【NeurIPS 2025】基于实例感知事后修正优化时间序列预测
·
目录
一段话概括
本文针对时间序列预测中普遍存在的实例级变异问题(由分布偏移、缺失数据和长尾模式导致,表现为预测误差的长尾分布),提出了模型无关的事后修正框架PIR(Post-forecasting Identification and Revision)。该框架通过不确定性估计识别预测失败实例,并从局部(协变量与外生信息)和全局(相似历史序列检索)两个维度对预测结果进行修正。在12个真实世界数据集上对4个主流预测模型的实验表明,PIR能平均降低MSE最高达25.87%,显著提升预测可靠性,相关成果已被NeurIPS 2025接收。
论文:Improving Time Series Forecasting via Instance-aware Post-hoc Revision
作者:Zhiding Liu, Mingyue Cheng, GuanHao Zhao, Jiqian Yang, Qi Liu, Enhong Chen
单位:State Key Laboratory of Cognitive Intelligence, University of Science and Technology of China
代码:https://github.com/icantnamemyself/PIR
更多资讯 搜索微信公众号:时序前沿研究,加入时序交流群;
请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
1. 研究背景与问题
- 时间序列预测的重要性:广泛应用于交通规划、能源管理、医疗分析和气象预报等领域,近年来深度学习方法取得了显著进展。
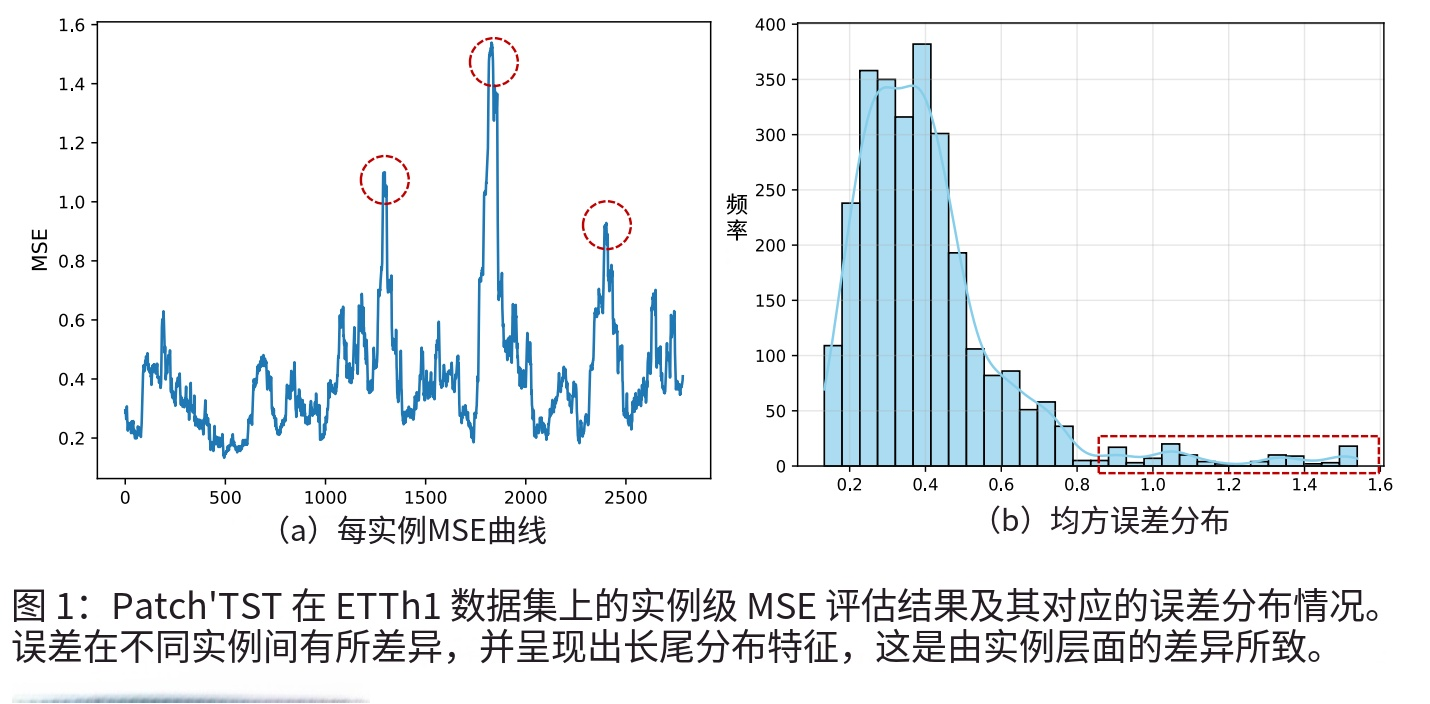
- 核心问题发现:尽管现有模型在整体评估中表现良好,但实例级变异导致部分特定实例的预测结果严重失真。这种变异源于时间序列数据的非平稳性、噪声、传感器故障和长尾分布,表现为预测误差的长尾分布(如图1所示,PatchTST在ETTh1数据集上,多数实例MSE低于0.4,但少数实例MSE超过1.6)。
- 现有方法的不足:传统方法和深度学习模型均未专门针对这一问题进行设计,导致预测可靠性不足。
2. PIR框架设计
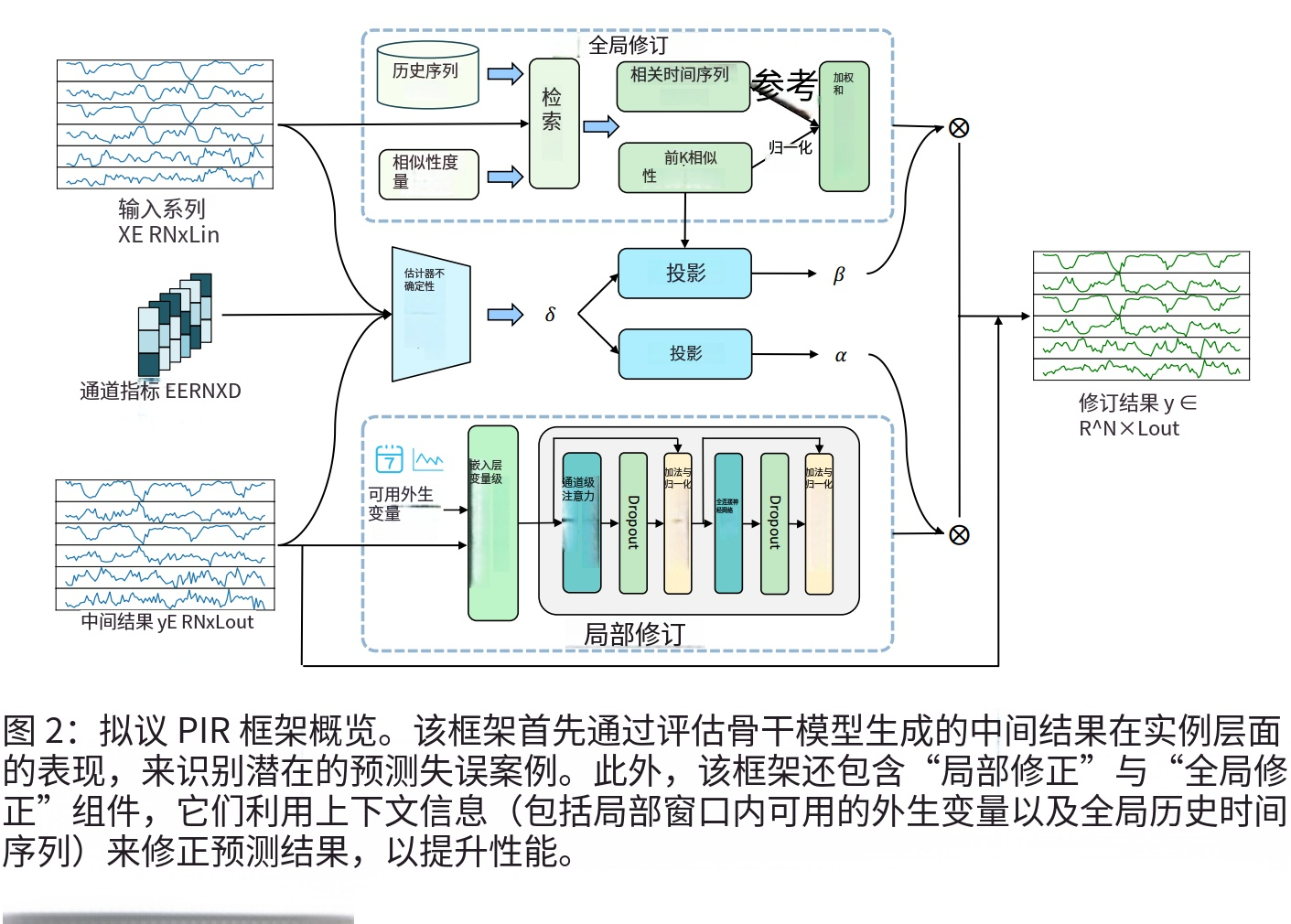
PIR是一个完全模型无关的事后处理插件,可无缝集成到任意时间序列预测模型中,无需修改骨干模型的结构或训练过程。框架包含三个核心组件:
2.1 故障识别模块
- 核心思想:将预测失败识别转化为不确定性估计任务,通过预测每个实例的MSE来量化其不确定性。
- 实现方式:使用两层全连接神经网络,输入为原始序列、骨干模型的预测结果和通道嵌入,输出为该实例的不确定性估计δ。
- 监督信号:以骨干模型预测结果与真实值的MSE作为监督,使用MAE损失函数 L u e L_{ue} Lue进行优化。
- 关键创新:同时考虑数据不确定性和模型不确定性,为后续修正提供可靠的依据。
2.2 局部修正模块
- 核心思想:利用局部窗口内的上下文信息(包括协变量的预测结果和已知的外生变量,如时间戳、节假日信息)来修正预测误差。
- 实现方式:
- 将协变量预测和外生变量分别投影到隐藏空间并拼接
- 使用Transformer编码器捕捉变量间的依赖关系(如领先-滞后效应)
- 通过线性头生成局部修正结果 y l o c a l y_{local} ylocal
- 优势:特别适用于采用通道独立策略的模型(如PatchTST),弥补其忽略跨变量依赖的缺陷。
2.3 全局修正模块
- 核心思想:针对长尾模式和罕见模式,从全局历史数据中检索相似的时间序列作为参考,利用"相似历史会重演"的假设进行修正。
- 实现方式:
- 构建仅包含训练集数据的检索数据库(避免数据泄露)
- 使用实例归一化对序列进行编码(缓解非平稳性对相似度计算的影响)
- 采用余弦相似度检索Top-K最相似的历史序列
- 以相似度为权重,对检索到的序列的真实未来值进行加权求和,生成全局修正结果 y g l o b a l y_{global} yglobal
- 优势:能够有效捕捉骨干模型因训练数据不足而无法学习到的罕见模式。
2.4 集成与优化
- 动态加权融合:最终预测结果为原始预测、局部修正和全局修正的加权和:
y p r e d = y ˉ + α y l o c a l + β y g l o b a l y_{pred} = \bar{y} + \alpha y_{local} + \beta y_{global} ypred=yˉ+αylocal+βyglobal
其中α和β是根据不确定性估计δ和检索相似度动态学习的权重(使用Sigmoid激活函数确保非负)。 - 多任务学习目标:
L = L p r + λ L u e \mathcal{L} = \mathcal{L}_{pr} + \lambda \mathcal{L}_{ue} L=Lpr+λLue
其中 L p r L_{pr} Lpr是最终预测与真实值的MSE损失, L u e L_{ue} Lue是不确定性估计的MAE损失,λ为权重超参数(实验中固定为1)。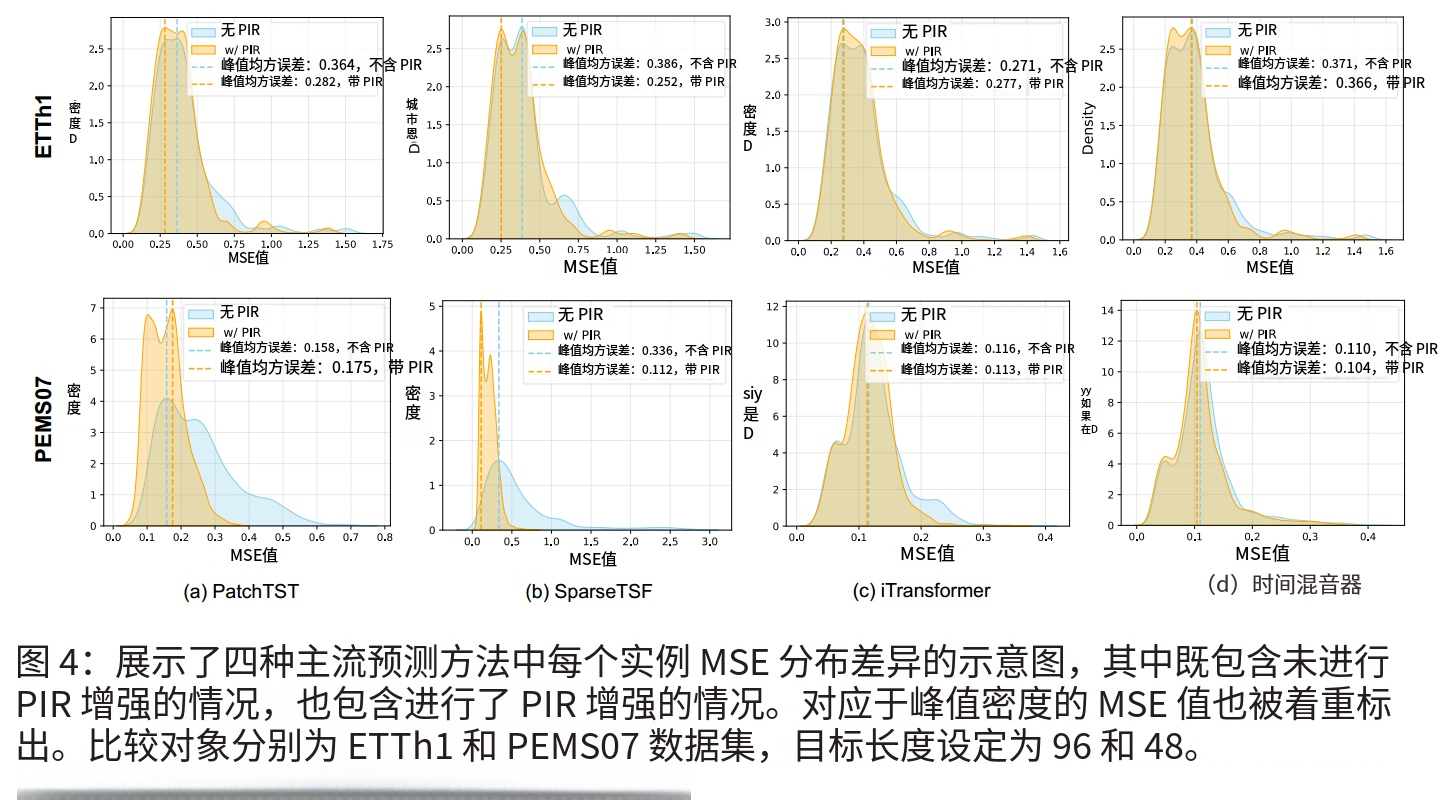
3. 实验验证
3.1 实验设置
- 数据集:12个真实世界数据集,覆盖能源、自然、交通、健康等多个领域,包括长序列预测(ETT、电力、太阳能等)和短序列预测(PEMS交通数据集)。
- 骨干模型:4个主流预测模型,代表不同的架构设计:
- PatchTST(通道独立,基于Transformer)
- SparseTSF(通道独立,基于稀疏MLP)
- iTransformer(通道依赖,基于倒置Transformer)
- TimeMixer(通道依赖,基于多尺度混合)
- 评估指标:均方误差(MSE)和平均绝对误差(MAE)。
3.2 主要实验结果
PIR在48个实验设置中的46个都取得了性能提升,平均MSE降低幅度如下表所示:
| 骨干模型 | 平均MSE降低幅度 | 最大MSE降低幅度(数据集) |
|---|---|---|
| PatchTST | 8.99% | 32.04%(PEMS04) |
| SparseTSF | 25.87% | 57.67%(PEMS07) |
| iTransformer | 3.47% | 10.19%(PEMS04) |
| TimeMixer | 2.34% | 5.20%(Traffic) |
- 关键发现:
- 通道独立型模型(PatchTST、SparseTSF)的提升幅度显著大于通道依赖型模型(iTransformer、TimeMixer),因为后者已经在模型内部考虑了跨变量依赖。
- 在交通数据集上提升最为显著,这与交通数据具有强周期性和大量相似历史模式的特点一致。
- PIR不仅降低了平均误差,还显著压缩了误差分布的长尾部分(如图4所示,SparseTSF在ETTh1上的最大预测误差从2.85降至0.81)。
3.3 定性与消融分析
- 不确定性估计有效性:估计的不确定性与实际预测误差的R²分数高达0.9067(PatchTST)和0.7500(iTransformer),证明了故障识别模块的准确性。
- 组件贡献分析:消融实验表明,局部修正和全局修正都能独立提升性能,两者结合效果最佳。
- 性能增益来源:PIR的性能提升并非来自简单的模型加深,而是来自对上下文信息的有效利用和对长尾模式的针对性处理。
3.4 复杂度分析
- 理论复杂度:检索阶段时间复杂度为O(NML_in),局部修正阶段为O(N²)。
- 实际效率:由于GPU并行化的支持,检索阶段引入的额外延迟可忽略不计(ETTh1数据集上仅增加0.024秒)。
- 检索策略对比:暴力余弦相似度检索在效率和效果上均优于基于LSH的近似检索。
4. 结论与局限
- 核心贡献:
- 首次系统地揭示了时间序列预测中实例级变异问题的普遍性和严重性。
- 提出了第一个模型无关的事后修正框架PIR,通过识别-修正的范式解决这一问题。
- 在广泛的基准测试中验证了PIR的有效性和通用性。
- 局限性:
- 目前仅处理了输入序列的实例级变异,未考虑目标序列中因数据质量问题导致的变异。
- 故障识别和局部修正模块使用了相对简单的网络结构,有进一步提升的空间。
- 未来方向:研究目标序列质量提升方法,引入更先进的网络架构和归纳偏置,探索多模态上下文信息的利用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)