YOLO26改进创新 | 全网首发,MV-Split均值-方差残差重构,破解深层特征统计漂移,高阶写作创新!
YOLO26改进创新 | 全网首发,MV-Split均值-方差残差重构,破解深层特征统计漂移,高阶写作创新!
购买相关资料后畅享一对一答疑!
微信公众号:Ai计算机视觉
畅享超多免费持续更新且可大幅度提升文章档次的纯干货工具!
YOLO26改进创新 | MV-Split均值-方差残差重构,破解深层特征统计漂移
本文围绕 MV-Split 的原始论文思想与 YOLO26 检测适配策略展开

一、原文链接
论文标题:Mean Mode Screaming: Mean–Variance Split Residuals for 1000-Layer Diffusion Transformers
论文地址:https://arxiv.org/abs/2605.06169
二、为什么这篇工作值得拿来做 YOLO26 改进
原文研究的是超深层 DiT 在训练中进入均值主导塌缩状态的问题,并提出 MV-Split Residuals 把均值项与中心化残差分开控制。
对目标检测研究者来说,真正值得借鉴的从来不只是“原论文在原任务上做得强不强”,更关键的是:它解决的到底是不是一个我们在检测里也会频繁碰到的核心矛盾。
MV-Split 在这一点上瞄准的是 超深网络在训练时可能悄悄进入均值主导的塌缩态。一旦残差更新过于偏向均值,token 多样性会被明显抹平。 表面上损失仍可能稳定,但内部表达已经在退化。这些问题在原论文里出现于 Mean Mode Screaming: Mean–Variance Split Residuals for 1000-Layer Diffusion Transformers 对应的任务域,但一旦转到 YOLO26,我们会发现它们几乎都能在检测特征流中找到对应影子。

三、原文摘要翻译
原文摘要指出,把 Diffusion Transformer 一路堆到数百层甚至上千层以后,网络会出现一种很隐蔽的结构性脆弱性:模型会逐渐进入均值主导的塌缩状态,使 token 表征趋同,中心化差异被压平。作者把这种现象命名为均值模式尖叫。更关键的是,这个问题并不一定通过训练曲线直接暴露出来,因为损失表面上仍可能看似稳定。为了解决它,论文提出 MV-Split Residuals,把中心化残差更新和主干均值替换分开增益控制,从而显式阻断均值项失控放大的路径。在 400 层和 1000 层 DiT 上,这种结构性改动显著提升了极深网络的可训练性。
四、原文引言翻译整理
引言部分最有价值的地方在于它提醒我们:深层网络的不稳定,不一定都是优化器或学习率的问题,也可能是残差结构本身把网络推向了错误的统计平衡。作者通过机制审计发现,一旦均值方向上的梯度过于一致,残差分支会被整体打开,后续层便更倾向输出彼此相似的表示。这对目标检测虽然未必以同样剧烈的形式出现,但‘特征过平滑、语义漂移、边界细节被吞掉’这些现象,本质上和统计主导权失衡非常接近。因此,把 MV-Split 的均值-细节拆分思想嫁接到 YOLO26,可以理解为在深层主干里加入一个更讲统计纪律的残差更新规则。
五、原理解析:把论文的核心抓手翻成检测语言
如果只把论文名字抄写上去,而不知道它真正改变了哪条信息流,那改进文章通常会写得很虚。MV-Split 的价值并不在“换了个更复杂的块”,而在于它重新定义了特征在网络内部应当如何流动。
首先,从原文角度看,作者强调的关键抓手包括:对残差梯度做均值与中心化成分分解。;分别控制中心残差与主干均值替换。;用结构性改造阻止均值主导失控扩散到整网。。这些抓手如果直接照抄到检测网络里,要么接口不兼容,要么成本过高。因此,真正高质量的 YOLO26 融合写法不是整网照搬,而是抓住最能转化成 2D feature block 的那部分思想。
其次,从检测角度看,YOLO26 的优势是高效、多尺度、训练稳定,但它并不是面面俱到的通用最优器。当我们把检测任务放到复杂背景、长距离依赖、统计漂移、上采样细节损失或恶劣天气退化这些问题上时,传统 Conv + C3k2 + Neck 融合流程会暴露出比较明显的短板。MV-Split 恰好提供了一个足够清晰的研究方向:在不破坏 YOLO26 主流程的前提下,用一个相对克制的独立模块,把最脆弱的那条特征链路补强。

六、关键公式与数学直觉
残差拆分
r=\bar r + \tilde r,\ \tilde r = r-\bar r
残差被分成均值项和中心化细节项,二者不再共用同一条增益路径。
中心化更新
y_c=\gamma_c\cdot Norm(\tilde r)
细节项先做归一化再放回主干,避免纹理信息被均值噪声淹没。
均值校正
y_m=\gamma_m\cdot(\bar r-\lambda\bar x)
均值方向的更新被单独约束,避免整个特征图朝单一统计中心塌缩。
从写作上讲,这样处理有两个好处。第一,读者能迅速抓住论文到底控制了哪个变量。第二,后面讲 YOLO26 融合时,可以自然把这些公式映射到“模块插在什么位置、改变了什么信息流、为什么这会帮助检测”这三个问题上。
七、原文方法图表解读
如果我们把原文的方法图拆开来看,它本质上都在处理同一件事:不是简单把特征算得更大,而是把特征算得更对。所谓“更对”,对应的是三层含义。
第一层,是输入表征是否足够保留对任务有用的结构信息。
第二层,是中间处理过程是否在不必要的地方丢掉了边缘、层级或统计多样性。
第三层,是输出特征是否真正适合下游任务,而不是只在原论文自己的评价协议里好看。
八、YOLO26 融合改进创新点
- 把极深 DiT 的统计稳定化思想改造成检测主干中的轻量残差重构策略。
- 重点不在更强的注意力,而在让深层特征更新更守规矩、更少漂移。
- 对复杂亮度、噪声、细粒度纹理目标而言,这类模块往往比盲目加宽网络更实用。
更进一步地说,这种融合写法的价值并不只是“我给 YOLO26 又加了一个新块”。真正的创新点在于,你把原论文最有信息含量的机制抽出来,重新安排到目标检测最需要它的位置上。这样形成的文章,不会流于“换模块”的流水账,而会更像一篇有研究判断力的结构创新笔记。
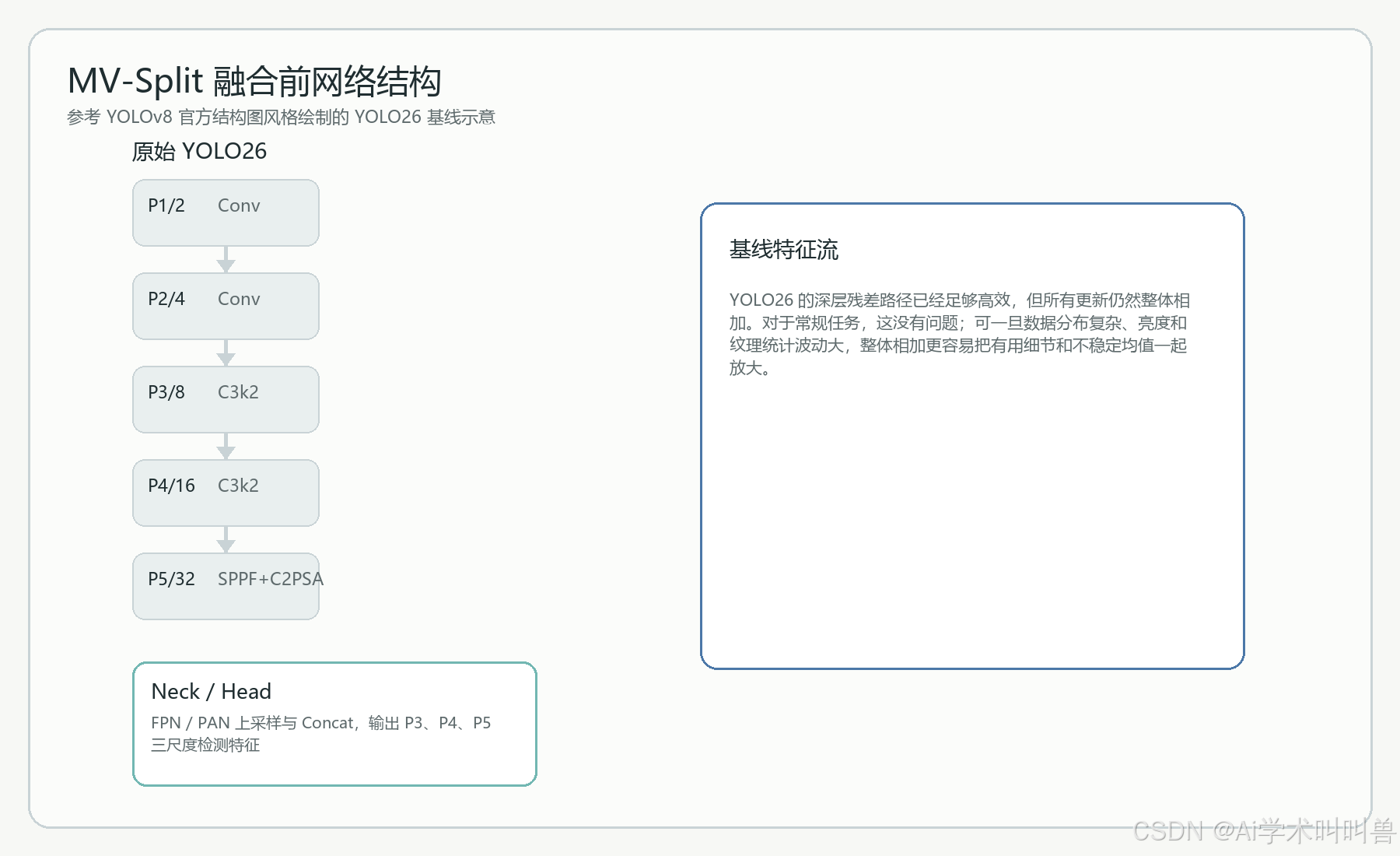
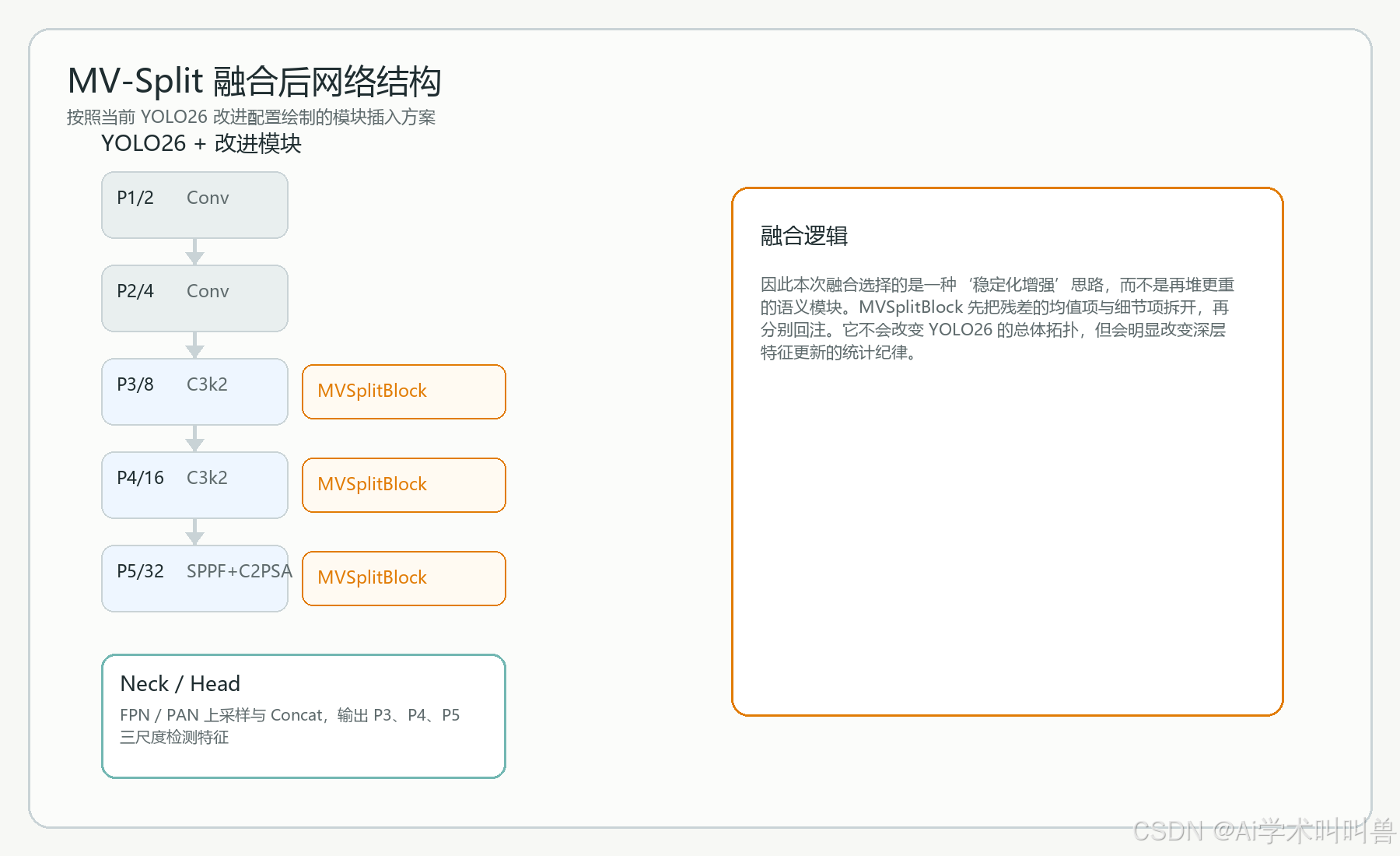
九、融合前后网络结构对比
在原始 YOLO26 中,主干和 Neck 的分工已经非常清晰:Backbone 负责逐级提炼语义,Neck 负责多尺度对齐,Head 负责检测输出。这套框架的优点是稳、快、成熟,但它默认所有节点的特征更新都遵循统一逻辑。问题恰恰出在这里:不同研究问题需要被修复的链路并不相同。
YOLO26 的深层残差路径已经足够高效,但所有更新仍然整体相加。对于常规任务,这没有问题;可一旦数据分布复杂、亮度和纹理统计波动大,整体相加更容易把有用细节和不稳定均值一起放大。
因此本次融合选择的是一种‘稳定化增强’思路,而不是再堆更重的语义模块。MVSplitBlock 先把残差的均值项与细节项拆开,再分别回注。它不会改变 YOLO26 的总体拓扑,但会明显改变深层特征更新的统计纪律。
十、模块改进前后对比

从检测视角总结,融合前后的变化至少可以从以下四个层面理解:
- 残差更新方式:融合前 统一残差直接相加;融合后 均值校正与细节增强分开处理
- 深层统计稳定性:融合前 可能出现特征偏置积累;融合后 通过 split 机制减缓均值漂移
- 对纹理保留:融合前 深层易过平滑;融合后 中心化细节分支保留更多局部变化
- 适合改进方向:融合前 堆叠语义块;融合后 优先稳住深层主干表达基础
十一、原理、创新点与写作思路如何展开
MV-Split 这类模块尤其适合做“原理型改进文章”,因为它既有论文层面的新意,又有结构迁移上的可解释性。只要你把“为什么插这里、为什么这样蒸馏、为什么这样比直接照搬更稳”讲清楚,整篇文章的质量就会上一个台阶。
十三、总结
总体来看,MV-Split 融合到 YOLO26 的意义,不在于制造一个花哨的新名词,而在于为检测网络补上一条原本相对薄弱的信息链路。它可能补的是全局语义,可能补的是多层 richness,可能补的是残差统计纪律,也可能补的是上采样边缘细节或复杂天气下的结构净化。但无论具体形式如何变化,真正高阶的创新写法始终遵循同一条逻辑:先识别 YOLO26 的真实短板,再从原文中提炼最适合检测的那部分机制,最后用结构、公式、图表和对比把这件事讲透。
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,关注UP:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。
因为经历过所以更懂小白的痛苦!
因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!
微信公众号:Ai计算机视觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)