时序大模型到底值不值得做?TimeGPT、Chronos、Moirai、TimesFM全拆解
时序大模型(TS Foundation Model):是真牛还是纯忽悠?
TimeGPT / Moirai / Chronos / TimesFM 哪个值得搞?
先聊两句:这事得早了解
从2024年底到现在,时间序列领域就跟炸了锅一样。各家大厂疯狂发模型:Google的TimesFM 2.5,亚马逊的Chronos-2,Salesforce连着出了Moirai-2和Moirai-MoE,Nixtla的TimeGPT-2.1也进了私有预览。
说白了,这帮大厂正在把NLP那套搬到时序预测上来。目标就一个:搞一个通用的模型,啥时序数据都能预测,不用再每个数据集重新训练一遍。
这画面是不是有点眼熟?没错,跟当年GPT-3刚出来时一模一样。
但问题来了:时序大模型到底是真的好用,还是大家跟风吹出来的泡沫?
今天我一次性把这四个模型讲清楚。架构、性能、适用场景、能不能拿来发论文,都给你说明白。看完这篇,你就能在你组里当半个专家了。

另外我整理了《时序大模型论文大礼包》,包含:
四大模型的原始论文 + 解读笔记
每个模型的一键复现代码(Colab直接跑)
GIFT-Eval / Monash 等主流benchmark的评测脚本
5个可直接套用的论文选题模板
审稿人常见问题 + 标准回复话术
姿 料 这儿~
一、先搞懂:啥是时序基础模型?
传统做时序预测的流程:拿到数据 → 选模型 → 调参数 → 训练 → 评估 → 上线。每个数据集都得从头来一遍,非常费劲。
而时序基础模型的做法是:先用海量不同类型的时序数据预训练出一个通用模型,下游任务直接拿来用,不需要再训练。就像GPT能写代码、做翻译、写摘要一样,这些时序大模型想做到“一个模型搞定所有时序预测”。
听着挺美好对吧?别急着觉得靠谱,我们先看看这四个模型到底啥水平。

二、四大模型挨个拆解
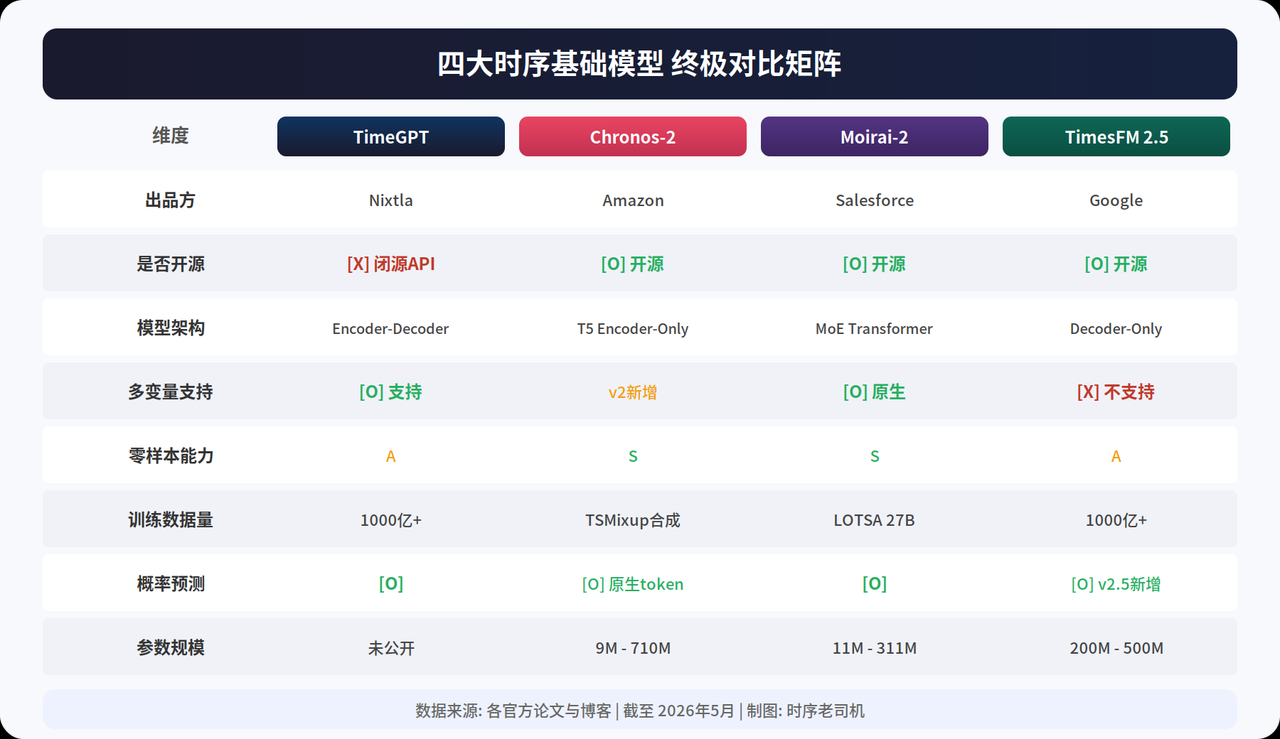
图1:四大时序基础模型核心维度对比矩阵
2.1 TimeGPT —— 黑盒,但方便
谁做的:Nixtla,这家号称自己是时序领域的OpenAI。
它靠什么吃饭:第一个提出“时序基础模型”这个概念。用的是Encoder-Decoder架构,在超过1000亿个数据点上预训练过。你写3行代码调一下API就能做预测和异常检测。最新的TimeGPT-2.1号称精度提升了60%。
最大问题:闭源。就这一点,对学术党来说基本等于“别想了”。你论文里写“用了TimeGPT的API”,审稿人第一反应:能复现吗?答案是:不能。大概率直接拒稿。
我的看法:工业场景想快速验证一下可以试试,发论文就算了吧。除非你跟Nixtla有合作。
2.2 Chronos-2 —— 学术圈最爱的选择
谁做的:亚马逊的AWS团队。
它靠什么吃饭:最骚的操作是把时序数据当文字处理。先把连续值归一化,再转成离散的Token,然后用T5模型预测下一个Token的概率分布。这不就跟GPT预测下一个词一样吗?所以它名字叫Chronos(希腊神话里的时间之神),一听就很有论文味。
2025年10月的大更新:Chronos-2开始支持多变量和协变量,把之前最大的短板补上了。模型大小从900万到7.1亿参数不等,HuggingFace上下载量已经上百万次。文档和社区支持是四个模型里最好的。
迪卡侬实测结果:Chronos-2做微调后,在所有场景里都是第一。而且有43.2%的产品上,不微调直接零样本预测,效果就超过了专门调优过的DeepAR模型。
我的看法:发论文的首选baseline。社区大、文档全、好复现,审稿人找不到理由拒你。做微调之后更容易刷到SOTA。
2.3 Moirai-2 / Moirai-MoE —— 效率惊人

谁做的:Salesforce的AI研究院。
它靠什么吃饭:两个关键词——MoE。别的模型都是传统架构,所有参数都激活。Moirai-MoE用的是稀疏专家混合,在Token级别做路由选择。结果是什么?一个激活参数只有1100万的Moirai-MoE-Small模型,打翻了3.1亿参数的Moirai-Large模型,精度还高了7%。也就是说,用了不到1/28的计算量,效果反而更好。
另一个杀手锏:Any-Variate注意力机制。原生支持任意维度的多变量输入,不像TimesFM那样每个变量都要单独预测。做金融的多资产组合、物联网的多传感器数据,Moirai-2是最合适的选择。
我的看法:想发MoE加时序方向的论文,Moirai-MoE就是你的起跑线。这个方向的坑还很多,至少还能挖一两年。
2.4 TimesFM 2.5 —— 企业用很稳
谁做的:Google研究院。
它靠什么吃饭:Decoder-Only架构,思路最直接——把时间序列切成小段(Patch),转成连续向量,然后自回归预测。同样在超过1000亿数据点上训练过。2.5版本加了概率预测和外部回归变量的支持。
最大优势:跟BigQuery深度集成,在Google Cloud上跑起来很快,每秒能处理300多条序列。如果你公司已经在用Google全家桶,这就是最好用的选择。
但有个反直觉的事情:迪卡侬的实测里,旧版TimesFM 2的效果反而比新版TimesFM 2.5好。这说明新版本不一定就更好,效果不是线性提升的。
我的看法:工业界上生产环境,这是首选。学术界拿来做baseline也行,但讲故事不如Chronos和Moirai好讲。
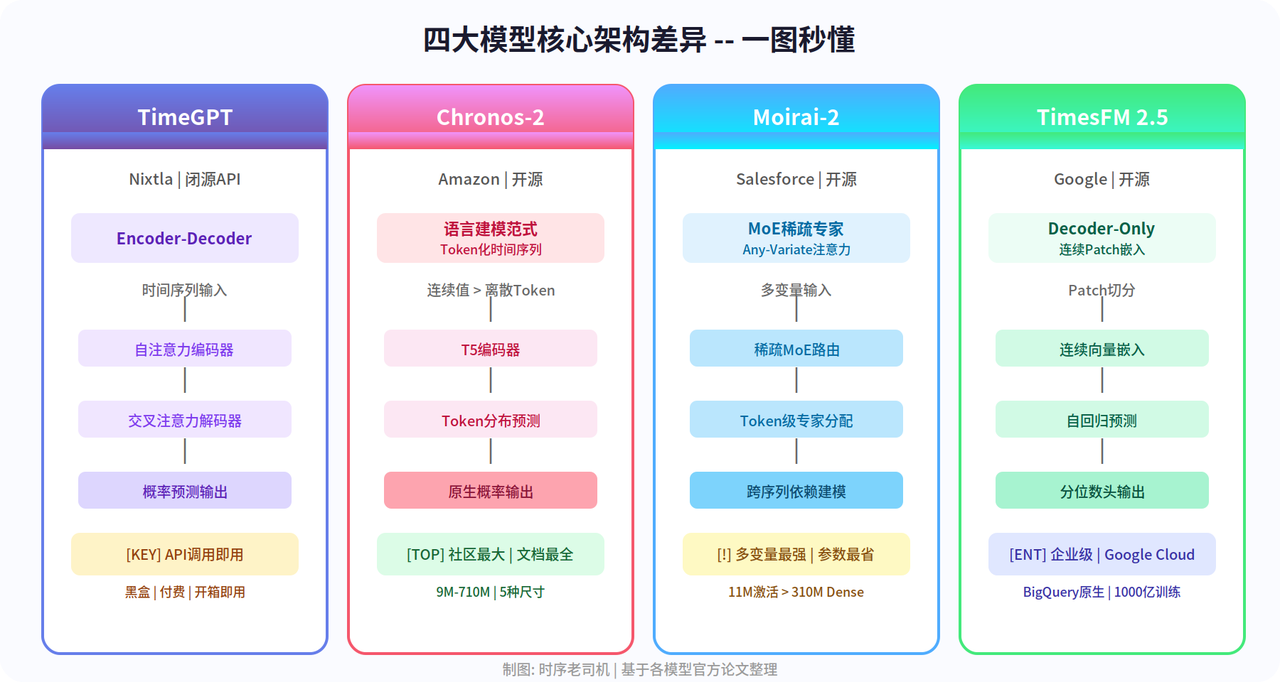
图2:四大模型核心架构差异一图秒懂
三、灵魂拷问:泡沫还是未来?
这可能是时序圈现在争议最大的话题。我把两边的论据都摆出来,你自己判断。

图3:泡沫 vs 未来——正反双方论据全景
3.1 说它是泡沫的人,有五个理由
理由1:测试集可能早就见过
多项研究发现,这些大模型的测试数据和预训练数据有重叠,导致测出来的精度虚高。有的模型虚高了47%到184%。你以为它是零样本学习的SOTA,可能只是因为它之前就见过这些数据。
理由2:在特定领域打不过传统统计模型
在金融数据上,调过参数的ARIMA或Prophet效果还是能比肩甚至超过这些大模型。想拿大模型预测股票,不一定比你师兄手工做的特征好用。
理由3:算力门槛太高
7.1亿参数的Chronos-2需要GPU才能推理。中小企业或者没显卡的学生表示:我卡呢?
理由4:说不清楚为什么好用
审稿人最喜欢问的问题:“为什么这个方法有效?”你很难回答上来。在医疗、金融这种高风险领域,说不清楚原因是很致命的问题。
理由5:创新越来越难
大家都在卷Transformer加时序,架构上的新东西越来越少。你很难再讲出让审稿人眼前一亮的创新点。

3.2 说它是未来的人,也有五个理由
理由1:工业生产上已经验证有效 迪卡侬对数万个商品的实测表明,TimesFM零样本预测的效果,已经达到甚至超过了每周重新训练一次的DeepAR。这不是论文里挑好的结果说,是真实的生产验证。
理由2:MoE路线打开了效率天花板 Moirai-MoE用1100万激活参数打翻3.1亿参数的模型。这条路还远远没走到头。以后可能出现“100万参数的模型比1亿参数的模型还强”的情况。
理由3:微调之后效果确实强 Chronos-2微调后在迪卡侬的所有时间跨度上都是断层第一。基础模型加领域微调,跟NLP里的GPT加监督微调的路子完全一样。
理由4:大厂都在持续砸钱 Google、亚马逊、Salesforce、Nixtla四家大厂都在持续投入迭代。这不是学术圈自己玩,是有商业前景的方向。
理由5:预测即服务 时序预测正在从“每次都要重新训练一个模型”变成“直接调API就能预测”。这种模式转变一旦完成,会彻底改变整个行业的玩法。
3.3 我自己的判断
短期有泡沫,长期是未来。
现在的时序大模型确实存在测试集数据泄露、解释性差等问题,但技术方向是对的。就像2020年的GPT-3,当时也有很多人说“这玩意不实用”,结果呢?
给研究生的建议:现在入场不晚。时序大模型的坑还远远没挖完——MoE路线、多模态时序、可解释性、领域微调……每个方向都够发好几篇一区。
四、怎么选模型?一张图搞定
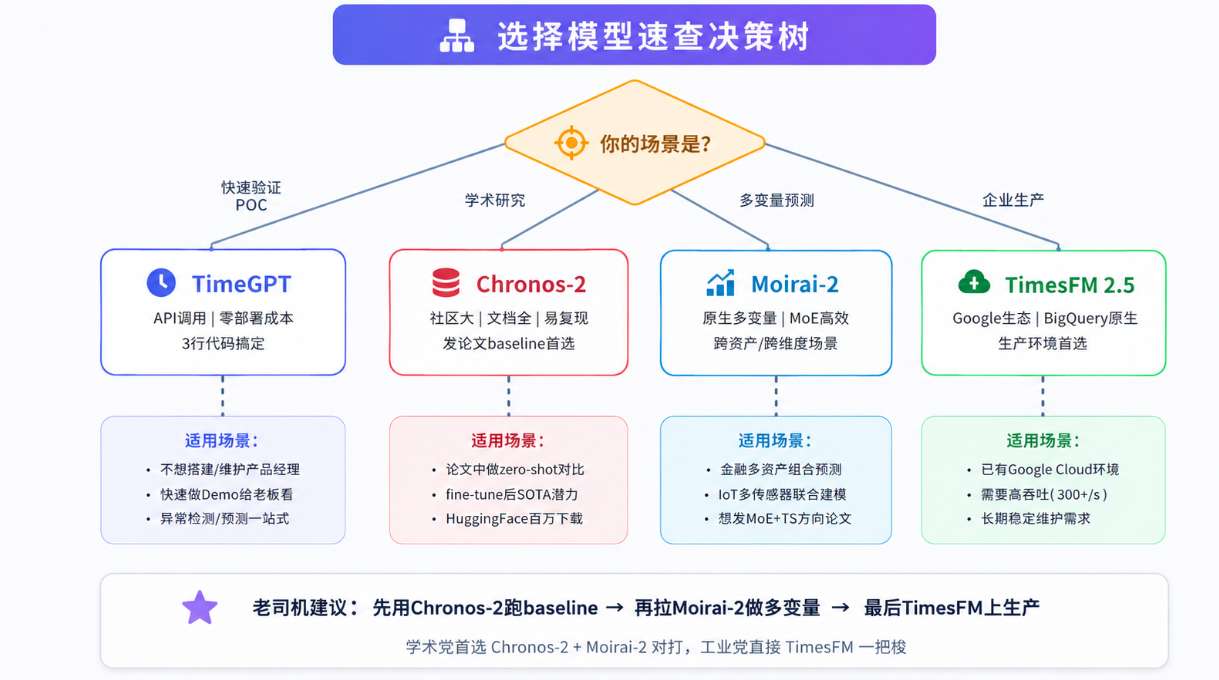
图4:时序大模型选型决策树
不绕弯子,直接给结论:
做学术、发论文:首选Chronos-2和Moirai-2,两个对着跑
工业界上生产:直接TimesFM一把梭
做个Demo演示:用TimeGPT的API,三分钟搞定
五、发论文实操:审稿人到底想看什么?
说了这么多,回到最核心的问题:用时序大模型怎么发论文?给你五个已经被验证过的方向。
方向1:做领域微调
选一个垂直领域(比如医疗、能源、交通),用Chronos-2或Moirai-2做微调。证明一件事:通用模型加领域微调,比从零开始训练的专用模型效果更好。审稿人很吃这套。
方向2:改进MoE架构
Moirai-MoE只是开了个头。专家的路由策略、专家数量、稀疏度怎么设……每个点都可以挖。论文标题我都帮你想好了:“XXX-MoE:通过自适应专家路由实现高效时序预测”。
方向3:做可解释性
时序大模型最大的痛点就是解释不清。如果你能做出一个既准又能说清楚原因的模型,至少是一区起步。
方向4:做评测集去污染
研究时序大模型评测中的数据泄露问题,提出更干净的评测方法。这类方法论论文审稿人很喜欢,因为你帮整个社区解决了一个实际问题。
方向5:做多模态时序
把文字、图片等其他模态的信息跟时序数据结合起来。比如用新闻文本加股价时序做联合预测。这是下一个蓝海方向。
声明:以上都是我个人的学术看法,不构成投资建议或技术选型建议。数据来源是各模型的官方论文、博客和第三方评测报告,截止到2026年5月。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)