从零搭建零成本本地 AI Agent:Hermes + Ollama 全流程
最近后台私信集中在两个问题上:
一个是「Hermes Agent 太费 token 了」。对话一长、工具一多,账单涨得比进度还快,很多人刚把流程跑通,就开始心疼 API 费用。
另一个更现实:「我的环境根本不能连外网」。在公司内网、实验室隔离网、甚至某些政企/金融场景里,能不能用、合不合规,第一道门槛就是离线可用、数据不出网。
所以这篇教程我想把话说得更直接一点——
你照着做完,就能在自己的电脑上跑起一个完全本地的 AI Agent:
有记忆、能调用工具、能持续学习技能,而且不花一分钱 API 费用。
断网也能用。数据全在本地。没有月账单。
完成后的样子
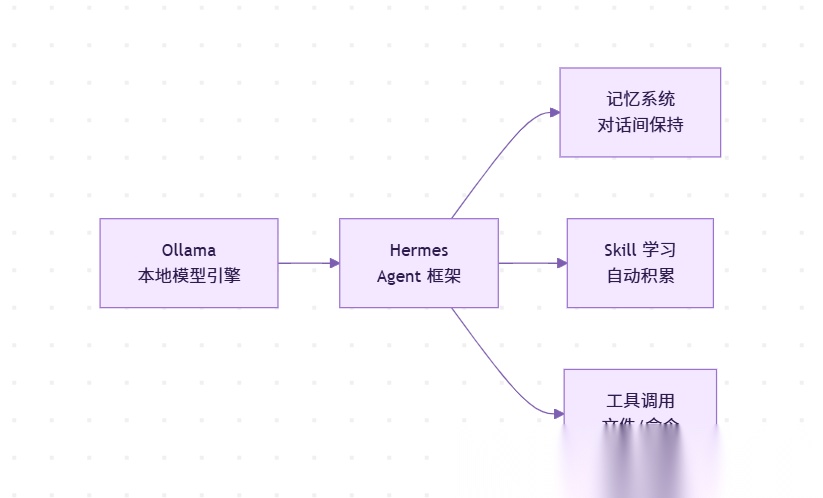
Ollama 负责跑模型。Hermes 负责当 Agent。两者配合,你得到一个免费的、有记忆的本地 AI 助手。
前提条件
- 一台电脑(macOS / Linux / WSL)
- 16GB 内存(跑 27B 模型)。8GB 也行,选 7B 模型
- 终端能跑 bash
- 不需要 GPU。有 GPU 会更快,但不是必须
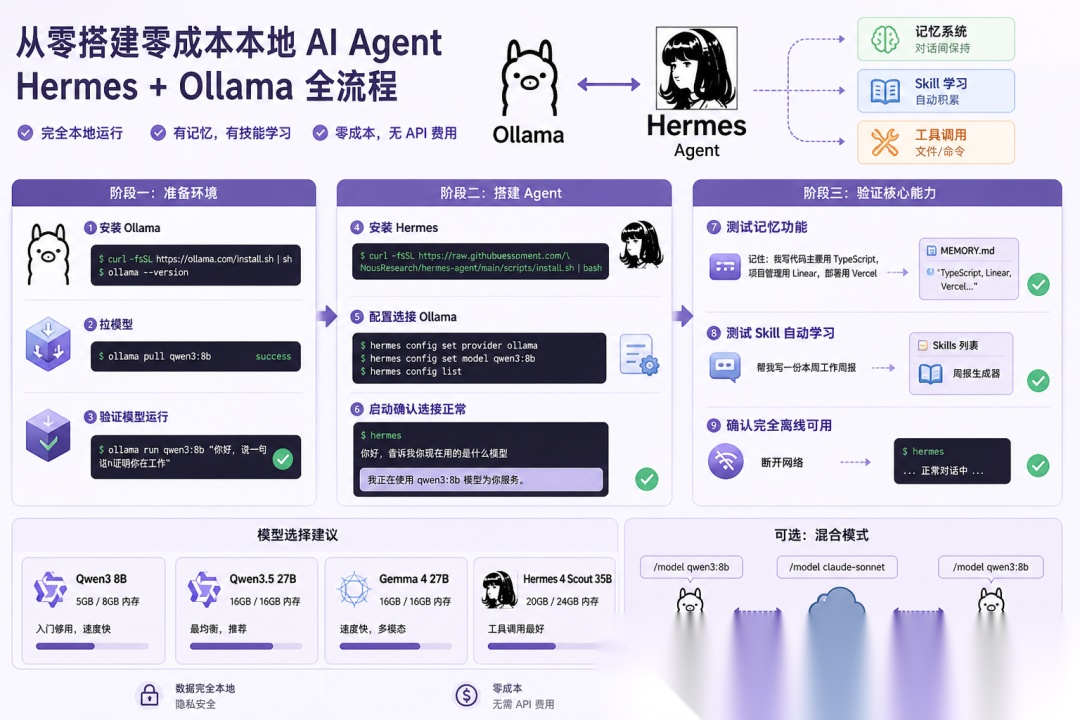
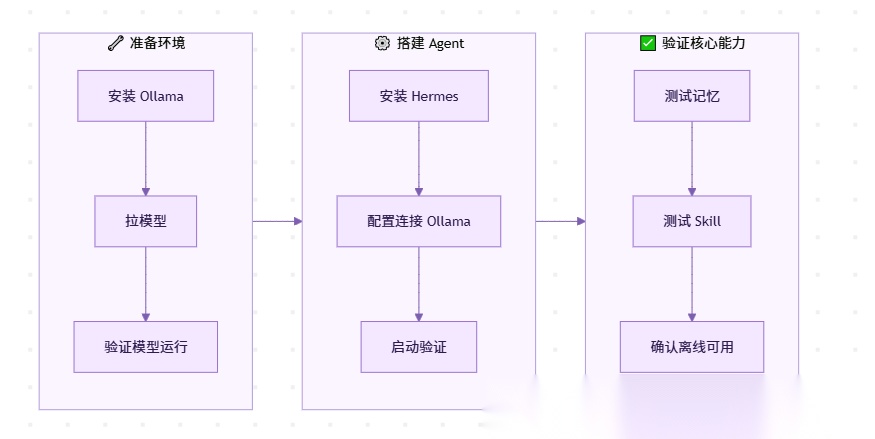
第一阶段:准备环境
第一步:安装 Ollama
Ollama 是本地模型的运行引擎。一行命令装好:
curl -fsSL https://ollama.com/install.sh | sh
装完验证一下:
ollama --version
看到版本号就对了。
macOS 用户也可以去 ollama.com[1] 下载桌面客户端。效果一样。
第二步:拉一个模型下来
模型是 Agent 的大脑。选一个拉下来:
ollama pull qwen3:8b
这是最小的选择。8GB 内存就能跑。先用这个验证流程通不通。
内存够的话,换更强的:
ollama pull qwen3.5:27b
或者:
ollama pull gemma4:27b
拉模型需要下载几个 GB。等它跑完。
完成标志:终端显示 success。
第三步:验证模型能跑
ollama run qwen3:8b "你好,说一句话证明你在工作"
看到模型回复了,说明本地推理引擎没问题。
按 Ctrl+D 退出。
第二阶段:搭建 Agent
第四步:安装 Hermes
Hermes 是 Agent 框架。装上它,本地模型才能变成有记忆、有技能的 Agent。
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
装完看到版本信息就行。
如果提示需要重新加载 shell:
source ~/.bashrc
或者关掉终端重新开一个。
第五步:配置 Hermes 连接本地 Ollama
第一次运行 hermes 会进入配置向导。
hermes
向导会问你用哪个 provider。选 Ollama。
它会问模型名称。填你刚才拉的那个:
qwen3:8b
或者 qwen3.5:27b,取决于你拉了哪个。
如果错过了向导,手动配置:
hermes config set provider ollamahermes config set model qwen3:8b
验证配置:
hermes config list
看到 provider 是 ollama,model 是你选的那个,就对了。
第六步:启动 Hermes,确认连接正常
hermes
进入对话界面后,说一句:
你好,告诉我你现在用的是什么模型
Hermes 正常回复,没有报错,说明本地 Agent 已经跑起来了。
到这里,零成本本地 AI Agent 已经搭好了。下面验证它的核心能力。
第三阶段:验证核心能力
第七步:测试记忆功能
在对话里告诉它一个偏好:
记住:我写代码主要用 TypeScript,项目管理用 Linear,部署用 Vercel
等它确认。然后退出:
/exit
重新启动 Hermes:
hermes
问它:
我平时用什么语言写代码?
它能回答出 TypeScript,说明记忆在跨会话保持。
想看记忆文件长什么样:
cat ~/.hermes/MEMORY.md
你的偏好应该已经写在里面了。
第八步:测试 Skill 自动学习
给它一个有结构的重复任务。我用的是写周报:
帮我写一份本周工作周报。内容:完成了用户认证模块重构,修复了 3 个线上 bug,参加了 2 次技术评审
让它输出一版。然后追问几轮:
格式改成 markdown 列表
``````plaintext
加上下周计划的占位符
``````plaintext
开头加一句一行总结
多聊几轮。Hermes 会在内部评估这段对话是否值得保存为 Skill。
过一会儿查看:
hermes skills list
如果列表里出现了和周报相关的 Skill,说明自动学习在工作。
下次你再说「帮我写周报」,它会直接用学到的格式。
第九步:确认完全离线可用
断开网络。关掉 Wi-Fi 或者拔网线。
hermes
``````plaintext
帮我写一个 TypeScript 函数,输入是日期字符串,输出是距今天数
能正常回答。说明整个系统完全本地运行。不依赖任何云服务。
重新连上网络。
可选:混合模式
简单任务走本地,复杂任务切云端。两全其美。
在 Hermes 对话中:
/model claude-sonnet
切到云端模型处理复杂任务。处理完再切回来:
/model qwen3:8b
日常问答、代码补全、格式化,本地模型够用。架构设计、长文写作、复杂推理,切云端。
这样一个月的 API 费用可能只有几块钱。
完整流程一览
模型选择建议
| 模型 | 大小 | 内存需求 | 特点 |
|---|---|---|---|
| Qwen3 8B | 5GB | 8GB | 入门够用,速度快 |
| Qwen3.5 27B | 16GB | 16GB | 最均衡,推荐 |
| Gemma 4 27B | 16GB | 16GB | 速度快,多模态 |
| Hermes 4 Scout 35B | 20GB | 24GB | 工具调用最好,需要更多显存 |
第一次建议从 8B 开始。跑通流程再换大模型。
第一次做的建议
- 先用 8B 小模型走完全部步骤。确认流程通了再换 27B。省得下载半天发现内存不够
- 第五步配置最容易卡。如果向导没出来,用
hermes config set手动配 - 第七步测记忆时,说得具体一点。「记住我喜欢简洁风格」比「记住我的偏好」更容易被正确存储
容易踩的坑
**Ollama 服务没启动,Hermes 连不上。**因为 Ollama 需要后台运行。Linux 上用 systemctl start ollama。macOS 上打开 Ollama 桌面客户端就行。
**模型太大,推理巨慢。**因为内存不够,模型在用 swap。换小一号的模型。或者加内存。ollama ps 能看当前模型占用。
**Hermes 报错找不到模型。**因为配置里的模型名和 Ollama 里的不一致。用 ollama list 看实际名称,确保和 hermes config 里的一模一样。
**记忆没保存。**因为对话太短。Hermes 需要足够的上下文才会触发记忆写入。多聊几轮,或者明确说「请记住这个」。
**Skill 没自动生成。**因为任务太模糊。Skill 学习需要有明确输入输出的结构化任务。「帮我想想」不行,「帮我把这段文字转成 markdown 表格」可以。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)