sft与rl
这篇文章要回答一个问题:同样是让模型变强,为什么 SFT 会让模型更多的忘掉原来会的东西,而 RL 和 OPD 不会?
答案藏在 KL 散度的方向里。但在到达那里之前,我们要从头推导每一步——不是背公式,而是理解"如果是你来设计,你也会这么写"。
从一个具体场景开始
你有一个通用大模型,什么都会一点:写诗、写代码、聊天、做数学。现在你想让它变成医学专家。
路线 A(SFT):收集医学问答数据,让模型背下来。
路线 B(RL):让模型自己尝试回答医学问题,告诉它哪些答案好、哪些不好。
两条路都能让模型学会医学。但路线 A 有个副作用:模型逐渐忘掉怎么写诗、怎么聊天。路线 B 几乎没这个问题。
为什么?要回答这个问题,我们需要先理解 SFT 的 loss 函数到底在做什么。而要理解 loss 函数,我们需要从一个更基本的问题开始。
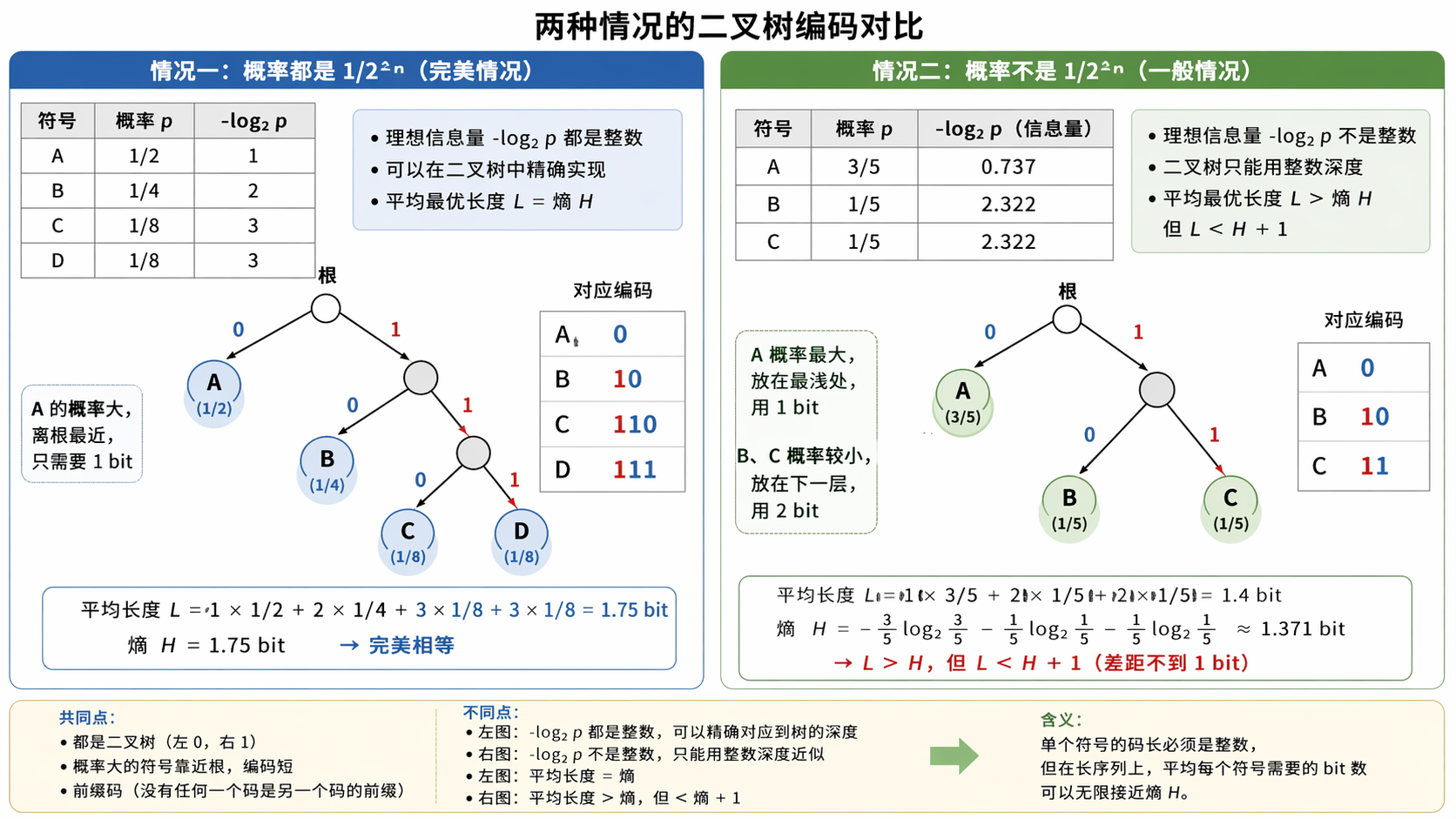
第一章:如果让你设计一套编码,你会怎么做?
问题设定
你和朋友只能用二进制通信(0 和 1)。你们常用 4 个词:
| 词 | 出现概率 |
|---|---|
| “the” | 1/2 |
| “cat” | 1/4 |
| “sat” | 1/8 |
| “mat” | 1/8 |
你要给每个词分配一个二进制编码。目标:让平均消息长度最短。
你会怎么设计?
直觉很明确:常用的词给短编码,罕见的词给长编码。比如:
| 词 | 概率 | 编码 | 长度 |
|---|---|---|---|
| “the” | 1/2 | 0 | 1 bit |
| “cat” | 1/4 | 10 | 2 bit |
| “sat” | 1/8 | 110 | 3 bit |
| “mat” | 1/8 | 111 | 3 bit |
平均消息长度 = 1/2 × 1 + 1/4 × 2 + 1/8 × 3 + 1/8 × 3 = 1.75 bit
最优编码长度是多少?
这里有个关键问题:对于概率为 p 的词,最优编码长度应该是多少 bit?
想想看。如果一个词的概率是 1/2,你需要 1 bit 来区分它(一个二进制位能区分 2 种情况)。如果概率是 1/4,你需要 2 bit(两个二进制位区分 4 种情况)。如果概率是 1/8,你需要 3 bit。
规律出来了:
| 概率 p | 需要区分的情况数 | 需要的 bit 数 |
|---|---|---|
| 1/2 | 2 种里选 1 种 | 1 bit |
| 1/4 | 4 种里选 1 种 | 2 bit |
| 1/8 | 8 种里选 1 种 | 3 bit |
| 1/2ⁿ | 2ⁿ 种里选 1 种 | n bit |
概率为 p = 1/2ⁿ 的词,最优编码长度是 n bit。
现在问题是:怎么从 p 反推出 n?
已知 p = 1/2ⁿ,两边取 log₂:
log2(p)=log2(1/2n)=log2(2−n)=−n\log_2(p) = \log_2(1/2^n) = \log_2(2^{-n}) = -nlog2(p)=log2(1/2n)=log2(2−n)=−n
所以:
n=−log2(p)n = -\log_2(p)n=−log2(p)
也可以写成:
n=log2(1/p)n = \log_2(1/p)n=log2(1/p)
(因为 -log§ = log(1/p),这是对数的性质:log(a/b) = log(a) - log(b),所以 log(1/p) = log(1) - log§ = 0 - log§ = -log§)
验证一下:
- p = 1/2 → -log₂(1/2) = -(-1) = 1 bit ✓
- p = 1/4 → -log₂(1/4) = -(-2) = 2 bit ✓
- p = 1/8 → -log₂(1/8) = -(-3) = 3 bit ✓
结论:概率为 p 的词,最优编码长度 = -log₂§ bit。
熵:平均最优编码长度
现在我们知道每个词的最优长度是 -log§。那平均最优长度是多少?就是对所有词,用概率加权求和:
H(p)=∑xp(x)⋅[−logp(x)]=−∑xp(x)logp(x)H(p) = \sum_{x} p(x) \cdot [-\log p(x)] = -\sum_{x} p(x) \log p(x)H(p)=x∑p(x)⋅[−logp(x)]=−x∑p(x)logp(x)
这就是熵。它不是从天上掉下来的定义——它是"如果你用最优编码,平均每条消息要花多少 bit"这个问题的答案。
验证:H = 1/2 × 1 + 1/4 × 2 + 1/8 × 3 + 1/8 × 3 = 1.75 bit。和我们手算的一样。
第二章:用错了编码本会怎样?
新问题
现在有两个人:
- 程序员 Bob:天天说 “function”(高频)、“whale”(低频)
- 海洋生物学家 Alice:天天说 “whale”(高频)、“function”(低频)
Bob 按自己的词频设计了编码本。如果 Alice 被迫用 Bob 的编码本通信,她的平均消息长度是多少?
Alice 的词频是 p(真实分布),Bob 的编码本是按 q(Bob 的词频)设计的。
Bob 给每个词分配的编码长度是 -log q(x)(对 Bob 来说最优)。但 Alice 用这套编码时,她的平均消息长度是:
Alice 的平均长度=∑xp(x)⋅[−logq(x)]=−∑xp(x)logq(x)\text{Alice 的平均长度} = \sum_{x} p(x) \cdot [-\log q(x)] = -\sum_{x} p(x) \log q(x)Alice 的平均长度=x∑p(x)⋅[−logq(x)]=−x∑p(x)logq(x)
这就是交叉熵 H(p, q)。
它回答的问题是:“用按 q 设计的编码本,去编码来自 p 的消息,平均要花多少 bit?”
浪费了多少?
Alice 用自己的最优编码本只需要 H§ bit。被迫用 Bob 的编码本需要 H(p, q) bit。多花的部分:
浪费=H(p,q)−H(p)\text{浪费} = H(p, q) - H(p)浪费=H(p,q)−H(p)
把两个公式代入展开:
=[−∑xp(x)logq(x)]−[−∑xp(x)logp(x)]= \left[-\sum_x p(x) \log q(x)\right] - \left[-\sum_x p(x) \log p(x)\right]=[−x∑p(x)logq(x)]−[−x∑p(x)logp(x)]
负号提出来,两个负负得正:
=−∑xp(x)logq(x)+∑xp(x)logp(x)= -\sum_x p(x) \log q(x) + \sum_x p(x) \log p(x)=−x∑p(x)logq(x)+x∑p(x)logp(x)
两个求和的下标一样,合并成一个求和:
=∑xp(x)[logp(x)−logq(x)]= \sum_x p(x) \left[\log p(x) - \log q(x)\right]=x∑p(x)[logp(x)−logq(x)]
利用对数性质 log(a) - log(b) = log(a/b):
=∑xp(x)logp(x)q(x)= \sum_x p(x) \log \frac{p(x)}{q(x)}=x∑p(x)logq(x)p(x)
这就是 KL 散度 D_KL(p ‖ q)。
它回答的问题是:“因为用错了编码本(用 q 代替 p),平均每条消息多浪费了多少 bit?”
三者的关系现在很清楚了:
H(p,q)⏟用错编码本的代价=H(p)⏟最优代价+DKL(p∥q)⏟浪费的部分\underbrace{H(p, q)}_{\text{用错编码本的代价}} = \underbrace{H(p)}_{\text{最优代价}} + \underbrace{D_{KL}(p \| q)}_{\text{浪费的部分}}用错编码本的代价 H(p,q)=最优代价 H(p)+浪费的部分 DKL(p∥q)
第三章:KL 散度的方向——整篇文章最关键的一点
同一个故事,换一个人说话
第二章我们算了 D_KL(p‖q):Alice(真实分布 p)在说话,被迫用 Bob(模型 q)的编码本,多浪费了多少 bit。
但这个故事可以反过来讲:如果是 Bob 在说话呢?
Bob 按自己的词频 q 产生消息,被迫用 Alice 按 p 设计的编码本。Bob 的每个词 x 的编码长度是 -log p(x)(Alice 的最优编码),但 Bob 的最优编码应该是 -log q(x)。Bob 多浪费的 bit:
DKL(q∥p)=∑xq(x)logq(x)p(x)D_{KL}(q \| p) = \sum_x q(x) \log \frac{q(x)}{p(x)}DKL(q∥p)=x∑q(x)logp(x)q(x)
公式结构完全一样,只是 p 和 q 的位置互换了。这就是反向 KL。
所以反向 KL 不是谁另外发明的新概念——它就是同一个"用错编码本的浪费",只是说话的人换了。
为什么"谁在说话"这么重要?
在编码本的故事里,"谁在说话"决定了你会遇到哪些词。Alice 说话你会频繁遇到 Alice 的高频词;Bob 说话你会频繁遇到 Bob 的高频词。
在机器学习里,“谁在说话”= 训练样本从哪来:
- SFT:训练样本来自真实数据(p 在"说话")→ 自然产生前向 KL
- RL:训练样本来自模型自己(q 在"说话")→ 自然产生反向 KL
这不是谁刻意选择的——它是"数据来源"这个决定的数学后果。但这个后果影响巨大。
先问一个问题:谁在采样?
用一个具体例子感受差异
假设世界上只有 3 个词,真实分布 p 和模型分布 q 如下:
| 词 | 真实分布 p | 模型 q |
|---|---|---|
| A | 0.5 | 0.9 |
| B | 0.5 | 0.1 |
| C | 0.0 | 0.0 |
真实世界里 A 和 B 各占一半,但模型 q 认为 A 占 90%、B 只占 10%。
计算前向 KL:D_KL(p‖q)——从真实分布 p 采样
DKL(p∥q)=∑xp(x)logp(x)q(x)D_{KL}(p \| q) = \sum_x p(x) \log \frac{p(x)}{q(x)}DKL(p∥q)=x∑p(x)logq(x)p(x)
逐项算:
- 词 A:p(A) × log(p(A)/q(A)) = 0.5 × log(0.5/0.9) = 0.5 × log(0.556) = 0.5 × (-0.588) = -0.294
- 词 B:p(B) × log(p(B)/q(B)) = 0.5 × log(0.5/0.1) = 0.5 × log(5) = 0.5 × 1.609 = 0.805
- 词 C:p© × log(…) = 0 × (…) = 0(概率为 0,直接不贡献)
D_KL(p‖q) = -0.294 + 0.805 = 0.511
为什么单个词的贡献可以是负的?为什么是相加而不是取绝对值?
先算出每个词在两套编码本下的编码长度:
| 词 | 真实概率 p | 模型概率 q | 最优编码长度 -log§ | 模型编码长度 -log(q) | 差值(模型 - 最优) |
|---|---|---|---|---|---|
| A | 0.5 | 0.9 | -log(0.5) = 0.693 | -log(0.9) = 0.105 | 0.105 - 0.693 = -0.588 |
| B | 0.5 | 0.1 | -log(0.5) = 0.693 | -log(0.1) = 2.303 | 2.303 - 0.693 = +1.609 |
- 词 A:最优编码需要 0.693 bit,模型的编码只用 0.105 bit。编码变短了 0.588 bit——看起来"赚了"。
- 词 B:最优编码需要 0.693 bit,模型的编码要用 2.303 bit。编码变长了 1.609 bit——在浪费。
现在 Alice 发 1000 条消息(A 出现 500 次,B 出现 500 次),算三种情况下的总 bit 数:
用最优编码本(熵):
- 词 A:500 × 0.693 = 346.5 bit
- 词 B:500 × 0.693 = 346.5 bit
- 总计:693 bit
- 平均每条:693 / 1000 = 0.693 bit ← 这就是熵 H§
用模型 q 的编码本(交叉熵):
- 词 A:500 × 0.105 = 52.5 bit
- 词 B:500 × 2.303 = 1151.5 bit
- 总计:1204 bit
- 平均每条:1204 / 1000 = 1.204 bit ← 这就是交叉熵 H(p, q)
净浪费(KL 散度):
- 1204 - 693 = 511 bit
- 平均每条:511 / 1000 = 0.511 bit ← 这就是 D_KL(p‖q)
验证:H(p, q) - H§ = 1.204 - 0.693 = 0.511 ✓
注意看:虽然词 A 上模型的编码比最优的短(省了 294 bit),但词 B 上模型的编码比最优的长得多(浪费了 805 bit)。净效果是浪费 805 - 294 = 511 bit。
这就像记账:A 上省了钱(负项),B 上多花了钱(正项),月底算净支出 = 多花的 - 省的。不取绝对值,因为省下来的确实抵消了一部分浪费。
只是数学上可以证明:省的部分永远不够抵消浪费的部分,所以 KL 散度整体永远 ≥ 0(Gibbs 不等式)。只有当 p = q(模型完美匹配现实)时,KL = 0——没有任何浪费。
计算反向 KL:D_KL(q‖p)——从模型 q 采样
DKL(q∥p)=∑xq(x)logq(x)p(x)D_{KL}(q \| p) = \sum_x q(x) \log \frac{q(x)}{p(x)}DKL(q∥p)=x∑q(x)logp(x)q(x)
逐项算:
- 词 A:q(A) × log(q(A)/p(A)) = 0.9 × log(0.9/0.5) = 0.9 × log(1.8) = 0.9 × 0.588 = 0.529
- 词 B:q(B) × log(q(B)/p(B)) = 0.1 × log(0.1/0.5) = 0.1 × log(0.2) = 0.1 × (-1.609) = -0.161
- 词 C:q© × log(…) = 0 × (…) = 0
D_KL(q‖p) = 0.529 + (-0.161) = 0.368
注意看:这次词 B 的贡献很小(只有 -0.161)。为什么?因为现在是从 q 采样,而 q 认为 B 很少出现(q=0.1),所以 B 很少被采到,它的问题就很少被"看见"。
关键洞察:你看不见的问题,你就不会去修
这就是方向的本质区别:
前向 KL D_KL(p‖q):从真实分布 p 采样,检查模型 q 的表现
你从现实世界采样数据,然后问"模型对这些数据解释得好不好"。现实世界里常出现的东西,如果模型给的概率低,惩罚就大。
后果:模型被迫给所有真实世界会出现的东西都分配足够的概率。不能遗漏任何一个。
反向 KL D_KL(q‖p):从模型 q 采样,检查真实分布 p 的表现
你从模型自己采样数据,然后问"这些数据在真实世界里合不合理"。模型自己不会生成的东西,永远不会被采到,永远不会被检查。
后果:模型只需要保证自己会生成的东西是合理的。它可以放弃覆盖真实世界的某些区域——只要它不去那里,就不会被惩罚。
用一个更直观的场景
想象你是一个学生,要学习一门课。有两种考试方式:
考试方式 A(前向 KL):老师出题,考你所有知识点
老师从整个课程大纲里出题。如果某个知识点你完全不会(q ≈ 0),而老师考了它(p > 0),你就挂科。
所以你必须每个知识点都学到,不能有盲区。哪怕学得不精,也得覆盖到。
结果:你什么都会一点,但可能每个都不深。
考试方式 B(反向 KL):你自己出题,老师判对错
你自己选择展示哪些知识。你只会展示你有把握的东西。你不会的知识点,你根本不会提起,老师也就不会发现你不会。
所以你只需要保证你展示的东西是对的。你可以只精通三个章节,完全忽略其他七个章节——只要你不提那七个章节,就不会被扣分。
结果:你展示的部分很精确,但覆盖面可能很窄。
现在回到公式,看看为什么数学上是这样
为什么前向 KL 会惩罚"遗漏"?看公式里什么时候会爆炸:
DKL(p∥q)=∑xp(x)logp(x)q(x)D_{KL}(p \| q) = \sum_x p(x) \log \frac{p(x)}{q(x)}DKL(p∥q)=x∑p(x)logq(x)p(x)
当 p(x) > 0 但 q(x) → 0 时,log(p/q) → +∞,而前面乘的权重 p(x) > 0,所以这一项 → +∞。
翻译成人话,四种组合逐个看:
| 真实世界 p(x) | 模型 q(x) | 这一项的值 | 人话 |
|---|---|---|---|
| > 0 | ≈ 0 | → +∞ | 真实世界会出现,模型说"不可能" → 惩罚爆炸 |
| > 0 | > 0 | 有限值 | 两边都认可,正常计算,没事 |
| ≈ 0 | > 0 | ≈ 0(因为权重 p ≈ 0) | 模型乱生成了,但前向 KL 根本不在乎 |
| ≈ 0 | ≈ 0 | ≈ 0 | 两边都不管,无事发生 |
关键洞察:前向 KL 的求和权重是 p(x)。真实世界不出现的东西(p ≈ 0),不管模型怎么乱放,这一项都被权重压成零——前向 KL 对"模型幻觉"视而不见。
为什么反向 KL 会惩罚"乱放"?看公式里什么时候会爆炸:
DKL(q∥p)=∑xq(x)logq(x)p(x)D_{KL}(q \| p) = \sum_x q(x) \log \frac{q(x)}{p(x)}DKL(q∥p)=x∑q(x)logp(x)q(x)
当 q(x) > 0 但 p(x) → 0 时,log(q/p) → +∞,而前面乘的权重 q(x) > 0,所以这一项 → +∞。
翻译成人话,四种组合逐个看:
| 模型 q(x) | 真实世界 p(x) | 这一项的值 | 人话 |
|---|---|---|---|
| > 0 | ≈ 0 | → +∞ | 模型会生成,真实世界说"不可能" → 惩罚爆炸 |
| > 0 | > 0 | 有限值 | 两边都认可,正常计算,没事 |
| ≈ 0 | > 0 | ≈ 0(因为权重 q ≈ 0) | 真实世界有但模型没学到,反向 KL 根本不在乎 |
| ≈ 0 | ≈ 0 | ≈ 0 | 两边都不管,无事发生 |
关键洞察:反向 KL 的求和权重是 q(x)。模型不生成的东西(q ≈ 0),不管真实世界多需要它,这一项都被权重压成零——反向 KL 对"模型遗漏"视而不见。
总结两种方向的行为
| 前向 KL:D_KL(p‖q) | 反向 KL:D_KL(q‖p) | |
|---|---|---|
| 谁在采样 | 真实分布 p | 模型 q |
| 什么会被惩罚 | 模型遗漏了真实世界的东西 | 模型生成了不存在的东西 |
| 模型的策略 | 宁可模糊,不可遗漏(覆盖所有峰) | 宁可局部精确,不可乱放(只抓一个峰) |
| 术语 | mean-seeking | mode-seeking |
| 谁用它 | SFT | RL / OPD |
为什么这和遗忘有关? 下一章会详细展开,但先记住核心:
- SFT 用前向 KL → 模型被迫覆盖训练数据的所有内容 → 概率从其他地方被抢走 → 遗忘
- RL 天然是反向 KL → 模型只在自己会生成的区域上被评判 → 其他区域不受影响 → 不遗忘
第四章:SFT 的 loss 到底在做什么
从 next-token prediction 说起
语言模型的训练任务是:给定前面的 token,预测下一个 token。模型输出一个概率分布,训练数据告诉你正确答案是什么。
问题来了:怎么衡量模型的预测有多"错"?
你需要一个 loss 函数。什么样的 loss 函数是合理的?
自然的选择
想想看:模型给正确答案 y_t* 分配的概率越高,说明预测越好。对于一个长度为 T 的序列,每个位置都要预测对,所以我们希望最大化整个序列的联合概率:
πθ(y1∗,y2∗,…,yT∗∣x)=πθ(y1∗∣x)⋅πθ(y2∗∣x,y1∗)⋅…⋅πθ(yT∗∣x,y<T∗)\pi_\theta(y_1^*, y_2^*, \ldots, y_T^* | x) = \pi_\theta(y_1^*|x) \cdot \pi_\theta(y_2^*|x, y_1^*) \cdot \ldots \cdot \pi_\theta(y_T^*|x, y_{<T}^*)πθ(y1∗,y2∗,…,yT∗∣x)=πθ(y1∗∣x)⋅πθ(y2∗∣x,y1∗)⋅…⋅πθ(yT∗∣x,y<T∗)
=∏t=1Tπθ(yt∗∣x,y<t)= \prod_{t=1}^T \pi_\theta(y_t^* | x, y_{<t})=t=1∏Tπθ(yt∗∣x,y<t)
这里 π_θ 是模型(参数为 θ)的输出概率分布,x 是输入的 prompt,y_t* 是标准答案中第 t 个 token,y_{<t} 是它前面的所有 token,T 是答案总长度。所以 π_θ(y_t* | x, y_{<t}) 就是:模型看到 prompt 和前面已生成的 token 后,预测第 t 个位置恰好是正确 token 的概率。∏ 是连乘符号,把每个位置的概率乘起来。
但直接最大化这个连乘有个实际问题——概率都是 0 到 1 之间的数,连乘 T 次会变得极小(比如 0.9^100 ≈ 0.00003),计算机处理这么小的数会有精度问题(下溢)。
解决办法:取 log。log 把乘法变加法(这是对数最重要的性质:log(a·b) = log a + log b):
log∏t=1Tπθ(yt∗∣x,y<t)=∑t=1Tlogπθ(yt∗∣x,y<t)\log \prod_{t=1}^T \pi_\theta(y_t^*|x, y_{<t}) = \sum_{t=1}^T \log \pi_\theta(y_t^*|x, y_{<t})logt=1∏Tπθ(yt∗∣x,y<t)=t=1∑Tlogπθ(yt∗∣x,y<t)
因为 log 是单调递增函数,最大化原式 = 最大化取 log 后的式子。
最后,机器学习习惯用"最小化 loss"而不是"最大化目标",所以加个负号:
LSFT=−∑t=1Tlogπθ(yt∗∣x,y<t)\mathcal{L}_{SFT} = -\sum_{t=1}^T \log \pi_\theta(y_t^* | x, y_{<t})LSFT=−t=1∑Tlogπθ(yt∗∣x,y<t)
就是把每个位置的 -log π_θ(模型给正确 token 的概率取负对数)加起来。概率越高,-log 越小,loss 越低。
这就是 SFT 的 loss。它不是谁规定的——它是"让模型给正确序列尽可能高的概率"这个目标的自然数学表达。
这个 loss 就是交叉熵——连接回第一章和第二章
注意 loss 里每一项的形状:-log π_θ(y_t*)。第一章我们已经建立了 -log 的含义——概率为 p 的事件,编码代价 = -log§ bit = 你对它的惊讶度。
所以 -log π_θ(y_t*) 就是:模型对正确答案有多惊讶。模型越确信正确答案(概率高),惊讶越小(-log 小);模型认为正确答案不可能(概率趋近 0),惊讶趋向无穷。SFT loss = 模型对整个正确序列的总惊讶度。
现在和第二章对接。交叉熵的定义是 H(p,q)=∑xp(x)⋅[−logq(x)]H(p, q) = \sum_x p(x) \cdot [-\log q(x)]H(p,q)=∑xp(x)⋅[−logq(x)] = “模型 q 面对真实分布 p 时的平均惊讶度”。训练数据在每个位置的"真实分布"是 one-hot(正确 token 概率 1,其余 0),代入后所有零项消失:
H(pdata,πθ)=1⋅[−logπθ(yt∗)]+0+…=−logπθ(yt∗)H(p_{data}, \pi_\theta) = 1 \cdot [-\log \pi_\theta(y_t^*)] + 0 + \ldots = -\log \pi_\theta(y_t^*)H(pdata,πθ)=1⋅[−logπθ(yt∗)]+0+…=−logπθ(yt∗)
和 SFT loss 的每一项完全一样。SFT loss = 交叉熵。
认出这一点的意义在于,第二章的等式可以直接搬过来:
H(pdata,πθ)=H(pdata)+DKL(pdata∥πθ)H(p_{data}, \pi_\theta) = H(p_{data}) + D_{KL}(p_{data} \| \pi_\theta)H(pdata,πθ)=H(pdata)+DKL(pdata∥πθ)
H(p_data) 是训练数据本身的熵——数据固定,它是常数。所以:
最小化 SFT loss = 最小化前向 KL 散度 D_KL(p_data ‖ π_θ)
这就是桥梁:从"让模型给正确答案高概率"这个朴素目标,经过交叉熵,连接到了第三章的前向 KL——mean-seeking、遗忘的必然性,全部跟过来了。
遗忘是怎么发生的
现在把第三章的结论搬过来。前向 KL 是 mean-seeking:模型被迫覆盖 p_data 有概率的所有地方。
但反过来想:p_data 没有概率的地方呢? 对 loss 完全没有贡献。梯度不关心。
想象模型原来的分布是一座多峰山脉——写诗、代码、医学、聊天各占一个峰。医学数据 p_data 只覆盖医学那个峰。
- 前向 KL 强制模型把概率堆到医学峰上
- 但概率总和 = 1(归一化约束)。给医学加概率,必须从别的峰抢
- 写诗、聊天那些峰的概率被压低——但 loss 不关心它们(因为 p_data 在那里是 0)
- 没有任何力量阻止这些峰塌缩
这就是灾难性遗忘。不是 bug,是前向 KL 的数学性质决定的必然结果。
为什么说 SFT 是 off-policy
还有一个角度理解遗忘。看 SFT 的训练循环:
- 从数据集取一个样本 (x, y*)
- 计算 loss = -log π_θ(y* | x)
- 反向传播,更新参数
注意:y 来自外部数据,不是模型自己生成的。* 模型被迫去拟合一个可能和自己差异很大的分布。
这就像让一个右撇子临摹左撇子的笔迹——他能学会,但过程中会丢失自己原来的书写习惯。因为训练信号完全来自"别人的轨迹",模型自己原来的轨迹无人维护。
冷启动:SFT 的正确用法
既然 SFT 会遗忘,为什么还要用?
因为 RL 有个前提:模型得先能生成"还行"的回答。如果模型完全不会做某个任务(比如从没见过 JSON 格式),它生成的所有样本都是垃圾,reward 信号无法提供有效梯度。
就像让一个从没摸过篮球的人"自由发挥然后给反馈"——他连球都投不到篮筐附近,你没法说"再偏左一点"。你得先教他基本姿势(SFT),然后才能让他自己练习并给反馈(RL)。
冷启动 = 用 SFT 的强制拟合能力,把模型从"完全不会"拉到"基本能做",然后交给 RL。
第五章:RL——让模型在自己的地盘上改进
换一种训练方式
SFT 的问题根源是:训练样本来自外部。那如果训练样本来自模型自己呢?
RL 的训练循环:
- 模型自己生成一个回答
- 一个打分器(reward model)给这个回答打分
- 如果分高,让模型以后更可能生成类似的回答;如果分低,反之
目标:让模型的"平均得分"最高
先用一个简单例子理解"平均得分"是什么。
假设模型面对问题 x = “1+1等于几?”,它可能生成 3 种回答:
| 回答 y | 模型生成它的概率 π_θ(y|x) | 得分 r(x,y) |
|---|---|---|
| “2” | 0.7 | 10 分 |
| “3” | 0.2 | 0 分 |
| “我不知道” | 0.1 | 2 分 |
模型的"平均得分"是多少?就是每种回答的得分,按它被生成的概率加权平均:
平均得分=0.7×10+0.2×0+0.1×2=7.2\text{平均得分} = 0.7 \times 10 + 0.2 \times 0 + 0.1 \times 2 = 7.2平均得分=0.7×10+0.2×0+0.1×2=7.2
写成通用公式:
平均得分=∑yπθ(y∣x)⋅r(x,y)\text{平均得分} = \sum_y \pi_\theta(y|x) \cdot r(x, y)平均得分=y∑πθ(y∣x)⋅r(x,y)
对所有可能的回答 y,把"生成它的概率"乘以"它的得分",然后加起来。
这个加权平均,在数学里有个名字叫"期望"(Expectation),记作 E。 它就是"如果你重复这个随机过程很多次,平均结果会是多少"。
比如上面的例子:如果模型回答这个问题 1000 次,大约 700 次答"2"(得 10 分),200 次答"3"(得 0 分),100 次答"我不知道"(得 2 分)。平均得分 ≈ (700×10 + 200×0 + 100×2) / 1000 = 7.2。
所以:
J(θ)=Ey∼πθ(⋅∣x)[r(x,y)]J(\theta) = \mathbb{E}_{y \sim \pi_\theta(\cdot|x)}[r(x, y)]J(θ)=Ey∼πθ(⋅∣x)[r(x,y)]
这个公式的意思就是:
J(θ)=模型生成的回答的平均得分J(\theta) = \text{模型生成的回答的平均得分}J(θ)=模型生成的回答的平均得分
下标 “y ~ π_θ(·|x)” 的意思是"y 是从模型的分布 π_θ 里随机采样出来的"——也就是说,是模型自己生成的。
RL 的目标:调整参数 θ,让这个平均得分 J(θ) 尽可能大。
为什么这个公式里"期望在 π_θ 上取"很重要?
对比 SFT:SFT 的 loss 是 -log π_θ(y*|x),这里的 y* 来自训练数据。模型不能选择 y* 是什么——数据给什么就是什么。
RL 的 J(θ) 里,求和/期望是对模型自己会生成的所有回答加权的。概率高的回答权重大,概率低的回答权重小,概率为 0 的回答完全不参与计算。
这意味着:模型只需要关心自己会生成的那些回答的得分。 它不会生成的回答,对 J(θ) 没有任何影响。
这就是为什么 RL 不遗忘的根本原因——但我们先把梯度推导完,再回来详细解释这一点。
怎么对这个目标求梯度?——为什么不能像 SFT 那样直接算
回到上面 “1+1等于几” 的例子。SFT 和 RL 的区别,用这个例子就能看清楚。
SFT 的情况: 你有一条训练数据——标准答案是 “2”。Loss = -log π_θ(“2”|x)。这个 loss 只涉及 “2” 这一条路径。你不需要知道模型生成 “3” 的概率是多少,也不需要知道 “我不知道” 的概率是多少。你只需要做一次前向传播(算出模型给 “2” 的概率),一次反向传播(算出梯度),完事。
RL 的情况: 你的目标是 J(θ) = 0.7×10 + 0.2×0 + 0.1×2 = 7.2。注意这个 7.2 是怎么来的——它是三种回答各自的得分,按各自的概率加权求和。每一种回答都参与了计算。
现在问题来了:这个例子里只有 3 种可能的回答,你可以穷举。但真实的语言模型呢?
模型的词表有 32000 个 token。一个回答假设 200 个 token 长。每个位置从 32000 个 token 里选一个,200 个位置,可能的回答总数是 32000²⁰⁰——比宇宙中的原子数大得多。J(θ) 的定义是对这所有可能的回答求加权和。你不可能把它们全部枚举出来。
SFT 不需要枚举所有回答,因为它的 loss 只看一条路径。RL 的目标天然定义在所有路径的加权平均上——这是本质区别。
实际训练怎么办
你没法穷举,但你可以采样。实际 PPO/GRPO 训练一个 batch 的流程:
- 取一个 prompt
- 让模型随机生成 8 个回答
- 给这 8 个回答打分
- 用这 8 个样本估计梯度方向,更新参数
关键问题:凭什么 8 个样本就能估计一个定义在天文数字种可能上的梯度?
这里有一个数学事实:如果一个求和长成 ∑yP(y)⋅f(y)\sum_y P(y) \cdot f(y)∑yP(y)⋅f(y) 的形式——也就是"概率 × 某个值"的加权和——你可以从 P 里随机抽样本,算 f 的平均值来近似它:
∑yP(y)⋅f(y)≈1N∑i=1Nf(yi),yi∼P\sum_y P(y) \cdot f(y) \approx \frac{1}{N}\sum_{i=1}^N f(y_i), \quad y_i \sim Py∑P(y)⋅f(y)≈N1i=1∑Nf(yi),yi∼P
为什么这行得通?因为从 P 里抽样时,高概率的 y 会被频繁抽到,低概率的 y 很少被抽到——抽样本身就自动完成了"按概率加权"这件事。所以你只需要对抽到的样本算 f 的简单平均,就能近似那个加权和。
J(θ) 本身就是这个形式:∑yπθ(y∣x)⋅r(x,y)\sum_y \pi_\theta(y|x) \cdot r(x,y)∑yπθ(y∣x)⋅r(x,y)。所以 J(θ) 的值可以用采样估计——让模型生成 8 个回答,算平均分,就是 J(θ) 的近似。这没问题。
但我们要的不是 J(θ) 的值,而是 J(θ) 的梯度。 梯度告诉你"θ 往哪调能让 J 增大"。梯度的原始形式是:
∇θJ=∑y∇θπθ(y∣x)⋅r(x,y)\nabla_\theta J = \sum_y \nabla_\theta \pi_\theta(y|x) \cdot r(x,y)∇θJ=y∑∇θπθ(y∣x)⋅r(x,y)
看这个求和:乘在 r(x,y) 前面的不是 π_θ(y|x)(概率),而是 ∇_θ π_θ(y|x)(概率对参数的导数)。这个导数有正有负——当你调 θ 时,有些回答的概率在涨,有些在跌。它不是概率分布,加起来不等于 1,你没法"从它里面采样"。
你手里有从 π_θ 采出来的 8 个样本(模型生成的 8 个回答),但梯度公式里站着的是 ∇π_θ,不是 π_θ。采样工具和公式对不上。
这就是为什么需要 log-derivative trick——它把 ∇π_θ 拆成 π_θ · (某个东西),让 π_θ 重新出现在公式里,这样你的 8 个样本就能派上用场了。
Log-derivative trick:把 ∇π 变成 π · (某个东西)
对 log f(x) 求导的链式法则:
ddxlogf(x)=f′(x)f(x)\frac{d}{dx} \log f(x) = \frac{f'(x)}{f(x)}dxdlogf(x)=f(x)f′(x)
两边乘以 f(x):
f′(x)=f(x)⋅ddxlogf(x)f'(x) = f(x) \cdot \frac{d}{dx} \log f(x)f′(x)=f(x)⋅dxdlogf(x)
翻译成我们的符号(f → π_θ,x → θ):
∇θπθ(y∣x)=πθ(y∣x)⋅∇θlogπθ(y∣x)\nabla_\theta \pi_\theta(y|x) = \pi_\theta(y|x) \cdot \nabla_\theta \log \pi_\theta(y|x)∇θπθ(y∣x)=πθ(y∣x)⋅∇θlogπθ(y∣x)
左边是"概率对参数的导数"(不是概率分布,没法采样)。右边拆成了"概率本身"乘以"log 概率对参数的导数"。关键是右边有 π_θ 这个因子——它是概率分布,可以采样。
代回梯度公式:
∇θJ=∑yπθ(y∣x)⋅[r(x,y)⋅∇θlogπθ(y∣x)]=Ey∼πθ[r(x,y)⋅∇θlogπθ(y∣x)]\nabla_\theta J = \sum_y \pi_\theta(y|x) \cdot \left[r(x,y) \cdot \nabla_\theta \log \pi_\theta(y|x)\right] = \mathbb{E}_{y \sim \pi_\theta}\left[r(x,y) \cdot \nabla_\theta \log \pi_\theta(y|x)\right]∇θJ=y∑πθ(y∣x)⋅[r(x,y)⋅∇θlogπθ(y∣x)]=Ey∼πθ[r(x,y)⋅∇θlogπθ(y∣x)]
左边的 Σ_y π_θ(y|x) · […] 就是"对 π_θ 求期望"的定义展开。右边用 E 符号简写。现在整个梯度是 π_θ 下的期望——而从 π_θ 采样就是让模型生成回答,所以可以用采样来估计。
现在可以用那 8 个采样回答来估计了:
∇J≈18∑i=18r(x,yi)⋅∇logπθ(yi∣x)\nabla J \approx \frac{1}{8}\sum_{i=1}^8 r(x, y_i) \cdot \nabla\log\pi_\theta(y_i|x)∇J≈81i=1∑8r(x,yi)⋅∇logπθ(yi∣x)
每个 yᵢ 已经有了(模型生成的),r(x, yᵢ) 已经有了(reward model 打的分),∇log π_θ(yᵢ|x) 通过对 yᵢ 这条路径做一次反向传播算出来——和 SFT 对一条数据算梯度的计算量一样。
整个 trick 的目的:让"模型自己生成回答"这个操作,能直接用来估计定义在无穷多回答上的目标函数的梯度。
这个梯度在说什么?
用人话翻译:
- ∇log π_θ(y|x) 是"让 y 的概率增大"的方向
- r(x,y) 是这个回答的得分
- 两者相乘:得分高的回答,沿着"增大其概率"的方向更新;得分低的回答,更新力度小(甚至反向)
实际中用优势函数 A(x,y) = r(x,y) - baseline 代替 r,减小方差:
∇J(θ)=Ey∼πθ[∑t=1TAt⋅∇logπθ(yt∣x,y<t)]\nabla J(\theta) = \mathbb{E}_{y \sim \pi_\theta}\left[\sum_{t=1}^{T} A_t \cdot \nabla \log \pi_\theta(y_t|x, y_{<t})\right]∇J(θ)=Ey∼πθ[t=1∑TAt⋅∇logπθ(yt∣x,y<t)]
A_t 是"优势"(Advantage):第 t 个 token 的得分减去平均水平(baseline)。A_t > 0 说明这个 token 比平均好,A_t < 0 说明比平均差。∇log π_θ(y_t|…) 是"让第 t 个 token 概率增大"的参数调整方向。两者相乘:好的 token 增大概率,差的 token 减小概率。
本质就是:试错,记住什么有效,多做有效的事。
为什么 RL 不容易遗忘
现在回到核心问题。看梯度公式:
∇J=Ey∼πθ[…]\nabla J = \mathbb{E}_{y \sim \pi_\theta}[\ldots]∇J=Ey∼πθ[…]
期望在 π_θ 上取。这意味着什么?
只有模型自己会生成的 token 序列,才对梯度有贡献。
如果模型从来不会生成某个序列(概率 ≈ 0),那个序列永远不会被采样到,对梯度贡献为零。模型不会被推向自己从未探索过的区域。
对比 SFT:外部数据可能包含模型从未见过的模式,强制模型去拟合它们,把概率从其他地方抢过来。
RL 的更新只是在模型已有分布的高概率区域做重新排序——好的上升,差的下降。整体分布形状不会剧变。
类比:
- SFT = 把你从北京空投到上海,让你适应上海(你会忘掉北京的路)
- RL = 你在北京生活,有人告诉你哪些路线更高效,你优化路线(你不会忘掉北京的地图)
PPO 的额外保险
实际训练中(PPO/GRPO),还会加一个显式 KL 惩罚:
JPPO(θ)=Ey∼πθ[r(x,y)]−β⋅DKL(πθ∥πref)J_{PPO}(\theta) = \mathbb{E}_{y \sim \pi_\theta}[r(x,y)] - \beta \cdot D_{KL}(\pi_\theta \| \pi_{ref})JPPO(θ)=Ey∼πθ[r(x,y)]−β⋅DKL(πθ∥πref)
第一项是"平均得分"(越大越好)。第二项是惩罚:D_KL(π_θ ‖ π_ref) 衡量当前模型 π_θ 和参考模型 π_ref(训练开始前的快照)之间的差距,β 控制惩罚力度。整体意思是:追求高分,但不许离出发点太远。
RL 在什么意义上是"反向 KL"?
RL 没有像 OPD 那样写出一个显式的 D_KL(q‖p) 来最小化。但它在两个层面上具有反向 KL 的性质:
第一层:采样方向。 RL 的梯度 E_{y~π_θ}[…] 从模型自己的分布采样。第三章已经说过,"谁在采样"决定了 KL 的方向。从 π_θ 采样 = 只有模型会生成的区域参与优化 = 反向 KL 的 mode-seeking 行为(精确但不求覆盖全部)。
第二层:KL 惩罚项本身。 PPO 目标里的 D_KL(π_θ ‖ π_ref) 就是字面意义上的反向 KL——第一个参数是当前模型(“说话的人”),第二个参数是参考模型(“编码本的主人”)。它惩罚的是"模型跑到了参考模型认为不太可能的地方",而不是"模型遗漏了参考模型覆盖的地方"。
所以 RL 和 OPD 都是反向 KL,只是表现形式不同:OPD 显式最小化 D_KL(π_s‖π_T);RL 通过 on-policy 采样 + 反向 KL 惩罚项,隐式地实现了同样的效果。
第六章:OPD——能不能两全其美?
RL 的一个遗憾
RL 不遗忘,很好。但它有个缺点:reward 信号是稀疏的。
模型生成一整段 200 个 token 的回答,最后只得到一个分数。就像写了一篇作文,老师只给了个总分 “7/10”,没告诉你哪句话写得好、哪句话有问题。模型得自己猜——是第 3 个 token 的功劳?还是第 150 个 token 搞砸了?
SFT 的信号是逐 token 的(每个位置都有正确答案),非常密集。但 SFT 会遗忘。
能不能有一种方法:信号像 SFT 一样密集(逐 token),但训练方式像 RL 一样 on-policy(不遗忘)?
OPD 的做法
OPD(On-Policy Distillation)的训练循环:
- 学生模型自己生成一个回答(和 RL 一样,on-policy)
- 把学生生成的这个回答喂给教师模型,教师对每个 token 位置给出自己的概率分布
- 学生在自己生成的轨迹上,向教师的判断靠拢
用一个具体例子看 OPD 到底在干什么
设定:词表只有 5 个 token:{答, 案, 是, 5, 。}。Prompt x = “2+3=”。
第 1 步:学生自己生成回答
学生模型做自回归采样,逐 token 生成:
| 位置 t | 输入(prompt + 已生成) | 学生的概率分布 π_s(·|x, y_{<t}) | 采样结果 |
|---|---|---|---|
| t=1 | “2+3=” | {答:0.6, 案:0.1, 是:0.2, 5:0.05, 。:0.05} | “答” |
| t=2 | “2+3= 答” | {答:0.05, 案:0.7, 是:0.15, 5:0.05, 。:0.05} | “案” |
| t=3 | “2+3= 答案” | {答:0.05, 案:0.05, 是:0.8, 5:0.05, 。:0.05} | “是” |
| t=4 | “2+3= 答案是” | {答:0.05, 案:0.05, 是:0.05, 5:0.7, 。:0.15} | “5” |
| t=5 | “2+3= 答案是5” | {答:0.05, 案:0.05, 是:0.05, 5:0.05, 。:0.8} | “。” |
学生生成的完整回答:y = “答案是5。”
第 2 步:把学生的轨迹喂给教师,教师给出每个位置的概率分布
关键操作:把学生生成的 token 序列作为前缀,让教师模型做 teacher-forcing 前向传播。也就是说,教师在每个位置 t 看到的上下文是 (x, y_{<t})——和学生生成时看到的完全相同的上下文——然后输出自己的概率分布。
| 位置 t | 输入(和学生一样) | 教师的概率分布 π_T(·|x, y_{<t}) |
|---|---|---|
| t=1 | “2+3=” | {答:0.3, 案:0.05, 是:0.05, 5:0.5, 。:0.1} |
| t=2 | “2+3= 答” | {答:0.05, 案:0.85, 是:0.05, 5:0.03, 。:0.02} |
| t=3 | “2+3= 答案” | {答:0.02, 案:0.02, 是:0.9, 5:0.03, 。:0.03} |
| t=4 | “2+3= 答案是” | {答:0.02, 案:0.02, 是:0.02, 5:0.9, 。:0.04} |
| t=5 | “2+3= 答案是5” | {答:0.02, 案:0.02, 是:0.02, 5:0.02, 。:0.92} |
注意 t=1 位置:教师认为最好的下一个 token 是 “5”(直接给答案,概率 0.5),而学生选了 “答”(概率 0.6)。教师给 “答” 的概率只有 0.3。
第 3 步:学生在每个位置上,把自己的分布向教师的分布靠拢
对每个位置 t,计算 KL 散度 D_KL(π_s(·|x,y_{<t}) ‖ π_T(·|x,y_{<t})),然后反向传播更新学生参数。
拿 t=1 举例:
DKL(πs∥πT)∣t=1=∑v∈词表πs(v)logπs(v)πT(v)D_{KL}(\pi_s \| \pi_T)\big|_{t=1} = \sum_{v \in \text{词表}} \pi_s(v) \log\frac{\pi_s(v)}{\pi_T(v)}DKL(πs∥πT) t=1=v∈词表∑πs(v)logπT(v)πs(v)
=0.6log0.60.3+0.1log0.10.05+0.2log0.20.05+0.05log0.050.5+0.05log0.050.1= 0.6 \log\frac{0.6}{0.3} + 0.1 \log\frac{0.1}{0.05} + 0.2 \log\frac{0.2}{0.05} + 0.05 \log\frac{0.05}{0.5} + 0.05 \log\frac{0.05}{0.1}=0.6log0.30.6+0.1log0.050.1+0.2log0.050.2+0.05log0.50.05+0.05log0.10.05
=0.6×0.693+0.1×0.693+0.2×1.386+0.05×(−2.303)+0.05×(−0.693)= 0.6 \times 0.693 + 0.1 \times 0.693 + 0.2 \times 1.386 + 0.05 \times (-2.303) + 0.05 \times (-0.693)=0.6×0.693+0.1×0.693+0.2×1.386+0.05×(−2.303)+0.05×(−0.693)
=0.416+0.069+0.277+(−0.115)+(−0.035)=0.612= 0.416 + 0.069 + 0.277 + (-0.115) + (-0.035) = 0.612=0.416+0.069+0.277+(−0.115)+(−0.035)=0.612
这个 loss 告诉学生:在 t=1 位置,你给 “答” 的概率相对教师偏高(0.6 vs 0.3),给 “5” 的概率相对教师偏低(0.05 vs 0.5)。梯度会推动学生降低 “答” 的概率、提高 “5” 的概率。
总 loss = 所有位置的 KL 之和:
LOPD=∑t=15DKL(πs(⋅∣x,y<t)∥πT(⋅∣x,y<t))\mathcal{L}_{OPD} = \sum_{t=1}^{5} D_{KL}\left(\pi_s(\cdot|x, y_{<t}) \| \pi_T(\cdot|x, y_{<t})\right)LOPD=t=1∑5DKL(πs(⋅∣x,y<t)∥πT(⋅∣x,y<t))
为什么这是"在自己的轨迹上学习"?
关键在于:每个位置的上下文 y_{<t} 是学生自己生成的 token。教师不是在自己的回答上教学生,而是站在学生走过的路上,告诉学生"在你走到的这个位置,我觉得下一步应该怎么走"。
如果学生从来不会走到某条路径(概率 ≈ 0),那条路径永远不会被采样到,教师永远不会在那条路径上给意见,学生在那条路径上的分布不会被改变。这就是 on-policy 保护旧知识的机制。
注意和传统蒸馏的区别:传统蒸馏是教师生成回答,学生去背(off-policy = SFT 的翻版 = 会遗忘)。OPD 是学生自己写作文,教师在旁边逐句点评。
OPD 最小化什么?
学生分布 π_s(s = student,学生模型的输出概率),教师分布 π_T(T = Teacher,教师模型的输出概率)。OPD 最小化:
DKL(πs∥πT)=Ey∼πs[logπs(y∣x)πT(y∣x)]D_{KL}(\pi_s \| \pi_T) = \mathbb{E}_{y \sim \pi_s}\left[\log \frac{\pi_s(y|x)}{\pi_T(y|x)}\right]DKL(πs∥πT)=Ey∼πs[logπT(y∣x)πs(y∣x)]
这就是第二章的 KL 散度,只是把 p 换成了 π_s,q 换成了 π_T。E_{y ~ π_s} 表示"y 是学生自己生成的"(从学生的分布里采样)。log(π_s/π_T) 衡量学生和教师在这个 y 上的分歧。
两个关键点:
- 期望在 π_s 上取(学生自己的分布)→ on-policy → 不遗忘
- KL 方向是 D_KL(学生‖教师),即反向 KL → mode-seeking → 学生不会被强制覆盖教师的所有模式
对比传统蒸馏最小化的是 D_KL(π_T ‖ π_s)——期望在教师上取,前向 KL,和 SFT 一样的问题。
OPD 其实就是 RL
把 KL 散度展开(利用 log(a/b) = log a - log b):
DKL(πs∥πT)=Ey∼πs[logπs(y∣x)−logπT(y∣x)]D_{KL}(\pi_s \| \pi_T) = \mathbb{E}_{y \sim \pi_s}\left[\log \pi_s(y|x) - \log \pi_T(y|x)\right]DKL(πs∥πT)=Ey∼πs[logπs(y∣x)−logπT(y∣x)]
最小化这个值,等价于最小化期望里的东西。给整个式子加负号,最小化变最大化:
最小化 E[logπs−logπT] ⟺ 最大化 E[−logπs+logπT]\text{最小化 } \mathbb{E}[\log \pi_s - \log \pi_T] \iff \text{最大化 } \mathbb{E}[-\log \pi_s + \log \pi_T]最小化 E[logπs−logπT]⟺最大化 E[−logπs+logπT]
整理顺序:
最大化 Ey∼πs[logπT(y∣x)−logπs(y∣x)]\text{最大化 } \mathbb{E}_{y \sim \pi_s}\left[\log \pi_T(y|x) - \log \pi_s(y|x)\right]最大化 Ey∼πs[logπT(y∣x)−logπs(y∣x)]
把这两项分开看:
| 项 | 含义 |
|---|---|
| log π_T(y|x) | 教师觉得学生生成的这个 token 有多好——逐 token 的 dense reward |
| -log π_s(y|x) | 学生自己的负对数概率——熵正则化(鼓励探索,不要太确定) |
对比标准 RL 的目标:
Ey∼πθ[r(x,y)−βlogπθ(y∣x)]\mathbb{E}_{y \sim \pi_\theta}\left[r(x,y) - \beta \log \pi_\theta(y|x)\right]Ey∼πθ[r(x,y)−βlogπθ(y∣x)]
r(x,y) 是 reward(得分),β 是控制正则化强度的系数,-log π_θ 是熵项(鼓励模型不要太确定,保持探索)。对比 OPD:把 r 换成 log π_T(教师的评分),β 自动等于 1。
结构完全一样。 OPD 就是一种特殊的 RL:
- reward = 教师的 log 概率(而且是逐 token 的,比传统 RL 的稀疏 reward 密集得多)
- 熵正则自动包含
为什么 OPD 不遗忘
和 RL 完全相同的原因:期望在学生自己的分布上取。
- 学生只在自己会到达的状态上接受教师指导
- 不会被强制拉到自己从未探索过的区域
- 教师的 logits 只是在学生已有的分布上做微调,不是替换
类比:
- 传统蒸馏(off-policy)= 教师写了一篇范文,学生逐字抄。学生被迫走教师的路,自己原来的路荒废了。
- OPD(on-policy)= 学生自己写作文,教师在旁边看,对每个句子说"这里可以更好"。学生在自己的写作风格基础上改进。
一个反直觉的结论
教师模型本身是否完美,不那么重要。
实验发现:即使用一个 SFT 得到的(泛化很差的)教师模型做 OPD,学生的表现也比直接 SFT 好。
为什么?因为关键不在于信号的质量,而在于训练分布是谁的。只要学生在自己的分布上学习(on-policy),就能避免灾难性遗忘。教师的作用是提供方向,不是提供轨迹。
总结:一个问题决定一切
| SFT | RL | OPD | |
|---|---|---|---|
| 训练样本谁生成的? | 外部数据 | 模型自己 | 模型自己 |
| 学习信号 | 标准答案(逐token) | 打分(稀疏) | 教师logits(逐token密集) |
| KL 方向 | 前向 D_KL(p_data‖π_θ) | 隐式反向 | 反向 D_KL(π_s‖π_T) |
| 对模型分布的影响 | 强制拉向外部分布 | 在自身分布附近微调 | 在自身分布上接受指导 |
| 遗忘风险 | 高 | 低 | 低 |
| 适合什么 | 冷启动、格式对齐 | 能力提升、偏好对齐 | 知识蒸馏、能力迁移 |
一句话总结:决定模型会不会遗忘的,不是谁给的信号,不是信号有多密集,而是一个简单的问题——
模型是在自己的分布上学习,还是在别人的分布上学习?
On-policy = 在自己的地盘上改进 = 不遗忘。
Off-policy = 被拉到别人的地盘 = 遗忘。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)