解剖 GPU 显存:多轮对话中大模型为什么会遭遇 OOM 噩梦?
在上一篇中,我们聊到大模型为了不在自回归解码(Decode)时重复发明轮子,选择把历史 Token 的 K 和 V 矩阵死死钉在显存里,这就是 KV Cache。
计算复杂度确实从 O(N^2) 降到了 O}(N),大模型吐字如飞。然而,天下没有免费的午餐。算力被解放的同时,一场更加惨烈的“空间危机”,正在 GPU 的显存世界里悄然爆发。
对于一个服务来说,可能会有很多人同时接入一台服务器,而且这么多人他们还可能会对某个问题重复提问,尤其是多轮对话会成为显存的头号杀手?为什么有些推理服务明明跑得好好的,突然就蹦出个 RuntimeError: CUDA out of memory?这一篇,我们来当一回“显存会计”,精准拆解大语言模型运行时的显存物理账本。

1. 大模型在显存里的“三大势力范围”
当一个大模型被加载到 GPU 显存并跑起来的时候,显存并不是一团浆糊,而是被严格划分为了三大核心阵营:
🧱 阵营一:模型权重(Static Weights)—— 稳如泰山
这是最容易计算的静态显存。模型有多少参数,开机就吃掉多少显存,雷打不动。
-
计算公式:
显存占用=参数量×每个参数的字节数 \text{显存占用} = \text{参数量} \times \text{每个参数的字节数} 显存占用=参数量×每个参数的字节数 -
举个例子: 经典的 Qwen2.5-7B 模型,在半精度(FP16,每个参数占 2 字节)下,静态权重显存就是
7×109×2 Bytes≈14 GB 7 \times 10^9 \times 2 \text{ Bytes} \approx 14 \text{ GB} 7×109×2 Bytes≈14 GB
只要你不关机、不卸载模型,这 14GB 的空间谁也别想碰。
🧬 阵营二:临时激活值与运行时开销(Runtime Activations)—— 动态流转
模型在前向传播计算(计算各类矩阵乘法、Softmax、LayerNorm)时,中间产生的临时张量(Tensor)。
- 特点: 它们是“快闪族”。计算完当前层,往往就把数据传递给下一层,自身随即被释放。
- 规模: 与 Batch Size(并发数)和模型层数相关,但总体占用相对较小且固定,在工程上通常可以预留一块几百 MB 到几 GB 的固定缓冲区来应对。
🐋 阵营三:KV Cache
这是整个推理系统里最大的变数,就像上一篇我们讲的它是怎么来的。 它不像权重那样固定,也不像激活值那样用完就扔。它随着并发请求数(Batch Size)和上下文长度(Context Length)的增加而疯狂地、线性地暴涨。
2. 硬核精算:一个 Token 的 KV Cache 到底有多大?
很多工程师对 KV Cache 的膨胀速度没有直观概念。我们直接上公式,看看一个 7B 模型每生成一个 Token,要吃掉多少显存。
对于 Transformer 的一层,每个 Token 需要存储一个 K 向量和一个 V 向量。
-
向量的长度等于模型的隐层维度(
hhidden h_{\text{hidden}} hhidden
)。 -
模型通常有
nlayer n{\text{layer}} nlayer
层。 -
如果是标准的 MHA(多头注意力),每个注意力头都有独立的 KV。
-
数据精度通常是 FP16(2 字节)。
我们可以得到单个 Token 在标准模型下的 KV Cache 字节数公式:
Single Token Size=2×nlayer×hhidden×2 (Bytes) \text{Single Token Size} = 2 \times n_{\text{layer}} \times h_{\text{hidden}} \times 2 \text{ (Bytes)} Single Token Size=2×nlayer×hhidden×2 (Bytes)
(注:前面的 2 代表 K 和 V 两个矩阵,后面的 2 代表 FP16 占 2 字节)
🧮 拿 Llama-2-7B 实测算账:
Llama-2-7B 的参数为:层数
nlayer=32 n_{\text{layer}} = 32 nlayer=32
,隐层维度
hhidden=4096 h_{\text{hidden}} = 4096 hhidden=4096
。
代入公式:
Size=2×32×4096×2=524,288 Bytes≈0.5 MB / Token \text{Size} = 2 \times 32 \times 4096 \times 2 = 524,288 \text{ Bytes} \approx 0.5 \text{ MB / Token} Size=2×32×4096×2=524,288 Bytes≈0.5 MB / Token
也就是说,单用户单并发下,每多输入或输出一个字,就要吞掉 0.5 MB 的显存。
看起来好像不多?我们把多轮对话和并发加上试试:
假设一个商用场景,我们需要支持 Batch Size = 16 的并发,每个用户都在进行长文本多轮对话,上下文累积到了 4096 Token:
Total KV Cache=16 (用户)×4096 (Token)×0.5 MB=32,768 MB=32 GB! \text{Total KV Cache} = 16 \text{ (用户)} \times 4096 \text{ (Token)} \times 0.5 \text{ MB} = 32,768 \text{ MB} = 32 \text{ GB}! Total KV Cache=16 (用户)×4096 (Token)×0.5 MB=32,768 MB=32 GB!
静态权重才 14GB,而 KV Cache 竟然烧掉了 32GB 显存! 此时整张卡需要
14+32=46 GB 14 + 32 = 46 \text{ GB} 14+32=46 GB
显存,一张 24GB 显存的 RTX 4090 直接当场暴毙,哪怕是 40GB 的 A100 也得跪。
3. 多轮对话的“滚雪球”放大效应
多轮对话(Multi-turn Dialogue)完美地将 KV Cache 的空间劣势放大了。
在大模型多轮对答中,为了保持上下文连贯,每一次新对话都必须把前面所有轮次的“历史输入+历史输出”作为 Prompt 整体重新打包喂给模型。
- 第一轮: 用户问 100 字,KV Cache 占用 50MB。
- 第二轮: 用户再问 100 字,但历史已经有了第一轮的回答(假设 200 字),此时输入的 Prompt 变成了 400 字,KV Cache 瞬间激增。
- 第 N 轮: 随着聊天的深入,历史记忆像滚雪球一样越来越大。原本在第一轮看似风平浪静的显存,在第十轮时可能因为某次用户输入稍微长了一点,或者模型蹦出了一个长难句,直接把显存最后的一丝稻草压断,瞬间触发 OOM。
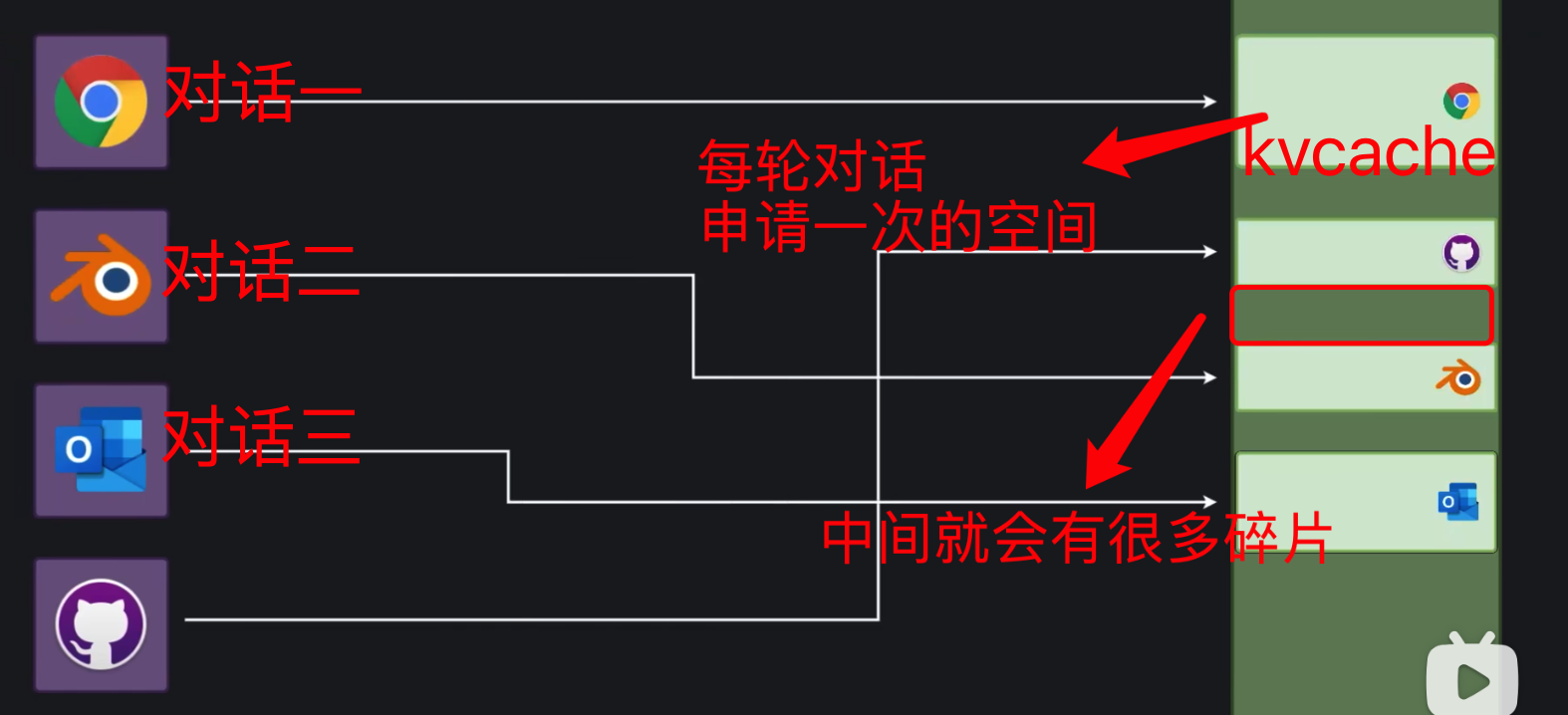
4. 传统框架的笨办法:预分配与显存碎片化
如果只是线性增长,工程上做好限流似乎也能苟住。但传统推理框架(如早期的 Hugging Face Transformers 朴素实现)在内存管理上的粗暴做法,直接给 OOM 埋下了炸弹。
传统框架为了让 GPU 能够进行高效矩阵计算,要求每个请求的 KV Cache 在显存里必须是物理连续的。
为了应对用户变长的输入输出,框架不得不采用静态预分配(Static Pre-allocation)的笨办法:不管你这次是问一句“你好”,还是让人家写长篇大论,系统一律按照模型支持的 Max Sequence Length(最大长度,比如 4096) 提前在显存里给这个请求圈地。
这就直接导致了两大灾难:
-
内部碎片(Internal Fragmentation)极度严重:
系统给请求 A 圈了 4096 的全套显存,但用户聊了两句(才用了 200 Token)就关掉窗口走了。剩下的 3896 个 Token 对应的显存空间只能空着“躺平”,其他请求根本进不来。绝大多数显存被浪费在了“根本没有发生的对话”上。
-
外部碎片(External Fragmentation)无法避免:
随着不同用户的请求频繁上线、离线,显存被开辟、释放得千疮百孔。就像被犁过的土地,表面上看剩余总显存还有 10GB,但全是零散的小缝隙。当一个需要连续 1GB 空间的新用户进来时,系统根本找不到一块连续的空间,只能绝望地报出 OOM。
5. 总结与下篇预告
算完这笔账,大模型推理的显存物理真相彻底水落石出:
大模型推理的并发瓶颈,在绝大多数场景下根本不是 GPU 的算力(TFLOPS)不够,而是那可怜的显存容量被 KV Cache 的内部碎片和连续预分配机制给活活撑爆了。
这种粗暴的内存管理方式,让高并发、低延迟的大模型商用成了一种奢侈。
工程界急需一场变革。既然痛点在“连续显存分配”和“内存碎片”,那能不能借鉴计算机操作系统中成熟的 “虚拟内存与分页机制” 呢?跨请求之间的相同历史对话,能不能像共享软件一样进行 “缓存复用” 呢?
下一篇(终结篇),我们将解构工业界最耀眼的推理加速双子星——vLLM 与 SGLang,看看它们是如何用 PagedAttention(分页内存)和 Radix Tree(基数树)拯救显存,完成这场惊心动魄的工业级工程破局。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)