写给普通人的AI_Token深度指南:从看懂账单到理解Embedding
你有没有遇到过这种情况:让AI帮你总结一篇几万字的长文,聊到后面,它却“忘”了你一开始设定的角色?或者查看API账单时,发现用中文提问的花费,竟然比英文高出一截?
这些体验的背后,都藏着一个共同的概念——Token。它是AI阅读和生成文本的最小单元,决定了你的使用成本、AI的“记忆”容量,甚至生成内容的质量。
但Token远不止“计费单位”这么简单。为什么同一个意思,中文比英文费Token?AI是怎么把一句人话,拆成一堆它能看懂的“积木”的?更进一步,这些积木是如何被赋予意义的?
这篇文章,就是为你准备的。我会带你先从看懂账单开始,一步步走进分词原理(BPE)和语义向量(Embedding)的大门。不管你是普通用户还是想深入一点的技术爱好者,都能在这里找到答案。
同一句话,为什么中文更“贵”?
你有没有看过你所使用AI大模型的账单?
当你兴奋地体验完最新的AI大模型,打开后台账单,却盯着那行“Token消耗量”愣了几秒。同样的对话,用中文提问和用英文提问,花费竟然不一样。更直观一点——假设你分别用中文和英文让AI帮你写一封相同意思的商务邮件,结果发现,中文输出的成本有时是英文的好几倍。
这不是错觉。我们来做个小实验。
分别向AI输入下面两句话,它们的意思几乎完全一致:
- 英文:
"I love artificial intelligence" - 中文:
“我爱人工智能”
如果不看账单,你会觉得中文只有6个字,英文足足有3个单词加空格,英文应该更长更贵,对吧?但真实的Token消耗可能是:
英文:["I", " love", " artificial", " intelligence"] → 4个Token中文:["我", "爱", "人工智能"]或更细的["我", "爱", "人工", "智能"]→ 3-4个Token,甚至更多
在这个极短例子里,差距还不明显。让我们把它放大到日常使用中。一段几百字的英文,可能被拆成几百个Token;而同样意思的中文,因为汉字的信息密度高,每个字都可能独立成Token,或者被切成更小的子词单元,最终Token数轻松超过英文的1.5到2倍。一篇万字长文的中文翻译,Token成本陡增,这会直接反映在你的API账单上,也影响着你使用次数的上限。
问题来了:AI为什么不能像我们一样,按“词”或者“字”来计费?它到底在背后把我们的语言切成了什么?
答案就是 Token。它不是单词,不是字母,更不是汉字——它是AI阅读和理解世界的“标准积木块”。而在这个世界里,英文的一块积木,往往比中文的一块积木要“大”,承载的意思更多。这就好比同样搭建一个“城堡”,用中文积木,你得花更多块,自然就更贵。
那么,凭什么英文就能用大积木,中文就得碎成渣?这个“智能切块机”到底是怎么工作的?它在切的时候,凭什么知道“人工智能”有时候是一块,有时候又得拆开?
要解释清楚这笔“糊涂账”,我们就不得不钻进AI的底层逻辑,去看看那个决定了你账单高低、记忆长短、甚至AI聪明程度的核心机制。从下一节开始,我会先给你一个关于Token的最直观画像,然后逐步深入它的两大灵魂:分词原理(BPE) 和 语义坐标(Embedding)。
系好安全带,让我们准备出发。
Token是什么?
上一节有一个问题:为什么AI处理中英文的成本不一样?为什么它不能按我们熟悉的“词”或“字”来算账?
答案就是:Token。
那到底什么是Token?
一句话定义
Token是AI模型阅读、理解和生成文本时的最小基本单位。
注意,我刻意避开了“单词”和“汉字”这两个词。因为Token既不是前者,也不是后者。它是一个完全独立的、属于AI自己的度量衡。
想象一台“智能切菜机”
如果这个概念还是有点抽象,我们来做一个小实验。假设你有一句简单的话:
“今天天气真不错。”
当你把它递给一个AI模型时,它做的第一件事,不是像人一样逐字阅读,而是把这整句话扔进一台 “智能切菜机”。一阵操作之后,你得到了一盘被切成固定形状的“食材块”:
["今天", "天气", "真", "不错", "。"]
每一个小块,就是一个 Token。
你可能会问:凭什么“不错”是一个块,而“真”和“。”是单独的两块?为什么不能把“天气真”切在一起?
这就是“智能”切菜机厉害的地方——它不是简单地按标点符号切,也不是把每个字都拆开,而是根据一套它自己从海量文本中学到的统计学规则,来决定哪里下刀。这套规则,在技术圈有一个正式的名字,叫做 分词算法(我们第三节会详细拆解它的核心原理)。
如果你觉得“切菜机”还不够直观,我们换一个更形象的比喻:乐高积木。
想象整个语言世界就是一个巨大的乐高模型展览。每一句话、每一篇文章、每一本书,都是不同的乐高成品。
Token,就是用来搭建这些成品的最小、最标准的乐高积木块。
有些积木块比较大,本身就构成了一个完整的意思单元,比如 "apple" 这个Token,它自己就是一块完整的积木,代表“苹果”这个概念。有些积木块则很小,甚至只是一个标点符号,比如 "。" 或 "!",但它们同样是必不可少的连接件。
AI模型手里有一个固定的“积木盒”,里面装着大约几万个不同形状的标准积木块(这个数量就是传说中的“词表大小”)。无论你给它什么文本,它都会把这段文本拆解成它盒子里已有的积木组合。它不认识“词语”或“字”,它只认识自己的积木。
回到那个让你困惑的现象
现在,我们重新看看第一节留下的问题:为什么中文比英文“贵”?
用积木的比喻,答案瞬间就清晰了:
- 英文,大量常用单词本身就是一整块积木。比如
"love"是一块,"artificial"是一块。一块积木就携带了比较完整的意思。 - 中文,积木块往往更碎。比如“爱”通常是一块,“人工智能”有时会被切成“人工”+“智能”两块,甚至在某些更细颗粒度的模型里,“智”和“能”都各算一块。
这就好比你用乐高搭建同一个建筑模型。英文版的图纸要求你使用少量、大块的积木;中文版的图纸呢,同样的建筑却需要你用更多、更小块的标准件去拼装。
结果是:描述完全相同的含义,中文往往需要更多块的积木。而AI的收费方式,正是按你消耗的积木块数量来计算的。你的账单,当然就更贵。
Token绝对不等于什么?
在继续深入之前,让我们先排掉几个最常见的认知地雷:
- Token ≠ 单词。
"unbelievable"这个单词可能被切成["un", "believe", "able"]三个Token。 - Token ≠ 汉字。 “北京烤鸭”可能被切成
["北京", "烤鸭"]两个Token,而不是四个字。 - Token ≠ 字符。 一个字母
"a"是一个Token吗?有时候是,但更多时候"apple"是整个作为一个Token,而不是拆成a, p, p, l, e。
Token只等于一件事:模型词表里的一条标准条目。 它有时大有时小,完全由训练出它的语料和算法决定,不以人的直觉为转移。
说的再多不如上手试试
到这里,你可能已经有点手痒,想看看自己平时说的话,在AI眼里究竟是几块积木。
给大家一个可以直接上手的神器:OpenAI Tokenizer(直接搜索即可,是官方提供的免费可视化工具,当然如果访问不了,就需要使用一些“魔法”了)。
你把任何一段中文或英文粘进去,它会用不同颜色标出来:每块积木的边界在哪里,一共有多少块。你会直观地看到我们刚才描述的一切——有的词是一整块,有的词则被切得七零八落。
例如:
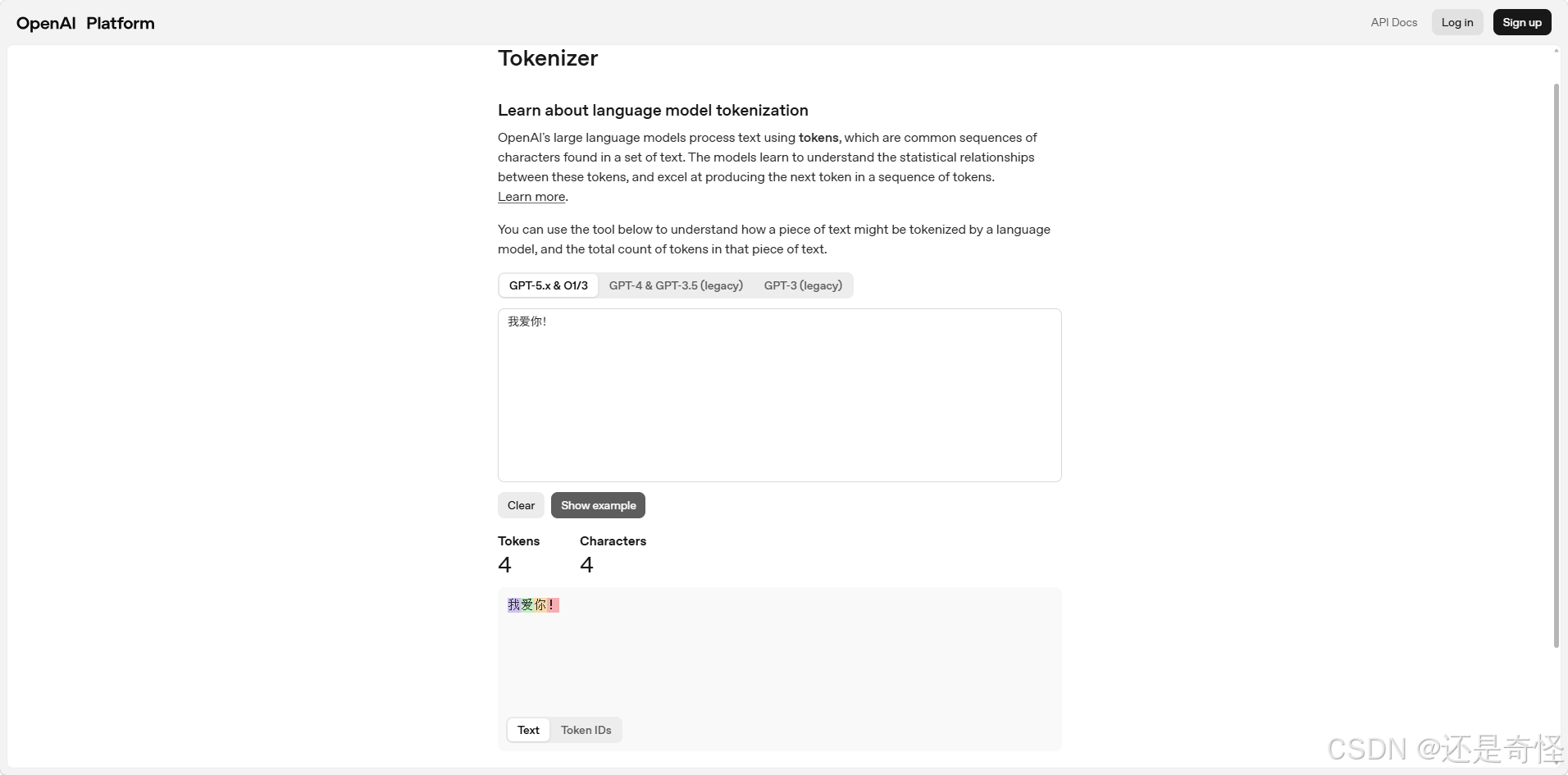
他还可以查看 Token IDs:
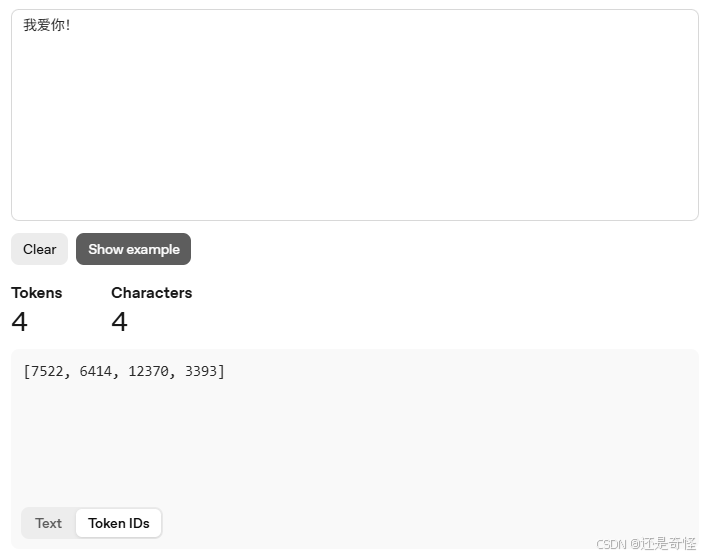
是不是很惊喜,快去试试看,那种“原来如此”的感觉,会比你读十遍理论都来得扎实。
热知识:
- 英文:1个单词 ≈ 0.75 个 Token。 所以一段100词的英文,大约消耗130个Token。
- 中文:1个汉字 ≈ 1.5-2个Token。 具体看文本类型——口语化短句偏少,书面语、成语、专业术语组合偏多。一段500字的文章,大约消耗750-1000个Token。
BPE分词原理拆解
现在,我们已经知道了Token就是积木块,AI用它们来搭建一切文本。但一个更深层的问题自然浮现了出来:
这把刀握在谁手里?那个“智能切菜机”的判断规则,到底是怎么来的?为什么同一个“不错”,有时候被当成一块积木,有时候被拆开?
这就是我们下一个要深入的核心——分词原理。AI是如何从零开始,自己学会“怎么切”的。它是怎么不靠任何人类的语法,只靠一套叫 BPE(字节对编码) 的算法,就从浩如烟海的文本中,自动摸索出了最优的切割方案。
而这,恰恰是整个Token大厦真正奠基的地方。
BPE(Byte Pair Encoding,字节对编码)
这是目前绝大多数大语言模型分词器的核心思想。我们不需要写一行代码,只需要听一个故事,就能看懂它到底在干什么。
在设计“怎么切文本”这个方案时,工程师们首先面对的是一个两难选择。
方案一:把每个单词都当成一块积木。
这样的话,AI的词表里就需要装上世界上所有的单词。英语单词至少几十万个,中文词组更是无穷无尽。一旦遇到一个词表里没有的生词——比如一个罕见的人名、一个网络新梗——AI就会当场卡壳。而且,“run”和“running”会被当成完全无关的两块积木,AI无法理解它们之间的血缘关系。这条路,走不通。
方案二:把每个字符都当成一块积木。
极端一点,英文就用26个字母加标点,中文就用几千个常用汉字。这样绝不会有生词了,随便什么文本都能拼出来。但代价是,一段文本会被拉得极长。"I love you" 变成 ["I", " ", "l", "o", "v", "e", " ", "y", "o", "u"]。序列一长,AI就很难抓住词语之间的远距离关系,计算效率也会骤降。这条路,也走不远。
全用单词不行,全用字符也不行,那该怎么办
我们需要一种折中的智慧:
- 积木块的数量不能太多(否则词表爆炸,生词问题依然存在)
- 积木块的数量不能太少(否则序列太长,语义被稀释)
- 常见的词语组合,最好就是一整块积木(效率高)
- 罕见的、新出现的词,可以用更小的子积木拼接出来(泛化能力强)
这就是Token要做的事。而BPE,就是实现这种智慧的具体方法。
举个例子:
假设现在你给一个初生的AI一台时光机,把它送回婴儿时期。它的积木盒子里,一开始只装着最基础的元件:英文的26个字母加上各种标点符号,或者中文的几千个常用单字。这是它能认识的全部世界。
然后,你扔给它一整座图书馆的文本,对它说:“孩子,我只能给你最多5万块积木的名额。你要用这些有限的积木,去搭建我给你的所有文本。现在,你开始学习吧。”
AI的学习过程出奇地简单,它只反复做一件事:
- 扫描:把整个图书馆的文本全部翻一遍,统计所有“相邻积木对”一起出现的次数。
- 发现:找到出现次数最多的那一对。比如在英文中,“t”和“h”这对相邻字母出现频率极高(
the,that,this……),于是AI说:“好,‘t’和‘h’你们俩总是粘在一起,从现在起,你们合并成一块新积木,叫‘th’。” - 合并:它把整座图书馆里所有的“t”后面跟着“h”的地方,都用胶水粘成一块新积木“th”。
- 重复:现在,AI手里的积木多了一块“th”。它回到第一步,重新扫描。这一次,它发现“th”和“e”又常常在一起(
the),于是又合并出一块“the”。接着,“the”后面经常跟一个空格,于是出现了“the ”(带空格的the)……再后来,“i”和“n”合并成“in”,“in”和“g”又合并成“ing”……
这个过程会一遍又一遍地循环,成千上万次。每一次合并,AI积木盒子里的积木块就多一个。当积木盒子的数量达到你设定的上限(比如5万块)时,AI就停手了。
现在,它低头看看自己的积木盒,发现了一个惊人的事实:
- 高频词变成了大积木:像“the”、“a”、“apple”、“love”这些最常出现的词,因为它们内部的字母对总是成双成对地出现,早就在一轮轮的合并中,被胶水粘成了一整块。AI把它们当做一个整体来处理。
- 低频词被拆成了子积木:像“unfortunately”这样的长词,因为出现频率不够高,没能在竞争中拼过那些更常见的组合,所以它只被部分合并。最终被保存为
["un", "fortunate", "ly"]这几块。而“un”、“fortunate”、“ly”这些子积木,因为在别的词里也经常出现,早就稳稳地待在盒子里了。 - 生词不再可怕:这时候,你突然造了一个新词“unfriendly”,AI从来没见过它。但它能立刻拆解成
["un", "friend", "ly"]。这三块积木它都认识——它知道“un”通常表示否定,“friend”是朋友,“ly”是副词后缀。于是,尽管素未谋面,AI已经能大概猜出这个词的意思和用法(这感觉像不像英语中的词根词缀学习法)。
这就是BPE的魔法:一个完全靠统计频率、自己学会最优切割的算法。 它不需要理解任何一条语法规则,却用最简单的方式,实现了“用有限积木搭建无限语言”的目标。
所以,回到那笔“糊涂账”
现在我们可以彻底回答第一部分的那个谜题了:为什么同一个意思,中文往往比英文更“费”Token?
原因就藏在BPE的训练过程里。
英文是表音文字,字母组合成词根、前缀、后缀的规律非常固定。在BPE的合并过程中,“ing”、“tion”、“re”、“un”这些高频子词会很快被合并成一块块稳定的积木。一个完整的单词,往往就是一两块大积木拼起来的。
而中文是表意文字,每个汉字本身就是最小的意义单元。在BPE的眼里,中文的起点不是几十个字母,而是几千个常用汉字。它的合并起点更高,但常见的“词语”组合(比如“人工智能”、“机器学习”)频率远不如英文的词根组合那么稳定。于是,BPE在中文上的合并更加保守——很多词被保留为单字Token,或者只合并到双字组合就停下了。
结果是:同样表达“我爱人工智能”,英文可能是3-4块大积木,中文却需要5-6块甚至更多的小积木。积木块数多了,成本自然就上去了。
这跟你用输入法打字时的体验是类似的——输入“re”会自动联想出“revolution”,它是一个整体;但输入“人”和“工”和“智”和“能”,你得一个字一个字地选。AI的处理成本,与此同源。
眼见为实,说的再多不如试一试
我强烈建议你现在就打开 OpenAI Tokenizer 这个在线工具(搜索即可找到),把下面这些例子分别贴进去,看看色块是怎么分布的:
"unfortunately""reinforcement learning""我爱人工智能""今天天气真不错"
你会亲眼看到BPE留下的那些“缝合线”。那些被切成同一颜色的,就是一块积木;被切成不同颜色的,就是被分开的积木块。这个体验,值得你为它停留三分钟。
(注:这些词未必只有一种分法,不同的模型训练出来就有不同的分法,当然 Token IDs 也一样)
Token如何主宰你的AI体验?
前面两节,我们搞清楚了Token是什么,也看到了那把“智能切菜刀”——BPE算法——是如何一刀一刀切出这些标准积木块的。
但坦白讲,如果Token只是一个技术宅的自娱自乐,它根本不值得你花时间读到这儿。
Token真正重要的地方在于:它不是你用AI时的一个背景参数,而是那个在幕后时刻操纵你成本、记忆和对话质量的无形之手。 你以为自己在和AI聊天,实际上,你是在和一个Token计算器跳一场精密的舞蹈。
让我们把那些账单上的数字、AI突如其来的“失忆”和偶尔的胡言乱语,都摊开在Token的灯光下。
1. 决定成本:你为每一块积木买单
如果你用的是ChatGPT、Claude或者任何一个大模型的API服务,你的账单最终都可以换算成一句话:输入Token数 × 输入单价 + 输出Token数 × 输出单价。
是的,你每发送一条消息,里面每一个字、每一个标点、甚至每一个空格,都先被切成了Token,然后按块计价。而AI返回给你的那一段洋洋洒洒的回答,也同样是一个Token一个Token地从无到有生成的,生成一个,就收一个的钱。通常,输出的单价要比输入贵得多——因为生成比理解更费算力。
还记得第一部分的发现吗?“我爱人工智能”的中文Token数往往比英文更多。这不止是一句闲聊的成本差异,而是你每一次请求、每一个对话回合,都在发生的真实消耗。一个重度使用AI写作的人,一个月的中文API账单可能比英文高出50%甚至更多,根源就在于BPE给中文切了更多、更碎的积木块。
这意味着什么?你有机会通过“省积木”来省钱。 几个立竿见影的技巧:
- 精简提示词:把“请你帮我写一篇关于春天的文章,要求文笔优美、逻辑清晰、字数在800字左右”压缩成“写一篇关于春天的优美短文,800字”。在不影响意图的前提下,删掉一切装饰性短语和客套话。
- 善用英文系统提示:如果你是开发者,在编写System Prompt时,考虑用英文。许多大模型对英文的分词效率更高,同样的指令,英文可能用更少的Token表达完整。生成的输出若是中文,虽然输出端仍是按中文Token计价,但输入端的成本已经省下来了。
- 避免重复上下文:当你把同一篇长文档反复贴在每次对话里时,每次都消耗大量输入Token。尽可能使用对话历史或让模型记忆关键信息,而不是重复喂入同样的背景。
你甚至可以做个小实验:分别用啰嗦版和精简版向以前的AI问同样的问题,然后在后台对比两次消耗的Token数。数字会告诉你,AI时代的“废话文学”真的很贵。
(注:不过好消息是,随着最新一代大模型(如 GPT-4o 以及很多国产大模型)优化了针对中文的词表,现在的中文‘积木’已经被做得比以前大多了,中英文的成本差距正在逐步缩小。)
2. 决定“记忆力”:那个看不见的篮子有多大
你一定经历过这个瞬间:跟AI聊了二十轮,让它帮你润色一篇论文,回过头来你问它“我最初说的论文题目是什么?”,它一脸无辜地胡编了一个。
这不是AI存心想气你,而是它脑袋里那个装积木的篮子——上下文窗口——已经塞满了,旧积木被挤出去了。
每一个大模型都有一个最大输入Token数(也就是上下文窗口大小),比如GPT-4o是128K,Claude 3.5 Sonnet是200K,Kimi甚至打出了200万Token的招牌。你可以把这个窗口想象成一个巨大但容量有限的“临时工作台”。你和AI的整个对话历史,包括系统提示、用户消息、模型回复,全部被切成Token,一块一块地码在这个台面上。
AI每生成一个新的Token,不是基于它“记住了”你的所有过去,而是基于此刻台面上还摆放着的所有Token,去预测下一个Token。这个过程,它全神贯注于当前窗口内的内容。一旦你们的对话历史总Token数超过窗口上限,台面就会开始“裁旧迎新”——最早放上去的积木块被自动推下台面,永久消失。
这就是为什么聊到后面,AI会忘记你一开始设定的角色、你说的关键信息。不是因为它的记忆像人一样随时间和干扰而模糊,而是那段记忆对应的Token块,已经被物理地扔出了工作台。
理解这一点,你就有了两个立刻能用上的认知武器:
- 长文总结时,把核心指令放最后。 如果你希望AI总结一篇超长文档,可以把指令放在文档末尾,或者当发现AI开始“忘事”时,主动把关键背景再喂一次。因为窗口的“注意力”机制往往对最近出现的Token更敏感,且你重新喂入会把那段信息重新放到台面最上方。
- 分段处理长任务。 处理超出窗口上限的超长文本时,不要幻想AI能一口气消化全部。把任务拆成多段,每次只给一部分,手动管理“台面”。这比让模型自作主张地遗忘要可靠得多。
所以,下次你看到某款AI宣称拥有“超长上下文”,你该知道,它说的不是更聪明,而是它那个装积木的篮子,被允许做得特别大。但篮子再大,也终究是有限的,积木太多,依然会被挤掉。
3. 决定生成质量:Token接龙与雪崩效应
让我们再往深探一步。你有没有想过,AI到底是怎样“写出”一句话的?
它不是先在脑海里构思好一整段话,然后再敲出来。AI的写作,是一种Token级的接龙游戏。
给定你输入的所有Token(那些摆在台面上的积木块),模型开始计算:如果按顺序继续拼搭,下一个最可能出现的积木是哪一块? 它会给词表中几万个候选Token逐一打分,然后从高分区域中挑选一个。也许是“我”,概率最高,于是它说“我”;现在台面上的Token序列变成了“…我”,它再算下一块:很可能是“爱”,于是接上“爱”;然后是“人工”,然后是“智能”……直到它选了一块名叫“<结束>”的特殊Token,这段话才算生成完毕。
整个过程,就像你蒙住双眼,由AI在你耳边依次告诉你下一块积木该放什么。每一个新Token的诞生,都只看当下的台面——也就是之前所有已确认的Token。
这意味着,任何一步的“选择偏差”,都会导致后续所有Token的概率分布发生连锁变化。 它可能在初期只犯了一个极微小的失误,选择了一个概率稍低但仍在合理范围的Token,但这个Token将彻底改变上下文,导致后续每步的“合理选择”都发生偏移。偏差累积,越滚越大——一段看似开头的微小颠簸,最终可能让整个回答牛头不对马嘴。
这就是为什么有时AI会突然“发疯”:你让它写一篇财经分析,开头它莫名选用了一个不那么常见的观点Token,之后为了上下文自洽,它只能沿着那条路继续接龙,最终写出了一篇逻辑诡异、数据臆造的东西。这便是“雪崩效应”——一个Token的错位,滚成了整个输出的灾难。
理解Token接龙机制,也让你看懂了一个真相:AI没有真正的“创造力”,它只是在做超大规模的概率续写。 每一次让你惊叹的“妙句”,都只不过是在那个语境下,模型计算的概率分布中,恰好冒出一个你非常认可的高分Token序列罢了。
Token的“灵魂”——Embedding向量
前面的旅程,我们解决了一个大问题:Token的“形体”是怎么来的。BPE算法像一位勤劳的工匠,把浩瀚的文本切成了一块块标准积木。现在,AI手里已经有了一个装得满满当当的积木盒,每块积木上都刻着一个符号——“apple”、“un”、“。”、“人工智能”……
但等等。在AI的数字世界里,符号本身是毫无意义的。一块刻着“apple”的积木,和一块刻着“car”的积木,对它来说只是两串不同的0和1。它怎么知道前者是一种水果,能吃,和“pie”关系很近;后者是一种交通工具,和“road”关系很近,和“eat”则基本无关?
如果它连这都不知道,后面那些让人惊叹的对答如流、逻辑推理,又从何谈起?
答案是:在BPE切出形体之后,AI还要给每一块积木注入灵魂。 这个“灵魂注入”的过程,就是我们要讲的核心概念——Embedding(词嵌入,也叫语义向量)。
给你一个“意义GPS”
想象一下,你拿到了一张巨大无比的空白地图,大到可以容纳世界上所有的词语。你的任务,是给每一个Token在这张地图上分配一个独一无二的位置(坐标)。规则只有一条:意思越相近的词,放得越近;意思越无关的词,放得越远。
- 你会把“开心”和“快乐”紧紧挨在一起,因为它们几乎可以互换。
- 你会把“开心”和“悲伤”放在地图的两端,因为它们是反义词。
- 你会把“跑”和“跳”放在同一个街区,因为它们都跟“运动”有关。
- 而“跑”和“石头”,则相隔天涯海角,几乎毫无关联。
这张地图,就是语义空间。每一个Token在这张地图上的坐标,就是它的Embedding向量。
“向量”这个词听起来有点唬人,但你可以简单地把它理解为一长串数字,比如:
- “国王”的坐标可能是
[0.13, 0.54, -0.21, 0.92, ...] - “王后”的坐标可能是
[0.15, 0.52, -0.19, 0.88, ...] - “苹果”的坐标可能是
[-0.31, 0.11, 0.73, -0.05, ...]
在实际的大模型里,这个坐标不是我们熟悉的二维(经度、纬度)或三维(经度、纬度、高度),而是几百甚至上千维。比如GPT模型里,每个Token的Embedding向量通常有768维、现代大模型通常有数千维甚至上万维。
为什么需要这么多维?因为语言的意义太复杂了。“苹果”这个词,同时关联着“水果”、“科技公司”、“红色”、“圆形”、“甜味”、“牛顿”等数十种不同的属性。二维地图根本不够用——你没法在平面上同时表达“既是水果又是公司”这种多维关系。只有用几百个维度,才能把这种交织的意义网络完整地铺展开来。
通俗地说,Embedding就是给每一块Token积木贴上了一张写满数字的“语义身份证”。 这张身份证上记录的不是姓名、性别、住址,而是几百个不同维度的“意义坐标”。AI读的不是积木上的字,而是这张身份证上的数字密码。
地图上的神奇算术:国王 - 男人 + 女人 = 王后
如果Embedding仅仅是把近义词放在一起,那还不算特别神奇。真正让人感到“AI理解了意义”的时刻,是我们可以在这张语义地图上做加减法。
一个被反复提及的经典例子是:
“国王”的向量 - “男人”的向量 + “女人”的向量 ≈ “王后”的向量
怎么理解?你可以把每个向量想象成从一个原点出发的箭头。不同维度上,箭头指向不同的方向。
- “国王”这个箭头,指向的方向里,同时包含了“王室属性”和“男性属性”。
- 我们减去“男人”的箭头,就相当于把“男性属性”这个方向上的分量给抽走了。剩下的,基本上是一个纯粹的“王室属性”。
- 然后,我们再加上“女人”的箭头,把“女性属性”这个方向上的分量补回去。
- 最终得到的箭头,恰好指向“王后”那个点附近。
同样的魔法还能变出更多花样:
- “巴黎” - “法国” + “意大利” ≈ “罗马”
- “walking” - “walk” + “swim” ≈ “swimming” (捕捉到了时态变化)
- “更好” - “好” + “快” ≈ “更快” (捕捉到了比较级关系)
这些运算不是人为设计的规则,而是模型从海量文本中自动学到的。它不知道“男”“女”“王室”这些概念,它只是在调整每个Token的几百个数字时,发现只有这样安排,才能最准确地预测下一个出现的词。而在这种最优化安排里,语义上的规律,就自然而然地以“向量可加减”的形式浮现了出来。
这些数字,是怎么被算出来的?
你一定会问:是谁给每个Token分配了这样一张神奇的身份证?这些数字,到底是怎么来的?
答案出奇地简单,甚至带着一丝哲学的意味:一个词的意义,由它身边的朋友决定。
训练Embedding最核心的思想,可以用一句话概括:经常出现在相似上下文中的词,意思往往也相近。
想象你是一个刚学中文的孩子,你不认识“红酒”和“白酒”这两个词。但你读过很多句子,你发现:
- “我喜欢喝__” 的空格里,既可以填“红酒”,也可以填“白酒”。
- “这瓶__年份久远” 里,也一样。
- “他喝__喝醉了” 里,还是一样。
渐渐地,你虽然还是不知道它们具体是什么颜色、什么味道,但你百分之百确定:“红酒”和“白酒”一定是同类的东西。 因为它们频繁地出现在一模一样的上下文里,身边围绕的朋友几乎完全重叠。
AI就是用同样的逻辑来学习Embedding的。在训练初期,它把每个Token的向量设为一堆随机数。然后,它开始疯狂阅读海量文本,玩一个叫“猜邻居”的游戏:
- 随便抓一个句子,比如“我今天吃了一个__”。
- 蒙住空格处的词,让AI根据上下文(周围的Token向量)来猜空格里最可能是哪个Token。
- 如果AI猜错了(比如它猜了“汽车”,但正确答案是“苹果”),它就受到“惩罚”,然后反向调整“苹果”和上下文词的向量坐标,让“苹果”离“吃”更近一点,离“汽车”更远一点。
- 如此反复,亿亿万次。
经过天文数字般的“猜词-纠错”循环,每个Token的向量坐标被调整到了一个精妙绝伦的位置:语义相近的词,因为总出现在相似的语境里,它们的向量被一次次拉近,最终聚在一起;语义无关的词,则被一次次推远,散落在地图各处。
这就是Embedding的诞生:一个完全自监督、从语言的使用方式中自动涌现意义的过程。 没有任何人给它标注“这是水果”、“这是情绪”,它只是在疯狂地玩猜词游戏,玩到最后,意义的几何结构就自己浮出了水面。
BPE是形体,Embedding是灵魂
现在,我们可以把Token的两个核心概念串起来了。
- BPE(分词算法)决定了Token长什么样。 它是一把刀,负责把无限的语言切成一盒有限的标准积木块。它回答的问题是:“AI眼里的一个基本单位是什么?边界在哪里?”
- Embedding(语义向量)决定了Token意味着什么。 它是一支笔,负责给每块积木写上一张密密麻麻的意义标签。它回答的问题是:“这个基本单位,对AI而言到底是什么意思?它和其他单位是什么关系?”
一块积木,如果只有BPE切出的形体,没有Embedding赋予的灵魂,那它在AI眼里就只是一个空洞的符号。AI可以拿着它,数一数有多少块,却无法理解它代表的是“爱”还是“恨”,是“买”还是“卖”。
只有同时具备了形体和灵魂,Token才真正成为一座桥梁——一头连着人类模糊多义的自然语言,一头连着机器精确冷酷的数字世界。BPE让文本变得可被计算,Embedding让这种计算有了方向和意义。
意义地图的威力:从搜索到推理
理解Embedding,不只是满足好奇心。它直接解释了你日常使用的许多AI功能,到底是如何工作的。
- 语义搜索:当你在一个AI知识库里搜索“如何让猫多喝水”,它找到的文档里可能根本没有“猫”和“水”这两个字,而是有一句“宠物的液体摄入量提升技巧”。传统的关键词匹配会完美错过,但基于Embedding的向量搜索,会计算你查询词的向量,然后找整个知识库里向量最接近的内容块。它找的不是字面匹配,而是意义接近。这就是RAG(检索增强生成)的基石。
- 内容聚类与推荐:AI可以将海量文档或用户评论,根据它们对应的Token向量的平均位置,自动聚集成不同的“意义群落”。你瞬间就能发现哪些话题在集中讨论,而不需要人工逐条阅读。
- 跨语言理解:在多语言模型里,中文的“猫”和英文的“cat”,尽管Token形体完全不同,但它们的Embedding向量被刻意训练得很近,落在语义地图的同一片区域。这意味着,AI在用一种近乎“通用的意义语言”进行思考,不受具体语种的束缚。
所以,当你惊叹于AI能听懂你的暗示、理解上下文中的双关语、甚至做出跨领域的类比推理时,请记得:这一切魔法的起点,是它手中的每一块Token积木,都已经被贴上了一张无比精确的“意义GPS标签”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)