AI进阶:什么是真正的 AI Agent?大多数人可能都理解错了
2026 年,AI Agent 是技术圈最热的词,没有之一。每场行业会议、每份融资公告、每家 SaaS 厂商的产品更新,三句话之内必提 Agent。G2 在 2025 年的一份报告显示,96% 的组织已经在以某种形式使用 AI Agent(emmm至少,他们以为自己在用)。
但一个尴尬的事实是:Gartner 在同年的分析中指出,成千上万家声称自己提供 Agentic AI 能力的厂商中,真正具备实质 Agentic 能力的只有大约 130 家。其余的都是什么?聊天机器人套了层壳,工作流引擎换了套皮肤,API 调用包装上"智能体"的标签。
Gartner 管这叫 “Agent Washing”,和当年的 “Greenwashing”(漂绿)如出一辙,把旧技术贴上新标签,趁风口卖溢价。
所以问题来了:你接触到的那个 AI Agent,到底是真正的 Agent,还是仅仅是一个会聊天的 API?
一、你以为的 Agent,大部分是假的
判断真假 Agent 的一个简单方法是:给它一个你从未详细定义过流程的开放式目标,看它能否自己拆解步骤、选择合适的工具、在执行过程出错时自己纠正。走不完三步的自己暴露了。
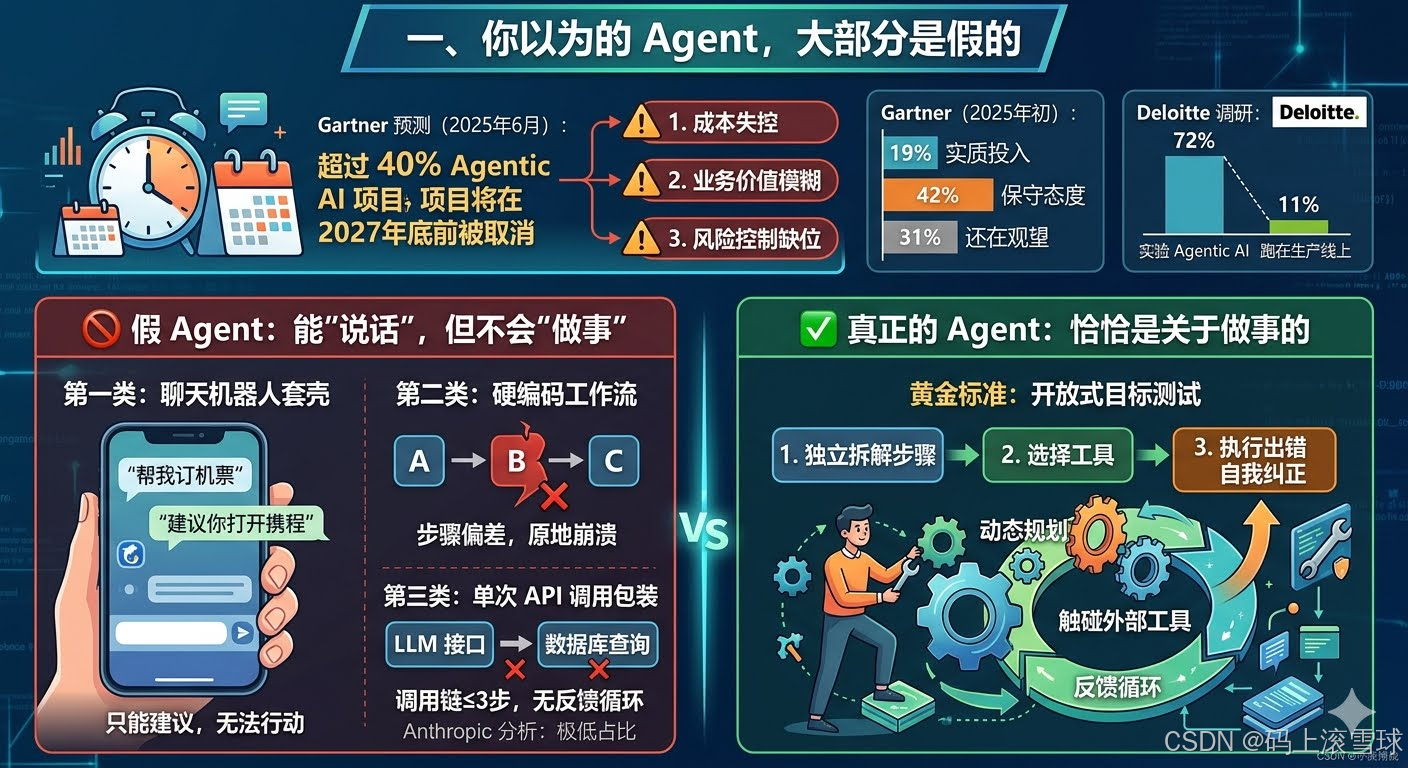
根据 Gartner 2025 年 6 月发布的预测,超过 40% 的 Agentic AI 项目将在 2027 年底前被取消,原因有三:成本失控、业务价值模糊、风险控制缺位。同一份报告显示,截至 2025 年初,只有 19% 的组织对 Agentic AI 做了实质性投入,42% 持保守态度,31% 还在观望。
Deloitte 的调研更直接:72% 的企业在实验 Agentic AI,但真正跑在生产线上的只有 11%。
为什么实验和生产之间存在如此巨大的鸿沟?一个重要原因是:很多团队在"实验"的根本就不是 Agent。
目前市面上最常见的三类"假 Agent":
第一类:聊天机器人套壳。 底层是一个 LLM,外面包了个对话界面,能回答问题,能生成文本,但没有调用任何外部工具的能力。你说"帮我订一张机票",它只能告诉你"建议你打开携程",因为它根本触碰不到真实世界。这是 Chatbot,不是 Agent。
第二类:硬编码工作流。 本质上是一个 if-else 流程引擎,每一条路径都是预先写死的。它能走通 A→B→C,但只要 B 步骤的输入稍有偏差,整个流程原地崩溃。真正 Agent 的核心特征之一是动态规划,根据中间结果实时调整下一步策略,而不是沿着预设轨道滑行。
第三类:单次 API 调用包装。 调用一次 GPT 接口,收到回复后做一次数据库查询,然后宣称自己是一个"智能 Agent"。Anthropic 在分析 998K 次工具调用后发现,真正意义上接近 Agent 的系统占比极低——绝大多数所谓的"Agent"调用链长度不超过三步,没有反馈循环,没有错误恢复机制。
这三类产品的共同问题:它们能"说话",但不会"做事"。 而真正的 Agent 恰恰是关于做事的。
二、真正的 AI Agent 长什么样?
一个衡量 Agent 架构成熟度的实用标准是看它的"最小人类干预可持续步数"——一个真正设计良好的 Agent,在人类设定目标后应该能自主完成至少 5-7 步不中断,每步包括观察→决策→执行→验证的完整循环。
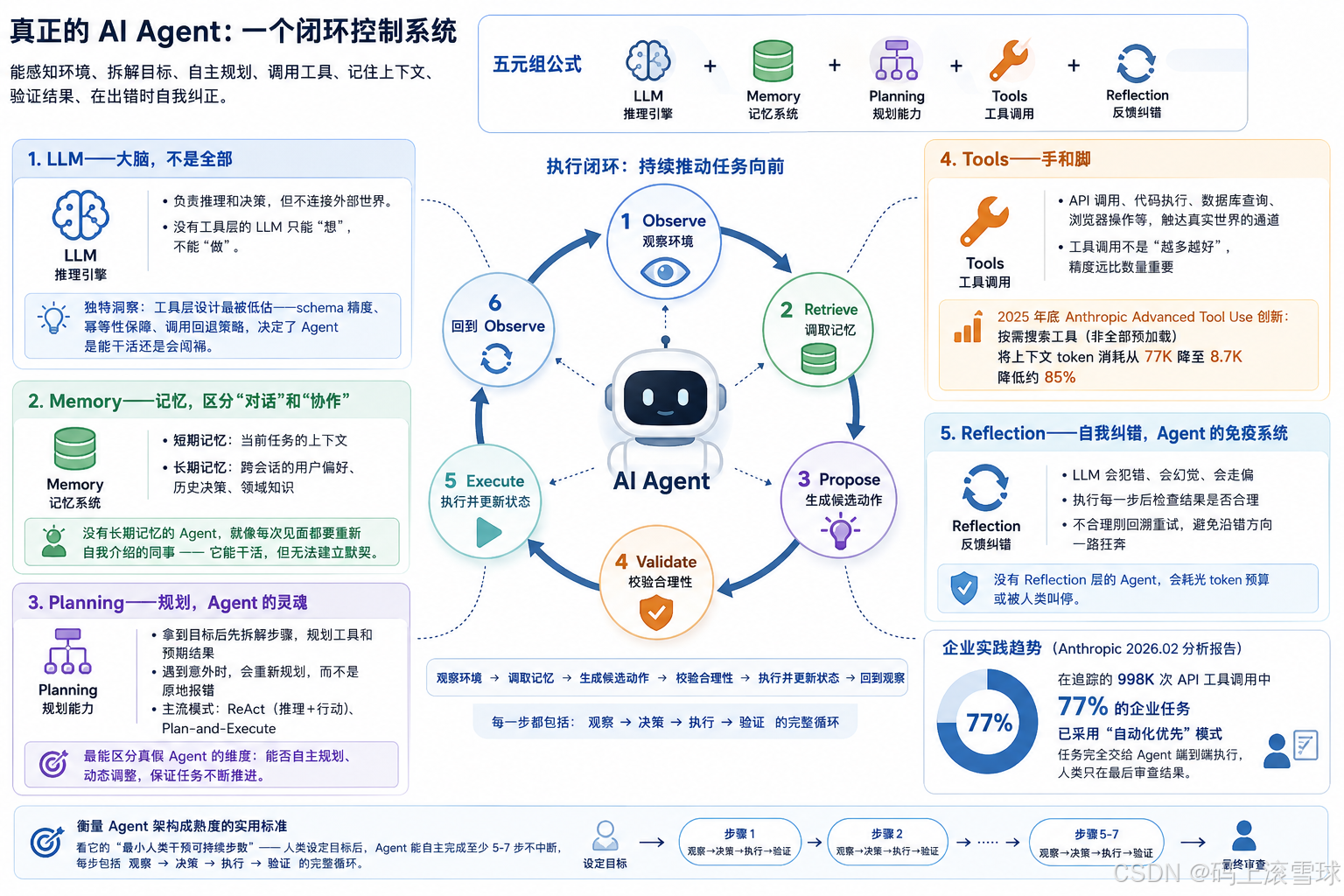
如果用一句话定义,真正的 AI Agent 是一个闭环控制系统:它能感知环境、拆解目标、自主规划、调用工具、记住上下文、验证结果、在出错时自我纠正。
学术界和工业界正在收敛到一个五元组公式:AI Agent = LLM(推理引擎)+ Memory(记忆系统)+ Planning(规划能力)+ Tools(工具调用)+ Reflection(反馈纠错),拆开来看:
1.LLM:大脑,不是全部。 很多人把 LLM 等同于 Agent,这就好比把发动机等同于整辆车。LLM 负责推理和决策,但它本身不连接外部世界。没有工具层的 LLM 只能"想",不能"做"。
2.Memory:记忆,区分"对话"和"协作"。 聊天机器人的记忆限于一个会话窗口,关掉就忘。真正的 Agent 需要两类记忆:短期记忆(当前任务的上下文)和长期记忆(跨会话的用户偏好、历史决策、领域知识)。没有长期记忆的 Agent 就像一个每次见面都要重新自我介绍的同事——它能干活,但永远无法和你建立默契。
3.Planning:规划,Agent 的灵魂。 这是最能区分真假 Agent 的维度。真正的 Agent 拿到一个目标后会先拆解:第一步做什么,第二步做什么,每一步用什么工具,预期的中间结果是什么。遇到意外时它会重新规划,而不是在第三步断了就原地报错。ReAct(Reasoning + Acting)和 Plan-and-Execute 是当前最主流的两种规划模式。
4.Tools:手和脚。 API 调用、代码执行、数据库查询、浏览器操作——这些是 Agent 触达真实世界的通道。但工具调用不是"越多越好"。Anthropic 在 2025 年底发布的 Advanced Tool Use 功能中引入了一个关键创新:按需搜索工具而非全部预加载,将上下文的 token 消耗从 77K 降到了 8.7K,降低了约 85%。这个数字本身说明了一个问题:工具的精度远比数量重要。
5.Reflection:自我纠错,Agent 的免疫系统。 LLM 会犯错,会幻觉,会走偏。没有 Reflection 层的 Agent 会沿着错误的方向一路狂奔,直到耗光 token 预算或者被人类叫停。好的 Agent 在执行每一步后会检查结果是否合理,如果不合理则回溯重试。
这五个组件构成一个执行闭环:Observe(观察环境)→ Retrieve(调取记忆)→ Propose(生成候选动作)→ Validate(校验合理性)→ Execute(执行并更新状态)→ 回到 Observe。 每一轮循环都在推动任务向前推进,而不是在原地打转。
Anthropic 在 2026 年 2 月发布的分析报告中指出,在他们追踪的 998K 次 API 工具调用中,77% 的企业任务已经是"自动化优先"模式——任务被完全交给 Agent 端到端执行,人类只在最后审查结果。
三、四个量级:Chatbot → Copilot → Agent → Autonomous System
很多人把 AI 系统理解为二元的:要么是聊天机器人,要么是 Agent。实际上,这更像一个从 L1 到 L4 的量级光谱。每一级的差异不在模型本身(底层可能都是同一个 LLM),而在架构设计。
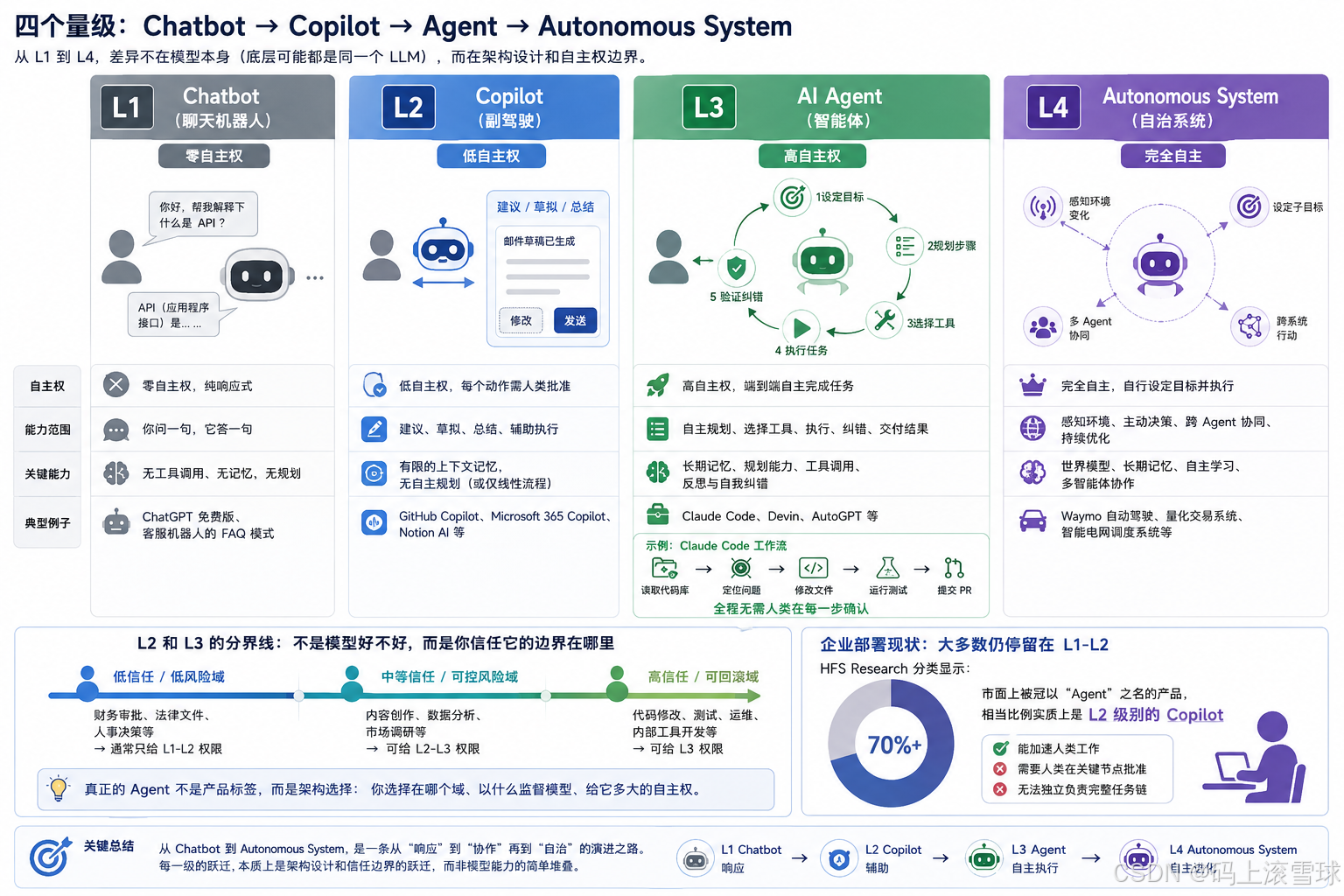
L1:Chatbot(聊天机器人)。 零自主权。纯响应式,你问一句它答一句。没有工具调用,没有记忆,没有规划。ChatGPT 免费版、客服机器人的 FAQ 模式都是典型 L1。
L2:Copilot(副驾驶)。 低自主权。能建议、能草拟、能总结,但每个动作都需要人类批准。GitHub Copilot 写完一行代码,Tab 键按不按在你。Microsoft 365 Copilot 写完了邮件草稿,发送键在你。
L3:AI Agent(智能体)。 高自主权。你设定目标,它自主规划步骤、选择工具、执行、纠错,最后交付结果。Claude Code 读取代码库 → 定位问题 → 修改文件 → 运行测试 → 提交 PR,全程不需要你在每一步点"确认"。Devin 接到一个 Issue → 理解需求 → 查阅文档 → 编码 → 自测 → 提交,人类在最终 Review 时介入。
L4:Autonomous System(自治系统)。 完全自主。不仅能执行任务,还能主动感知环境变化、自行设定子目标、跨多个 Agent 协调。Waymo 的自动驾驶、某些量化交易系统属于这个层级。
L2 和 L3 之间有一条很多人忽略的分界线:不是"模型好不好",而是"你信任它的边界在哪里"。同一个模型,在代码审查场景你愿意给 L3 权限(改错了 git revert 就行),在财务审批场景你可能连 L2 都觉得冒险。所以"真正的 Agent"不是一个产品标签,而是一个架构选择,你选择在哪个域、以什么监督模型、给它多大的自主权。
当前大多数企业的部署停留在 L1-L2。HFS Research 的分类显示,市面上被冠以 “Agent” 之名的产品,相当比例实质上是 L2 级别的 Copilot——它们能加速人类的工作,但远未达到可以独立负责一个完整任务链的程度。
四、为什么理解这个区别如此重要?
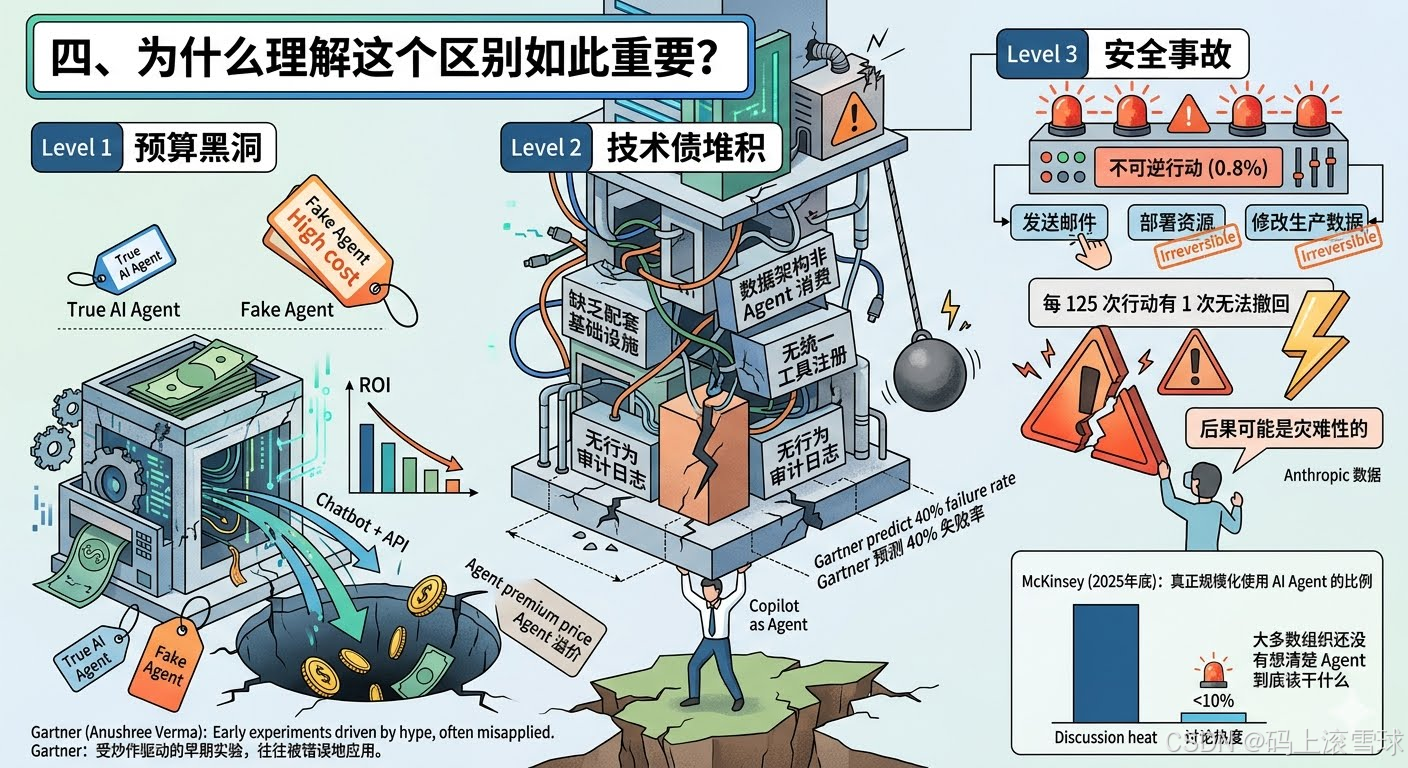
把 Copilot 当 Agent 用,不只是多花冤枉钱的问题,它会在三个层面上制造真实风险。
第一,预算黑洞。 厂商为 “Agent” 标签收溢价,你为此买单的却是一套本质上是聊天机器人 + API 的组合。Gartner 分析师 Anushree Verma 的原话是:"目前大多数 Agentic AI 项目是受炒作驱动的早期实验或概念验证,而且往往被错误地应用。"当一个概念验证被包装成生产级产品卖给你,ROI 从一开始就是负的。
第二,技术债堆积。 Gartner 预测 40% 项目失败的核心原因不是模型不行,而是组织从未建立配套的基础设施,数据架构是为 ETL 设计的,不是给 Agent 消费的;没有统一的工具注册中心;没有 Agent 行为的审计日志。在这种地基上盖楼,塌是迟早的事。
第三,安全事故。 Anthropic 的数据揭示了一个危险的细节:在他们的分析中,大约 0.8% 的 Agent 行动是不可逆的:发送了邮件、部署了资源、修改了生产数据。0.8% 听起来很小,但在自动化执行的规模下,这意味着每 125 次行动就有一次无法撤回。如果这个 Agent 恰好是一个"假 Agent"(没有 Reflection 层、没有 Validate 步骤、没有人类兜底),后果可能是灾难性的。
McKinsey 2025 年底的调研也印证了这一点:尽管 Agent 的讨论热度已经拉满,但任何给定企业职能中,真正在规模化使用 AI Agent 的比例不超过 10%。讨论和落地之间的差距之大,本身就说明了多数组织还没有想清楚 Agent 到底该干什么。
五、2026 年,真正落地的 Agent 长什么样?
剥掉炒作,一个规律在反复浮现:走得最远的团队,往往是那些心态上最不着急的团队。
2026 年已被业界称为 “Agentic Enterprise 元年”,但成功案例的共同模式不是"全面铺开"——恰恰相反,是窄域单场景起步 → 跑通生产 → 摸清能力边界 → 再谨慎扩展。
软件工程是目前最大、也是最成熟的落地场景,可以理解成 Coding 场景。在 Anthropic 分析的近 100 万次工具调用中,软件工程独占 47.8%,远超第二名的商业智能(8.3%)。Claude Code、Cursor、Devin 这类工具已经证明,在编码这个相对封闭、输出可验证的域内,Agent 模式是成立的。
但对于其他场景,2026 年的真实现状是:大多数"Agent"还处在从 L2 到 L3 的爬坡阶段。 不是说它们没用(很多 Copilot 级别产品已经创造了巨大价值),而是说,如果你听到某个厂商说自己做出了能横跨五个部门、自动协调数十个系统的 L4 级自治 Agent,保持怀疑是合理的。
怎么判断你面对的是不是一个真正的 Agent?三个实操标准:
- 给它一个开放式目标。 不要告诉它每一步该干什么。真正的 Agent 应该能自己拆解、自己规划。"帮我整理上个月的项目进展并生成周报"是 Agent 测试,"调用这个 API、取这个字段、填入这个模板"是自动化脚本。
- 观察它是否在意外面前会应变,而不仅仅是"报错退出"。 真 Agent 的特征是遇到障碍时换一条路试试,假 Agent 的特征是"第三步的返回值格式不对,程序终止"。
- 检查它有没有记忆。 关掉窗口,重新打开,换一个上下文再回来,它还记得之前你的偏好吗?不记得的,是 Chatbot。记得但不用的,是 Copilot。记得并根据记忆调整行为的,才配得上 Agent 这个名字。
写在最后
2026 年不会是"Agent 接管一切"的年份,Gartner 的 40% 失败预测也不是对技术的否定。它更像是市场在经历一轮必要的去伪存真:Agent Washing 会褪色,炒作会退潮,真正留下来的,是那些理解了 Agent 本质:不是"更聪明的模型",而是"模型 + 记忆 + 规划 + 工具 + 纠错"五位一体的系统工程,并愿意为此打好地基的团队。
下一次当有人向你推销一个"AI Agent"时,别问它能回答什么问题,问它:“你能替我做什么?做错了怎么办?做完了还记得我吗?”
这三个问题的答案,就是真假 Agent 的分界线。
常见问题(FAQ)
Q1: 我家公司用的那个客服系统能自动回复、也能查订单状态,它是 Agent 吗?
大概率不是。如果它的回复路径是预定义的(用户问 X → 查订单 API → 返回 Y),这是一条自动化工作流。Agent 的关键区别在于:当用户问了一个不在预设剧本里的问题时,它是直接卡住,还是能自己想办法绕过去。
Q2: GitHub Copilot 算是 Agent 吗?
截至 2026 年,Copilot 更准确的定位是 L2 级 Copilot,它需要你在每一步选择接受或拒绝。它不具备自主规划多步骤任务、调用多种工具、在执行中自我纠错的能力。相比之下,Claude Code 和 Devin 更接近 L3 Agent,你给目标,它自主完成中间过程。
Q3: 我的团队想引入 Agent,第一步应该做什么?
挑一个窄域、输出可验证的单场景。软件工程是最好的实验田之一(代码对不对跑一下测试就知道了)。先从 L2 Copilot 模式开始,摸清楚模型在你场景中的能力边界,再逐步向 L3 过渡。记住 Gartner 的教训:全面铺开的 Agent 项目 40% 以上会失败,而从一个具体场景稳步扩展的团队,成功率要高得多。
Q4: “Multi-Agent” 架构比单 Agent 更强大吗?
不一定。多 Agent 系统会复合错误率,单个 Agent 精度 95%,链上五个后掉到约 77%(Gartner 分析)。多 Agent 架构的价值在于任务分工(比如一个 Agent 负责研究、一个负责写作、一个负责审查),但每增加一个 Agent,就需要配套更完善的编排和校验机制。2026 年的行业共识是:能用单 Agent 解决的问题,先不要上多 Agent。
数据来源
- Gartner, “Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027,” 2025-06-25, https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- G2, “Enterprise AI Agents Report: Industry Outlook for 2026,” 2025, https://learn.g2.com/enterprise-ai-agents-report
- Deloitte, “State of AI 2026,”
- Anthropic, “Measuring AI Agent Autonomy in Practice,” 2026-02, https://www.saastr.com/ai-agents-in-sales-and-finance-arent-behind-theyre-just-next-the-latest-data-from-anthropic-and-1000000-tool-calls/
- McKinsey, “AI Survey,” late 2025
- HFS Research, “Agentic AI Maturity Model,” 2025
- Zapier, “State of Agentic AI Adoption Survey,” 2025-10, https://zapier.com/blog/ai-agents-survey/
- Forbes, “AI Agents And Hype: 40% Of AI Agent Projects Will Be Canceled By 2027,” 2025-06-28, https://www.forbes.com/sites/solrashidi/2025/06/28/ai-agents-and-hype-40-of-ai-agent-projects-will-be-canceled-by-2027/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)