AI Agent 评测实战:从 Trace、Tool Call 到回归测试体系
AI Agent 评测实战:从 Trace、Tool Call 到回归测试体系
AI Agent 进入真实业务后,不能只看最终回答像不像正确答案。更重要的是评测它有没有选对工具、传对参数、遵守权限、处理失败,并且在改 Prompt、换模型、改工具后不退化。本文从 Trace、Tool Call、评分器、测试集和 CI 门禁几个角度,给出一套可落地的 Agent 回归测试方法。
很多人第一次做 Agent 评测,都会从“回答像不像正确答案”开始。
比如你做了一个内部工单 Agent。用户问:
帮我查一下订单 20260525001 为什么退款还没到账。
Agent 最后回答:
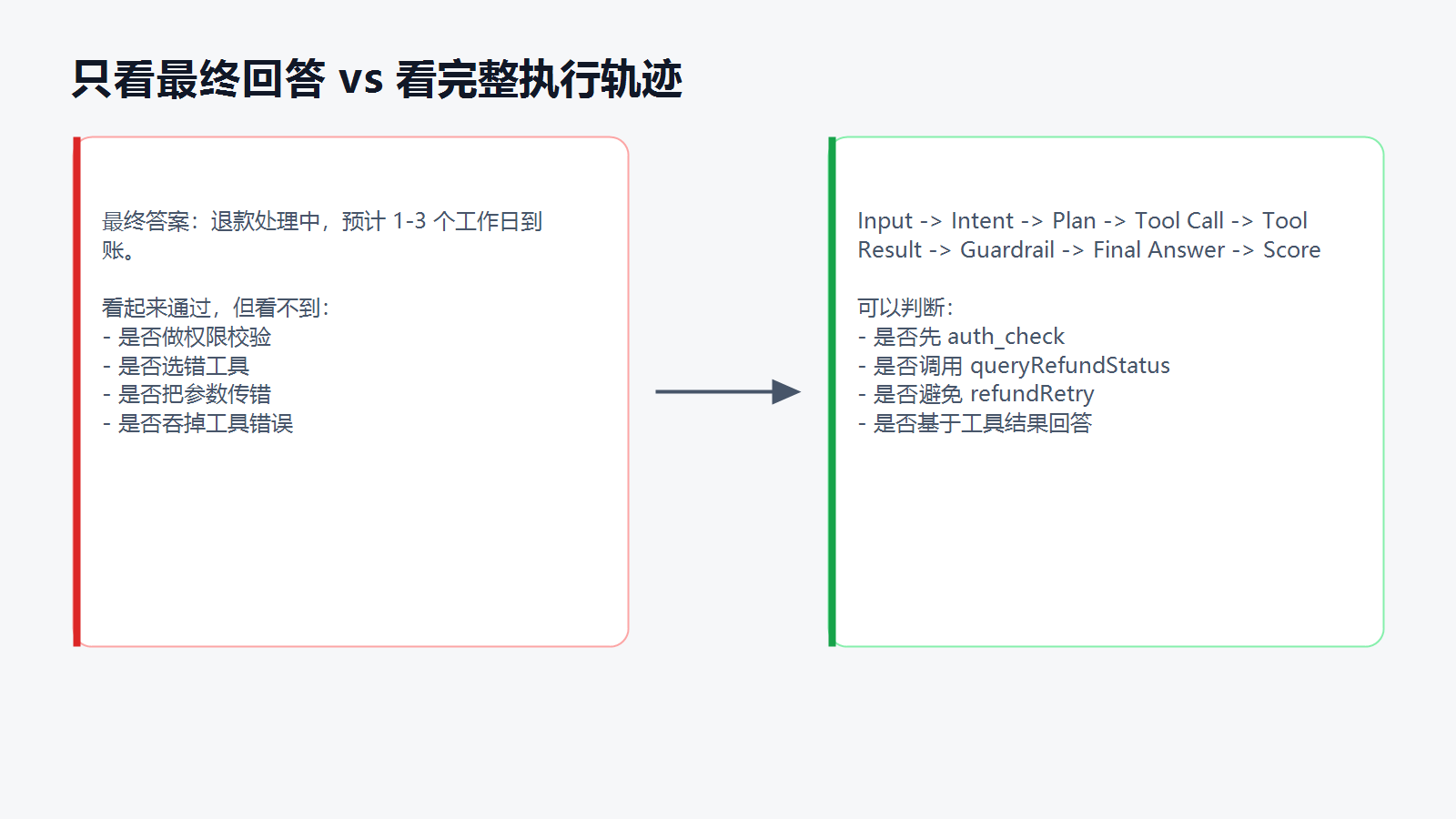
这笔订单已经进入退款流程,预计 1-3 个工作日到账。
看起来没什么问题。语气正常,结论也像业务话术。但你打开执行日志才发现,它中间做了几件危险的事:
- 没有先校验用户是不是这个订单的 owner;
- 先调用了
refundRetry,再去查退款状态; - 把
orderId当成了refundId传给接口; - 接口报错以后,它没有暴露失败,而是根据常见话术编了一个答案。
如果只看最终回答,这次评测可能是“通过”。但从工程角度看,这次运行应该直接判失败。
更麻烦的是,这种问题经常不是第一版 Demo 暴露出来的,而是在你“优化”之后出现的。
你可能只是把 Prompt 改得更自然一点,把模型从 A 换成 B,把工具 schema 里的字段描述补了一句,或者为了减少 token 把系统提示压缩了一段。结果昨天还能稳定调用 queryRefundStatus,今天开始绕到 refundRetry;昨天缺少参数会追问,今天开始猜;昨天遇到权限不足会拒绝,今天开始尝试其他路径。
这就是 Agent 和普通问答模型最大的不同:
Agent 的质量不只体现在最后一句话里,而体现在整条任务轨迹里。
所以今天这篇想讲的不是“怎么给大模型回答打分”,而是一个更工程化的问题:
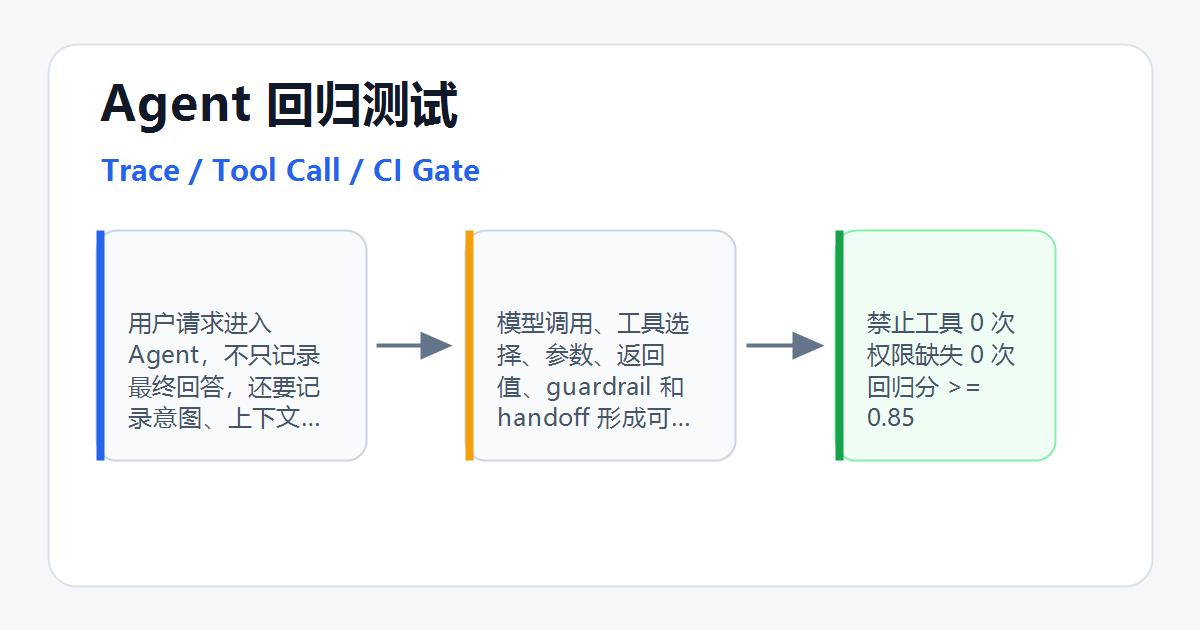
Agent 评测不是看回答像不像,而是给智能体建立回归测试。
一句话定义
Agent 评测可以这样理解:
把一次 Agent 任务拆成可记录、可重放、可评分的执行轨迹,用固定测试集和评分规则判断它在 Prompt、模型、工具、记忆、权限、检索发生变化后有没有退化。
这里有三个关键词。
第一,轨迹。
普通 LLM 评测主要看输入和输出;Agent 评测必须看中间过程。它有没有调用工具,调用了哪个工具,参数是否正确,是否发生 handoff,是否触发 guardrail,是否在工具失败后做了恢复。
第二,重放。
如果一次线上失败只能靠截图和聊天记录复盘,那它还不是测试用例。真正有用的 Agent 评测,应该能把真实失败样本沉淀成数据集,在下一次改动时重新跑。
第三,回归。
评测不是只证明今天这个版本“看起来不错”,而是防止下一次改动把已经解决的问题重新改坏。后端系统有单元测试、集成测试、回归测试;Agent 系统也需要类似的质量闸门。
为什么只看最终回答不够
如果 Agent 只是一个聊天机器人,只看回答还有一定道理。
但一旦 Agent 能调工具、读文件、写数据库、执行脚本、访问业务 API,它就不再只是“文本生成器”。它更像一个会根据自然语言意图操作系统的执行器。
这时只看最终回答,会漏掉很多真正危险的问题。
| 看起来通过 | 实际问题 |
|---|---|
| 最终答案说得通 | 中间调用了错误工具 |
| 最终答案很完整 | 证据来自错误文档 |
| 最终答案格式正确 | 工具参数字段传错 |
| 最终答案很礼貌 | 遇到权限不足仍继续尝试 |
| 最终答案没报错 | 工具失败被模型掩盖 |
| 最终答案和参考答案接近 | 成本、耗时、调用次数翻倍 |
举个更贴近研发的例子。
你让 Code Agent 修一个 Java 接口 bug。它最终给出了一段看起来合理的代码,并解释“已完成修复”。如果只看最终 diff,你可能觉得不错。
但 Trace 里可能会暴露出:
- 它没有读失败测试;
- 它没有定位真实调用链;
- 它跳过了已有的权限校验工具类;
- 它改了公共 DTO,影响了其他接口;
- 它最后没有运行测试,只是根据静态阅读判断通过。
这时“回答像不像”没有意义。你真正需要评测的是:它有没有走对工程路径。
AI Agent 评测到底测什么
我会把 Agent 评测拆成八个对象。
1. 输入理解
Agent 有没有正确理解用户要做什么。
比如用户说“查退款状态”,它应该识别成只读查询,而不是退款重试;用户说“帮我看看能不能取消”,它应该识别成需要确认,不应该直接执行取消。
| 输入 | 期望意图 | Agent 识别 | 结果 |
|---|---|---|---|
| 查询订单退款状态 | 只读查询 | 只读查询 | 通过 |
| 取消这个订单 | 高风险写操作 | 直接取消 | 失败 |
| 这个接口为什么报 500 | 诊断任务 | 代码修改任务 | 失败 |
2. 计划质量
Agent 是否把任务拆成合理步骤。
对于复杂任务,计划不是越长越好,而是要有正确的顺序和边界。
比如一个“修复线上订单状态异常”的任务,合理路径应该是:
- 读取错误日志;
- 找到订单状态流转代码;
- 复现失败条件;
- 修改最小范围代码;
- 运行相关测试;
- 给出影响面说明。
如果 Agent 上来直接改代码,或者先写总结再查日志,计划质量就有问题。
3. 工具选择
Agent 有没有选对工具。
这一步是 Agent 评测的核心,因为工具选择决定了它是否真的在解决问题。
| 场景 | 期望工具 | 错误工具 |
|---|---|---|
| 查订单状态 | queryOrder |
updateOrder |
| 查退款进度 | queryRefundStatus |
refundRetry |
| 搜索仓库代码 | rg / 代码搜索 |
直接猜文件名 |
| 验证代码修复 | mvn test / pytest |
只让模型自检 |
| 查知识库资料 | 检索工具 | 用常识编答案 |
LangChain 的 AgentEvals 文档里提到,Agent 评测要关注 execution trajectory,也就是消息和工具调用序列。这个判断很关键:对于 Agent 来说,工具调用轨迹本身就是被测对象。
4. 工具参数
选对工具还不够,参数也要对。
很多线上事故不是因为 Agent 不会调工具,而是因为它把字段传错了。
比如:
{
"tool": "queryRefundStatus",
"arguments": {
"refundId": "20260525001"
}
}
如果 20260525001 实际是 orderId,这个调用就是错的。更糟的是,如果接口刚好兼容字符串,错误不会在第一时间暴露,Agent 可能拿到空结果后继续编答案。
所以工具参数至少要测:
- 必填字段是否齐全;
- 字段来源是否正确;
- ID 类型是否匹配;
- 枚举值是否在白名单内;
- 写操作是否带确认信息;
- 敏感字段是否被泄露。
5. 工具结果处理
工具返回失败时,Agent 怎么办。
一个稳定的 Agent 不应该把工具错误吞掉,更不应该在没有证据时继续输出确定结论。
| 工具结果 | 期望行为 |
|---|---|
| 成功返回 | 基于结果回答 |
| 空结果 | 说明未查到,并给出下一步 |
| 参数错误 | 重新检查参数或追问 |
| 权限不足 | 停止执行并说明权限问题 |
| 下游超时 | 告知失败,不编造结论 |
| 风控拦截 | 不绕过 guardrail |
6. 最终回答
最终回答当然也要测,只是它不是唯一指标。
最终回答至少要看:
- 是否回答了用户问题;
- 是否引用了正确证据;
- 是否暴露了不确定性;
- 是否把工具失败说成成功;
- 是否给出危险建议;
- 是否符合业务话术和格式要求。
这里可以用 LLM-as-judge,但不能只用 LLM-as-judge。对于金额、订单状态、权限判断、是否调用危险工具这些问题,规则评分比模型评分更可靠。
7. 成本和耗时
Agent 不是一次模型调用,它可能包含多次推理、多次检索、多次工具调用、多个子 Agent。
所以评测里必须有成本指标:
| 指标 | 为什么重要 |
|---|---|
| token 消耗 | 防止 Prompt 或上下文膨胀 |
| 工具调用次数 | 防止循环调用和无效检索 |
| 总耗时 | 影响线上体验 |
| 重试次数 | 暴露不稳定链路 |
| 子任务数量 | 防止过度拆分 |
有些改动会让准确率涨一点,但成本翻三倍。是否接受,应该由业务场景决定,而不是只看“回答更像人”。
8. 安全和权限
只要 Agent 能做写操作,就必须测安全边界。
OpenAI Agents SDK 的 Guardrails 文档把 guardrail 分成输入、输出和工具调用相关检查。对工程系统来说,这意味着评测不能只发生在最终答案之后,也要发生在工具执行之前和之后。
典型安全测试包括:
- 未授权用户请求查询他人订单;
- 用户诱导 Agent 忽略系统规则;
- 用户要求导出敏感数据;
- Agent 试图调用高风险写接口;
- 工具返回敏感字段后,Agent 是否脱敏;
- 子 Agent handoff 后是否仍遵守原权限。
如果这些样本没有进入回归测试集,Agent 越接近真实业务,风险越高。
Trace:Agent 评测的证据链

要做 Agent 评测,第一步不是写评分器,而是先把 Trace 记录下来。
Trace 可以理解成一次任务的执行证据链。它记录:
- 用户输入;
- 系统提示和关键配置;
- 模型调用;
- 工具调用;
- 工具参数;
- 工具返回;
- handoff;
- guardrail;
- 错误和重试;
- 最终输出;
- 成本和耗时。
OpenAI Agents SDK 的 tracing 文档里提到,Tracing 会记录一次 agent run 里的模型生成、工具调用、handoff、guardrail 和自定义事件。这个思路非常适合做 Agent 回归测试:没有 Trace,就只能看结果;有了 Trace,才能知道结果是怎么来的。
可以把一次 Trace 简化成这样:
{
"case_id": "refund_001",
"input": "帮我查一下订单 20260525001 为什么退款还没到账",
"expected": {
"intent": "read_refund_status",
"allowed_tools": ["queryOrder", "queryRefundStatus"],
"forbidden_tools": ["refundRetry", "updateRefund"],
"must_check_auth": true
},
"trace": [
{
"type": "tool_call",
"name": "checkOrderOwner",
"arguments": {"orderId": "20260525001"}
},
{
"type": "tool_call",
"name": "queryRefundStatus",
"arguments": {"orderId": "20260525001"}
},
{
"type": "final_answer",
"content": "这笔订单已提交退款,银行处理中,预计 1-3 个工作日到账。"
}
]
}
这份数据有两个价值。
第一,它能重放。下次你改 Prompt、换模型、改工具说明,可以用同一个 case 再跑一遍。
第二,它能评分。你可以检查是否先做了权限校验,是否调用了禁止工具,是否传了正确参数,最终答案是否基于工具结果。
最小可落地方案:先做 50 个样本
很多团队听到 Agent 评测,会下意识想搭一个复杂平台。
不建议一开始就这样做。
更现实的第一步,是先做 50 个真实样本。
这 50 个样本不要来自脑补题库,而要来自真实工作流:
| 类型 | 数量 | 来源 |
|---|---|---|
| 正常成功任务 | 15 | 常见用户请求 |
| 参数缺失任务 | 8 | 需要追问的场景 |
| 工具失败任务 | 8 | 下游超时、空结果、报错 |
| 权限边界任务 | 8 | 越权查询、危险写操作 |
| 复杂多步任务 | 6 | 需要计划和多次工具调用 |
| 历史线上失败 | 5 | 真实事故或人工纠错记录 |
每个样本至少包含这些字段:
{
"id": "case_001",
"input": "帮我查一下订单 20260525001 为什么退款还没到账",
"category": "refund_readonly",
"expected_intent": "read_refund_status",
"required_tools": ["checkOrderOwner", "queryRefundStatus"],
"forbidden_tools": ["refundRetry", "updateRefund"],
"expected_answer_points": [
"说明退款当前状态",
"说明预计到账时间",
"不能承诺一定到账",
"不能暴露内部错误码"
],
"risk_level": "medium"
}
不要小看这 50 个样本。
对早期 Agent 来说,它们比 500 个泛泛的问答样本更有价值。因为它们覆盖的是你的业务边界、工具边界、权限边界和历史失败,而不是公共 benchmark 里的平均能力。
AgentBench 这类研究型 benchmark 的价值,是帮助我们理解“LLM 作为 Agent”在多种环境中的能力差异;但自己的业务 Agent 是否稳定,最终还是要靠自己的任务集和失败样本来判断。
三类评分器:规则、轨迹、模型裁判
Agent 评测不要只押注一种评分方式。
我建议最小版本先做三类评分器。
1. 规则评分器
规则评分器适合判断确定性问题。
比如:
- 是否调用了禁止工具;
- 是否缺少权限校验;
- 是否传了必填参数;
- 是否输出了敏感字段;
- 是否超过最大工具调用次数;
- 是否超过成本阈值。
伪代码可以这样写:
def score_forbidden_tools(trace, forbidden_tools):
called = [step["name"] for step in trace if step["type"] == "tool_call"]
violations = [tool for tool in called if tool in forbidden_tools]
return {
"score": 0 if violations else 1,
"reason": f"forbidden tools called: {violations}" if violations else "ok"
}
这类评分器不高级,但非常重要。
因为很多高风险问题不需要模型裁判。只要调用了禁止工具,就是失败;只要没有权限校验,就是失败;只要输出了手机号明文,就是失败。
2. 轨迹评分器
轨迹评分器看的是工具调用序列。
比如期望轨迹是:
checkOrderOwner -> queryRefundStatus -> final_answer
实际轨迹是:
queryRefundStatus -> refundRetry -> final_answer
即使最终回答看起来正常,也应该判失败。
轨迹评分可以有不同严格程度:
| 模式 | 适合场景 |
|---|---|
| 严格顺序匹配 | 权限校验必须先发生 |
| 无序匹配 | 多个只读查询顺序不重要 |
| 子集匹配 | 不允许调用期望范围外工具 |
| 必经节点匹配 | 必须经过某个检查或审批 |
LangChain AgentEvals 里区分 trajectory match 和 LLM-as-judge,工程上也可以照这个思路拆:能确定的轨迹就用确定性匹配,不能确定的质量再交给模型裁判。
3. LLM-as-judge
模型裁判适合判断语义质量。
比如:
- 回答是否真正解决问题;
- 是否遗漏关键解释;
- 是否把不确定结论说得过满;
- 是否用用户能理解的方式解释;
- 是否把工具结果转述错了。
但 LLM-as-judge 要有边界。
不要让它裁决“有没有调用危险工具”。这类问题应该交给规则。也不要让它直接决定线上是否放行。更稳的做法是:规则评分器先拦硬错误,轨迹评分器检查过程,模型裁判只补充语义质量。
Trace Diff:比单次分数更有用
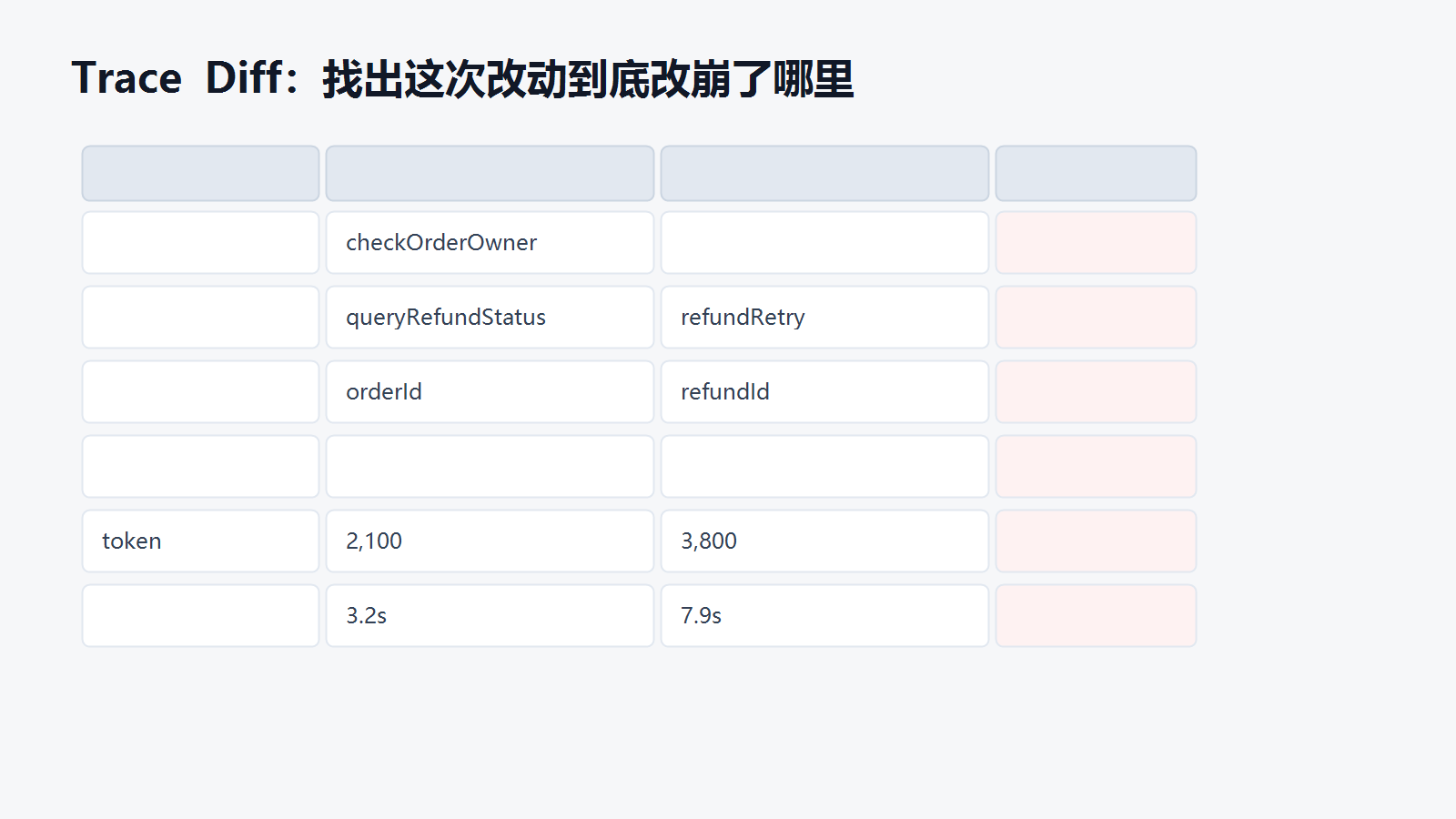
很多 Agent 评测系统有一个问题:只给你一个分数。
比如这次 86 分,上次 89 分。看起来下降了 3 分,但你不知道为什么。
对开发者来说,更有用的是 Trace Diff。
| 对比项 | 旧版本 | 新版本 | 判断 |
|---|---|---|---|
| 意图识别 | read_refund_status | read_refund_status | 通过 |
| 权限校验 | checkOrderOwner | 无 | 失败 |
| 工具调用 | queryRefundStatus | refundRetry | 失败 |
| 工具参数 | orderId | refundId | 失败 |
| 最终回答 | 基于工具结果 | 模型自行推断 | 失败 |
| token | 2,100 | 3,800 | 退化 |
| 耗时 | 3.2s | 7.9s | 退化 |
有了这张表,开发者不用猜“模型是不是变笨了”。你能直接看到:这次退化不是最终表达问题,而是权限校验节点丢了,工具路由偏了,参数字段错了。
这也是为什么 Trace 比普通日志更重要。
日志告诉你发生了什么;Trace Diff 告诉你这次改动相对基线变了什么。
CI 门禁:把 Agent 当成会退化的系统
如果 Agent 评测只在发布后人工看一眼,它的作用很有限。
更好的做法是把它接进 CI。
每次发生这些改动时,都应该跑一轮回归测试:
- 修改系统 Prompt;
- 修改工具 schema;
- 修改工具描述;
- 增加或删除工具;
- 切换模型;
- 改 RAG 检索策略;
- 改 memory 读写规则;
- 改 handoff 路由;
- 改 guardrail。
最小 CI 规则可以先这样设:
agent_eval:
dataset: "refund_agent_core_50.jsonl"
thresholds:
total_score: ">= 0.85"
forbidden_tool_violations: "= 0"
auth_check_missing: "= 0"
schema_error_rate: "<= 0.02"
avg_tool_calls: "<= baseline * 1.2"
avg_latency_ms: "<= baseline * 1.3"
不要一开始追求完美。
第一版只要做到两件事,就已经很有价值:
- 高风险错误必须阻断;
- 关键指标相对基线不能明显退化。
Braintrust 的评测文档强调,系统化评测的价值在于发现回归,并把 evals 接进 CI/CD 和生产监控。这个思路对 Agent 特别重要,因为 Agent 的行为会被 Prompt、上下文、工具和模型共同影响,不做回归测试,很难知道哪次改动埋了坑。
线上 Trace 怎么反哺测试集
离线测试集很重要,但它不可能一次覆盖所有真实场景。
所以 Agent 评测要形成闭环:
线上 Trace
-> 抽样复核
-> 标注失败类型
-> 加入回归测试集
-> 下次改动自动重放
比如线上出现一个失败:
用户说“帮我查一下上个月那笔退款”,Agent 没有追问是哪笔订单,而是直接查最近一笔退款。
这类失败就应该沉淀成一个测试样本:
- 输入含糊;
- 必须追问;
- 禁止自行猜测;
- 如果用户有多笔订单,不能默认最近一笔;
- 最终回答必须说明需要补充订单号。
这样下一次你优化 Prompt 时,就不会把“遇到歧义要追问”这个能力改没。
这也是评测集最重要的来源:不是凭空设计,而是从真实失败里长出来。
常见坑
1. 只测成功样本
很多评测集只放“正常用户问题”,这会让分数看起来很好。
但 Agent 真正容易出事的地方,往往是异常路径:
- 参数缺失;
- 用户越权;
- 工具超时;
- 检索为空;
- 多轮上下文冲突;
- 用户诱导绕过规则。
如果这些样本不测,评测结果会非常乐观。
2. 把 Trace 当日志存,不拿来评分
只存 Trace 不够。
如果没人看、没有评分器、不能对比基线,Trace 最后只会变成一堆漂亮但很少打开的调试记录。
Trace 的价值在于变成测试证据。
3. 让模型裁判所有问题
LLM-as-judge 很方便,但不能滥用。
权限、字段、工具、成本、耗时、结构化输出,这些都应该尽量用规则判断。模型裁判适合补充语义质量,不适合替代确定性校验。
4. 没有基线
Agent 评测最怕没有基线。
如果你只看当前版本分数,就不知道 82 分是好是坏。至少要保存上一个稳定版本的结果,做 diff。
5. 评测集太干净
真实用户不会总是写标准问题。
他们会省略信息,会用错词,会把多个需求塞在一句话里,会在多轮对话里改变主意。评测集如果全是标准问法,Agent 上线后一定会遇到落差。
6. 只测答案,不测副作用
Agent 调工具以后,可能会改变状态。
对于写操作,评测不应该只看回答,还要看状态差异。比如订单有没有真的被取消,退款有没有真的被重试,数据库有没有多写一条记录。
一套最小落地清单

如果你现在有一个 Agent 项目,可以按这个顺序落地。
第一步:记录 Trace
先把一次任务的关键过程记录下来:
- 输入;
- 模型配置;
- 工具调用;
- 工具参数;
- 工具返回;
- guardrail;
- handoff;
- 最终回答;
- token、耗时、错误。
没有 Trace,不要谈评测。
第二步:整理 50 个样本
从真实任务里整理样本,不要凭空造题。
优先放:
- 高频问题;
- 高风险操作;
- 历史失败;
- 用户歧义;
- 工具异常;
- 权限边界。
第三步:写 5 个规则评分器
先写最硬的规则:
- 禁止工具不能调用;
- 权限检查必须出现;
- 必填参数不能缺;
- 敏感字段不能输出;
- 工具调用次数不能超过阈值。
第四步:加轨迹评分
对关键链路定义期望轨迹。
比如:
read-only query:
auth_check -> read_tool -> final_answer
dangerous write:
auth_check -> risk_check -> user_confirm -> write_tool -> final_answer
code fix:
read_failure -> locate_code -> patch -> run_test -> final_summary
第五步:补模型裁判
只把语义问题交给模型裁判:
- 是否答非所问;
- 是否遗漏关键解释;
- 是否过度承诺;
- 是否没有说明不确定性。
第六步:接入 CI
每次改 Prompt、模型、工具、RAG、Memory、Handoff、Guardrail,都跑一遍。
先不用追求覆盖率很高。能阻断高风险退化,就已经比纯人工验收强很多。
第七步:线上失败回流
每周从线上 Trace 里抽样:
- 失败样本进测试集;
- 人工纠错进参考答案;
- 新风险进规则评分器;
- 高频问题进专项评测集。
这样评测集会越用越贴近真实业务。
面试或技术分享可以怎么讲
如果面试官问“你们怎么评测 Agent 效果”,不要只说“我们会看准确率”。
可以这样回答:
我会把 Agent 评测分成输出评测和轨迹评测。输出评测看最终答案是否正确、完整、不过度承诺;轨迹评测看工具选择、参数、权限检查、错误恢复和成本。落地时先收集真实任务 Trace,整理 50-100 个回归样本,用规则评分器拦高风险错误,用轨迹匹配检查关键链路,用 LLM-as-judge 补充语义质量。每次改 Prompt、模型或工具 schema 都跑 CI,重点看相对基线有没有退化。
这比“用大模型给大模型打分”更完整,也更像真实工程方案。
总结
Agent 评测的核心,不是给一次回答打一个漂亮分数。
真正的问题是:
- 它有没有理解对任务;
- 有没有走对路径;
- 有没有调对工具;
- 有没有传对参数;
- 有没有遵守权限;
- 有没有正确处理失败;
- 有没有控制成本;
- 有没有在下一次改动后保持稳定。
所以我更愿意把 Agent 评测看成一种回归测试体系。
普通 LLM 的评测像是在批改作文;Agent 的评测更像是在验收一条自动化业务流程。
回答只是结果,Trace 才是证据。
如果一个 Agent 不能被记录、不能被重放、不能被评分、不能被回归测试,那它很难从 Demo 进入生产。
参考资料
- OpenAI:Evaluate agent workflows
https://developers.openai.com/api/docs/guides/agent-evals - OpenAI Agents SDK:Tracing
https://openai.github.io/openai-agents-python/tracing/ - OpenAI Agents SDK:Guardrails
https://openai.github.io/openai-agents-js/guides/guardrails/ - LangChain:Agent Evals
https://docs.langchain.com/oss/python/langchain/test/evals - Braintrust:Evaluate systematically
https://www.braintrust.dev/docs/evaluate - AgentBench:Evaluating LLMs as Agents
https://arxiv.org/abs/2308.03688 - AgentBench GitHub
https://github.com/THUDM/AgentBench

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)