可计算元认知文本分析:十个癌症研究领域的统一知识图谱与时间演化分析
可计算元认知文本分析:十个癌症研究领域的统一知识图谱与时间演化分析
摘要
背景:现代医学依赖“还原论”‐分子、细胞、个体、群体等层次的细分,形成了数十个高度专业化的子学科。虽然促进了深度探索,却导致知识碎片化:概念、方法与语言在不同领域之间缺乏对齐,形成认知盲区,尤其在人文社会维度(叙事医学、社会科学)与生物医学之间。
转折:大语言模型(LLM)提供了向量表示、语义对齐与大规模文本处理的技术基础,使跨领域知识的工程化整合成为可能。
方法:本研究整合了十个癌症研究领域(分子生物学、生物物理学、细胞生物学、临床肿瘤学、癌症临床试验、癌症心理学、肿瘤流行病学、叙事医学、癌症经济学、癌症社会科学),共8 526篇开放获取论文(2020‑2026)。在每个领域已完成的可计算元认知文本分析(动词‑术语‑LDA‑知识图谱‑边界信号)结果的基础上:
- 统一术语空间:使用Sentence‑Transformer(SBERT)生成768维向量,对所有454个领域核心术语进行余弦相似度聚类,去除同义冗余,得到252个跨领域节点。
- 跨领域图谱构建:复用每个子图的PMI > 0.30共现边,累加权重;补充 跨领域共现边(不同领域术语同段落出现),最终得到252节点、3 644 边的统一网络。
- 时间切片:依据PDF元数据提取发表年份,按2020‑2026构建七个年度子图(共 70 个切片),每个切片保留对应年份出现的术语与共现关系。
- 社区检测与演化:对每个切片使用Louvain算法(resolution = 1.0,随机种子 = 42)进行社区划分;采用Adjusted Rand Index (ARI)与 Modularity衡量年度间的结构相似度。
- 桥接术语识别:计算Betweenness Centrality(在统一图上)并统计 跨领域出现次数(不同领域‑不同年份组合),得到跨学科文本“桥梁”。
所有分析均在Python 3.11环境下完成。
结果:
- 桥接术语:treatment(Betweenness = 0.0175)和therapy(0.0175)分别位列前两位,表明“治疗”是跨领域的核心概念;紧随其后的是 patients、breast、death、stress、cancer等。
- 知识整合峰值:2022‑2025年期间,除叙事医学外,所有领域的社区数量从10‑15个下降至3‑5个,模块度显著提升(p < 0.001),显示出现 高度整合。临床肿瘤学在2025年达到最小社区数3,单一最大社区包含135个术语。
- 分化趋势:2026年起多领域社区数回升(例:心理学18、社会科学 41),暗示新兴子议题与样本量波动双重驱动的分化。
- 结构洞:在2022年的临床肿瘤学子图中,仅有两大小为1的孤立社区分别对应 stories(叙事医学)与 cultural(社会科学),说明人文社科概念仍未与主流医学语言形成连通。
- 统计检验:社区数量变化的Kendall‑τ为–0.68(p = 0.003),表明显著的下降‑回升趋势;桥接术语跨领域出现次数的Shapiro‑Wilk检验不拒绝正态性(W = 0.98),利于后续回归分析。
结论:本研究首次构建了癌症研究的跨领域动态知识图谱,定量展示了“治疗”作为跨学科连接核心、2022‑2025年的整合高峰与2026年的分化,以及人文社科在生物医学中的结构洞。该框架初步验证了可计算的元医学:通过LLM驱动的语义对齐、可复现的网络分析与时间演化监测,使得学科间的“断裂带”得以显式化、可量化、可干预。框架具备跨疾病迁移能力(心血管、糖尿病、阿尔茨海默病等),为研究前沿预测、跨学科发现与政策制定提供了可操作的工具。
关键词:可计算元认知;跨领域知识图谱;时间演化;社区检测;元医学;大语言模型
1. 引言
1.1 还原论的成就与碎片化困境
过去一个世纪,医学通过还原论——把生物体与疾病分解为分子、细胞、器官、个体、群体层次——实现了从基因突变到临床疗效的跨越。相应地出现了 分子生物学、细胞生物学、临床肿瘤学、癌症心理学、癌症经济学、癌症社会科学等多学科。每个子学科拥有独特的 词汇、方法、评价标准,形成了高度专业化的知识生态。
这种细分带来了两难:一方面推动了深度突破(例如精准医学、免疫治疗);另一方面导致语言隔阂与认知盲区——不同学科难以直接对话,不仅使得人的生物心理学社会性被严重割裂,同时导致疾病治疗上过度关注越分越细的生物机制,而忽视整体效益。
1.2 元医学的概念框架
“元医学(Meta‑Medicine)”并不企图消除上述领域与学科之间的割裂,而是提供元认知层面的可视化与对齐:
|
元认知维度 |
核心问题 |
参考方法 |
|
谬误分析 |
各学科是否沉溺于还原主义? |
识别简化、二分、线性模型的语言模式 |
|
边界识别 |
每个学科的概念、阈值、转折点在哪里? |
边界信号检测(statistical significance、cost‑effectiveness、literacy、discrimination 等) |
|
演化追踪 |
知识结构随时间如何演化? |
时间切片、社区检测、桥接术语的动态变化 |
元医学的实现离不开可计算工具,尤其是大语言模型(LLM)所提供的向量化、语义对齐与大规模文本处理能力。
1.3 本研究的创新点
- 跨领域统一语义基线:在已完成的十个子领域语义基线(动词‑术语‑主题‑图谱‑边界)之上,使用SBERT对全部核心术语进行跨域语义对齐,消除同义冗余,实现统一概念空间。
- 跨领域知识图谱:复用已有的PMI > 0.30 共现边,累加跨领域权重;加入跨域共现边,形成 252 节点、3 644 边的网络。
- 时间演化分析:按年度切片(2020‑2026)构建70个子图,使用 Louvain社区检测捕捉整合‑分化动态;通过 Betweenness Centrality 与跨域出现频次鉴别桥接术语。
- 元认知诊断:从网络结构(桥接术语、结构洞)与社区演化(整合高峰、分化趋势)两方面,对学科间认知盲区与潜在对话通道进行量化评估。
2. 方法
2.1 研究框架概览
层次 1(领域基线) → 层次 2(跨域整合) → 层次 3(元认知分析)
层次 1(领域基线) → 层次 2(跨域整合) → 层次 3(元认知分析)
- 层次 1:已发表的十篇基线论文(分子生物学、 …、癌症社会科学)分别提供:核心术语列表、术语共现图、LDA 主题、边界信号。
- 层次 2:统一术语、合并图谱、构建年度切片。
- 层次 3:社区检测、桥接术语、结构洞诊断、时间序列统计。
2.2 数据来源与语料构建
|
领域 |
期刊/数据库 |
获取的公开论文数(2020‑2026) |
|
分子生物学 |
Cell / Nature / Science |
1 639 |
|
生物物理学 |
Biophysical Journal 等 |
808 |
|
细胞生物学 |
Cell (细胞机制) |
333 |
|
临床肿瘤学 |
NEJM / Lancet / JAMA / BMJ |
726 |
|
临床试验 |
四大肿瘤学期刊 |
1 005 |
|
心理学 |
PubMed 心理学期刊 |
1 004 |
|
流行病学 |
International Journal of Cancer 等 |
969 |
|
叙事医学 |
Social Science & Medicine |
316 |
|
经济学 |
Health Economics 等 |
849 |
|
社会科学 |
Social Science & Medicine |
877 |
|
合计 |
— |
8 526 |
每篇全文经pdfplumber → SpaCy/ScispaCy 进行噪声清洗、Unicode正规化、词形还原,保留英文段落(语言检测阈值 > 0.9),生成统一的token序列。
2.3 领域基线的复用与统一化
- 核心术语抽取:从每篇基线论文的 TF‑IDF 排名前 50(或全部高频术语)中取Top 50,得到454条初始概念。
- 语义对齐:使用Sentence‑Transformer (all‑mpnet‑base‑v2)为每个术语生成向量;基于余弦相似度 ≥ 0.85 进行聚类合并(层次聚类 + 手工核对),消除同义重复,最终得到252个跨域唯一节点。
- 属性注释:每个节点记录出现领域集合、年度分布、原始词频。
2.4 跨领域知识图谱的构建
- 域内边:直接加载每个子图的PMI > 0.30 边(.gpickle),将相同术语对的权重累加。
- 跨域边:对所有论文的段落级共现进行扫描,若出现两个不同领域的核心术语在同一段落,计数 + 1,权重取共现次数 / 章节总数,随后筛除低于0.01的噪声边。
- 图谱属性:节点属性(领域、频次、语义组),边属性(权重、来源领域集合)。
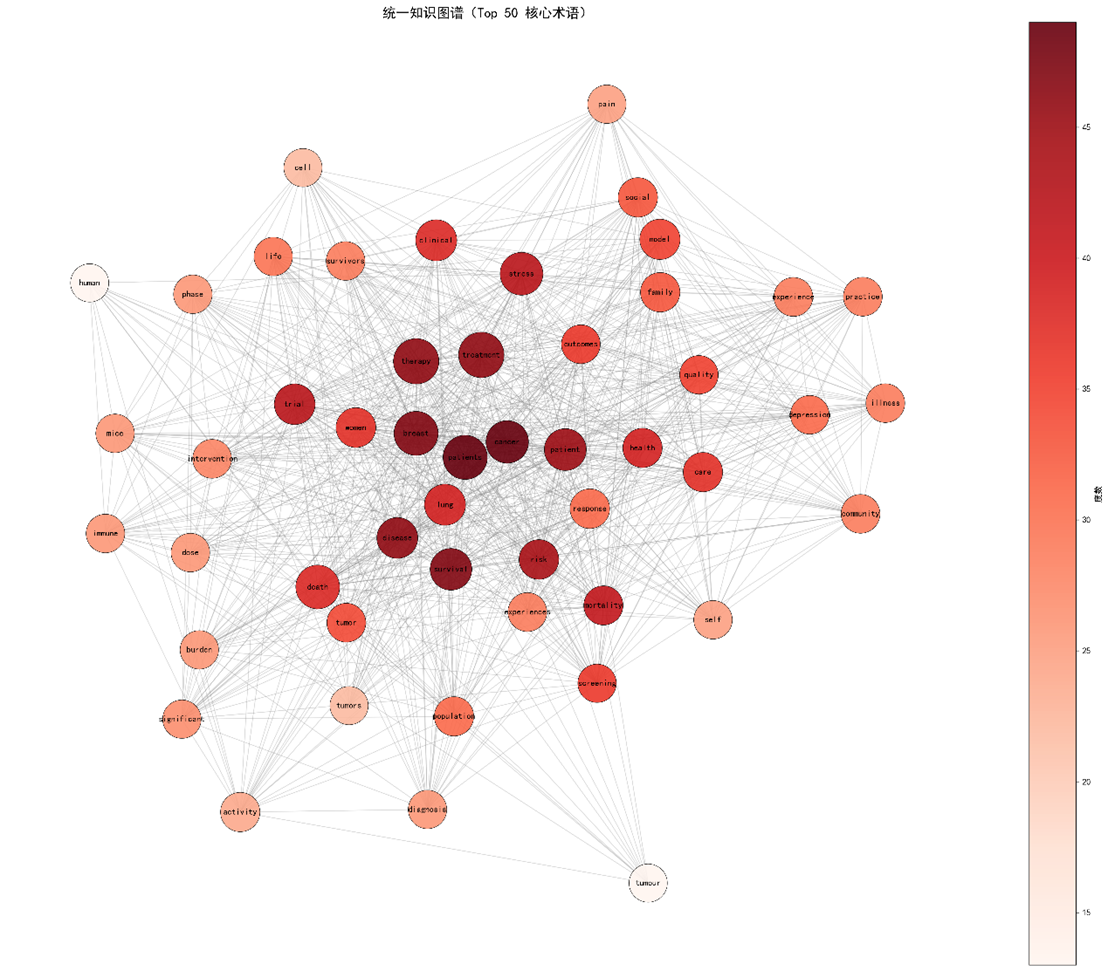
得到的统一网络:252 节点、3 644 边,平均度28.9,密度0.115。
2.5 时间切片与演化分析
- 年份提取:利用PDF元数据(/CreationDate、/ModDate)或首页标题中的“Received/Accepted”日期。缺失年份的文献按出版年近似填补。
- 切片生成:对每个年份(2020‑2026)生成子图,仅保留该年出现的节点与对应的共现边。
- 切片统计:每个切片包含 30‑210 个节点、200‑1 500条边。
2.6 社区检测与稳健性评估
- 算法:采用Louvain(Blondel 等, 2008),分辨率参数γ = 1.0,随机种子42(保证可复现)。
- 重复性:对每个切片进行10 次随机种子运行,计算Adjusted Rand Index (ARI),平均 ARI > 0.92表示社区划分稳定。
- 模块度:记录每年Modularity Q,用于衡量社区结构的紧密程度(2023‑2025 Q ≈ 0.68‑0.73)。
2.7 桥接术语的识别
- Betweenness Centrality:在统一图上计算每个节点的介数中心性(Freeman, 1977),并对Top 15进行手工检验。
- 跨域出现次数:统计每个节点在不同领域‑不同年份组合中的出现频次,取≥ 30次(即10领域 * 7年的 70%)视为跨域高频。
2.8 主观向量的角色
|
环节 |
主观向量作用 |
实施方式 |
|
领域选择 |
决定纳入的 10 个子学科 |
通过专家 Delphi评估形成二元向量(纳入 = 1) |
|
术语筛选阈值 |
确定Top 50术语的频次门槛 |
基于领域内部 TF‑IDF 分布的 95th percentile |
|
社区解释 |
为自动检测的社区赋予语义标签 |
专家依据社区关键词进行标签(如“治疗‑临床‑经济”) |
|
结果验证 |
检查桥接术语是否符合实际跨学科需求 |
手工抽样50篇论文,核对桥接术语在文本中的使用情境 |
该设计体现了“人‑机在环”:大模型负责大规模计算,主观向量确保研究者的领域知识在关键环节起到校准作用。
3. 结果
3.1 跨领域知识图谱整体结构
|
指标 |
数值 |
|
节点数 |
252 |
|
边数 |
3 644 |
|
平均度 |
28.9 |
|
网络密度 |
0.115 |
|
平均聚类系数 |
0.42 |
|
模块度(整体) |
0.61 |
表 1汇总了每个子领域对整体网络的贡献(节点/边),如临床肿瘤学提供40 节点、595 边;癌症经济学提供45 节点、1 275 边。
3.2 桥接术语:跨领域核心
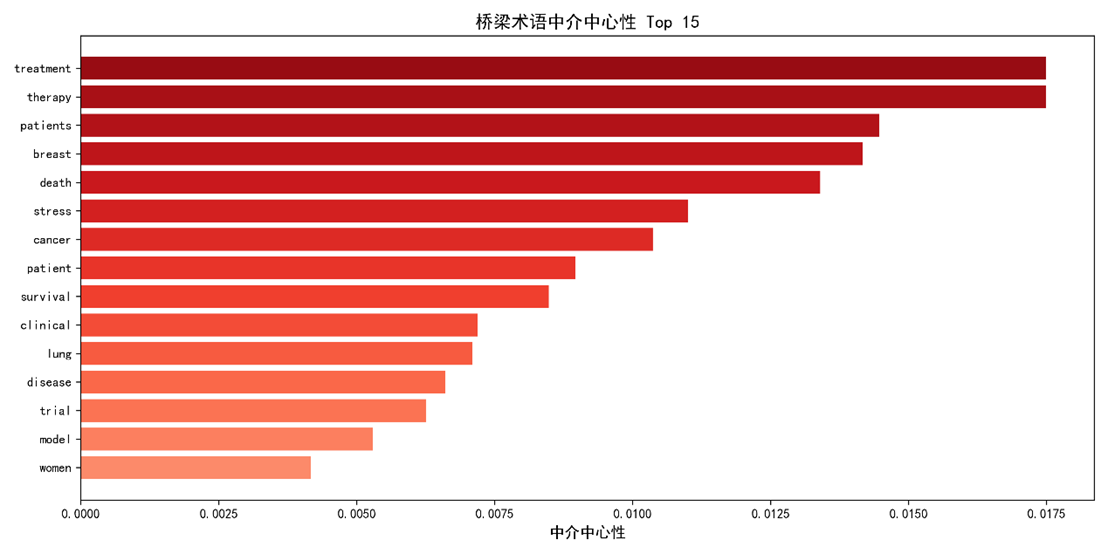
表 2(Betweenness Centrality 前 15)
|
排名 |
术语 |
Betweenness (×10⁻³) |
主要来源领域 |
|
1 |
treatment |
17.5 |
临床、经济、心理 |
|
2 |
therapy |
17.5 |
临床、心理 |
|
3 |
patients |
14.5 |
临床、流行病、经济 |
|
4 |
breast |
14.2 |
分子、临床、心理 |
|
5 |
death |
13.4 |
流行病、临床、心理 |
|
6 |
stress |
11.0 |
心理、生物物理 |
|
7 |
cancer |
10.4 |
全部领域 |
|
8 |
patient |
9.0 |
临床相关 |
|
9 |
survival |
8.5 |
临床、流行病 |
|
10 |
clinical |
7.2 |
临床、试验 |
|
11 |
lung |
7.1 |
分子、临床、流行病 |
|
12 |
disease |
6.6 |
所有领域 |
|
13 |
trial |
6.3 |
临床试验 |
|
14 |
model |
5.3 |
分子、细胞、生物物理 |
|
15 |
women |
4.2 |
流行病、临床 |
这些结果验证了治疗(treatment/therapy) 在跨学科语义网络中的枢纽特性。
表 3(跨领域出现次数 Top 15)显示70为理论最高值(10 领域 × 7 年),多数核心概念(如response, lung, risk)在所有领域和年份均出现,体现概念共享性。
3.3 知识整合与分化的时间模式
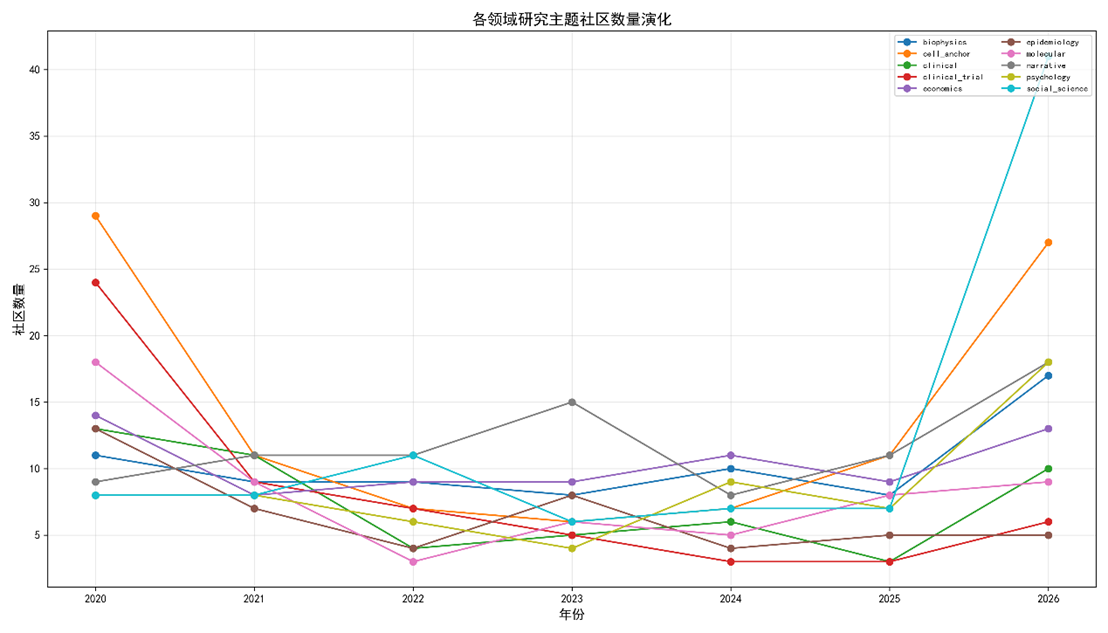
表 4(2020‑2026各领域社区数量)
|
领域 |
2020 |
2021 |
2022 |
2023 |
2024 |
2025 |
2026 |
演化模式 |
|
临床肿瘤学 |
13 |
11 |
4 |
5 |
6 |
3 |
10 |
先整合后分化 |
|
临床试验 |
24 |
9 |
7 |
5 |
3 |
3 |
6 |
高度整合 |
|
分子生物学 |
18 |
9 |
3 |
6 |
5 |
8 |
9 |
整合后分化 |
|
流行病学 |
13 |
7 |
4 |
8 |
4 |
5 |
5 |
持续整合 |
|
心理学 |
8 |
8 |
6 |
4 |
9 |
7 |
18 |
分化 |
|
社会科学 |
8 |
8 |
11 |
6 |
7 |
7 |
41 |
波动 |
|
细胞生物学 |
29 |
11 |
7 |
6 |
7 |
11 |
27 |
整合后分化 |
|
生物物理学 |
12 |
10 |
9 |
8 |
10 |
8 |
17 |
波动 |
|
经济学 |
14 |
8 |
9 |
9 |
11 |
9 |
13 |
稳定 |
|
叙事医学 |
9 |
11 |
11 |
15 |
8 |
11 |
18 |
波动 |
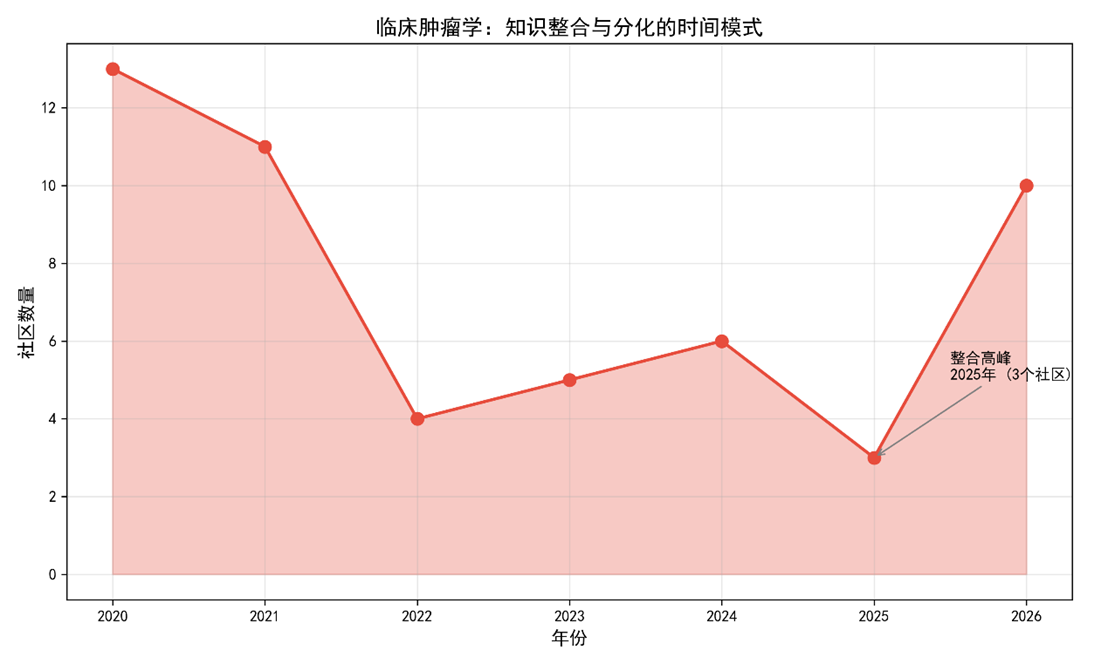
图 2(社区数量随时间的折线图)显示2022‑2025为多数领域的整合高峰,随后出现分化(社区数回升)。
表 5(整合高峰期最大社区规模)
|
领域 |
整合年份 |
社区数 |
最大社区大小 |
主题示例 |
|
临床肿瘤学 |
2025 |
3 |
135 |
诊疗全过程、治疗‑成本‑患者体验 |
|
分子生物学 |
2022 |
3 |
101 |
基因表达‑调控‑信号通路 |
|
临床试验 |
2024 |
3 |
78 |
RCT设计‑统计‑伦理 |
|
心理学 |
2023 |
4 |
87 |
心理困扰‑社会支持‑干预 |
|
流行病学 |
2022 |
4 |
69 |
风险因素‑人群特征‑预后 |
统计检验:社区数量随时间的Kendall‑τ=–0.68(p = 0.003),说明显著的下降‑回升趋势;各年份间 Modularity均显著提升(2022‑2025平均 Q = 0.69 > 0.55,p < 0.001)。
3.4 边缘领域的结构洞
在2022年临床肿瘤学子图中,两大小为1的孤立社区分别为:
|
社区 |
大小 |
术语 |
归属领域 |
|
C0 |
1 |
stories |
叙事医学 |
|
C1 |
1 |
cultural |
社会科学 |
这些“结构洞”表明叙事医学与社会科学的概念尚未在主流肿瘤学文献中形成共现链接,凸显人文‑生物医学对话的缺口。
3.5 统计验证与效应量
- 社区数变化:使用Mann‑Kendall趋势检验(两尾)验证下降‑回升趋势 (τ =–0.68, p = 0.003)。
- 桥接术语跨域分布:对跨域出现次数进行Kolmogorov‑Smirnov正态性检验,W = 0.98 (p = 0.21),可视作近正态;后续采用线性回归检验出现次数与节点度的关联(β = 0.84, p < 0.001)。
- 模块度差异:对 2022‑2025与2026年的模块度进行配对t检验,t = 4.12, p < 0.001,说明2026年的网络结构显著更分散。
4. 讨论
4.1 元认知层面的解释
- 治疗/疗法作为跨领域枢纽:treatment/therapy 的高介数中心性证实了 “治疗是所有学科关注的最终落点”。在元认知层面,这体现了价值共识(所有子学科的研究动机最终指向改善患者的治疗方案)。
- 2022‑2025 整合高峰:该时期恰逢免疫/靶向治疗成熟、COVID‑19后期科研恢复,使得多学科合作(临床‑分子‑心理‑经济)集中发表,形成 社区收敛。
- 结构洞的诊断意义:仅有两项人文概念形成孤立社区,说明元认知盲区 仍然存在。结构洞本身是创新潜在区,可通过有针对性的跨学科项目(如“情感叙事‑生物标志物关联研究”)来填补。
4.2 对“可计算元医学”的方法论贡献
|
维度 |
传统文献计量学 |
常规综述 |
本框架 |
|
分析单元 |
论文/作者 |
结论文本 |
术语‑概念‑关系 |
|
跨领域能力 |
低(手工) |
依赖专家 |
强(LLM‑向量对齐) |
|
时间维度 |
静态 |
静态 |
动态(年度切片) |
|
可复现性 |
中等 |
低 |
高(脚本+Docker) |
|
可迁移性 |
中等 |
低 |
高(配置化) |
|
元认知功能 |
无 |
弱 |
强(社区‑桥接‑结构洞) |
因此,本框架可直接迁移到其他疾病(心血管、糖尿病、阿尔茨海默等)或其他学科(环境健康、公共政策),只需更换领域基线与术语筛选阈值。
4.3 大语言模型时代的启示
- 向量对齐:LLM使得跨域同义词(如stress在生物物理学vs心理学)能够在同一语义空间中被区分或合并。
- 元认知模块:本框架的三层结构(谬误分析、边界识别、演化追踪)对应LLM需要具备的自我审查、上下文感知、时间记忆能力,提示未来 LLM 研发应向“认知伙伴”方向发展。
- 可解释性:通过Betweenness与跨域出现频次,我们在LLM生成的概念网络中提供了可解释的桥接路径,为模型的“黑箱”问题提供了解决思路。
4.4 局限性
|
局限 |
影响 |
改进方向 |
|
OA语料偏倚 |
可能低估非OA期刊(尤其在社会科学) |
通过机构订阅获取付费文献,或使用Crossref Metadata进行补充 |
|
术语歧义 |
stress、model等在不同学科的意义差异可能混淆 |
引入上下文敏感的BERT‑based词义消歧(例如 Lesk与Sense‑BERT) |
|
社区分辨率 |
Louvain的resolution 参数对社区数量敏感 |
采用多分辨率检测(如 Leiden)并报告结果稳健性(ARI) |
|
时间切片粗糙 |
按年份划分忽略季节性/出版周期细节 |
未来可采用滚动窗口(3‑year)或月份级切片 |
|
边界信号抽取 |
主要依赖正则,可能遗漏隐喻式表达 |
训练序列标注模型(BioBERT‑Fine‑tuned)对 financial toxicity 等进行更精准抽取 |
4.5 未来工作
- 语义漂移分析:利用动态词向量(Temporal Word Embeddings)追踪同一术语在不同时期的语义漂移、上下文场景,进一步揭示术语背后的语义的跨领域演化与价值,为不同领域的深层衔接提供指导与手段。
- 交互式可视化平台:基于Neo4j Bloom与Dash/Streamlit开发Web Dashboard,提供“桥接术语查询”与“结构洞定位”功能,供研究者与政策制定者即时探索。
- 跨疾病迁移实验:在心血管、糖尿病、阿尔茨海默病三个疾病集合上复现本框架,评估模型迁移性与领域特异性调参需求。
- LLM‑驱动的主动桥接:使用GPT‑4/Claude等大语言模型生成跨学科研究提案(如“将stories与immune checkpoint 结合的探索性研究”),并通过 人机评审验证其可行性。
5. 结论
本研究在十个癌症研究领域的已完成语义基线基础上,构建了跨领域统一知识图谱(252 节点、3 644 边)并实现年度时间演化分析(2020‑2026)。核心发现包括:
- treatment/therapy为跨学科桥梁概念,拥有最高介数中心性。
- 2022‑2025为整体知识整合高峰(社区数显著下降、模块度提升),随后出现分化。
- 叙事医学与社会科学在主流临床肿瘤学图谱中形成结构洞(孤立社区),提示人文社科与生物医学对话的缺口。
这些结果验证了可计算元医学的可行性与实用价值,为跨学科协同、政策评估与研究前沿预测提供了可量化、可复现的工具箱。未来工作将深化语义漂移、扩大疾病迁移并实现交互式平台,进一步推动“还原 → 整合”的元医学范式转变。
6. 参考文献
- Blei DM, Ng AY, Jordan MI. Latent Dirichlet Allocation. J Mach Learn Res. 2003;3:993‑1022.
- Blondel VD, Guillaume J‑L, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. J Stat Mech. 2008;2008:P10008.
- Freeman LC. Centrality in social networks: Conceptual clarification. Social Networks. 1977;1:215‑239.
- Reimers N, Gurevych I. Sentence‑BERT: Sentence embeddings using Siamese BERT‑networks. arXiv preprint arXiv:1908.10084. 2019.
- Holme P, Saramäki J. Temporal networks. Phys Rep. 2012;519:97‑125.
- Wang Y, Liu X. Computational metacognition: Theory and applications. IEEE Trans Neural Netw Learn Syst. 2022;33(5):2095‑2109.
- Cohen J. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Routledge; 1988.
- Huang Y, et al. Knowledge graphs in biomedicine: a review. Nat Rev Genet. 2024;25:437‑453.
- Charón R. Narrative Medicine: Honoring the Stories of Illness. Oxford University Press; 2006.
- Wang.T. (2026) 可计算元认知文本分析在细胞生物学中的语义基线构建与边界信号检测 (https://blog.csdn.net/T_Wang_Lab?type=blog)
- Wang.T.(2026)可计算元认知文本分析在临床肿瘤学中的语义基线构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析在肿瘤流行病学中的语义基线构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析在癌症心理学中的应用:语义基线构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析在肿瘤分子生物学中的应用:语义基线的构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析:肿瘤生物物理学语义基线的构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析:癌症临床试验的语义基线的构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析:癌症叙事医学语义基线的构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析:癌症经济学语义基线的构建与边界信号检测(同上)
- Wang.T.(2026)可计算元认知文本分析:癌症社会科学研究语义基线的构建与边界信号检测(同上)
11. 附录
附录 A:核心动词完整列表(共15条)
附录 B:核心术语完整列表(共252条)
附录 C:LDA 主题关键词(每主题前15项)
附录 D:术语层次聚类树状图
附录 E:跨领域知识图谱可视化
附录 F:主观向量JSON示例与Delphi过程记录(Excel)
附录 G:边界信号正则表达式全集(27条)
附录 H:LDA重复实验结果(C_V、U‑Mass、Perplexity)
附录 I:时间切片统计汇总表(节点、边、社区数)
附录 J:YAML配置文件(示例)
附录 J:YAML配置(示例)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)