Agent 记忆机制到底怎么理解?从短期记忆、长期记忆到记忆压缩。
一、前言:为什么 Agent 需要“记忆”?
最近在学习 Agent 架构时,我发现一个很容易混淆的问题:
Agent 的记忆到底是什么?
是不是把历史聊天记录放进 prompt 里就行?
长期记忆存到向量数据库里,那和 RAG 又有什么区别?
一开始我以为 Agent 记忆就是“保存历史对话”,但深入理解后发现并不是这么简单。
在普通 LLM 对话中,大模型本身是没有真正持久记忆的。它每次回答问题,本质上都是根据当前输入的上下文进行推理。也就是说,模型能“记住”什么,取决于你这次请求时给它传了什么。
而 Agent 不一样。
Agent 往往需要完成多轮任务,例如:
-
记住用户前面说过的目标;
-
保存任务执行过程中的中间结果;
-
根据历史信息调整后续计划;
-
在上下文太长时进行总结压缩;
-
从外部数据库中检索过去的重要经验。
所以,Agent 的记忆机制,本质上是为了让 Agent 在多轮任务中具备更强的连续性和稳定性。
二、先理解一个核心前提:短期记忆受上下文窗口限制
Agent 的短期记忆,最直观的实现方式就是:
把历史对话、任务状态、中间结果继续放进下一次 prompt 里。
比如用户第一次说:
我要做一个基于 Spring AI 的 RAG 项目。
Agent 回复并记录:
用户想做一个基于 Spring AI 的 RAG 项目。
下一轮用户继续问:
那这个项目怎么加 Agent 能力?
如果系统把上一轮信息一起带给大模型,大模型就能知道“这个项目”指的是前面说的 Spring AI RAG 项目。
这就是短期记忆最基本的实现方式。
但是这里有一个问题:上下文窗口是有限的。
比如一个模型最多只能处理 128K token,并不代表我们可以无限塞历史记录。因为:
-
历史消息越多,成本越高;
-
无关信息越多,模型越容易分心;
-
上下文太长,关键信息可能被淹没;
-
超过窗口限制后,旧消息必须被裁剪。
所以,短期记忆通常不会无限保存,而是会采用类似“滑动窗口”的方式。
三、短期记忆常见实现:滑动窗口
滑动窗口可以理解为:
只保留最近 N 轮对话,太早的内容先丢掉或总结。
例如:
最近 5 轮对话:
1. 用户上传了项目代码
2. Agent 分析了用户模块
3. 用户追问 JWT 实现
4. Agent 分析 token 和 refreshToken
5. 用户继续问 Bearer 的作用
下一轮请求时,只把最近几轮对话传给模型。
对应到项目里,可能会用类似这样的结构保存:
Map<String, List<Message>> conversationMemory = new ConcurrentHashMap<>();
每个用户一个历史对话列表:
conversationMemory.put(userId, messages);
每次请求时:
List<Message> history = conversationMemory.get(userId);
history.add(new UserMessage(userInput));
if (history.size() > maxWindowSize) {
history.remove(0);
}
这样就能保证 Agent 记得最近发生的事情,但不会让上下文无限增长。
不过,滑动窗口也有问题。
比如用户很早之前说过:
我现在是 Java 后端方向,想往 AI Agent 工程师转。
如果这句话被滑动窗口裁掉了,Agent 后面可能就不知道这个长期背景了。
这时候就需要长期记忆。
四、长期记忆:不放在 prompt 里,而是存到外部系统中
长期记忆不是每次都全部塞进 prompt,而是通常存到外部存储系统里。
常见存储方式包括:
| 记忆类型 | 常见存储 |
|---|---|
| 用户偏好 | MySQL、Redis、MongoDB |
| 长期背景 | MySQL、文档库 |
| 语义记忆 | 向量数据库 |
| 任务经验 | 向量数据库 + 结构化数据库 |
| 工具调用结果 | Redis、MySQL、日志系统 |
比如 Agent 发现用户长期关注:
Java 后端转 AI Agent 工程师
Spring AI
RAG
Multi-Agent
AIOps 项目
简历优化
CSDN 学习总结
这些信息就可以作为长期记忆存储起来。
后续用户说:
帮我写今天的 CSDN。
Agent 就可以根据长期记忆知道:
-
用户喜欢写 AI Agent 学习总结;
-
用户希望文章适合 CSDN 发布;
-
用户希望有摘要、标题、正文、层次感;
-
用户最近在学习 Agent 记忆机制和 Multi-Agent。
这就不是简单的“聊天记录”,而是从长期信息中提取出的用户画像和学习上下文。
五、长期记忆和 RAG 有什么区别?
这个问题很关键。
我一开始也觉得:
长期记忆存到向量数据库里,用的时候再检索出来,这不就是 RAG 吗?
从技术链路上看,确实很像。
RAG 的流程是:
用户问题 → 向量化 → 检索知识库 → 拼接上下文 → 发送给 LLM
长期记忆的流程也可能是:
用户问题 → 向量化 → 检索用户记忆 → 拼接上下文 → 发送给 LLM
所以从实现机制上看,长期记忆确实可以借用 RAG 的方式。
但是它们的区别在于:存的内容不一样,使用目的也不一样。
| 对比点 | RAG 知识库 | Agent 长期记忆 |
|---|---|---|
| 存储内容 | 文档、资料、业务知识 | 用户偏好、历史任务、经验、状态 |
| 目标 | 补充外部知识 | 维持个性化和任务连续性 |
| 数据来源 | 用户上传文档、企业知识库 | 对话、行为、执行结果 |
| 使用场景 | 问文档、查资料、知识问答 | 记住用户目标、偏好、长期上下文 |
举个例子。
RAG 里存的是:
Spring AI 中 ChatClient 是对 ChatModel 的高级封装。
Agent 记忆里存的是:
用户正在学习 Spring AI,并且希望从 Java 后端转向 Agent 工程师。
前者是知识,后者是用户上下文。
这就是二者最大的区别。
六、什么是记忆压缩?
记忆压缩,也可以叫 Memory Compression。
它的核心目的不是“删除记忆”,而是:
在上下文窗口有限的情况下,把大量历史信息压缩成更短、更重要的摘要。
比如一段很长的对话:
用户先问了 Agent 的定义,
然后问了大模型和 Agent 的区别,
接着问了 ReAct、Plan-and-Execute,
又问了 Workflow 和 Agent 的区别,
最后开始研究 Agent 记忆机制。
如果每次都把完整聊天记录传给模型,会非常浪费 token。
所以可以压缩成:
用户正在系统学习 Agent 架构,已理解 Agent 与大模型的区别,
关注 ReAct、Plan-and-Execute、Workflow、工具调用和记忆机制,
希望将这些内容整理成适合 CSDN 和面试表达的学习总结。
这样原本几千字的历史记录,就被压缩成了几十字。
这就是记忆压缩。
七、记忆压缩和短期记忆是什么关系?
记忆压缩通常是配合短期记忆使用的。
可以这样理解:
短期记忆:保存最近发生的具体细节
记忆压缩:把更早的历史内容总结成摘要
长期记忆:把重要信息持久化保存
例如一个 Agent 的上下文可以由三部分组成:
系统提示词
+ 长期记忆检索结果
+ 历史对话摘要
+ 最近几轮完整对话
+ 当前用户问题
也就是:
Prompt = System Prompt
+ Retrieved Long-term Memory
+ Conversation Summary
+ Recent Messages
+ Current User Input
这就是一个比较典型的 Agent 记忆拼接方式。
八、单层记忆:只保存最近对话
单层记忆是最简单的 Agent 记忆架构。
它只有一层:
最近对话记录
结构大概是:

这种方式的优点是简单,适合入门项目。
比如一个普通聊天助手,可以只用:
Map<String, List<Message>> memory = new ConcurrentHashMap<>();
每个用户保存最近几轮消息即可。
优点:
-
实现简单;
-
不需要数据库;
-
适合 Demo 和简单问答;
-
对代码侵入小。
缺点:
-
服务重启后记忆丢失;
-
无法保存长期偏好;
-
上下文过长后必须裁剪;
-
不适合复杂任务型 Agent。
所以单层记忆更像是“临时会话记忆”。
九、双层记忆:短期记忆 + 长期记忆
双层记忆就更接近真实 Agent 项目了。
它一般包括:
短期记忆:最近对话、当前任务状态
长期记忆:用户偏好、历史经验、长期背景
结构可以理解为:
这里有一个关键点:
不是所有内容都要写入长期记忆。
比如用户随口说:
今天天气不错。
这没有必要长期保存。
但如果用户说:
我以后写 CSDN 都希望先有摘要,再有正文,再有封面图提示词。
这就适合写入长期记忆。
因为它会影响未来的回答方式。
双层记忆的核心在于:
-
最近发生的事情放短期记忆;
-
长期稳定的信息放长期记忆;
-
当前请求时,根据问题检索相关长期记忆。
这种结构就已经很像真实 Agent 应用了。
十、三层记忆:工作记忆 + 短期记忆 + 长期记忆
三层记忆会更细一些,常见划分是:
工作记忆 Working Memory
短期记忆 Short-term Memory
长期记忆 Long-term Memory
它们的区别可以这样理解:
| 记忆层级 | 作用 | 示例 |
|---|---|---|
| 工作记忆 | 当前任务执行中的临时状态 | 当前计划、工具调用结果、中间变量 |
| 短期记忆 | 最近几轮对话 | 用户刚刚问了什么,Agent 刚刚回答了什么 |
| 长期记忆 | 持久化的重要信息 | 用户偏好、历史项目、长期目标 |
举个具体例子。
用户让 Agent 分析一个项目:
你帮我分析这个 RAG 项目,并告诉我怎么写进简历。
Agent 可能会有三类记忆。
1. 工作记忆
当前任务中的临时状态:
当前目标:分析 RAG 项目并提炼简历表达
已完成:分析用户模块
待完成:分析聊天助手模块、文件解析模块、检索模块
工具结果:读取到项目中使用 Elasticsearch 做混合检索
这类信息只对当前任务有用。
任务结束后,不一定要长期保存。
2. 短期记忆
最近对话内容:
用户刚才问了 Elasticsearch 是否可以当向量数据库;
用户又追问了 BM25 和混合检索的关系;
用户希望简历表达不要太像模板。
这些信息用于保持当前对话连续性。
3. 长期记忆
稳定背景:
用户是 Java 后端方向,正在准备实习简历;
用户希望突出 AI Agent、RAG、Multi-Agent 项目经验;
用户喜欢把学习过程整理成 CSDN 文章。
这些信息适合长期保存。
十一、三层记忆在项目中怎么实现?
如果用 Java / Spring AI 的思路,可以大致设计成这样:
MemoryManager
├── WorkingMemory
├── ShortTermMemory
└── LongTermMemory
伪代码结构:
public class MemoryManager {
private final WorkingMemory workingMemory;
private final ShortTermMemory shortTermMemory;
private final LongTermMemory longTermMemory;
public AgentContext buildContext(String userId, String userInput) {
List<Message> recentMessages = shortTermMemory.getRecentMessages(userId);
List<Memory> relatedMemories = longTermMemory.search(userId, userInput);
TaskState taskState = workingMemory.getCurrentTaskState(userId);
return new AgentContext(
taskState,
relatedMemories,
recentMessages,
userInput
);
}
public void updateAfterResponse(String userId, String userInput, String answer) {
shortTermMemory.addMessage(userId, userInput, answer);
if (shouldSaveToLongTerm(userInput, answer)) {
longTermMemory.save(userId, extractMemory(userInput, answer));
}
}
}
然后在调用大模型前构造 prompt:
AgentContext context = memoryManager.buildContext(userId, userInput);
String prompt = promptBuilder.build(
context.getTaskState(),
context.getRelatedMemories(),
context.getRecentMessages(),
context.getCurrentInput()
);
String answer = chatClient.prompt()
.user(prompt)
.call()
.content();
memoryManager.updateAfterResponse(userId, userInput, answer);
这样 Agent 就不是只会“单轮问答”,而是具备了状态管理能力。
十二、记忆系统和 Agent 执行流程的关系
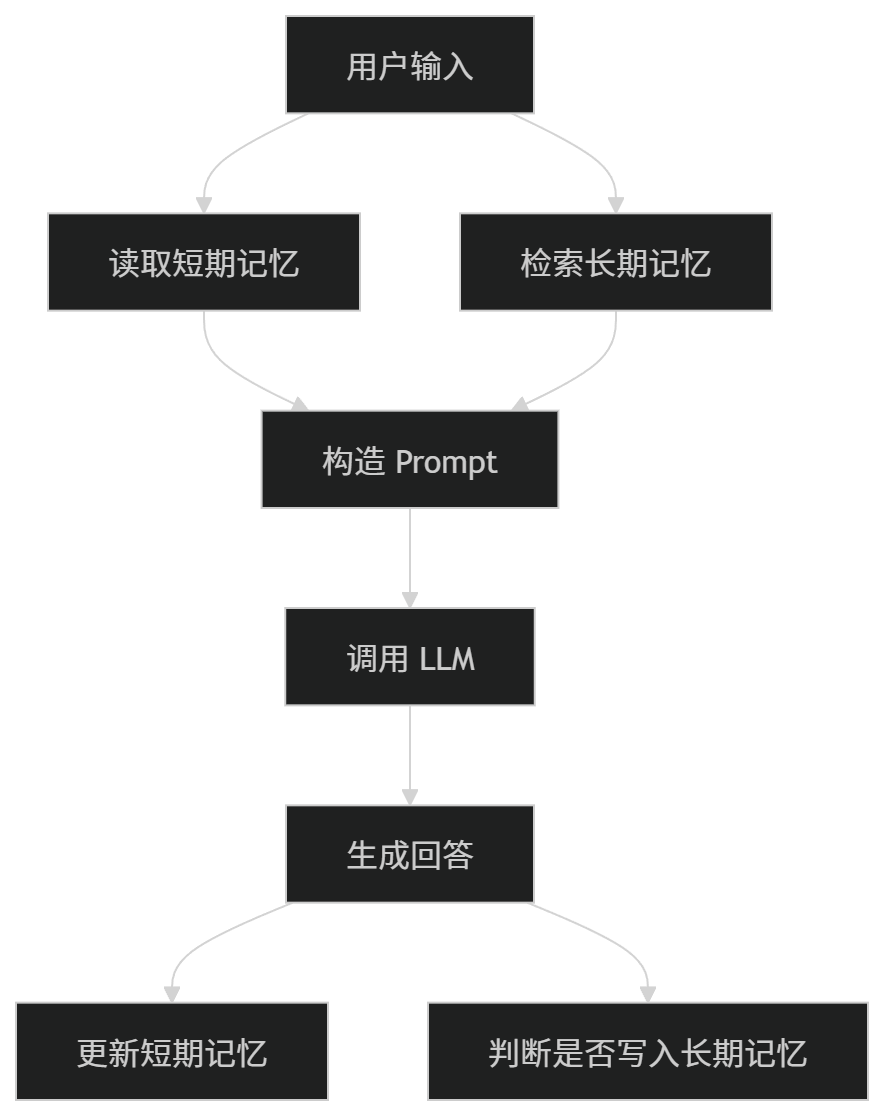
Agent 的完整执行流程可以这样理解:

这里的记忆既参与任务开始,也参与任务结束。
任务开始时,Agent 需要读取记忆:
我以前和这个用户聊过什么?
用户当前目标是什么?
有没有和当前问题相关的历史信息?
任务结束时,Agent 需要更新记忆:
这次任务产生了什么重要结论?
用户有没有新的偏好?
有没有值得长期保存的经验?
所以记忆不是一个孤立模块,而是贯穿 Agent 执行全过程的能力。
十三、记忆不是越多越好,而是越准越好
很多人一开始会觉得:
Agent 记忆越多越智能。
但实际项目中不是这样。
记忆太多会带来几个问题:
1. 噪声问题
如果什么都记,长期记忆会越来越乱。
比如把用户所有闲聊都存进去,后面检索时可能召回无关内容,反而干扰模型判断。
2. 隐私和安全问题
有些内容不应该长期保存,尤其是敏感信息。
3. 检索质量问题
长期记忆存到向量库后,后续能不能召回正确内容,取决于:
-
切分粒度;
-
embedding 模型质量;
-
相似度算法;
-
topK 设置;
-
是否有重排序;
-
是否有标签过滤。
这和 RAG 项目里的知识库检索很像。
4. 更新问题
用户偏好可能变化。
比如用户以前说:
我只学 Java 后端。
后来又说:
我现在想往 AI Agent 工程师发展。
那么长期记忆也要能更新,而不是一直保留旧信息。
所以 Agent 的记忆系统不只是“保存”,还要考虑:
写入什么?
什么时候写?
怎么检索?
怎么压缩?
怎么删除?
怎么更新?
这才是难点。
十四、我对 Agent 记忆机制的理解
现在我对 Agent 记忆机制的理解是:
Agent 记忆不是大模型自己真的记住了什么,而是系统在大模型外部构建了一套信息管理机制,把历史对话、任务状态、用户偏好、工具结果等内容按不同层级保存,并在需要时重新组织进上下文中,让模型表现得像“记得”。
也就是说,记忆机制本质上是工程能力。
它不是单独靠模型完成的,而是由下面这些部分共同构成:
Prompt 设计
+ 上下文拼接
+ 滑动窗口
+ 摘要压缩
+ 数据库存储
+ 向量检索
+ 记忆筛选
+ 记忆更新
大模型只是负责理解和生成,真正让它具备连续性的,是外部系统对上下文的组织能力。
十五、总结
Agent 的记忆机制可以分成几个层次理解。
第一,短期记忆通常依赖上下文窗口,把最近几轮对话放入 prompt 中,让模型保持当前对话连续性。
第二,短期记忆不能无限增长,所以需要滑动窗口和记忆压缩,把旧的历史内容总结成更短的摘要。
第三,长期记忆通常存储在外部数据库中,比如 MySQL、Redis、MongoDB 或向量数据库,需要时再检索出来参与回答。
第四,长期记忆和 RAG 的技术链路很像,但存储内容和使用目的不同。RAG 存的是外部知识,Agent 长期记忆存的是用户偏好、历史任务和经验上下文。
第五,真实项目中可以设计单层、双层、三层记忆架构。单层适合简单聊天,双层适合普通 Agent,三层更适合复杂任务型 Agent。
最后,Agent 的记忆不是越多越好,而是要做到:
该记的记住,
不该记的不记,
需要时能找回来,
太长时能压缩,
过期时能更新。
这才是一个真正可用的 Agent 记忆系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)