企业研发用 AI,如何避免幻觉?药企/新材料企业的实战指南
企业研发用 AI,如何避免幻觉?药企/新材料企业的实战指南
导读:当实验室的研究员用 AI 辅助文献分析、配方推演、实验设计时,AI 一本正经地编造不存在的文献、错误的分子式、虚假的实验数据——这就是 AI 幻觉(Hallucination)。在研发这个"一分一毫都关乎成败"的领域,AI 幻觉轻则浪费实验资源,重则误导研发方向。本文专为药企、新材料企业的实验室研发人员打造,提供系统性防御策略。
一、什么是 AI 幻觉?为什么研发场景更不能容忍?
1.1 AI 幻觉的本质
AI 幻觉(Hallucination),指大语言模型(LLM)生成的内容看似流畅合理,却与事实不符、引用不存在、或逻辑不自洽。典型表现包括:
| 幻觉类型 | 典型案例 | 研发场景风险 |
|---|---|---|
| 虚构引用 | AI 声称某论文发表于 Nature 2023,实际并不存在 | 误导文献综述方向 |
| 捏造数据 | AI 生成"实验表明转化率87%",实为编造 | 导致错误研发决策 |
| 虚假事实 | AI 声称某化学反应的活化能为 35 kJ/mol,文献查无此数据 | 配方设计失效 |
| 错误推理 | AI 推导出"A + B → C",实际反应路径不存在 | 浪费大量实验资源 |
1.2 为什么研发场景的幻觉代价更高?
消费级内容出错,顶多是"尴尬一下";但研发场景出 AI 幻觉,后果是真金白银的损失:
普通用户:用AI写文案,幻觉→ 修改 → 影响有限
研发人员:用AI分析文献,幻觉→ 方向错误 → 浪费数月+数十万实验成本
高风险场景特征:
- 需要引用具体文献、数据、法规
- 涉及配方、比例、工艺参数等精确信息
- 决策后果不可逆(实验一旦开始,时间资金成本就沉没了)
📌 [文献支撑点1]:检索"AI hallucination detection"、"LLM reliability research"相关研究,补充学术界对幻觉问题的量化评估数据。
二、预防层:从源头降低幻觉风险
2.1 选对模型——不是所有模型都一样
| 模型 | 幻觉率(相对基准) | 适用场景 | 注意事项 |
|---|---|---|---|
| GPT-4 / Claude 3 | 较低(推理能力强) | 复杂分析、多步推理 | 仍需验证 |
| GPT-3.5 / 通义/Qwen | 中等 | 基础信息整理 | 需严格审核 |
| 开源小模型 | 较高 | 简单任务 | 不建议用于关键决策 |
实战建议:
- 关键决策:使用 GPT-4 / Claude 等推理能力强的模型
- 信息整理:可用国产模型,但必须人工复核
- 避免在单一模型上做"一键完成所有分析"
📌 [文献支撑点2]:检索"大语言模型 幻觉率 对比"相关中文期刊论文,用数据支撑模型选择。
2.2 构建"AI研发助手"的正确Prompt框架
错误示范(容易产生幻觉):
帮我找一下关于XX靶点的最新研究进展
正确示范(结构化+约束):
## 任务
帮我总结近3年关于XX靶点的药物研发进展
## 要求
1. 只引用真实存在的文献,注明:DOI/期刊名/年份
2. 如某信息不确定,明确标注"待验证"
3. 数据类信息必须给出数据来源
## 格式
- 每条结论后用[文献]标注来源
- 区分:已验证事实 / 推测 / AI推断
2.3 限制AI的知识截止日期
在使用 AI 时明确告知:
当前对话的知识截止日期为2024年12月,
任何关于此后发表文献的描述均为不可靠信息。
三、验证层:建立研发级AI审核流程
3.1 “三明治验证法”——研发人员的AI使用规范
┌─────────────────────────────────────────┐
│ 第一层:AI生成 → 研究员自审 │
│ - 逐条核查关键数据、引用是否可验证 │
│ - 用专业文献数据库/PubMed核对关键文献 │
├─────────────────────────────────────────┤
│ 第二层:AI复核 → 让AI自我纠错 │
│ "请核实上述内容,指出哪些需要进一步确认"│
├─────────────────────────────────────────┤
│ 第三层:人工专家评审 → 最终把关 │
│ 由资深研究员/PI确认后,方可作为决策依据 │
└─────────────────────────────────────────┘
3.2 关键信息核查清单
每次使用 AI 辅助研发决策前,必须核查以下项目:
- 文献核查:AI引用的文献在专业文献数据库/PubMed中真实存在
- 数据溯源:AI给出的数值(IC50、Kd、转化率等)可追溯到原始文献
- 逻辑一致性:AI的推理链条无跳跃或自相矛盾
- 时效性:AI引用的法规、标准是否为最新版本
- 单位核对:AI给出的剂量、比例单位是否正确
3.3 AI辅助≠AI决策
核心原则:AI是助手,不是决策者
- AI负责:信息检索、初步分析、方案建议
- 人类负责:判断结论可靠性、做出最终决策、承担决策责任
四、防御技术:研发场景的AI幻觉检测工具
4.1 实时检测工具
| 工具/方法 | 功能 | 适用场景 |
|---|---|---|
| Self-Consistency(自洽性检测) | 让AI用不同方式回答同一问题,比较答案一致性 | 关键数据验证 |
| Chain-of-Thought Prompting | 强制AI展示推理过程 | 发现推理链错误 |
| 知识图谱校验 | 将AI输出与已有知识图谱比对 | 结构化信息验证 |
| 文献回溯验证 | 用专业文献数据库等工具自动验证AI引用的文献 | 引用核查 |
4.2 实战操作:让AI自己核查自己
Prompt示例:
你是一个严谨的科研助手,请对以下内容进行"严格审查":
[粘贴AI生成的内容]
审查维度:
1. 哪些引用/数据我可以验证?请列出可验证项
2. 哪些信息可能存在不确定性?请标注"风险点"
3. 是否有逻辑矛盾或推理跳跃?
📌 [文献支撑点3]:检索"AI hallucination mitigation techniques"、"RAG retrieval augmented generation"等最新技术文献,补充技术防御手段。
五、药企/新材料企业的落地建议
5.1 建立AI使用管理制度
建议企业层面制定:
## 研发AI使用规范(示例)
### 允许场景
- ✅ 文献检索初步筛选(需人工复核关键文献)
- ✅ 方案建议生成(需专家评审)
- ✅ 报告初稿撰写(需逐条核实数据)
### 禁止场景
- ❌ 直接生成实验配方用于实验(必须有文献/数据支撑)
- ❌ 直接引用AI生成的数据作为申报材料依据
- ❌ 用AI替代正规渠道获取法规/标准信息
### 审核流程
L1:研究员自审(所有AI生成内容)
L2:项目负责人复核(涉及决策/实验的内容)
L3:QA/合规审核(涉及注册/申报的内容)
5.2 按风险等级使用AI
| 任务风险等级 | 示例 | AI使用策略 |
|---|---|---|
| 🔴 高风险 | 配方直接实验、法规引用、申报材料 | 严格审核,AI仅辅助整理,人工最终确认 |
| 🟡 中风险 | 文献综述、方案讨论、技术报告 | AI辅助+交叉验证,关键引用人工核查 |
| 🟢 低风险 | 格式整理、语言润色、会议纪要 | AI可直接使用,但仍需通读确认 |
5.3 典型案例:AI辅助文献分析的正确姿势
场景:研究员需要了解"PROTAC在肝癌治疗中的最新进展"
错误流程:
AI快速生成"综述" → 直接用于PPT汇报 → 某关键文献被指出不存在 → 尴尬
正确流程:
1. AI生成初步文献清单(带DOI/标题)
2. 用专业文献数据库逐条验证文献真实性
3. 筛选真实存在的文献,手动获取摘要
4. AI辅助整理归类,但核心观点来自真实文献
5. AI生成PPT时,注明"基于XX篇验证文献整理"
六、技术方案探讨:如何让工具系统化防幻觉
前面的策略讲的是"人工+流程",但如果你每天要处理几十篇AI辅助生成的文献分析,纯人工核查效率太低。更好的思路是——构建一个从"文献发现"到"核查验真"再到"知识沉淀"的系统化工具链,让防幻觉从"靠个人经验"升级为"靠工具系统"。
6.1 三类工具:定位互补,形成闭环
理想的技术方案应包含三类能力,互相补充:
| 能力层 | 核心定位 | 解决什么问题 |
|---|---|---|
| 文献发现 | 集中的学术文献检索 | AI不再编文献,而是从真实文献库中检索 |
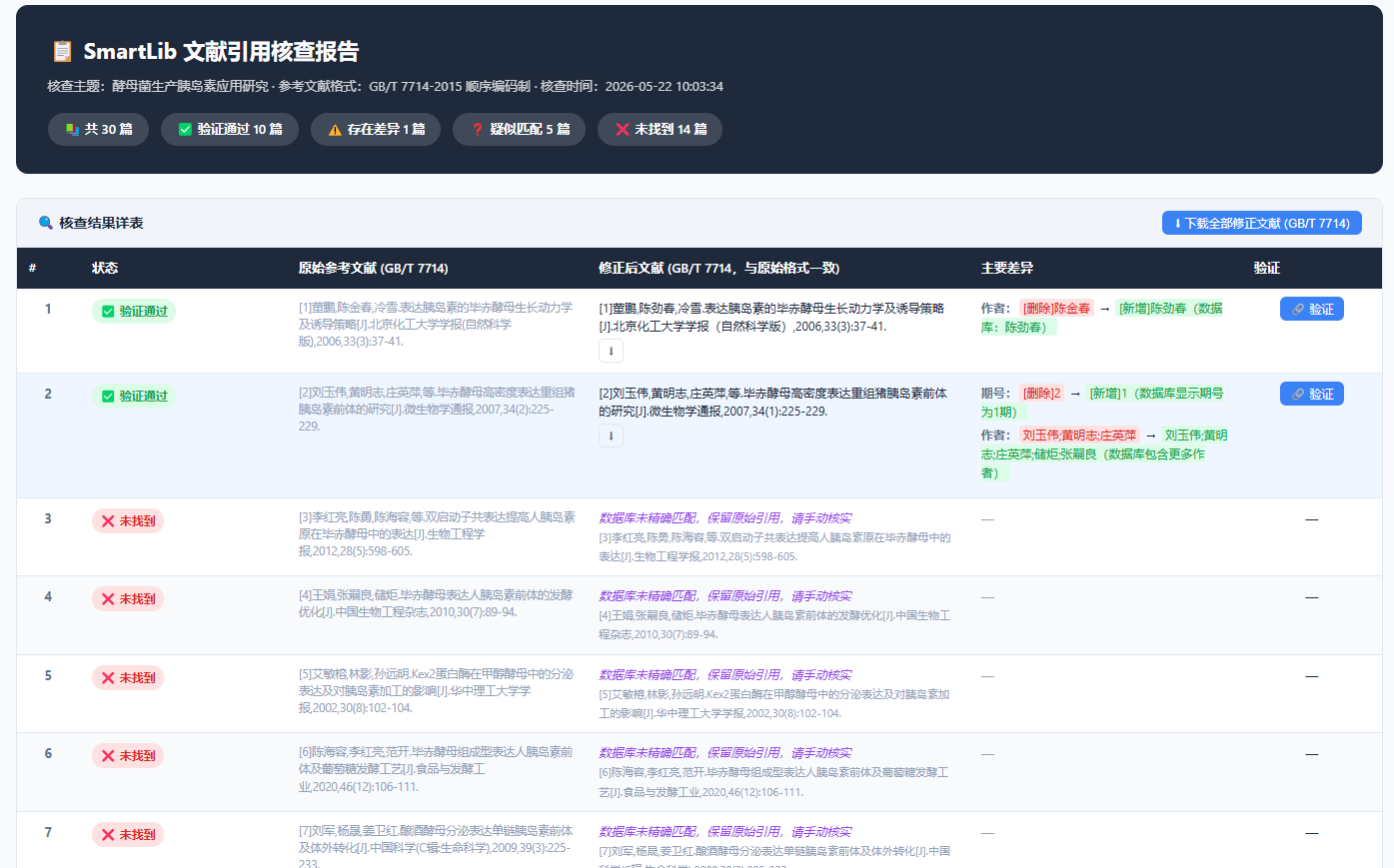
| 参考文献核查 | 多来源文献验真 | 一键验证引用是否真实,精准打击虚假文献 |
| 知识沉淀 | 资料管理与积累 | 管理已检索资料,减少重复搜索,越用越智能 |
核心逻辑:文献发现负责"找到真文献",核查验真负责"验证是不是真文献",知识沉淀负责"把真的管起来、下次不用再找"。 三者构成防幻觉的完整闭环。
相关参考实现:
- 文献发现:SmartLib 文献检索(腾讯 SkillHub)
- 参考文献核查:SmartLib 参考文献核查(腾讯 SkillHub)
- 知识沉淀:学术知识库(腾讯 SkillHub)
6.2 各能力层的技术要点
文献发现层:将真实文献库接入AI
核心思路:通过API将全球文献数据库(覆盖8000万篇中文期刊+12亿条全球文献元数据)接入AI助手。当AI帮你做文献调研时,检索结果天然来自真实文献源,从根源上消除"虚构引用"类幻觉。
应用场景:
场景:调研"PROTAC在肝癌治疗中的最新进展"
未接入文献库时:
→ AI凭训练数据"编"文献,可能3篇是假的
接入文献库后:
→ AI从真实文献库中检索
→ 每条引用都有真实的标题、作者、期刊、DOI
→ 可直接下载全文验证
技术实现要点:
- 文献API需支持关键词检索、分面筛选、全文下载等能力
- 在AI的Prompt中约束"只返回API检索到的结果,不得自行编造"
- 检索结果需缓存,避免重复调用
参考文献核查层:批量验证文献真实性
核心思路:对于AI生成内容中的参考文献、同事转来的文献列表、或从多个渠道收集的文献信息,通过API批量在文献数据库中逐条验证,输出差异标记和统计分析。
应用场景:
场景:用AI辅助写了一份文献综述初稿,引用了35篇文献
核查结果:
→ 28篇验证通过
→ 5篇信息有误:如作者名拼写错误、年份偏差
→ 2篇完全不存在:AI编造的虚假文献
→ 输出完整核查报告,附验证链接
技术实现要点:
- 支持多种引用格式解析(GB/T 7714、APA、MLA等)
- 并行检索提升效率(如8条/批)
- 差异标记需区分"完全不存在"和"信息有误"两种级别
知识沉淀层:建立私有学术知识库
核心思路:将检索到的文献、个人笔记、研究资料沉淀为可复用的私有知识库,支持向量化语义检索。下次遇到相似问题时直接从本地库中匹配,无需重复调用外部API——既省钱又提效。
应用场景:
场景:长期跟踪某新药研发方向的文献
知识库带来的价值:
→ 创建研究专题,每次检索到的相关文献自动归档
→ 个人实验笔记、会议记录也可入库
→ 语义搜索:"找一下我之前看过的关于靶点选择的那篇文献"
→ 自动生成文献引用关系图谱
技术实现要点:
- 需要向量数据库支持语义检索
- 外部文献库 + 内部私有库的双轨架构
- 支持文献子集管理和Wiki知识层自动维护
6.3 闭环工作流
┌──────────────────────────────────────────────────────────────┐
│ │
│ ① 文献发现 — 从真实文献库检索 │
│ → AI调用文献API,而非凭空编造 │
│ → 从根源上杜绝"虚构引用" │
│ │
│ ↓ │
│ │
│ ② 知识沉淀 — 归档到本地知识库 │
│ → 检索结果自动归档到研究专题 │
│ → 下次调研优先从本地库检索,省时省钱 │
│ │
│ ↓ │
│ │
│ ③ 参考文献核查 — 定稿前批量验真 │
│ → AI编的、同事转的、网上搜的,全部过一遍验证 │
│ → 确保零虚假引用,放心提交 │
│ │
└──────────────────────────────────────────────────────────────┘
关键优势:知识沉淀层的存在让整个体系"越用越便宜"——第一次调研需要调用API检索,但检索结果沉淀到知识库后,后续相关问题可以直接从本地知识库中匹配,大幅减少重复API调用。对于长期跟踪某一研发方向的人来说,这不仅是效率问题,更是成本问题。
七、总结:研发AI使用的"黄金法则"
┌────────────────────────────────────────────────┐
│ │
│ 1. 永远假设AI可能出错 → 核实验证是必须的 │
│ │
│ 2. 关键决策不用AI结论 → AI只是高级搜索+整理 │
│ │
│ 3. 建立审核流程 → 三明治验证法是基本功 │
│ │
│ 4. 用制度管人 → 企业需要AI使用规范 │
│ │
│ 5. 持续学习 → AI能力在进化,使用方法也要更新 │
│ │
└────────────────────────────────────────────────┘
附录:推荐检索关键词(用于文献数据库验证)
| 主题 | 推荐检索词 |
|---|---|
| AI幻觉研究 | AI hallucination / LLM hallucination / 大语言模型幻觉 |
| AI可靠性 | AI reliability / LLM calibration / AI trust |
| 幻觉检测 | Hallucination detection / Fact verification / RAG |
| 研发AI应用 | AI in drug discovery / AI-assisted R&D / Laboratory AI |
作者注:本文内容基于AI技术原理和研发管理实践整理。文中标注的[文献支撑点]建议通过专业文献数据库(如维普智图、PubMed等)检索相关中文期刊论文填充,以增强内容的学术权威性。实操建议请结合贵司实际情况调整。第六章描述的技术方案思路,可结合团队实际需求选型落地。
字数:约4200字 | 建议阅读人群:药企/新材料企业研发人员、实验室PI、研发管理层

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)