学习笔记(卷积神经网络CNN)
一、卷积神经网络概念
卷积神经网络(Convolutional Neural Network,CNN)是一种专门为处理具有网格结构数据(如图像、音频)而设计的深度学习模型 ,是深度学习的代表算法之一。它通过卷积层中的卷积核与输入数据进行卷积操作,自动提取数据中的特征 。
卷积神经网络受到人类视觉皮层的启发,在从结构化网格数据(如图像)中提取特征的空间层次结构方面特别有效。图像自然地被表示为多维阵列-通常是具有对应于高度、宽度和颜色通道的维度的3D张量(RGB)。这种结构化表示使图像成为CNN的理想候选者,CNN利用卷积运算来有效地处理输入数据的局部区域。
典型的 CNN 模型层次主要包括:数据输入层、卷积层、池化层和全连接层。
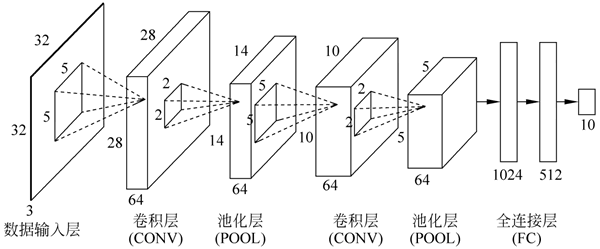
通常来说一个图像识别相关的卷积神经网络模型是这些不同功能层的组合。

卷积神经网络模型有小到几层的浅层网络结构也有大道数百层的超深层网络(如ResNet 的变体),网络的层数并非越深越好,ResNet 论文指出,超过一定深度后(如 152 层 vs 1000 层),精度提升趋于饱和,甚至因过拟合而下降。实际部署中,ResNet-50 仍是工业界的"黄金标准"之一,兼顾精度与推理速度。
二、CNN各层次结构概念
1.输入层
输入层是 CNN 处理数据的入口,它的主要作用是接收原始数据,并将其转换为适合后续层处理的格式 。对于图像数据而言,通常以多维数组的形式输入,比如常见的 RGB 彩色图像,其维度为 (高度,宽度,通道数),其中通道数为 3,分别对应红、绿、蓝三个颜色通道;灰度图像的通道数则为 1 。


在数据进入后续层之前,往往需要进行一些预处理操作 。去均值操作是将图像中每个像素点的 RGB 值减去数据集的均值,这样可以使数据的中心分布在原点附近,有助于模型的收敛。归一化操作则是将像素值的范围缩放到特定区间,如 [0, 1] 或 [-1, 1],减少不同特征之间的尺度差异对模型训练的影响 。对于一张像素值范围在 0 - 255 的图像,将其每个像素值除以 255,就可以将其归一化到 [0, 1] 区间 。这些预处理步骤对于提升模型的性能和稳定性至关重要。
2.卷积层
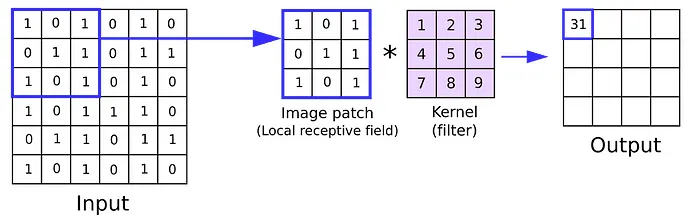
CNN的主干是卷积层,它将过滤器(或内核)应用于输入数据以提取边缘,纹理和模式等特征。这些层负责检测输入中的局部模式并构建数据的分层表示。每个卷积层产生一个或多个特征图,突出显示输入的特定特征。
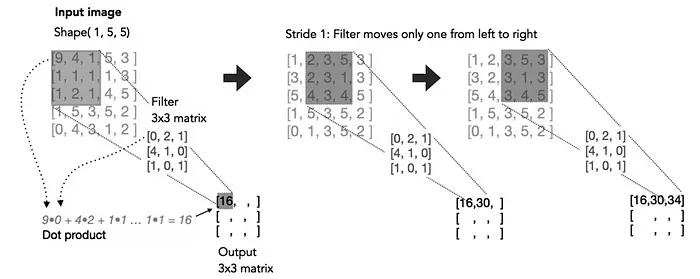
在数学上,卷积运算涉及在输入矩阵上滑动滤波器并计算滤波器权重与输入的对应区域之间的点积。这个过程捕获空间关系,使网络能够学习有意义的特征。
1.卷积核(Kernel):过滤器
卷积核(或滤波器)是一个小的权重矩阵,它在输入数据上滑动以执行卷积运算。核的大小决定卷积的感受野,即,对每次计算有贡献的输入的局部区域。常见的内核大小包括3×3、5×5或7×7。
对于给定的大小为H×W的输入矩阵I和大小为K×K的卷积核F,位置(i,j)处的输出特征图O计算为:
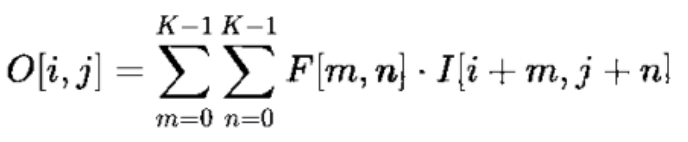
每个过滤器检测特定类型的特征,例如水平边缘、垂直边缘或纹理。通过堆叠多个滤波器,卷积层可以并行捕获各种模式。
常见的卷积核有:
Sobel 算子(垂直边缘检测)
[-1 0 1]
[-2 0 2]
[-1 0 1]
作用为检测图像中垂直方向的边缘(左右亮度突变)。比如一道竖直的墙与天空的交界。
Sobel 算子(水平边缘检测)
[-1 -2 -1]
[ 0 0 0]
[ 1 2 1]
作用为检测水平方向的边缘(上下亮度突变)。比如地平线的位置。
Prewitt 算子(类似 Sobel,权重更均匀)
[-1 0 1] [-1 -1 -1]
[-1 0 1] 和 [ 0 0 0]
[-1 0 1] [ 1 1 1]
拉普拉斯算子(二阶边缘检测)
[ 0 1 0]
[ 1 -4 1]
[ 0 1 0]
通常检测所有方向的边缘,对边缘位置更敏感,但对噪声也更敏感。常用于提取图像的轮廓。
高斯模糊卷积核(平滑/去噪)
[1/16 2/16 1/16]
[2/16 4/16 2/16]
[1/16 2/16 1/16]
可对图像进行平滑模糊,减少噪声。高斯核在 CNN 中不常用作检测器,但池化层(如平均池化)有类似思想。
锐化卷积核
[ 0 -1 0]
[-1 5 -1]
[ 0 -1 0]
作用为增强图像边缘和细节,使图像看起来更清晰。
2.填充Padding
填充涉及在输入矩阵的边界周围添加额外的像素(通常为零)。填充可确保输出特征图保持与输入相同的空间维度,或防止边缘处的信息丢失。
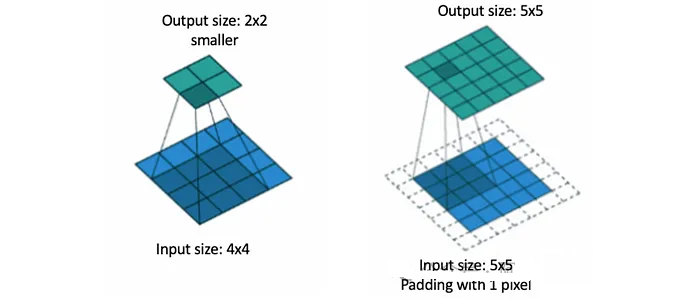
例如,如果将3×3滤波器应用于具有“相同”填充的5×5输入,则输出仍为5×5。如果没有填充,输出大小将由于过滤器与边缘的重叠而缩小。
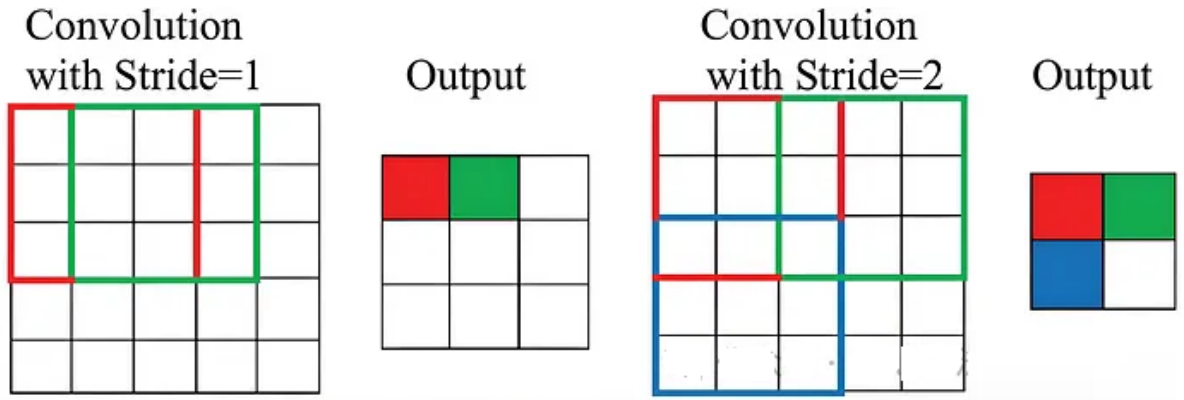
3.步幅Stride
步幅决定了在卷积运算期间滤波器在输入矩阵上移动的程度。步幅为1意味着过滤器一次移动一个像素,而较大的步幅跳过像素,减少输出特征图的空间维度。
在应用具有步幅S的卷积之后,用于计算输出大小的公式为:![]()
H和W是输入的高度和宽度,K是卷积核大小,P是填充大小,S是步幅。
例如,步长为2时,过滤器会跳过每隔一个像素,从而有效地将输出特征图的空间维度减半。
3.ReLU激活层
在卷积层提取到线性特征后,激活函数的作用就凸显出来了。它为神经网络引入了非线性因素,使得模型能够学习和表示更加复杂的函数关系,大大增强了模型的表达能力 。如果没有激活函数,无论神经网络有多少层,其输出都只是输入的线性组合,这就相当于只有一个隐藏层的神经网络,无法处理复杂的任务 。
CNN 采用的激活函数一般为 ReLU(the rectified linear unit,修正线性单元),它的特点是收敛快、求梯度简单,但较脆弱,其图像如下图所示。
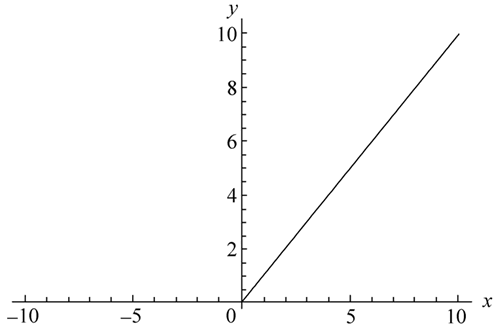
它的优点十分显著,计算简单,收敛速度快,能够有效缓解梯度消失问题 。在深层神经网络中,使用 ReLU 作为激活函数,训练速度比使用 Sigmoid 等函数快很多 。但它也存在一些缺点,当 x 小于 0 时,神经元会处于 “死亡” 状态,即梯度为 0,在训练过程中无法更新参数 。如果学习率设置不当,可能会导致大量神经元死亡,从而影响模型性能 。为了解决这个问题,出现了一些 ReLU 的变体,如 Leaky ReLU,它在 x 小于 0 时,会给予一个很小的非零梯度,避免神经元完全死亡 。
4.池化层
池层在减少特征映射的空间维度方面发挥着至关重要的作用,使模型的计算效率更高,更不容易过拟合。通过总结特征图的局部区域中的信息,池化有助于保留最重要的特征,同时丢弃不太相关的细节。这种降维也减少了后续层中的参数数量,加快了训练和推理,最常见的池化类型是最大池化和平均池化。
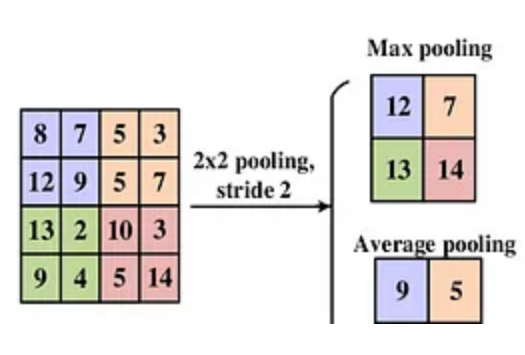
最大池化:最大池化从特征图的每个局部区域获取最大值。例如,如果我们使用一个2×2的窗口来应用最大池化,则位置(i,j)处的输出计算为:![]()
最大池化被广泛使用,因为它保留了每个区域中最突出的特征,例如边缘或纹理,这些特征通常是图像分类等任务中信息量最大的。
例如:一个4×4特征图:

应用步长为2的2×2最大池化会有:
![]()
平均池化:平均池化计算每个局部区域的平均值,而不是最大值。此操作平滑了特征图,并提供了输入的更全局的表示。平均池的公式为:
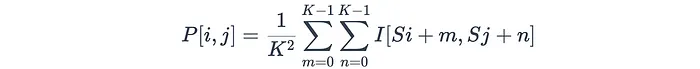
其中K是池化窗口的大小,S是步幅。
使用与上述相同的4×4特征图,应用步长为2的2×2平均池化,结果为:

虽然最大池化强调的是最显著的特征,但平均池化捕捉了更广泛的输入摘要,使其在微妙模式很重要的场景中非常有用。
5.全连接层
在CNN的结尾,全连接(FC)层联合收割机结合提取的特征进行预测。这些层基于学习的表示执行分类或回归。在多个卷积层和池化层降低了空间维度并提取了高级特征之后,完全连接的层充当网络的决策组件。
全连接层中的每个神经元都连接到前一层中的每个神经元。全连接层的输出是使用线性变换和激活函数计算的:
W是权重矩阵,x是输入向量(平坦化特征图),B是偏置项。结果通过激活函数(例如,ReLU、softmax)引入非线性并产生最终输出。
全连接层集成了卷积层和池化层提取的分层特征,以理解数据。虽然卷积层专注于局部模式,但全连接层提供了全局视图,使网络能够做出明智的预测。
池化层降低了维度并强调了关键特征,而全连接层联合收割机结合了这些特征来解决分类或回归等特定任务。它们共同构成了现代深度学习架构的支柱。
三、用CNN实现MNIST手写数字分类(灰度图)
以下示例展示用 PyTorch 构建一个简单的 CNN 模型,用于 MNIST 数据集的数字分类。
1.数据加载与预处理
使用 torchvision 提供的 MNIST 数据集,加载和预处理数据。
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
# 1. 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=1000, shuffle=False)
2.使用 nn.Module 构建一个 CNN
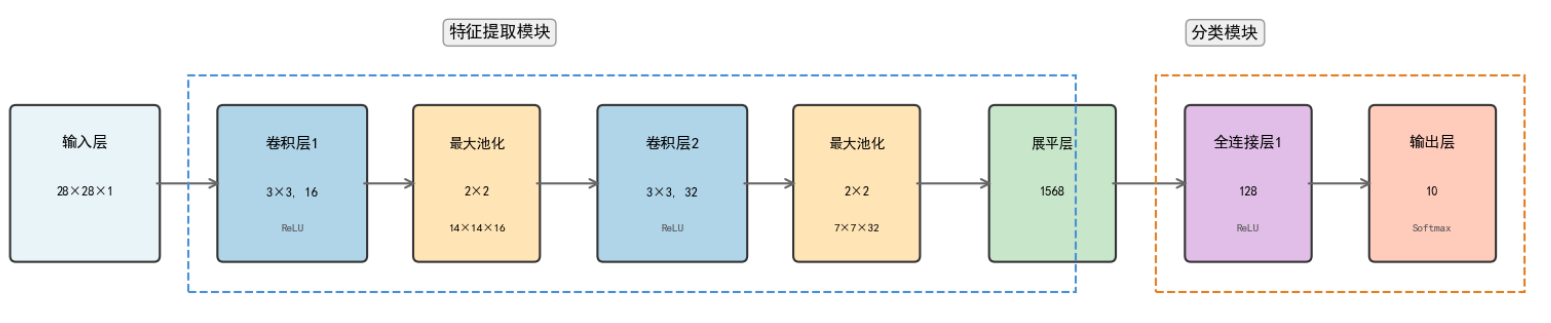
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 28x28 -> 14x14
x = self.pool(F.relu(self.conv2(x))) # 14x14 -> 7x7
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleCNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
3.训练模型并记录损失
losses = []
epochs = 5
for epoch in range(epochs):
running_loss = 0.0
for images, labels in trainloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
losses.append(avg_loss)
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}")
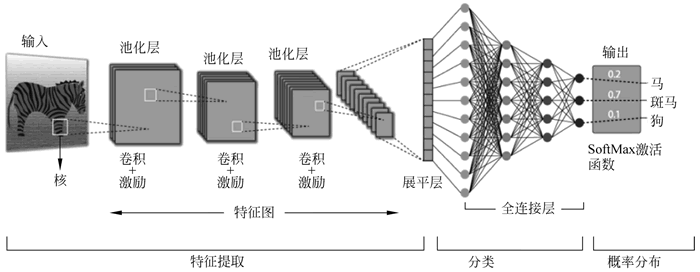
4.相关结构可视化输出
plt.figure(figsize=(7, 4))
plt.plot(range(1, epochs+1), losses, marker='o')
plt.title('Training Loss Curve (CNN on MNIST)')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.tight_layout()
plt.show()
#测试集准确率
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")
#可视化部分测试样本及预测结果
examples = enumerate(testloader)
batch_idx, (example_data, example_targets) = next(examples)
output = model(example_data)
_, preds = torch.max(output, 1)
plt.figure(figsize=(10, 3))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(example_data[i][0].cpu().numpy(), cmap='gray')
plt.title(f"Label: {example_targets[i]}\nPred: {preds[i].item()}")
plt.axis('off')
plt.suptitle('CNN Predictions on MNIST Test Samples')
plt.tight_layout(rect=[0, 0, 1, 0.92])
plt.show()
结果输出:

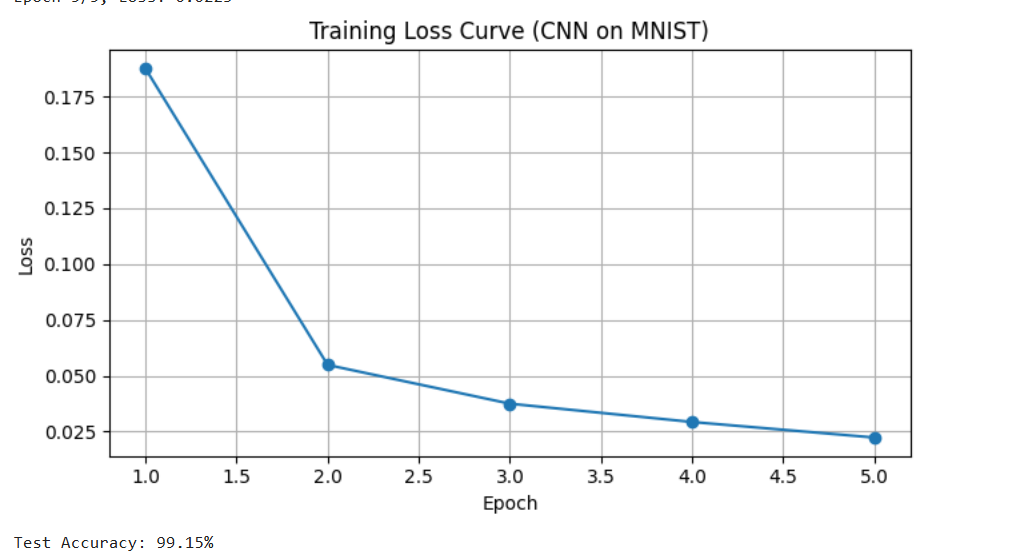

可以看出本次运行的CNN模型在MNIST手写数字分类任务上表现优异:仅训练5个epoch,训练损失便从0.1876稳步下降至0.0223,收敛迅速且无过拟合迹象;最终在测试集上取得了99.15%的高准确率,对随机抽取的10个测试样本全部预测正确。
使用matplotlib简要的画出本次CNN的网络结构:
四、用CNN实现CIFAR-10彩色图像分类(彩色图)
这个任务的主要挑战是处理彩色图像和更复杂的分类,使用的是CIFAR-10数据集,CIFAR-10是一个更接近普适物体的彩色图像数据集。。
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
# ============ 中文显示 ============
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
# 1. 数据加载与预处理(CIFAR-10专用)
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转,数据增强
transforms.RandomCrop(32, padding=4), # 随机裁剪,数据增强
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR-10的均值和标准差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 下载CIFAR-10数据集
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# CIFAR-10的类别名称
classes = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
# 2. 定义改进的CNN模型(适用于CIFAR-10)
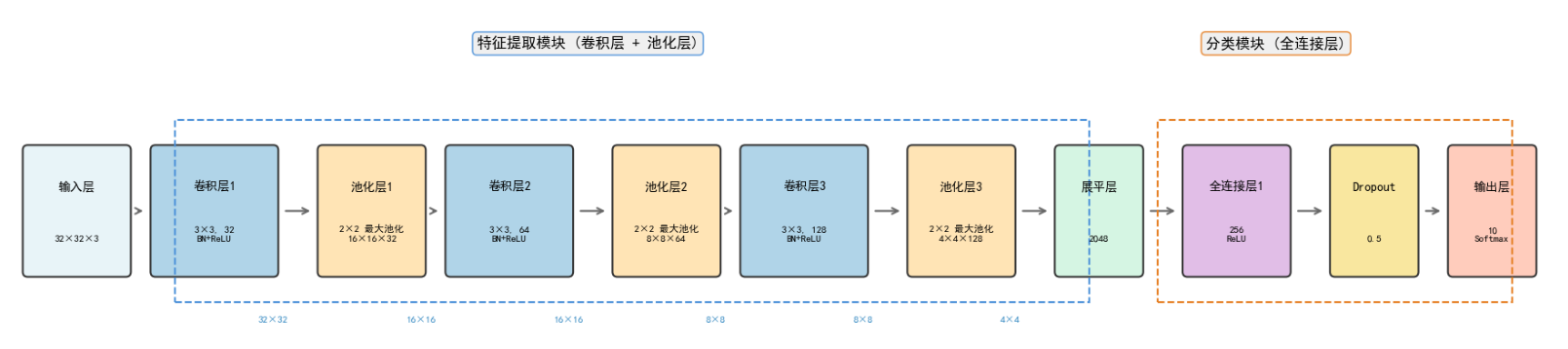
class ImprovedCIFAR10CNN(nn.Module):
def __init__(self):
super().__init__()
# 第一个卷积块:输入3通道RGB图像 -> 32通道
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32) # 批归一化,加速收敛
self.pool = nn.MaxPool2d(2, 2)
# 第二个卷积块:32 -> 64通道
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
# 第三个卷积块:64 -> 128通道
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
# CIFAR-10原始尺寸32x32,经过三次池化后:32 -> 16 -> 8 -> 4
# 最终特征图大小:128通道 x 4 x 4 = 2048
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.dropout = nn.Dropout(0.5) # 防止过拟合
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
# 第一个卷积块
x = self.pool(F.relu(self.bn1(self.conv1(x)))) # 32x32 -> 16x16
# 第二个卷积块
x = self.pool(F.relu(self.bn2(self.conv2(x)))) # 16x16 -> 8x8
# 第三个卷积块
x = self.pool(F.relu(self.bn3(self.conv3(x)))) # 8x8 -> 4x4
# 展平
x = x.view(-1, 128 * 4 * 4)
# 全连接层
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
model = ImprovedCIFAR10CNN()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
print(f"使用设备: {device}")
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 学习率调度器:每10个epoch将学习率乘以0.5
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 3. 训练模型并记录损失和准确率
losses = []
accuracies = []
epochs = 20 # CIFAR-10需要更多epoch
print("开始训练...")
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = running_loss / len(trainloader)
train_acc = 100 * correct / total
losses.append(avg_loss)
accuracies.append(train_acc)
# 更新学习率
scheduler.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Train Acc: {train_acc:.2f}%")
print("训练完成!")
# 4. 可视化训练曲线
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
ax1.plot(range(1, epochs+1), losses, marker='o', color='blue', linewidth=2)
ax1.set_title('训练损失曲线', fontsize=12, fontweight='bold')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('损失值')
ax1.grid(True)
ax2.plot(range(1, epochs+1), accuracies, marker='s', color='green', linewidth=2)
ax2.set_title('训练准确率曲线', fontsize=12, fontweight='bold')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('准确率 (%)')
ax2.grid(True)
plt.tight_layout()
plt.show()
# 5. 测试集准确率
model.eval()
correct = 0
total = 0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算每个类别的准确率
c = (predicted == labels).squeeze()
for i in range(len(labels)):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
print(f"\n测试集总准确率: {100 * correct / total:.2f}%")
# 打印每个类别的准确率
print("\n各类别准确率:")
for i in range(10):
print(f"{classes[i]:<4}: {100 * class_correct[i] / class_total[i]:.2f}%")
# 6. 可视化部分测试样本及预测结果
model.eval()
examples = enumerate(testloader)
batch_idx, (example_data, example_targets) = next(examples)
example_data, example_targets = example_data.to(device), example_targets.to(device)
output = model(example_data)
_, preds = torch.max(output, 1)
# 将数据移回CPU用于显示
example_data_cpu = example_data.cpu()
example_targets_cpu = example_targets.cpu()
preds_cpu = preds.cpu()
plt.figure(figsize=(12, 6))
for i in range(16): # 显示16个样本
plt.subplot(4, 4, i+1)
# CIFAR-10图像需要反归一化才能正确显示
img = example_data_cpu[i].numpy().transpose(1, 2, 0)
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
img = std * img + mean
img = np.clip(img, 0, 1)
plt.imshow(img)
color = 'green' if preds_cpu[i] == example_targets_cpu[i] else 'red'
plt.title(f"真: {classes[example_targets_cpu[i]]}\n预: {classes[preds_cpu[i]]}",
fontsize=9, color=color)
plt.axis('off')
plt.suptitle('CIFAR-10 CNN预测结果 (绿色=正确, 红色=错误)', fontsize=12, fontweight='bold')
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()结果输出:

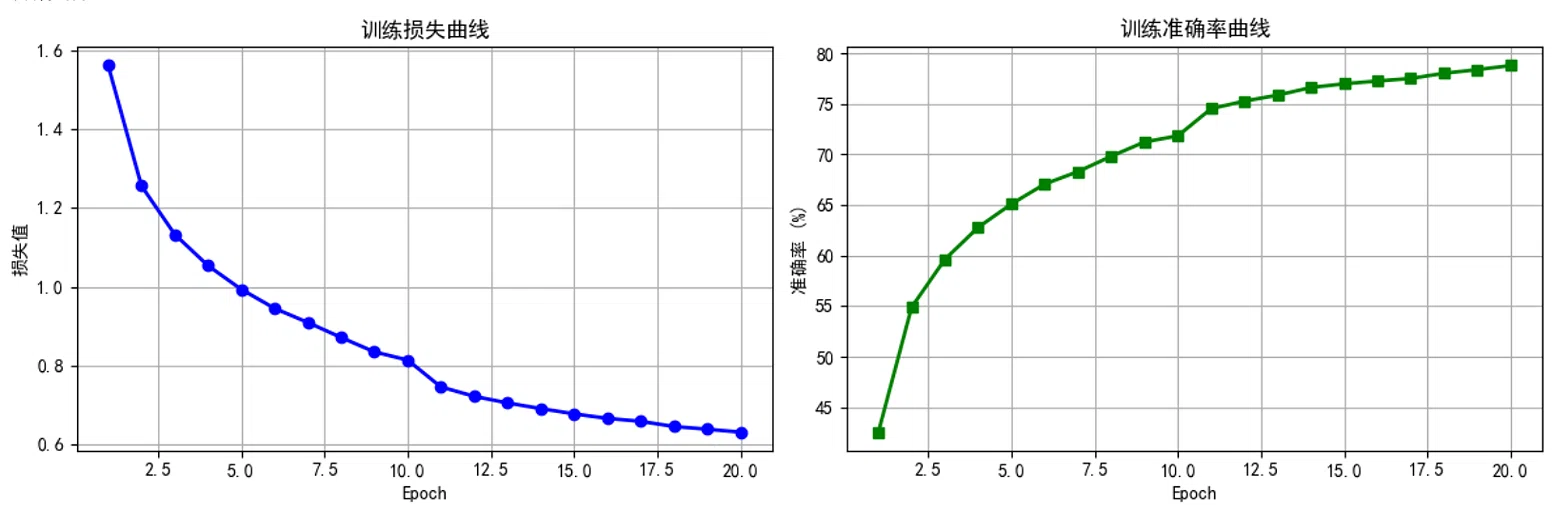
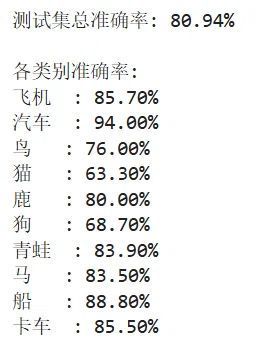

通过结果可以看出,本次运行的CNN模型在CIFAR-10彩色图像分类任务上表现良好:经过20个epoch的训练,训练损失从1.56稳步下降至0.63,训练准确率从42.5%提升至78.8%,整个过程收敛平稳、无过拟合迹象;最终在测试集上取得了80.94%的准确率,其中对汽车(94.0%)、船(88.8%)、飞机(85.7%)等特征鲜明的类别识别效果优秀,而对猫(63.3%)和狗(68.7%)这类纹理多变、形态相似的动物分类相对困难。该结果说明,采用批归一化、Dropout和数据增强的轻量级CNN能够有效处理CIFAR-10这类中等复杂度的彩色图像分类任务,其性能已显著超越简单baseline,接近更复杂网络的下限水平。
使用matplotlib简要的画出本次CNN的网络结构:
参考资料
http://www.uml.org.cn/ai/202503074.asp
https://zhuanlan.zhihu.com/p/561991816

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)