双向链表(带头循环)学习笔记
双向链表(带头循环)学习笔记
这篇文章是我学习双向链表的过程记录,代码已经跑通,注释写得很细,希望能帮助同样在学数据结构的你。
一、什么是双向带头循环链表?
| 特性 | 含义 |
|---|---|
| 双向 | 每个节点有两个指针:next 指向后一个节点,prev 指向前一个节点。 |
| 带头 | 有一个特殊的节点叫哨兵位(head),它不存有效数据,只负责“站岗”。空链表时,它的 next 和 prev 都指向自己。 |
| 循环 | 最后一个节点的 next 指向哨兵位,哨兵位的 prev 指向最后一个节点,形成一个环。 |
一张图胜过千言万语: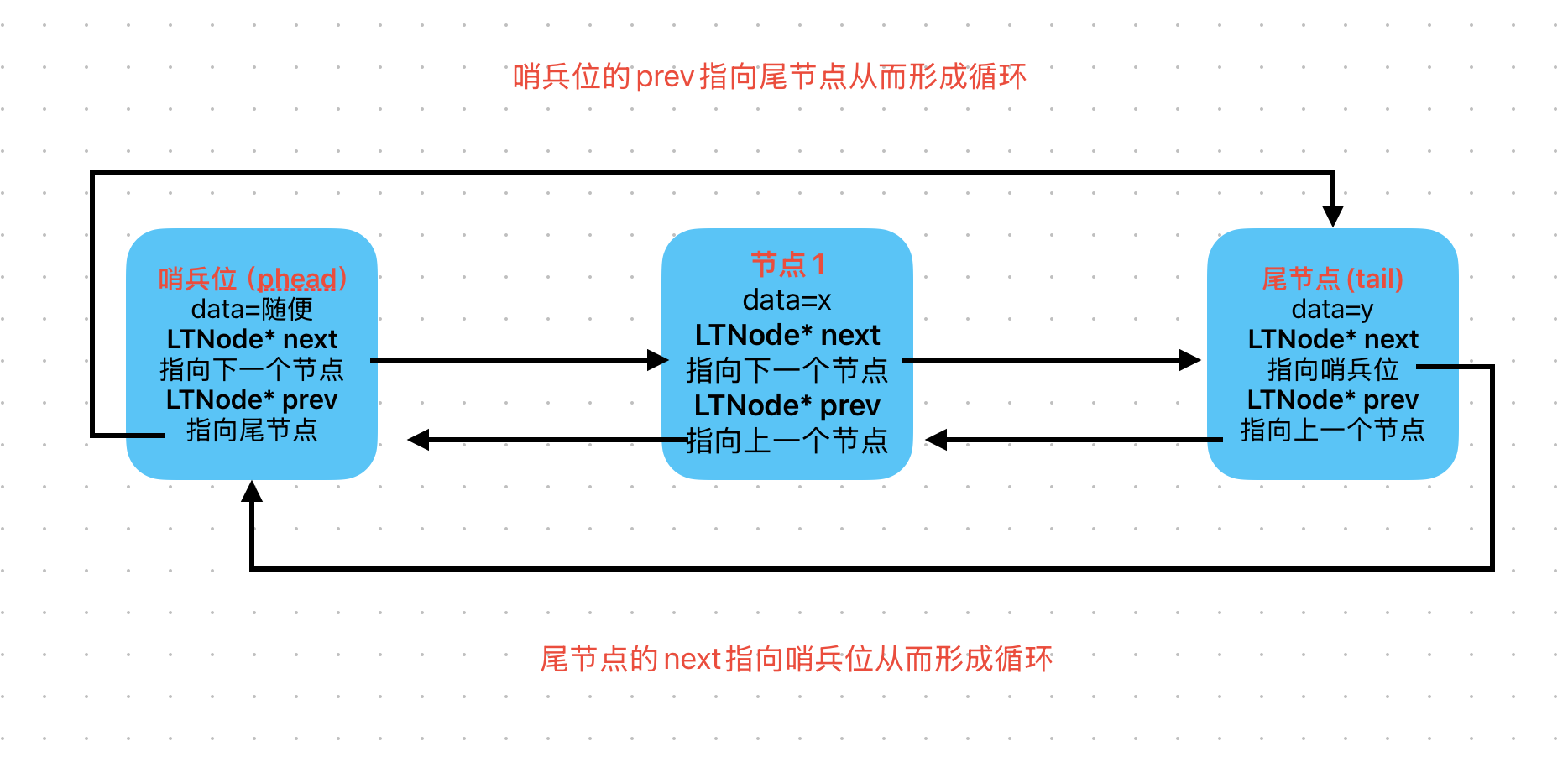
哨兵位的好处:
- 空链表和非空链表的操作完全统一,不用再单独判断
if (head == NULL) - 插入删除永远不需要修改“头指针”的值(因为哨兵位固定存在),所以函数参数只需要一级指针
LTNode* phead
二、节点结构定义
来自 DoublyLinkedList.h:
//链表存储数据的类型(可修改)
typedef int LTDataType;
//链表的节点结构体
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
三、核心操作及代码实现(关键部分)
1. 初始化(创建哨兵位)
来自 DoublyLinkedList.c:
/**
* @brief 创建并初始化双向链表的哨兵位
* @param 无
* @return 指向哨兵位的指针
* @note 如果内存分配失败则退出程序
*/
LTNode* LTInit()
{
LTNode* phead = (LTNode*)malloc(sizeof(LTNode));
if(phead == NULL)
{
perror("malloc fail");
exit(-1);
//由于perror不会退出程序所以需要使用exit退出程序,防止程序继续进行出现错误
}
phead->data = 0;
phead->next = phead;
phead->prev = phead;
return phead;
}
要点:空链表时,哨兵位的 next 和 prev 都指向自己。
2. 尾插(O(1))
/**
* @brief 从尾部插入新节点
* @param x (新节点的数据)
* @return 无
* @note 传入的指针不能为空
*/
void LTPushBack(LTNode* phead,LTDataType x)
{
assert(phead != NULL);
LTNode* newnode = BuyNewNode(x);
LTNode* tail = phead->prev;// 尾节点 = 哨兵位的前一个
// 链接关系: tail <-> newnode <-> phead
newnode->next = phead;
newnode->prev = tail;
tail->next = newnode;
phead->prev = newnode;
}
对比单链表:单链表尾插需要遍历到末尾,O(n);双向链表因为有 phead->prev,一步就拿到尾,O(1)。
3. 头插
/**
* @brief 从头部插入新节点
* @param x (新节点的数据)
* @return 无
* @note 传入的指针不能为空
*/
void LTPushFront(LTNode* phead,LTDataType x)
{
assert(phead != NULL);
LTNode* newnode = BuyNewNode(x);
LTNode* first = phead->next;
// phead <-> newnode <-> first
newnode->next = first;
newnode->prev = phead;
first->prev = newnode;
phead->next = newnode;
}
4. 在 pos 节点之后插入
/**
* @brief 在 pos 节点之后插入新节点
* @param pos (pos节点的指针)
* @param x (新节点的数据)
* @return 无
* @note 传入的指针不能为空
*/
void LTInsert(LTNode* pos,LTDataType x)
{
assert(pos != NULL);
LTNode* newnode = BuyNewNode(x);
LTNode* after = pos->next;
//pos <-> newnode <-> after
newnode->next = after;
newnode->prev = pos;
after->prev = newnode;
pos->next = newnode;
}
5. 删除节点
/**
* @brief 删除 pos 节点
* @param pos (pos节点指针)
* @return 无
* @note 传入的指针不能为空
*/
void LTErase(LTNode* pos)
{
assert(pos != NULL);
// 注意:一般不会删除哨兵位,调用者需保证
LTNode* prevNode = pos->prev;
LTNode* nextNode = pos->next;
prevNode->next = nextNode;
nextNode->prev = prevNode;
free(pos);
}
注意:删除后不需要在函数内把 pos 置空(因为 pos 是局部拷贝),调用者如果需要,自己 pos = NULL。
6. 打印链表
/**
* @brief 打印整个链表
* @param phead (哨兵位指针)
* @return 无
* @note 传入的指针不能为空
*/
void LTPrint(LTNode* phead)
{
assert(phead != NULL);
printf("哨兵位 <=> ");
LTNode* cur = phead->next;
while (cur != phead) {
printf("%d <=> ", cur->data);
cur = cur->next;
}
printf("哨兵位\n");
}
循环条件:cur != phead,走到哨兵位就停止,避免了单链表中 cur != NULL 的判断。
四、测试程序及运行结果
test.c 中我按照以下步骤测试了所有功能(完整代码见仓库):
- 初始化空链表并打印
- 尾插 10,20,30
- 头插 5,1
- 查找 10,在其后插入 15
- 查找并删除 15
- 头删一次 + 尾删一次
- 循环删除直到空链表
- 销毁链表
运行输出(关键部分):
===== 双向链表测试开始 =====
1. 初始化空链表: 哨兵位 <=> 哨兵位
2. 链表是否为空? 是
3. 尾插 10, 20, 30
哨兵位 <=> 10 <=> 20 <=> 30 <=> 哨兵位
4. 头插 5, 1
哨兵位 <=> 1 <=> 5 <=> 10 <=> 20 <=> 30 <=> 哨兵位
5. 查找 10,在其后插入 15
哨兵位 <=> 1 <=> 5 <=> 10 <=> 15 <=> 20 <=> 30 <=> 哨兵位
6. 查找 15 并删除
哨兵位 <=> 1 <=> 5 <=> 10 <=> 20 <=> 30 <=> 哨兵位
7. 头删一次,尾删一次
哨兵位 <=> 5 <=> 10 <=> 20 <=> 哨兵位
...
11. 销毁链表
链表已销毁
所有操作均符合预期,内存泄漏检测(使用 AddressSanitizer)通过。
五、双向链表 vs 单链表 vs 顺序表
| 操作 | 顺序表 | 单链表 | 双向带头循环链表 |
|---|---|---|---|
| 尾插 | O(1)*(需扩容) | O(n) | O(1) |
| 尾删 | O(1) | O(n) | O(1) |
| 头插 | O(n)(搬移元素) | O(1) | O(1) |
| 任意位置插入 | O(n) | O(n)(需找前驱) | O(1)(已知 pos) |
| 随机访问 | O(1) | O(n) | O(n) |
| 内存占用 | 连续空间,可能浪费 | 每节点一个指针 | 每节点两个指针 |
结论:双向链表在频繁插入删除的场景下性能优秀,但牺牲了随机访问能力和一点内存。
六、我踩过的坑 & 经验总结
-
哨兵位不是头指针
单链表我们经常用二级指针操作头指针,但双向链表有哨兵位后,所有函数传一级指针phead即可,因为哨兵位的地址永远不会改变。 -
指针修改顺序很重要
插入或删除时,先连接好新节点的前后指针,再修改前后节点的指针。画图可以避免丢失节点。 -
遍历条件不要写错
循环链表遍历判断是cur != phead,而不是cur != NULL。 -
销毁链表要先释放所有数据节点,最后释放哨兵位
如果先把哨兵位 free 掉,后面的节点就找不到了。 -
使用 assert 检查空指针
所有函数开头都加上assert(phead != NULL),调试阶段能快速定位错误。 -
测试要覆盖边界
空链表、单节点、多节点的情况都要测。我的测试用例中连续尾删直到空链表就是为了验证空链表下LTPopBack是否断言。
七、完整代码仓库
所有代码已上传至 GitHub:
https://github.com/ZhangXiaolin-persist/data-structures-learning/tree/main/03_DoublyLinkedList
仓库中包含:
DoublyLinkedList.h(接口声明,带详细注释)DoublyLinkedList.c(实现,每个函数都有 Doxygen 风格的注释)test.c(完整测试用例)- -Makefile(编译脚本)
- 编译运行指令见 README
八、下一步计划
双向链表学完后,我会继续学习:
- 栈和队列(用双向链表实现会非常简单)
- 二叉树基础(递归思想)
- 排序算法(快排、归并)
如果你也在学数据结构,欢迎一起交流。代码有任何问题或建议,可以在 GitHub 上提 issue。
写博客真的是最好的复习方式 —— 写这篇博客的过程中,我又重新理解了“为什么哨兵位能让代码变简单”以及“删除节点后为什么不用置空指针”这些细节。
本文作者:zhangxiaolin
创建日期:2025-05-24
代码及注释均来自我的实现

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)