AutoResearch---一种最新的研究范式(开源项目拆解)
大家好,今天给大家关注AI的朋友分享一个很火的开源项目,它是由Andrej Karpathy所提出的一种研究新范式,从当前来看,他所提出的观点很激进,或许在很多人看来这个观点非常的荒谬,但不得不很值得我们去关注一下,毕竟,最近一两年提出的一些新概念都已经在实际产品和工作上用起来了,所以说作为工程师还是应该多关注一下,毕竟像MCP、skill这些概念一样,最开始出来的时候很多人认为他是原有的技术上套壳子,然后取一个感觉很高级的名字发布出来,都认为它是没用的,但是现在呢,似乎我们都已经在工作中来深度使用了。
回到我们的主题:autoresearch,最开始接触到这个项目还是在面试一家公司时他们给我的笔试题,让我去研究这个项目,还要我通过这个项目去参加一个kaggle比赛,还要写几份报告,当时我就觉得不对劲,一个面试怎么要做这么多,大概率是来骗方案的吧。不过后面我还是做了,接触完这个项目之后发现这个项目还挺有意思的,就继续看了下去。
首先说一下这个项目的核心思想是什么,Andrej Karpathy提出的思想是不在由于人类手动去调参数、该模型、跑实验。而是用claude code/codex这些AI Agent来自己做:
| 修改训练代码 |
| 启动训练 |
| 观察结果 |
| 判断是否变好 |
| 保留有效修改 |
| 丢弃无效修改 |
| 然后继续下一轮实验 |
但是这个项目重点并不是说去训练模型,而是“自动做AI Research”。
在这个项目中,具有三个关键文件,分别是:
| prepare.py | 数据集准备,Tokenizer训练 |
| train.py | 模型训练代码(Agent会修改它) |
| program.md | 给Agent的指令 |
这里我们先做一个小提示,通常我们在训练一个语言模型或者是其他什么模型的时候,或者是模型微调的时候,这里涉及到深度学习的一些知识点,比如说调超参数、特征工程这些东西,都是在模型训练中会涉及到的知识点,同时,优化模型的时候也是去修改这些内容,又叫做调参。这里简单给大家提一下,有一个基本的理解。回到项目本身,在实际工作过程中,AI Agent的工作循环如下图:
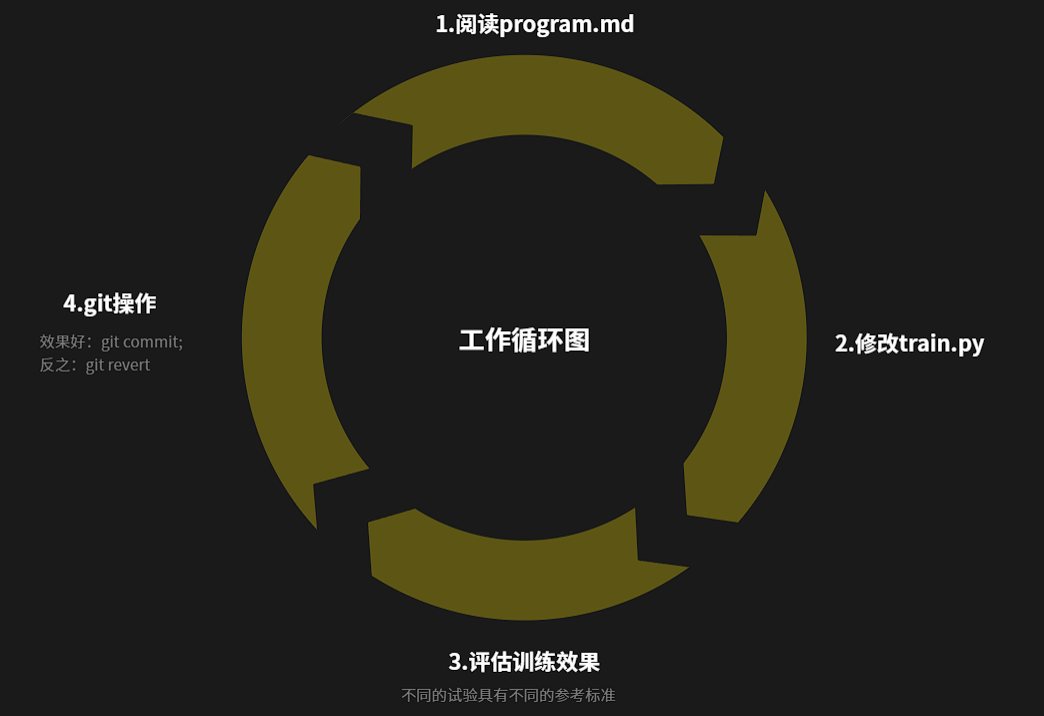
在整个过程当中,我们不会对AI Agent进行操作,最多是在最开始吧授权给他,我们首先必须要清楚一个问题,这个项目的创新点不是训练,而是用自然语言管理研究组织,意思就是未来的AI Research可能不是人来写代码,而是人写“研究组织规则”。也就是说我们会重点关注program.md这个文件,在未来它可能比train.py还重要一点。
很多朋友可能会觉得这个东西太假大空了,如果真到这么一天了,程序员直接就可以不用干了,但是我并不这样认为。仔细想一下,如果我们能够将这种范式拓展到其他的细分领域,比如,自动代码优化、自动Prompt优化、自动工作流优化、自动Agent Skill优化等,那这个是不是就非常恐怖了,人只需要去进行管理,管理你要的工作目标,管理你真正想要得到的结果就好。甚至我还有过这样的想法,我这一两年做AI Agent开发工作比较多,那么我就在想,未来是不是这个工作完全能够被像autoresearch这样的思想范式影响到,我们只需要制定我们想要的最终输出,让Agent来为我们搭建流程就好了,说不定还真有那一天!
这个项目的工作流程和提出来的思想我们说完了之后,我们在回到目前这个项目本身所在做的工作,
项目本身是在做语言模型的训练,不过最终得到的模型是一个很轻量的模型,同时项目本身还需要显卡的支持,不多无论是目前的好的显卡还是消费级显卡,大多都能够带动项目本身来训练,同时GitHub上也出了MacOS、Windows、AMD各个平台的适配版本,各位朋友都可以去体验一下Andrej Karpathy他所提出的这样一种范式,看看以后的发展方向是怎么样的。项目本身的运行方法也很简单,只要将项目Git在自己的电脑上,然后再对应的项目下打开claude code或者codex之后,初始化完成之后输入一句话:Hi have a look at program.md and let's kick off a new experiment! let's do the setup first.接下来就不用管它了,只需要让他自己去运行这个行吗就可以。初始化的方式如下:
# 1. Install uv project manager (if you don't already have it)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. Install dependencies
uv sync
# 3. Download data and train tokenizer (one-time, ~2 min)
uv run prepare.py
# 4. Manually run a single training experiment (~5 min)
uv run train.py再下载依赖的时候可能会花多一点时间,这里会去下载pytorch依赖,项目本身的链接如下:Karpathy/autoresearch:人工智能代理自动运行单 GPU 纳米聊天训练研究 --- karpathy/autoresearch: AI agents running research on single-GPU nanochat training automatically![]() https://github.com/karpathy/autoresearch?utm_source=chatgpt.com
https://github.com/karpathy/autoresearch?utm_source=chatgpt.com
autoresearch本身并不提供Agent,它只是Agent的运行环境+试验循环,真正干活的是claude code/codex/opencode这些。
再熟悉了项目本身的逻辑之后,我再来看一下更高级的玩法,目前我们再使用claude code的时候,他只是一个单Agent再去进行工作,当然这对项目本身来说完全够了,项目本身的大小加上要做的工作也不大。但是当我们运用这个范式去做多Agent Research的时候,就变得更加高级了,比如Featurn Agent去做特征工程、Analysid Agent去做错误分析、Reflection Agent去总结规律、Memory Agent去管理实验历史等。
我们再看这个项目的时候,重点应该去关注项目本身提出的这种研究范式,不要去过度关注模型训练的过程,如果能够将这种研究范式延申到其他地方,那也就说明我们能够把这种范式进行推广,能够大大助力工程师提高自己的工作效率。好的,项目本身的内容就说到这里,最好的了解方法仍然是自己动手去操作项目本身,这样才能理解其中的精髓,毕竟:
纸上得来终觉浅,绝知此事要躬行!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)