AI 智能体/API 故障排查指南:从认证失败、记忆错乱到观测缺失的全流程修复手册
AI 智能体/API 故障排查指南:从认证失败、记忆错乱到观测缺失的全流程修复手册
结合 2026 年 5 月多条 AI 基础设施热点,给开发者一套可复现的排障框架:先分类,再定位,最后修复。
先看最终效果:这篇文章能帮你解决什么
如果你在做 ChatGPT 接入、AI 智能体、MCP Server、语音 Agent、模型 API 编排,这篇文章的目标很明确:帮你把“能跑但不稳定”的系统,快速定位到到底是认证、观测、记忆、流程还是实时交互出了问题。
你看 2026 年 5 月这波热点,其实已经把行业痛点写在脸上了:
- 2026-05-25,有媒体把“AI Agent 与 MCP Server 的认证”列为最关键基础设施之一;
- 2026-05-25,WorkOS 发布 auth.md,试图解决“AI agent 没有结构化注册方式”的问题;
- 2026-05-24,Langfuse 的教程重点放在 tracing、prompt 管理、评分、实验,说白了就是:别再裸奔上线;
- 2026-05-23,腾讯开源 TencentDB Agent Memory,主打 4 层本地记忆流水线;
- 2026-05-23,SuperClaude 工作流教程强调 commands、agents、modes、session memory;
- 2026-05-24,StepFun 发布 StepAudio 2.5 Realtime,把实时语音和副语言理解推到更高要求。
这些新闻看似分散,放到一线开发环境里,其实都在回答同一个问题:为什么你的 AI 系统一进生产就开始闹脾气?
本文按 CSDN 读者最常用的方式来写:先定义问题,再判断类型,再按优先级排查,最后给出不建议做法和 FAQ。
工具资源导航
如果你看完这波热点,想顺手把方案跑起来或者把账号环境补齐,这两个入口可以先收藏:
- JLS工具站:工具网站,GPT成品号,GPT代充,真实靠谱,可开发票。
- SuperStore:工具网站,GPT成品号,GPT代充,真实靠谱,可开发票。
文中工具入口属于资源信息整理,请结合平台规则和自身需求判断。
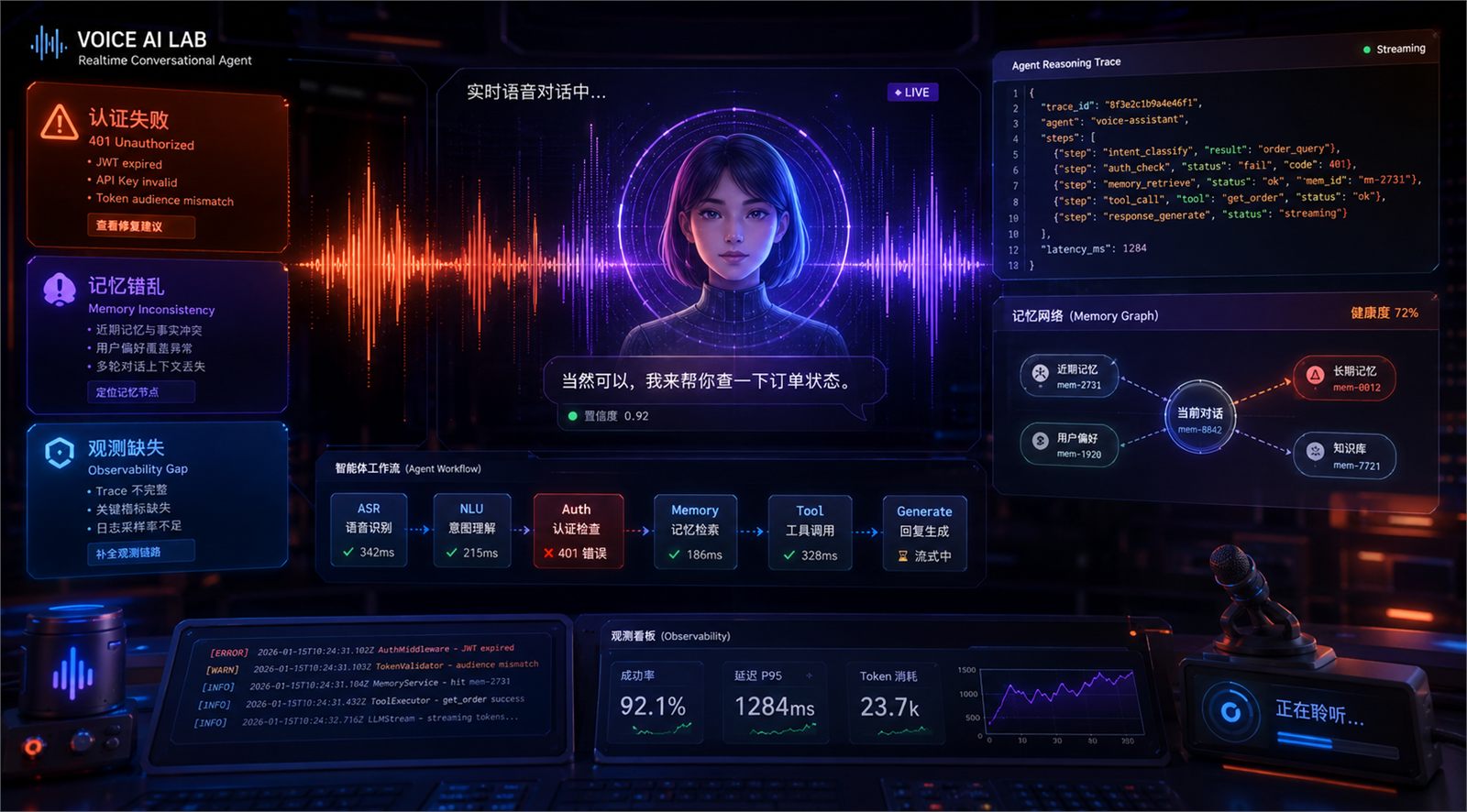
一、问题定义与适用范围
本文解决什么
本文主要解决以下几类真实故障:
- API 或 Agent 无法完成认证/授权,表现为调用失败、注册失败、工具访问被拒;
- 智能体能跑,但缺乏可观测性,出了错不知道卡在哪一层;
- 上下文记忆不稳定,会话记忆丢失、工具状态错乱、长期记忆失效;
- 工作流编排复杂后行为异常,如命令链错、模式切换错、会话状态互相污染;
- 实时语音 Agent 体验差,包括延迟高、角色语气不稳定、语音理解与文本链路脱节。
本文不解决什么
边界也说清楚,避免“拿扳手修 Wi-Fi”:
- 不解决具体模型效果优劣评测;
- 不展开讨论模型训练、微调和 RLHF 实现细节;
- 不提供任何“万能平台推荐”或“内部渠道方案”;
- 不保证某一个框架一装就万事大吉,工程上从来没有这种童话。
事实描述: 上述热点分别关注认证、注册协议、观测评测、记忆系统、工作流框架和实时语音能力。
观点分析: 这说明 2026 年 AI 落地的主要故障点,已经从“模型会不会答题”转向“系统能不能稳定交付”。
二、先判断问题类型:别一上来就怀疑模型发疯
建议先把问题归到下面 5 类之一。分类对了,排查效率至少翻倍。
类型 1:认证与注册问题
典型现象:
- API key 明明配置了,Agent 仍然拿不到资源;
- MCP Server 可见但不可用;
- 第三方应用不知道怎么让 AI agent 规范化注册;
- 权限作用域不对,导致“能登录,不能干活”。
这类问题和 2026-05-25 的认证平台讨论、以及 auth.md 协议发布 高度相关。
类型 2:观测缺失问题
典型现象:
- 用户说“回答不对”,你只能说“我这边复现不了”;
- 调用了多个工具,但不知道是 prompt、路由、模型还是工具返回先出错;
- A/B 实验做了,但没有统一 trace 和评分结果。
这类问题对应 2026-05-24 的 Langfuse 可观测性与评测流水线。
类型 3:记忆与上下文问题
典型现象:
- 智能体记得开头,忘了中间;
- 会话隔离做不好,A 用户的信息串到 B 用户;
- 长短期记忆层没有边界,命中逻辑一团乱麻。
这类问题对应 2026-05-23 腾讯开源的 4 层本地记忆系统,也和 SuperClaude 的 session memory 设计思路呼应。
类型 4:工作流编排问题
典型现象:
- 命令、agent、mode 一多,系统行为不可预测;
- 会话状态在多轮链路中丢失;
- 工具调用顺序和 fallback 逻辑冲突。
这和 2026-05-23 的 SuperClaude 工作流教程 直接相关。
类型 5:实时交互问题
典型现象:
- 语音对话延迟太高;
- 语气、角色感、语音理解与文本生成不同步;
- 实时链路中某一层阻塞,整体像“半双工电台”。
这对应 2026-05-24 StepAudio 2.5 Realtime 所强调的实时语音与副语言理解场景。
三、高频原因清单:按风险和出现概率排序

下面按“最常见 + 最容易造成线上事故”排序。
1)认证链路设计不完整
高风险,高概率。
很多团队的问题不是没有认证,而是只有“人类用户认证”,没有“AI agent 如何注册、如何拿到权限、如何声明能力”的结构化方案。WorkOS 发布 auth.md,本质上就是在补这块空白。
常见后果:
- Agent 接入要靠人工文档猜;
- 不同客户端行为不一致;
- 权限边界模糊,排错时只能靠抓包和祈祷。
2)缺少端到端 tracing
高风险,高概率。
如果没有 trace,你看到的不是系统,而是碎片。Langfuse 教程把 tracing、prompt 管理、评分、实验放到同一条流水线上,这透露出一个工程常识:没有统一观测,就没有可复现排错。
3)记忆层级没有拆分
中高风险,高概率。
腾讯开源的 4 层本地记忆流水线 很值得注意。仅从新闻摘要能看出,它强调的是“fully local memory system”和分层。说明行业已经默认:单一上下文缓存,不足以支撑生产级智能体。
4)工作流抽象过多,但缺少状态边界
中高风险,中高概率。
Commands、agents、modes、session memory 这些概念一旦叠起来,系统会很优雅,也可能很“玄学”。最常见的问题不是框架本身,而是:
- 谁负责会话态?
- 谁负责路由决策?
- 谁负责工具失败重试?
如果没人负责,那就是线上事故负责。
5)把实时语音当成普通文本接口来调
中风险,中概率。
StepAudio 2.5 Realtime 强调实时语音、角色化 RLHF 和副语言理解,这说明实时语音系统不是“文本模型 + TTS”的简单拼装。你如果还按普通文本 API 的思路做容错,用户会第一时间用沉默表达不满。
四、可执行排查流程:按步骤来,别用直觉修分布式系统
下面这套流程适合大多数 AI Agent / API 项目。每一步都包含“如何做”和“预期结果”。
步骤 1:先确认故障落点,是认证、观测、记忆还是实时链路
如何做:
- 复现一次完整请求;
- 记录输入、时间戳、调用链路、目标工具/模型;
- 判断失败是在“发起前、调用中、结果后处理”哪个阶段发生。
你至少要回答这 3 个问题:
- 请求有没有成功发出去?
- 中间有没有经过多 agent / 多工具?
- 最终失败是权限问题、响应问题还是状态问题?
预期结果:
把问题先归到前文的 5 大类型之一,别一上来就说“模型又抽风了”。很多时候,抽风的是集成层。
步骤 2:排查认证与注册链路
如何做:
- 检查 API key、token、scope、过期时间是否一致;
- 如果涉及 AI agent 自动接入,检查是否有明确的注册描述机制;
- 对照应用是否提供结构化的 agent 注册入口。根据 2026-05-25 的新闻,auth.md 的核心价值就是给应用发布一个标准化注册描述文件。
如果你的系统是“文档写在 README,接入全靠猜”,那就已经很危险了。
预期结果:
你应该能明确回答:
- Agent 是否被系统识别为合法调用方;
- 权限是否覆盖目标资源;
- 注册信息是否足够让 Agent 自动发现接入方式。
步骤 3:补齐 tracing,建立最小可观测闭环
如何做:
参考 2026-05-24 的 Langfuse 教程思路,至少建立下面几个观测点:
- 请求入口 trace id;
- prompt 版本;
- 模型调用耗时;
- 工具调用入参/出参摘要;
- 评分或结果标注;
- 实验版本标记。
如果你现在日志里只有一句 request failed,那它唯一的价值可能是提醒你:日志系统确实在工作。
预期结果:
做到这一层后,线上故障不再只是“有问题”,而是可以进一步判断:
- 是 prompt 回归;
- 是工具超时;
- 是模型响应格式变化;
- 还是下游接口返回异常。
步骤 4:检查记忆架构,确认是否需要分层
如何做:
根据腾讯开源项目的信号,重点检查你的系统是不是把所有记忆都塞进一个桶里。建议至少把以下问题问清楚:
- 会话级记忆和长期记忆是否分离?
- 本地记忆是否可以独立运行?
- 记忆检索命中后,是否有去重、优先级或时效策略?
- 多用户场景下,记忆是否有严格隔离?
预期结果:
你能判断“记不住”到底是:
- 没存进去;
- 存了但找不到;
- 找到了但注入顺序错;
- 注入了但被后续工作流覆盖。
步骤 5:检查工作流状态边界
如何做:
如果你用了类似 SuperClaude 这种有 commands、agents、modes、session memory 的工作流,建议画出最小链路:
用户输入 -> 路由决策 -> 选定 agent -> 调工具 -> 写入 session memory -> 返回结果
然后逐个确认:
- 命令解析是否唯一;
- 模式切换是否有条件触发;
- session memory 的读写是否只在必要节点发生;
- 工具失败后是重试、降级还是中断。
预期结果:
你应该能定位是“框架太复杂”还是“状态设计太松”。大多数时候,锅在后者。
步骤 6:排查实时语音链路的延迟与一致性
如何做:
结合 StepAudio 2.5 Realtime 的新闻重点,把实时语音问题拆成 3 层:
- 输入层:音频采集与识别是否稳定;
- 理解层:文本理解是否保留语气、角色、停顿等副语言线索;
- 输出层:生成与播报是否连续,是否发生阻塞。
不要只测总延迟,要测链路分段延迟。
预期结果:
你能知道卡顿是发生在:
- 音频进来太慢;
- 模型理解阶段过长;
- 生成后播报链路阻塞;
- 还是角色化输出与实时调度互相打架。
步骤 7:回放一次真实用户请求,验证修复是否稳定
如何做:
- 选一个线上真实问题样本;
- 按修复前后的相同输入做对比;
- 比较 trace、耗时、记忆命中、工具调用成功率、最终输出一致性。
预期结果:
修复不是“这次好了”,而是“同类问题可以稳定复现并被消除”。这才叫工程,不叫碰运气。
五、不建议做法:这些坑,踩一次就够了

1. 不要把所有故障都归因于模型
模型当然会犯错,但认证失败、上下文串线、工具超时,这些很多是系统问题。别让模型替你的架构背锅。
2. 不要没有 tracing 就直接上线多工具 Agent
多工具编排如果没有观测,排障体验会像在黑屋里找黑猫,而且黑猫还会调 API。
3. 不要把记忆当成一个全局字符串
看起来省事,后续调试会极其痛苦。会话、用户、任务、长期偏好,最好有边界。
4. 不要只写面向人类的接入文档
如果系统希望 Agent 自动接入,那么结构化注册描述会越来越重要。auth.md 这类方案值得持续关注。
5. 不要用文本接口思维硬套实时语音
实时语音不仅要求“答得对”,还要求“答得及时、像人在说话”。这是两个完全不同的工程目标。
六、热点拆解与趋势判断:这些新闻为什么值得开发者注意
事实描述: 2026 年 5 月的几条热点分别指向认证、注册协议、可观测性、记忆系统、工作流抽象和实时语音。
观点分析: 这说明 AI 应用正在从“单次问答工具”变成“持续运行的生产系统”。
我更关心的是三个趋势:
趋势 1:认证会从“可选项”变成“第一优先级”
当 AI agent 开始自动调用工具、访问资源、执行工作流时,认证不是登录页的事情,而是系统边界的事情。谁能访问、怎么注册、权限怎么声明,会越来越标准化。
趋势 2:可观测性会成为 AI 工程默认配置
Langfuse 这类 tracing + prompt 管理 + 评分 + 实验的一体化思路,说明团队已经不满足于“把日志记下来”。未来更重要的是:能不能快速判断问题来自提示词、模型、工具还是状态。
趋势 3:记忆与工作流会从 demo 能力升级为基础设施
腾讯的本地记忆系统、SuperClaude 的结构化工作流,都在证明一点:Agent 真正进入生产,不靠灵感,靠分层。
七、对开发者、技术运营和副业实践者的启发
对开发者
先搭最小排障框架,再追求复杂能力。顺序最好是:
- 认证清晰;
- trace 打通;
- 记忆分层;
- 工作流编排;
- 再考虑实时语音和高级体验。
对技术运营
运营侧不要只盯转化,也要看“故障可解释性”。如果用户反馈无法映射到 trace、版本和调用链,问题会长期积压。
对做副业项目的人
小项目最容易犯的错,是“先拼功能,后补工程”。现实通常是:功能用户还能忍,连续故障用户直接走。哪怕是 MVP,也至少把认证、日志和会话隔离先做好。
八、常见问题速查(FAQ)
Q1:我的 AI Agent 能调用模型,但调用工具总失败,先查哪里?
先查 认证与注册链路。模型能调用,不代表工具也拿到了正确权限。尤其在多系统接入时,要优先确认 token、scope、注册描述是否完整。
Q2:回答质量忽高忽低,是不是模型不稳定?
不一定。先查有没有 trace、prompt 版本、工具返回差异。没有观测数据时,所有结论都只是猜测。
Q3:会话记忆老丢,是不是上下文窗口不够?
有可能,但不一定。也可能是 记忆没存进去、没检索到、注入顺序错、被工作流覆盖。先看记忆架构是否分层。
Q4:为什么要关注 auth.md 这类协议?
因为新闻已经点出一个真实痛点:很多 web 应用还没有给 AI agent 提供结构化注册方式。随着 agent 自动接入变多,靠自然语言文档接入会越来越吃力。
Q5:实时语音最先该优化什么?
先不要追“听起来像真人”,先把 链路延迟拆段测清楚。否则你会在错误的环节优化出一套很努力但没效果的方案。
九、结语:先把系统排障能力建起来,再谈 AI 规模化
如果要把这几条 2026 年 5 月的热点压缩成一句话,那就是:AI 工程的核心矛盾,正在从“模型够不够聪明”转向“系统够不够可靠”。
对开发者来说,最实用的行动建议不是立刻追新框架,而是马上做 4 件事:
- 给认证和 Agent 注册链路做一次梳理;
- 补最小 tracing 闭环;
- 检查记忆是否需要分层;
- 给工作流和实时链路画出状态边界。
你会发现,很多所谓“AI 故障”,最后并不是 AI 的锅,而是系统工程在提醒你:别再把生产环境当实验室。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)