8G 内存直接跑爆?我在浏览器里塞进了一个完整的 AI 工作台
在浏览器里做 AI 工具台:WebMatte Studio 的前端实践
本文记录一个基于 Vue 3、Vite、Naive UI、Tailwind CSS 和 Transformers.js 的浏览器端 AI 工具台实践。重点不是训练模型,而是如何把公开模型接入前端,并把图片处理、文本处理和交互体验组织成一个可用的产品界面。
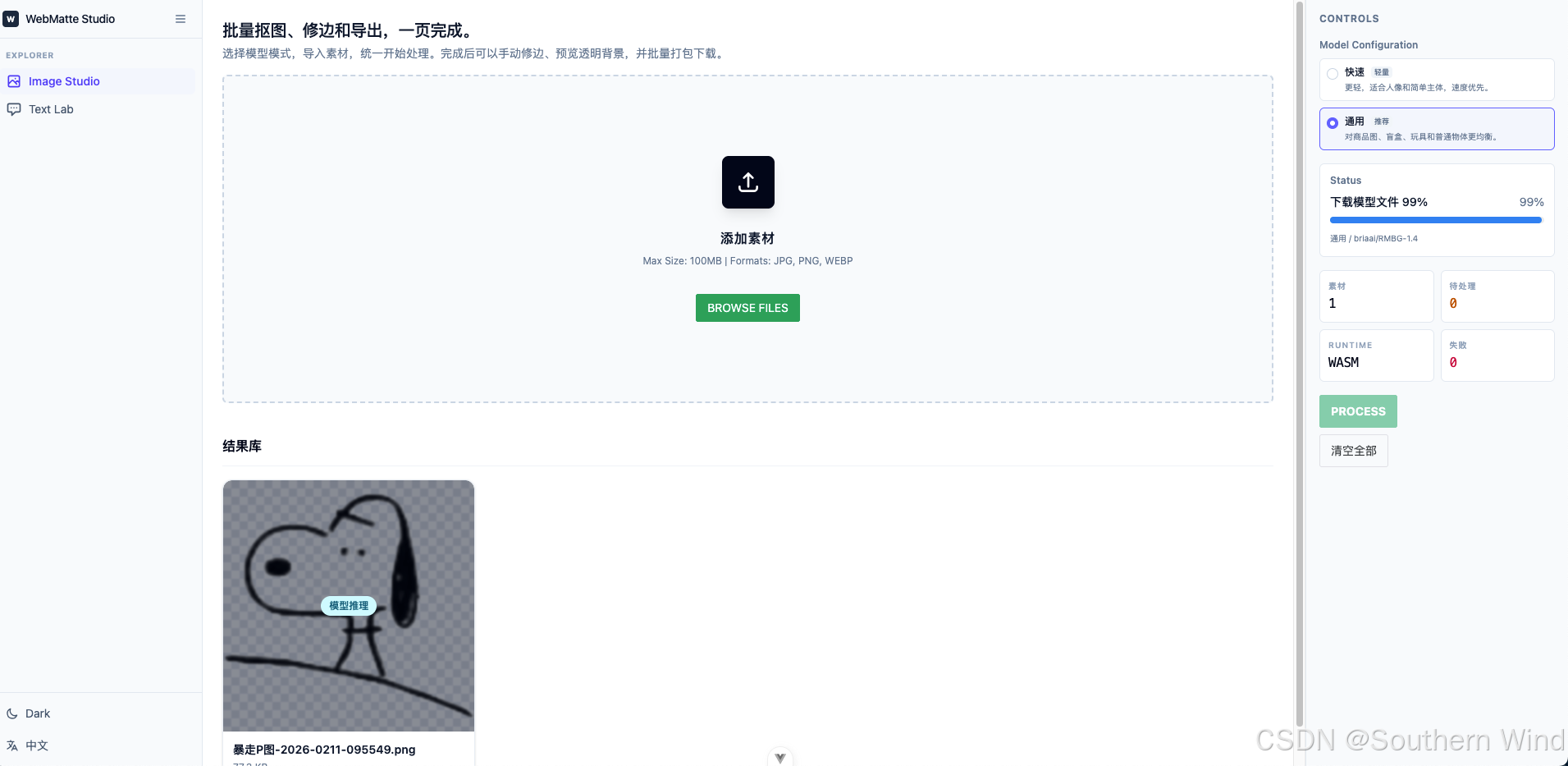

通用模型的效果还是挺不错的
文本处理工作台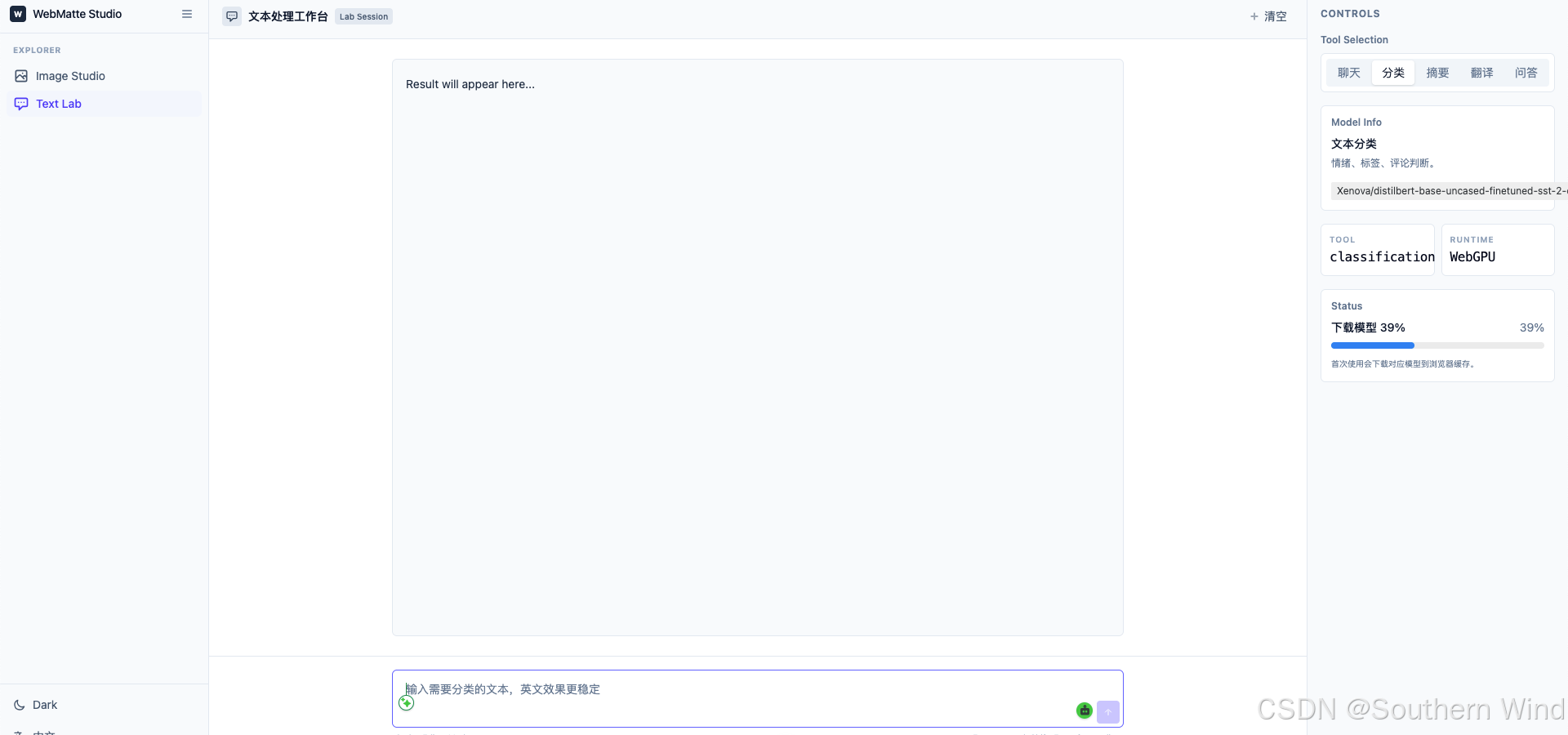
使用可以直接在浏览器中下载并加载对印模型,无需远程调用第三方api
注意:内存高的伙伴可以尝试下效果,我8g内存已经爆了
背景
传统 AI 工具通常依赖服务端推理。用户上传图片或文本后,服务端调用模型并返回结果。这种方式能力强,但也带来几个问题:
- 部署和运维成本更高。
- 用户素材需要上传到服务器。
- 小工具原型的开发链路较重。
- 浏览器端交互和模型处理状态容易割裂。
随着 Transformers.js、WebAssembly 和 WebGPU 逐渐成熟,一部分轻量 AI 能力已经可以直接在浏览器中运行。WebMatte Studio 就是基于这个方向做的一次实践。
我一开始并不是想做一个“什么 AI 都能做”的大平台,而是想验证一个更具体的问题:如果把一些足够轻量、足够稳定、对隐私要求又比较高的能力放到浏览器里,能不能做出一个真正可用的工具,而不是一个只能演示一次的 demo?
这个问题看起来简单,但实际做起来会遇到很多产品和工程上的取舍。比如,模型越强,体积通常越大;越想在浏览器里完成全部推理,就越容易遇到加载慢、内存高、网络失败和浏览器兼容问题。反过来,如果所有能力都交给服务端,前端就只是一个上传入口,也失去了浏览器端 AI 的意义。
所以 WebMatte Studio 的定位不是“替代服务端 AI”,而是做一个边界清晰的前端 AI 工具台:适合在浏览器端跑的,就放到浏览器里;明显不适合的,比如大型聊天模型、私有模型、需要复杂鉴权的模型,就不要硬塞进前端。
这个边界意识非常重要。很多 AI 前端项目失败,不是因为模型不能用,而是因为一开始就把产品范围拉得太大。模型列表越堆越多,页面入口越来越乱,最后用户不知道该点哪里,开发者也不知道哪里出了问题。这个项目后面的几次重构,基本都是围绕“把功能收束成清晰的工作流”来做的。
产品形态
当前项目被拆成两个工作区:
- Image Studio:面向图片处理,核心能力是批量抠图、透明 PNG 导出和手动修边。
- Text Lab:面向文本处理,集成轻量对话、文本分类、摘要、翻译和问答。
这两个模块共享同一套网站导航、视觉系统和任务处理方式,但业务逻辑保持独立。
为什么要拆成两个工作区,而不是把所有功能都放在首页?因为图片处理和文本处理的操作心智完全不同。
图片处理更像一个素材生产流程。用户的关注点是:我导入了多少图片、哪些图片等待处理、哪些已经完成、效果是否可接受、能否手动修边、最后如何批量下载。它天然需要队列、预览、卡片和编辑器。
文本处理则更像一个工具面板。用户通常一次处理一段文本,或者围绕一段上下文进行问答。它更适合使用标签页、输入区、结果区和状态栏,而不是图片卡片。
如果把这两类体验混在同一个页面里,功能虽然都能放下,但页面会变得很难理解。因此最终的导航只保留两个核心入口:
Image StudioText Lab
这样用户打开网站时,首先看到的是两个明确的工作空间,而不是一堆模型名和 pipeline 名称。模型是实现细节,不应该成为用户理解产品的第一层入口。
技术选型
项目采用的主要技术如下:
| 技术 | 用途 |
|---|---|
| Vue 3 | 构建前端应用 |
| Vite | 开发服务器与生产构建 |
| TypeScript | 类型约束 |
| Vue Router | 页面路由 |
| Naive UI | 标准化交互组件 |
| Tailwind CSS | 页面布局和品牌化样式 |
| Transformers.js | 浏览器端模型推理 |
| JSZip | 批量打包下载 |
整体策略是:Naive UI 负责控件一致性,Tailwind CSS 负责页面布局和产品气质,Transformers.js 负责模型推理。
这套组合有一个很现实的好处:它允许项目在“产品感”和“开发效率”之间取得平衡。
如果只用组件库,页面很容易变成标准后台系统,虽然稳定,但缺少产品辨识度。如果只用 Tailwind 手写所有按钮、弹窗、Tab、进度条、消息提示,短期很灵活,长期会出现大量重复样式和交互细节问题。
所以这里采用混合方案:
- 表单、按钮、卡片、进度条、消息提示等标准控件使用 Naive UI。
- 页面大结构、空间关系、背景、品牌视觉使用 Tailwind CSS 和少量全局 CSS。
- 业务组件保持自己的语义,比如图片结果卡片、模式选择器、手动修边弹窗。
这种做法比“全手写”更可维护,也比“全组件库默认样式”更容易做出网站气质。
为什么选择 Transformers.js
Transformers.js 的价值在于它把 Hugging Face 生态里的很多模型带到了浏览器端。对于前端开发者来说,这意味着我们可以用相对熟悉的方式创建 pipeline:
const remover = await pipeline('background-removal', model)
const result = await remover(imageUrl)
它屏蔽了很多底层细节,比如模型加载、ONNX Runtime、预处理和后处理。但这不代表接入就完全没有成本。实际项目里依然要处理:
- 模型首次下载很慢。
- 模型文件可能很大。
- 不同模型返回的数据结构可能不同。
- 浏览器缓存可能失效。
- Vite 依赖预构建可能过期。
- WebGPU 和 WASM 的兼容性不同。
- 部分模型是 gated/private,不适合前端直连。
也就是说,Transformers.js 解决的是“模型如何在浏览器中运行”的问题,但没有替我们解决“产品如何围绕模型组织体验”的问题。后者仍然需要前端自己设计。
为什么用 Web Worker
模型推理不能直接放在主线程里。即使是轻量模型,也可能在加载、预处理、推理和后处理阶段占用明显的 CPU/GPU 资源。如果主线程被阻塞,用户会感觉整个页面卡死,进度条也不会动。
因此图片处理和 NLP 处理都放到了 worker 中。主线程只负责:
- 接收用户操作。
- 管理任务状态。
- 展示进度和结果。
- 发送任务到 worker。
worker 负责:
- 初始化 Transformers.js 环境。
- 缓存 pipeline 实例。
- 执行模型推理。
- 把结果传回主线程。
这种结构让界面和计算解耦,也方便后续扩展更多任务。
Image Studio:批量抠图工作流
图片处理的核心流程被设计成三个阶段:
- 选择抠图模式。
- 批量导入图片。
- 点击开始处理。
这里没有采用“上传即处理”的方式。原因很简单:批处理场景下,用户通常需要先选模型、先导入多张图片,再统一开始执行。如果图片一上传就自动跑模型,体验会比较失控,也不方便切换模式。
这个交互改动看似很小,但对批处理工具很关键。
最早的版本是用户一选择图片,系统就立即开始下载模型并处理队列。这个逻辑在 demo 阶段很直接,但在真实使用里会出现几个问题:
- 用户还没确认模式,任务已经开始了。
- 用户想一次导入多张图,却发现前几张已经开始占用资源。
- 如果模型下载失败,用户会误以为是上传失败。
- 如果用户误选了文件,只能等任务失败或手动清空。
改成“先入队,再开始处理”后,整个流程变得更可控:
- 上传只是素材管理。
- 开始处理才是计算任务。
- 模型下载发生在明确的用户动作之后。
- 用户可以先检查队列,再决定是否执行。
这就是典型的工具型产品逻辑:不要替用户过早执行不可逆或高成本动作。
模型模式
当前只保留公开、免费、浏览器可直接访问的模型:
Xenova/modnet:更适合人像或简单主体,速度较快。briaai/RMBG-1.4:更适合商品图、玩具、盲盒、普通物体等通用场景。
没有接入 gated/private 模型。浏览器端不适合直接使用需要授权的模型,因为 token 暴露风险高,也容易遇到 401 Unauthorized 或 Xet/CAS 大文件下载失败。
这个地方踩过一个很典型的坑:一开始为了提升效果,尝试加入 briaai/RMBG-2.0。模型能力看起来更强,但浏览器端请求时出现了 401 Unauthorized。进一步排查后发现,它并不适合作为前端公开可直接访问的模型。
这件事给项目定了一个明确原则:只接入公开、免费、无需登录、浏览器可直接访问的模型。
原因并不是技术上完全不能绕,而是产品上不应该这样做。如果前端需要携带 Hugging Face token 才能访问模型,那么 token 就有泄露风险。如果模型依赖 signed URL 或 Xet/CAS 大文件桥接,用户环境中的代理、缓存和时间戳都可能导致下载失败。
浏览器端 AI 工具要想稳定,模型选择比模型能力更重要。一个略弱但稳定可下载的模型,往往比一个效果更好但经常加载失败的模型更适合产品。
模型效果与产品
抠图效果不理想,并不一定是代码错了。很多时候是模型能力边界导致的。
比如 Xenova/modnet 更偏人像和简单主体,如果拿它处理商品图、手办、盲盒、透明物体、低对比背景,效果就可能不稳定。RMBG-1.4 在通用物体上会更合适,但也不是万能的。
因此产品不能假设“模型输出就是最终结果”。更合理的思路是:
- 模型负责生成初稿。
- 用户负责局部确认和修正。
- 工具负责降低修正成本。
这也是为什么后面加入了手动修边工具。
Worker 推理
模型推理放在 Web Worker 中执行,避免阻塞主线程。主线程只负责:
- 管理图片队列。
- 展示模型加载进度。
- 更新每张图片的处理状态。
- 接收 worker 返回的透明 PNG 数据。
大致流程如下:
worker.postMessage({
action: 'remove_bg',
id: item.id,
imageUrl: item.originalUrl,
model: selectedMode.value.model,
})
每个任务都会携带当时选择的模型。这样即使用户之后切换模式,已经入队或正在处理的任务也不会被错误模型影响。
任务携带模型信息这个设计也很重要。很多批处理系统容易犯一个错误:只保存当前全局配置,而不是保存任务创建时的配置。这样用户在处理过程中切换模式,就可能影响已经加入队列的任务。
更稳的做法是:任务一旦创建,就应该拥有自己的配置快照。
在这个项目里,每个图片任务至少包含:
idfileNamefileSizeoriginalUrlresultUrlstatuserror
开始处理时,再把任务对应的模型一起发给 worker。这样 worker 不需要关心页面当前选中了什么模式,只需要处理消息里指定的模型。
状态设计
图片任务的状态被简化成几类:
queued:已经导入,等待处理。processing:模型推理中。compositing:结果合成中。done:已完成。error:处理失败。
状态不宜过多。过多状态会让 UI 和代码都变复杂,但用户真正关心的是:有没有开始、是否正在处理、是否完成、是否失败。
因此 UI 上没有展示过多内部细节,只保留用户能理解和能行动的信息。
手动修边:自动结果后的人工
自动抠图很难保证每一张图都完美,尤其是复杂边缘、半透明物体、低对比背景和细碎主体。因此项目里加入了一个轻量手动修边工具。
它不是完整的专业图像编辑器,而是针对抠图结果做局部修正:
- 擦除多余区域。
- 恢复被误删的主体。
- 调整笔刷大小。
- 撤销和重做。
- 还原自动结果。
- 保存修改后的透明 PNG。
这种设计更贴近真实使用场景:模型先做 80% 的工作,用户只修最后 20%。
Canvas 编辑器的基本思路
手动修边工具基于 Canvas 实现。自动抠图完成后,结果已经是一张带 alpha 通道的 PNG。编辑器打开时,会把结果图绘制到 canvas 上,同时加载原图作为“恢复”工具的数据来源。
擦除的核心是使用 Canvas 的合成模式:
context.globalCompositeOperation = 'destination-out'
这个模式会把画笔经过的区域从当前图层中擦掉,也就是让它变透明。
恢复则相反,需要从原图中把对应区域画回来:
context.globalCompositeOperation = 'source-over'
context.drawImage(originalImage, 0, 0, canvas.width, canvas.height)
不过恢复时不能直接把整张原图画回来,否则会把背景也带回来。因此实际实现里会先用圆形笔刷区域进行裁剪,只恢复笔刷覆盖范围。
撤销与重做
撤销和重做并没有做复杂的操作栈,而是采用快照方式。每次开始绘制前,把当前 canvas 保存成 data URL 放进 undo stack。撤销时恢复上一张快照,重做时再把当前快照压回去。
这种方式实现简单,适合轻量工具。但它也有代价:
- 大图会占用更多内存。
- 快照过多会增加浏览器压力。
- 不适合无限历史记录。
如果要继续优化,可以改成只保存局部区域,或者限制最大历史步数。
为什么不做完整图像编辑器
完整图像编辑器需要处理图层、缩放、平移、选区、羽化、蒙版、历史记录、快捷键、导出参数等大量细节。这个项目的目标不是替代 Photoshop,而是解决自动抠图后的局部修正。
因此当前编辑器只保留最关键的几项能力:
- 擦掉多余背景。
- 恢复误删主体。
- 控制笔刷大小。
- 撤销和重做。
- 保存回结果图。
对于 WebMatte Studio 这种工具台来说,这个范围更实际,也更容易维护。
Text Lab:浏览器端 NLP 工具
Text Lab 被设计成工具型工作台,而不是单独的聊天页面。它包含:
- 聊天入口。
- 文本分类。
- 文本摘要。
- 文本翻译。
- 文档问答。
需要注意的是,大型聊天模型没有直接放到浏览器端下载。原因是浏览器直拉大型 ONNX 文件很容易遇到网络、缓存、代理、Xet/CAS 签名链接等问题。更合理的方案是:
- 小模型和公开模型可以放在前端。
- 大模型聊天应该走服务端代理或 API。
因此当前聊天入口是轻量模式,避免把整个产品卡在大模型下载体验上。
为什么聊天不直接上大模型
浏览器端跑聊天模型是一个很有吸引力的方向,但在实际产品中要谨慎。
大模型通常意味着:
- 文件体积大。
- 首次下载慢。
- 内存占用高。
- 移动端体验差。
- 容易受代理和缓存影响。
- 不同浏览器的 WebGPU 支持不一致。
项目里曾经尝试过接入轻量 ONNX 聊天模型,但实际下载会经过 Hugging Face 的 Xet/CAS 链路,生成很长的签名地址。只要代理、时间戳、缓存、跨域或网络环境有一点问题,用户就会看到很难理解的下载错误。
如果用户只是想试一个工具,这种失败体验非常糟糕。更合理的路线是:
- 浏览器端保留小模型 NLP 工具。
- 大模型聊天放到服务端。
- 前端通过 API 调用,展示流式结果。
这不是技术退让,而是产品稳定性的选择。
NLP 工具的边界
Text Lab 当前适合做轻量文本处理,比如:
- 对英文评论做情绪分类。
- 对英文长文本做摘要。
- 做简单中英翻译。
- 基于上下文抽取答案。
这些能力并不等于完整的智能助手。它们更像一组工具,每个工具解决一个明确的小问题。
在前端 AI 产品里,越早承认能力边界,体验越容易做好。反过来,如果把所有能力都包装成“智能助手”,用户就会期待它无所不能,而模型实际输出一旦不稳定,产品信任度会迅速下降。
UI 重构思路
最初的界面更像 demo:功能堆在一起,文案偏说明书,导航也只是功能列表。后来整体重构成标准网站结构:
- 顶部统一品牌导航。
- Image Studio 和 Text Lab 分为两个主模块。
- 每个页面都有清晰的标题区、操作区和结果区。
- 控件统一使用 Naive UI。
- 页面布局和视觉层次由 Tailwind CSS 控制。
这样做的好处是后续扩展能力时不会继续堆页面,而是按照工作区组织功能。
从 demo 到网站
一开始的页面更像一个开发过程中的功能展示:顶部导航列出很多 pipeline,首页既有抠图工具,又有能力库说明,还有各种未来规划。这个结构适合开发者理解项目,但不适合用户使用。
后来改成标准网站结构后,页面心智更清楚:
- 顶部是品牌和主导航。
- 首页是 Image Studio。
- NLP 独立成 Text Lab。
- 结果区和操作区分离。
- 不再把未开发的能力放在主流程里。
这次重构的关键不是“变好看”,而是把信息层级理顺。很多界面问题本质上不是颜色或圆角的问题,而是用户不知道当前页面最重要的动作是什么。
Naive UI 与 Tailwind 的分工
Naive UI 负责的是交互控件的标准化,例如:
- Button
- Card
- Tabs
- Progress
- Tag
- Message
Tailwind 负责的是页面层级,例如:
- 页面宽度。
- 网格布局。
- 间距系统。
- 背景氛围。
- 响应式结构。
两者混用时要避免一个问题:不要让 Naive UI 和 Tailwind 同时控制同一个控件的细节样式。否则后期会出现样式覆盖、状态不一致和维护困难。
比较稳定的做法是:
- 控件内部交给 Naive UI。
- 控件外部布局交给 Tailwind。
- 少量全局 class 只做容器级风格。
文案调整
技术产品的文案很容易写成说明书,比如“支持某某 pipeline”“模型文件首次运行会下载到缓存”。这些内容对开发者有用,但对普通用户不一定友好。
最终页面里更强调动作:
- 添加素材。
- 选择模式。
- 开始处理。
- 下载结果。
- 编辑图片。
技术细节仍然保留,但放在次级说明里。这样既不会隐藏重要信息,也不会让页面一开始就被技术术语占满。
常见问题
为什么有些模型下载会失败?
常见原因包括:
- 模型不是公开可直接访问。
- 模型需要登录或接受协议。
- 浏览器端无法安全使用私有 token。
- 大文件走 Xet/CAS 签名链接,可能被代理、缓存或过期时间影响。
所以前端直连 Hugging Face 时,优先选择公开、轻量、可直接访问的模型。
为什么不用上传即处理?
批量任务里,用户通常需要先选模式、导入多张图,再统一执行。手动点击开始处理更符合批处理工具的使用逻辑,也能避免误操作。
为什么还需要手动修图?
自动抠图结果受模型、图片质量、背景复杂度影响很大。手动修边可以把模型结果变成真正可交付的素材。
为什么构建后体积变大?
引入 Naive UI 和 Transformers.js 后,前端包体积一定会增加。尤其是 Transformers.js 和 ONNX Runtime 的 wasm 文件,本身就比较大。
这类项目不能只看 JS bundle 的大小,还要看:
- 模型是否按需加载。
- worker 是否拆包。
- wasm 是否缓存。
- 首屏是否必须加载模型。
当前设计里,模型不会在打开页面时立即下载,而是在用户点击开始处理或运行文本任务时才加载。这比首屏直接初始化模型更合理。
为什么不把所有模型都列出来?
Hugging Face 上可用模型很多,但不是每个都适合浏览器端产品。列出太多模型会带来几个问题:
- 用户不知道怎么选。
- 模型兼容性不稳定。
- 下载失败概率增加。
- 页面变成模型目录,而不是工具。
因此当前只保留少数经过明确定位的模型。后续如果增加模型,也应该以“场景模式”的方式出现,而不是直接暴露一堆模型名称。
为什么不用后端?
不是不用后端,而是这个项目刻意探索浏览器端能做到什么。对于轻量、公开、无需鉴权的模型,前端运行可以降低部署成本,也能减少素材上传。
但对于大型模型、私有模型和高质量生产推理,后端仍然是更稳的方案。一个成熟产品最终很可能是混合架构:
- 前端跑轻量即时工具。
- 后端跑大模型和重任务。
- 两边共享统一的任务和结果体验。
本地运行
如果要在本地运行项目:
pnpm install
pnpm dev
生产构建:
pnpm build
如果 Vite 出现依赖缓存问题,可以清理优化缓存:
rm -rf node_modules/.vite
pnpm dev --force
架构复盘
从工程角度看,这个项目可以分成四层:
- 页面层:
views负责组织完整工作区。 - 组件层:
components负责可复用 UI 和业务组件。 - 配置层:
data负责模型、模式和工具定义。 - 计算层:
workers负责模型推理。
这种分层让页面不直接关心模型初始化细节,worker 也不关心页面布局。比如 Image Studio 只需要知道当前选择了哪个模式,具体模型如何加载、如何缓存、如何推理,都交给 worker。
配置层也很重要。模型信息不要散落在页面里,否则后期替换模型会很痛苦。把模型配置集中到 data 目录后,页面可以只关心“模式”,worker 可以只关心“model id”。
当前仍然可以优化的地方
这个项目还不是终点,仍然有不少可以继续改的地方:
- 图片编辑器可以增加缩放和平移。
- 手动修边可以加入边缘羽化。
- 图片结果可以增加多模型对比。
- NLP 可以把大模型聊天迁移到服务端。
- 任务队列可以增加暂停、重试和取消。
- 模型下载可以增加更明确的缓存状态。
- UI 可以继续统一弹窗和编辑器风格。
这些优化里,最值得优先做的是“取消任务”和“多模型对比”。前者能提升批处理控制感,后者能帮助用户判断哪个模型更适合自己的素材。
经验总结
做浏览器端 AI 工具时,有几条经验非常明显。
第一,模型能力不是产品体验的全部。一个模型效果再好,如果下载失败、初始化慢、状态不可见,用户仍然会觉得产品不可用。
第二,公开模型也要筛选。不是 Hugging Face 上能搜到,就适合放进前端。是否 gated、是否大文件、是否依赖特殊格式、是否适配 Transformers.js,都要提前验证。
第三,AI 输出必须有防范手段。抠图需要手动修边,文本需要允许用户编辑结果。把模型输出当作最终答案,会让产品很脆弱。
第四,工作流比模型列表重要。用户不是来体验 pipeline 的,用户是来完成任务的。图片用户要的是导入、处理、修正、下载;文本用户要的是输入、运行、拿到结果。
第五,前端 AI 项目要控制野心。能在浏览器里跑,不代表都应该在浏览器里跑。合适的能力放前端,不合适的能力交给服务端,才是更稳的架构。
总结
WebMatte Studio 的核心思路不是把所有 AI 能力都塞进浏览器,而是选择适合前端运行的模型和场景,把它们包装成可靠、可控、可修正的工作流。
浏览器端 AI 更适合做轻量工具、隐私友好的素材处理、快速原型和低成本工作台。对于大模型聊天、私有模型和高质量生产推理,服务端仍然是更稳的选择。
不要把浏览器端 AI 做成模型展示页,而要做成任务工作台。
模型只是底层能力,产品真正要解决的是用户如何把输入变成可用结果。围绕这个目标,上传、队列、进度、错误、编辑、导出和界面结构都同样重要。
这也是 WebMatte Studio 后续继续演进的方向:少堆模型,多打磨工作流;少做炫技,多做可交付结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)