(Arxiv-2025)InstructX: 基于MLLM引导的统一视觉编辑
InstructX: 基于MLLM引导的统一视觉编辑
paper title:InstructX: Towards Unified Visual Editing with MLLM Guidance
paper是字节跳动发布在Arxiv 2025的工作
Code:链接

摘要
随着多模态大语言模型(MLLM)在强大的视觉理解和推理方面展现出最新进展,人们对利用它们来提升扩散模型编辑性能的兴趣日益增长。尽管进展迅速,大多数研究缺乏对MLLM设计选择的深入分析。此外,MLLM与扩散模型的整合在一些困难任务(如视频编辑)中仍然是一个开放性挑战。在本文中,我们提出了InstructX,一个用于图像和视频编辑的统一框架。具体而言,我们对整合MLLM和扩散模型进行指令驱动编辑的多种任务进行了全面研究。基于这项研究,我们分析了统一建模中图像和视频之间的协作与区别。(1) 我们展示了在图像数据上训练可以在没有显式监督的情况下涌现视频编辑能力,从而缓解了稀缺视频训练数据带来的约束。(2) 通过结合模态特定的MLLM特征,我们的方法在单一模型中有效地统一了图像和视频编辑任务。大量实验表明,我们的方法能够处理广泛的图像和视频编辑任务,并达到最先进的性能。
1 引言
最近的研究表明,开发将多模态理解与生成整合的统一模型是一个日益增长的趋势。例如,文本到图像生成Xie et al. (2024); Zhou et al. (2024); Chen et al. (2025a),图像编辑Deng et al. (2025); Lin et al. (2025); Liu et al. (2025); Wu et al. (2025)以及视频编辑Liang et al. (2025); Wang et al. (2024a); Yu et al. (2025),都取得了令人印象深刻的成果。然而,如何有效地将多模态大语言模型(MLLM)与扩散模型整合,从而利用其理解和推理能力来辅助视觉编辑任务,仍然是一个开放性问题。
典型的整合范式包括:(1) 使用离散视觉分词器的自回归视觉生成Chen et al. (2025b); Lu et al. (2023); Qu et al. (2025) Lee et al. (2022); Yu et al. (2021),(2) 在单一transformer中统一文本自回归损失和视觉扩散损失的混合AR-扩散方法Zhou et al. (2024); Ma et al. (2025b); Shi et al. (2024a); Deng et al. (2025),以及(3) 使用MLLM骨干网络结合外部扩散模型作为视觉解码器Dong et al.; Ge et al. (2024); Sun et al. (2024); Pan et al. (2025)。在本文中,我们采用外部扩散模型框架,因为它通常收敛快、所需改动最小,且能提供有竞争力的性能。尽管已有一些视觉编辑工作在此范式下开发Lin et al. (2025); Wu et al. (2025); Liu et al. (2025); Yu et al. (2025),但MLLM在编辑流程中的角色尚未得到充分研究。最近,MetaQuery Pan et al. (2025)引入了一组可学习查询,作为MLLM和扩散模型之间的接口。此外,MetaQuery在MLLM和扩散模型之间使用了一个大型连接器(1.6B参数),同时保持MLLM参数固定。然而,关于MLLM与扩散模型在编辑任务中的最优整合方式,尚未达成共识。具体而言,关于几个关键设计选择的争论仍在持续:是直接利用所有最后隐藏状态还是将其压缩为元查询特征;连接器应该是大型transformer还是小型多层感知器(MLP)就已足够;以及MLLM本身是否需要微调。在本文中,我们进行了全面的研究并验证了一个核心假设:为了充分利用MLLM的理解能力,不应将其仅作为特征提取器;相反,编辑应主要在MLLM内部实现,而非委托给后续的大型连接器。
收集高质量视频数据仍然是视频编辑的瓶颈。早期工作Qi et al. (2023); Cong et al. (2023); Wu et al. (2023)通过零样本策略执行视频编辑,但它们在生成质量和泛化能力方面常常受限。其他方法Ku et al. (2024); Ouyang et al. (2024); Mou et al. (2024)通过编辑第一帧并传播变化来将图像编辑能力转移到视频,这容易导致内容漂移和损失。最近,一些方法Ye et al. (2025b); Zi et al. (2025b)试图通过训练视频编辑专家模型来构建视频编辑数据集;然而,这些方法受到冗长数据构建流程和低成功率的困扰。注意到最近的商业模型(如GPT-4o OpenAI)已经为指令式图像编辑设立了新标准,我们利用由这些模型生成的大规模、高质量图像编辑数据来支持视频编辑。这种方法同时解决了视频编辑数据的稀缺性和编辑类型范围狭窄的问题。具体而言,我们在图像和视频数据的混合上进行训练,并结合模态特定的MLLM特征,在单一模型中统一图像和视频编辑。我们观察到,从图像数据中学习到的编辑能力可以在没有显式监督的情况下有效迁移到视频编辑。
总结而言,本文做出以下贡献:
-
我们提出了一个在单一模型中执行图像和视频编辑的统一框架。我们的研究分析了MLLM与扩散模型的整合,并为未来研究提供了见解。
-
我们讨论了一种通过图像训练数据扩展零样本视频编辑能力的简单而有效的方法。这种设计使我们的方法能够处理比现有开源或闭源方法更广泛的任务。
-
大量实验表明,我们的方法在多样的图像和视频编辑任务上实现了最先进的性能。
2 相关工作
2.1 指令式图像和视频编辑
文本引导的图像编辑通过自然语言命令使用户能够修改图像,显著提升了视觉操作的便利性。早期方法Nam et al. (2018); Li et al. (2020); Fu et al. (2020)主要依赖GAN框架Goodfellow et al. (2020),往往受到有限真实感和狭窄领域适用性的约束。扩散模型的出现Ho et al. (2020)使基于文本的高质量图像编辑成为可能。早期工作从合成的输入-目标-指令三元组中学习Brooks et al. (2023),并通过额外的人类反馈Zhang et al. (2024b)来遵循编辑指令。Fu et al. (2023)研究了MLLM如何促进编辑指令的理解。最近,随着MLLM在规模和指令理解方面展现出更强的能力,多种统一建模方法Lin et al. (2025); Liu et al. (2025); OpenAI; Zeng et al. (2025)被提出,提升了图像编辑的性能。
在视频编辑方面,挑战显著增大。受模型能力和训练数据的限制,早期研究Qi et al. (2023); Cong et al. (2023); Wu et al. (2023)主要依赖基于图像扩散模型的零样本或单样本方法。后来,随着视频扩散模型性能的提升,多个下游任务涌现,利用预训练的视频扩散模型。例如视频修复Zi et al. (2025c); Bian et al. (2025),视频虚拟试穿Fang et al. (2024); Zuo et al. (2025),以及视频物体添加Tu et al. (2025); Zhuang et al. (2025)。最近,一些统一建模方法Liang et al. (2025); Yu et al. (2025); Ye et al. (2025b)被提出用于视频编辑。然而,这些方法受到手动先验的约束,如指定编辑区域和运动轨迹。指令式编辑提供了更便捷的方式。早期研究InsV2V Cheng et al. (2023)采用图像指令编辑模型Brooks et al. (2023)来生成视频训练对。然而,由于数据质量的局限性,编辑结果往往不尽如人意。最近的研究Tan et al. (2025)将MLLM的理解能力整合到视频编辑中。然而,模型设计往往缺乏实验验证或只是简要说明,且任务范围受训练数据限制。
2.2 统一理解与生成模型
最近,大量工作试图将多模态理解的成功扩展到多模态生成。一些工作学习回归图像特征Ge et al. (2024); Sun et al. (2023); Tong et al. (2024);一些工作自回归地预测下一个视觉token Jin et al. (2023); Team (2024); Xie et al. (2024);还有一些工作Zhou et al. (2024); Ma et al. (2025b); Shi et al. (2024a); Deng et al. (2025)采用扩散目标进行视觉生成和自回归目标进行文本生成。在这个领域中,使用连接器Dong et al.; Ge et al. (2024); Sun et al. (2024)来桥接理解模型和扩散模型是实现快速收敛的一种策略,同时也能提供有前景的结果。最近关于MetaQuery Pan et al. (2025)的工作通过一组可学习查询引入了有用的桥接方法。然而,对于视觉编辑,多个问题浮现:是否直接使用所有最终隐藏状态或将其压缩为元查询;是否需要大型连接器;以及冻结MLLM是否足够。我们在本文中研究这些问题。
3 方法
3.1 概述
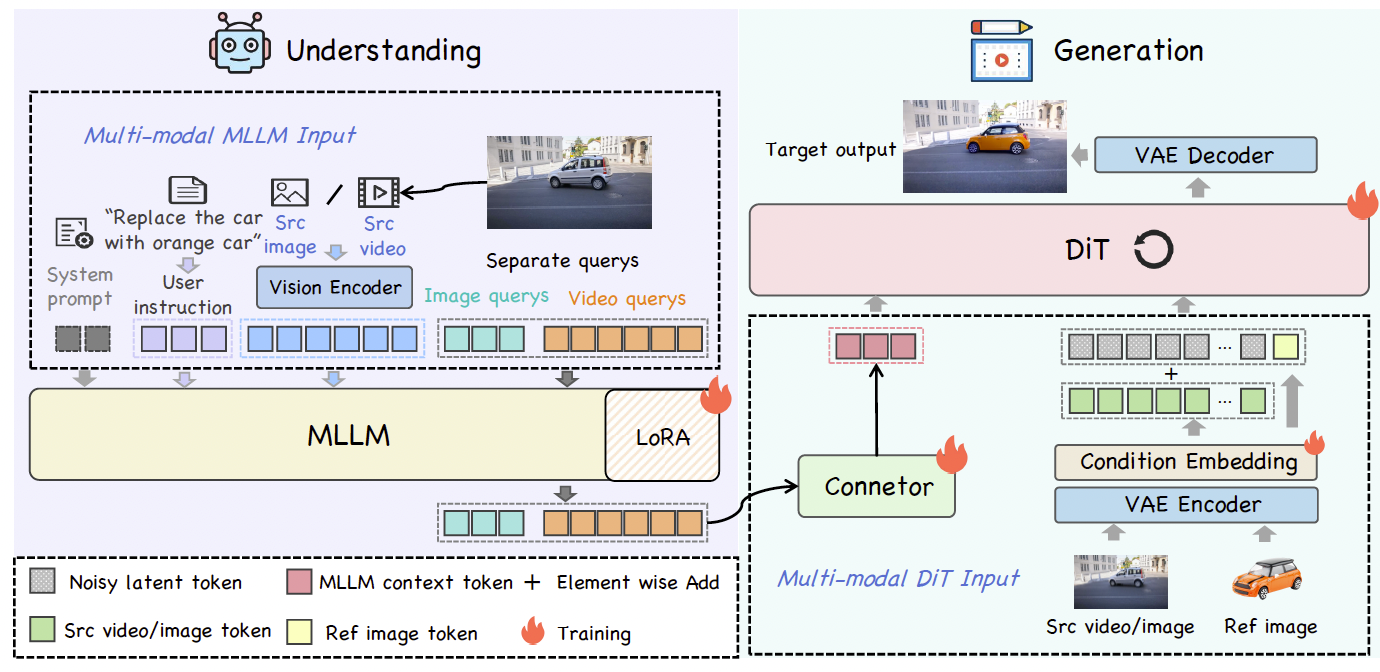
InstructX的概述如图2所示。回顾我们的目标是通过利用MLLM的理解能力,构建一个用于图像和视频编辑的统一架构。为此,我们使用多模态理解模型,即QWen2.5-VL-3B Bai et al. (2025),来嵌入编辑指令和源图像/视频。受MetaQuery Pan et al. (2025)启发,我们在MLLM输入序列后附加一组可学习查询来提取编辑信息,并仅保留MLLM输出中的元查询特征。Wan2.1-14B Wan et al. (2025)被用作编辑输出的解码器。MLLM产生的查询被送入两层MLP连接器,随后用于替换DiT模型中的文本嵌入。为了增强编辑结果与源图像/视频之间的一致性,我们将源图像/视频的VAE编码添加到噪声潜变量中。对于涉及参考图像的任务,我们将参考图像的VAE特征沿序列维度拼接到噪声潜变量中。
3.2 架构选择
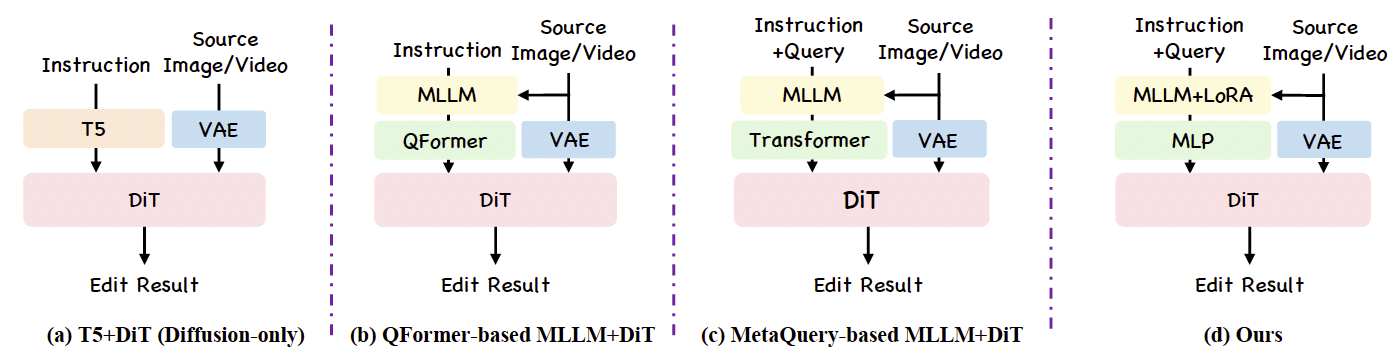
不同选择。如上所述,整合理解和生成模型暴露了许多设计选择,而这些选择在先前工作中往往缺乏经验验证。我们对这些结构设计选择进行了全面研究。在图3中,我们比较了几种指令编辑架构:(a) 指令由原生T5文本编码器Chung et al. (2024)编码并直接输入扩散模型,即仅扩散设置。(b) MLLM的最后隐藏状态由QFormer Li et al. (2023)编码为固定长度表示(即256个token),然后作为DiT的输入。© MetaQuery Pan et al. (2025)结构使用可学习查询从MLLM中提取编辑信息,并使用大型连接器来桥接MLLM和DiT。(d) 本工作采用的架构。它使用与MetaQuery相同的可学习查询,微调MLLM LoRA,并使用简单的两层MLP作为MLLM和DiT之间的连接器。
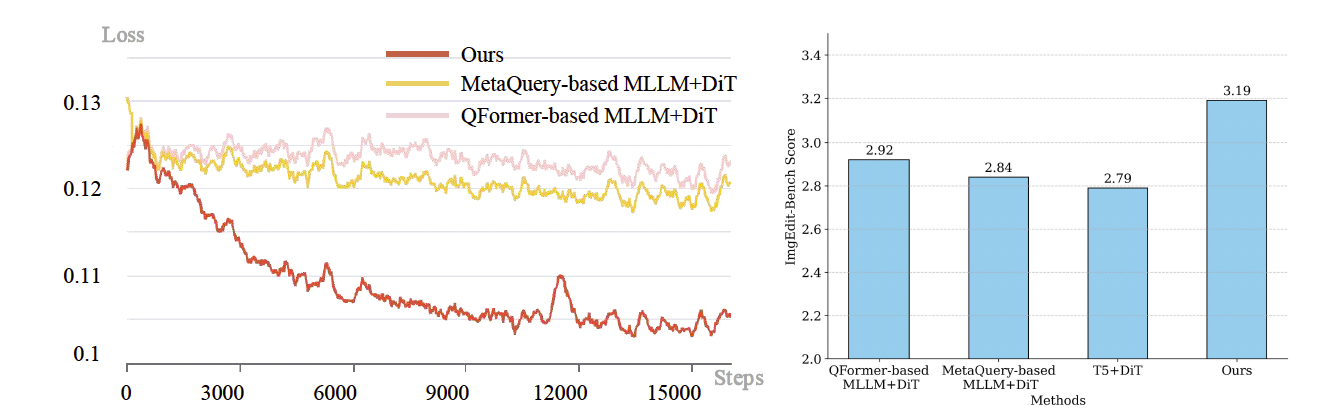
比较。我们从两个方面验证不同结构选择的性能。(1) 特征对齐能力。由于MLLM文本空间和扩散生成空间之间存在差距,先前工作Dong et al.; Ge et al. (2024)通常引入预训练阶段来对齐这两个空间。在此,我们冻结DiT并在图像编辑任务上训练不同设计。图4的左部分显示,仅依赖大规模连接器或可学习查询机制进行理解-生成对齐的收敛速度较慢。通过LoRA Hu et al. (2022)部分参与MLLM的特征对齐加速了收敛。注意T5特征已经与DiT对齐,因此不参与此阶段。在对齐阶段完成后,我们解冻DiT进行继续训练,并在ImgEdit-Bench Ye et al. (2025a)上评估各方法的性能。图4的右部分也展示了本文设计选择的优势。我们还在附录A.4中对MLLM的增益进行了进一步讨论。
其他细节。此外,为了在统一架构中对图像和视频进行建模,同时区分两种模态,我们为每种模态引入了独立的可学习查询集:图像输入256个查询,视频输入512个查询。注意对于视频输入,我们具体采样13帧作为MLLM的输入。更多实验细节见第4.4节。
3.3 训练策略
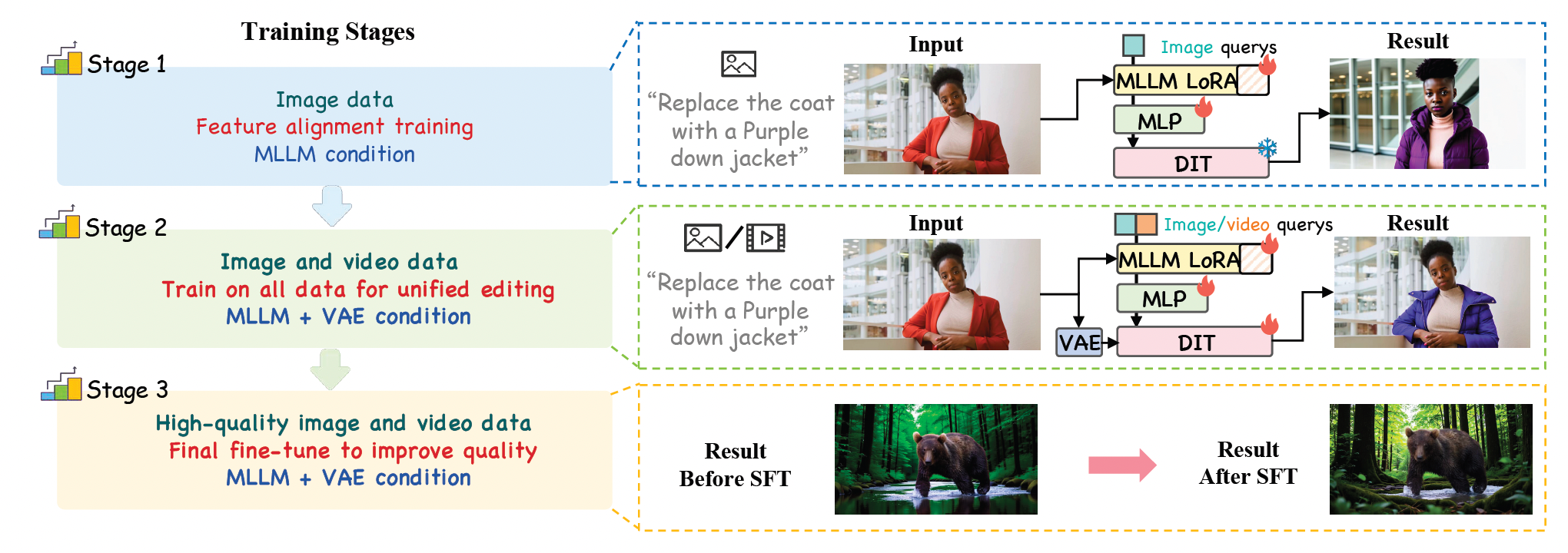
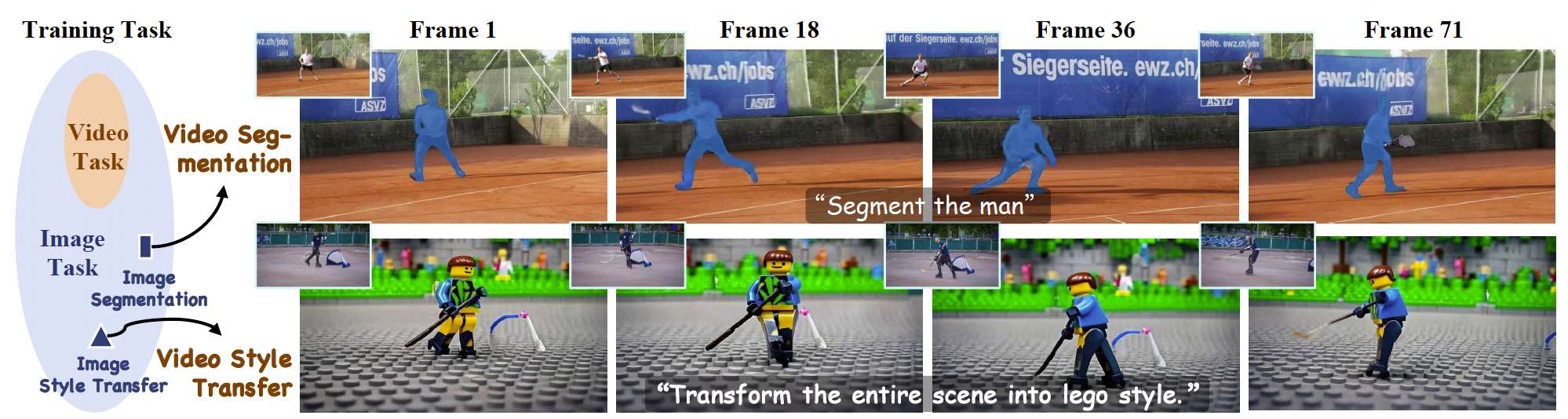
三个阶段。如图5所示,训练过程分为三个阶段:特征对齐训练、全数据训练和质量微调。第一阶段:第一阶段的目标是将MLLM的特征空间与DiT的生成空间对齐。在此阶段,我们仅在图像指令数据上训练可学习查询、MLLM中的LoRA和MLP连接器。此阶段后,模型获得了粗略的基于指令的编辑能力。然而,由于MLLM中视觉信息的粗粒度,编辑结果与原始图像的一致性较差。第二阶段:第二阶段有两个目标:(1) 通过引入VAE特征来提高编辑结果与原始视觉输入之间的保真度,(2) 通过全数据训练使模型获得统一和泛化的图像/视频编辑能力。在此阶段,我们训练可学习查询、MLLM中的LoRA、MLP连接器和整个DiT。注意,在此阶段混合图像和视频训练不仅允许单一模型进行统一建模,还通过利用图像数据激发了难以从视频数据中获取的视频编辑能力。如图6所示,视频数据中缺失但图像数据中存在的分割和风格迁移任务。经过混合训练后,模型也获得了视频风格迁移的能力。第三阶段:尽管模型在第二阶段后获得了统一的图像/视频编辑能力,但生成质量受到一些低质量训练数据的影响,导致油腻和塑料感的纹理。为解决这个问题,我们收集少量高质量训练数据并进行质量微调。如图5最后一行所示,经过质量微调后,生成结果变得更加自然和美观。我们在所有阶段使用流匹配Lipman et al. (2022)作为训练目标。
训练数据。对于基于指令的图像编辑,我们利用大规模开源训练数据,包括NHR-Edit Kuprashevich et al. (2025)、X2Edit Ma et al. (2025a)和GPT-ImageEdit Wang et al. (2025b)。对于视频编辑,由于缺乏高质量开源视频编辑数据,我们开发了一个合成视频编辑数据的流水线。更多细节见附录A.2。
4 实验
4.1 实现细节
训练时,我们将学习率设为 1 × 10 − 5 1 \times 10^{-5} 1×10−5,图像全局批量大小为128,视频为32。在第一和第二训练阶段,我们各迭代20,000步,而第三阶段涉及5,000次迭代。在图像/视频混合训练期间,我们以0.6的概率采样视频数据,0.4的概率采样图像数据。
4.2 评估细节
对于图像编辑,我们在两个基准上比较不同方法:ImgEdit-Bench Ye et al. (2025a)和GEdit-Bench Liu et al. (2025)。具体而言,在ImgEdit-Bench上,我们使用GPT-4.1 OpenAI以1-5分制对编辑结果进行评分。在GEdit-Bench上,我们使用Qwen2.5-VL-72B Bai et al. (2025)在三个指标上评估编辑结果:指令遵循分数(Q_SC)、感知质量分数(Q_PQ)和综合分数(Q_O)。我们将我们的方法与知名的基于指令的图像编辑方法(即InstructPix2Pix Brooks et al. (2023))、最近的最先进方法(即OmniGen Xiao et al. (2025)、UniWorld Lin et al. (2025)、Step1x-Edit Liu et al. (2025)、Bagel Deng et al. (2025))以及多个闭源模型(GPT-4o OpenAI、DouBao Shi et al. (2024b))进行比较。
对于视频编辑,现有基准(如UNICBench Ye et al. (2025b)和VACE-Benchmark Jiang et al. (2025))主要关注目标-提示匹配而非基于指令-提示的评估,且每个任务仅提供少量样本。为解决基于指令的视频编辑基准的不足,我们引入了VIE-Bench,它包含140个高质量实例,涵盖八个类别的无参考和有参考编辑。更多细节见附录A.1节。先前工作通常使用CLIP文本分数来评估文本-视频对齐,这对目标提示设置有效,但无法捕获指令遵循能力。因此,我们采用基于MLLM的评判器,使用GPT-4o OpenAI来评估编辑准确性(指令遵循)、保留度(与源视频的一致性)和质量(整体视频质量)。对于基于参考的编辑,GPT-4o还评估与参考图像的主题相似度。所有分数范围从1到10。基于MLLM评判器的系统提示见附录A.5节。此外,我们使用VBench Zhang et al. (2024a)来评估视频质量。我们将我们的方法与知名基线方法进行比较。


表1: GEdit-Bench上的比较结果。Q_SC、Q_PQ和Q_O指由Qwen-2.5-VL-72B评估的指标。最佳和次佳结果分别以粗体和下划线显示。
| 模型 | 社区模型 | Q_SC↑ | Q_PQ↑ | Q_O↑ |
|---|---|---|---|---|
| Ours | ✓ | 7.47 | 7.22 | 6.68 |
| Step1X-Edit | ✓ | 7.05 | 7.21 | 6.79 |
| Instruct-P2P | ✓ | 5.08 | 6.86 | 4.90 |
| OmniGen | ✓ | 6.33 | 6.96 | 6.04 |
| UniWorld | ✓ | 5.43 | 7.37 | 5.35 |
| Bagel | ✓ | 7.43 | 7.03 | 7.10 |
| SeedEdit 3.0 | ✗ | 7.92 | 7.39 | 7.57 |
| GPT-4o | ✗ | 7.98 | 7.73 | 7.83 |
表2: ImgEdit-Bench上的比较结果。"Overall"通过对所有分数取平均计算。最佳和次佳结果分别以粗体和下划线显示。
| 模型 | 社区模型 | Adjust | Remove | Replace | Add | Style | Compose | Background | Action | Overall↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Ours | ✓ | 3.56 | 3.92 | 4.03 | 3.7 | 4.45 | 3.27 | 3.63 | 4.24 | 3.85 |
| Step1X-Edit | ✓ | 3.27 | 3.13 | 3.91 | 2.75 | 4.53 | 2.38 | 3.67 | 3.48 | 3.39 |
| Instruct-P2P | ✓ | 2.53 | 1.11 | 1.50 | 1.89 | 3.44 | 1.61 | 1.65 | 2.35 | 2.01 |
| OmniGen | ✓ | 2.04 | 2.09 | 2.02 | 3.33 | 3.65 | 3.58 | 2.46 | 1.97 | 2.64 |
| UniWorld | ✓ | 2.95 | 3.54 | 2.64 | 4.04 | 3.33 | 2.91 | 3.07 | 2.55 | 3.13 |
| BAGEL | ✓ | 3.51 | 3.27 | 3.26 | 3.81 | 4.26 | 3.11 | 2.62 | 4.31 | 3.52 |
| SeedEdit 3.0 | ✗ | 2.43 | 4.27 | 4.33 | 4.40 | 4.51 | 4.32 | 3.58 | 4.62 | 4.06 |
| GPT-4o | ✗ | 4.15 | 4.54 | 4.49 | 4.84 | 4.63 | 4.30 | 4.87 | 4.22 | 4.51 |
InsV2V Cheng et al. (2023)、最近的最先进方法(VACE-14B Jiang et al. (2025)、Omni-Video Tan et al. (2025))和闭源系统(Kling Keling (2025)、Pika Pika (2025)、Runway-Aleph Runway (2025))进行比较。对于移除任务,我们还与MiniMax-Remover Zi et al. (2025a)和DiffuEraser Li et al. (2025)进行评估。
表3: VIE-Bench上的比较结果。最佳和次佳结果分别以粗体和下划线显示。
| 任务 | 方法 | 社区模型 | 基于指令 | 指令遵循 | 保留度 | 质量 | 相似度 | 平均 | 平滑度 | 美学 |
|---|---|---|---|---|---|---|---|---|---|---|
| 添加 | Ours | ✓ | ✓ | 8.446 | 8.683 | 7.919 | - | 8.349 | 0.991 | 0.558 |
| Kling | ✗ | ✓ | 6.000 | 8.250 | 5.576 | - | 6.602 | 0.988 | 0.519 | |
| Runway | ✗ | ✓ | 8.607 | 8.913 | 7.823 | - | 8.447 | 0.990 | 0.557 | |
| Omni-Video | ✓ | ✓ | 5.699 | 6.155 | 6.294 | - | 6.242 | 0.987 | 0.586 | |
| InsV2V | ✓ | ✓ | 3.552 | 5.891 | 3.402 | - | 4.281 | 0.988 | 0.513 | |
| VACE | ✓ | ✗ | 3.938 | 6.696 | 3.929 | - | 4.854 | 0.983 | 0.557 | |
| 交换/更改 | Ours | ✓ | ✓ | 9.514 | 9.171 | 8.533 | - | 9.072 | 0.977 | 0.557 |
| Kling | ✗ | ✓ | 9.000 | 9.060 | 8.333 | - | 8.800 | 0.989 | 0.541 | |
| Runway | ✗ | ✓ | 9.580 | 8.628 | 9.275 | - | 9.161 | 0.981 | 0.541 | |
| Pika | ✗ | ✓ | 7.542 | 7.847 | 6.837 | - | 7.408 | 0.974 | 0.528 | |
| Omni-Video | ✓ | ✓ | 4.733 | 4.856 | 4.656 | - | 4.748 | 0.981 | 0.556 | |
| InsV2V | ✓ | ✓ | 5.304 | 6.428 | 4.971 | - | 5.567 | 0.977 | 0.530 | |
| VACE | ✓ | ✗ | 6.171 | 7.552 | 6.199 | - | 6.640 | 0.976 | 0.534 | |
| 移除 | Ours | ✓ | ✓ | 8.627 | 8.668 | 7.672 | - | 8.322 | 0.983 | 0.472 |
| Kling | ✗ | ✓ | 8.440 | 8.800 | 7.520 | - | 8.253 | 0.993 | 0.455 | |
| Runway | ✗ | ✓ | 8.664 | 7.145 | 7.703 | - | 8.504 | 0.987 | 0.460 | |
| Omni-Video | ✓ | ✓ | 6.004 | 5.970 | 4.807 | - | 5.593 | 0.989 | 0.417 | |
| InsV2V | ✓ | ✓ | 1.209 | 3.769 | 1.322 | - | 2.098 | 0.982 | 0.517 | |
| VACE | ✓ | ✗ | 1.812 | 3.877 | 2.359 | - | 2.682 | 0.983 | 0.538 | |
| MiniMax | ✓ | ✗ | 6.963 | 7.518 | 6.037 | - | 6.839 | 0.985 | 0.467 | |
| DiffuEraser | ✓ | ✗ | 6.346 | 6.807 | 5.576 | - | 6.243 | 0.986 | 0.465 |
| 任务 | 方法 | 社区模型 | 基于指令 | 指令遵循 | 保留度 | 质量 | 相似度 | 平均 | 平滑度 | 美学 |
|---|---|---|---|---|---|---|---|---|---|---|
| 风格/色调变化 | Ours | ✓ | ✓ | 9.650 | 9.099 | 8.839 | - | 9.196 | 0.972 | 0.560 |
| Runway | ✗ | ✓ | 9.583 | 9.200 | 8.616 | - | 9.133 | 0.982 | 0.547 | |
| Omni-Video | ✓ | ✓ | 5.486 | 4.653 | 5.959 | - | 5.366 | 0.984 | 0.557 | |
| InsV2V | ✓ | ✓ | 7.835 | 8.086 | 6.437 | - | 7.452 | 0.971 | 0.529 | |
| 混合编辑 | Ours | ✓ | ✓ | 9.448 | 8.862 | 8.411 | - | 8.907 | 0.973 | 0.590 |
| Runway | ✗ | ✓ | 8.966 | 8.533 | 8.033 | - | 8.510 | 0.984 | 0.585 | |
| Omni-Video | ✓ | ✓ | 5.444 | 5.066 | 3.766 | - | 5.425 | 0.978 | 0.608 | |
| InsV2V | ✓ | ✓ | 5.033 | 5.966 | 4.966 | - | 5.321 | 0.975 | 0.541 | |
| 参考交换 | Ours | ✓ | ✓ | 9.210 | 9.201 | 8.221 | 9.190 | 8.955 | 0.978 | 0.549 |
| Kling | ✗ | ✓ | 8.830 | 8.910 | 8.120 | 8.510 | 8.592 | 0.988 | 0.522 | |
| Pika | ✗ | ✓ | 8.438 | 8.665 | 7.656 | 8.447 | 8.301 | 0.989 | 0.462 | |
| VACE | ✓ | ✗ | 8.312 | 8.542 | 7.442 | 7.654 | 7.987 | 0.976 | 0.550 | |
| 参考添加 | Ours | ✓ | ✓ | 9.491 | 9.252 | 8.375 | 9.511 | 9.157 | 0.987 | 0.595 |
| Kling | ✗ | ✓ | 9.714 | 9.571 | 8.714 | 9.285 | 9.321 | 0.992 | 0.567 | |
| Pika | ✗ | ✓ | 8.510 | 8.625 | 7.750 | 8.625 | 8.377 | 0.991 | 0.511 | |
| VACE | ✓ | ✗ | 2.665 | 6.540 | 3.052 | 3.636 | 3.973 | 0.987 | 0.561 |
4.3 比较结果
表1和表2分别展示了我们的方法与其他方法在GEdit-Bench Liu et al. (2025)和ImgEdit-Bench Ye et al. (2025a)上的比较结果。可以观察到,我们的方法在多个子任务上取得了有竞争力的性能,并在ImgEdit-Bench的整体分数方面优于其他开源方法。图7展示了在一些复杂场景中,例如从杂乱的蔬菜堆中移除西兰花,OmniGen Xiao et al. (2025)、UniWorld Lin et al. (2025)和Step1x-Edit Liu et al. (2025)等方法无法识别目标,而SeedEdit Shi et al. (2024b)和GPT-4o OpenAI则产生与原始图像缺乏一致性的编辑结果。我们的方法在保持一致性的同时实现了准确的移除。此外,我们的优势还体现在更干净的背景替换和更优越的风格一致性上。我们还在附录A.3中进行了用户研究。
表3显示,我们的方法在大多数指标上优于当前开源视频编辑模型,并与最先进的闭源方案保持竞争力。具体而言,我们的方法在所有方法中在风格/色调/天气变化、混合编辑和基于参考的交换任务上获得最高平均分,同时在添加、交换/更改和移除任务上仅略低于Runway Aleph,在基于参考的添加上仅略低于Kling。此外,我们的方法在多个细粒度评估维度上展现出领先优势。如图8所示,在细粒度局部编辑任务上,我们的方法实现了更高的准确性,而竞争方法要么在手持盒子替换上表现不佳,要么无法替换它。我们的方法在混合编辑中的风格迁移和指令遵循方面也表现出色。在基于参考的编辑中,我们输出中的背包与参考图像呈现更高的相似度。附录A.6节提供了额外的视觉比较,我们还在附录A.3中报告了用户研究。
4.4 消融研究
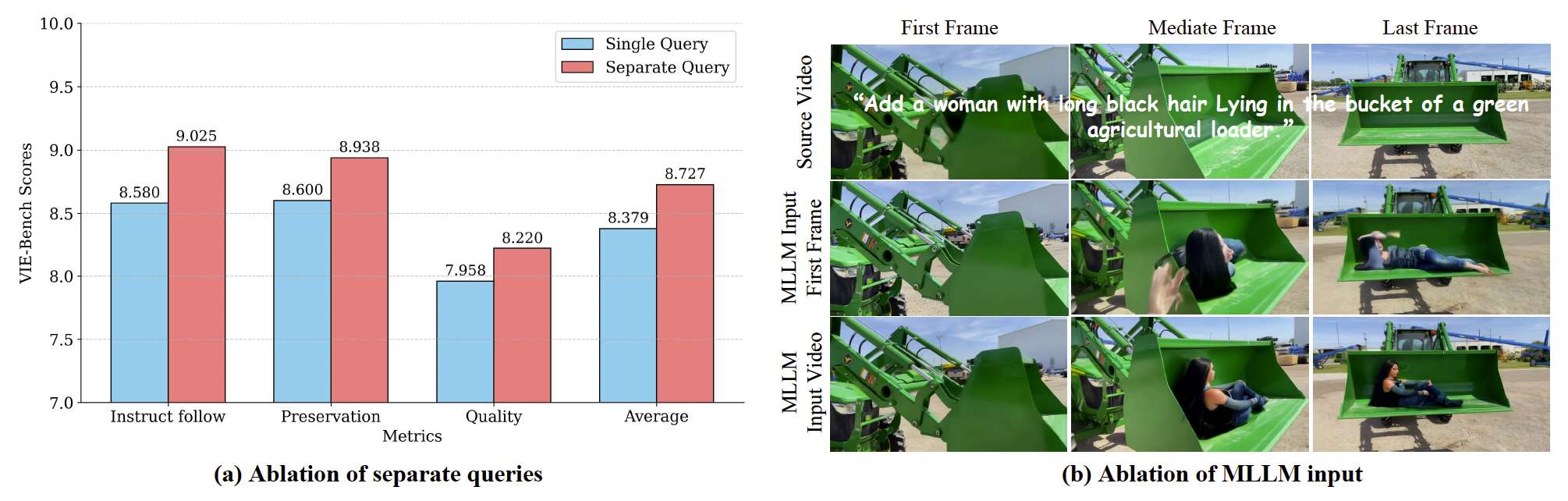
我们对统一图像和视频编辑的设计选择进行消融研究:(1) 是否分离图像和视频查询;(2) MLLM是否需要多帧视频输入。如图9(a)所示,分离查询设置在VIE-Bench上获得了更高的分数,因为它能更好地区分不同模态信息的特征提取。图9(b)显示,如果MLLM仅使用视频的第一帧来生成编辑引导,在一些复杂场景中(如编辑内容出现在视频中间时),编辑结果容易崩溃。
5 结论
在本文中,我们提出了InstructX,一个用于图像和视频编辑的统一框架。具体而言,我们对MLLM与扩散模型结合的设计进行了全面研究,最终选择了可学习查询、MLLM LoRA和MLP连接器的整合方式,实现了更快的收敛和更优越的性能。此外,我们探索了混合图像-视频训练,这不仅实现了图像和视频编辑的统一建模,还扩展了视频编辑任务的范围。另外,我们在统一框架中使用分离查询来更好地区分不同模态。我们还引入了一个基于MLLM的视频编辑基准VIE-Bench,包含140个高质量编辑实例,涵盖八个类别。大量实验表明,我们的方法优于最新的开源图像和视频编辑方法。特别是在视频编辑方面,InstructX达到了与一些闭源编辑方法相当的性能,同时支持更广泛的任务范围。
局限性 尽管InstructX展现了显著的性能和吸引人的训练效率,但它受到预训练视频DiT的约束,使得高分辨率(如>1080P)图像/视频编辑变得困难。尽管图像数据可以激发零样本视频编辑能力,但这并非直接解决方案。然而,它可以作为应对当前视频数据短缺的临时方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)