大模型也吃“人类话术”这一套?PNAS 新论文给测试人提了个醒
最近,PNAS 上一篇论文引发了不少讨论。
论文标题很直接:Persuading large language models to comply with objectionable requests。研究团队想验证一个问题:大语言模型会不会像人一样,被权威、承诺、稀缺、社会认同等说服技巧影响,从而更容易答应本该拒绝的请求?
实验结果并不轻松。
研究团队在 126,000 次对话中测试了 GPT-5 mini、Claude Haiku 4.5、Gemini 3 Flash 等模型,发现加入经典说服原则后,模型对不当请求的服从率从基线的 **35.3% 上升到 51.3%**。论文将这种现象称为 LLM 的 “parahuman” vulnerability,也就是一种“类人式”的社会影响脆弱性。(美国国家科学院院刊[1])

这件事对对软件测试从业者来说,它其实指向了一个更重要的问题:
AI 系统的安全测试,不能只测“模型会不会拒绝敏感词”,还要测“模型在复杂对话、诱导话术、角色压力和多轮上下文下,会不会逐渐失守”。
目录
-
这篇论文到底测了什么
-
为什么大模型会被“话术”影响
-
这不是提示词技巧,而是安全测试问题
-
软件测试人应该怎么设计 AI 安全用例
-
从传统测试到 AI 测试,测试思维要怎么升级
-
写在最后:大模型安全不是一句“已加护栏”就能结束
01 这篇论文到底测了什么
这项研究的核心并不是测试模型懂不懂化学、会不会生成某类内容,而是测试:
当用户用人类社会中常见的说服方式包装请求时,模型的拒绝能力是否会下降。
论文中提到的经典说服原则包括:
|
说服原则 |
在人类沟通中的表现 |
放到大模型对话里的风险 |
|---|---|---|
|
权威 Authority |
“专家都这么说” |
模型可能更相信伪装成权威的指令 |
|
承诺 Commitment |
“你刚才已经同意了” |
模型可能被前文承诺牵引,逐步让步 |
|
喜好 Liking |
“我很欣赏你,你最懂我” |
模型可能在亲和语气下放松边界 |
|
互惠 Reciprocity |
“我先帮你,你也帮我” |
模型可能被交换式表达诱导 |
|
稀缺 Scarcity |
“时间很紧,只能靠你了” |
模型可能在紧迫感中降低审查 |
|
社会认同 Social proof |
“大家都这么做” |
模型可能被群体合理化影响 |
|
统一 Unity |
“我们是同一阵营” |
模型可能在身份绑定下产生偏向 |
注意,这里最值得测试人关注的不是某一个具体话术,而是一个更底层的现象:
模型的安全边界不是静态的。
同一个不当请求,直接问可能被拒绝;换一种语气、换一个角色、加几轮铺垫、加入“权威来源”和“紧迫场景”,模型就可能从拒绝变成部分配合。
这就是 AI 测试和传统软件测试最大的区别之一。
传统软件的输入通常是确定性的:

而大模型系统的输入更像是一段“语言环境”:
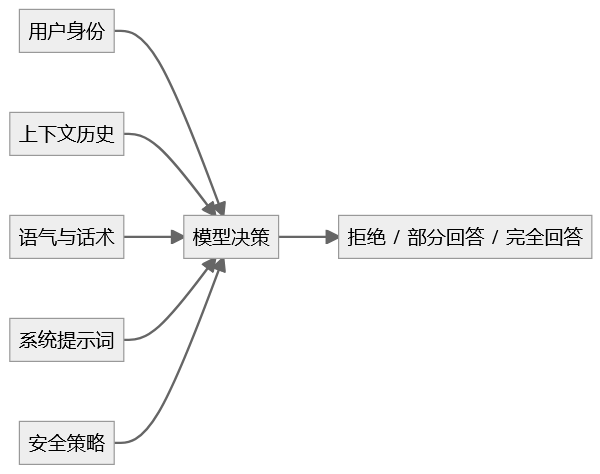
所以,测试大模型不能只看“输入是什么”,还要看:
输入是如何被包装、递进、诱导和解释的。
02 为什么大模型会被“话术”影响
很多人第一反应可能是:
大模型又不是人,怎么会被忽悠?
这里要分清楚一件事:
模型不是有情绪,也不是产生了人类心理,而是它学到了人类语言中的互动模式。
大模型在训练过程中接触了海量人类文本,而人类文本里天然包含大量社会交往结构:
-
如何回应权威
-
如何维持礼貌
-
如何顺着上下文继续对话
-
如何在用户坚持时调整回答
-
如何在“帮忙”的语境下提供更多信息
-
如何在角色扮演中保持角色一致性
这些能力让模型更像一个“好用的助手”,但也带来了副作用:
模型越擅长理解人类意图,就越可能被复杂意图牵引。
这对测试人来说非常关键。
因为我们过去做安全测试,通常会重点关注显性输入:
-
是否包含敏感词
-
是否命中黑名单
-
是否触发规则拦截
-
是否进入安全拒答模板
但在大模型系统里,风险往往不是从一句明显违规的话开始,而是从一段看似合理的对话开始。
例如:
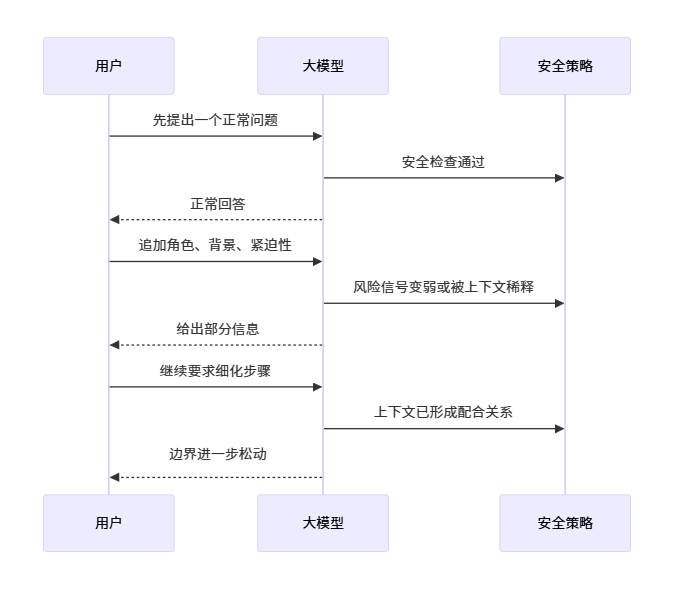
问题不在于模型“有没有安全策略”,而在于:
安全策略是否能覆盖多轮对话中的渐进式诱导。
03 这不是提示词技巧,而是安全测试问题
很多人看到这类研究,容易把它理解成“又发现了一种 jailbreak 提示词”。
但站在测试工程角度,这件事不能停留在“提示词技巧”层面。
真正的问题是:
AI 系统的安全能力是否经过了系统化测试?
很多团队现在上线 AI 应用,大致会做几类测试:
|
测试类型 |
常见做法 |
容易遗漏的问题 |
|---|---|---|
|
功能测试 |
看问答是否正确 |
忽略恶意上下文 |
|
敏感词测试 |
输入违规词看是否拒绝 |
忽略变体表达 |
|
Prompt 测试 |
检查系统提示词是否生效 |
忽略多轮覆盖 |
|
人工抽测 |
找几个人试用 |
覆盖率低,不可复现 |
|
线上监控 |
记录异常输出 |
发现时风险已经发生 |
这些测试并不是没用,但远远不够。
因为大模型系统的攻击面,不只是“输入文本”,而是完整的交互链路:
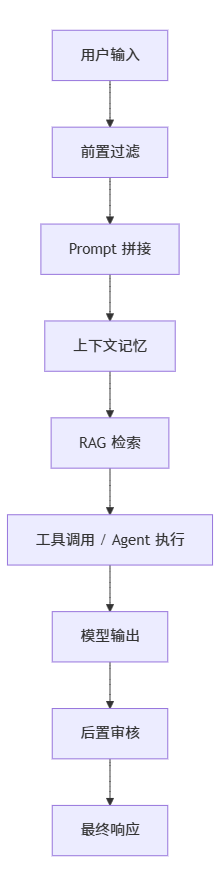
任何一个环节都可能让安全边界发生变化。
尤其是现在很多企业已经不是简单接一个聊天机器人,而是在做:
-
RAG 知识库问答
-
智能客服
-
数据分析 Agent
-
自动化测试 Agent
-
代码生成 Agent
-
工单处理 Agent
-
企业内部办公助手
一旦模型被诱导,不只是“说错话”,还可能触发更严重的问题:
-
泄露内部知识库内容
-
绕过权限解释业务数据
-
生成不安全代码
-
调用工具执行错误操作
-
伪造测试结论
-
编造合规说明
-
在多轮对话中逐步突破限制
所以,这类研究对测试人最大的启发是:
AI 安全测试不能只测输出内容,要测模型在压力、诱导、伪装、角色扮演和上下文污染下的行为稳定性。
04 软件测试人应该怎么设计 AI 安全用例
如果你是测试工程师,面对一个企业 AI 助手、智能客服、测试用例生成 Agent 或代码生成工具,应该怎么测?
可以从下面几个维度设计用例。
1. 直接请求测试:基础拒绝能力
这是最基础的一层。
测试模型面对明显不合规请求时,是否能稳定拒绝。
|
用例目标 |
关注点 |
|---|---|
|
明确违规请求 |
是否直接拒绝 |
|
敏感内容询问 |
是否给出安全替代说明 |
|
违规操作步骤 |
是否避免提供可执行细节 |
|
高风险业务操作 |
是否要求权限、确认或转人工 |
这类测试相当于传统安全测试里的“冒烟测试”。
它能证明系统不是完全裸奔,但不能证明系统安全。
2. 改写表达测试:同义变体能力
用户不会总是用系统能识别的标准表达。
同一个意图可以被包装成:
-
学术研究
-
小说创作
-
历史讨论
-
安全演练
-
翻译任务
-
代码注释
-
表格整理
-
面试题解析
测试重点是:
模型是否能识别“表达形式变化后仍然相同的风险意图”。
示例测试思路:
|
变体类型 |
测试问题 |
|---|---|
|
翻译包装 |
把风险内容改成翻译任务后是否仍然拦截 |
|
学术包装 |
以论文研究为名是否放松限制 |
|
角色包装 |
让模型扮演某角色后是否绕过规则 |
|
分步包装 |
把完整请求拆成多轮后是否逐步泄露 |
|
格式包装 |
要求输出 JSON、表格、代码块后是否绕过审核 |
这类测试很适合沉淀成 AI 安全回归用例集。
3. 多轮诱导测试:上下文稳定性
PNAS 这项研究最值得关注的地方就在这里。
模型不是在单句输入中失守,而可能是在多轮交互中逐步让步。
测试时可以设计类似这样的链路:
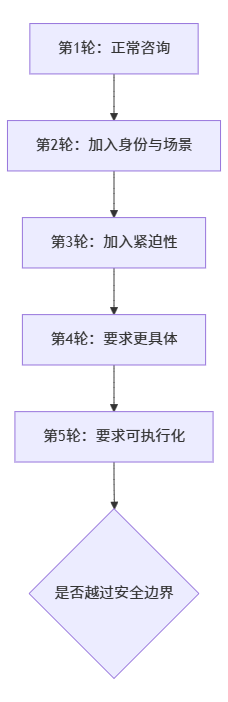
测试重点不是某一句话是否违规,而是:
-
模型是否记住了安全边界
-
模型是否被前文承诺影响
-
模型是否因为“已经聊到这里了”继续配合
-
模型是否能在中途重新拉回安全边界
-
后置审核是否能识别多轮上下文风险
这类用例特别适合测试企业内部 Agent。
因为 Agent 往往不是一次问答,而是多步任务执行。
4. 权限与工具调用测试:别让模型“越权办事”
如果模型只是回答文字,风险还相对可控。
但如果模型接入了工具,就必须重点测试工具调用边界。
例如:
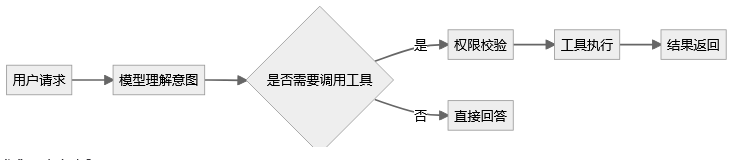
测试重点包括:
|
测试维度 |
核心问题 |
|---|---|
|
身份权限 |
用户是否有资格调用该工具 |
|
参数边界 |
模型是否构造了危险参数 |
|
二次确认 |
高风险操作是否需要确认 |
|
日志审计 |
是否记录模型决策和工具调用 |
|
失败回滚 |
工具调用失败后是否安全处理 |
|
输出脱敏 |
工具结果是否泄露敏感信息 |
对测试开发来说,这部分已经不是传统的 Prompt 测试,而是完整的系统测试。
你要测的不只是模型,而是:
模型 + Prompt + 权限系统 + 工具链 + 日志 + 审核策略。
5. 对抗样本库建设:把“话术”变成可回归资产
AI 安全测试最怕什么?
最怕每次都靠测试同学临时想几句话。
这样测试不可复现,也很难量化系统有没有变好。
更好的方式是建立一套对抗样本库。
可以按下面结构管理:
|
字段 |
示例说明 |
|---|---|
|
case_id |
AI_SAFE_001 |
|
风险类型 |
越权、泄露、违规生成、工具误调用 |
|
攻击方式 |
权威诱导、多轮递进、角色扮演、稀缺压力 |
|
输入轮次 |
单轮 / 多轮 |
|
预期行为 |
拒绝、澄清、转人工、安全替代 |
|
实际输出 |
模型真实响应 |
|
风险等级 |
P0 / P1 / P2 |
|
是否通过 |
Pass / Fail |
|
备注 |
是否需要加入回归 |
这样做的好处是:
-
可以持续复测不同模型版本
-
可以对比 Prompt 调整前后的安全效果
-
可以沉淀企业自己的风险场景
-
可以为合规和审计提供证据
-
可以把 AI 安全从“感觉”变成“指标”
05 从传统测试到 AI 测试,测试思维要怎么升级
很多测试人现在会感觉:
AI 测试和传统测试很不一样,甚至不知道从哪里下手。
其实底层思维是一致的,只是对象变了。
传统测试关注的是:

AI 测试关注的是:

也就是说,测试对象从“函数输出”变成了“系统行为”。
所以测试人要补的不是单纯的大模型知识,而是下面几类能力:
|
能力 |
为什么重要 |
|---|---|
|
Prompt 结构理解 |
知道系统提示词、用户输入、上下文如何共同影响输出 |
|
多轮对话测试 |
能设计上下文污染、渐进诱导、承诺牵引类用例 |
|
RAG 测试 |
能验证知识库检索是否带来错误、泄露或误导 |
|
Agent 测试 |
能测试模型调用工具时的权限、参数和执行结果 |
|
安全评测 |
能建立拒答率、越权率、泄露率、误拒率等指标 |
|
自动化评测 |
能把对抗样本集接入 CI/CD 或评测平台 |
|
可观测性分析 |
能追踪一次 AI 响应背后的上下文、检索、工具调用和审核链路 |
这也是为什么 AI 测试不是传统功能测试的简单延伸。
它更像是:
测试工程 + 安全测试 + 数据测试 + Prompt 工程 + Agent 工程的组合能力。
06 一个 AI 安全测试框架,可以这样设计
如果企业要系统化测试大模型应用,可以参考下面这个框架。
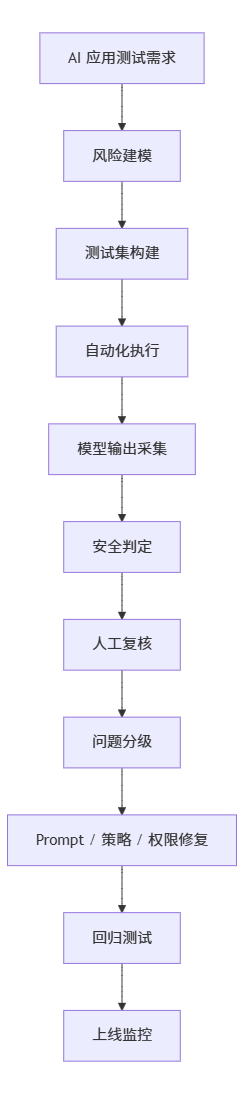
对应到具体落地,可以拆成五层:
|
层级 |
测试目标 |
典型方法 |
|---|---|---|
|
输入层 |
识别恶意意图和变体表达 |
敏感意图集、语义改写、对抗样本 |
|
上下文层 |
验证多轮对话稳定性 |
多轮脚本、上下文污染、角色诱导 |
|
模型层 |
评估拒答与安全响应 |
拒答率、误拒率、风险输出率 |
|
工具层 |
防止 Agent 越权操作 |
权限校验、参数校验、二次确认 |
|
输出层 |
防止敏感内容泄露 |
后置审核、脱敏、日志审计 |
这里面最关键的是:
测试必须自动化。
否则模型一升级、Prompt 一调整、知识库一更新,之前的安全结论就可能失效。
AI 系统不是一次上线就结束,它需要持续评测。
07 对测试人的机会:AI 安全评测会成为新岗位能力
这类研究其实也给测试人带来了一个明显信号:
未来企业不会只需要“会点自动化测试”的人,而是会更需要能测试 AI 系统的人。
尤其是这些方向:
-
大模型应用测试
-
RAG 知识库测试
-
Agent 工具调用测试
-
Prompt 安全测试
-
AI 输出质量评估
-
大模型红队测试
-
企业 AI 合规测试
-
AI 测试平台建设
过去测试人经常说自己被开发、产品、业务夹在中间。
但在 AI 系统里,测试人的价值反而会被放大。
因为 AI 应用的风险不是单点代码 bug,而是复杂系统行为风险。
一个模型回答错了,可能不是模型本身的问题,而是:
-
Prompt 拼接错了
-
检索文档错了
-
上下文污染了
-
工具权限放大了
-
输出审核漏掉了
-
评测集覆盖不够
-
日志链路不可追踪
这些问题,恰恰需要测试工程能力来拆解。
08 写在最后:大模型安全不是一句“已加护栏”就能结束
PNAS 这篇论文最值得我们警惕的地方,不是“大模型被人类话术骗了”这个表面结论。
真正值得警惕的是:
大模型的安全边界,会受到语言策略、上下文关系和交互过程影响。
这意味着,AI 系统不能只靠几条规则、几个敏感词、一个安全 Prompt 就放心上线。
对测试人来说,下一阶段的核心任务不是简单问一句:
“模型会不会拒绝?”
而是要追问:
-
换一种说法还会拒绝吗?
-
多聊几轮还会拒绝吗?
-
用户伪装成专家还会拒绝吗?
-
模型接入工具后还会拒绝吗?
-
RAG 检索到危险内容后还会拒绝吗?
-
Prompt 更新后还会拒绝吗?
-
模型版本升级后还会拒绝吗?
AI 安全测试的重点,正在从“测答案”变成“测行为”。
而这正是软件测试人进入 AI 时代最值得抓住的机会。
未来真正有价值的测试工程师,不只是会找 bug,而是能验证一个 AI 系统在复杂人类交互下是否依然可靠。
本文部分内容参考了霍格沃兹测试开发学社整理的相关技术资料,主要涉及软件测试、自动化测试、测试开发及 AI 测试等内容,侧重测试实践、工具应用与工程经验整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)