网络原理:HTTP/HTTPS协议
HTTP/HTTPS协议是应用层上的协议,在开始介绍这个协议前,先了解“应用层上的协议”到底有什么用?
“应用层协议”专注于“传输的数据的格式定义或如何使用,作用是什么”。
而我们要介绍的HTTP/HTTPS(全称“超文本传输协议”,“超文本”即可以传输图片,音频,等等包括但不仅限于文本信息的传输协议),这是一个典型的“一问一答”的模型。
HTTP/HTTPS经常应用于两个场景之下:
- 前端网页和后端服务器的交互通信
- 移动app(客户端)与后端服务器的交互通信
这个工作协议的工作流程如上面模型的特征一样“一问一答”:
我们输入一个网址访问时,就会有这种现象(当然也可能设计不止一次的HTTP请求和响应)
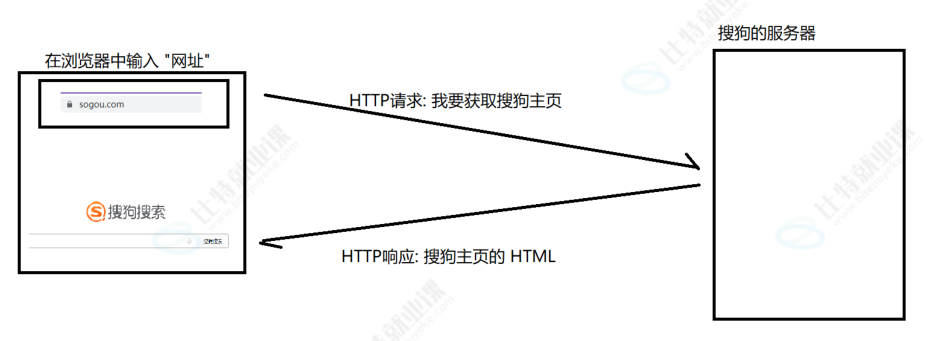
HTTP/HTTPS协议格式
与TCP/IP协议一样,每个协议都会有自己的格式,我们HTTP/HTTPS协议在进行发送“请求”和“响应”的数据都有自己的格式:
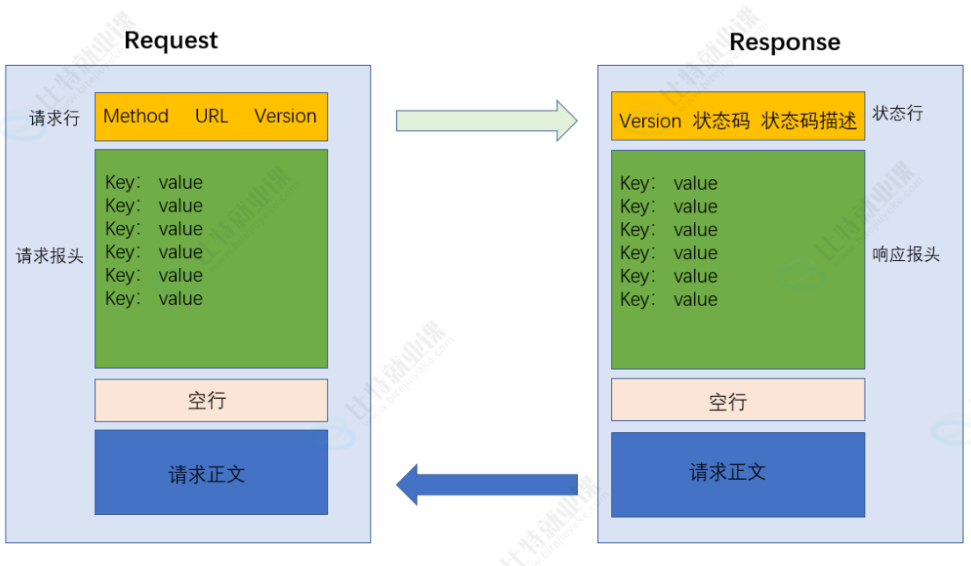
我们可以使用抓包软件获取到详细的“请求”和“响应”的格式特征来给大家介绍:

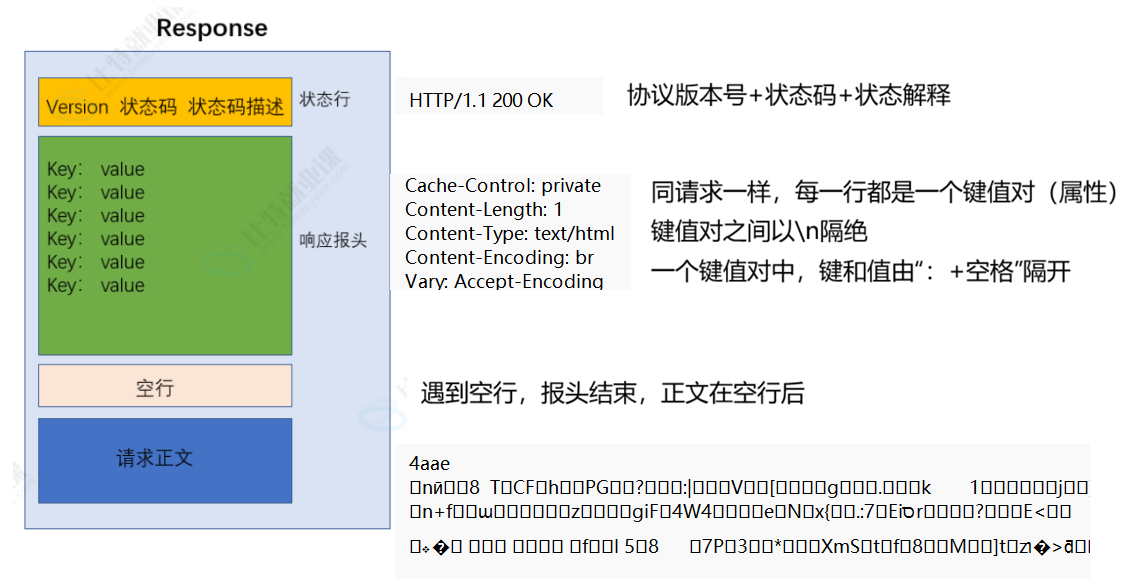
补充:为什么会出现空行的存在?
在HTTP/HTTPS协议中关于传输层是基于TCP实现的--TCP是基于字节流传输,因此可能会出现“粘包”问题,这里加上空行,作为报头的结束,正文的开始,这样不会使传输信息的混乱。
HTTP请求格式中的重要点
URL:统一资源定位符
“URL”其实就是我们平常说的“网址”,它起到一个浏览器根据这个URL在网络上去定位“网址指代的资源”的位置。我们给出一个标准的URL的格式:

我们根据这个标准的URL格式来详细解析一下里面的部分:
1.协议方案名:使用的协议类型
2.登录信息(认证):现在已经基本被弃用(相当于在URL中输入你的账号和密码,肯定很不安全啊!!!所以被淘汰了)
3.服务器地址:一般此处都是一个“域名”,DNS服务器会把“域名”解析成“IP地址”(这里直接填“IP地址”也可行,本质“IP地址”这里)
我们这里就用“Ping”命令解析了百度的“域名”对应的“IP地址”
4.服务器端口号:可以程序员指定端口号(http默认80,https默认443)
5.带层次的文件路径:类似于这个URL,就像我们“文件路径”一样,我们访问的内容是一层夹一层的文件夹中的
6.查询字符串(query string):本质是键值对结构(里面也是很多键值对组成)。键值对z之间用“&”分隔。键和值之间使用“=”分隔(可以与get方法一起起到“正文”的作用,后续再介绍)
https://v.bitedu.vip/personInf/student?userId=10000&classId=100
像这个网址中“userId=10000&classId=100”就是典型的查询字符串
7.片段标识符:实现页面内的跳转(文档文件中常用,看哪部分点击标题,URL中的片段标识符就会换成那个部分的“片段标识符”)
URL中可省略部分:
- 协议名:省略后默认为http://
- ip地址/域名:在HTML中可以省略(网页中),省略后默认该URL的“域名”与当前html的“域名”一致
- 端口号:如果是HTTP/HTTPS协议,http默认80,https默认443
- 带层次的文件路径
- 查询字符串
- 片段标识

URL中的encode:
我们知道query string是程序员自定义的字串,在URL中也有许多拥有特殊含义的字符,因此,如果“程序员定义的内容和URL中的特殊含义字符重合了怎么办?”。
对于这个问题我们URL中有encode的转义规则,这样就解决了由于UTF-8/GBK将字符编码,从而导致的“浏览器把编码中某个字节当作URL的特殊符号”。
转义规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每两位做一位,前面加上%,编码成%XY格式
例如:其中“+”就被转义成了"%2B"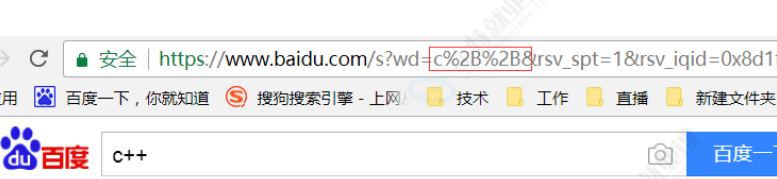
认识方法(请求行中的)
上面我们介绍到,在“请求行”中由“方法+URL+协议版本号”组成。其中“方法”就决定了这次请求是为了“做什么”,我们介绍几种经常使用到的方法(也很容易被抓包到)
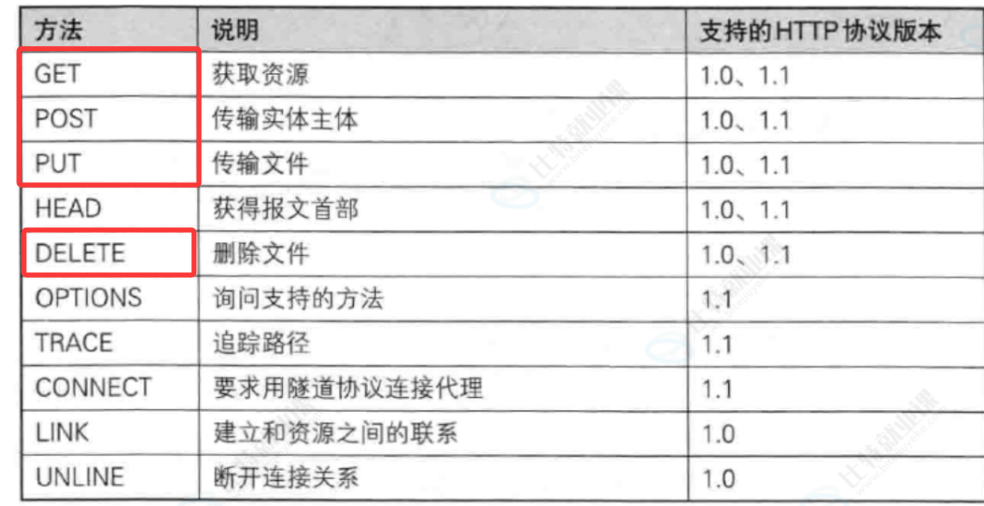
在这么多方法中我们主要介绍get和post(在实际中使用最多的)
get方法:
从字面意思上我们就能知道get方法的大致作用
发起请求--这次请求时为了获取某个网络资源。
我们可以来看一看,一般方法是get的请求的基本格式:
1.URL中可以存在Query String也可以没有
例如,在这里我们就看到URL中有Query String
而这串URL中就没有Query String
2.“请求”中可能没有请求正文(详细我们会在后面介绍),对于绝大多数“请求”一般都是没有“请求正文”的
例如,我们这里抓包到的,“空行”后就没有了下文
3.请求报头中有若干个“键值对”结构




post方法:
post方法也是非常常见的,常用于在请求中“给服务器提交数据”的情况
一般来说,常见于下列两个情况的场景中:
- 登录
- 上传文件
同上面一样,我们同样来看一看post方法的请求的基本格式:
1.一般(绝大数情况下)都会有“请求正文”--毕竟是“提交数据”肯定得有东西作为承载信息的载体吧!
例如,这个post请求中:
2.一般URL中不含有Query String
例如,这个post请求中:
3.header中有许多的“键值对”结构
4.“请求正文”不为空--header中会有“Content Type”和“Content Length”的特有键值对,表示正文的“类型”和“长度”

get和post的特殊补充:
前面我们在介绍get方法和post方法时,专门有提到两个重要的特点“Query String”和“请求正文”的存在。这关系到我们在日常使用时的问题--get也能用来传输数据(实现post类似的效果)
get方法中URL的Query String可以充当“我们发送给服务器的数据信息”
关于get和post方法的具体区别如下:
- get方法是“幂等”的,post方法是“不幂等”的(可以理解成“多次请求得到的结果相同或者明确”--像我们刷B站首页刷新后“视频都是不一样的”,这就是不幂等的)
- get方法可以被缓存,post方法不能被缓存(基于幂等实现的)
- get方法传输信息要使用“Query String”,post方法使用“请求正文”(body)
- get方法一般用于语义“获取”,post方法一般用于语义“发送”
同时,还有许多跟get和post方法相关的误解点:
- post方法比get方法更安全(错误结论):虽然get方法传输信息是暴露在URL里,post方法传输信息“藏”在body中,但是“安全”取决于“是否对信息进行加密”
- post方法传输信息的大小“大于”get方法传输信息(错误结论):虽然get方法是局限于Query String传输(过去的浏览器对URL长度有限制),但是现在已经对URL长度一般无长度限制,理论上不存在一定传递信息大小“小”
- post方法能传输二进制,图像文件;get方法只能传输文本文件(不够准确):虽然get方法的Query String一般是传输文本,但对于“二进制文件”也能先通过encoding转义,再进行传输
其他方法的认识:
- PUT和POST方法相似,但是具有幂等特性,一般用于更新
- DELETE删除服务器指定资源
- OPTIONS返回1服务器所支持的请求方法
- HEAD类似于GET,只不过响应体不返回,只返回响应头(也是获取资源,但是接收到的响应信息格式不同)
- TRACE回显服务器端收到的请求,测试的时候会用到这个
- CONNECT预留,暂无使用
认识请求“报头”中的内容
请求报头中是多个“键值对”组成的,每个“键值对”之间用“\n”隔绝,键与值通过“:+空格”隔开。
我们来介绍报头中几个重要的“键值对”
1.host:服务器的IP地址和端口号(端口号可省略)
例如,这个实例中用“域名”来表示“IP地址”
2.Content-Length和Content-Type(body中数据长度--“字节”和数据格式),一般要有“正文”才会有这两个键值对(告诉浏览器如何理解我们传输的数据)
3.UA(User Agent):表示浏览器/操作系统的属性
UA的产生是历史遗留的问题,之前是为了处理这两方面而产生的:
- 区别是“电脑”还是“手机”在访问网页(好兼容屏幕,显现网页信息)可以看作是“适配效果”
- 根据浏览器版本返回“支持的信息内容”--版本不同的浏览器,兼容的信息不同(有支持文本的,有支持图像的)
4.Referer:表示页面是从哪个部分跳转过来的
例如,我们访问bilibili时:
可以看到我们是通过bing这个搜索引擎来访问bilibili的
5.Cookie:可以在浏览器中查看到
也可以在报头中查看到
关于Cookie的几种作用我们介绍以下几个方面:
1.保持用户的登陆状态:与Session结合使用
相当于“一个存储在本地的令牌”,在访问网页时,随着报头发送过去,网页识别到就会直接通行,登录到你的账户(不用每次都是“账号+输入密码”),等到令牌“过期”,再重新设置存储一个
2.实现访问用户的“个性化设置”体现:
在网页中用户设置的个性化布局等待,都会被Cookie记录下来,下次访问时,根据报头中的Cookie就会自动设置跳转
3.提供网页本地存储数据的方案





正文内容(body)
我们先前谈到,只有有了正文,才会有Content-Type和Content-Length。因此,关于正文的了解,我们也能通过它们来进行,长度不用多说(知道是字节单位就行了),我们看看不同的Content-Type对正文的影响。
一般来说有三种常用的正文类型:
1.application/x-www-form-urlencoded:表单的默认格式,键值对用&连接,空格转+
2.multipart/form-data:用于上传文件,每个字段用boundary分隔,二进制不编码
3.application/json:最流行的API格式,类似结构体,结果清晰
HTTP响应格式中的重要点
状态码
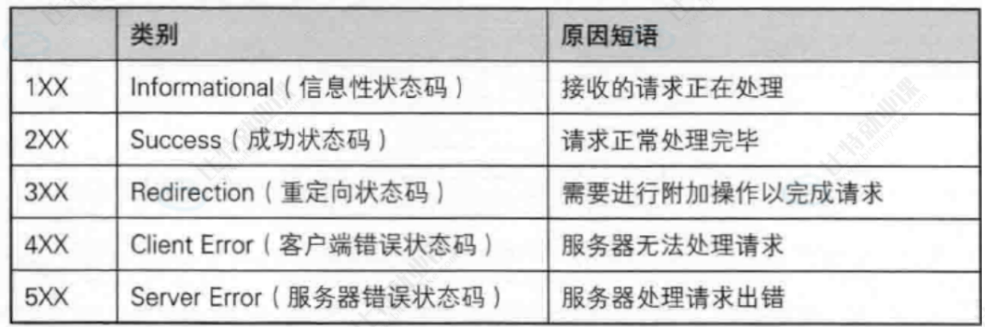
我们发送HTTP请求访问页面之后,响应肯定要给我们一个访问的结果--是成功,还是失败?
因此,响应内容中首行会有我们这次访问的“状态码”--表示结果如何
“2xx”系列状态码(访问成功):
一般我们见到最多的就是“200”状态码,它表示我们成功访问了目标网页--200状态码的响应中的“正文”就是我们请求的返回结果
“4xx”系列状态码(访问失败,“请求方”的问题):
“4xx”系列的状态码--表示我们访问失败,但是失败的原因多和我们“请求方”有关,我们来介绍几个常见的“4xx”系列的状态码。
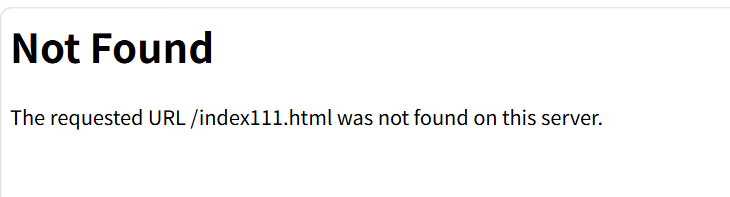
1.404 Not Found(输入的URL有误,无法找到访问内容):
这就是我们常说的404NOT FOUND(别想歪了),这就是我们构造的URL有误,无法在服务器上找到资源。
2.403 Forbidden(无权限访问该内容,被拒绝了):
比如,我们没有权限访问别人的私人仓库,被服务器拒绝了(也算是用户的操作失误)
3.405 Method Not Allowed(服务器不支持,我们请求中的“方法”):
比如,对方服务器不支持post方法,我们使用post方法发送请求时,就会这样。目前不太可能有这种情况,因此,我们没有例子。
“5xx”系列状态码(访问失败,服务器方的问题):
出现“5xx”系列的话,那么就是服务器方出现的问题,导致我们失败的
1.500 Internal Server Error(服务器挂了):
一般都是因为服务器代码执行出现一些bug,导致“服务器挂了”
2.504 Gateway Timeout(服务器连接超时):
一般是因为,服务器负载较大(处理任务太多了出现超时,一般学校大家一起选课就有!)
“3xx”系列状态码(需要进行一些操作):
1.302 Move temporarily(临时重定向):
首先,我们先来了解以下“重定向”==>相当于,原本手机号是“186……”,后面换成“181……”,但是不想让一些人知道,就可以办理一个“呼叫转移”,别人呼叫“186……”就会自动到“181……”
那么我们就能来理解,“临时重定向”一般适用于login界面,你输入比如gitee的网址,但是会先跳转到“登录”,输入完后再到gitee,这就是一个重定向。
2.301 Move Permanently(永久重定向):
永久重定向,服务器收到这个响应时,后续请求就会自动改地址(URL换新)



关于“状态码”的内容详情,我们就总结在下面这张图表中:
认识响应“报头”中的内容
对于,响应中的“报头”其实基本是与“请求报头”一样的,但是有关“Content-Type”和“Content-Length”与“请求报头“中不同。
Content-Type:
- text/html:body数据格式是HTML(一个网页)
- text/css:body数据格式是CSS
- application/JavaScript:body数据格式是JavaScript
- application/json:body数据格式是json
正文内容(body)
因为Content-Type的取值有不同,我们“响应正文”也有不同。
通常情况下是与Type对应的
1.text/html:
2.text/css:
3.application/JavaScript:
4.application/json:

HTTPS
HTTPS也是一个应用层协议,是基于http为基础,进行加密后的一个应用层协议。(主要是对“报头”+“正文”进行加密)。至于这个HTTPS的由来是--十几年前的“运营商事件”,感兴趣的朋友们可以去搜搜看。
关于HTTPS开始前的准备
我们在开始介绍HTTP是如何发展成如今的终极“HTTPS”,需要先引入以下的几个概念:
既然提到加密就要有以下几个概念:
- 明文:传输的数据(本来的样子没有经过任何加工)
- 密文:通过密钥加密后的明文(通常是一些看不懂的乱码,无法辨别出含义一般)
- 密钥:用来加密明文的工具,同时也是解密密文的工具
可以看到”加密“的实现有赖于“密钥”,因此,我们也要提一提常见的密钥:
- 对称加密中的密钥:一般加,解密使用同一个密钥进行
- 非对称加密中的密钥:有公钥和私钥,私钥加密的明文,只能使用公钥解开;公钥加密的明文,只能使用私钥解开。
引入对称加密
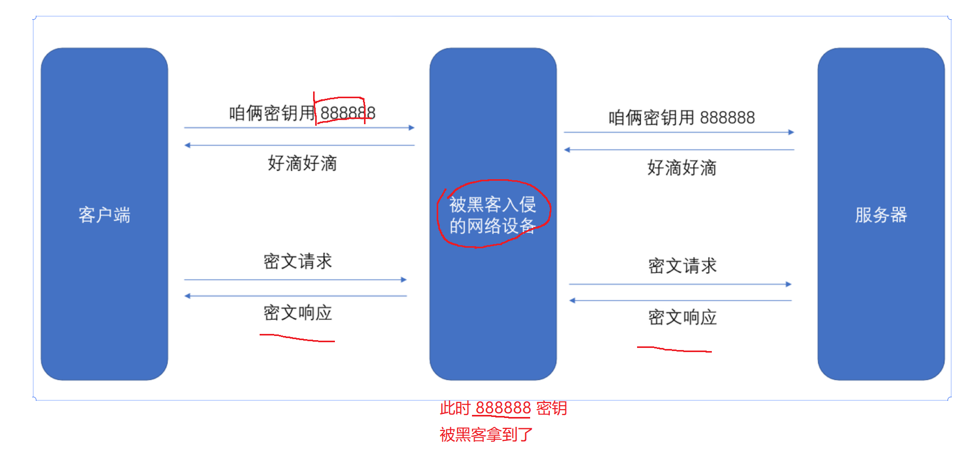
进行对称加密,我们就要先让“客户端”和“服务器”都先拥有密钥,这样才能进行下去。(一般理想状态是:建立连接之前)
可以看到,理想状态下,双方在建立连接前,就协商好了密钥。
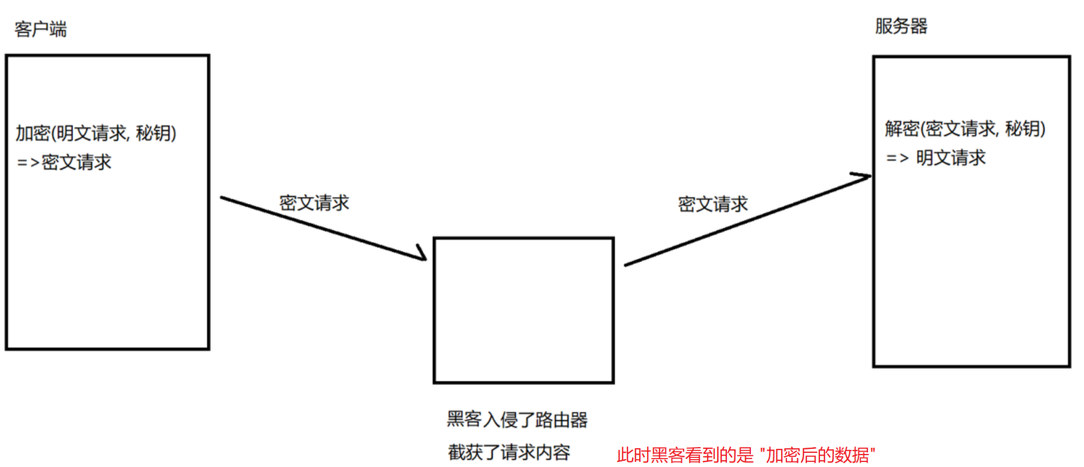
因此,在进行传输信息时,黑客截取的内容是“密文”,由于没有密钥无法破解,也就截取失败了
但是,现实情况是,一般我们的“密文”要通过通信传递给对方,这样黑客就能截取到我们的密钥,从而使我们的加密失效了。
可以看到,只要黑客在我们传递密钥时截取,本次加密就毫无作用了。
也有可能有人问:那我再用一个密钥加密要使用的密钥呢?这就类似于俄罗斯套娃,黑客向上一层层截取你加密密钥的密钥,不就行了。
总之,由此,我们得到一个结论:“密钥要加密后传递,才会真正安全”
引入非对称加密
对于上面我们对称加密最大的问题--“密钥传递时会暴露”来说,非对称加密一定程度上就解决了这个问题:
通过这张图,我们可以看到“非对称加密”解决截取问题的几个重要方面:
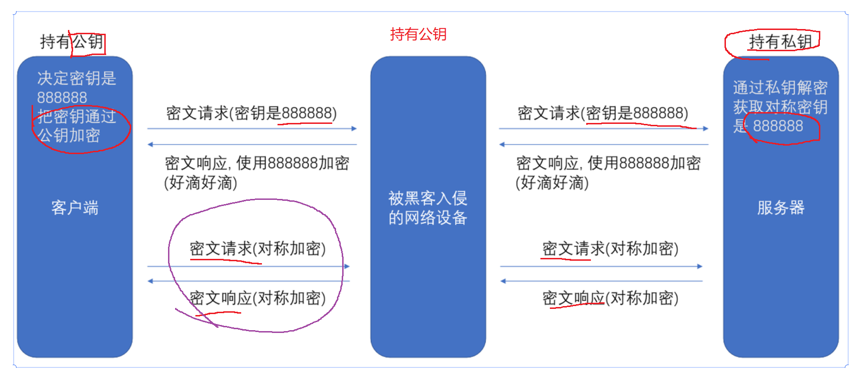
1.服务器生成公,私两密钥。公钥大家都知道(黑客也是),密钥只有服务器持有。
重要前提:“公钥生成的密文只能由私钥解密,私钥生成的密文只能由公钥解密”
2.加密进行的过程
- 核心:仍旧使用对称加密来传输数据--对称密钥效率更高,占有资源少(但是使用公钥加密了“对称密钥”--解决了被截取的毒点)
- 公钥先加密“对称加密”的密钥,黑客没有私钥无法获取到;
- 服务器使用“对称加密”的密钥对传输数据进行加密,黑客即使拥有“公钥”也无法(根本不是一个密钥体系!!!)
3.后续全使用“对称加密”的密钥即可
可以看到引入的“非对称加密”主要是为了解决“对称加密”的毒点,两种加密方式互相结合,才实现了数据的安全传输,但是,黑客明显也不是吃干饭的啊,人家又想到了新的解决方法。
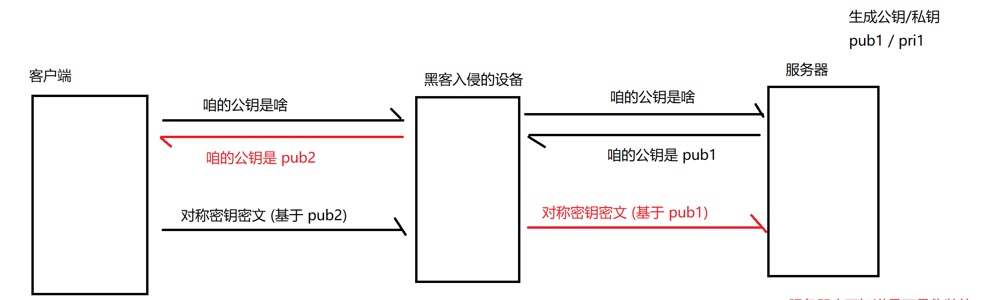
黑客进行的前提:公钥不是一开始客户端就知道
基于这个前提,我们的加密方式就又有了可乘之处:
1.服务器传输公钥pub1给客户端,黑客自己生成一个公钥“pub2”给客户端,冒充服务器
(客户端只能相信对方是服务器)
2.客户端传输基于pub2生成的“对称密钥”发送给服务器,黑客可以拦截并且解密,在使用pub1加密发回服务器
3.服务器接收到“对称密钥”--确信双方连接完毕,后续全使用这个“对称密钥”加密通信(但是黑客也知道“对称密钥”)
在这里主要是因为“公钥”被伪造,才造成的加密通信失效。这种攻击方式,一般被称作
“中间人攻击”
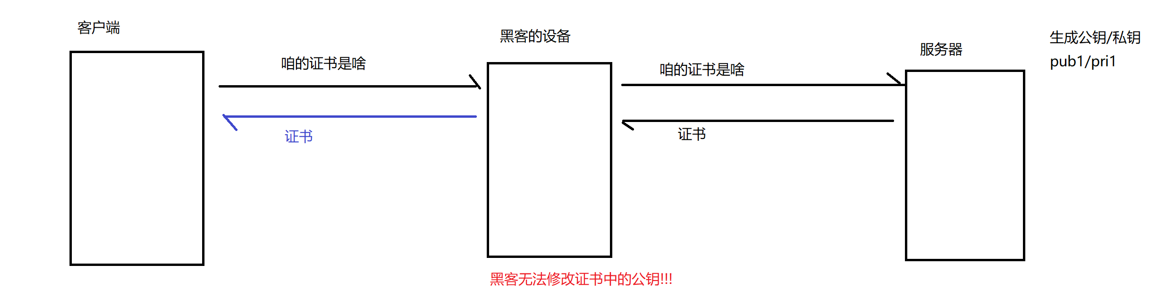
引入证书
首先,我们要认识证书是什么。每个服务器网站的运营方,需要使用自己的域名以及生成的公钥去找第三方机构,第三方机构会使用自己的私钥一系列操作之后,并且给服务器方一个证书。
证书的内容:
- 证书内容
- 证书颁发时间
- 证书有效期
- 服务器方生成的公钥“pub1”
- 签名--(使用pri1的密钥加密,一串hash函数处理过的校验和)
那么为什么“证书”可以有效防止黑客的“中间人攻击”呢?
- “证书”的签名,相当于是用pri密钥加密的,一串hash处理过的校验和
- 黑客更改“证书”上的公钥为“pub2”
- 客户端使用pub2解密签名后计算到的“校验和”与pub1解密出来计算的校验和不同,认为错误!!!
- 黑客不能造假签名!!!(没有私钥pri1)
最后,我们就这样解决了,网络通信中的安全问题。
整个流程如下:
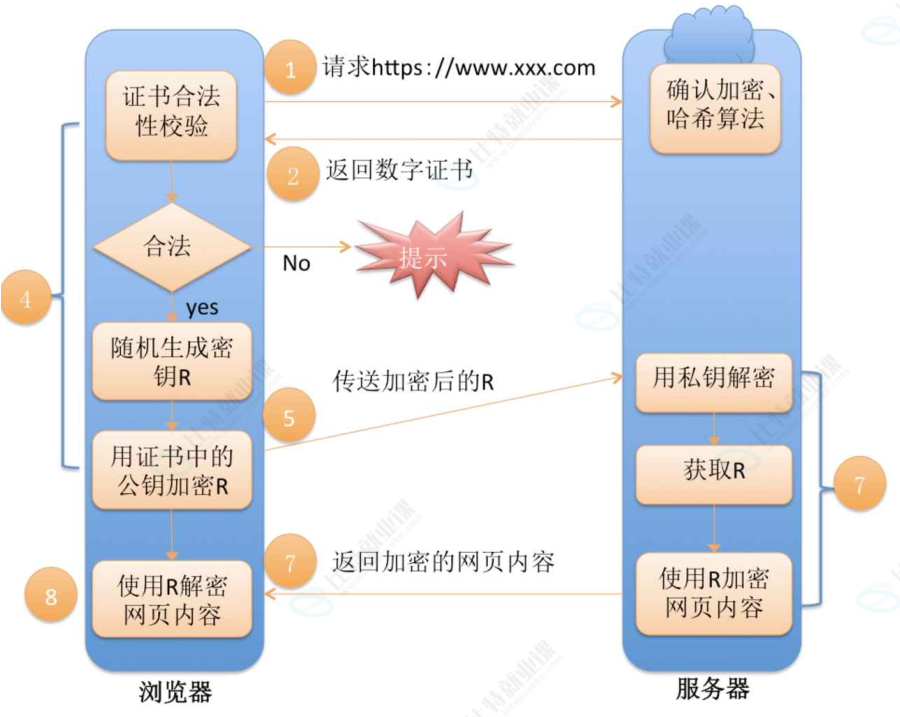
本篇文章到此结束,希望能够帮助大家对HTTP/HTTPS协议有进一步的认识。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)