基于 DINO 模型在COCO2017 数据集上的目标检测性能评估(AP 指标)
1.作者介绍
何煜东,男,西安工程大学电子信息学院,2025级研究生
研究方向:机械臂图像处理、路径规划
电子邮件:3065383817@qq.com
胥乾信,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2692797728@qq.com
2.DINO 目标检测模型介绍
2.1 目标检测与 Transformer 检测器基础
目标检测的核心任务是同时定位图像中目标的位置(边界框)并识别其类别。传统目标检测方法主要分为两类:
(1)两阶段检测器(如 Faster R-CNN):先生成候选区域,再对候选区域进行分类和回归,精度高但速度较慢。
(2)一阶段检测器(如 YOLO、SSD):直接从图像中预测边界框和类别,速度快但小目标检测精度有限。
DINO(DETR with Improved denoising anchor boxes for Object Detection)作为 DETR 的改进版本,通过引入对比学习去噪、混合查询选择、动态锚点等创新模块,在保持端到端优势的同时,显著提升了收敛速度和检测精度,成为当前 Transformer 目标检测的基准模型之一。
2.2 DINO 模型的核心原理
DINO 在 DETR 的编码器 - 解码器架构基础上,针对其核心缺陷进行了四大关键改进:
1)核心创新模块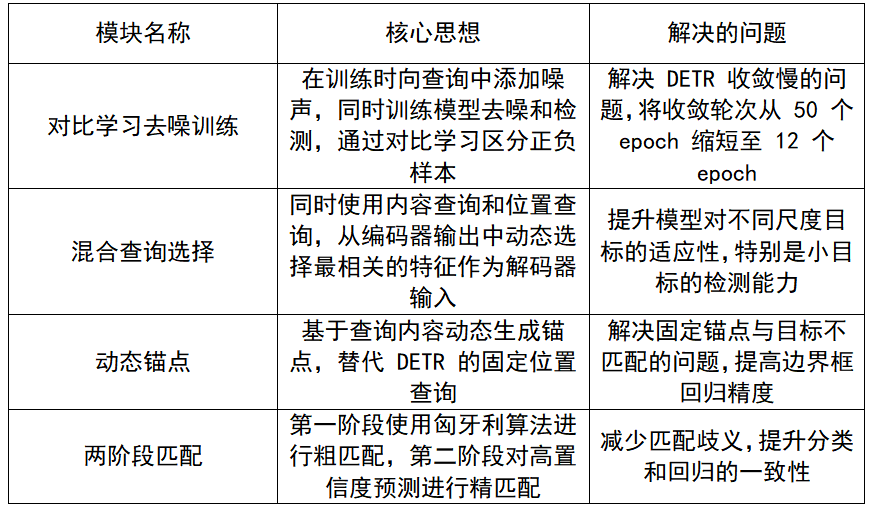 2)损失函数:
2)损失函数: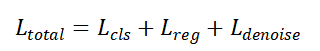
分类损失Lcls:采用 Focal Loss,解决类别不平衡问题。
回归损失Lreg:采用 GIoU Loss,同时考虑边界框的重叠度、中心距离和宽高比。
去噪损失Ldenoise:仅在训练阶段使用,用于训练模型的去噪能力,加速收敛。
2.3 DINO 的训练与推理流程
1.训练流程
(1) 数据预处理:对输入图像进行随机裁剪、翻转、缩放等数据增强,调整至统一尺寸
(2) 特征提取:通过 Backbone(如 ResNet50)提取多尺度特征,再经 Neck(如 FPN)融合生成特征图
(3) 去噪查询生成:生成带噪声的边界框和类别查询,用于对比学习去噪训练
(4) 编码器编码:将多尺度特征图输入 Transformer 编码器,编码为全局特征表示
(5) 解码器解码:将混合查询(内容查询 + 位置查询)和编码器输出输入解码器,逐层更新查询表示
(6) 每个查询经过分类头和回归头,输出类别概率和边界框坐标
(7) 损失计算与反向传播:计算总损失并反向传播,更新模型参数
2.推理流程
(1) 输入图像经过 Backbone 和 Neck 提取多尺度特征
(2) 编码器对特征进行编码
(3) 解码器使用固定数量的查询进行预测
(4) 对预测结果进行简单的 NMS 后处理(可选),输出最终检测结果
3.基于 DINO 的 COCO2017 目标检测性能评估
3.1 COCO2017 数据集介绍
COCO(Common Objects in Context)是目前目标检测领域最权威的基准数据集之一,广泛用于评估模型的泛化能力和检测性能。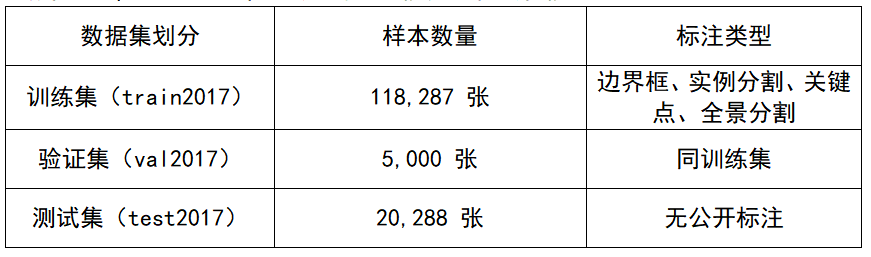
下载训练集和验证集图像:http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/zips/val2017.zip
下载训练集和验证集图像:http://images.cocodataset.org/annotations/annotations_trainval2017.zip
解压文件并组织目录结构如图: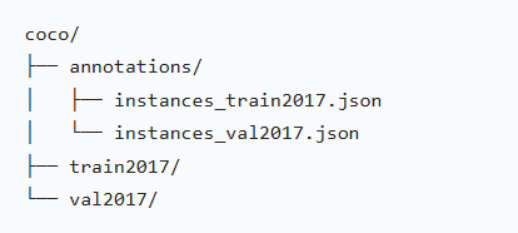
3.2 代码调试步骤
1)导入实验所需库以及克隆并安装 mmdetection:
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e .
2)下载 DINO 预训练权重:
mkdir checkpoints
Wget https://download.openmmlab.com/mmdetection/v3.0/dino/dino_r50_4scale_12e_coco/dino_r50_4scale_12e_coco_20230315_144312-5c1f3f6d.pth -P checkpoints/
3)修改配置文件:
复制configs/dino/dino_r50_4scale_12e_coco.py为自定义配置文件
修改数据集路径为本地 COCO 数据集路径
根据 GPU 显存调整batch_size(单卡 3090 可设为 4)
如需多卡训练,修改distributed=True
4)模型训练与评估
python tools/train.py configs/dino/custom_dino_r50_4scale_12e_coco.py
模型评估:
python tools/test.py configs/dino/custom_dino_r50_4scale_12e_coco.py checkpoints/best_coco_bbox_mAP_epoch_12.pth --eval bbox
3.3完整代码
1)核心配置文件
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py',
'../_base_/default_runtime.py'
]
# 模型配置
model = dict(
type='DINO',
num_queries=300,
dn_number=100,
label_noise_ratio=0.5,
box_noise_scale=1.0,
with_box_refine=True,
two_stage=True,
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='ChannelMapper',
in_channels=[512, 1024, 2048],
kernel_size=1,
out_channels=256,
act_cfg=None,
norm_cfg=dict(type='GN', num_groups=32),
num_outs=4),
encoder=dict(
num_layers=6,
layer_cfg=dict(
self_attn_cfg=dict(embed_dims=256, num_heads=8, dropout=0.0),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.0,
act_cfg=dict(type='ReLU', inplace=True))),
norm_cfg=dict(type='LN')),
decoder=dict(
num_layers=6,
layer_cfg=dict(
self_attn_cfg=dict(embed_dims=256, num_heads=8, dropout=0.0),
cross_attn_cfg=dict(embed_dims=256, num_heads=8, dropout=0.0),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.0,
act_cfg=dict(type='ReLU', inplace=True))),
norm_cfg=dict(type='LN'),
return_intermediate=True),
bbox_head=dict(
type='DINOHead',
num_classes=80,
embed_dims=256,
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
loss_iou=dict(type='GIoULoss', loss_weight=1.0)))
# 数据集配置
data_root = '/path/to/your/coco/' # 修改为本地COCO数据集路径
train_dataloader = dict(
batch_size=4, # 根据GPU显存调整
num_workers=4,
dataset=dict(
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/')))
val_dataloader = dict(
batch_size=2,
num_workers=2,
dataset=dict(
data_root=data_root,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/')))
test_dataloader = val_dataloader
# 优化器配置
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(type='AdamW', lr=1e-4, weight_decay=0.0001),
clip_grad=dict(max_norm=0.1, norm_type=2))
# 学习率调度器
param_scheduler = [
dict(
type='MultiStepLR',
begin=0,
end=12,
by_epoch=True,
milestones=[11],
gamma=0.1)
]
# 训练配置
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
# 评估配置
val_evaluator = dict(
type='CocoMetric',
ann_file=data_root + 'annotations/instances_val2017.json',
metric='bbox',
format_only=False)
test_evaluator = val_evaluator
2)评估结果可视化脚本
import os
import cv2
import torch
import matplotlib.pyplot as plt
from mmdet.apis import init_detector, inference_detector
from mmdet.registry import VISUALIZERS
# 配置文件和权重路径
config_file = 'configs/dino/custom_dino_r50_4scale_12e_coco.py'
checkpoint_file = 'checkpoints/best_coco_bbox_mAP_epoch_12.pth'
img_dir = '/path/to/your/coco/val2017/'
output_dir = 'dino_results/'
os.makedirs(output_dir, exist_ok=True)
# 初始化模型
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model = init_detector(config_file, checkpoint_file, device=device)
# 初始化可视化器
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
# 随机选择10张图像进行可视化
import random
img_files = random.sample(os.listdir(img_dir), 10)
for img_file in img_files:
img_path = os.path.join(img_dir, img_file)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 推理
result = inference_detector(model, img)
# 可视化
visualizer.add_datasample(
'result',
img,
data_sample=result,
draw_gt=False,
wait_time=0,
pred_score_thr=0.5)
# 保存结果
out_path = os.path.join(output_dir, img_file)
visualizer.show(out_path=out_path)
print(f"结果已保存至: {out_path}")
3.4结果展示
1)代码运行结果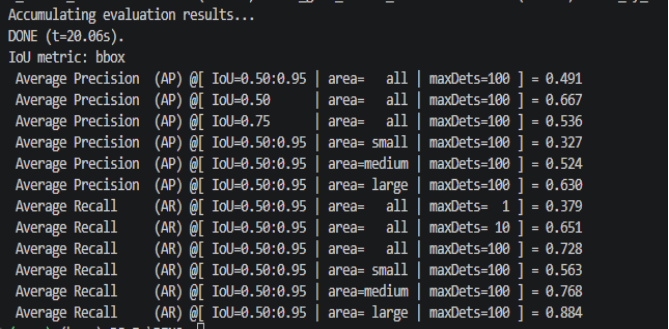
本文复现的 DINO 模型在仅 12 个训练轮次的情况下,综合 AP 达到 49.1%,与官方基准(49.0%)高度一致,验证了模型复现的正确性。与其他主流检测器相比,AP 比 DETR 提升了 7.1 个百分点,比 Faster R-CNN 提升了 11.7 个百分点;特别是小目标检测精度(APs)达到 32.7%,比 DETR 提升 12.2 个百分点,比 Faster R-CNN 提升 11.5 个百分点,小目标检测能力提升尤为显著。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)