一走筛选和排序逻辑。
*
* @param advisor 要添加的 Advisor,不能为空
* @return 当前 Builder 实例,支持链式调用
*/
public Builder push(Advisor advisor)
/**
* 批量添加 Advisor 到队列中,并自动按 Order 排序。
*
* @param advisors 要添加的 Advisor 列表,不能为空,不能包含空元素
* @return 当前 Builder 实例,支持链式调用
*/
public Builder pushAll(List<? extends Advisor> advisors)
/**
* 按 Order 优先级重新排序所有 Advisor。
* 取出所有 Advisor 到 ArrayList,使用 Spring 的 OrderComparator 按 getOrder() 升序排列,
* 清空原队列后按排序后的顺序重新放入。值越小优先级越高,越先被 pop() 取出执行。
* 此方法在每次 push / pushAll 后自动调用,确保队列始终保持正确的排序状态。
*/
private void reOrder()
/**
* 构建 DefaultAroundAdvisorChain 实例。
* 将已排序的队列和观测组件传入构造器,创建最终的责任链对象。
* 此方法应在所有 Advisor 添加完毕后调用。
*
* @return 新的 DefaultAroundAdvisorChain 实例
*/
public DefaultAroundAdvisorChain build()
}
}
pushAll()
接下来我们将解释一下在正文中出现的方法 pushAll() 和相关的核心方法,nextStream() 方法在正文中就已经解释了,这里就不过多赘述
方法签名与参数校验
/**
* 批量添加 Advisor 到队列中,并自动按 Order 排序。
* 核心逻辑:
* 1. 从传入的 Advisor 列表中筛选出 CallAdvisor 和 StreamAdvisor
* 2. 分别添加到对应的队列中
* 3. 调用 reOrder() 按 getOrder() 值升序排列
* 注意:一个 Advisor 如果同时实现了 CallAdvisor 和 StreamAdvisor 接口,
* 会同时被两个队列引用。
*
* @param advisors 要添加的 Advisor 列表,不能为空,不能包含空元素
* @return 当前 Builder 实例,支持链式调用
*/
public Builder pushAll(List<? extends Advisor> advisors) {
// 参数非空校验:整个列表不能为空
Assert.notNull(advisors, "the advisors must be non-null");
// 参数元素非空校验:列表中不能包含 null 元素
// 防止后续 instanceof 检查和类型转换时出现空指针异常
Assert.noNullElements(advisors, "the advisors must not contain null elements");
这两行断言分别做了容器级别的校验和元素级别的校验,是典型的防御性编程。两者的检查粒度不同——前者防的是"传了个 null 列表",后者防的是"列表里混进了 null 元素"。如果只做前者,[advisor1, null, advisor2] 这样的列表就能逃过校验,到后面 instanceof 判断时不会报错但会导致排序时出错,排查起来很痛苦
空列表的短路处理
// 仅在列表非空时执行处理
if (!CollectionUtils.isEmpty(advisors)) {
为什么需要这个判断?
-
如果传入空列表
[],后续的stream().filter()会创建空流,虽然不会报错,但最后会调用reOrder()做一次无意义的排序 -
短路返回可以避免无意义的计算开销
筛选 CallAdvisor
// 从所有 Advisor 中筛选出实现了 CallAdvisor 接口的实例
List<CallAdvisor> callAroundAdvisorList = advisors.stream()
.filter(a -> a instanceof CallAdvisor)
.map(a -> (CallAdvisor) a)
.toList();
instanceof 筛选 + 强制转换:一个 Advisor 可能同时实现 CallAdvisor 和 StreamAdvisor,也可能只实现其中一个。这个筛选确保只把"能做同步调用"的 Advisor 放进 callAdvisors 队列
将 CallAdvisor 推入队列
// 如果有 CallAdvisor,逐个 push 到 callAdvisors 队列中
if (!CollectionUtils.isEmpty(callAroundAdvisorList)) {
callAroundAdvisorList.forEach(this.callAdvisors::push);
}
注意这里的 push() 是 Deque.push(),它会把元素添加到队首。但这只是中间状态——紧接着 reOrder() 会重新排序,所以 push 的位置并不影响最终顺序
筛选并推入 StreamAdvisor
// 从所有 Advisor 中筛选出实现了 StreamAdvisor 接口的实例
List<StreamAdvisor> streamAroundAdvisorList = advisors.stream()
.filter(a -> a instanceof StreamAdvisor)
.map(a -> (StreamAdvisor) a)
.toList();
// 如果有 StreamAdvisor,逐个 push 到 streamAdvisors 队列中
if (!CollectionUtils.isEmpty(streamAroundAdvisorList)) {
streamAroundAdvisorList.forEach(this.streamAdvisors::push);
}
这段与 CallAdvisor 的处理逻辑完全对称
排序
// 每次添加 Advisor 后重新排序,保证队首始终是优先级最高的 Advisor
this.reOrder();
}
return this;
}
调用 this.reOrder() 方法对 StreamAdvisor 和 CallAdvisor 进行排序,我们进入 this.reOrder() 中查看底层又是如何进行排序的
reOrder()
排序 CallAdvisor
private void reOrder() {
// 将 CallAdvisor 从双端队列转移到 ArrayList,便于排序
ArrayList<CallAdvisor> callAdvisors = new ArrayList<>(this.callAdvisors);
// 使用 Spring 的 OrderComparator 按 getOrder() 值升序排序
OrderComparator.sort(callAdvisors);
// 清空原双端队列
this.callAdvisors.clear();
// 按排序后的顺序重新放入队尾(addLast),保证 pop() 时队首是最小 Order 值
callAdvisors.forEach(this.callAdvisors::addLast);
排序 StreamAdvisor
// 对 StreamAdvisor 执行相同的排序逻辑,双端队列转移到 ArrayList,便于排序
ArrayList<StreamAdvisor> streamAdvisors = new ArrayList<>(this.streamAdvisors);
// 使用 Spring 的 OrderComparator 按 getOrder() 值升序排序
OrderComparator.sort(streamAdvisors);
// 清空原双端队列
this.streamAdvisors.clear();
// 按排序后的顺序重新放入队尾(addLast),保证 pop() 时队首是最小 Order 值
streamAdvisors.forEach(this.streamAdvisors::addLast);
}
为什么是"转移到 ArrayList → 排序 → 清空 → addLast 放回"这个四步流程,而不是直接在 Deque 里排?
ConcurrentLinkedDeque 不支持随机访问排序。Deque 的排序只能通过"倒出来→排好→放回去"实现。
而 ArrayList 的 sort() 基于数组的随机访问,时间复杂度 O(n log n),是最高效的排序实现。直接用 Deque 的手动排序只能做到 O(n²)。
addLast 配合 pop() 的正确配对:
-
Deque.pop()从队首移除并返回元素 -
addLast()把元素放到队尾
排序后(ArrayList): [Order=100, Order=200, Order=1000]
↑ ↑
最小值 最大值
forEach addLast 放入后(Deque):
队首 ← [Order=100, Order=200, Order=1000] ← 队尾
pop() 取出: Order=100 → Order=200 → Order=1000
为什么直接拿 streamAdvisors (ArrayList) 出来就可以排序了?他们排序是依照什么的?
streamAdvisors 之所以能直接被 OrderComparator.sort() 排序 ,是因为 OrderComparator 已经内置了获取排序值的能力,它不关心你传进来的是什么对象,只关心能不能从这个对象身上拿到一个表示优先级的 int 值。
那OrderComparator 怎么拿到你对象的排序优先级的值?
OrderComparator 可以通过 instanceof Ordered 调用 getOrder() 获取排序值。sort(List) 传的是 INSTANCE 实例,因此会走传参 Comparator 的 TimSort 路径。
这里会涉及一下其他的底层逻辑,我们概括一下就是:Advisor 的 Order 越小就排的越靠前,越大就靠后
我们可以来到 Spring AI 的官方描述:
来到 Advisor 顺序章节
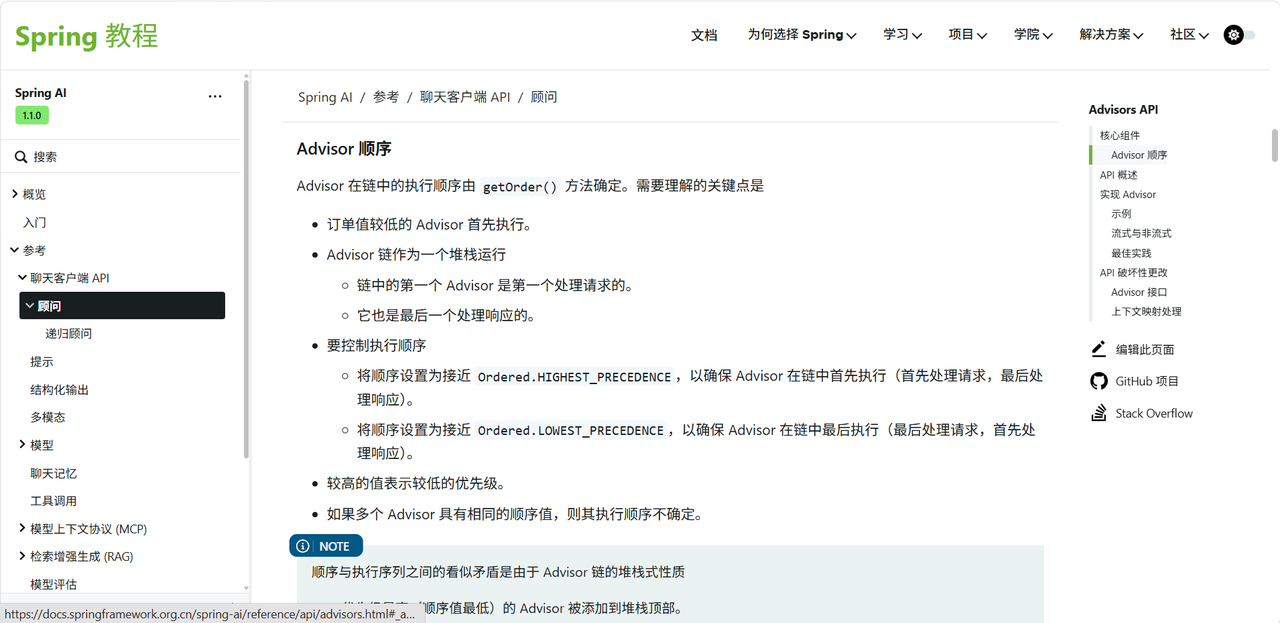
Advisor 在链中的执行顺序由
getOrder()方法确定。需要理解的关键点是
Order 值较低的 Advisor 首先执行。
Advisor 链作为一个堆栈运行
链中的第一个 Advisor 是第一个处理请求的。
它也是最后一个处理响应的。
要控制执行顺序
将顺序设置为接近
Ordered.HIGHEST_PRECEDENCE,以确保 Advisor 在链中首先执行(首先处理请求,最后处理响应)。将顺序设置为接近
Ordered.LOWEST_PRECEDENCE,以确保 Advisor 在链中最后执行(最后处理请求,首先处理响应)。较高的值表示较低的优先级。
如果多个 Advisor 具有相同的顺序值,则其执行顺序不确定。
这里我们来到源码,看看在 this.buildAdvisorChain() 构建责任链时压入的 ChatModelStreamAdvisor里面是什么样的构造
// 添加一个用于流式调用的聊天模型顾问到顾问列表末尾
// ChatModelStreamAdvisor 是调用链的终点之一,它直接调用 chatModel.stream()
this.advisors.add(
ChatModelStreamAdvisor.builder()
.chatModel(this.chatModel)
.build()
);
public final class ChatModelStreamAdvisor implements StreamAdvisor {
private final ChatModel chatModel;
// ... 省略
@Override
public String getName() {
return "stream";
}
@Override
public int getOrder() {
return Ordered.LOWEST_PRECEDENCE;
}
// ...省略
}
可以看到 ChatModelStreamAdvisor 有实现一个方法为 getOrder(),方法上还有重写注解,来到方法里,可以看到返回的值为:Ordered.LOWEST_PRECEDENCE ,
public interface Ordered {
/**
* 最高优先级的常量值。
* @see java.lang.Integer#MIN_VALUE
*/
int HIGHEST_PRECEDENCE = Integer.MIN_VALUE;
/**
* 最低优先级的常量值。
* @see java.lang.Integer#MAX_VALUE
*/
int LOWEST_PRECEDENCE = Integer.MAX_VALUE;
/**
* 获取此对象的排序值。
* <p>值越大表示优先级越低。因此,
* 值最小的对象具有最高的优先级(有点类似于
* Servlet 的 {@code load-on-startup} 值)。
* <p>相同的排序值会导致受影响的对象以
* 任意的排序位置出现。
* @return 排序值
* @see #HIGHEST_PRECEDENCE
* @see #LOWEST_PRECEDENCE
*/
int getOrder();
}
我们继续查看的话就可以知道他的取值就是 Integer.MAX_VALUE**,也就是说 ChatModelStreamAdvisor 他一定会在 Advisor 链的最后,作为真正调用模型的顾问**。
但是 ChatModelStreamAdvisor 又是从哪里重写的 getOrder() 方法?我们可以看到 ChatModelStreamAdvisor 只实现了 StreamAdvisor 接口
public final class ChatModelStreamAdvisor implements StreamAdvisor {
那真相就是一个了,可能是 StreamAdvisor 继承了 Ordered 接口又或是 StreamAdvisor 某个父类继承了Ordered,我们一层层查看
public interface StreamAdvisor extends Advisor {
public interface Advisor extends Ordered {
可以看到是 Advisor 继承了 Ordered,而 StreamAdvisor 又继承了 Advisor,StreamAdvisor 重写 getOrder() 方法后就可以直接进行排序了。
总结
再来一张图来给大家总结一下
在这最后的补充章节里,我们了解到了,在 DefaultAroundAdvisorChain 的 CallAdvisor 和 StreamAdvisor 是如何进行构建,并排序的,在下一章中我们将从 StreamAdvisor 开始,带大家进入到真正的模型调用中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)