Cosmos Policy:用视频生成模型的“肌肉记忆“教会机器人操控
凌晨三点的NVIDIA实验室,一个实习生的灵光乍现
Moo Jin Kim 揉了揉眼睛,盯着屏幕上的 Cosmos-Predict2 生成的视频——一个杯子被推倒、水洒出来、桌面被打湿,物理因果链一帧一帧地展开,真实得不像话。他突然冒出一个念头:这个模型已经"理解"了物理世界的运动规律,那为什么不让它直接输出机器人该做什么动作?别的团队都在给视频模型外面套各种动作模块、搞多阶段训练……可如果动作本身也是一种"帧"呢?
这个看似简单的想法,最终变成了 Cosmos Policy——一篇把视频生成模型原封不动变成机器人操控策略的工作,在 LIBERO、RoboCasa 和真实 ALOHA 双臂机器人上全部刷到了 SOTA。
arXiv 链接:Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
把动作塞进"帧"里:一个关于乐高积木的类比
Cosmos Policy 的核心机制可以用一个类比说清楚。
想象你是一个乐高大师,你有一套已经拼好的"世界模型"乐高底板——Cosmos-Predict2 视频生成模型,它从海量视频中学会了物体怎么运动、碰撞、变形。现在你想教它操控机器人。之前的思路是:在底板旁边再搭一个新模块(动作扩散器、逆动力学模型),用螺丝拧上去,然后分两步训练——先微调视频部分,再训练动作部分。
Cosmos Policy 的做法完全不同:它把机器人动作、关节状态、未来画面、价值分数全都当成"乐高积木块",直接插进原来的底板的缝隙里。视频模型原本的扩散序列是 (1+T') × H' × W' × 16 的 latent 帧序列,Cosmos Policy 在这些帧之间插入新的 latent 帧——每个新帧里填的是归一化后的动作向量、关节角度、标量价值——然后让模型像原来去噪视频一样去噪这些新帧。
这就是 Latent Frame Injection(潜在帧注入):不改架构、不加模块,只改输入序列的内容。
让我用论文里最重要的那张图来展开讲。
Figure 2: Cosmos Policy 的潜在扩散序列。展示了"潜在帧注入"机制——将机器人动作、关节状态、未来画面等新模态直接注入视频扩散模型的 latent 帧序列中,无需架构修改。
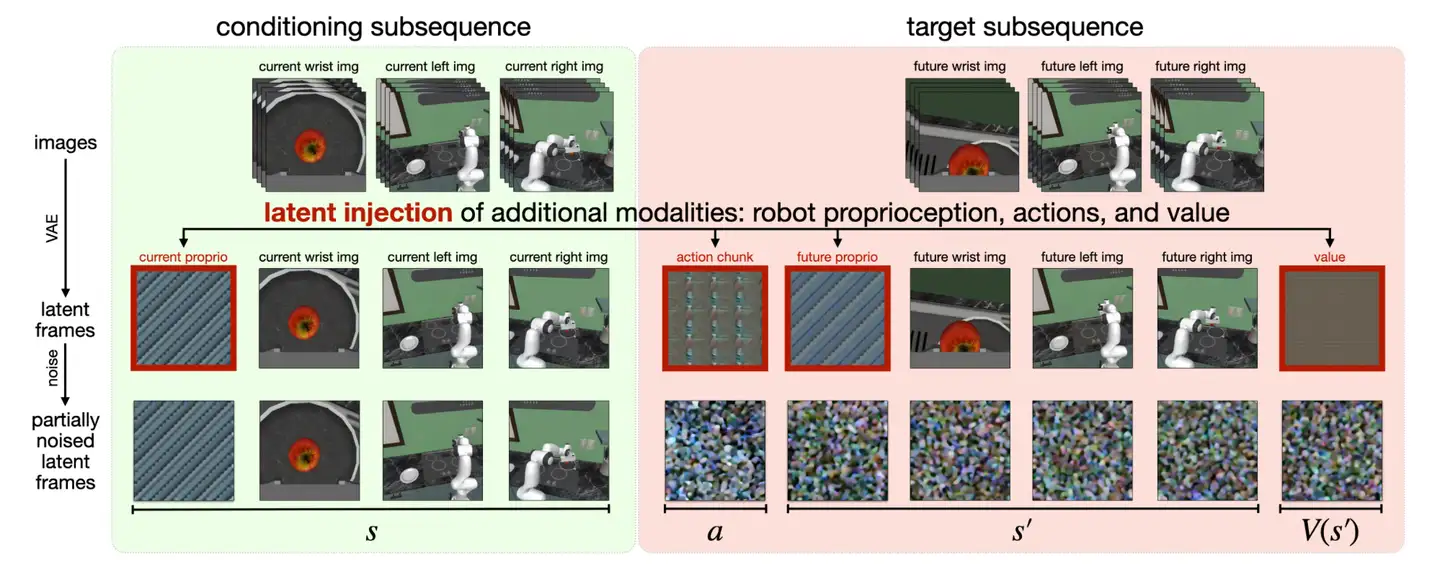
看这张图的逻辑是这样的:
- 第一行(原始图像帧):把来自多个相机的图像(腕部相机、第三人称相机1、第三人称相机2)排成序列,中间穿插空白占位图。这些图像经过 Wan2.1 VAE 编码器压缩成 latent 帧。
- 第二行(注入后的 latent 序列):空白占位帧被"覆写"——填入归一化后的机器人本体感知(14个关节角度)、动作块(50步动作序列)、未来关节状态、未来状态价值。多个相机视角的图像也各自占据一个 latent 帧。
- 第三行(去噪训练):模型的任务和原始视频生成一样——给定干净的帧作为条件,去噪被噪声污染的帧。但"帧"的含义已经扩展了:不仅有图像帧,还有动作帧、状态帧、价值帧。
整个序列的排列顺序是 (s, a, s', V(s'))——当前状态、动作、未来状态、未来价值——从左到右可以自回归解码。
关键洞察:视频生成模型天生擅长建模复杂的多模态分布。动作空间本质上也是一种多模态分布(同一任务可以有多种合理解法)。用 L1 回归去学动作(像很多 VLA 那样)会把多模态压成平均值,而扩散模型天然适合表达这种分布——这就是为什么 Cosmos Policy 在高多模态性任务上(比如抓糖果)碾压 L1 回归的 VLA。
消融实验:每一刀下去都见血
去掉辅助监督,性能掉1.5个点
Cosmos Policy 的训练不是只预测动作。策略网络要联合预测 p(a, s', V(s')|s),世界模型要联合预测 p(s', V(s')|s,a)。论文做了一个消融:把辅助目标去掉,只让策略预测 p(a|s),只让世界模型预测 p(s'|s,a)。
结果如下表所示:
Table 4: LIBERO 消融实验。去掉辅助损失和预训练权重对性能的影响。
| Spatial | Object | Goal | Long | Average | |
|---|---|---|---|---|---|
| SR (%) | SR (%) | SR (%) | SR (%) | SR (%) | |
| Cosmos Policy (完整版) | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
| (1) 去掉辅助损失 | 97.6 | 99.8 | 96.7 | 94.0 | 97.0 |
| (2) 从零训练(无预训练) | 94.7 | 98.9 | 96.3 | 88.6 | 94.6 |
去掉辅助损失掉1.5个点,去掉预训练掉3.9个点。两个都有用,但预训练视频模型的先验更关键——它带来的是物理直觉,不是调参能补回来的。
未来状态预测是 Cosmos Policy 的灵魂
RoboCasa 上的消融更精细,逐个剥掉组件:
Table 5: RoboCasa 消融实验。逐步去除训练组件的影响。
| Average SR (%) | |
|---|---|
| Cosmos Policy (完整版, 5步去噪) | 67.1 |
| (1) 去掉价值函数训练样本 | 66.6 |
| (2) 去掉世界模型和价值函数训练样本 | 64.0 |
| (3) 再去掉策略的辅助价值监督 | 62.5 |
| (4) 再去掉策略的辅助未来状态监督(只预测动作) | 44.4 |
从67.1%暴跌到44.4%——这最后一刀砍掉的是"策略网络要同时预测未来状态"这个目标。这意味着让策略网络学会"想象"未来画面,本身就是它能做好动作预测的核心原因。这不是锦上添花,是根基。
从零训练的代价:抖动的动作
论文还报告了一个有趣的定性发现:从零训练的 Cosmos Policy 在真实 ALOHA 机器人上"fold shirt"任务得分只有80.8,比完整版低18.7分。更关键的是,它产生的动作"抖动剧烈"(jerky motions),长时间部署可能损坏机器人硬件,所以作者直接中止了进一步评估。
这说明视频模型的预训练先验不仅提升性能,还提供了动作平滑性的隐式约束。
从演示到实战:学习失败的价值
仅靠演示数据训练,规划是废的
这是论文里一个容易被忽视但极其重要的设计决策。
演示数据只包含成功轨迹。世界模型和价值函数如果只看成功案例,就会变成"天真的乐观主义者"——它不知道动作失败后会发生什么,也无法准确评估状态的好坏。
所以 Cosmos Policy 的做法是:
- 先用基础策略在各种初始条件下跑 rollout,记录成功/失败
- 用这些 rollout 数据微调世界模型和价值函数(90%的训练 batch 分给世界模型和价值函数,只有10%给策略)
- 双部署:原始 checkpoint 当策略用,微调后的 checkpoint 当世界模型和价值函数用
这个"双部署"设计很巧妙——它确保世界模型看到的是 on-policy 数据(由原始策略收集的),避免了分布偏移问题。
Best-of-N 规划的实际效果
在两个最具挑战性的 ALOHA 任务上,规划带来了平均12.5个百分点的提升。
Figure 7: 模型规划结果对比。基于模型的规划(V(s'))在两个挑战性任务上一致性地提升了成功率。
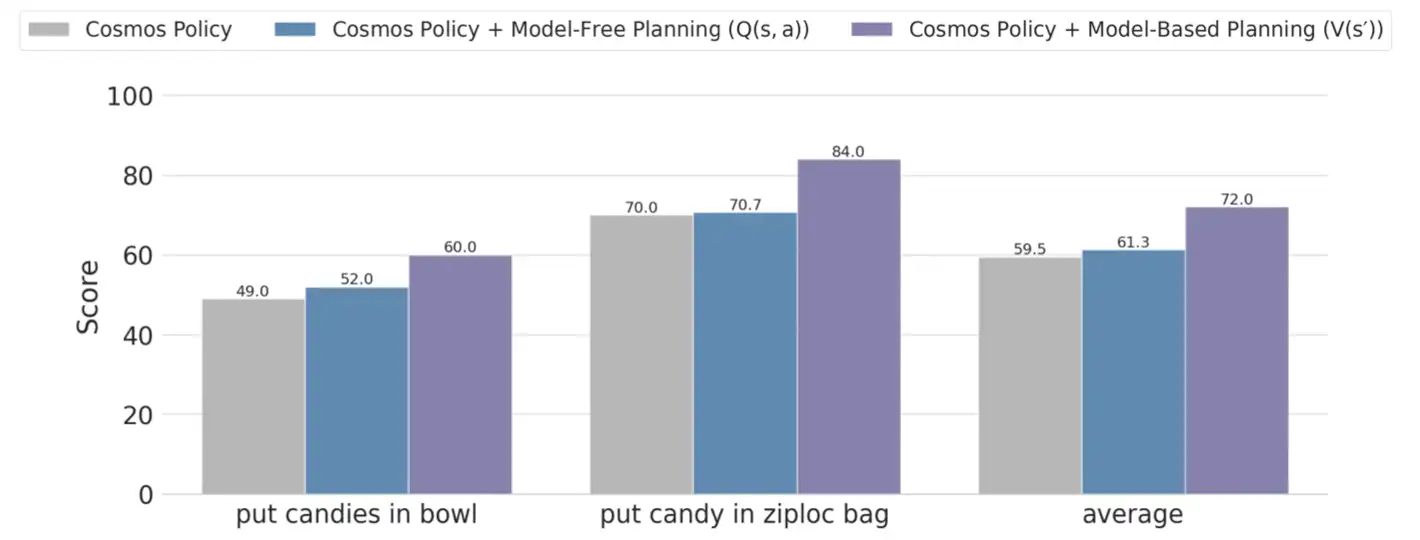
具体做法是:对每个动作提案,世界模型跑3次、价值函数跑5次(共15个价值预测),用"多数均值"(majority mean)聚合——先判断多数预测是成功还是失败,再在多数组内取均值。这比朴素平均对双峰分布更鲁棒。
代价是推理延迟:8张 H100 GPU 并行搜索需要4.9秒。对于静态任务可以接受,对动态任务就是问题了。
世界模型的进化:从"天真"到"见过世面"
Figure 6 展示了微调前后的世界模型预测差异:
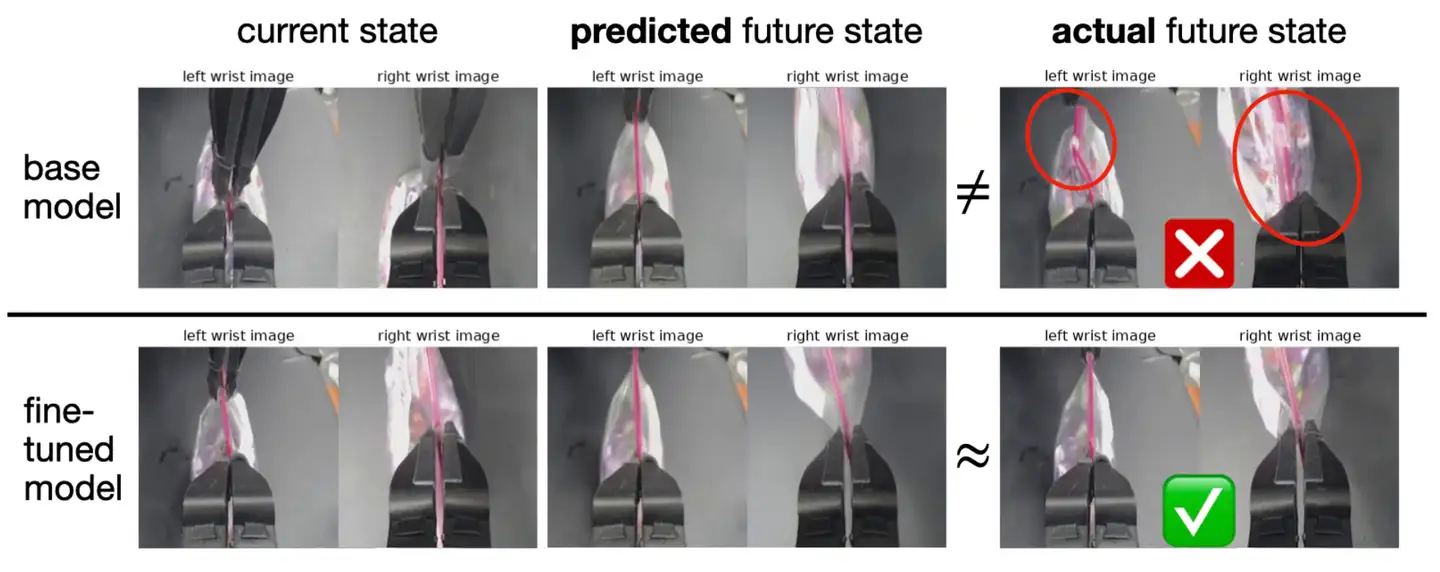
上方是基础版世界模型——它预测 ziploc 袋子会被顺利打开,但实际上机器人会滑脱。下方是微调后的世界模型——它能更准确地预测失败情况(滑脱),从而在规划时选择更稳妥的动作方案,最终成功完成任务。
实验全景:SOTA 不是说说而已
LIBERO 仿真基准
Table 1: LIBERO 仿真基准结果。
| Spatial | Object | Goal | Long | Average | |
|---|---|---|---|---|---|
| SR (%) | SR (%) | SR (%) | SR (%) | SR (%) | |
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Dita | 97.4 | 94.8 | 93.2 | 83.6 | 92.3 |
| π₀ | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| π₀.₅ | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CogVLA | 98.6 | 98.8 | 96.6 | 95.4 | 97.4 |
| Cosmos Policy | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
注意 Long 任务上的差距:97.6% vs. 第二名 CogVLA 的 95.4%。长时序任务是视频模型先验最能发挥作用的地方。
真实世界 ALOHA 双臂机器人
Table 3: ALOHA 机器人评估的分布内 vs. 分布外得分。
| Method | put X on plate | fold shirt | put candies in bowl | put candy in ziploc | Average |
|---|---|---|---|---|---|
| 分布内 | |||||
| Diffusion Policy | 85.0 | 23.3 | 37.3 | 11.0 | 39.2 |
| OpenVLA-OFT+ | 87.5 | 99.2 | 22.7 | 59.0 | 67.1 |
| π₀ | 97.5 | 98.3 | 73.3 | 56.0 | 81.3 |
| π₀.₅ | 97.5 | 99.2 | 98.7 | 56.0 | 87.8 |
| Cosmos Policy | 100.0 | 99.2 | 100.0 | 86.0 | 96.3 |
| 分布外 | |||||
| Diffusion Policy | 20.0 | 23.8 | 26.0 | 26.7 | 24.1 |
| π₀.₅ | 100.0 | 100.0 | 90.0 | 80.0 | 92.5 |
| Cosmos Policy | 100.0 | 100.0 | 74.0 | 83.3 | 89.3 |
| 总分 | |||||
| π₀.₅ | 98.3 | 99.5 | 95.2 | 61.5 | 88.6 |
| Cosmos Policy | 100.0 | 99.5 | 89.6 | 85.4 | 93.6 |
几个值得注意的点:
- 分布外场景下 π₀.₅ 反超了 Cosmos Policy(92.5 vs 89.3),主要差距在"put candies in bowl"的 OOD 条件上(90.0 vs 74.0)。这暗示 Cosmos Policy 在面对训练分布之外的场景时,世界模型的泛化可能不如 π₀.₅ 的 VLM 先验。
- "put candy in ziploc bag" 是 Cosmos Policy 的杀手级任务——85.4 分 vs. π₀.₅ 的 61.5 分。这个任务需要毫米级精度的抓取,正是视频模型对精细运动的理解发挥作用的地方。
- Figure 5 展示了 π₀.₅ 和 OpenVLA-OFT+ 的典型失败模式:

π₀.₅ 在 ziploc 袋子任务上反复滑脱(左图),OpenVLA-OFT+ 在糖果任务上"伸到两颗糖之间而不是对准其中一颗"(右图)——后者是 L1 回归把多模态动作分布压成平均值的经典症状。
一个值得深挖的隐患:OOD 泛化的短板
论文最让我打问号的地方,是 Cosmos Policy 在 OOD 条件下的表现。
在"put candies in bowl"的 OOD 评估中,Cosmos Policy 得分74.0,而 π₀.₅ 得分90.0——差距16个点。虽然总分上 Cosmos Policy 仍然领先,但这个差距暴露了一个结构性问题:Cosmos Policy 的世界模型是从有限的 rollout 数据中学习的,它的泛化能力直接取决于这些数据覆盖了多少"世界状态"。当面对训练中从未见过的场景配置时,世界模型的预测可能不准,价值函数的估计也会偏移,导致规划反而帮倒忙。
我的推理:Cosmos-Predict2 的视频先验在物理运动层面是强的(物体怎么动),但在语义推理层面("如果碗里已经有3颗糖,再放一颗需要什么角度")不如 VLM。VLA 模型通过大规模图文预训练获得了更强的语义泛化能力,这可能是 π₀.₅ 在 OOD 上更鲁棒的原因。
如果我来修补:我会尝试一个混合方案——用 Cosmos Policy 作为底层控制器处理精细动作执行,用 VLM 作为高层规划器处理语义推理和任务分解。类似"大脑(VLM)+ 小脑(Cosmos Policy)"的分层架构。具体来说,可以先用 VLM 生成子目标序列,再用 Cosmos Policy 的世界模型在每个子目标附近做 best-of-N 搜索。
推理延迟的工程真相
论文坦诚地给出了推理延迟数据,这在机器人论文中不常见,值得单独拎出来说:
| 配置 | 延迟 | 性能 |
|---|---|---|
| 1步去噪 | 0.16秒/块 | 66.4% (RoboCasa) |
| 5步去噪 | 0.61秒/块 | 67.1% (RoboCasa) |
| 10步去噪 | 0.95秒/块 | — |
| 规划(8 GPU, N=8) | 4.9秒/块 | +12.5分提升 |
1步去噪只需0.16秒,性能只掉0.5个点——这对实际部署来说是极其有价值的信息。4.9秒的规划延迟对静态操作可以接受,但对动态交互(比如接住抛来的物体)就完全不适用了。
最终结论
一句话本质:Cosmos Policy 证明了视频生成模型的扩散学习机制可以直接用来表示和生成机器人动作,无需任何架构修改——动作就是另一种"帧"。
最该记住的词:Latent Frame Injection(潜在帧注入)——把非图像模态编码为 latent 帧注入扩散序列,是对预训练视频模型最轻量、最优雅的适配方式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)