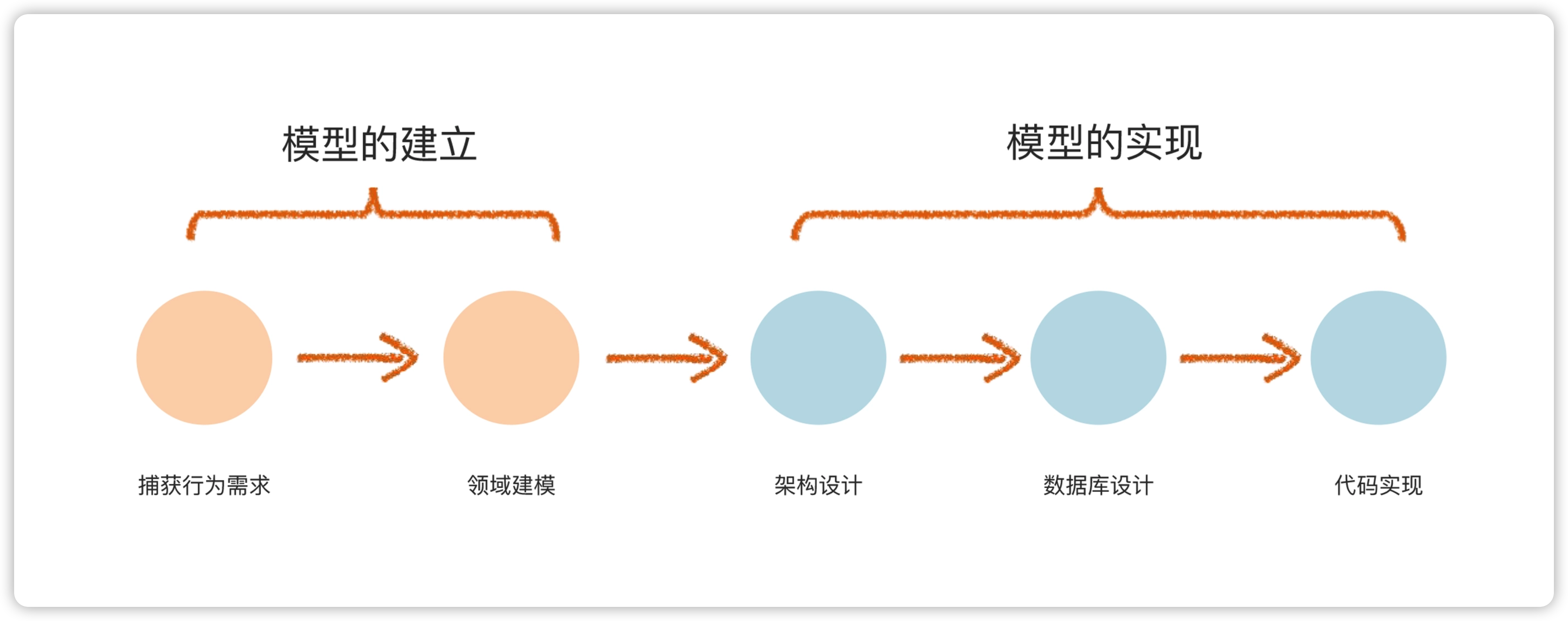
【领域驱动设计 打通DDD的最小闭环】三 模型的实现-设计和编码
前面两节,我们学习了模型的设计,通过事件风暴了解真实的业务行为,得到领域名词;之后通过领域建模,得到了领域模型。本节,我们要学习模型的实现,主要包括:
- 数据库设计:基于领域模型完成数据库表的设计,保证数据库设计与领域模型的一致性。
- 架构设计:引入 DDD 的分层架构,建立代码的骨架。
- 编码实现:基于代码骨架,进行更详细的代码编写。
数据库设计
首先,就是基于领域模型进行数据库设计,这个过程我们要着重体会数据库设计是如何与领域模型保持一致的。
数据库设计具体设计什么?
既然要进行数据库设计,要产出的东西都是什么呢?主要包括以下几点:
- 建立哪些表;
- 表中有哪些字段;
- 字段的数据类型以及约束是什么;
- 表的主键和外键是什么;
本质上就是创建一个数据库表需要的所有信息。
如何进行数据库设计?
在进行数据库设计之前,先说下如何描述数据库设计的产物。其实,并没有统一的国际标准。
- 使用建表语句(create table) 表示表的结构
- 使用一些绘图工具中提供的符号
这些都是可以的,为了直观,我们还是使用图示的方法。
那么,如何基于领域模型进行数据库设计呢?有这么几个步骤:
- 一般来说,一个实体可以映射为一个数据库表。
- 领域模型中的属性,一般会映射成表中的字段,在此基础上再为这个表添加其他字段。
- 最后为表添加主键和外键。
不过,为了减少数据库处理的瓶颈,一般不主张建立真正的外键,而是用程序来保证外键约束。但是在物理数据模型里,我们又希望表达外键参照,方便理解数据表间的关系。这时候,我们可以把实线箭头换成虚线箭头,表示虚拟外键。
基于以上步骤,可以分别得到组织管理、项目管理、工时管理三个模块的数据库设计图。
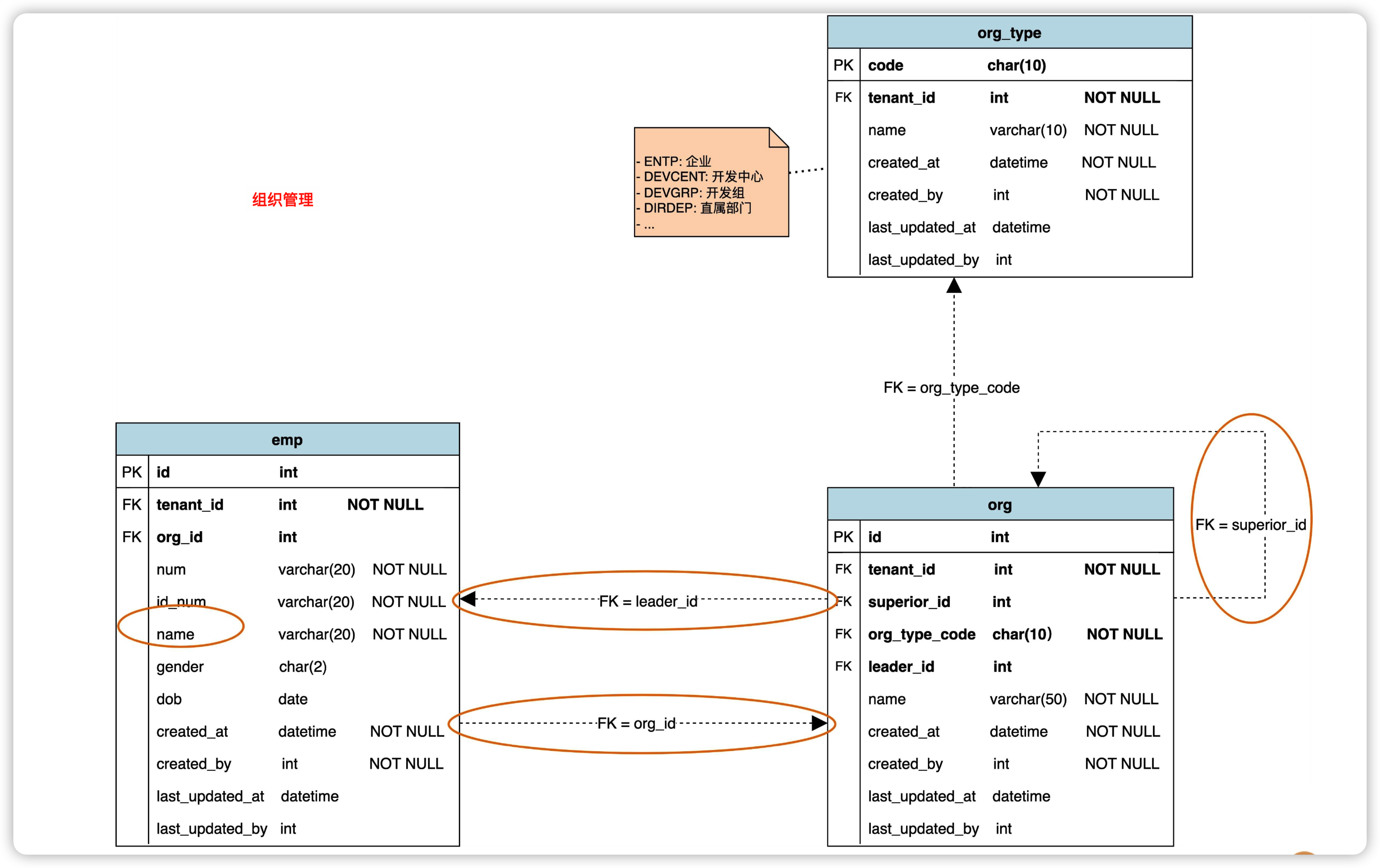
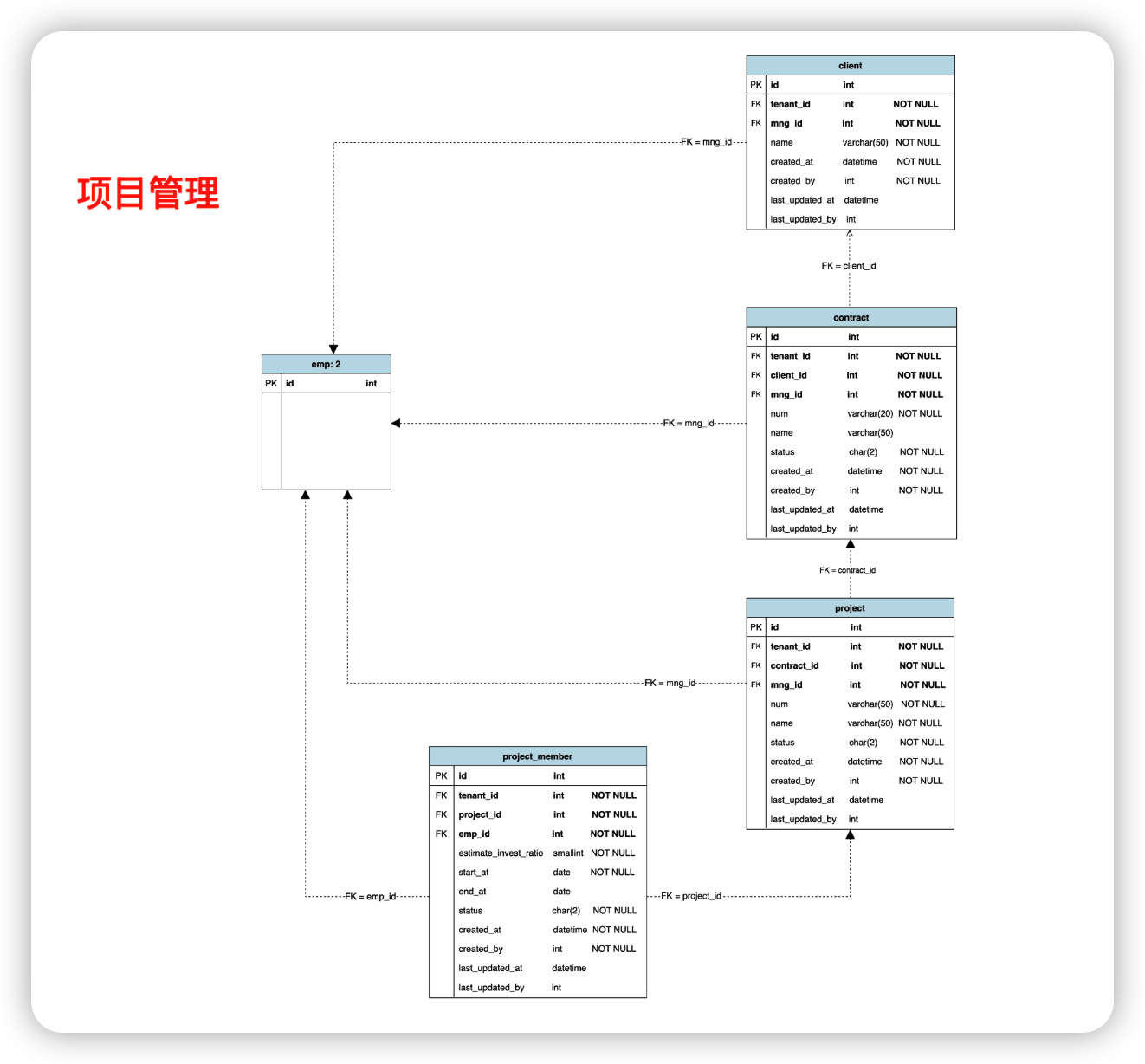
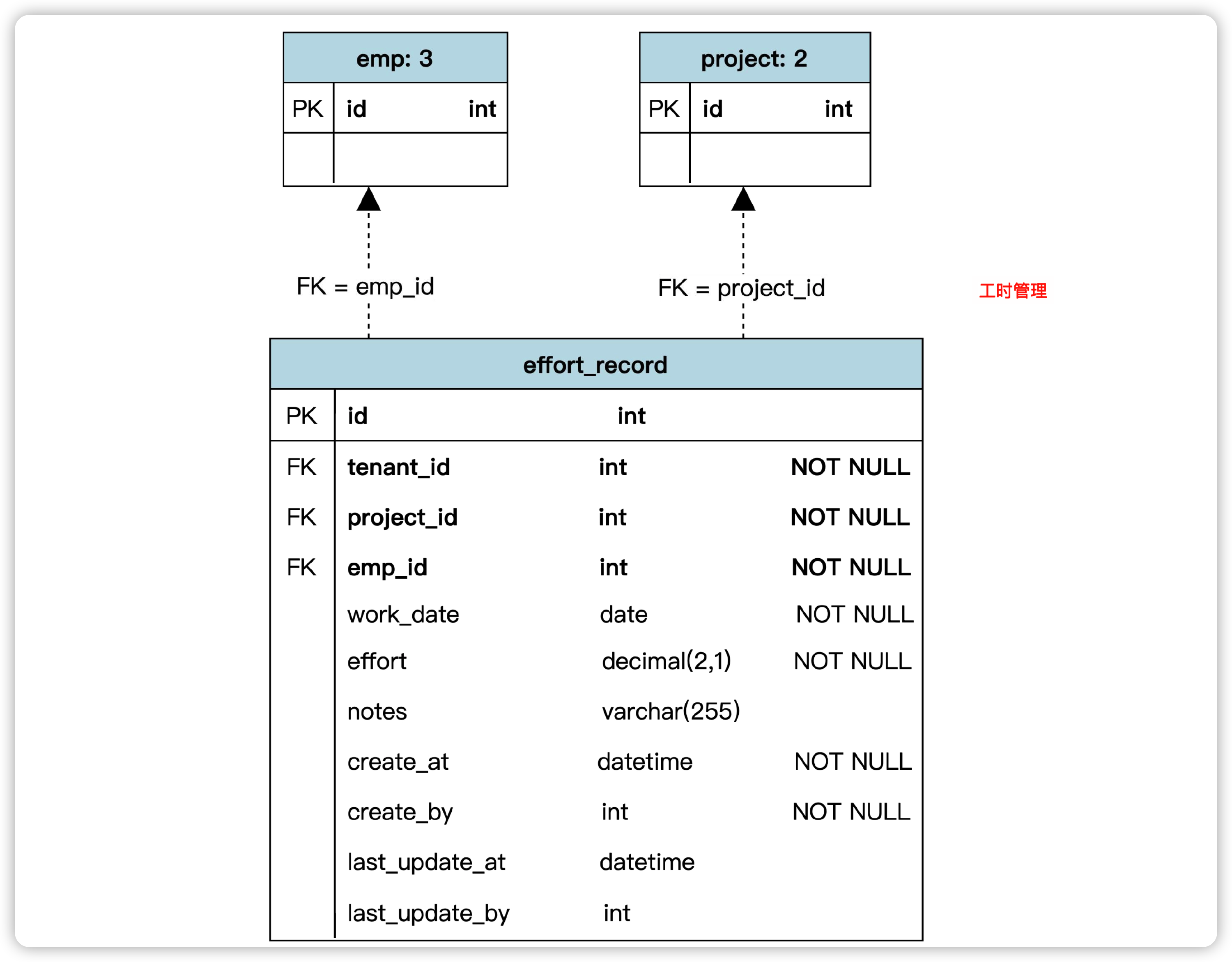
数据库设计思考题
Q1:在实际项目的数据表设计中,其实都用了没有业务含义的 id 作为主键,这种做法比起使用有业务含义的字段做主键有什么优点?
首先明确两种主键:
- 代理主键:如
BIGINT自增、雪花 id,本身没有业务含义。 - 业务主键:如
订单号、(模板编码, 版本号),来自业务规则。
使用代理主键的优点:
- 稳定。当业务主键变更时,因为代理主键不变,所以关联关系不变。
- 外键简单,查询更快,维护成本更低。
BIGINT型主键,比多列 VARCHAR 联合外键更短、索引更小、JOIN 更快。 - 自增主键,对于并发插入效率更高。
实际项目中,更常见的做法是,代理主键负责关联和生命周期,唯一索引负责业务约束。
Q2:数据库设计中三范式的存在是为了避免冗余字段存在。但有时为了性能的原因,常常会有意引入冗余字段,进行“反规范化”设计。在反规范化设计中,你觉得应该注意什么呢?
- 一致性问题。如何保证冗余字段和字段来源的一致性。
- 性能问题。字段的冗余不能降低查询性能。
数据推演
对于新项目或者数据库设计很复杂的项目来说,为了避免数据库设计无法适配客观真实世界,可以通过数据推演,最小成本验证其在业务上的适配度。
具体的做法就是:
- 列出所有的数据库表
- 验证每个业务指令(除查询外)最终落库的样子是否符合预期
- 验证各种查询场景是否能高效查询
其中,前两点是必须要满足的,但是查询不是强制性的,因为有些复杂查询就是要通过多表关联检索到,这种我们可以考虑支持复杂检索的数据库,如 MongoDB、ElasticSearch,或者在现有表基础上产出一个大宽表。当然这种表的设计就不是领域模型的部分了,而是基于业务场景的应用延伸出的一些表,后面的内容中会介绍到。
架构设计
有了数据库表,就要开始编码实现了。这个阶段分为两层:第一个层面是要有一个合理的代码架构,第二个层面是更详细的代码编写。
这一小节就是通过引入 DDD 的分层架构,建立代码的骨架。
不采用分层架构的问题
为什么要采用分层架构呢?原来有什么问题呢?
我们知道,系统中的代码都有各自的目的,有些处理领域逻辑,有些处理用户界面,有些处理数据库的访问……这些代码的关注点各不相同。但在很多开发团队中,并没有明确的手段来分离代码的关注点,从而使不同关注点的代码混在一起。
我们设想这样一个场景,每个对外的能力或功能都是一个文件,从接受外部请求到访问第三方,都在这个文件中完成(面条型代码)。它会造成下面几个问题:
-
业务逻辑和领域逻辑混合在一起,相互交织,无法区分。会导致新加入的成员只能从代码中片段的看到领域的能力,而不是整体看到领域能力。也会导致一旦领域模型改动,改动的代码分散在各个地方,无法区分哪些是领域逻辑、哪些是业务逻辑,极端的说每次改动都会影响全部业务功能,使得改动成本极高,测试成本更高。 领域逻辑不内聚
-
技术代码和非技术代码混合在一起。假设原来是通过 http 对外提供服务,现在要改成 dubbo 服务,同样需要在一堆代码中找出 http 相关代码,非技术代码要重新拷贝一份,在此基础上加上 dubbo 服务的相关代码。即使是拷贝非技术代码没有改动,仍然需要测试所有业务功能。 技术和非技术代码不分离
分层架构的思想
因为上面的问题,就出现了分层架构,它有两种等价的画法,一种由内而外,另一种自下而上。
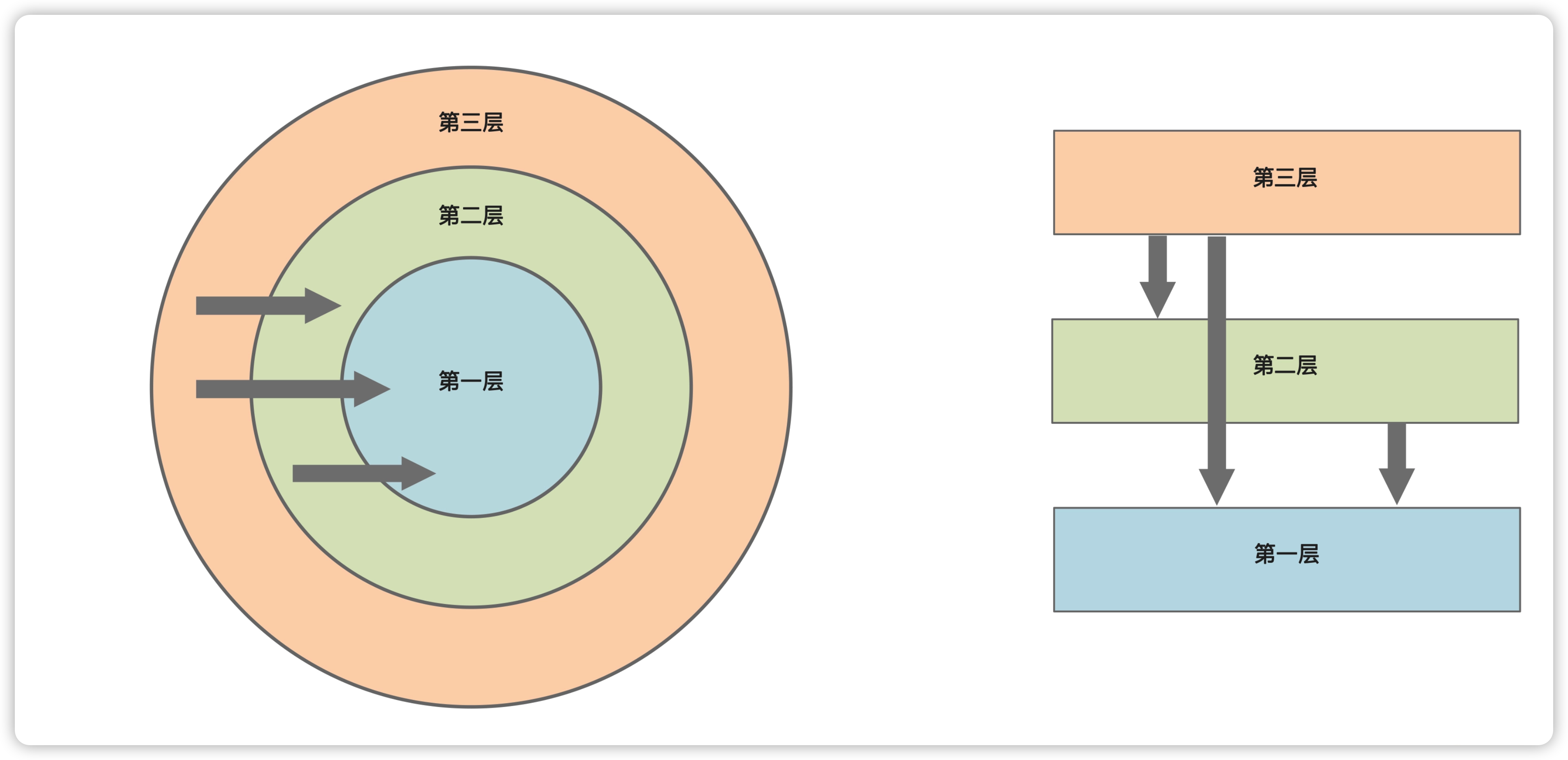
在这样的架构下,它是这么解决上述问题的:
- 分离关注点。分层架构将项目分成多层,每层职责单一。层间依赖关系为外层依赖内层,内层不能依赖外层。这反映了软件架构中的一个重要原则:代码中不稳定的部分,应该依赖稳定的部分。所以,分层架构中越是内层,就越稳定,越是外层,相对就越容易变化。另外,分层也体现了高内聚低耦合的思想,每一层都有各自的职责。层间通过有限的接口完成依赖调用,只要接口不变,接口实现的改动不影响上层调用。
- 领域居中。系统存在的理由是解决业务问题,所以最稳定、最有价值的应该是领域模型及其行为,它们应该放在架构中心。而技术(Spring、JOOQ、HTTP)是可替换的外围,不是设计的起点。其次,将领域层独立出来,才能保证与领域模型的一致性,也才能让领域层独立演化。
按照上述分层架构的思想,就产生了一些具体的DDD架构。
- DDD落地架构:DDD落地时具体的分层架构,包括四层架构、六边形架构、洋葱架构、整洁架构。这四种都是基于同一套思想的不同架构,强调领域居中,外层依赖内层,只是不同的架构侧重点不同。其中,四层架构强调职责分离;六边形架构强调技术可替换,采用端口和适配器;洋葱架构强调依赖严格向内;整洁架构强调可测试性。
- 增强变体:有了基本分层之后,针对特定痛点做的DDD增强变体。其中CQRS 解决的是性能问题,强调读写模型拆分;事件驱动解决的上下文耦合问题,强调领域事件解耦上下文。
- 部署形态。这里讲的是系统怎么部署,有两种:模块化单体、微服务。其中,模块化单体,指的是将项目按限界上下文拆模块,使得边界清晰、运维简单,但仍在一个项目内;微服务,指的是一个或多个限界上下文独立部署、独立扩缩容,分布式复杂度更高,在多个项目内。
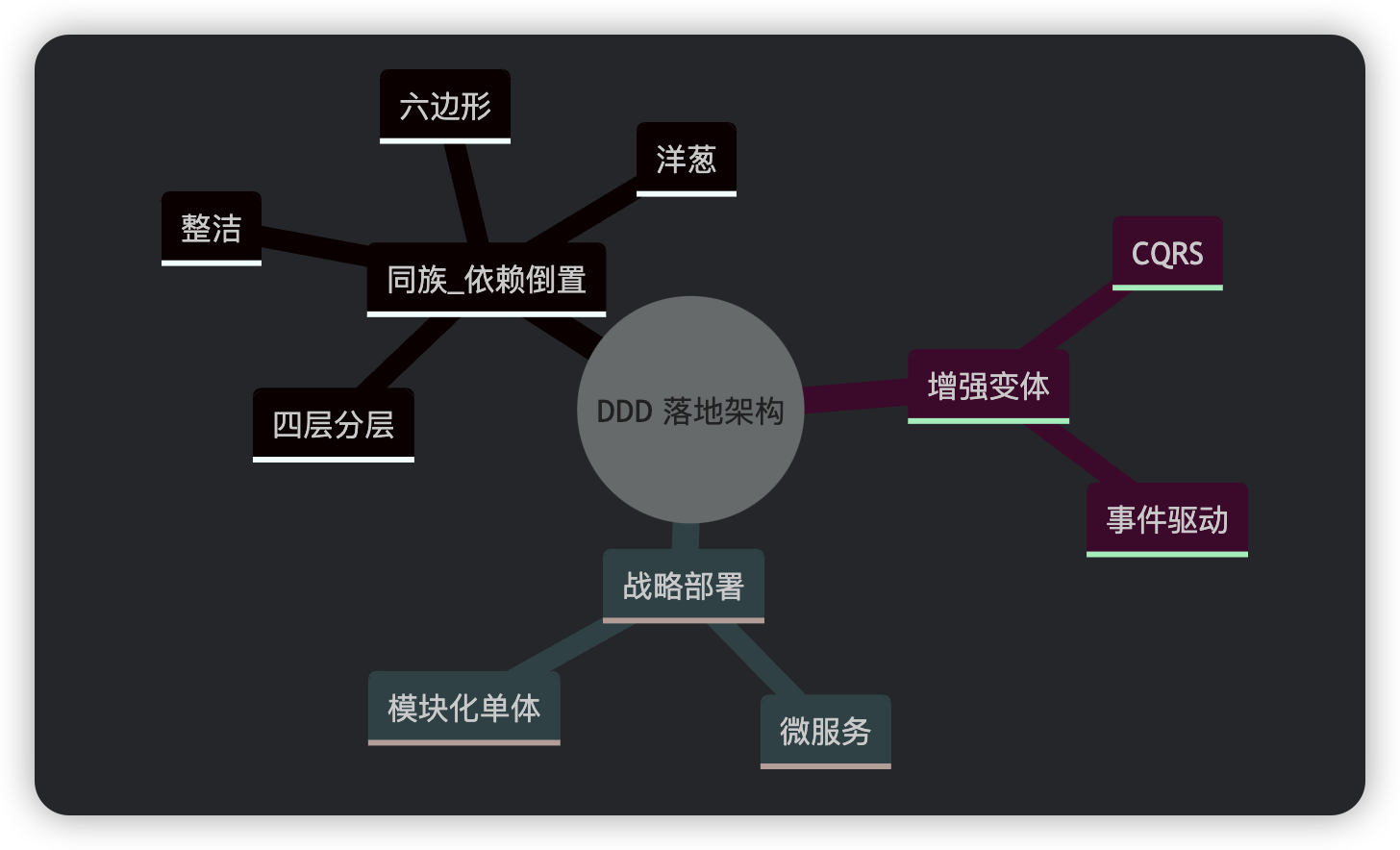
下面我们就详细介绍下四层架构、六边形架构、洋葱架构、整洁架构这四种分层架构,增强变体和部署形态在后面的章节中会介绍到。
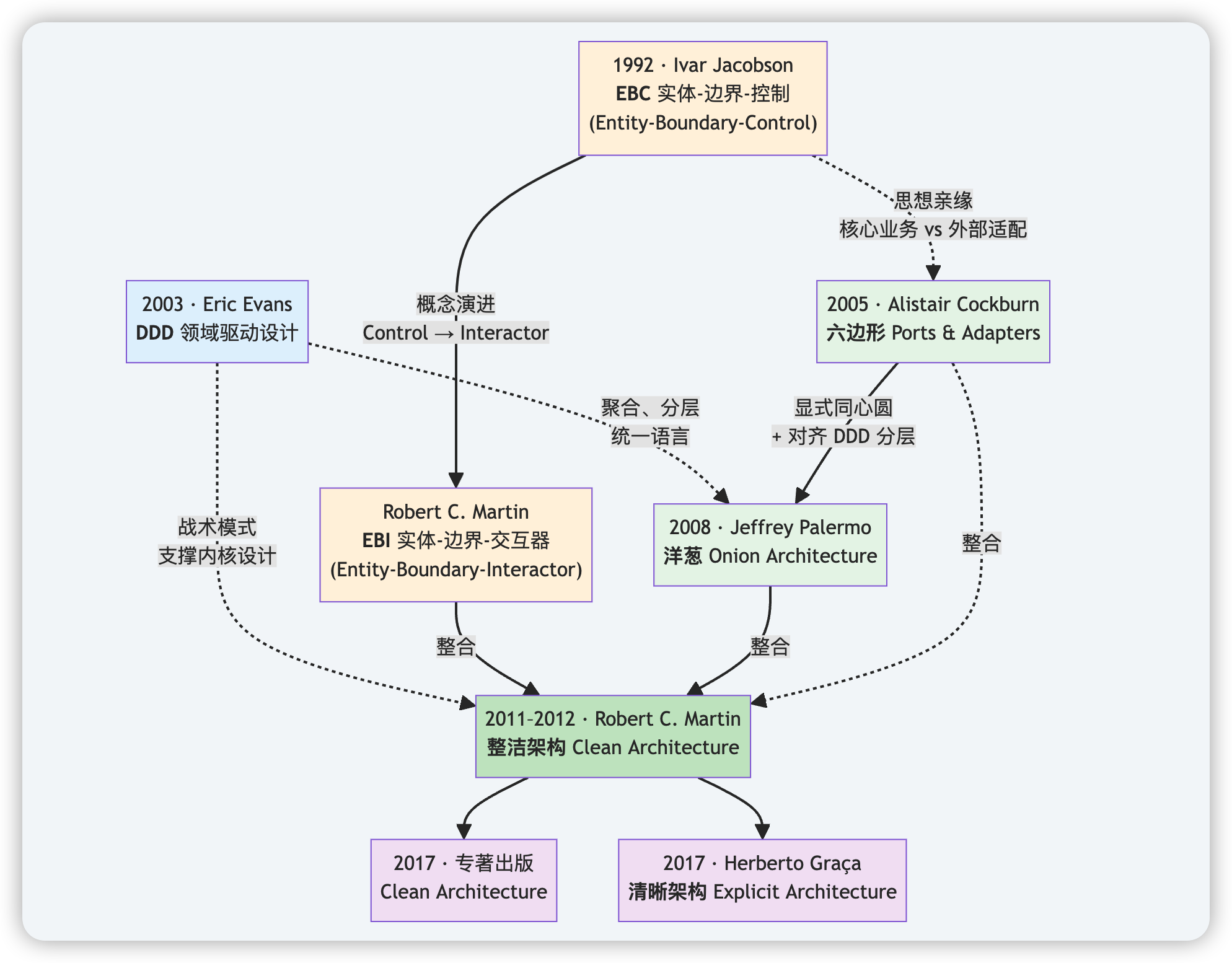
下图是六边形架构、洋葱架构、整洁架构的演进历程。
四层架构
四层架构是 Eric Evans 在 2003 年出版的《领域驱动设计:软件核心复杂性应对之道》一书中推荐的落地架构,它最好理解,是最常见的落地方式。
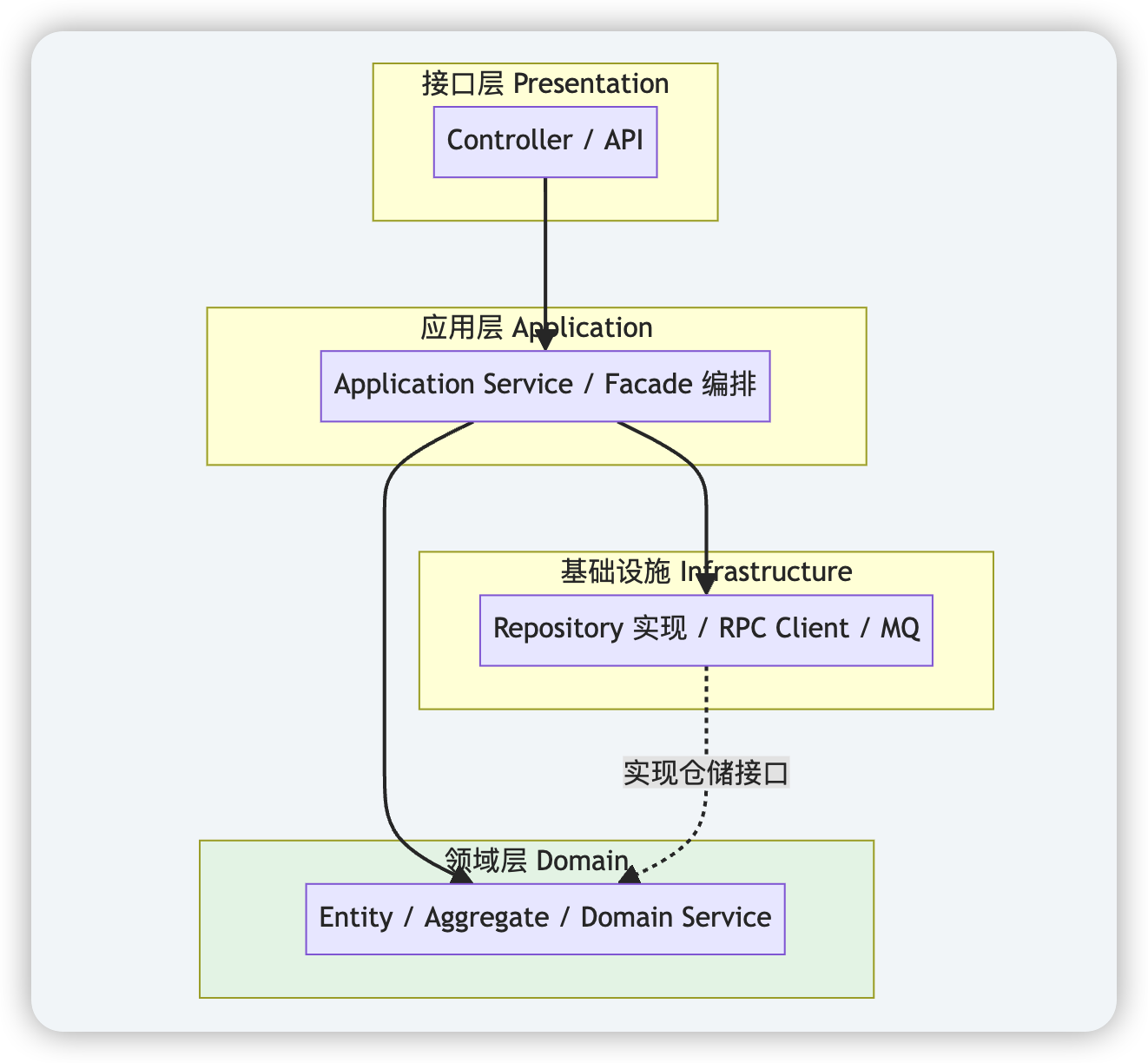
它强调职责分离。四层从上到下包括:
- 接口层/表现层。负责把外部请求翻译成应用层能理解的命令。
- 应用层。接受接口层的请求,调用领域层、基础设施层能力完成业务逻辑的编排。应用逻辑
- 领域层。负责领域模型定义、领域行为的约束,是领域模型的直接体现。领域逻辑
- 基础设施层。负责具体技术的实现,比如数据库访问、RPC调用、消息队列等。
要注意一点,基础设施层和领域层之间是依赖倒置关系。领域层需要访问数据库,按理说应该是领域层依赖基础设施层,但因为领域层最稳定,要在最底层。为了实现领域居中,采用了依赖倒置,也就是:
- 领域层定义数据库访问接口
- 基础设施层实现数据库访问接口
依赖倒置是面向对象设计中常见的调整依赖关系的手段。
六边形架构
六边形架构是由敏捷软件开发专家 Cockburn 在 2005 年提出的,强调分离技术和非技术关注点。一切能力通过端口声明,适配器提供具体实现。具体分层由里向外包括为:
- 领域层。负责领域模型定义、领域行为的约束,是领域模型的直接体现。领域逻辑
- 应用层。接受的请求,调用领域层完成业务逻辑的编排。应用逻辑
- 端口-适配器。外界要请求系统的业务功能,可以通过不同技术来实现,比如 Restful API、 RPC,以及传统的 Web 页面等。同样系统要请求第三方,比如数据库,也可以通过不同的技术实现,比如 Jooq、MyBatis等。不论具体技术是什么,依赖的业务功能很可能都是一样的。所以,输入输出技术和业务功能是两个不同的关注点。为了分离这两个关注点,我们在应用层外面再加一层,专门处理输入输出技术,就是端口-适配器层。其中端口用来声明能力,与具体技术无关;适配器提供不同技术的具体实现。根据数据流向的不同,将适配器分为主动适配器、被动适配器两种。
- 主动适配器(driving adapter)。从外界向系统的调用。适配器会把和具体技术有关的请求,翻译成和技术无关的请求,再调用应用层的接口(端口层)来实现业务功能;在接收到应用层的返回值以后,又转化成技术相关的响应,返回给外界。
- 被动适配器(driven adapter)。由系统向外界的调用,比如对缓存、文件系统、对象存储服务、数据库的访问等。以数据库为例来说,可以在领域层定义数据库的接口,通过被动适配器实现具体的数据库接口逻辑。
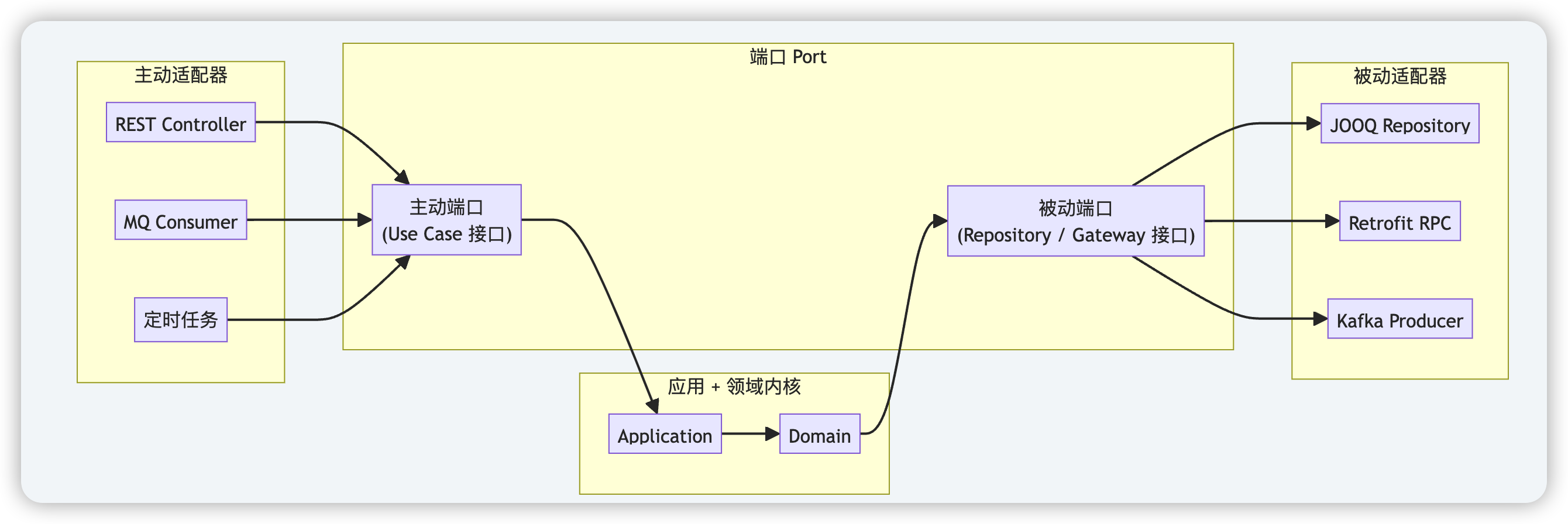
为了便于理解,我画了上图。
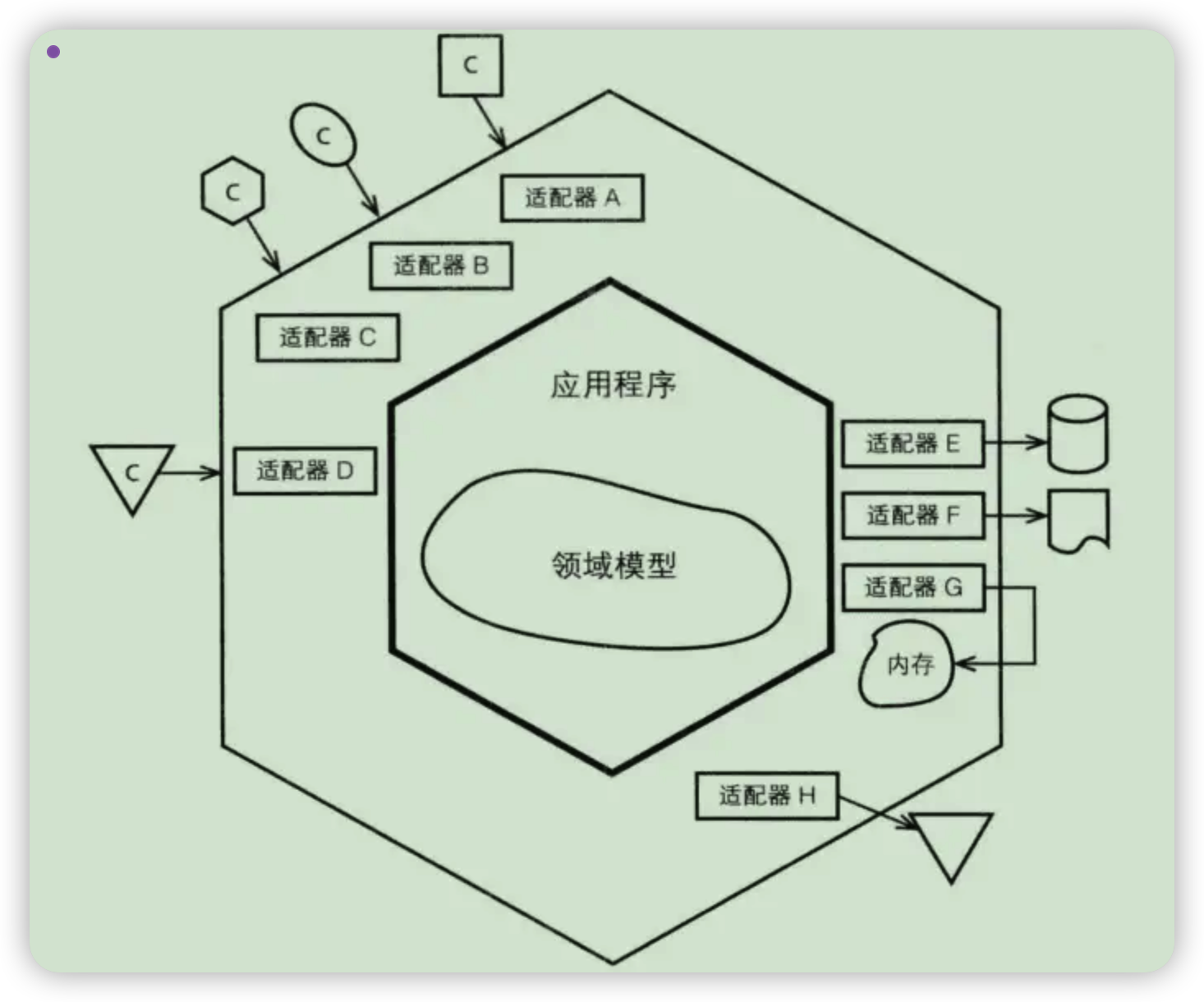
但敏捷软件开发专家 Cockburn 提出六边形架构时,采用的是下图。按照下图理解六边形架构是这样的,它将应用分为内六边形和外六边形两层,内六边形实现应用的核心业务逻辑,也就是上面的领域层和应用层。外六边形为适配器层,完成外部应用,基础资源等的交互和访问。对于与不同的外部系统交互,由外六边形的适配器负责协议转换,保证内六边形业务逻辑的干净。
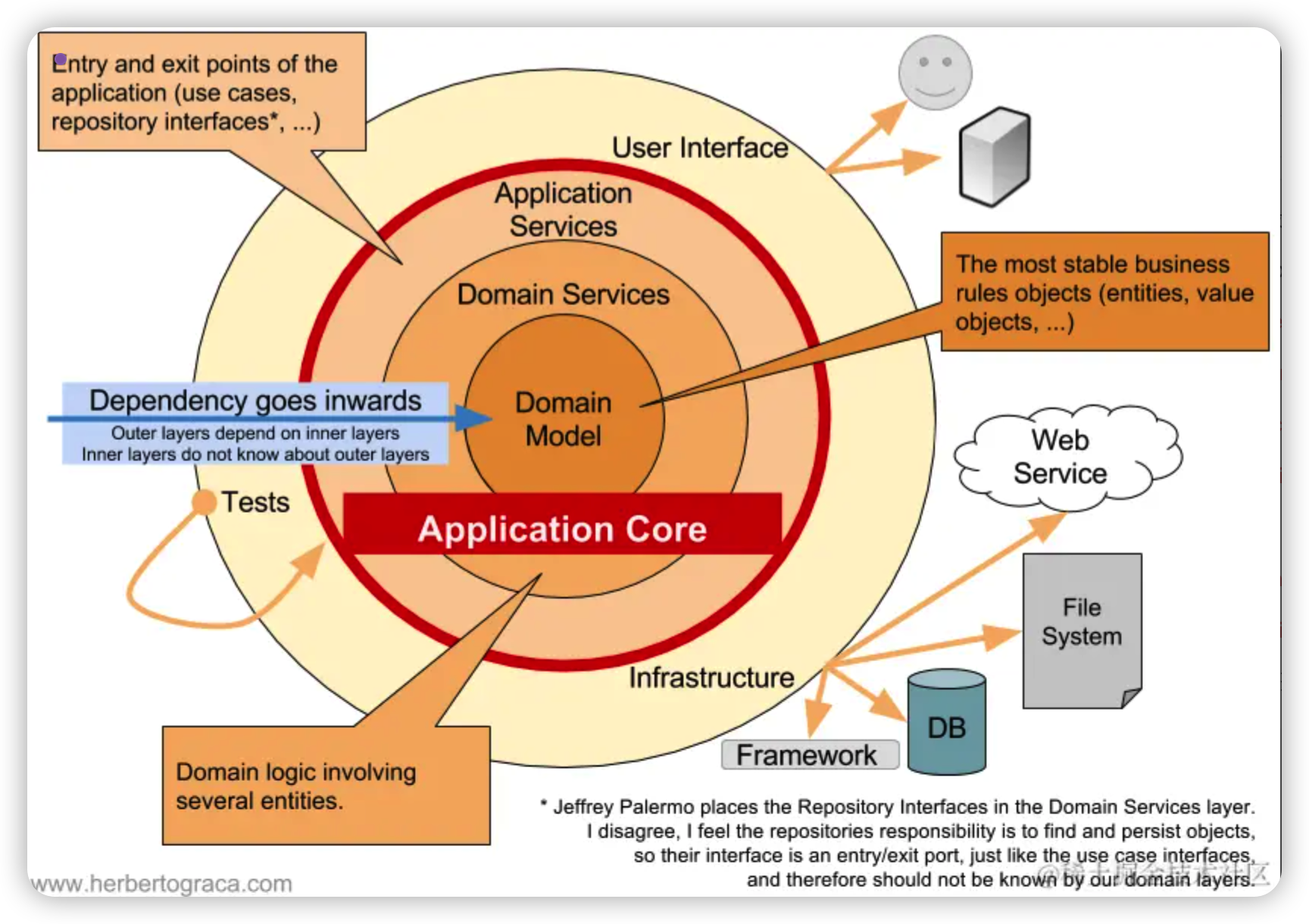
洋葱架构
洋葱架构(Onion Architecture) 是由Jeffrey Palermo 在2008年提出,强调依赖严格向内。它在六边形架构的基础之上,将业务逻辑层进一步划分,最终为:
- 适配器层(Adapters),对应六边形架构中的适配器层。
- 应用核心层(Application Core),对应六边形架构中的业务逻辑层。又具体分层:
- Application Services - 应用服务册层
- Domain Services - 领域服务层。领域模型的行为。
- Domain Model - 领域模型层。领域模型本身。
其中领域服务层和领域模型层对应六边形架构中的领域层。
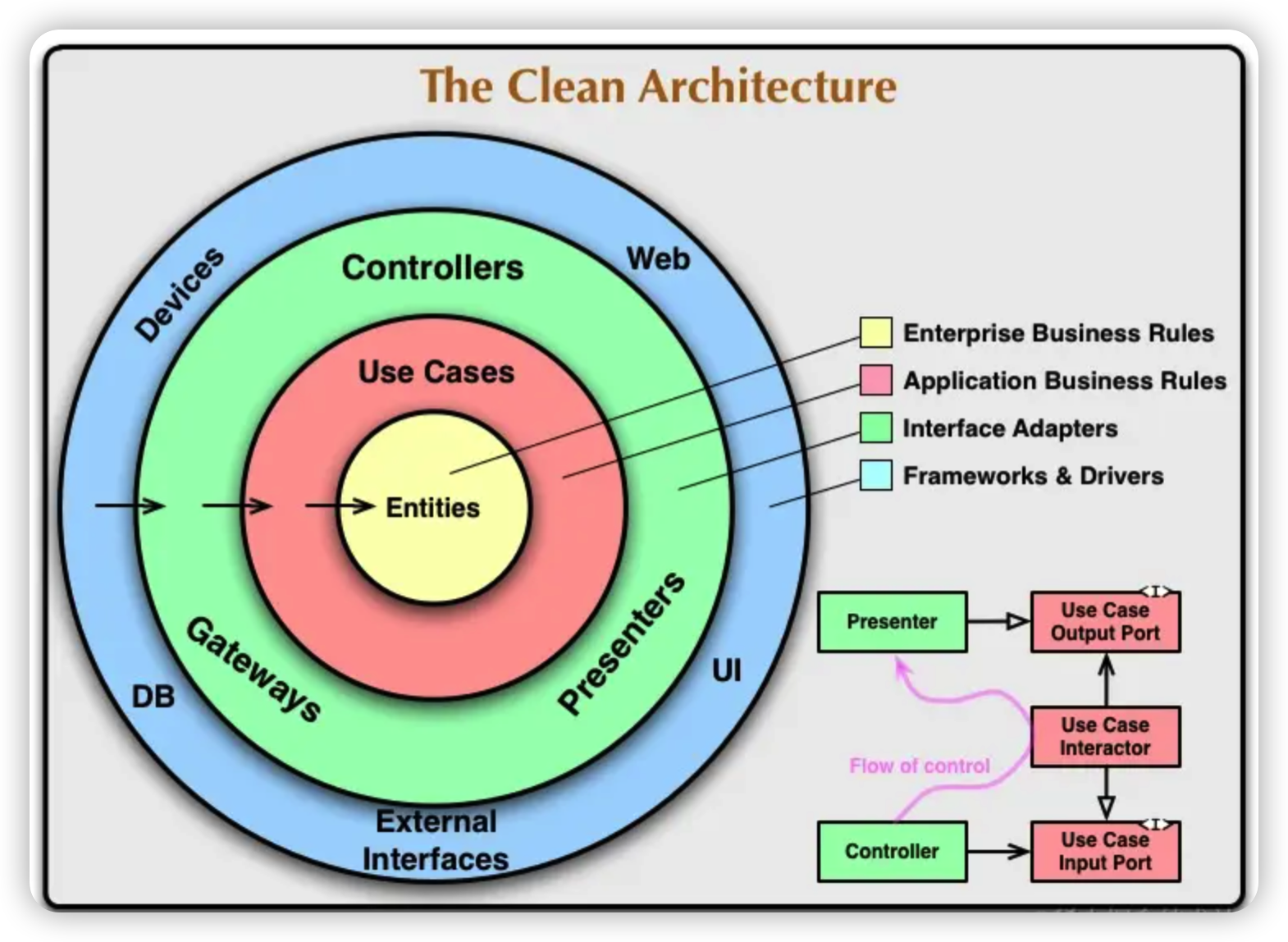
整洁架构
整洁架构(Clean Architecture)是由 Robert C. Martin (又名Uncle Bob) 在 2012年提出,它在EBI、六边形架构、洋葱架构的基础上形成。
与洋葱架构相比,整洁架构调整如下:
- Application Services调整为Use Cases
- Domain Services, Domain Model 调整为 Entities
整洁架构并没有带来突破性的概念或模式,但是:
- 它发掘了某种程度上被遗忘了的概念、规则和模式;
- 它澄清了一些实用且重要的概念、规则和模式;
- 它告诉我们如何把所有的概念、规则和模式整合起来,形成一种构建复杂应用并保持可维护性的标准套路
代码实现
确定了分层架构,就要在此基础上进行代码实现了。虽然上述架构各有不同,但都提到了领域层和应用层。其中对于领域层代码的实现,经常遇到的一个问题就是:应该采用贫血模型还是充血模型?另外,上文提到,领域层对应着领域逻辑,应用层对应着应用逻辑,那领域逻辑和应用逻辑的区别是什么?边界又是什么呢?下面我们就介绍这几个问题。
贫血模型 OR 充血模型
贫血模型(Anemic Domain Model),是 Martin Fowler 在 2003 年提出的,恰好在《领域驱动设计:软件核心复杂性应对之道》这本书写作的同一年。贫血模型指的是领域对象中只有数据,没有行为,由于过于单薄,就好像人贫血了一样,显得不太健康。这种风格违背了面向对象的原则。所以,Martin Fowler 认为这是一种反模式,他主张的方式叫做 Rich Domain Model,可以译作“富领域模型”,也就是领域对象里既包含数据,也包含行为。
至于所谓充血模型则是后人提出的,为了避免混淆,我们不采用“充血模型”这个词。在后面的讨论中,我会把贫血模型称为面向过程或者过程式编程,把富领域模型称为面向对象或对象式编程,因为真正的面向对象本来就是包含丰富逻辑的。
早期的面向对象编程,主要是用来开发桌面软件的,比如说开发一个 Office、一个 IDE 等等。这类软件的特点是基本上整个软件的数据都能装入内存,这样就可以通过对象之间自由的导航实现复杂的逻辑。对象在内存里形成一种网状结构,称为对象图(Object Graph)。但是企业应用则有一个本质的不同,就是数据主要在数据库里,每次只能把一小部分远程拿到内存,所以不能在内存里对对象进行自由地导航。这个区别就造成,早期的面向对象编程很难直接用在企业应用,间接导致了贫血模型的普及。
但在实践中,面向对象和面向过程往往不是非黑即白的,而是像下面这张图这样:在纯粹的面向对象和纯粹的面向过程之间有一个广阔的“灰色地带”。我们需要在其中找到一个平衡点。

应用逻辑 VS 领域逻辑
首先要承认,这两者有时候确实有些模糊地带。不过还是有一个总的思路:如果一个逻辑需要和领域专家讨论才能确认的,就是领域逻辑;如果领域专家根本不感兴趣的,多半就是应用逻辑。用再理性一点的话术就是:
- 领域逻辑:描述领域对象的行为有哪些
- 应用逻辑:描述完成一个业务功能如何编排领域接口及其他第三方接口。
一些好的代码习惯
除了上面的DDD领域中的几个问题外,还有一些在实际开发过程中的好的编程习惯,可以帮助我们写出更易维护的代码。
- 重视命名。DDD 强调,每个类、方法、甚至属性的命名都应该尽量直观地反映领域知识,与统一语言保持一致。初学者往往不重视命名,越是高手,越重视命名。
- 方法行数要适度。一般来说,函数一旦太长,就会不容易维护和测试。业界并没有统一的说法,我个人的建议是,一般不要超过二十行。
- 最小接口原则。所谓“封装”,指的是将一个模块的实现细节尽量隐藏在内部,只向外界暴露最小的可访问接口,目的是减少模块间的耦合,提高程序的可维护性。这里说的模块是广义的,一个函数、一个类、一个包乃至整个应用系统,都可以看作模块,而我们之前领域建模中说的模块模式是狭义的,专门指领域模型里的领域对象所组成的包。比如提供给上层调用的接口参数,要按照最小可用原则给出。
我的架构和代码实现
再次强调,架构设计中介绍的所有架构虽然都是由前人提出的,但并不是说要严格按照上述架构进行项目分层。上面架构的介绍,只是为了让大家了解DDD分层架构的思想。我们要形成适合自己项目的架构规范,可以是上面几种架构的结合、或者新的变种。
这部分后续完善。
写在最后
这篇文章断断续续写了有一周的时间,好在写完了。本章是迭代一的最后一节,在领域模型的基础上,进行了数据库设计、架构设计和代码实现,保证了代码实现与领域模型的一致性。最后介绍了我个人常用的分层架构及领域层的代码实现方式,希望大家都能找到适合自身的分层架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)