Mr. DETR++:混合专家为检测Transformer提供指导性多路线培训(CVPR 2025)
摘要
现有方法通过引入辅助的一对多分配来增强检测Transformer的训练。在这项工作中,我们将模型视为一个多任务框架,同时执行一对一和一对多预测。我们在这两个训练目标上研究了Transformer解码器中每个组件的作用,包括自注意、交叉注意和前馈网络。我们的实证结果表明,即使在共享其他组件的情况下,解码器中的任何独立组件都可以有效地同时学习两个目标。这一发现促使我们提出了一种多路径训练机制,其特征是用于一对一预测的主路径和用于一对多预测的两个辅助训练路径。我们提出了一种新颖的指导性自注意机制,集成到第一辅助路线中,动态灵活地指导对象查询进行一对多预测。对于第 二条辅助路由,我们引入了一个路由感知的混合专家(MoE)来促进知 识共享,同时减少路由之间的潜在冲突。此外,我们将MoE应用于编 码器中的低尺度特征,优化效率和有效性之间的平衡。辅助路线在推 理过程中被丢弃。我们在各种目标检测基线上进行了广泛的实验,实 现了如图1所示的一致改进。我们的方法非常灵活,可以很容易地适 应其他任务。为了证明其通用性,我们对实例分割和全视分割进行了 实验,进一步验证了其有效性。
我们做出了以下主要贡献:
·我们经验性地证明,在多任务框架内,解码器中的任何独立组件都可以同时有效地学习一对一和一对多预测目标,即使其他组件是共享的。我们提出了一种由新的指导性自注意机制增强的多路由训练机制,该机制动态地指导对象查询以进行一对多预测;
·我们引入了路由感知专家混合(莫伊)框架以使得能够在Mr.DETR中的两个独立前馈网络(FFN)之间共享知识。通过进一步在Transformer编码器中结合尺度感知莫伊,我们开发了Mr. DETR++。
·我们通过探索实验研究了我们提出的多路径训练框架的内在机制。我们的研究结果表明,辅助训练路径通过选择性地破坏一对一所需的信息来减轻与主路径的冲突。
·我们通过在多个基准测试上进行广泛的实验来验证我们的方法的有效性,包括COCO 2017,Objects365和NuImages,在各种基线模型上实现了一致的改进。此外,我们将我们的方法扩展到不同的任务,例如实例分割和全景分割。
1、数据集和代码
1.1 代码地址::https://visual-ai.github.io/ mrdetr/
1.2 数据集
我们使用三个流行的数据集对对象检测、实例分割和全景分割进行了广泛的实验(见附录A):COCO 2017 [90],NuScenes [23]和Objects365 [22]。我们对COCO 2017验证集进行评估,提供标准化指标的结果,即平均精度(mAP,AP50,AP75)。
2、要解决的问题
2.1 DETR训练存在的问题
为了加速类似DETR的目标检测器的训练,一些作品提出了辅助训练方法,通过引入辅助一对多分配或多组一个来提高预测定位的质量。然而,以前的工作检查的功能,每个组件的Transformer解码器的两个训练目标,只有在单任务设置。任务框架仍需严格执行。
2.2 使用Transformers进行目标检测
与传统的基于CNN的对象检测器不同,DETR 实现了端到端的对象检测,无需任何后处理,利用基于查询的Transformer和集合预测机制。为了提高性能并加速DETR 的训练,许多后续工作介绍先进的注意力架构。在我们的工作中,我们提出了一种指导性的多路线训练机制,可以增强各种DETR类模型的训练。
2.3 训练检测Transformer
许多典型的目标检测器设计了各种策略来匹配每个目标与多个预测,从而提高检测器学习鲁棒表示的能力。相比之下,DETR类检测器通过一对一匹配实现端到端的目标检测,其中每个目标被分配给单个预测,同时考虑定位和分类成本。尽管如此,具有一对一匹配的DETR类检测器经常遇到缓慢收敛问题。为了加速香草DETR的训练,一些研究结合了辅助训练方法。与以前的技术不同,我们讨论了多任务框架中Transformer解码器中每个组件的角色,在此基础上,提出了一种指导性的多路径训练机制,以便于辅助训练的使用。
2.4 混合专家
混合专家(莫伊)旨在动态地联合收割机组合多个专家的知识,同时在推理过程中保持低计算成本。这种技术已广泛应用于各个领域,以扩大模型,例如自然语言处理和计算机视觉。在多任务学习的背景下,M3 ViT和Mod-Squad 引入了基于MoE的模型来有效地处理多个任务。AdaMVMoE 通过使用部分共享的专家来增强任务特异性,同时保持效率。此外,建议使用LoRA 构建专家来解决多个密集预测任务。
2.5 研究的主要问题
我们经验性地研究了该框架中Transformer解码器中每个组件的角色,并发现:
(1)当所有组件在两个任务之间共享时,结合一对多分配显著降低了主要一对一预测的性能。我们预计它是由两个任务之间的干扰引起的。例如,在一对多分配中,预测框可以被分配为正预测,而在一对一分配中被分配为负预测;
(2)解码器中的任何独立分量显著有益于主要一对一预测路径,即使在共享其他组件时。该观察结果表明,任何独立组件都能够有效地掌握一对一和一对多训练目标,从而解决这两个任务之间的冲突。这是预期的,因为共享组件可以提取两个任务的共同线索,而独立组件进一步区分不同的任务;
(3)具有两个独立组件的辅助训练路线不会优于只有一个独立组件的路线;以及(iv)将辅助路线与独立的自注意和独立的FFN相组合实现了联合收割机不同辅助训练路线的变体中的最高性能。
3、提出的创新点

图三:具有辅助一对多训练的Transformer解码器的不同配置。“SA”:自注意。“CA”:交叉注意。“FFN”:前馈网络。“o2o”:一对一预测。“o2m”:一对多预测。
3.1 初步
DETR体系结构。类似DETR的检测器通常由图像主干、Transformer编码器和解码器组成。Transformer编码器通过多尺度图像标记之间的自关注来提取特征。一组对象查询Q = {q 0,q1,...,qn}被馈送到Transformer解码器中,其中分类和盒回归头导出预测分类S = {s 0,s1,...,sn}和边界框B = {b 0,b1,.,bn}。解码器由L个堆叠的Transformer层组成,每个层包含自注意、交叉注意和前馈网络(FFN)。自注意应用于对象查询之间,交叉注意促进对象查询和图像特征之间的交互,FFN提取对象查询中的特征。
一对一训练目标。利用一对一训练目标[1],DETR实现端到端检测,而不需要非最大值抑制(NMS)。具体来说,令B = {b 0,b 1,...,b bt}和S = {s 0,s 1,...,s t}表示地面实况框和对应的类。所有可能的预测和地面实况框之间的匹配成本真值对是通过同时考虑分类成本和盒子成本而得到的。最佳匹配是使用二分匹配[1],[53]确定的,表示为
![]()
其中Lcls和Lbox分别表示分类和边界框损失。
一对多训练目标。传统的对象检测器通常使用一对多分配策略,根据特定标准将每个地面真值框分配给多个预测,然后通过NMS消除重复的预测。在我们的工作中,我们应用了一个简单的一对多分配策略[17],如[13],[14],具体地,预测(si,bi)和地面实况(s t,B t)之间的匹配得分Mij被定义为:
![]()
其中IoU计算预测框bi和地面实况框B j之间的交并。给定肯定候选的最大数量K和IoU阈值τ,可以确定肯定预测。首先,选择具有最高匹配分数M的多达K个预测作为肯定预测。然后,对于每个地面实况框,过滤掉具有低于τ的IoU的预测。如等式(1)中计算定位和分类损失。
3.2 多路径训练
我们的目标是引入一对多分配作为额外的训练策略来增强检测转换器。首先,我们将具有辅助一对多预测的检测器视为多任务框架,它同时实现一对一和一对多预测。
我们的方法包括三个训练路线,如图4所示。我们在三个路线之间共享对象查询,分类和回归头。路线2是一对一预测的主要路线,与基线模型相同。路线1和路线3是用于一对多预测的辅助训练路线,在推理过程中被丢弃。因此,在我们的方法中的辅助训练路线不影响模型结构或推理时间。
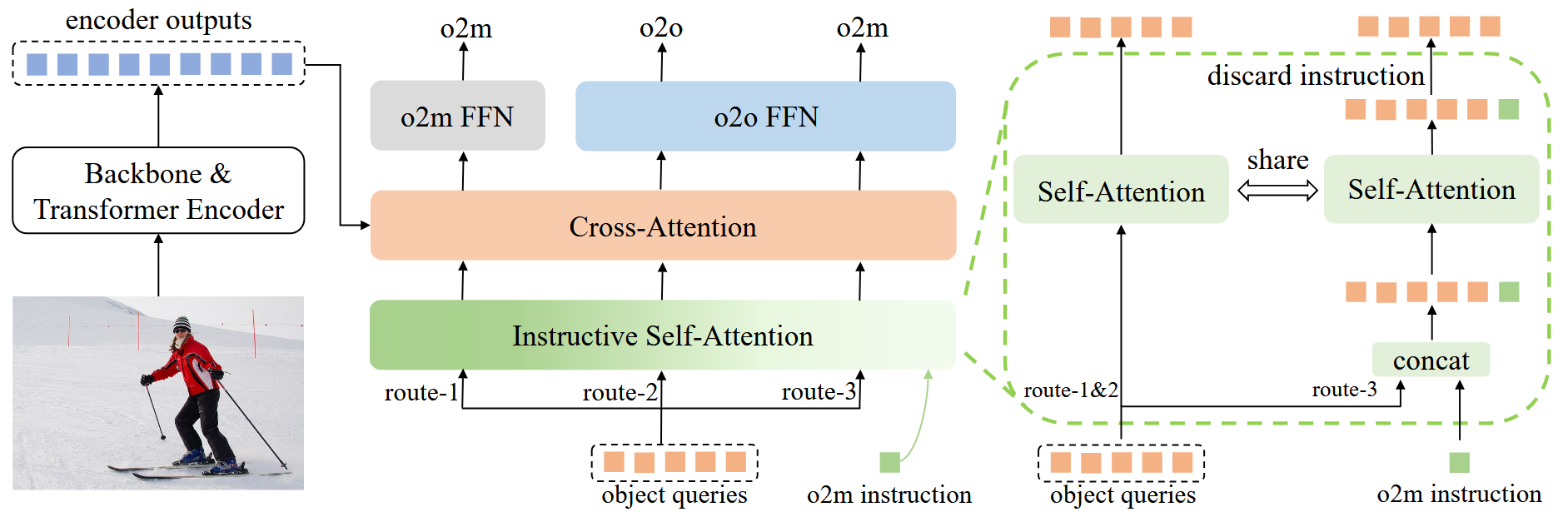
图四:我们在DETR先生中提出的多路线训练方法。它包括三条训练路线:Route-1、Route-2和Route-3。这三条路由共享相同的对象查询和检测头,用于分类和回归。Route-2作为一对一预测的主要路由,与基线模型相同。Route-1共享自我注意力和交叉注意力,但使用独立的前馈网络(o2 m FFN)进行一对多预测。3、与主路由共享所有组件,引入了一种新的指导性自注意,通过在对象查询中添加可学习的指令令牌来指导它们和后续网络进行一对多预测,在推理过程中,丢弃辅助路由Route-1和Route-3。
一对一预测的主路由。图4中路由2的架构和训练目标与基线模型相同。具体地,对于路线2,给定对象查询Q = {q 0,q1,...,qn-1},查询输出定义为:
![]()
其中SA、CA和FFNo 20分别表示自注意、交叉注意和FFN。Route-2的查询输出由等式(1)中的一对一分配来监督。在推理期间,Route-2被保留以实现一对一预测,而不需要任何额外的成本。
具有独立FFN的辅助路由。如图4所示,我们将一个辅助训练路由(称为Route-1)集成到我们的方法中,该路由具有单独的FFN。具体而言,我们在Route-1中直接使用一个独立的FFN(FFNo 2 m),与主路由共享所有自注意和交叉注意分量。由于FFN的简单架构和有效的参数利用,我们保持它的独立性而不作进一步的修改。Route-1的查询输出Q_1可以写为:
![]()
此输出由一对多分配进行监督。
具有指导性自我注意力的辅助路线。在第一节中,我们讨论了在图3(e)所示的路线3中引入独立自我注意力的动机,该路线是为一对多预测而设计的。为了进一步减少可训练参数并增强与主路线的参数共享,我们提出了一种创新的指令机制,如图4所示。该机制引导共享对象查询,以实现一对一的查询。路线-3的查询输出Q_3被写为:
![]()
其中,InstracutSA表示我们提出的指导性自注意,它与其他两条路径中的自注意共享参数。输出Q_3由一对多分配监督。接下来,我们将介绍我们的指导性自注意InstracutSA设计的细节。
3.3 指导的自我注意力
在本节中,我们检查指导性自注意的不同实现,其旨在通知对象查询以实现一对多预测,与主路由共享自注意参数。如图5(a)所示,涉及使用单独的查询集作为输入以促进一对多预测。
为了提高跨不同路由的对象查询的兼容性,我们引入了可学习的令牌作为指令,如图5(B)所示,这些预测目标通过加法将指令令牌合并到共享对象查询中。这种方法需要与查询计数相等的固定数量的指令令牌。
与加法方法不同,我们的方法通过级联来适配指令令牌,从而提供更大的灵活性。如图5(c)所示,这种灵活性不仅扩展到指令令牌的数量,而且还允许这些学习的令牌通过自注意动态地向对象查询发送信息。自注意是对组合序列SQIN执行的,但是在自-自-注意,因为它们不打算用于对象定位。
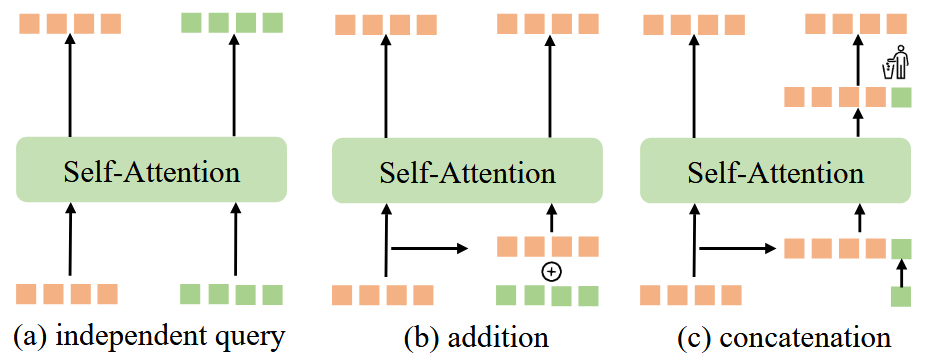
图5:指导性自我关注的各种实现。
具体来说,我们构建m个可学习令牌= {q
,q
,...,q
},称为指令令牌。最初,这些指令令牌通过级联被附加到自注意力的输入序列,形成输入查询的复合集合
= {q
,q
,...,q
,q
,q1,...,qn-1},导致长度m + n。随后,在这些组合查询上执行自注意。由于附加的指令令牌不用于对象定位,因此它们的输出在自注意后被丢弃,仅用于向对象查询传达信息。路由3的输出Q_n 3被写为:
![]()
其中函数R消除了自注意后的指令令牌输出。值得注意的是,Route3的所有组件,包括自注意,交叉注意和FFN,都与主路由共享参数。指令令牌有效地引导对象查询和后续模块实现一对一预测。辅助路由和主路由之间的共享参数有利于主路由的一对一预测。
3.4 从Mr.DETR到M.DETR++
如图3(g)所示,为了在Mr. DETR中使用的两个独立FFN之间实现知识共享,我们提出了一种路由感知的MoE来代替FFN。我们进一步将MoE架构扩展到Transformer编码器以增强特征表示。为了减轻计算开销,我们引入了一种应用于低尺度特征的尺度感知的MoE。此外,我们引入了一个本地化感知的分数来改进分类校准。这个扩展的方法被称为Mr. DETR++。
解码器中的路由感知专家混合。在Mr. DETR中使用的两个独立的FFN可以被认为是为单独的任务定制的不同的专家,代表MoE范例的特殊情况。因此,如图6所示,我们提出了路由感知的MoE来代替FFN,从而实现跨路由的知识共享和特定于任务的专业化。具体地,三条路由共享一组t个专家E = {e0,e,....}为了防止路由之间的冲突,路由2和路由3共享选通函数G(·),而路由1使用独立的选通函数G ′(·)。
形式上,在Mr. DETR++中路由-1的查询输出Q 1表示为:
![]()
其中,SA表示自注意,CA表示交叉注意,G'是选通函数,并且E表示专家计算。类似地,用于路线2中的一对一预测的查询输出Q = 2由下式给出:
![]()
对于配备有指导性自我注意的路线3,查询输出Q_n 3是:
![]()
这种路由感知的MoE设计促进了知识共享,同时减少了潜在的冲突。
对于MoE块,我们使用topk专家的稀疏激活。门控函数G(·)(或对于Route-1为G '(·))计算每个专家的分数,并且仅具有最高分数的top-k专家被激活用于处理查询。对于给定的查询Q和门控函数G(·),门控输出是分数c = G(Q)的向量,其中ci表示专家ei的得分。前k个专家索引被选择为:
![]()
其中TopK(s,k)返回具有最高分数的k个专家的索引。然后,查询Q的MoE块的输出被计算为所选专家的输出的加权和:
![]()
其中ei(Q)是输入查询Q的专家ei的输出,并且ci是对应的门控分数。
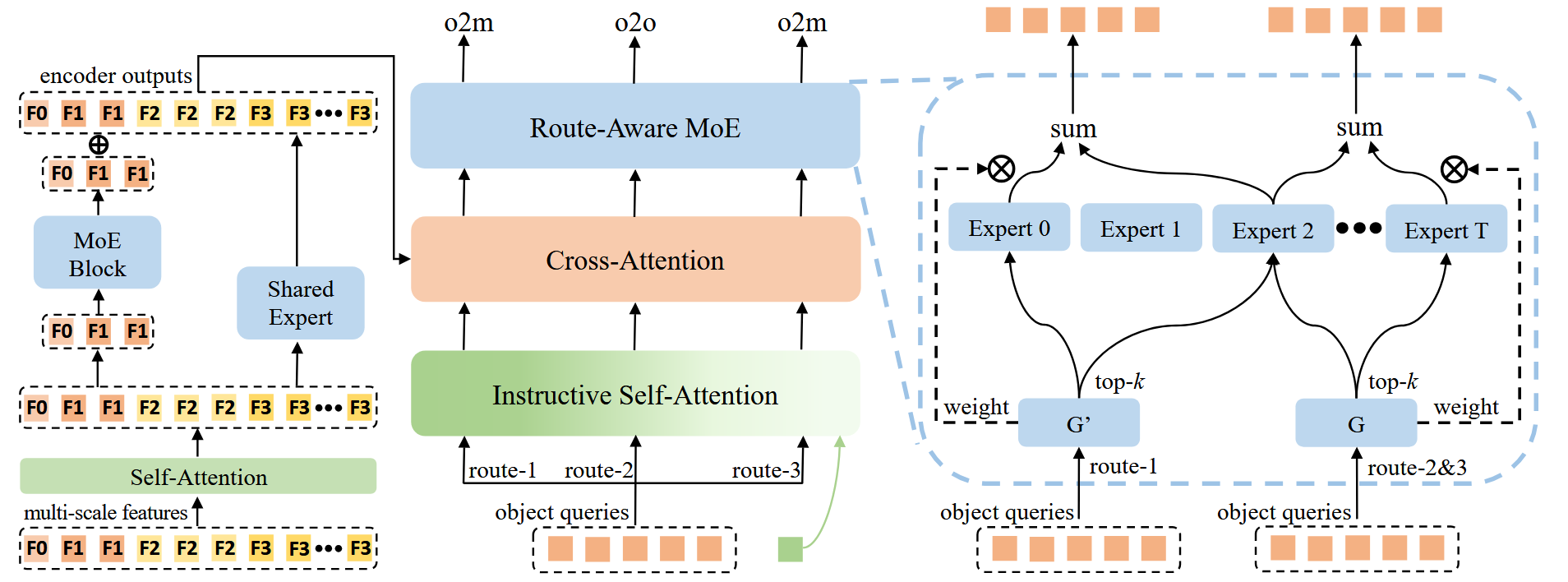
图六:所提出的Mr. DETR++架构的图示。我们的方法用路由感知的MoE取代了Mr. DETR中的两个独立的FFN,从而实现了跨路由的知识共享和特定于任务的专业化。采用了两个不同的门控函数G和G ':G控制路线1,而G'在路由2和路由3之间共享。MoE块进一步集成到变换器编码器中。为了减少计算成本,MoE块应用于低尺度特征,所有令牌共享单个专家。
编码器中的尺度感知混合专家。我们进一步将MoE框架扩展到变换器编码器以增强特征表示。通常,编码器处理来自多个尺度的平坦化特征令牌序列,F = {f0,f1,.,fd-1},其中fi表示尺度i处的图像令牌。将MoE直接应用于该长序列将显著增加计算成本。为此,我们提出了一个尺度感知的MoE,它将共享专家应用于所有令牌,并将专用MoE块应用于低尺度特征。
假设令牌序列长度随着尺度索引而增加,类似于等式(11),我们将莫伊应用于前η个尺度(低尺度特征),并且将共享FFN应用于F中的所有令牌。通过组合前η个尺度的输出并保留较高尺度的FFN输出来计算最终特征:
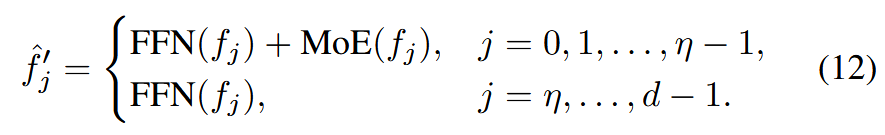
假设令牌序列长度随着尺度索引而增加,类似于等式(11),我们将莫伊应用于前η个尺度(低尺度特征),并且将共享FFN应用于F中的所有令牌。通过组合前η个尺度的输出并保留较高尺度的FFN输出来计算最终特征。
本地化感知分数校准。仅依赖分类分数可能会导致低质量边界框的排名高于高质量边界框,从而导致性能次优。该问题已被广泛研究。与Cascade-DETR [28]不同,它在分类分数旁边引入了一个与类别无关的IoU分数分支,受VarifocalNet [18]的启发,我们提出了一个类感知的IoU得分来校准分类得分。在训练过程中,与Stable-DINO [19]和Align-DETR [12]相比,标签分配过程排除了IoU得分,简化预测目标和标签分配。我们使用VFL Loss [18]来学习classaware IoU得分,其中目标得分根据经验通过starget = iou0.75提升。在推理时,我们通过结合分类和IoU得分来计算校准得分:
![]()
其中scls ∈ [0,1]是分类得分,spred ∈ [0,1]是预测的IoU得分,φ是为了平衡分类和定位置信度的贡献。这种校准易于使用,并且不影响原始模型的训练过程。
4、结论与不足
将一对多辅助训练模型视为多任务框架,我们研究了Transformer解码器中每个组件在两个训练目标中的作用。我们的经验发现表明,解码器中的任何独立组件都可以有效地学习一对一和一对多训练目标,即使其他组件共享。基于这一认识,我们提出了一种多路径训练机制,具有一个主路径和两个辅助训练路径。第一个辅助路径结合了我们提出的指导性自我注意力,它动态灵活地指导对象查询进行一对多预测。第二个辅助路径通过我们提出的路径感知混合专家来增强,在减少路径之间潜在冲突的同时实现知识共享。此外,Transformer编码器进一步增强了我们提出的尺度感知莫伊,应用于低尺度特征以降低计算成本。值得注意的是,在推理过程中丢弃了辅助训练路径。在多个任务上的广泛实验,包括对象检测,实例分割和全景分割,验证我们方法的有效性和通用性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)